







目录
实验问题
malloc是在堆上进行内存非配的系统调用,设计一个实验逆向分析linux才用了何种分配策略,给出分析。
基础知识
malloc / free函数
使用malloc,需要包含头文件 stdlib.h ,函数原型如下:
extern void *malloc(unsigned int num_bytes);功能: 分配长度为num_bytes的内存块,如果分配成功,则返回指向被分配内存的指针,否则返回空指针NULL,否则发生的情况,一般为系统堆上可用的内存上无法找到一块长度大于num_bytes的连续内存空间。
特别情况:如果num_bytes为0,malloc成功分配0字节的空间,返回一个有效指针,但无法使用此指针。
当内存不再使用时,应使用free函数将内存块释放。
返回值类型为void*,表示未确定类型的指针,它可以强制转换为任何其他类型的指针。
使用free函数释放空间,原型如下:
extern free(void *FirstByte);功能: 将之前malloc分配的空间还给操作系统,释放传入指针指向的那块内存区域,指针本身的数值没变,释放前,指向的内容是可理解的,释放后,指向的内容是垃圾内容。
注意: 释放空指针,不会出错。释放同一个有效指针两次,会出错。释放后,最好把指向这块内存的指针指向NULL,防止后面的程序误用。
malloc的使用
在Linux中,用户态申请分配内容的系统调用是sbrk(n),参数n是期望得到的内存字节数。但是,频繁的调用sbrk进行分配会使得真实内存出现越来越多的零碎空间。Linux操作系统的基本分配方式是伙伴分配方式,所以即使申请的字节数不是2的幂数,系统也会分配出2的幂数的空间来。因此malloc的实现不会是每次都动用内核的。
malloc采用的总体策略:先系统调用sbrk一次,会得到一段较大的并且是连续的空间。进程把系统内核分配给自己的这段空间留着慢慢用。之后调用malloc时就从这段空间中分配,free回收时就再还回来(而不是还给系统内核)。只有当这段空间全部被分配掉时还不够用时,才再次系统调用sbrk。当然,这一次调用sbrk后内核分配给进程的空间和刚才的那块空间一般不会是相邻的。一次sbrk之后,malloc就会保留着一段大的连续空间(称作堆空间)。之后对于堆空间malloc不断地分配,free不断地收回,这段空间有的已分配,有的未分配。
空闲链表分配内存块方法:
1、首次适应法(First Fit):链表按块地址排序。选择第一个满足要求的空闲块。特点:低地址碎片多,高地址碎片少。
2、最佳适应法(Best Fit):链表按空闲块大小排序。选择满足要求的,且大小最小的空闲块。特点:费时间,并且会出现很小的碎片。
3、最坏适应法(Worst Fit):链表按空闲块大小排序。选择最大的空闲块。特点:碎片少,容易缺乏大块。
Linux 内存分配
Linux 使用虚拟地址空间,大大增加了进程的寻址空间,由低地址到高地址分别为:
1、只读段:该部分空间只能读,不可写;(包括:代码段、rodata 段(C常量字符串和#define定义的常量) )
2、数据段:保存全局变量、静态变量的空间;
3、堆 :就是平时所说的动态内存, malloc/new 大部分都来源于此。其中堆顶的位置可通过函数 brk 和 sbrk 进行动态调整。
4、文件映射区域:如动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
5、栈:用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看。
6、内核虚拟空间:用户代码不可见的内存区域,由内核管理(页表就存放在内核虚拟空间)。
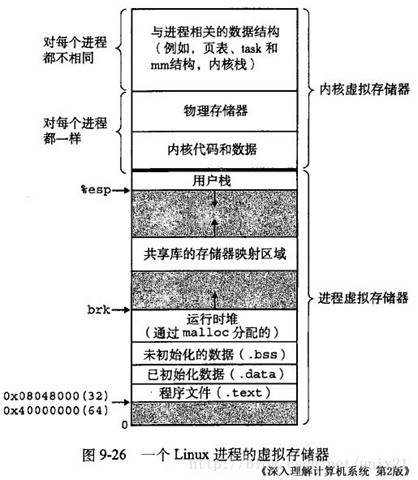
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap。
(1)brk是将数据段(.data)的最高地址指针_edata往高地址推;
(2)mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存。
1、malloc小于128k的内存,使用brk分配内存,将_edata往高地址推
mmap内存映射文件是在堆和栈的中间_edata指针(glibc里面定义)指向数据段的最高地址。
进程调用malloc(30K)以后malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。
因为_edata+30K只是完成虚拟地址的分配,这块内存现在还是没有物理页与之对应的,等到进程第一次读写这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了这块内容,然后从来不访问它,那么其对应的物理页是不会被分配的。
2、malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配
因为brk分配的内存需要等到高地址内存释放以后才能释放,而mmap分配的内存可以单独释放。
3、查看碎片及地址分配情况
glibc 提供了以下结构和接口来查看堆内内存和 mmap 的使用情况。
struct mallinfo {
int arena; /* non-mmapped space allocated from system */
int ordblks; /* number of free chunks */
int smblks; /* number of fastbin blocks */
int hblks; /* number of mmapped regions */
int hblkhd; /* space in mmapped regions */
int usmblks; /* maximum total allocated space */
int fsmblks; /* space available in freed fastbin blocks */
int uordblks; /* total allocated space */
int fordblks; /* total free space */
int keepcost; /* top-most, releasable (via malloc_trim) space */
};
/*返回heap(main_arena)的内存使用情况,以 mallinfo 结构返回 */
struct mallinfo mallinfo();
/* 将heap和mmap的使用情况输出到stderr*/
void malloc_stats();实验过程
测试代码如下:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/mman.h>
#include <malloc.h>
size_t heap_malloc_total, heap_free_total,mmap_total, mmap_count;
void print_info()
{
struct mallinfo mi = mallinfo();
printf("count by itself:\n");
printf("\theap_malloc_total=%lu heap_free_total=%lu heap_in_use=%lu\n\tmmap_total=%lu mmap_count=%lu\n",
heap_malloc_total*1024, heap_free_total*1024, heap_malloc_total*1024-heap_free_total*1024,
mmap_total*1024, mmap_count);
printf("count by mallinfo:\n");
printf("\theap_malloc_total=%lu heap_free_total=%lu heap_in_use=%lu\n\tmmap_total=%lu mmap_count=%lu\n",
mi.arena, mi.fordblks, mi.uordblks,
mi.hblkhd, mi.hblks);
printf("from malloc_stats:\n");
malloc_stats();
}
#define ARRAY_SIZE 20
int main(int argc, char** argv)
{
char** ptr_arr[ARRAY_SIZE];
int i;
//malloc操作
for( i = 0; i < ARRAY_SIZE; i++)
{
ptr_arr[i] = malloc(i * 1024);
if ( i < 128) //glibc默认128k以上使用mmap
{
heap_malloc_total += i;
}
else
{
mmap_total += i;
mmap_count++;
}
printf("%dptr_arr是%p\n",i,ptr_arr[i]);
}
print_info();
//free操作
for( i = 0; i < ARRAY_SIZE; i++)
{
if ( i % 2 == 0)
continue;
free(ptr_arr[i]);
if ( i < 128)
{
heap_free_total += i;
}
else
{
mmap_total -= i;
mmap_count--;
}
printf("%dptr_arr是%p\n",i,ptr_arr[i]);
}
printf("\nafter free\n");
print_info();
//再次malloc操作
for( i = 0; i < ARRAY_SIZE; i++)
{
ptr_arr[i] = malloc(i * 1024);
if ( i < 128) //glibc默认128k以上使用mmap
{
heap_malloc_total += i;
}
else
{
mmap_total += i;
mmap_count++;
}
printf("%dptr_arr是%p\n",i,ptr_arr[i]);
}
print_info();
return 1;
}验证两种内存分配方式
先直接测试不加地址输出的结果,根据测试可知,当i的值大于128之后,统计出mmap在堆和栈之间找一块空闲内存分配的个数与mallinfo 得到的信息基本吻合。因为用的测试量为200,每次申请的空间大小循环以 (i x 1024)递增,所以当i>128之后mmap_count为72。free一半之后,可见mmap_count减半,但heap_malloc_total没有太大变化。
由此验证了上文所述的内存分配方式,brk分配的内存需要等到高地址内存释放以后才能释放,而mmap分配的内存可以单独释放。

其逻辑如图示:

测试分析内存分配策略
再次加入输出地址语句printf("%dptr_arr是%p\n",i,ptr_arr[i]);,可看到地址分配情况
在测试地址时为便于查看,将循环改为20次,故malloc我的空间全部为小于128K的情况。
1)首先进行循环malloc操作,逐次递增的申请空间

2)接下来抽选一些空间进行释放

3)再次进行空间申请

可知申请的空间按顺序是递增的,但当初释放的空间是有间隔释放的,故再次申请的时候,申请需求一定为小于等于可用的空间。由于结果为申请到的空间顺序还是按照当初释放空间的顺序,也就是说较小的需求优先选择了较小的空间去满足自己,故由此可以排除最坏适应法(Worst Fit)
但是此处也出现了一个问题:正因为可用空间和需求都递增,此种情况既符合首次适应法,也符合最佳适应法。
4)尝试颠倒顺序,申请空间的为逐次递减
修改代码如下:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/mman.h>
#include <malloc.h>
#define ARRAY_SIZE 20
int main(int argc, char** argv)
{
char** ptr_arr[ARRAY_SIZE];
int i;
//malloc操作
for( i = ARRAY_SIZE; i>0; i--)
{
ptr_arr[i] = malloc(i * 1024);
printf("%dptr_arr是%p\n",ARRAY_SIZE-i,ptr_arr[i]);
}
printf("\n");
//free操作
for( i = ARRAY_SIZE; i>0; i--)
{
if ( i % 2 == 0)
continue;
free(ptr_arr[i]);
printf("%dptr_arr是%p\n",ARRAY_SIZE-i,ptr_arr[i]);
}
printf("\n");
//再次malloc操作
for( i = 0; i<ARRAY_SIZE; i++)
{
ptr_arr[i] = malloc(i * 1024);
printf("%dptr_arr是%p\n",i,ptr_arr[i]);
}
return 1;
}5)编译运行修改后的程序,初次申请空间的地址分配如图,由地址分配情况可确认申请的空间大小为逐次递减。

6)同上一次操作类似,有间隔是释放一些空间

根据编号可见释放为当初的单数序号空间,同样空间大小为递减
7)再次进行申请空间操作,这里要注意,再次申请的空间大小是递增,如此可以保证再次申请的空间需求一定是小于等于可用的空间大小,且随着序号的增加差距越小,由此可以实现乱序的目的。同时可以有效分辨首次适应法与最佳适应法
可作出两种判断:
a、如果为首次适应法,那么先再申请的较小空间遇到第一个释放的较大空间就会申请成功,地址分配与释放空间顺序一致
b、如果为最佳适应法,那么先再申请的较小空间会在遇到满足需求且较小的空间时才申请成功,地址分配与释放空间顺序相反
逻辑图如下:

测试结果如下图:

由测试结果可明显看出前十个再申请的空间的地址顺序与之前释放的顺序相反,也就是说先从可用的最小空间开始满足需求,在所释放的10个空间用完之后再去申请新的空间。因此我们可以得出该操作系统动态内存分配策略采用的是最佳适应法。
实验总结
通过本次实验,对于内存分配的各种策略以及malloc/free函数的运用有了进一步的认识和理解。同时对于linux系统也有了更深一层的感受,在实验过程中查阅了大量的资料,加上实际的测试,对于一些较为抽象的知识概念也更加明确。在本次实验中涉及到的两个系统调用:brk和mmap,对于他们不同的内存分配和释放方式,通过实验验证也有了更加感性的认识,同时在这个过程中巩固了对系统调用的理解。希望在之后的实验中可以再接再厉,加油~















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









