






 本文介绍了Elasticsearch的基本概念、安装步骤、Kibana的安装与验证、ES中的核心概念以及常用的API接口,包括创建索引、文档操作、条件查询、高亮显示和分词搜索等,帮助读者快速理解并开始使用Elasticsearch。
本文介绍了Elasticsearch的基本概念、安装步骤、Kibana的安装与验证、ES中的核心概念以及常用的API接口,包括创建索引、文档操作、条件查询、高亮显示和分词搜索等,帮助读者快速理解并开始使用Elasticsearch。
目录
什么是Elasticsearch?
The Elastic Stack, 包括 Elasticsearch【搜索,分析】、 Kibana【可视 化】、 Beats 和 Logstash【数据的搜集】(也称为 ELK Stack)。能够安 全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、 分析和可视化。 Elaticsearch,简称为 ES, ES 是一个开源的高扩展的分布式全文搜索引 擎, 是整个 ElasticStack 技术栈的核心。 它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台 服务器,处理 PB 级别的数据。
安装
安装很简单,下载好压缩包后,解压运行就可以了
解压后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务 。
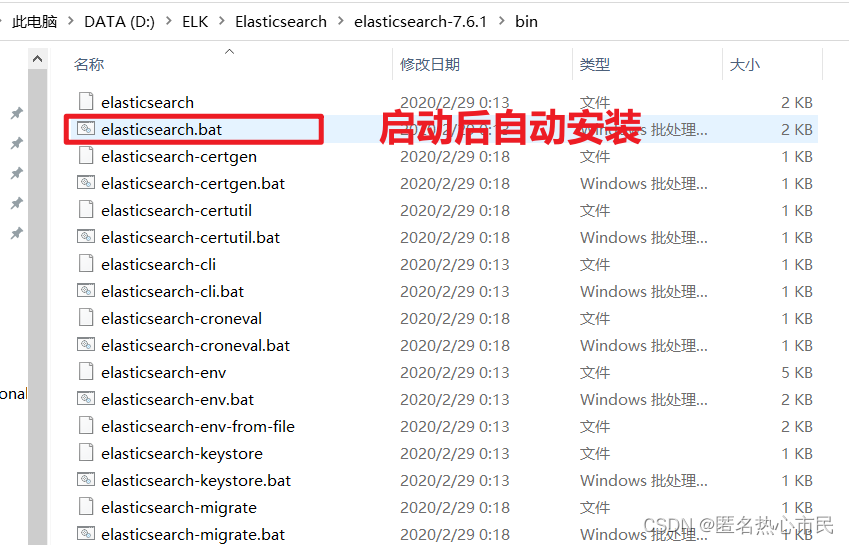
验证安装
注意: 9300 端口为 Elasticsearch 集群间组件的通信端口, 9200 端口为 浏览器访问的 http协议 RESTful 端口。
按装图形化界面Kibana
Elasticsearch是专门用来作搜索的,图形化界面需要安装kibana,他是es数据的前端展现,数据分析时,可以方便地看到数据。作 为开发人员,可以方便访问es。
安装
他的安装也很简单,下载完毕后,解压后直接运行。
解压后进入in目录
验证安装
访问5601端口
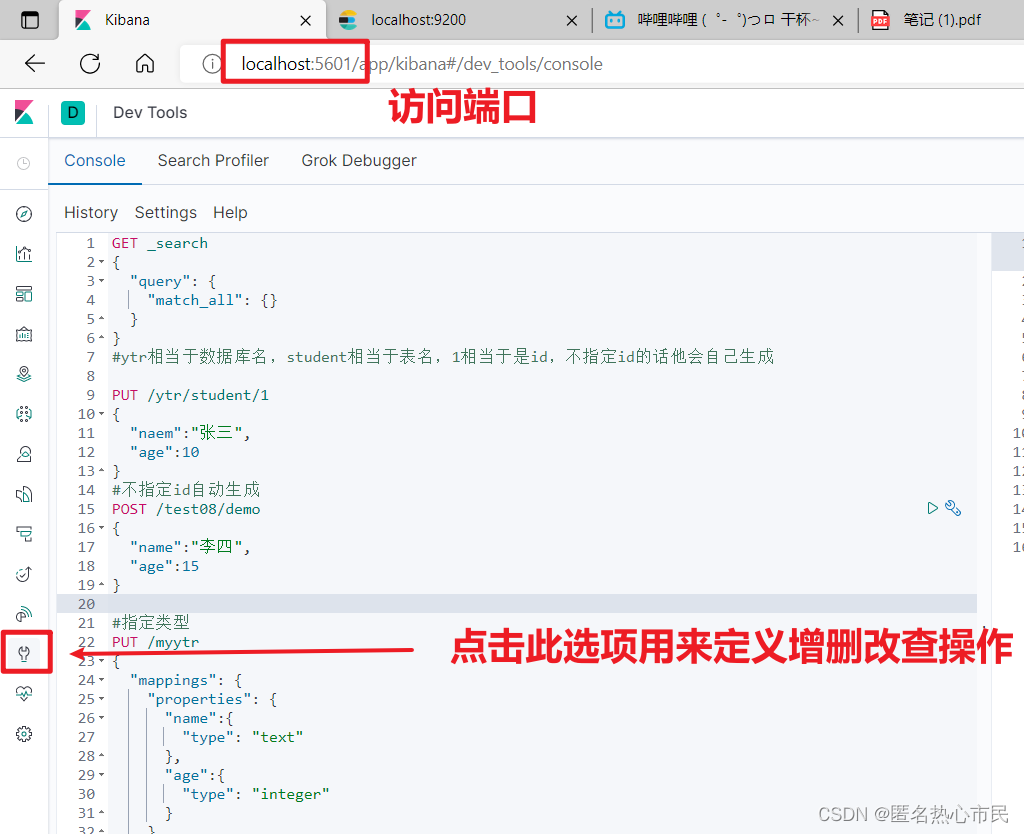
ES中常见的概念
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当 于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一 个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已 经被删除了。
将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
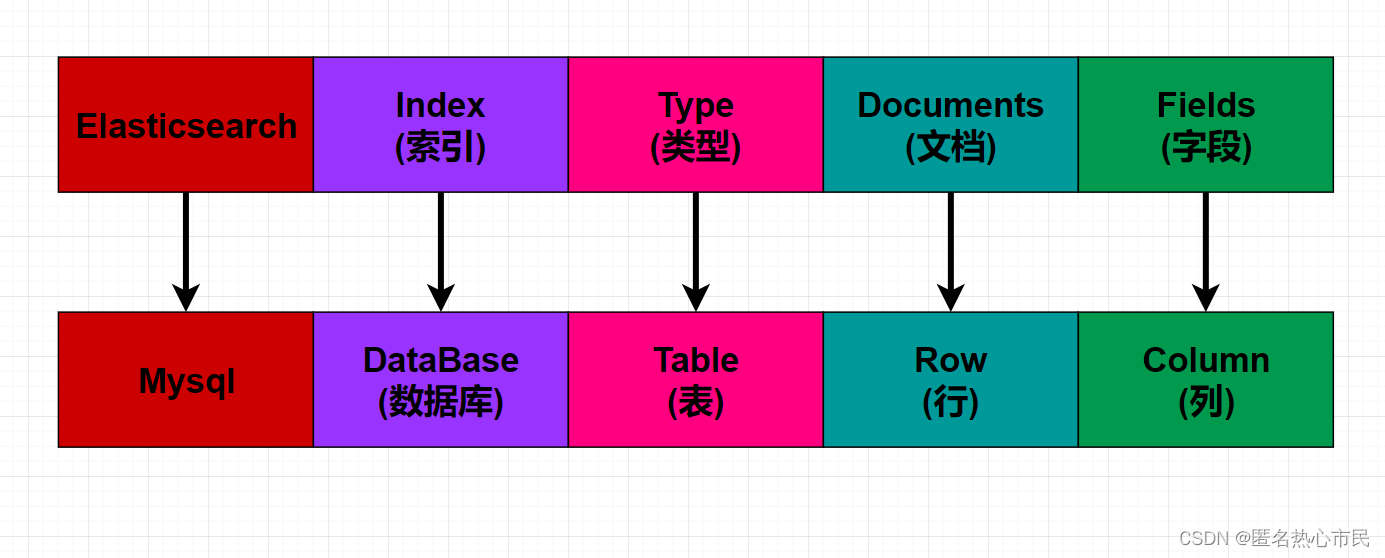
ES常用API接口

基本操作
创建索引
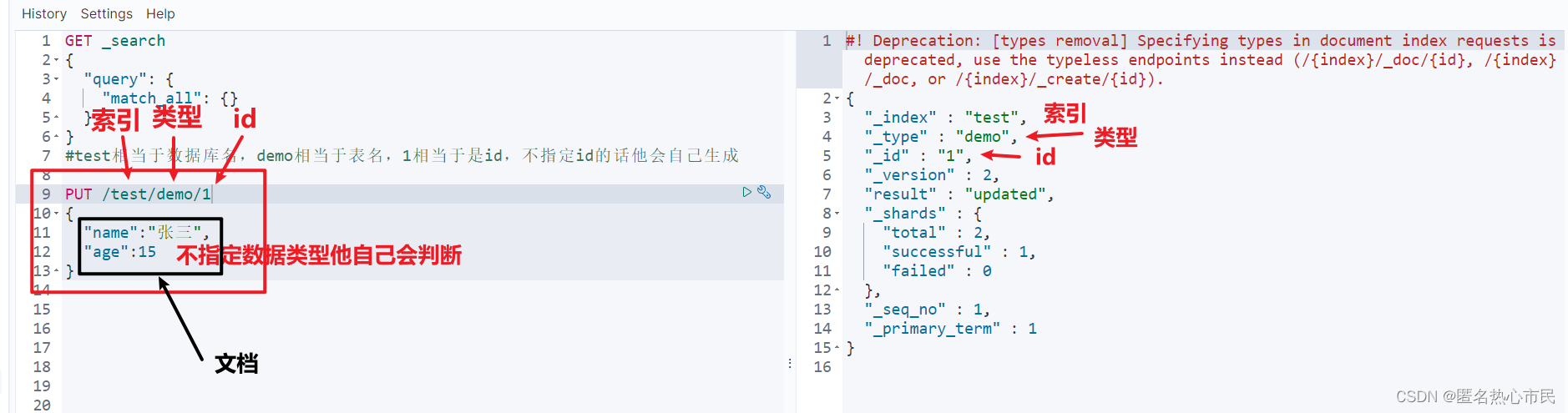
创建索引并往索引中添加一条文档
PUT /索引名称/类型名称/1
{
文档(数据)
}PUT /test/demo/1
{
"name":"张三",
"age":15
}
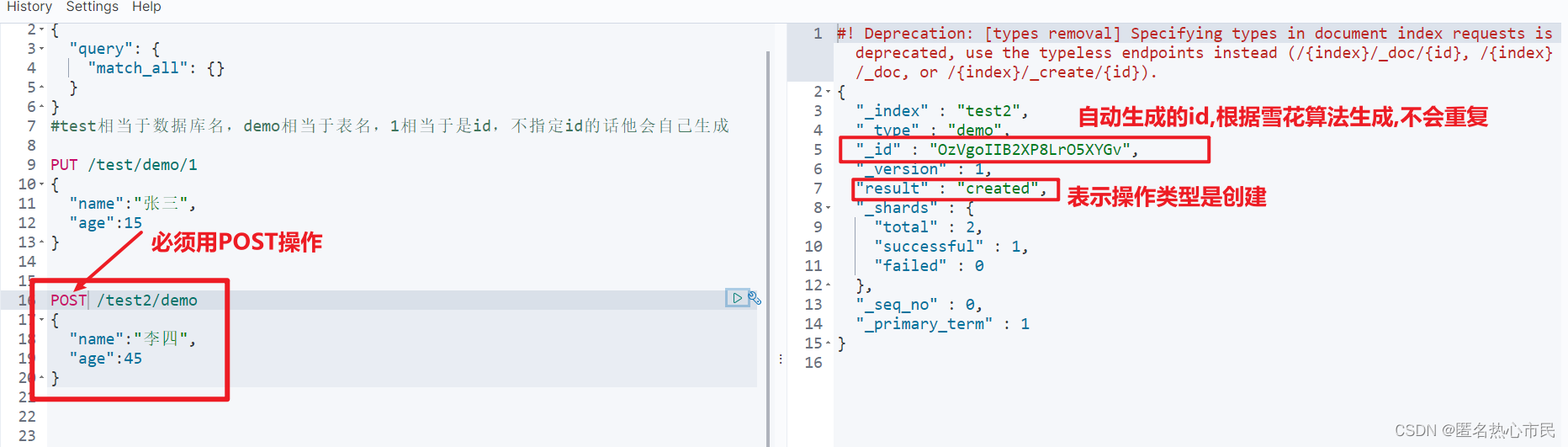
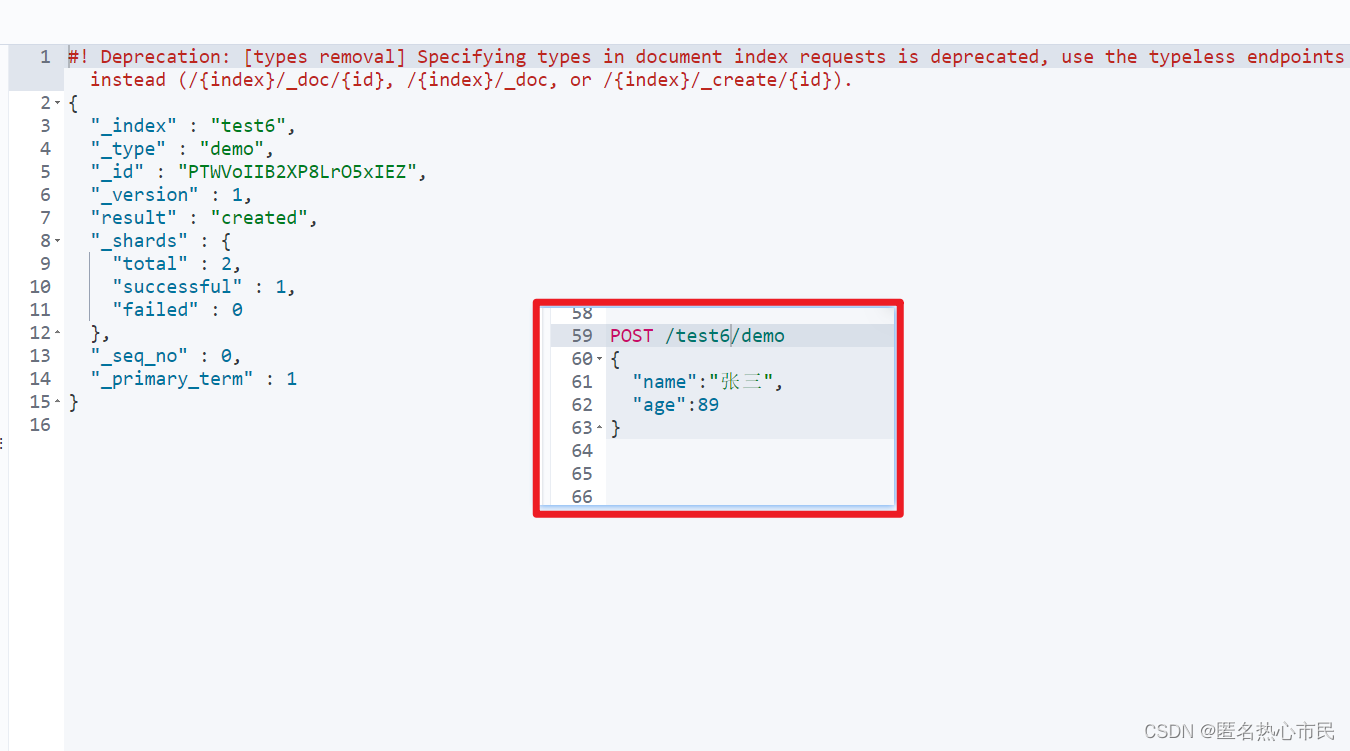
创建索引但不指定id
POST /test2/demo
{
"name":"李四",
"age":45
}
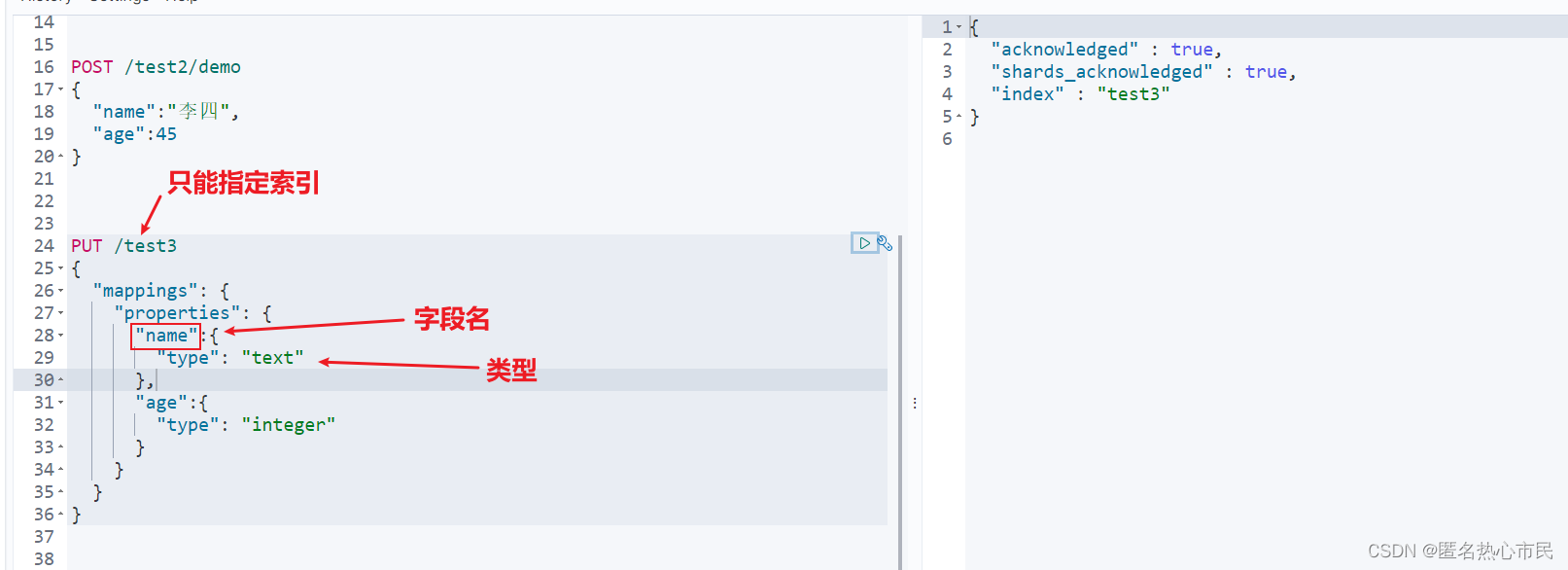
创建索引指定数据类型
PUT /test3
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
}
}
}
}
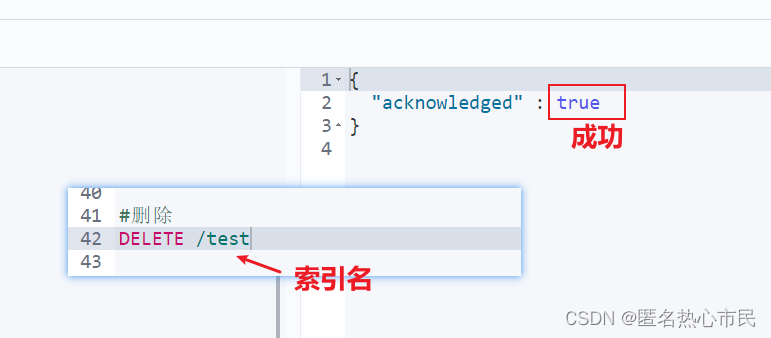
删除索引
相当于删除数据库
DELETE /索引名
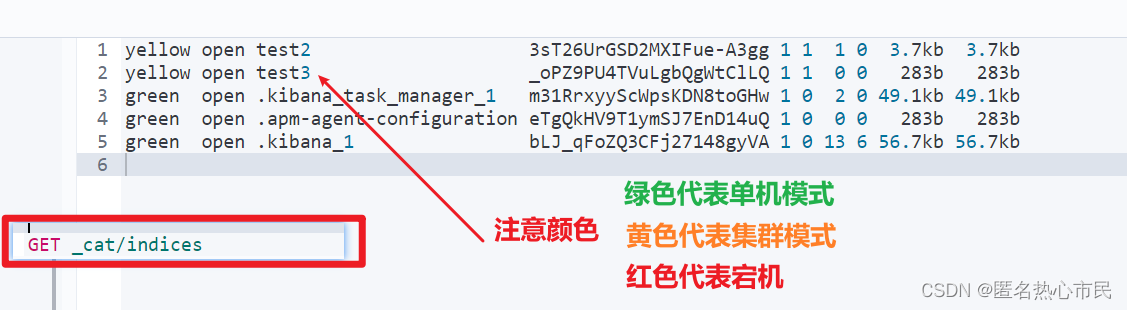
查询有哪些索引
查询用GET,部分get命令

相当查询所有表
GET _cat/indices
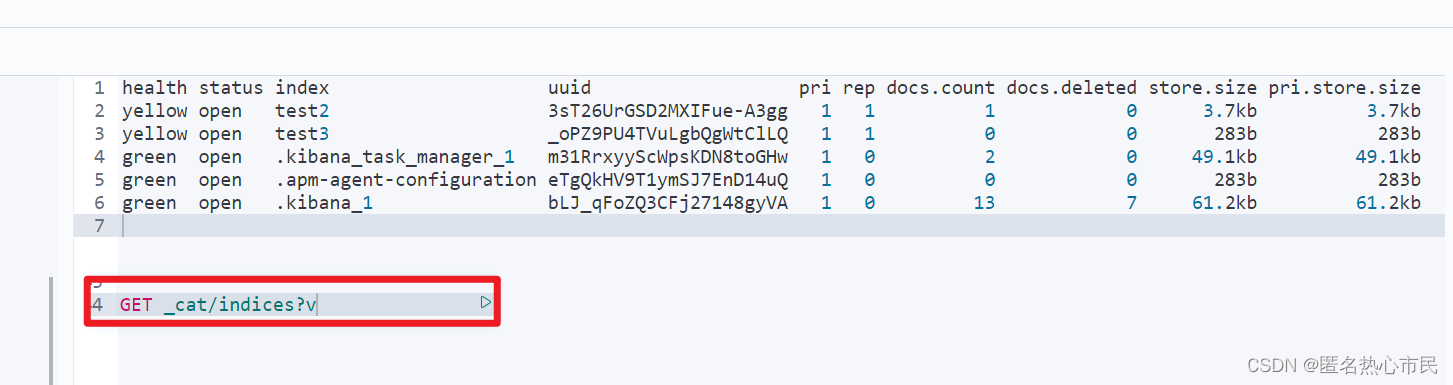
查询详细信息
GET _cat/indices?v
查询索引结构,相当于查看表节构
GET /索引名

文档
添加文档(记录)
使用put添加
使用put添加必须指定id值

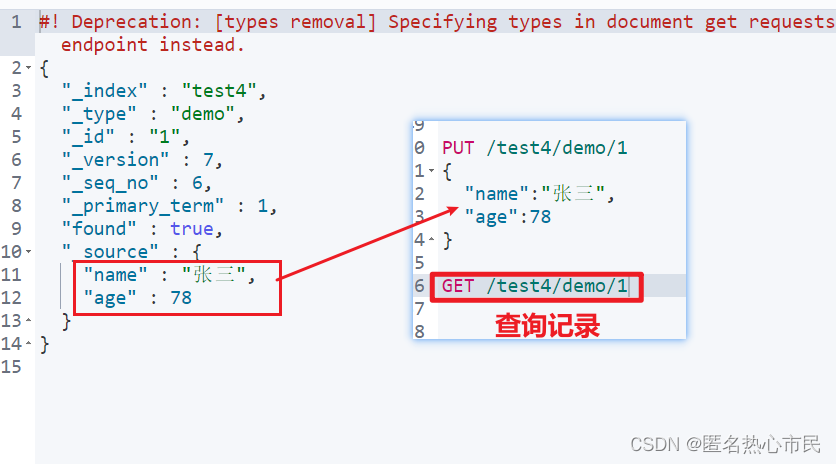
注意使用put添加记录可以说是覆盖,他会之前的记录
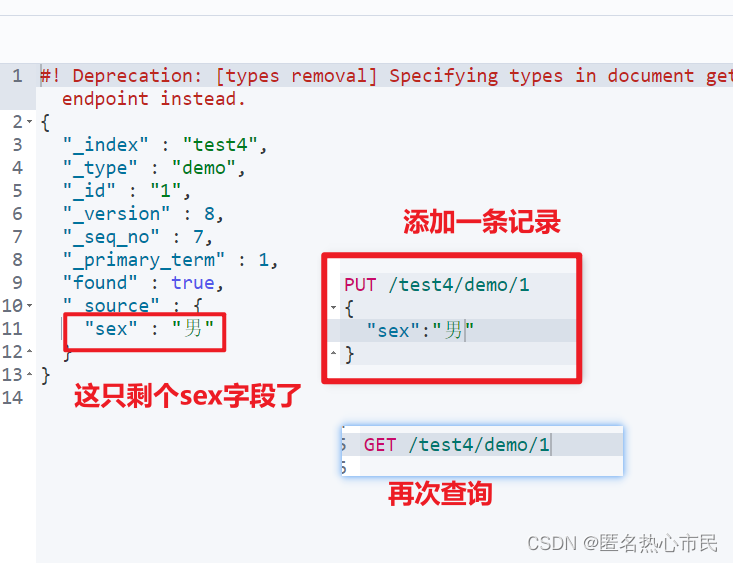
使用post添加
这就不用指定id值了
使用post添加字段的话需要指定id,但他和put基本一样,也是覆盖,上面的添加完毕生成了id,取到id进行操作。

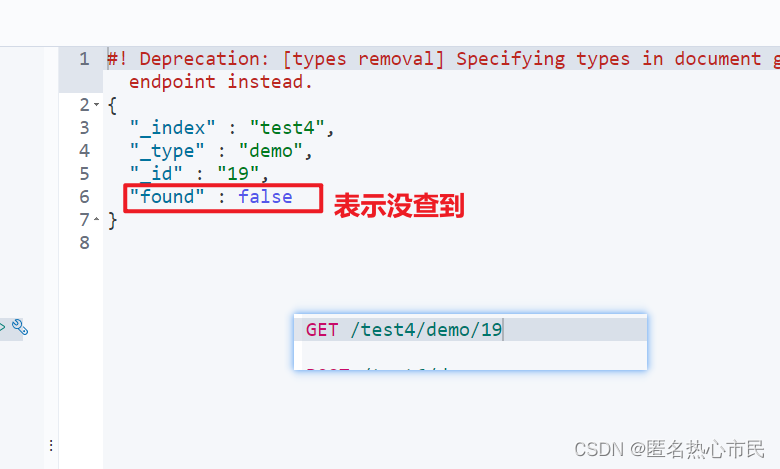
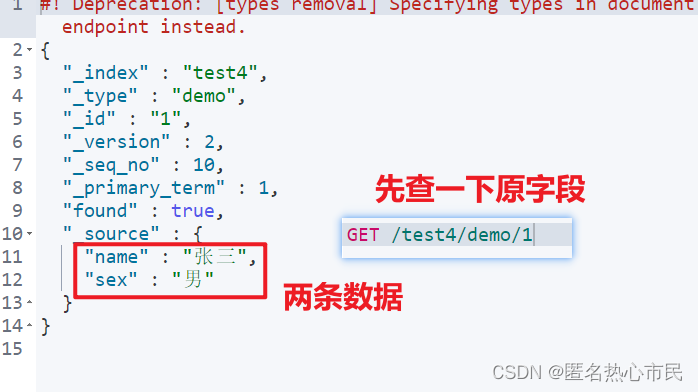
查询文档
查询指定索引
GET /索引/类型/id

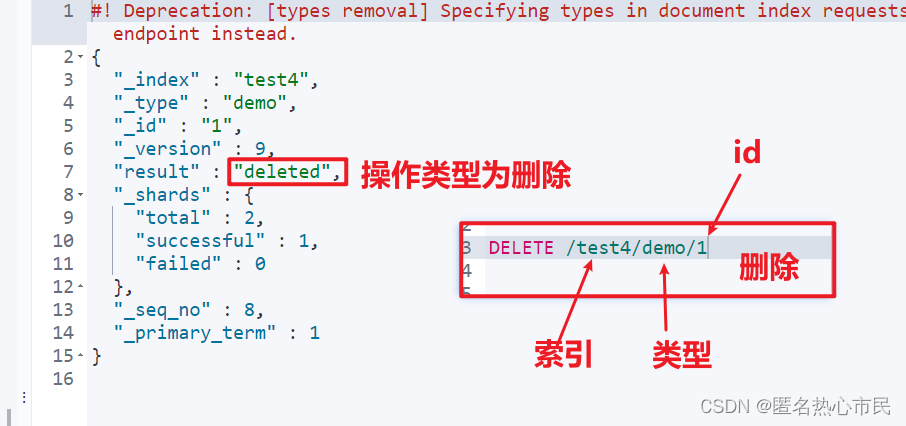
删除文档
相当于删除一条记录
DELETE /索引/类型/id
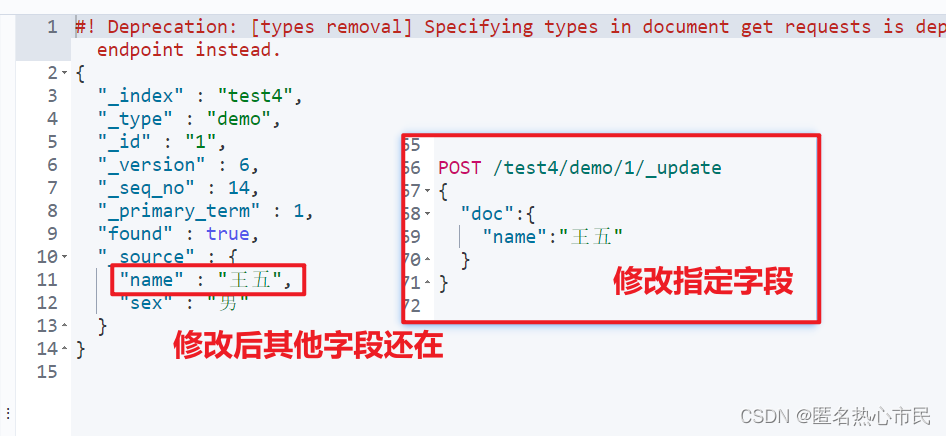
修改文档
修改和上面的添加一样,只是这里处理一下上面的修改就覆盖原来的字段的bug
POST /test4/demo/1/_update
{
"doc":{
"name":"王五"
}
}
按条件查询
查询所有文档
GET /索引/类型/_search

根据指定条件搜索
GET /索引/类型/_search?q=条件
可以模糊查询
GET /test4/demo/_search?q=王

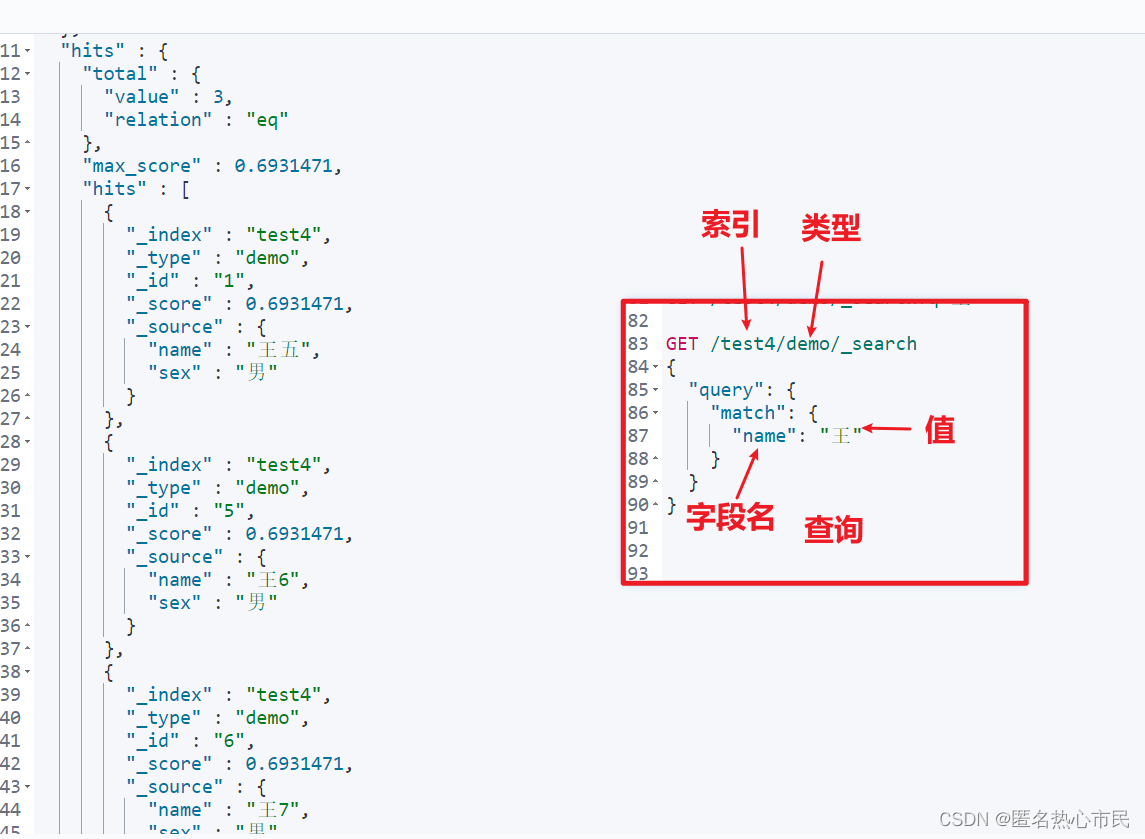
将查询的条件封装成json数据
指定列名和值查询
类型可省去,默认为_doc,
query后的值有:
match:匹配
range:范围匹配
term:精准匹配
GET /索引/类型/_search
{
"query": {
"match": {
"name": "王"
}
}
}
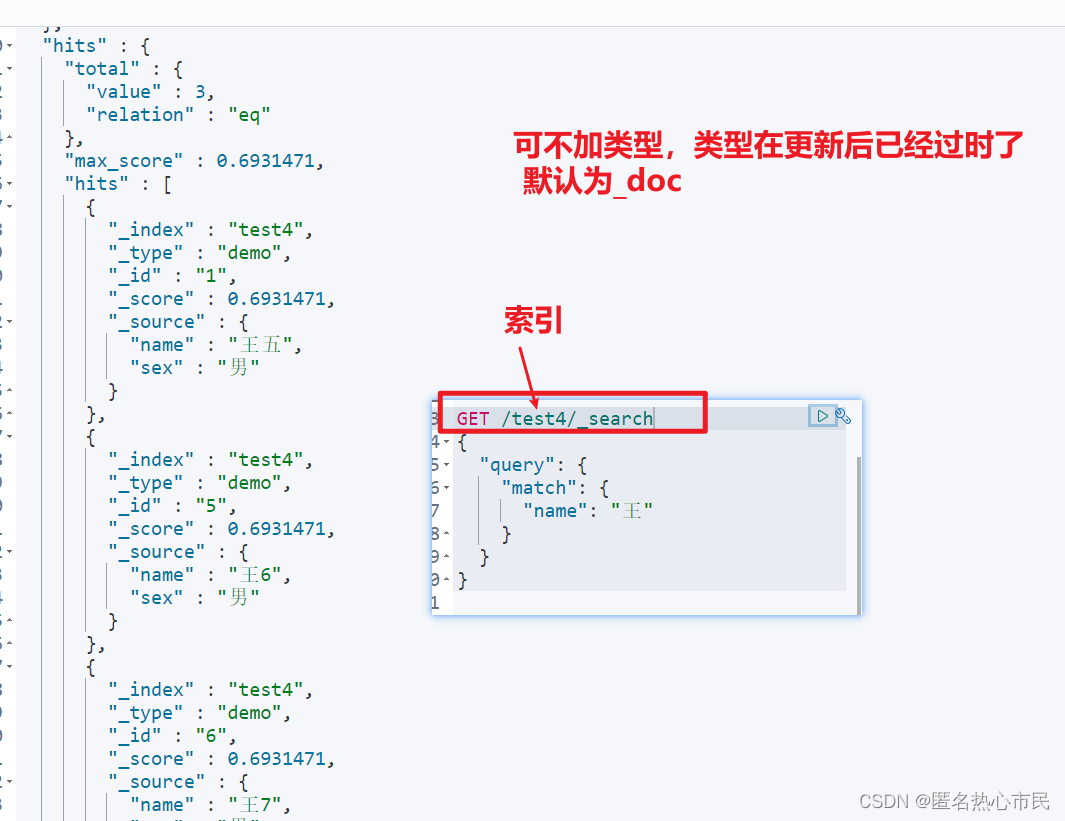
只查询部分列
GET /test4/_search
{
"query": {
"match": {
"name": "王"
}
},
"_source":["sex","name"]
}
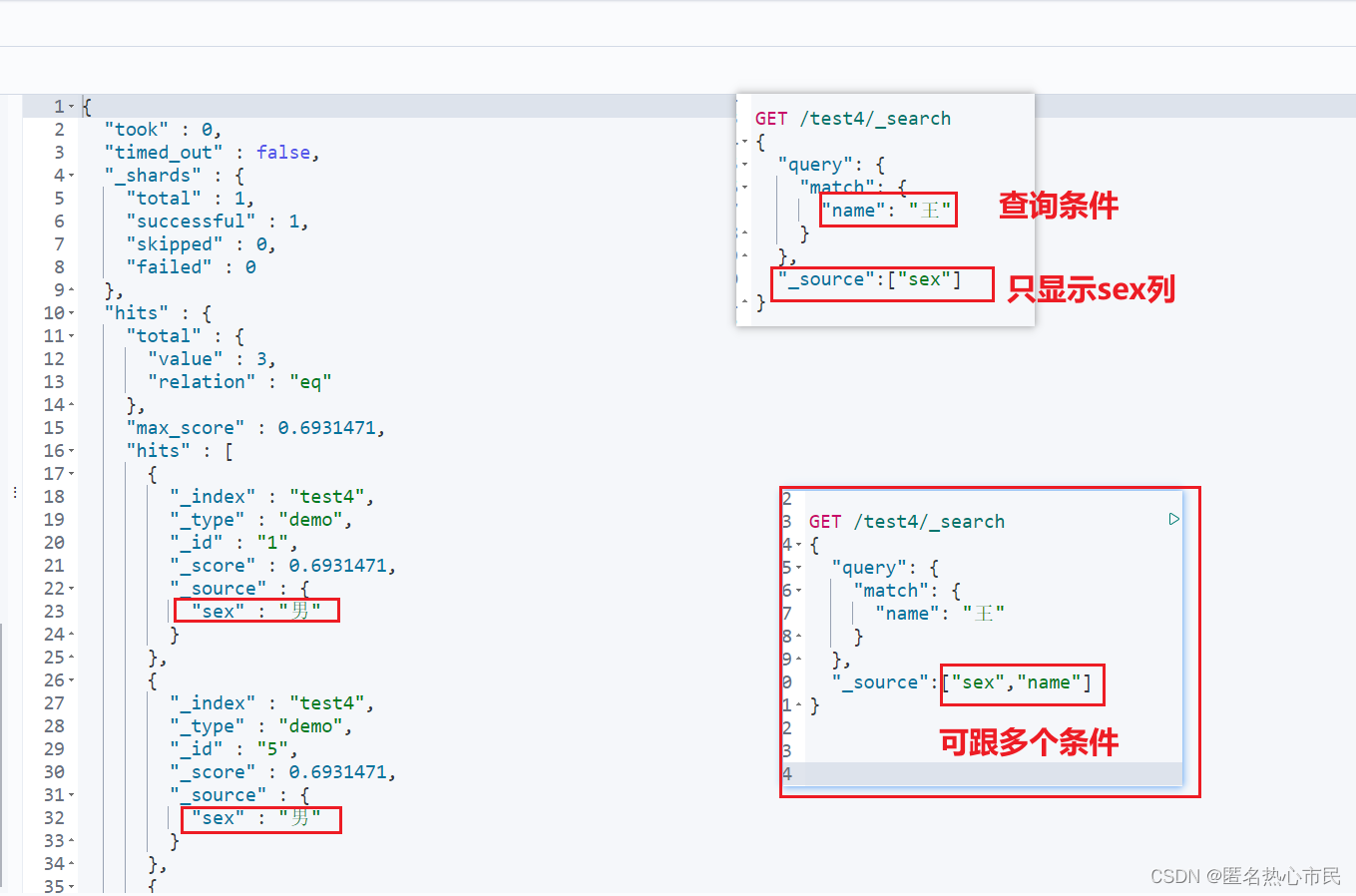
分页查询
GET /test4/_search
{
"query": {
"match": {
"name": "王"
}
},
"_source":["sex","name"],
"from": 0,
"size": 1
}

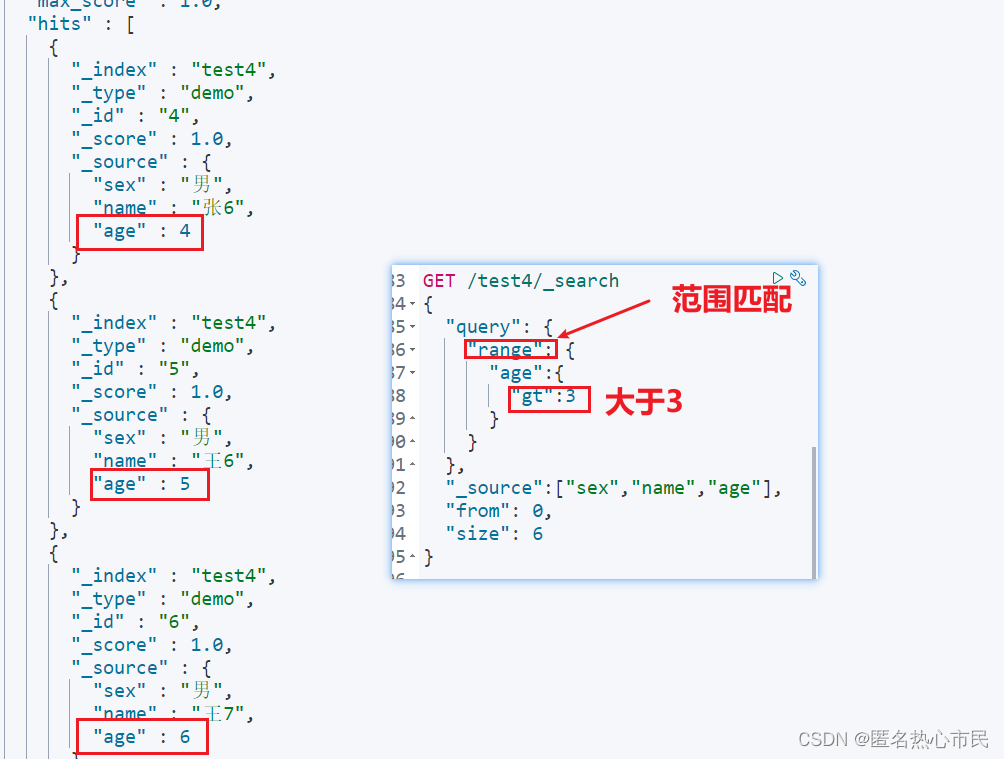
查询指定范围的
GET /test4/_search
{
"query": {
"range": {
"age":{
"gt":3
}
}
},
"_source":["sex","name","age"],
"from": 0,
"size": 6
}

查询并排序
GET /test4/_search
{
"query": {
"range": {
"age":{
"gt":3
}
}
},
"_source":["sex","name","age"],
"from": 0,
"size": 6,
"sort": [
{
"age": {
"order": "desc"
}
}
]
}

多条件查询
must:等同于sql中的and
should:等同于sql中的or
must_not:等同于sql中的!
and
GET /test4/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "王"
}
},
{
"match": {
"age": "5"
}
}
]
}
}
}

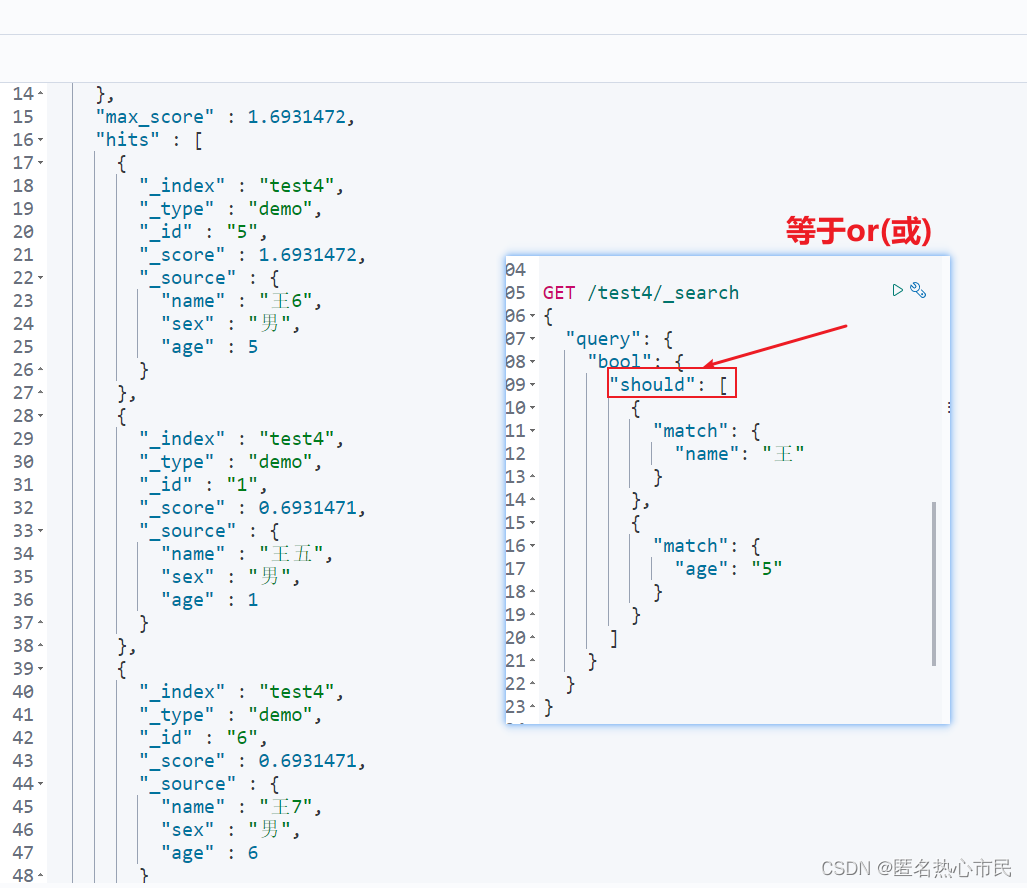
or
GET /test4/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "王"
}
},
{
"match": {
"age": "5"
}
}
]
}
}
}
取反
GET /test4/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "王"
}
}
]
}
}
}

高亮显示
GET /test4/_search
{
"query": {
"match": {
"name": "王"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
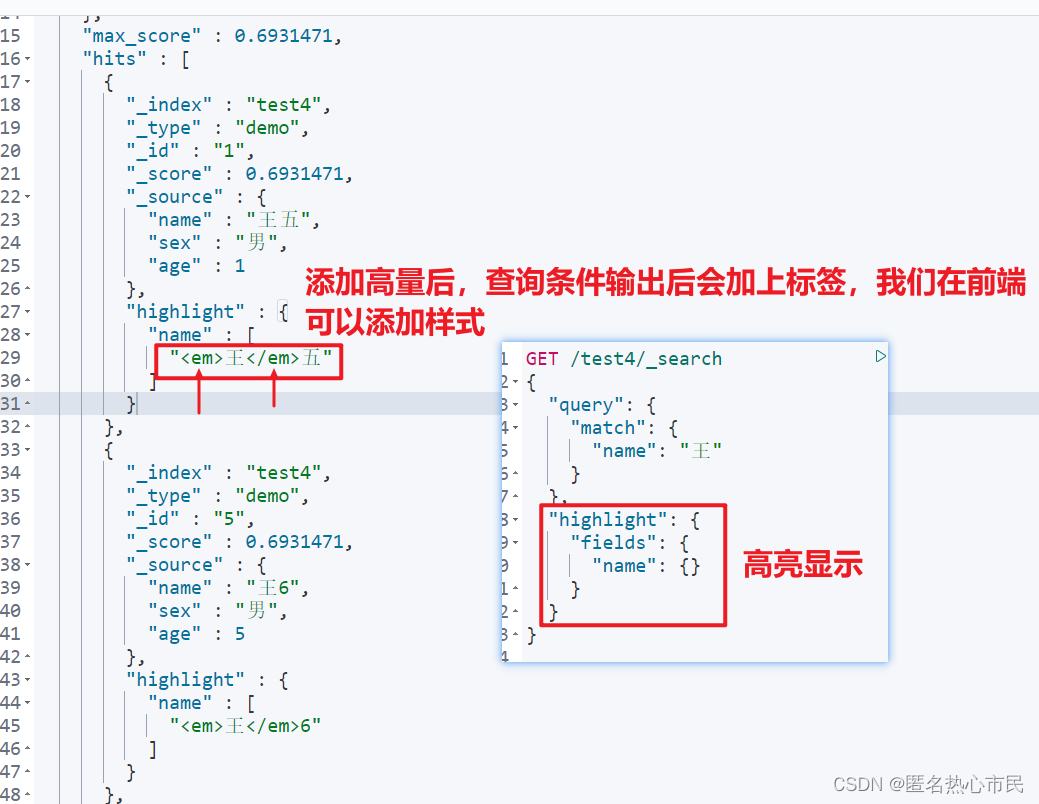
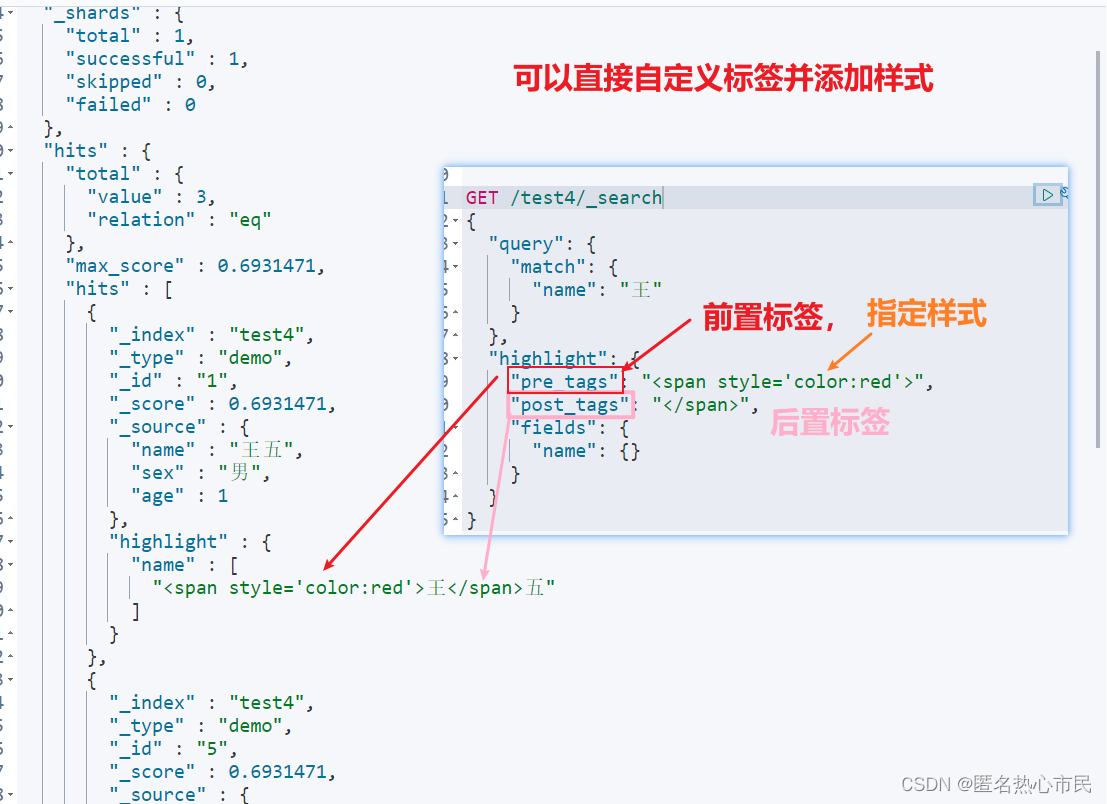
GET /test4/_search
{
"query": {
"match": {
"name": "王"
}
},
"highlight": {
"pre_tags": "<span style='color:red'>",
"post_tags": "</span>",
"fields": {
"name": {}
}
}
}
分词搜索
什么是分词搜索
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行—一个匹配操作,默认的中文分词是将每个字看成一个词(不使用用IK分词器的情况下),比如“"我爱闫克起"会被分为"我”,"爱","闫”,"克”,"起"这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
Test和keyword类型区别
text:它会为该字段的内容进行拆词操作,并放入倒排索引表中
keyword:它不会进行拆词操作
使用match匹配查询---对匹配的关键字进行拆词操作,并和倒排索引表中对应。
使用term精准匹配---它不会对关键字进行拆词操作,而且把关键字作为一个整体和倒排索引表进行匹配
测试


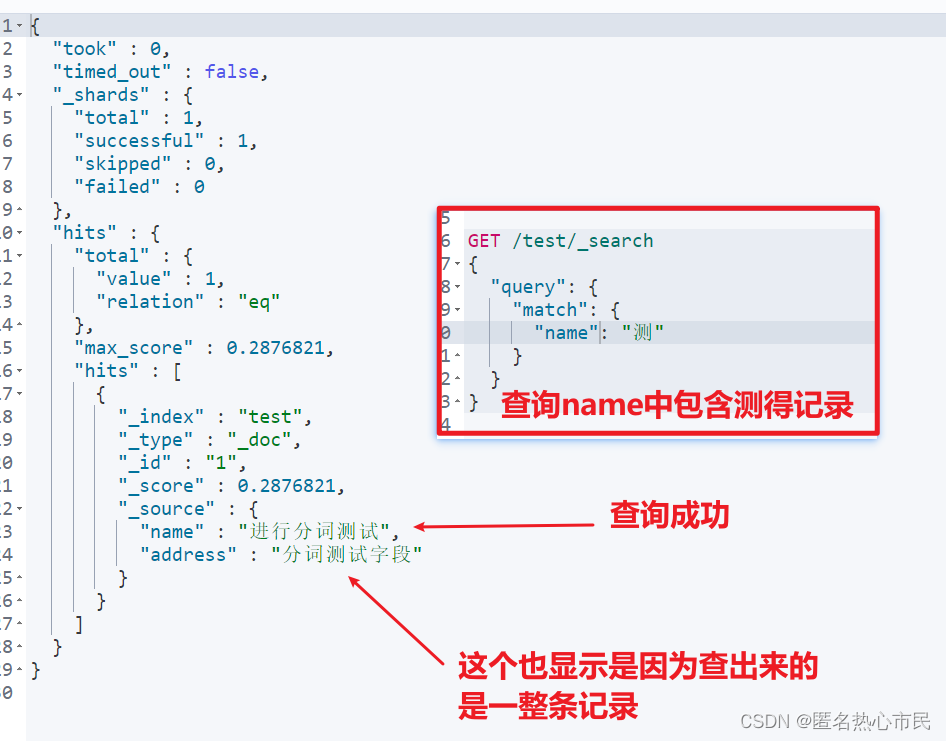
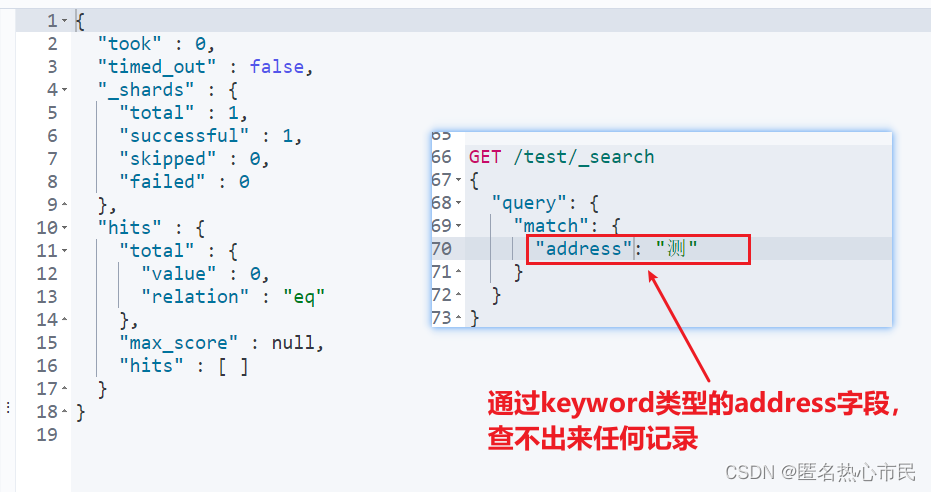
原理
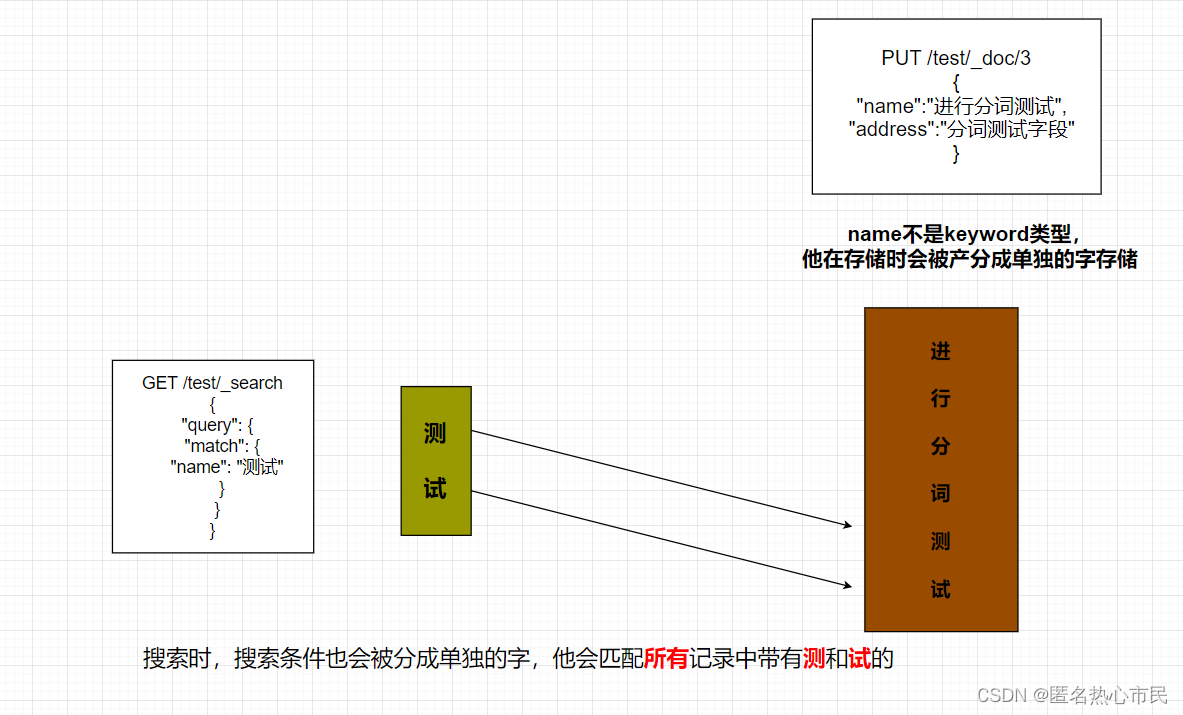
精准匹配
term直接通过倒排索引指定词条查询
适合查询number、date、keyword,不适合text使用match匹配查询会对匹配的关键字进行拆词操作,并和倒排索引表中对应。
使用term精准匹配,它不会对关键字进行拆词操作,而且把关键字作为一个整体和倒排索引表进行匹配
GET /test/_search
{
"query": {
"term": {
"name": "测"
}
}
}



















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









