




 本文探讨OCR中的一种文本检测方法,通过Differentiable Binarization(DB)解决传统分割方法中二值化阈值固定的问题。DB模型能自适应设置阈值,简化后处理并提高检测性能,尤其在处理曲形文本时表现优越。该方法在多个基准数据集上取得最佳性能,同时保持较快的推理速度。
本文探讨OCR中的一种文本检测方法,通过Differentiable Binarization(DB)解决传统分割方法中二值化阈值固定的问题。DB模型能自适应设置阈值,简化后处理并提高检测性能,尤其在处理曲形文本时表现优越。该方法在多个基准数据集上取得最佳性能,同时保持较快的推理速度。
目 录
摘 要
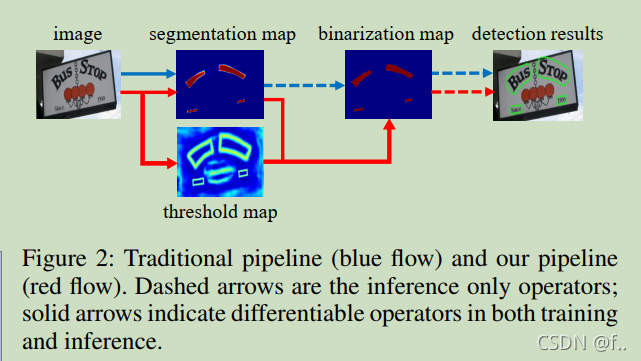
蓝线——传统意义上的文本检测 , 需对segmentation map 人为的设定一个阈值,转换为二值化图,即binarization map,然后,通过binarization map中的红色区域,慢慢扩张,找到文字区域,即detection results。 属于自底向上的过程,先找到像素点,再确定文字区域。
缺点在于 segmentation map中区域选择的阈值是人为固定的。
红线——与传统方法区别在于阈值选取方面,通过网络预测每一个位置处的阈值,而不是采用一个固定的值,可以很多的将背景和前景分离出来,但是这样的操作会遇到一个问题:给训练带来了梯度不可微的情况,因此,对于此二值化提出了Differentiable Binarization (DB)来解决不可谓的问题。
1、问题:
针对曲形文本检测任务,基于分割的算法比回归算法的表现更好,但是分割算法都需手工设置二值化的后处理算法,将分割生成的概率图转换成文本的包围框。
2、创新点:
提出Differentiable Binarization(DB),可以在分割网络中执行二值化的过程,可以自适应的设置二值化阈值,不仅可以简化后处理,并且提高了文本检测的性能。
一、背景介绍
1、传统分割方法的缺点
需要复杂的后处理,导致推理阶段耗时较长(Ps : PSE-Net 、Pixel Embedding)
2、后处理Pipline
a.通过设定一个固定阈值将概率图转化为二值化图像;
b. 利用启发式算法(像素聚类)将像素聚合成文本实例;
本文解决办法:
期望将二值化操作融入到分割网络中进行联合优化,进而形成一个自适应学习二值化阈值的过程。
3、主要贡献
a. 在5个基准数据集上获得最好的性能,包括水平、多方向和弯曲文本;
b. 在速度上,比以前的文本检测方法都要快;(微分二值化方法的运用,极大的简化了后处理过程);
c. 利用轻量级的骨架也可以取得很好的效果;(如:ResNet-18)
d. DB部分可以在推理阶段移除,但不影响网络性能。(因为网络已经训练好)
二、相关工作
1、基于回归的方法
TextBoxes、TextBoxes++、DMPNet、SSTD、RRD、、DeepReg、SegLink、DeRPN,以上后处理算法(回归框)比较简单,但是它们不适用于不规则文本和弯曲文本。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









