







深度优先算法(DFS 算法)是什么?
寻找起始节点与目标节点之间路径的算法,常用于搜索逃出迷宫的路径。主要思想是,从入口开始,依次搜寻周围可能的节点坐标,但不会重复经过同一个节点,且不能通过障碍节点。如果走到某个节点发现无路可走,那么就会回退到上一个节点,重新选择其他路径。直到找到出口,或者退到起点再也无路可走,游戏结束。当然,深度优先算法,只要查找到一条行得通的路径,就会停止搜索;也就是说只要有路可走,深度优先算法就不会回退到上一步。
下图是使用 DFS 算法搜寻出来的一条路径:
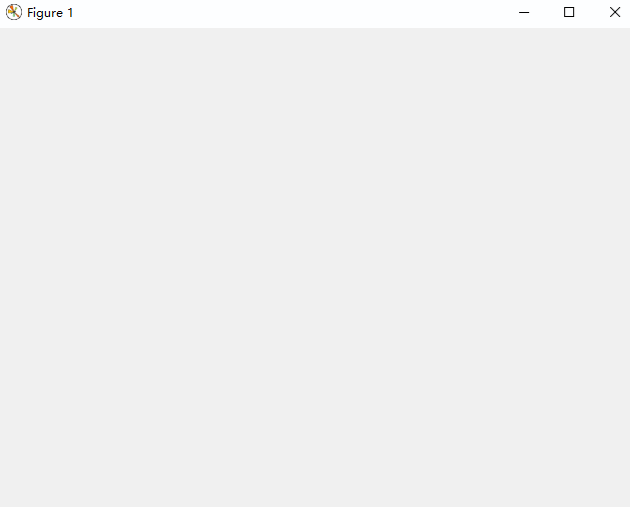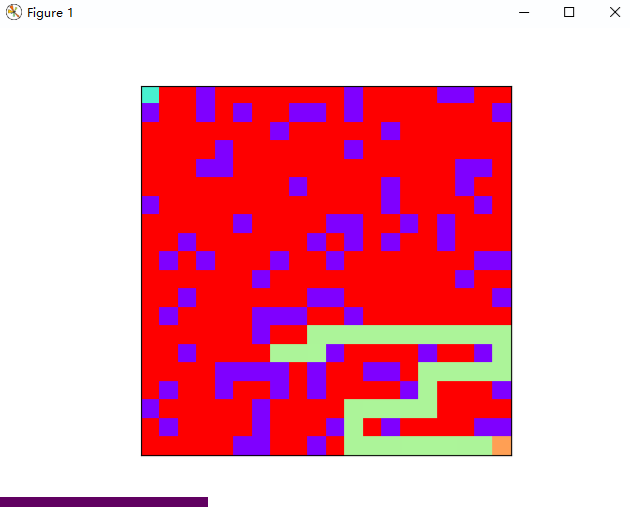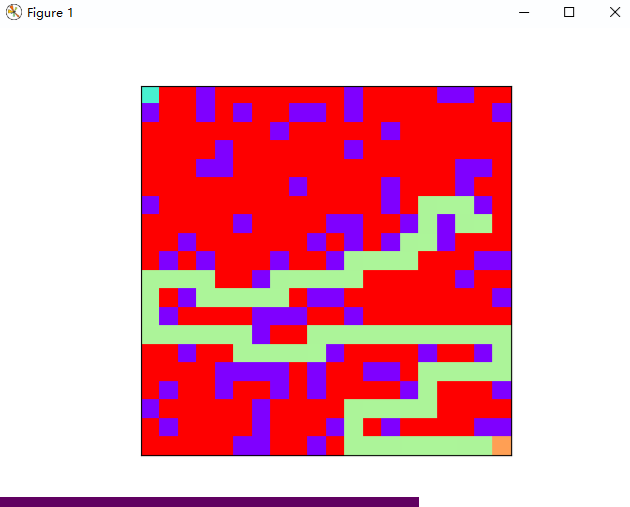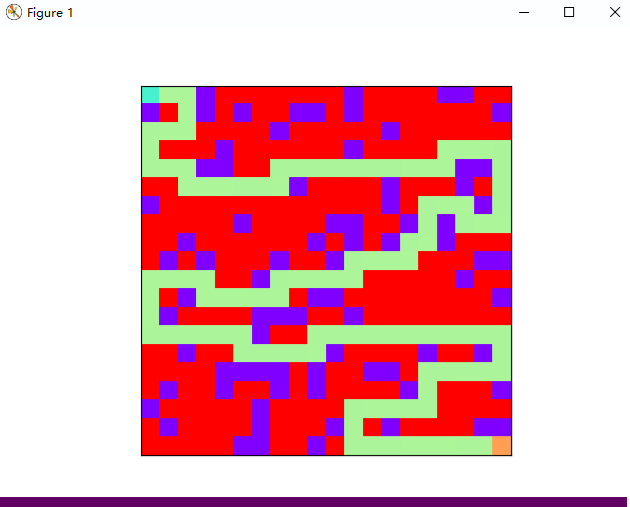
总结一下:
从起点开始,查询下一步走得通的节点,将这些可能的节点压入堆栈中,已经走过的节点不再尝试。查询完毕之后,从堆栈中取出一个节点,查询该节点周围是否存在走得通的节点。如果不存在可能的节点,就继续从堆栈中取一个节点。重复以上操作,直到当前节点为终点,或者堆栈中再无节点。
定义数据:
- 起始节点与目标节点
- 存储节点的堆栈
定义辅助函数
- 获取下一节点的函数: successor
- 判断是否为终点的函数: test_goal
首先,我们来定义栈这种数据结构,栈是一种后进先出的数据结构,之前公众号写过一篇介绍性文章:
https://mp.weixin.qq.com/s/adC4Y3YWCuvLmjSuj90Mrw
因为之后的广度优先搜索会使用到队列,A* 算法会用到优先队列,我们定义了抽象基类,以便后续使用。deque 是双端队列,与内置类型 list 操作类似,但头部与尾部插入和删除操作的时间复杂度均为 O(1)。
# utils.py
from abc import abstractmethod, ABC
from collections import deque
class Base(ABC):
def __init__(self):
self._container = deque()
@abstractmethod
def push(self, value):
"""push item"""
@abstractmethod
def pop(self):
"""pop item"""
def __len__(self):
return len(self._container)
def __repr__(self):
return f'{type(self).__name__}({list(self._container)})'
class Stack(Base):
def push(self, value):
self._container.append(value)
def pop(self):
return self._container.pop()
下面我们来定义 dfs 函数。其中,initial 为初始节点, s 为栈,marked 用来记录经过的节点。successor 函数用来搜寻下一个可能的节点,test_goal 函数用来判断该节点是否为目标节点。children 为可能的节点列表,遍历这些节点,将没有走过的节点压入栈中,并做记录。
# find_path.py
from utils import Stack
def dfs(initial, _next = successor, _test = test_goal) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9157
9157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









