







 本文详细解释了NUMA架构中的核心概念,包括CPU核心、Socket、逻辑CPU和线程,以及如何通过`numastat`工具监控内存分配情况。重点介绍了如何优化内存分配策略(默认、绑定、交叉、优先)和解决网卡中断绑定导致的性能瓶颈问题,包括使用IRQBalance和调整中断亲和性。
本文详细解释了NUMA架构中的核心概念,包括CPU核心、Socket、逻辑CPU和线程,以及如何通过`numastat`工具监控内存分配情况。重点介绍了如何优化内存分配策略(默认、绑定、交叉、优先)和解决网卡中断绑定导致的性能瓶颈问题,包括使用IRQBalance和调整中断亲和性。
#概念
-
chip:芯片,一个cpu芯片上可以包含多个cpu core,比如四核,表示一个chip里4个core。
-
socket:芯片插槽,颗,跟上面的chip一样。两颗四核,就表示总共8个core
-
core:包含在一个cpu芯片里的多个核心
-
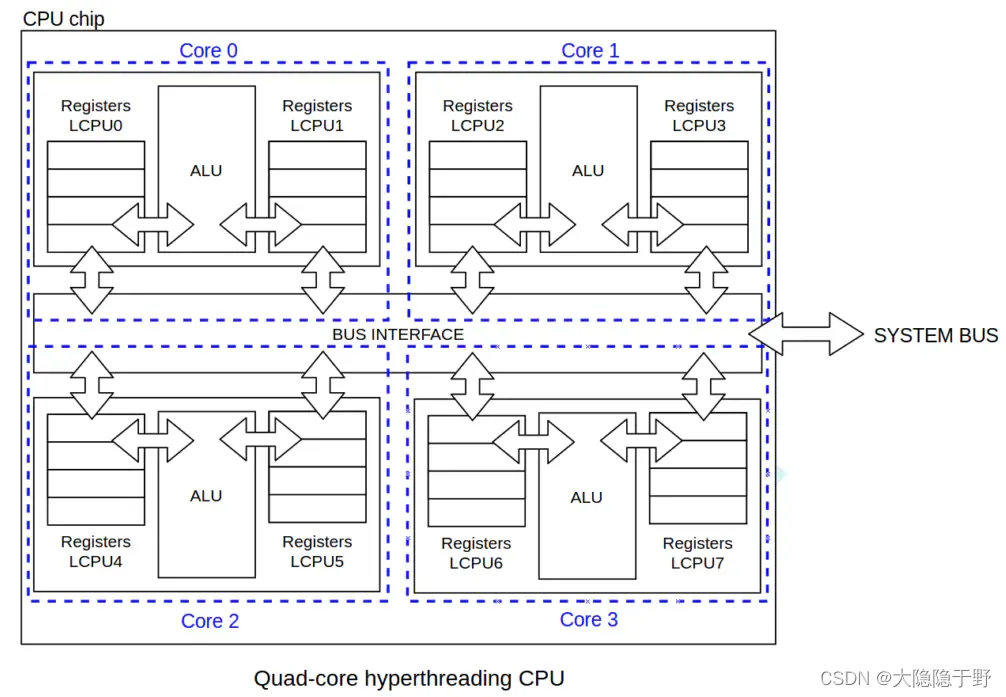
LCPU:逻辑cpu,一个core里可以做多个逻辑cpu,每个LCPU只有寄存器,没有计算单元,类似于分时复用,就是人们常说的线程。4核8线程,就是4个core,一个core里两个线程。
下图为一个四核八线程的chip:
#numastat查看当前numa状态:
$ numastat
node0 node1
numa_hit 1296554257 918018444
numa_miss 8541758 40297198
numa_foreign 40288595 8550361
interleave_hit 45651 45918
local_node 1231897031 835344122
other_node 64657226 82674322
12345678
# 说明:
numa_hit—命中的,也就是为这个节点成功分配本地内存访问的内存大小
numa_miss—把内存访问分配到另一个node节点的内存大小,这个值和另一个node的numa_foreign相对应。
numa_foreign–另一个Node访问我的内存大小,与对方node的numa_miss相对应
local_node----这个节点的进程成功在这个节点上分配内存访问的大小
other_node----这个节点的进程 在其它节点上分配的内存访问大小
很明显,miss值和foreign值越高,就要考虑绑定的问题。
# 查看某个进程的numa内存分配情况
$ numastat -p 39862
Per-node process memory usage (in MBs) for PID 1860 (yd_ex1)
Node 0 Node 1 Total
--------------- --------------- ---------------
Huge 0.00 0.00 0.00
Heap 0.02 0.00 0.02
Stack 0.02 0.00 0.02
Private 1.55 0.10 1.65
---------------- --------------- --------------- ---------------
Total 1.59 0.10 1.69
# 查看numa节点的cpu分配
# $ numactl --hardware
$ numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 32756 MB
node 0 free: 19642 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 32768 MB
node 1 free: 18652 MB
node distances:
node 0 1
0: 10 21
1: 21 10
#numa默认的内存分配策略:
1.缺省(default):总是在本地节点分配(分配在当前进程运行的节点上); 2.绑定(bind):强制分配到指定节点上; 3.交叉(interleave):在所有节点或者指定的节点上交织分配; 4.优先(preferred):在指定节点上分配,失败则在其他节点上分配。
$ numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
cpubind: 0 1
nodebind: 0 1
membind: 0 1
#mysql等指定interleave
对于mysql等占用内存比较多的应用,在numa local 内存不足时,上述策略会优先淘汰/Swap本Chip上的内存,使得大量有用内存被换出。当被换出页被访问时就会出现数据库响应时间飙高甚至阻塞。参考https://www.cnblogs.com/cenalulu/p/4358802.html(opens new window)
解决方法,修改为interleave:
# 轮询分配内存
numactl --interleave=all ./program args
#执行程序时指定numa配置:
# 运行 program 程序,参数是 argument,绑定到cpu11, 内存分配时分配node 1 的内存
numactl --physcpubind=11 --membind=1 ./program args
# 优先考虑从 node 1 上分配内存
numactl --preferred=1
#冷函数问题的 membind 和 numa_balancing
不常访问的函数偶尔访问时(几秒一次),可能会出现延迟较高的情况,比如原来是1us,冷的情况下是3us,perf中观察到有较多的minor-fault(page-fault)
使用numactl --membind 将程序的cpu和mem绑定到同一节点上后,会大大减少perf中观察到的minor-fault(page-fault)的次数,同样会在延迟,只比原来的1us增加几百ns
关闭numa_balancing可起到和membind类似的效果,具体情况需实际测试。
# 关闭numa_balancing
echo 0 > /proc/sys/kernel/numa_balancing
# 查看numa_balancing
sysctl -a | grep numa网卡中断与CPU绑定
1.背景
在Linux的网络调优方面,如果你发现网络流量上不去,那么有一个方面需要去查一下:网卡处理网络请求的中断是否被绑定到单个CPU或跟处理其它中断的是同一个CPU。
先说一下背景,网卡与操作系统的交互一般有两种方式:
<1>中断IRQ,网卡在收到了网络信号之后,主动发送中断到CPU,而CPU将会立即停下手边的活以便对这个中断信号进行分析;
<2>DMA(Direct Memory Access), 也就是允许硬件在无CPU干预的情况下将数据缓存在指定的内存空间内,在CPU合适的时候才处理;
现在的对称多核处理器(SMP)上,一块网卡的IRQ还是只有一个CPU来响应,其它CPU无法参与,如果这个CPU还要忙其它的中断(其它网卡或者其它使用中断的外设(比如磁盘)),那么就会形成瓶颈。
2.检查环境
首先,让网络跑满。如:对于MySQL/MongoDB服务,可以通过客户端发起密集的读操作 或执行一个大文件传送任务。查明是不是某个CPU在一直忙着处理IRQ?从 mpstat -P ALL 1 输出里面的 %irq一列即说明了哪个CPU忙于处理中断的时间占比;
18:20:33 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
18:20:33 all 0.23 0.00 0.08 0.11 6.41 0.02 0.00 93.16 2149.29
18:20:33 0 0.25 0.00 0.12 0.07 0.01 0.05 0.00 99.49 127.08
18:20:33 1 0.14 0.00 0.03 0.04 0.00 0.00 0.00 99.78 0.00
18:20:33 2 0.23 0.00 0.02 0.03 0.00 0.00 0.00 99.72 0.02
18:20:33 3 0.28 0.00 0.15 0.28 25.63 0.03 0.00 73.64 2022.19 上面的例子中,第四个CPU有25.63%时间在忙于处理中断,后面 intr/s 也说明了CPU每秒处理的中断数。从上面的数据可以看出,其它几个CPU都不怎么处理中断。
然后,我们要查另外一个问题:忙于处理中断的CPU都在处理哪些中断?
cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
0: 245 0 0 7134094 IO-APIC-edge timer
8: 0 0 49 0 IO-APIC-edge rtc
9: 0 0 0 0 IO-APIC-level acpi
66: 67 0 0 0 IO-APIC-level ehci_hcd:usb2
74: 902214 0 0 0 PCI-MSI eth0
169: 0 0 79 0 IO-APIC-level ehci_hcd:usb1
177: 0 0 0 7170885 IO-APIC-level ata_piix, b4xxp
185: 0 0 0 59375 IO-APIC-level ata_piix
NMI: 0 0 0 0
LOC: 7104234 7104239 7104243 7104218
ERR: 0
MIS: 0 这里记录的是自启动以来,每个CPU处理各类中断的数量。第一列是中断号,最后一列是对应的设备名。从上面可以看到: eth0所出发的中断全部都是 CPU0在处理,而CPU0所处理的中断请求中,主要是eth0和LOC中断。有时我们会看到几个CPU对同一个中断类型所处理的的请求数相差无几(比如上面的LOC),这并不一定是说多个CPU会轮流处理同一个中断,而是因为这里记录的是“自启动以来”的统计,中间可能因为irq balancer重新分配过处理中断的CPU。
3.问题解决
若通过上面的诊断方法查明当前系统是受这个原因影响,那我们就开始寻求解决办法;
现在的多数Linux系统中都有IRQ Balance这个服务(服务程序一般是 /usr/sbin/irqbalance),它可以自动调节分配各个中断与CPU的绑定关系,以避免所有中断的处理都集中在少数几个CPU上。在某些情况下,这个IRQ Balance反而会导致问题,会出现 irqbalance 这个进程反而自身占用了较高的CPU(当然也就影响了业务系统的性能)。
首先当然要查明,该网卡的中断当前是否已经限定到某些CPU了?具体是哪些CPU?
根据上面 /proc/interrupts 的内容我们可以看到 eth0 的中断号是74,然后我们来看看该中断号的CPU绑定情况或者说叫亲和性 affinity。
$ sudo cat /proc/irq/74/smp_affinity
ffffff 这个输出是一个16进制的数值,0xffffff = ‘0b111111111111111111111111’,这就意味着这里有24个CPU,所有位都为1表示所有CPU都可以被该中断干扰。
修改配置的方法(设置为2表示将该中断绑定到CPU1上,0x2 = 0b10,而第一个CPU为CPU0)
echo 2 > /proc/irq/74/smp_affinity















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









