









https://mp.weixin.qq.com/s/33cKjVFf7pERyRHQtDwXoQ
k8s是什么?请说出你的了解?
答:Kubenetes是一个针对容器应用,进行自动部署,弹性伸缩和管理的开源系统。主要功能是生产环境中的容器编排。
K8S是Google公司推出的,它来源于由Google公司内部使用了15年的Borg系统,集结了Borg的精华。
K8s架构的组成是什么?
答:和大多数分布式系统一样,K8S集群至少需要一个主节点(Master)和多个计算节点(Node)。
- 节点主要用于暴露API,调度部署和节点的管理;
- 计算节点运行一个容器运行环境,一般是docker环境(类似docker环境的还有rkt),同时运行一个K8s的代理(kubelet)用于和master通信。计算节点也会运行一些额外的组件,像记录日志,节点监控,服务发现等等。计算节点是k8s集群中真正工作的节点。
简述 Kubernetes 中什么是 Minikube、Kubectl、Kubelet?
Minikube 是一种可以在本地轻松运行一个单节点 Kubernetes 群集的工具。
Kubectl 是一个命令行工具,可以使用该工具控制 Kubernetes 集群管理器,如检查群集资源,创建、删除和更新组件,查看应用程序。
Kubelet 是一个代理服务,它在每个节点上运行,并使从服务器与主服务器通信。
简述 Kubernetes 集群相关组件?
1、Master节点(默认不参加实际工作):
- Kubectl:客户端命令行工具,作为整个K8s集群的操作入口;
- Api Server:在K8s架构中承担的是“桥梁”的角色,作为资源操作的唯一入口,它提供了认证、授权、访问控制、API注册和发现等机制。客户端与k8s群集及K8s内部组件的通信,都要通过Api Server这个组件;
- Controller-manager:负责维护群集的状态,比如故障检测、自动扩展、滚动更新等;
- Scheduler:负责资源的调度,按照预定的调度策略将pod调度到相应的node节点上;
- Etcd:担任数据中心的角色,保存了整个群集的状态;
2、Node节点:
Kubelet:
负责维护容器的生命周期,同时也负责Volume和网络的管理,一般运行在所有的节点,是Node节点的代理,当Scheduler确定某个node上运行pod之后,会将pod的具体信息(image,volume)等发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向master返回运行状态。(自动修复功能:如果某个节点中的容器宕机,它会尝试重启该容器,若重启无效,则会将该pod杀死,然后重新创建一个容器)
Kube-proxy:
Service在逻辑上代表了后端的多个pod。负责为Service提供cluster内部的服务发现和负载均衡(外界通过Service访问pod提供的服务时,Service接收到的请求后就是通过kube-proxy来转发到pod上的)
Kube-proxy 是 kubernetes 工作节点上的一个网络代理组件,运行在每个节点上。
Kube-proxy维护节点上的网络规则,实现了Kubernetes Service 概念的一部分 。它的作用是使发往 Service 的流量(通过ClusterIP和端口)负载均衡到正确的后端Pod。
kube-proxy 工作原理
在k8s中,提供相同服务的一组pod可以抽象成一个service,通过service提供的统一入口对外提供服务,每个service都有一个虚拟IP地址(VIP)和端口号供客户端访问。
kube-proxy存在于各个node节点上,主要用于Service功能的实现,具体来说,就是实现集群内的客户端pod访问service,或者是集群外的主机通过NodePort等方式访问service。
在当前版本的k8s中,kube-proxy默认使用的是iptables模式,通过各个node节点上的iptables规则来实现service的负载均衡,但是随着service数量的增大,iptables模式由于线性查找匹配、全量更新等特点,其性能会显著下降。
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
- kube-proxy其实就是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。
- kube-proxy管理sevice的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP, 集群内通过访问这个Cluster IP:Port就能访问到集群内对应的serivce下的Pod。
- service是通过Selector选择的一组Pods的服务抽象,其实就是一个微服务,提供了服务的LB和反向代理的能力,而kube-proxy的主要作用就是负责service的实现。
- service另外一个重要作用是,一个服务后端的Pods可能会随着生存灭亡而发生IP的改变,service的出现,给服务提供了一个固定的IP,而无视后端Endpoint的变化。


container-runtime:
是负责管理运行容器的软件,比如docker
- Pod:是k8s集群里面最小的单位。每个pod里边可以运行一个或多个container(容器),如果一个pod中有两个container,那么container的USR(用户)、MNT(挂载点)、PID(进程号)是相互隔离的,UTS(主机名和域名)、IPC(消息队列)、NET(网络栈)是相互共享的。我比较喜欢把pod来当做豌豆夹,而豌豆就是pod中的container;

pod
简述 Kubernetes 中什么是静态 Pod?
静态 pod 是由 kubelet 进行管理的仅存在于特定 Node 的 Pod 上,他们不能通过 API Server 进行管理,无法与 ReplicationController、Deployment 或者 DaemonSet 进行关联,并且 kubelet 无法对他们进行健康检查。静态 Pod 总是由 kubelet 进行创建,并且总是在 kubelet 所在的 Node 上运行。
简述 Kubernetes 中 Pod 可能位于的状态?
Pending:API Server 已经创建该 Pod,且 Pod 内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
Running:Pod 内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
Succeeded:Pod 内所有容器均成功执行退出,且不会重启。
Failed:Pod 内所有容器均已退出,但至少有一个容器退出为失败状态。
Unknown:由于某种原因无法获取该 Pod 状态,可能由于网络通信不畅导致。
简述 Kubernetes 创建一个 Pod 的主要流程?
Kubernetes 中创建一个 Pod 涉及多个组件之间联动,主要流程如下:
- 客户端提交 Pod 的配置信息(可以是 yaml 文件定义的信息)到 kube-apiserver。
Apiserver 收到指令后,通知给 controller-manager 创建一个资源对象。 - Controller-manager 通过 api-server 将 pod 的配置信息存储到 ETCD 数据中心中。
- Kube-scheduler 检测到 pod 信息会开始调度预选,会先过滤掉不符合 Pod 资源配置要求的节点,然后开始调度调优,主要是挑选出更适合运行 pod 的节点,然后将 pod 的资源配置单发送到 node 节点上的 kubelet 组件上。
- Kubelet 根据 scheduler 发来的资源配置单运行 pod,运行成功后,将 pod 的运行信息返回给 scheduler,scheduler 将返回的 pod 运行状况的信息存储到 etcd 数据中心。
删除一个Pod会发生什么事情?
答:Kube-apiserver会接受到用户的删除指令,默认有30秒时间等待优雅退出,超过30秒会被标记为死亡状态,此时Pod的状态Terminating,kubelet看到pod标记为Terminating就开始了关闭Pod的工作;
关闭流程如下:
- pod从service的endpoint列表中被移除;
- 如果该pod定义了一个停止前的钩子,其会在pod内部被调用,停止钩子一般定义了如何优雅的结束进程;
- 进程被发送TERM信号(kill -14)
- 当超过优雅退出的时间后,Pod中的所有进程都会被发送SIGKILL信号(kill -9)。
简述 Kubernetes deployment 升级策略?
在 Deployment 的定义中,可以通过 spec.strategy 指定 Pod 更新的策略,目前支持两种策略:Recreate(重建)和 RollingUpdate(滚动更新),默认值为 RollingUpdate。
- Recreate:设置 spec.strategy.type=Recreate,表示 Deployment 在更新 Pod 时,会先杀掉所有正在运行的 Pod,然后创建新的 Pod。
- RollingUpdate:设置 spec.strategy.type=RollingUpdate,表示 Deployment 会以滚动更新的方式来逐个更新 Pod。同时,可以通过设置 spec.strategy.rollingUpdate 下的两个参数(maxUnavailable 和 maxSurge)来控制滚动更新的过程。
简述 Kubernetes 中 Pod 的重启策略?
Pod 重启策略(RestartPolicy)应用于 Pod 内的所有容器,并且仅在 Pod 所处的 Node 上由 kubelet 进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet 将根据 RestartPolicy 的设置来进行相应操作。
Pod 的重启策略包括 Always、OnFailure 和 Never,默认值为 Always。
- Always:当容器失效时,由 kubelet 自动重启该容器;
- OnFailure:当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器;
- Never:不论容器运行状态如何,kubelet 都不会重启该容器。
同时 Pod 的重启策略与控制方式关联,当前可用于管理 Pod 的控制器包括 ReplicationController、Job、DaemonSet 及直接管理 kubelet 管理(静态 Pod)。
不同控制器的重启策略限制如下:
RC 和 DaemonSet:必须设置为 Always,需要保证该容器持续运行;
Job:OnFailure 或 Never,确保容器执行完成后不再重启;
kubelet:在 Pod 失效时重启,不论将 RestartPolicy 设置为何值,也不会对 Pod 进行健康检查。
K8S的HPA机制
HPA(Horizontal Pod Autoscaler)Pod自动弹性伸缩,K8S通过对Pod中运行的容器各项指标(CPU占用、内存占用、网络请求量)的检测,实现对Pod实例个数的动态新增和减少。
Deployment和Statefulset区别
Deployment
- 适合场景
无状态的应用 - 特点
1.pod之间没有顺序
2.所有pod共享存储
3.pod名字包含随机数字
4.service都有ClusterIP,可以负载均衡
StatefulSet
- 适合场景
有状态的应用 - 特点
1.部署、扩展、更新、删除都要有顺序
2.每个pod都有自己存储,所以都用volumeClaimTemplates,为每个pod都生成一个自己的存储,保存自己的状态
3.pod名字始终是固定的
4.service没有ClusterIP,是headlessservice,所以无法负载均衡,返回的都是pod名,所以pod名字都必须固定,State


https://blog.csdn.net/nickDaDa/article/details/90401635
pod中penging状态,是什么原因产生的,pod出现问题,排查思路
Kubernetes 执行的过程中,对 API 对象的所有重要操作,都会被记录在这个对象的 Events 里,并且显示在 kubectl describe 指令返回的结果中。
比如,对于这个 Pod,我们可以看到它被创建之后,被调度器调度(Successfully assigned)到了 node-1,拉取了指定的镜像(pulling image),然后启动了 Pod 里定义的容器(Started container)。所以,这个部分正是我们将来进行 Debug 的重要依据。如果有异常发生,你一定要第一时间查看这些 Events
kubectl describe pod nginx-deployment-67254d7ar6-9bdvr
Name: nginx-deployment-67254d7ar6-9bdvr
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: node-1/10.168.0.3
Start Time: Thu, 03 Aug 2020 20:36:42 +0000
Labels: app=nginx
pod-template-hash=2321707621
Annotations: <none>
Status: Running
IP: 10.32.0.23
Controlled By: ReplicaSet/nginx-deployment-67254d7ar6
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 1m default-scheduler Successfully assigned default/nginx-deployment-67254d7ar6-9bdvr to node-1
Normal Pulling 23s kubelet, node-1 pulling image "nginx:1.7.9"
Normal Pulled 15s kubelet, node-1 Successfully pulled image "nginx:1.7.9"
Normal Created 16s kubelet, node-1 Created container
Normal Started 16s kubelet, node-1 Started container
pod如何优雅退出?
最后我们串起来再整个表述一下 Pod 退出的流程(官方文档):
- 1.用户删除 Pod
- 2.1.Pod 进入 Terminating 状态;
- 2.2.与此同时,k8s 会将 Pod 从对应的 service 上摘除;
- 2.3.与此同时,针对有 preStop hook 的容器,kubelet 会调用每个容器的 preStop hook,假如 preStop hook 的运行时间超出了 grace period,kubelet 会发送 SIGTERM 并再等 2 秒;
- 2.4.与此同时,针对没有 preStop hook 的容器,kubelet 发送 SIGTERM
- 3.grace period 超出之后,kubelet 发送 SIGKILL 干掉尚未退出的容器
阿里云监听设置连接优雅中断。
https://help.aliyun.com/document_detail/86531.html
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-connection-drain: "on"
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-connection-drain-timeout: "30"
name: nginx
namespace: default
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancer
service
K8s的Service是什么?
答:Pod每次重启或者重新部署,其IP地址都会产生变化,这使得pod间通信和pod与外部通信变得困难,这时候,就需要Service为pod提供一个固定的入口。
Service的Endpoint列表通常绑定了一组相同配置的pod,通过负载均衡的方式把外界请求分配到多个pod上

k8s是怎么进行服务注册的?
答:Pod启动后会加载当前环境所有Service信息,以便不同Pod根据Service名进行通信。
k8s集群外流量怎么访问Pod?
答:可以通过Service的NodePort方式访问,会在所有节点监听同一个端口,比如:30000,访问节点的流量会被重定向到对应的Service上面。
标签与标签选择器的作用是什么?
标签:是当相同类型的资源对象越来越多的时候,为了更好的管理,可以按照标签将其分为一个组,为的是提升资源对象的管理效率。
健康管理
请你说一下kubenetes针对pod资源对象的健康监测机制?
答:K8s中对于pod资源对象的健康状态检测,提供了三类probe(探针)来执行对pod的健康监测:
1) livenessProbe探针
可以根据用户自定义规则来判定pod是否健康,如果livenessProbe探针探测到容器不健康,则kubelet会根据其重启策略来决定是否重启,如果一个容器不包含livenessProbe探针,则kubelet会认为容器的livenessProbe探针的返回值永远成功。
2) ReadinessProbe探针
同样是可以根据用户自定义规则来判断pod是否健康,如果探测失败,控制器会将此pod从对应service的endpoint列表中移除,从此不再将任何请求调度到此Pod上,直到下次探测成功。
3) startupProbe探针
启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被上面两类探针kill掉,这个问题也可以换另一种方式解决,就是定义上面两类探针机制时,初始化时间定义的长一些即可。
Service
简述 Kubernetes Service 类型?
通过创建 Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。其主要类型有:
- ClusterIP:虚拟的服务 IP 地址,该地址用于 Kubernetes 集群内部的 Pod 访问,在 Node 上 kube-proxy 通过设置的 iptables 规则进行转发;
- NodePort:使用宿主机的端口,使能够访问各 Node 的外部客户端通过 Node 的 IP 地址和端口号就能访问服务;
- LoadBalancer:使用外接负载均衡器完成到服务的负载分发,需要在 spec.status.loadBalancer 字段指定外部负载均衡器的 IP 地址,通常用于公有云。
简述 Kubernetes Service 分发后端的策略?
Service 负载分发的策略有:RoundRobin 和 SessionAffinity
- RoundRobin:默认为轮询模式,即轮询将请求转发到后端的各个 Pod 上。
- SessionAffinity:基于客户端 IP 地址进行会话保持的模式,即第 1 次将某个客户端发起的请求转发到后端的某个 Pod 上,之后从相同的客户端发起的请求都将被转发到后端相同的 Pod 上。
容器
容器和主机部署应用的区别是什么?
答:容器的中心思想就是秒级启动;一次封装、到处运行;这是主机部署应用无法达到的效果,但同时也更应该注重容器的数据持久化问题。
另外,容器部署可以将各个服务进行隔离,互不影响,这也是容器的另一个核心概念。
k8s网络
ingress
简述 Kubernetes ingress?
Kubernetes 的 Ingress 资源对象,用于将不同 URL 的访问请求转发到后端不同的 Service,以实现 HTTP 层的业务路由机制。
Kubernetes 使用了 Ingress 策略和 Ingress Controller,两者结合并实现了一个完整的 Ingress 负载均衡器。
使用 Ingress 进行负载分发时,Ingress Controller 基于 Ingress 规则将客户端请求直接转发到 Service 对应的后端 Endpoint(Pod)上,从而跳过 kube-proxy 的转发功能,kube-proxy 不再起作用,全过程为:ingress controller + ingress 规则 ----> services。
同时当 Ingress Controller 提供的是对外服务,则实际上实现的是边缘路由器的功能。
ip
k8s-集群里的三种IP(NodeIP、PodIP、ClusterIP)
Kubernetes集群里有三种IP地址,分别如下:
Node IP:Node节点的IP地址,即物理网卡的IP地址。
Pod IP:Pod的IP地址,即docker容器的IP地址,此为虚拟IP地址。
Cluster IP:Service的IP地址,此为虚拟IP地址。
Node IP
可以是物理机的IP(也可能是虚拟机IP)。每个Service都会在Node节点上开通一个端口,外部可以通过NodeIP:NodePort即可访问Service里的Pod,和我们访问服务器部署的项目一样,IP:端口/项目名
Pod IP
Pod IP是每个Pod的IP地址,他是Docker Engine根据docker网桥的IP地址段进行分配的,通常是一个虚拟的二层网络
同Service下的pod可以直接根据PodIP相互通信
不同Service下的pod在集群间pod通信要借助于 cluster ip
pod和集群外通信,要借助于node ip
Cluster IP
Service的IP地址,此为虚拟IP地址。外部网络无法ping通,只有kubernetes集群内部访问使用。
https://blog.csdn.net/qq_21187515/article/details/101363521
面试题
StatefulSet 用过吗?有什么特点?
RC、Deployment、DaemonSet都是面向无状态的服务,它们所管理的Pod的IP、名字,启停顺序等都是随机的,而StatefulSet是什么?顾名思义,有状态的集合,管理所有有状态的服务,比如MySQL、MongoDB集群等。
特点:
- 稳定的不共享持久化存储:即每个pod的存储资源是不共享的,且pod重新调度后还是能访问到相同的持久化数据,基于pvc实现。
- 稳定的网络标志:即pod重新调度后其PodName和HostName不变,且PodName和HostName是相同的,基于Headless Service来实现的。
- 有序部署,有序扩展:即pod是有顺序的,在部署或者扩展的时候是根据定义的顺序依次依序部署的(即从0到N-1,在下一个Pod运行之前所有之前的pod必都是Running状态或者Ready状态),是基于init containers来实现的。
- 有序收缩:在pod删除时是从最后一个依次往前删除,即从N-1到0.
适用statefulset常用的服务有elasticsearch集群,mogodb集群,redis集群等等。
Kubernetes 的所有资源约定了版本号, 为什么要这么做?
为了在兼容旧版本的同时不断升级新的 API,Kubernetes 支持多种 API 版本,不同的 API 版本代表其处于不同的稳定性阶段,低稳定性的 API 版本在后续的产品升级中可能成为高稳定性的版本。
API 版本规则是通过基于 API level 选择版本,而不是基于资源和域级别选择,是为了确保 API 能够描述一个清晰的连续的系统资源和行为的视图,能够控制访问的整个过程和控制实验性 API 的访问。
K8s为什么要弃用docker?
然而在 2020 年 12 月,Kubernetes 社区决定着手移除仓库中 Dockershim 相关代码,这对于 Kubernetes 和 Docker 两个社区来说都意义重大。
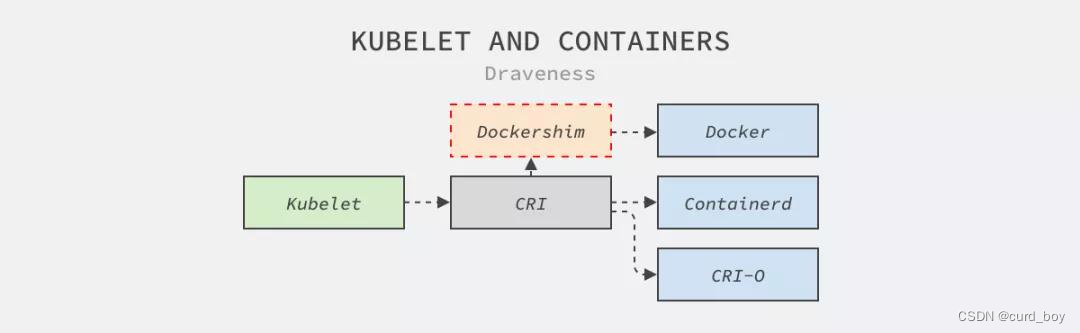
如上图所示,Kubernetes 中的节点代理 Kubelet 为了访问 Docker 提供的服务需要先经过社区维护的 Dockershim,Dockershim 会将请求转发给管理容器的 Docker 服务。
其实从上面的架构图中,我们就能猜测出 Kubernetes 社区从代码仓库移除 Dockershim 的原因:
- Kubernetes 引入容器运行时接口(Container Runtime Interface、CRI)隔离不同容器运行时的实现机制,容器编排系统不应该依赖于某个具体的运行时实现。Docker 构建的镜像,将在你的集群的所有运行时中继续工作,一如既往。
- Docker 没有支持也不打算支持 Kubernetes 的 CRI 接口,需要 Kubernetes 社区在仓库中维护 Dockershim。
什么是CRI?
说到Kubernetes剔除dockershim事件,不得不提到CRI。
首先我们先了解下CRI出现的背景:在 Kubernetes 早期(v1.5 之前),Docker 作为K8s支持唯一的容器运行时,Kubelet 是通过硬编码的方式 (dockershim) 直接调用 Docker API的;
后来出现了新的容器运行时rkt,也希望整合进了Kubelet代码中。但是后来随着越来越多的容器运行时的出现,继续内嵌的方式显然已经不适合了。在这个背景下,就提出了Container Runtime Interface(CRI )标准,用于将 Kubelet 代码与具体的容器运行时的实现代码解耦。
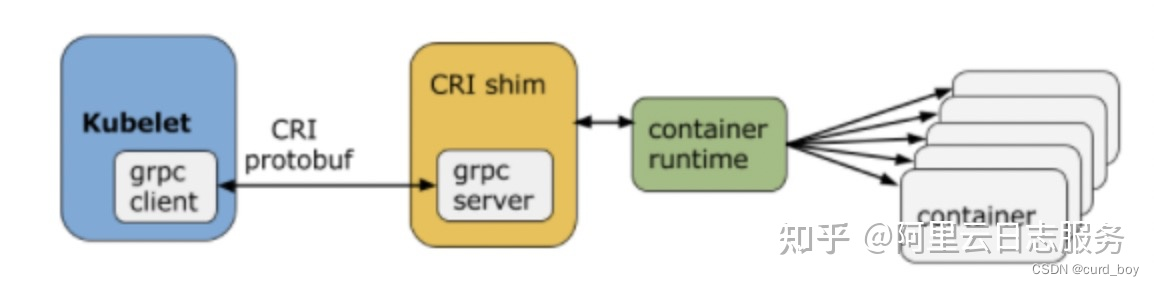
有了CRI,kubelet可以实现对于容器运行时(例如Docker、containerd、CRI-O等)的统一管理。
使用dockershim调用Docker,调用链路有点过长,且冗余操作较多
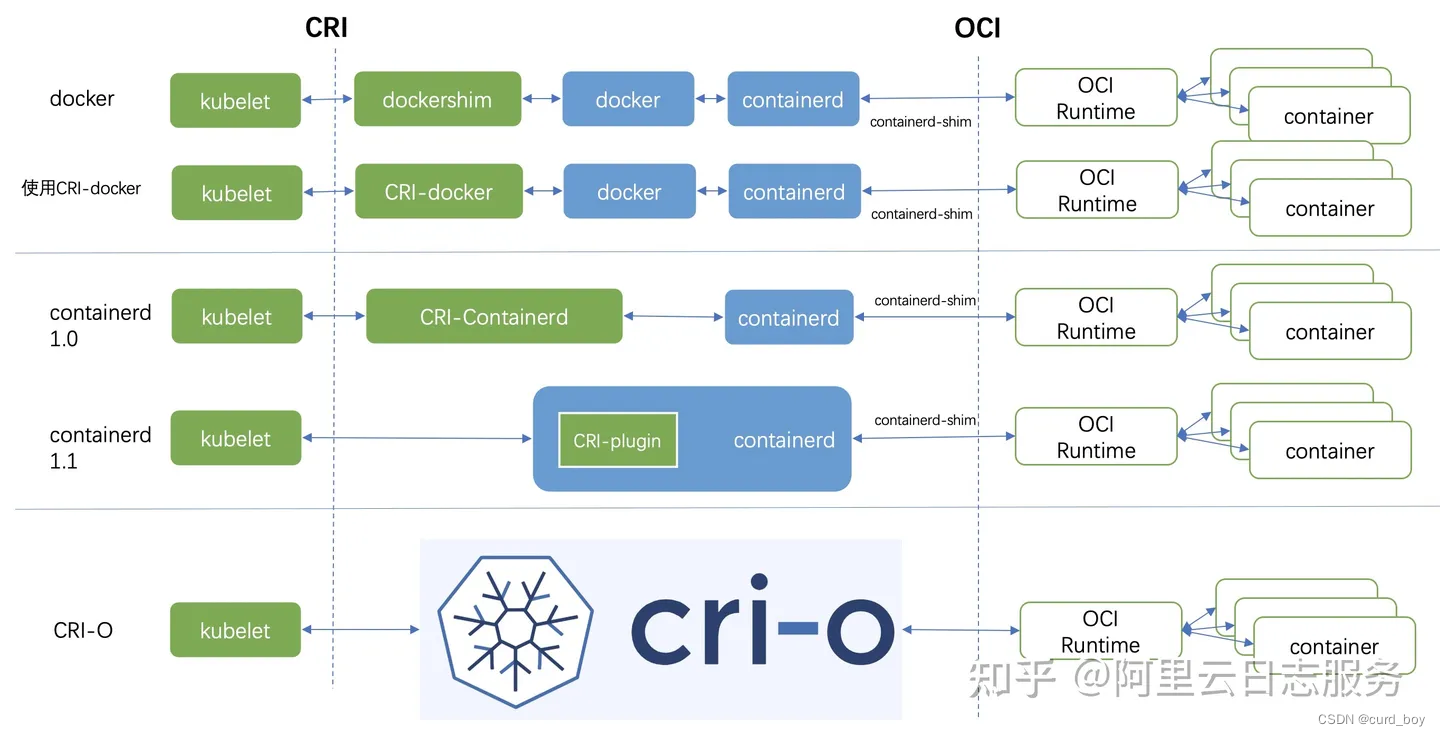
Kubernetes 推出 CRI 的时候还没有现在的统治地位,各种容器运行时并不会主动去实现 CRI 接口,所以就需要通过CRI shim的方式对各种容器运行时进行适配。
例如,Docker就没有打算支持CRI,原因有:Docker出现比Kubernetes早,Docker的地位比较稳固,处于强势的一方;Docker也有意推广Swarm,Swarm被视为K8s的竞品。最终,Kubelet选择了内置dockershim的方式,提供对Docker的支持。
Docker的调用链路有点过长,且冗余操作较多
Docker支持形态:
CRI推出初期,Docker江湖地位很高,Kubernetes为了支持Docker,在 kubelet 中内置了 dockershim。
流程:kubelet(CRI Client)通过 CRI 接口调用 dockershim(CRI Server);dockershim请求 Docker Daemon去调用containerd,然后通过containerd-shim、runc去真正创建容器。
很显然,Docker的调用链路有点过长,且冗余操作较多。也正是因为这个原因,随着 CRI 的生态越来越完善,最终Kubernetes 社区在2020年7月决定开始着手移除 dockershim 了,1.24 版本已正式删除dockershim。
提高可扩展性
Kubernetes 通过引入新的容器运行时接口将容器管理与具体的运行时解耦,不再依赖于某个具体的运行时实现。
很多开源项目在早期为了降低用户的使用成本,都会提供开箱即用的体验,而随着用户群体的扩大,为了满足更多定制化的需求、提供更强的可扩展性,会引入更多的接口。
containerd
containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性。
- 管理容器的生命周期(从创建容器到销毁容器)
- 拉取/推送容器镜像
- 存储管理(管理镜像及容器数据的存储)
- 调用 runc 运行容器(与 runc 等容器运行时交互)
- 管理容器网络接口及网络
containerd 最早是从 Docker 里分离出来,作为一个独立的开源项目,目标是提供一个更加开放、稳定的容器运行基础设施。(详见Docker部分的架构图)
总结
今天的 Kubernetes 已经是非常成熟的项目,它的关注点也逐渐从提供更完善的功能转变到提供更好的扩展性,这样才能满足不同场景和不同公司定制化的业务需求。
Kubernetes 在过去因为 Docker 的热门而选择 Docker,而在今天又因为高昂的维护成本而放弃 Docker,我们能够从这个过程中体会到容器领域的发展和进步。
移除 Docker 的种子其实从 CRI 发布时就种下了,Dockershim 一直都是 Kubernetes 为了兼容 Docker 获得市场采取的临时决定。
对于今天已经统治市场的 Kubernetes 来说,Docker 的支持显得非常鸡肋,移除代码也就顺理成章了。
我们在这里重新回顾一下 Kubernetes 在仓库中移除 Docker 支持的两个原因:
-
Kubernetes 在早期版本中引入 CRI 摆脱依赖某个具体的容器运行时依赖,屏蔽底层的诸多实现细节,让 Kubernetes 能够更关注容器的编排。
-
Docker 本身不兼容 CRI 接口,而且官方并没有实现 CRI 的打算,同时也不支持容器的一些新需求,所以 Dockershim 的维护成为了社区的想要摆脱负担。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









