







 本文介绍了Intel的DAOS,一个开源的高性能全闪存分布式存储系统,着重讨论了其架构、技术选型(如PMDK、SPDK、RDMA、UTL)、接口设计、生态和实现原理,以及VOS的日志存储设计对事务一致性的支持。
本文介绍了Intel的DAOS,一个开源的高性能全闪存分布式存储系统,着重讨论了其架构、技术选型(如PMDK、SPDK、RDMA、UTL)、接口设计、生态和实现原理,以及VOS的日志存储设计对事务一致性的支持。
随着闪存的价格不断下降,新型的应用(AI,HPC,高性能的分析等)对性能的不断需求。目前全闪存的分布式存储系统是一个大的趋势。Intel 的DAOS是目前能看到的唯一的开源的高性能的采用全部闪存的存储系统。所以研究它的架构和实现对我们有极大的借鉴意义。
自从2018年intel把自己维护的高性能Lustre文件系统卖给DDN后,intel就着力开发了DAOS,也就是被称为下一代Lustre高性能文件系统。主要用于HPC和AI等高性能场景中。
DAOS是完全从头设计,完全在用户态开发的文件系统。主要针对大规模分布式非易失性内存介质。这里的介质主要是 SCM和 NVME SSD存储介质。用 Persistent Memory Development Kit (PMDK)来把SCM通过memory map files直接访问。通过Storage Performance Development Kit (SPDK)库直接访问NVM-Express SSD盘。提供非阻塞IO事务,数据保护和自我修复,基于commodity 硬件,End-to-End数据一致性。
在对外接口上,通过libdaos实现了两类接口:Native key-value 和 Native array接口。可以理解为:DAOS同时实现了一个分布式的KV存储系统和一个分布式的类似Ceph RADOS的对象存储系统。基于libdaos库可以实现各种应用层的接口:POSIX filesystem,HDF5,HDFS Connector等接口。
DAOS主要采用了目前流行的一些技术:
- By OS kernel:直接使用PMDK,SPDK等用户态库绕过操作系统直接访问SCM和NVME SSD等高性能设备。
- RDMA:实现用户空间数据端到端的数据拷贝。
- UTL(user level thread)用户态线程或者协程的概念。
通过上述技术,DAOS可以是完全实现在用户态的高性能分布式存储系统。

DAOS提供数据接口
- Native key-value:一种是比较熟悉的Key/Value模型,提供kv存储接口。例如put,get,remove,list操作。
- Native Array:一种提供Array Object,也就是一般理解的对象存储。比如Ceph中RADOS的对象存储一个对象默认4M,就可以把这个4M的对象看成是一个Array Object:可以修改对象的任意字节,也就是支持随机读写,punch,删除操作。
DAOS 生态系统
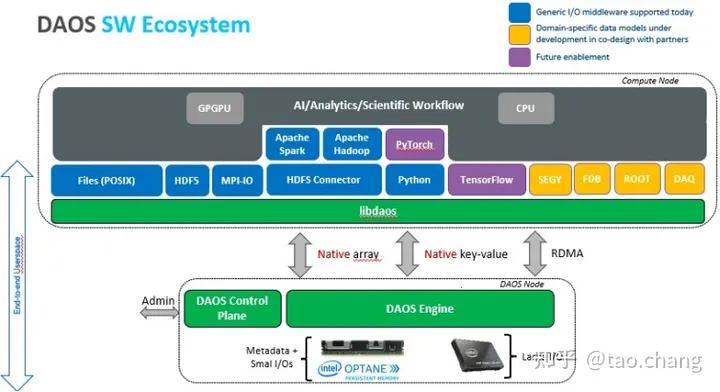
DAOS 的生态
DAOS的生态系统可以看到,DAOS的设计目标不是提供一个单一应用的存储系统。DAOS提供了两个基本的接口:Native Array和Native key-value接口。基于这两个接口,提供了众多的应用接口:
- Posix File System
- 科学计算的HDF5格式
- 高性能计算MPI_IO接口
- 大数据 HDFS接口
- AI:Pytorch,TensoFlow
- 其它Domain-Specific Data Model
DAOS的架构介绍
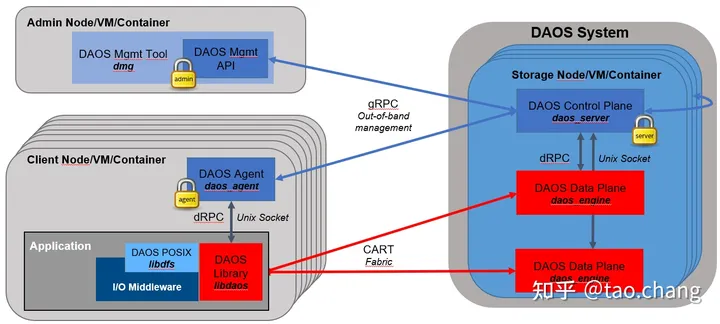
架构图
整个DAOS系统从物理部署的角度分为:
- 管理节点:Admin Node,用于部署管理工具dmg,通过DAOS Mgmnt API访问。
- 客户端节点:Client Node
- 存储节点:Storage Node
这三类节点都可以部署在物理节点,虚拟机或者容器中(node/vm/container)。
DAOS系统从逻辑视图可以划分为:
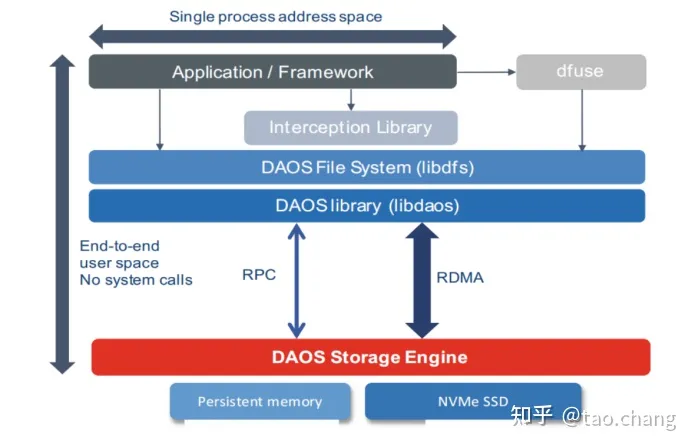
- Control Plane:Control Plane是系统的控制面或者管理面,用golang语言开发。客户端和服务端之间用基于tcp/ip的gRPC通信。和对应本机上Data Plane组件通过基于Unix Socker的dRPC通信。
- Data Plane为数据平面:图示中红色的部分。用C语言开发。主要实现了IO的数据通道。通过高性能的RDMA实现数据通信。
daos_server是一个damon进程,部署在数据节点的control plane,用过管理数据节点挂载的SCM和NVME SSD存储设备。
daos_agent是一个部署在客户端节点上的control plane侧独立的进程,主要的两个作用:daos client library通过daos agent完成鉴权和权限管理;daos agent通过gRPC访问daos server获取集群和pool的状态信息。
daos_engine是一个daemon进程,部署在存储节点的Data Plane侧提供数据服务器,一个Target对应一个daemon进程。
daos Library(libdaos)是部署再client node上的data plane,为数据的读写的客户端。
通信网络
- gRPC通过tcp/ip实现了网络通信,主要用于管理面客户端和服务端之间的通信。
- dRPC基于Unix Domain Socket用于本地进程之间的通信:主要是本机control plane和data plane组件通信。
- CART:用户态实现的网络通信库用于为Data Plane(数据面)提供低延迟高带宽的网络通信,支持RDMA capabilities 和 scalable collective operations操作。
基本概念介绍
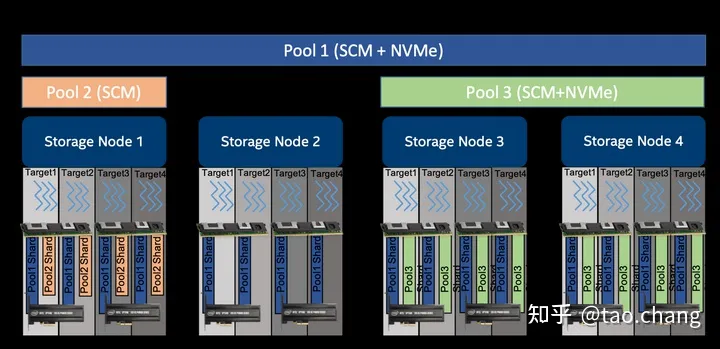
DAOS System:是一组物理节点,通过一个System Name标识,由一组Storage Node组成,一个Storage Node只能属于一个DAOS System。一个DAOS pool不能跨多个Daos System
DAOS pool:逻辑存储空间,包含若干pool shards (可以理解为ceph pool概念)
- 一个pool里包含若干个pool shard
- 每个pool shard 分布在一个target上。一个target上可以承载多个pool shard。pool shard是target上的子空间。
DAOS Target:可以理解为物理存储设备(可以理解为ceph OSD)
- single-ported SCM module
- NVMe SSD attached to a single storage node
一个single-ported SCM或者 NVMe SSD 对应一个Target。 类似于ceph中的一个磁盘对应一个OSD的概念。
DAOS Container:每个container是一个独立的对象地址空间,类似于S3的buckets概念。Container被UUID标c识,这个概念对用户是可见的。在使用时需要用户自己创建。
Container级别实现快照和事务的功能。
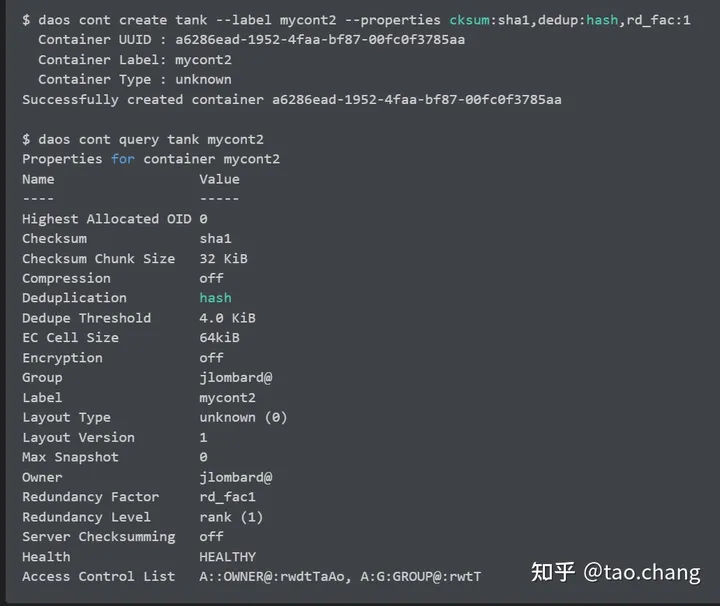
container的相关的属性信息
DAOS Object: DAOS objects belonging
Object schema: 定义了对象的数据分布和冗余信息:例如动态或者静态strip,副本或者EC等参数。在一个Container中的对象可能拥有不同的 object schema。
Object class 定义了一组对象集合,它们有相同的object schema。每个object class 有一个ID,并在pool层级上关联特定的 schema。 Object class 可以理解为对应ceph 的pg组。

管理数据和集群服务
DAOS相关的管理数据例如pool, container,management service等集群相关的数据保存在基于Raft协议实现的key-value 的高可用的存储系统。类似于Ceph的monitor的功能。
DAOS的 RSVC(replicated service)实现了一个基于Raft协议的服务框架,和具体的RDB(replicated database)组合来实现高可用,持久化保存相应的管理数据。
数据分布 Placement
DAOS的数据分布算法基于Jump consistent hash来实现分布式系统的数据分布。
实现了object到副本所在的 targets的映射关系的计算。
object identifier -> list of targets和Ceph的数据分布相比,ceph的数据分布是分三步的:
object ----(hash)-----> PG
PG------(cursh)----> list of osds这里DAOS是直接管理对象。对象直接映射到 targets,相当于直接管理数百万个object的副本位置,这种设计似乎不太灵活。
副本一致性 DAOS Two Phase Commit(DTX)
DAOS支持副本和EC两种数据高可用模式。通过改进的两阶段提交算法DTX(DAOS Two Phase Commit)实现副本一致性。
Epoch & Timestamp Ordering
每个DAOS IO操作都会带一个timestamp,该timestamp也被成为epoch, 一个epoch是一个64-bit的integer,该64位的整数包括了logical和physial clocks(参考 HLC paper). DAOS内部提供了epoch和traditional POSIX time的转换。
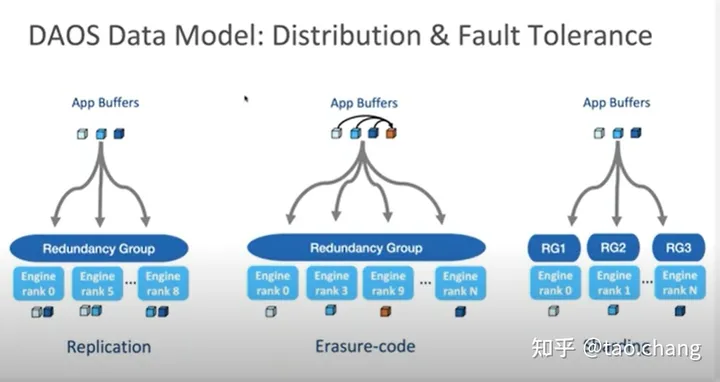
DAOS Data Model
DAOS API 支持分布式事务,允许对属于同一容器的对象的任何更新操作合并到单个 ACID 事务中。 通过基于多版本时间戳排序的无锁乐观并发控制机制提供分布式一致性。
DAOS 可以基于版本控制机制创建持久的 Container 快照,该快照提供 Container 的实时分布一致性视图。
写操作流程
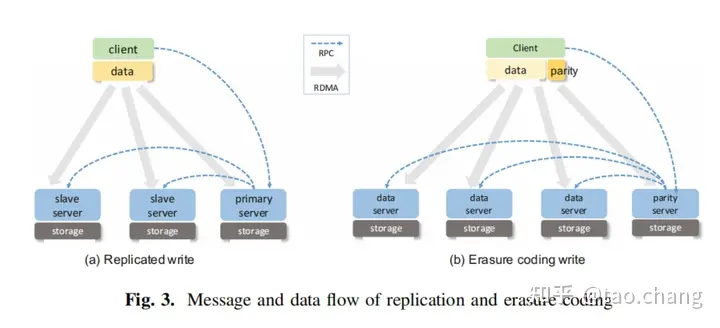
图:读写流程
写操作由客户端发起:
- 客户端发送给DTX Leader节点
- Leader节点通知所有副本做本地事务的修改,本地事务DTX的变为状态为prepared状态
- Leader收到所有本地事务修改成功后(包括自己成功修改本地事务),把DTX的状态变为committable状态,并返回给客户端。Leader在后台异步的提交事务,使事务处于提交的状态:可以是定时提交,或者达到一定的事务量后批量提交,或者后续的RPC请求中顺便提交。
- 如果有repla在prepared阶段失败,Leader向剩余存活的节点发送 abort DTX的操作。
- 客户端如果收到 abrot DTX操作,说明事务提交失败,会选择新的一组节点重新提交。
如图读写流程所示:虚线是控制流,灰色箭头是数据流。对于DAOS的写操作特别要强调的是:控制流和数据流分离的模式:客户端发送写操作的rpc控制请求给primary server,primary server发送控制请求rpc请求给slave。在数据流方面:slave server 和 master server同时请求RDMA,直接从client的buffer中读取数据到storage server上,然后返回。
读操作流程
当需要读取数据时,客户端可以向任意数据副本发送请求。在server端,检索正在提交的事务(active DTX records),如果有对应读取对象相关的分布式事务DTX都已经提交或者处于可提交状态,就可以读取数据。如果对应的DTX的状态为prepared状态,就需要通知客户端,重新发起请求给Leader来获取最新的数据。
DTX Leader Election
在DTX模型中,leader副本做了如下的工作:
- 所有的修改操作都发送给leader,leader做必要的sanity check
- 读操作, 如果DTX处于prepared状态,需要把请求转发给Leader
Leader的选举是基于每个Object或DKey的粒度的。也就是每个对象都需要自己通过选举流程选出自己的Leader。具体的选择算法比较简单。
故障检测和数据修复
故障检测
- 通过SWIM协议来完成节点的故障检测。
- 故障节点会自动踢出集群
数据修复
- 数据修复以对象为基本单位
- 存活节点会被通知到有失效节点,自行全量扫描回复。

故障节点恢复
- 数据依然迁移回原来的节点
- 所有的对象需要扫描检测版本确认一致性
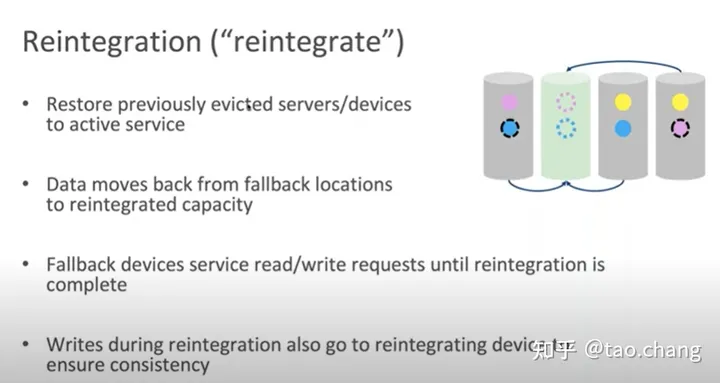
故障节点恢复
集群扩容
自动完成数据均衡
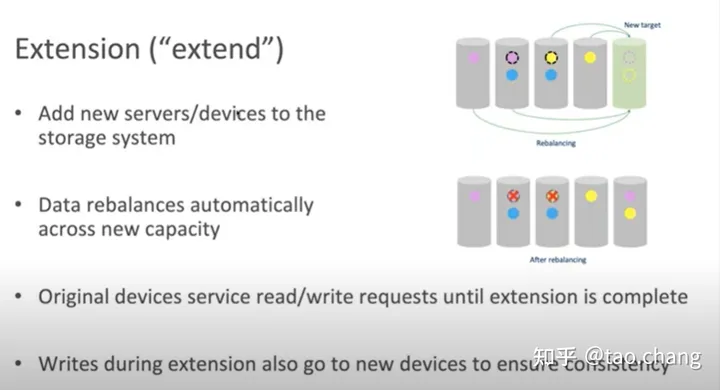
集群扩容
本地存储VOS
VOS(versioning Object Store)
VOS(version object stroage)是带多版本的本地对象存储系统。类似于Ceph的Bluestore的角色。
- 元数据存储在SCM上,使用 per-server的pmemobj pool存储。
- 数据小IO存储在SCM中,大块IO存储在NVMe-SSD上。 SCM存储空间使用PMKD的 pmemobj pool分配。NVMe磁盘使用SPDK Blob库分配。
小块IO在SCM,大块IO直接落盘NVMe SSD上。同时支持后台小块IO的合并成大块IO并迁移到NVMe SSD上。
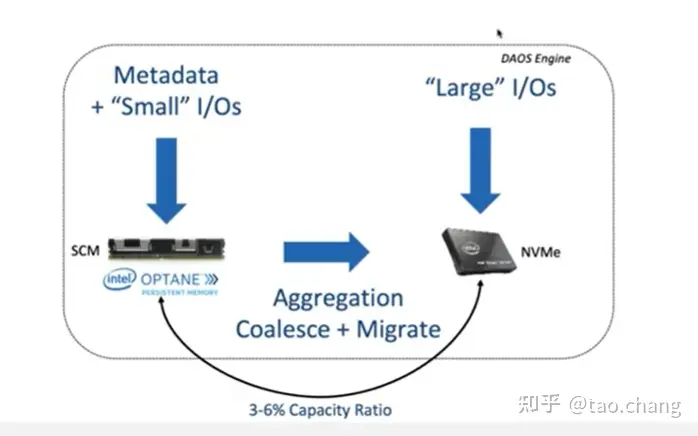
Small IO 合并迁移
VOS最大的设计亮点是:基于日志型的多版本机制。所有的写操作都带有epoch,并且都是追加写操作,不会覆盖原有的数据。基于多版本机制可以方便实现事务机制,snpashot,数据恢复等。
VOS内部保存了三个index:
- object index: object ID + epoch ---> object metadata
- active DTX records:正在提交的事务记录
- commited DTX records:已经提交的事务记录
KV Store
VOS 提供了一个基于SCM的multi-version,concurrent Key-Value Store。KV支持高性能的insert,update,delete和scan操作。updat和delete操作都是添加一条新的记录。
两种Key:Hashed Keys和 Direct Keys。Hashed Keys基于Hash值产生的Key,优点是快速查找,分布均匀,缺点是不支持SCAN操作。Direct Keys支持SCAN操作。 Direct Keys有两种:一种是Lexical Keys:基于 lexical ordering,其长度最大支持80字节。另一种是Integer Keys,用一个unsigned 64-bit integers做为key。
在对比了红黑树和B+树的优缺点后,VOS使用了B+树做为存储结构。
Key Array Stores
VOS实现了数据多版本的读写:所有的写操作都是追加写到新的地址空间中,并更新VOS中object的metadata index值。VOS的对象元数据保存了多版本的信息,通过R-Tree实现空间查找。
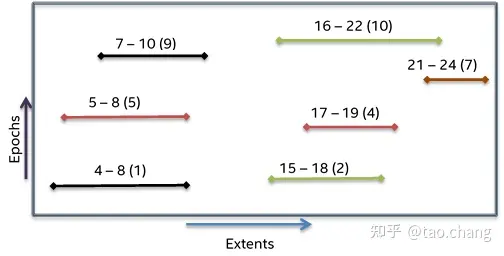
R-Tree介绍
R-Trees provide a reasonable way to represent both extent and epoch validity ranges in such a way as to limit the search space required to handle a read request. VOS provides a specialized R-Tree, called an Extent-Validity tree (EV-Tree) to store and query versioned array indices.
Blob I/O(BIO)
BIO用于NVME SSD磁盘空间管理和分配。
DAOS的control plane处理SSD的配置管理。DAOS data plane通过SPDK处理数据块的分配,使用的算法为VEA(Versioned Extent Allocator)数据分配算法。
Background Aggregation操作:用于数据从SCM合并小的数据块到NVME SSD上大的数据块。
应用层介绍
DAOS POSIX Support
总结和评论
DAOS由于从头设计,采用了一些关键的技术:by pass kernel技术如:PMDK,SPKD技术,User Thread等,主要的设计亮点如下:
VOS的设计比较有参考价值:采用了基于Log的对象存储系统设计,所有的更新操作都以追加的形式写到新的空间,丢弃了传统的in-place update的设计模式。采用这种设计:
- 优点比较明显:无论是顺序写还是随机写操作都比较友好。后续可以较容易的支持snapshot操作。
- 特别是可以支持本地事务的提交和回滚:支持redo和undo两种操作,支持分布式事务的提交。
- 缺点:读操作需要处理多版本和可能的大量的元数据操作;顺序读操作可能大量分散成大量随机读IO。这对于SCM和NMVE SSD似乎问题不大。
对于DAOS的设计目标,元数据保存在SCM中,性能和空间可能都不是问题。顺序读操作或许可以通过scatter-gather模型在SCM上可以缓解。数据从SCM上通过merge合并到大块的 NVMe SSD上也可以部分缓解。
有了VOS的日志型的多版本设计,副本一致性就通过了传统的two-phrase来实现相对就比较简单。
总的来说,DAOS从架构设计的角度,还是比较合理的。笔者比较看好DAOS的未来发展,继续持续关注学习中。
参考
《DAOS: A Scale-Out High Performance Storage Stack for Storage Class Memory》

















 2395
2395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









