









1、ods层做了哪些事?
(1)ods层建模的规则:保持数据原貌,不做任何修改,和业务系统保持一致====>数据备份
(2)采用压缩 snappy,lzo =====>节省磁盘的空间
(3)创建分区表,增加抽取日期做为分区。 =====>防止后续全表扫描(有些十几年的数据,使用分区表,从ods--->dwd层,只需要扫描一天的数据,这就是分区的意义)
2、dwd层做了哪些事?
dwd层的维度规则:定义表名,事实表、维度表。
清洗只会影响行,不影响列。
转换:会影响(要统一)字段名、字段类型、字段的数量、有些表要增加转换后的字段(年、季度、月、周)。
拉链表:要增加起始时间、结束时间(所以也会影响表结构)。
(1)数据清洗
1)空值去除
2)过滤核心字段无意义的数据,比如订单表中订单id为null,支付表中支付id为空;
3)重复数据,进行过滤;
(2)清洗手段
HQL、MR、SparkSQL、Kettle、Python(一般项目中采用sql进行清除)
(3)清洗掉多少数据算合理
1万条数据清洗掉1条。
(4)数据脱敏
md5(hive自带的函数);身份证号、手机号(177***0013)、银行卡号
(5)采用压缩
lzo 、snappy ======>减少磁盘空间(100G-->10G)
(6)采用列式存储
parquet、orc =====>增加查询速度
(7)数仓建模(这个是第一步的!!!!!,但是内容太多放在第7了)
dwd层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
维度建模一般按照以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
1)选择业务过程
选择关心的事实表(下单、支付、点赞、收藏)
中小型公司:选择所有的业务线
大型公司:3000张表(选择感兴趣的业务线)
2)声明粒度
一行数据表示上面含义:1次、1天、1周、一个月(尽可能选择最小粒度,不然一行代 表 聚合一个月的数据,求这个月中某一天的数据就没办法了)
例如订单表里面: 张三(用户) 下单 10块钱 (1.代表买了一个商品一次10块?2.还是 代表一天以内把所有商品买了10块?3.还是一周时间内买的所有商品10块?)
声明粒度:一般选择一次或者一天
(不要做聚合操作就可以了)
3)确认维度
时间、地区、用户、商品、活动、优惠卷(都是描述性的名称,称为维度信息,一般也就 是 where或者group by筛选的字段)
对于某些维度信息退化(维度建模当中的星型模型,让事实表周围只有一级维度):
1)对业务数据传过来的表进行维度退化和降维。(商品一级二级三级、省市县、年月 日)
2)商品表、spu表、品类表、商品一级分类、二级分类、三级分类===>商品表
3)省份表、地区表=>地区表
4)时间表、假期表===>时间表
5)活动表、活动规则表===>活动表
4)确认事实
确认事实中的度量值(次数、件数、个数、金额)。
度量值的特点是可以累加。
通过以上步骤,结合本数仓的业务事实,得出业务总线矩阵表如下表所示。业务总线矩 阵的原则,主要是根据维度表和事实表之间的关系,如果两者有关联则使用√标记。
表 业务总线矩阵表
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
| 订单 | √ | √ | √ | √ | 件数/金额 | |||
| 订单详情 | √ | √ | √ | 件数/金额 | ||||
| 支付 | √ | √ | 次数/金额 | |||||
| 加购 | √ | √ | √ | 件数/金额 | ||||
| 收藏 | √ | √ | √ | 个数 | ||||
| 评价 | √ | √ | √ | 个数 | ||||
| 退款 | √ | √ | √ | 件数/金额 | ||||
| 优惠券领用 | √ | √ | √ | 个数 |

至此,数仓的维度建模已经完毕,DWS、DWT和ADS和维度建模已经没有关系了。
DWS和DWT都是建宽表,宽表都是按照主题去建。主题相当于观察问题的角度。对应着维 度表。
3、dws层做了哪些事?
字段怎么来?
站在维度表的角度去看待事实,主要看的是事实表的度量值,通过与之关联的事实表,获得不同的事实表的度量值。
不懂? 没关系
思考:1、dws是根据什么建模规则来创建表的?
宽表的目的:减少join,复用,提升select查询时的性能,
同时副表的数据不能比主表多太多,会影响效率,
将关联表的字段,都放进来,尽量不要丢字段,不然以后要使用就麻烦。
2、还有为啥不弄一张大宽表,到时候直接查一张表就可以了?
原因就是每个不同的表数据不一样。

4、dwt层做了哪些事?
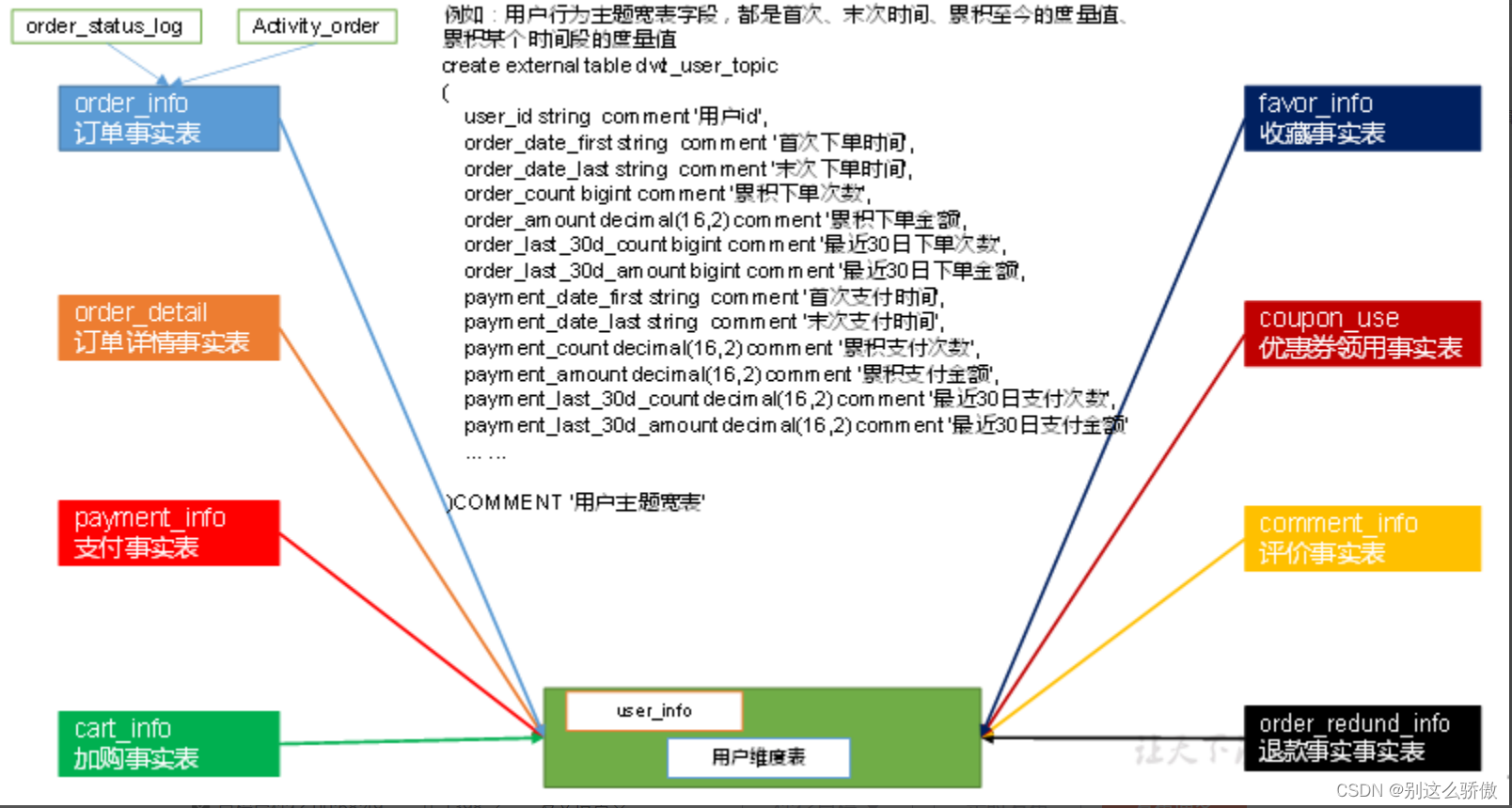
DWT层主题宽表都记录什么字段?
如图所示,每个维度关联的不同事实表度量值以及首次、末次时间、累积至今的度量值、累积某个时间段的度量值。
根据需求倒推
业务过程 + 统计周期 + 统计粒度 相同的 多个派生指标 ===》 放到一张汇总表
比如:交易域用户商品粒度订单最近1日汇总表
业务过程: 订单
统计周期: 最近1日
统计力度: 用户商品
分类: 最近1天的汇总、最近n天的汇总、历史至今的汇总 ==》 22张汇总表
5、ads层做了哪些事?
有多少个?
平时100左右 活动时200个左右 我们公司试过400、500个
分别对设备主题、会员主题、商品主题和营销主题进行指标分析,其中营销主题是用户主题和商品主题的跨主题分析案例
出指标: 分析过哪些指标
---》 手写 (指标实现的思路 :例如:谁跟谁Join、按照什么groupby聚合、怎么开窗)
















 2887
2887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











