






文章信息
- 来源:AAAI 2023收录
- 作者:Hong-Kyun Bae, Jeewon Ahn, Dongwon Lee, Sang-Wook Kim
- 机构:汉阳大学、宾夕法尼亚大学
- 领域:新闻推荐
- 主要成果:使之前推荐算法的推荐准确率提升40%
一、概要
Introduction
根据前人研究,已过期的新闻极少被点击(MIND数据集中85%的新闻在发布后48小时内最后一次被点击)。所以作者提出以下两种假设:
- 新闻有生命周期(从发布到最后一次被点击,且为小时级别)。
- 新闻只和那些处在重叠的生命周期中的其他新闻构成有限的竞争关系,也就是只和那些生命周期有交集的其他新闻构成竞争。
基于这些前提,作者提出新闻推荐方法Lifetime-Aware News reCommEndeR system (LANCER),(好牵强的名字),具备以下三个创新点:
- 对处于竞争关系的新闻进行考量:生命周期有交集的新闻里,被点击的新闻是更受欢迎的。
- 对处于竞争关系的新闻进行基于置信度的负采样:在所有未被点击且处于交集生命周期的新闻里,那些不受欢迎的新闻才是真正的负样本。
- 将新闻的剩余生命周期纳入考量:即去推荐那些既具有好的预测表现,又具有充足的剩余生命周期的新闻。
主要贡献:
- 通过新闻大多数点击发生的时间制定了生命周期这一概念,并且定量表示了新闻的平均生命周期。
- 提出了新闻间的优先竞争,并证实这一关系可以有效提升模型的训练。
- 提出了LANCER这一方法。
- 评估了LANCER这一方法对现有新闻推荐模型的显著提升。
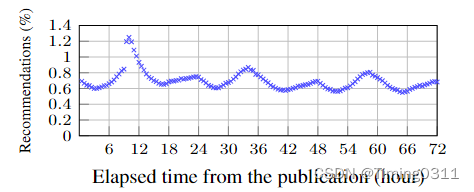
Motivation
通过统计发现Adressa(新闻数据集)和Netflix(视频数据集)相比确实具有更短的点击率生命周期。由此定义新闻的生命周期Lifetime(m)即m%的点击率发生时的新闻发布时间,例如lifetime(80)=36 hours。而前人的研究并没有考虑新闻的生命周期,也没有考虑新闻的竞争关系是建立在各自的剩余生命周期上的。如NRMS这一模型,仍在推荐发布48小时后的新闻。
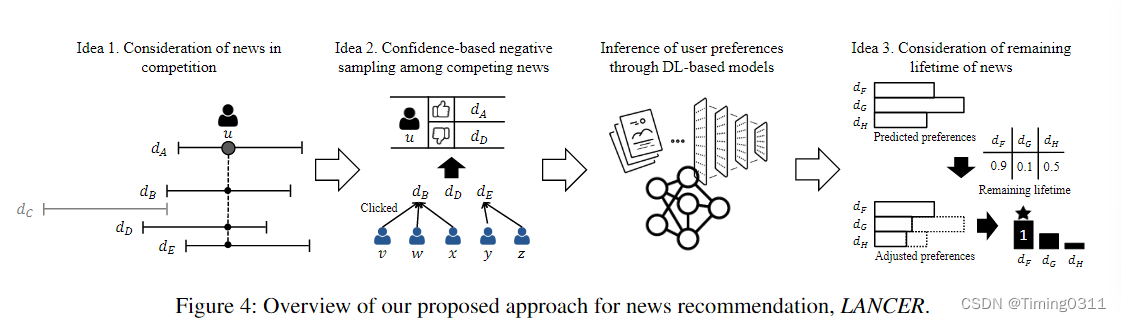
The Proposed Approach: LANCER
Idea1:找到生命周期有交集的新闻,并区别出阳性和阴性的样本
设定36小时为新闻的生命周期
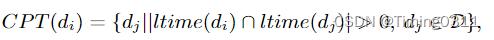
在相同生命周期内,被点击的样本是阳性的,未被点击的是阴性的。训练数据是阳性/阴性对,如:
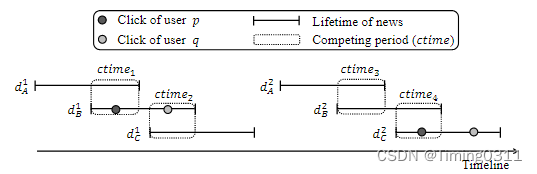
对用户p:db1/da1, dc2/db2, C > B > A
对用户q:db1/dc1, B > C
Idea2:从阴性样本中基于置信度筛选出真阴性样本
阴性样本:构成竞争的样本中未被点击的
但是这种阴性样本可能是由于用户还不知道它们的存在,所以才没有被点击,而非真的对他们不感兴趣。所以真阴性被定义为:既未被点击又本身就不受欢迎的新闻。
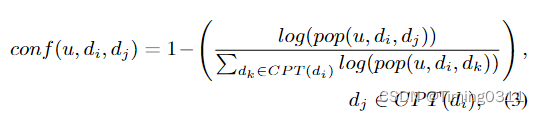
u:用户,di:阳性样本,dj:阴性样本
pop(u,di,dj):其他用户在用户u点击di之前,dj的点击量。
为了缓解基于pop的置信度之间巨大的差异,用log进行了平滑处理。
训练:
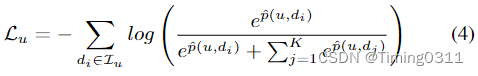
对用户u,1个阳性样本对应K个阴性样本,p是u对d的偏好程度,由用户特征u和新闻特征d做点积得到。
本质上还是个softmax,期望最大化输出di的概率。这里公式的推到可以借鉴一文详解Softmax函数,讲的十分详细。
Idea3:推荐那些剩余生命周期充足的新闻
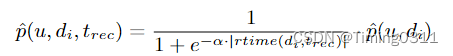
|rtime(di, trec)|di在trec时刻的剩余生命周期,trec即推荐的时刻。计算方式是生命周期-(推荐时刻-发布时刻)。
α需要学习的超参数,决定了u对di的偏好p需要减少多少。
Empirical Evaluation
所选数据集:MIND,Adressa
预处理:MIND无发布时间和点击时间,所以对某一新闻,所有用户中第一次对其有印象的时间视为发布时间,对其点击有印象的时间作为点击时间。
评价指标:AUC,MRR,NUCG(G)
实验目标:
- 考虑有限的竞争后,对决定用户的阴性样本到底有多大效果。
- 加入基于流行度的置信评估后,对阴性样本的采样到底有多大效果。
- 考虑剩余生命周期后,对预测用户的偏好到底有多大效果。
- 超参数α对推荐的准确率到底有多大影响。
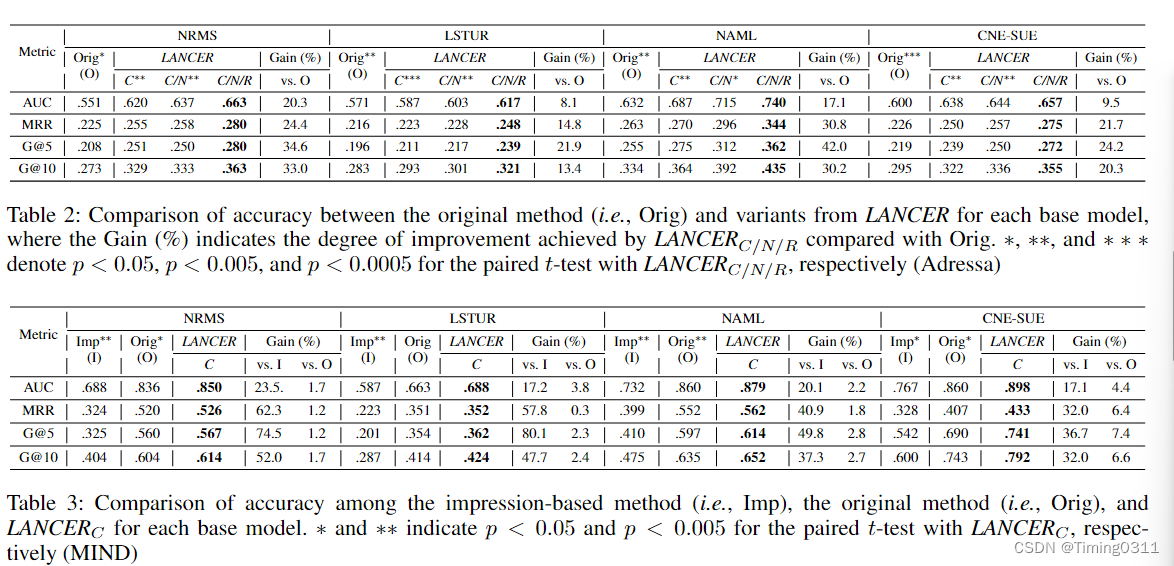
C:只考虑有限竞争的阴性样本,随机采样K个,结论是在Adressa数据集上提升了10%-20%;在MIND上提升3%-7.5%,甚至还有负提升的。
C/N:结合ideas1-2后,对低流行度的负样本给予高概率。结果是在Adressa上又提升了2.7%-13.5%。
C/N/R:又多考虑了剩余生命周期,在Adressa上又提升了9%-16%。还给出了考虑剩余生命周期后的推荐概率变化。
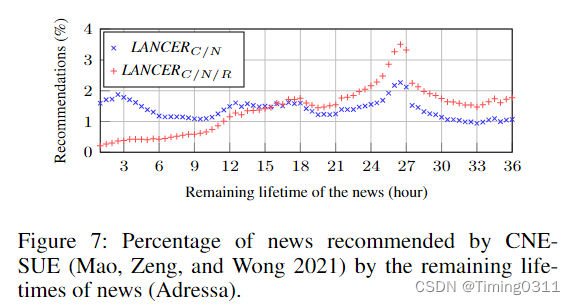
文章也测试了不同α取值对推荐准确度的影响,结果证明较小的α更为有效地区分了剩余生命周期较短的新闻的偏好。
二、个人评价
- 文章构建了新闻生命周期这一新特征,并对该特征进行了较为深度的挖掘,对基础模型提升明显,这也提示我们,学科交叉真的能提供一些新思路,看似不复杂的特征其实大有可为。
- 文章实验很饱满很丰富,这一点上下的功夫和耐心真的值得学习。
- 文章提出的模型可以插入到任一基础模型上,这一点更说明了该特征的有效性。
- 对于总体的训练流程如果能再细致说明下输入输出就好了。
- 对于新闻生命周期的界定,文章仅计算了数据集中的平均长度,个人认为这一特征对于不同领域、不同重要程度、不同敏感度的人都应该是不一样的,当然这一点如果也做点积去预测、计算得到再输入到整体的推荐结果里应该也是能起效的,但是提升可能相对于本文就不大了。















 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









