






 ObjectFormer是一个端到端的多模态框架,结合RGB和频率特征来检测图像篡改。通过使用可学习的对象原型,它建模了对象级和补丁级一致性,以检测和定位图像操作。在多个基准数据集上,ObjectFormer展示了优越的检测和定位性能。
ObjectFormer是一个端到端的多模态框架,结合RGB和频率特征来检测图像篡改。通过使用可学习的对象原型,它建模了对象级和补丁级一致性,以检测和定位图像操作。在多个基准数据集上,ObjectFormer展示了优越的检测和定位性能。
paper:https://arxiv.org/abs/2203.14681
Abstract
近年来图像编辑技术的发展对多媒体数据的可信度提出了严峻的挑战,这推动了图像篡改检测的研究。在本文中,我们提出了ObjectFormer来检测和定位图像操作。为了捕捉在RGB域中不可见的细微操作痕迹,我们提取图像的高频特征,并将它们与RGB特征结合起来作为多模态补丁嵌入。此外,我们使用一组可学习的对象原型作为中间层表示来建模不同区域之间的对象级一致性,并进一步使用这些模型来改进补丁嵌入以捕获补丁级一致性。我们在各种数据集上进行了广泛的实验,结果验证了所提出方法的有效性,优于最先进的篡改检测和定位方法。
1. Introduction
随着GAN[13,25,47]和VAE[18,33]等深度生成模型的快速发展,大量的图像编辑应用已经被公众广泛使用[10,20,29,38]。这些编辑工具使制作可用于娱乐,交互设计等的逼真图像和视频变得简单有效,否则这些图像和视频需要专业技能。然而,越来越多的人担心滥用编辑技术来恶意操作图像和视频内容。因此,开发有效的图像处理检测方法来检测图像是否被修改,并识别图像中被修改的区域至关重要。
图像处理技术一般可分为三种类型:(1)拼接方法,即从一张图像中复制区域并粘贴到其他图像中;(2)复制-移动,即移动图像中物体的空间位置,以及(3)从图像中擦除区域并用视觉上可信的内容重新绘制缺失区域的去除方法。如图1所示,为了产生语义上有意义和感知上令人信服的图像,这些方法通常在对象级别操作图像,即在图像中添加/删除对象。虽然最近有一些研究专注于图像操作检测[16,43,46],但它们通常使用cnn直接将输入图像映射到二值标签(即真实/被操作),而无需显式建模对象级表示。相反,我们认为图像处理检测不仅要检查某些像素是否不在分布范围内,还要考虑物体之间是否一致。此外,在RGB域中无法察觉的图像编辑带来的视觉伪影,在频域往往是明显的[6,31,39]。这需要一种多模态方法,联合建模RGB域和频率域,以发现微妙的操作痕迹。

本文介绍了ObjectFormer,一个用于图像处理检测和定位的多模态transformer框架。ObjectFormer建立在transformer的基础上,因为它们在各种视觉任务上的表现令人印象深刻,如图像分类[12,15,24],目标检测[5,49],视频分类[4,23,40,41]等。更重要的是,transformer是模拟图像中补丁/像素是否一致的自然选择,因为它们利用自注意来探索不同空间位置之间的相关性。受自动学习的对象查询的启发[1,49],我们使用一组可学习的参数作为对象原型(作为中级对象表示)来发现对象级一致性,并进一步利用这些参数来改进补丁嵌入,以实现补丁级一致性建模。
考虑到这一点,ObjectFormer首先使用离散余弦变换将图像从RGB域转换到频域,然后用几个卷积层提取多模态补丁嵌入。将RGB补丁嵌入和频率补丁嵌入进一步连接以相互补充。此外,我们使用一组可学习的嵌入作为对象查询/原型,与派生的补丁嵌入交互以学习不同对象之间的一致性。我们通过交叉注意来改进这些对象原型的补丁嵌入。通过迭代这样做,ObjectFormer派生出显式编码中级对象特征的全局特征表示,这些特征可以很容易地用于检测操作工件。最后,利用全局特征以多任务的方式预测图像是否被修改和相应的操作掩码。可以以端到端方式训练框架。我们在CASIA[11]、Columbia[35]、Coverage[42]、NIST16[27]、IMD20[28]等常用的图像篡改数据集上进行了实验。结果表明,ObjectFormer优于最先进的篡改检测和定位方法。总之,我们的工作做出了以下关键贡献:
•我们引入了ObjectFormer,这是一个端到端的多模态框架,用于图像处理检测和定位,结合RGB特征和频率特征来识别篡改工件。
•我们明确地利用可学习的对象原型作为中级表示来建模对象级一致性和改进补丁嵌入以捕获补丁级一致性。
•我们在多个基准上进行了广泛的实验,并证明我们的方法达到了最先进的检测和定位性能。
2. Related Work
Image Manipulation Detection / Localization:大多数早期研究集中于检测特定类型的操作,例如,拼接[8,17,19],复制-移动[7,32]和移除[48]。然而,在现实场景中,确切的操作类型是未知的,这激发了一系列专注于一般操作检测的工作[3,16,43]。此外,RGB- N[46]引入了一个用于操作定位的双流网络,其中一个流提取RGB特征以捕获视觉伪像,另一个流利用噪声特征对篡改区域和未篡改区域之间的不一致性进行建模。SPAN[16]通过局部自注意块的金字塔结构,在多个尺度上对图像补丁内像素之间的关系进行建模。PSCCNet[22]使用自顶向下的路径提取层次特征,并使用自底向上的路径检测输入图像是否被操作。在这项工作中,我们通过显式地采用一组可学习的嵌入作为对象级一致性建模的对象原型和用于补丁级一致性建模的精细补丁嵌入来检测操作工件。
Visual Transformer:transformer[37]及其变体在自然语言处理中的显著成功,激发了大量的工作,探索各种计算机视觉任务的transformer,因为它们具有建模远程依赖关系的能力。更具体地说,ViT[12]将图像重塑为一系列平坦的补丁,并将其输入到transformer编码器中进行图像分类。T2T[45]采用Token-toToken模块,在使用自注意层之前逐步聚合本地信息。也有一些研究将自注意块与经典卷积神经网络相结合。例如,DETR[5]使用预训练的CNN提取底层特征,然后将其馈送到基于transformer的编码器-解码器架构中进行对象检测。相比之下,我们引入了频率信息,以方便捕获细微的伪造痕迹,并通过多模态transformer将其与RGB模态特征进一步结合,用于图像篡改检测。
3. Method
我们的目标是通过建模中间层表示之间的视觉一致性来检测图像中的被操纵对象,中间层表示是通过关注多模态输入自动导出的。在本节中,我们将介绍ObjectFormer,它由高频特征提取模块(第3.1节)、对象编码器(第3.2节)组成,该编码器使用可学习的对象查询来学习图像中的中级表示是否一致,以及补丁解码器(第3.3节),该解码器生成用于操作检测和定位的精细全局表示。图2给出了该框架的概述。
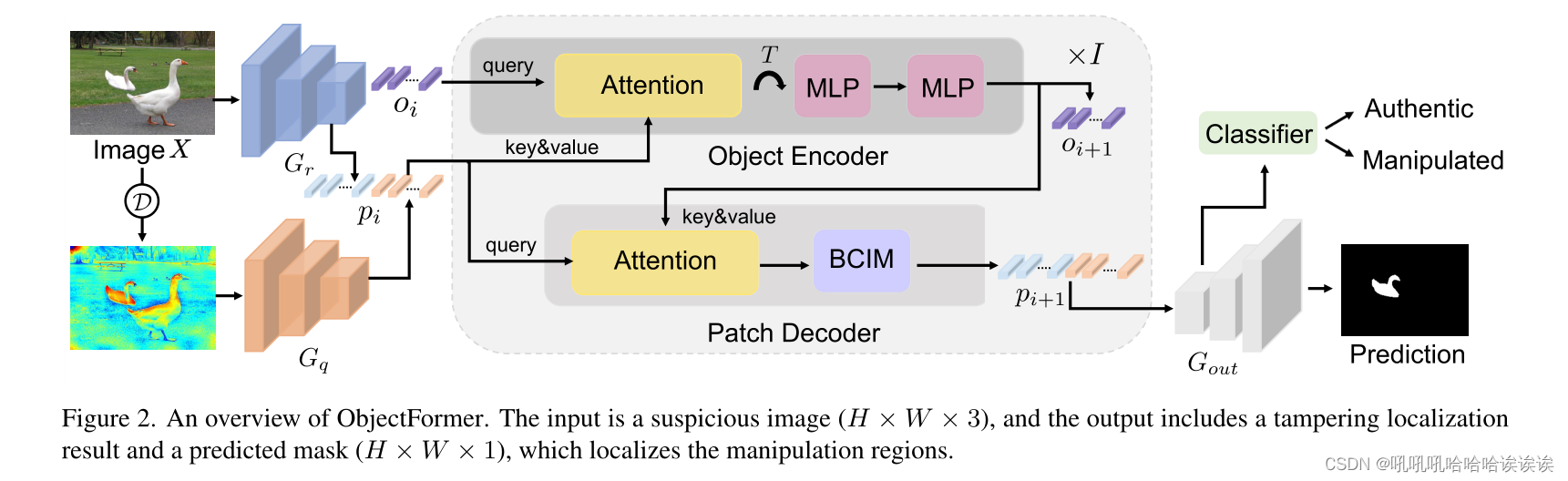


更正式地说,我们将输入图像表示为X∈RH×W ×3,其中H和W分别是图像的高度和宽度。我们首先提取特征映射Gr∈RHs×Ws×Cs,并使用几个卷积层(参数化为g)生成补丁嵌入,以便更快地收敛,如[44]所示。
3.1. High-frequency Feature Extraction 高频特征提取
由于被篡改的图像通常经过后处理以隐藏篡改的痕迹,因此很难在RGB空间中捕捉到细微的伪造痕迹。因此,我们从频域提取特征,为操纵检测提供补充线索。
ObjectFormer以图像X为输入,首先使用离散余弦变换(Discrete Cosine Transform, DCT)将其从RGB域变换到频域:

其中Xq∈RH×W ×1为频域表示,D为DCT。然后,我们通过高通滤波器获得高频分量,并将其变换回RGB域,以保持自然图像的移位不变性和局部一致性:
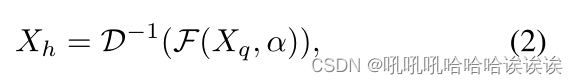
其中F表示高通滤波器,α为手动设计的阈值,控制低频分量被滤除。之后,我们将Xh输入到几个卷积层中,提取频率特征Gf,其大小与Gr相同。
然后,我们使用Gr和Gf生成相同大小的空间补丁,并进一步将它们平铺成长度为L的C-d向量序列。我们将这两个序列连接起来,得到一个多模态补丁向量 p∈R2L×C。将正弦位置嵌入[5]添加到p中以提供位置信息。
3.2. Object Encoder
目标编码器旨在自动学习一组中级表示,这些表示关注Gr/Gf中的特定区域,并识别这些区域是否彼此一致。为此,我们使用一组可学习的参数o∈RN×C作为对象原型,通过学习来表示可能出现在图像中的对象。N是一个人工设计的常数值,表示对象的最大数量,我们在本文中经验地设置为16。
具体来说,给定来自第i层的对象表示oi,我们首先使用层规范化(LN)对其进行规范化,并将其用作注意块的查询。归一化后的patch embedding(pi)作为key和value。注意,我们分别设置p0 = p, o0 = o。然后利用矩阵乘法和softmax函数计算 object-patch 关联矩阵Ai∈RN×L:
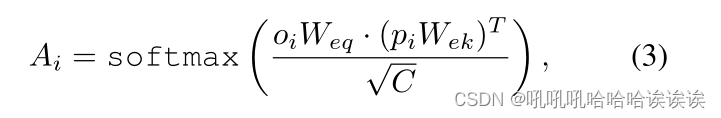
其中,Weq和Wek是两个线性投影层的可学习参数。之后,我们使用另一个线性层将pi投影到值嵌入中,并进一步用Ai计算其加权平均值,得到注意矩阵。最后,通过与注意矩阵的残差连接更新对象表示,得到:
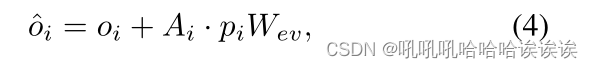
其中,Wev是值嵌入层的可学习参数。这样,每个对象表示都可以注入来自所有位置的全局上下文信息。然后我们进一步使用单个线性投影实现不同对象之间的交互:
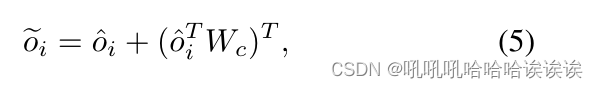
其中Wc∈RN×N是一个可学习的权重矩阵。这本质上是学习不同的对象原型如何相互作用,以发现对象级别的视觉不一致性。
由于图像中的目标数量不同,我们还使用线性投影层和激活函数GELU[14]来增强目标特征。这个过程可以表述为:
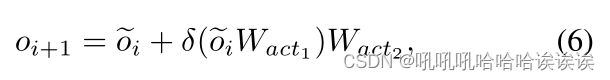
其中Wact1和Wact2为可学习参数,δ为GELU函数,oi+1为更新后的对象表示
3.3. Patch Decoder
目标编码器允许图像中的不同对象彼此交互,以模拟中层表示是否在视觉上连贯并关注重要的补丁。除此之外,我们使用来自目标编码器的更新对象表示来进一步细化补丁嵌入。更具体地说,我们使用pi作为查询,oi+1作为键和值,并按照经典的注意力范式增强补丁特征。这样,每个补丁嵌入都可以进一步从派生的对象原型中吸收有用的信息。
更具体地说,我们首先采用层归一化对pi和oi+1进行归一化,然后将它们馈送到一个注意块中进行补丁嵌入细化。整个过程可表述为:
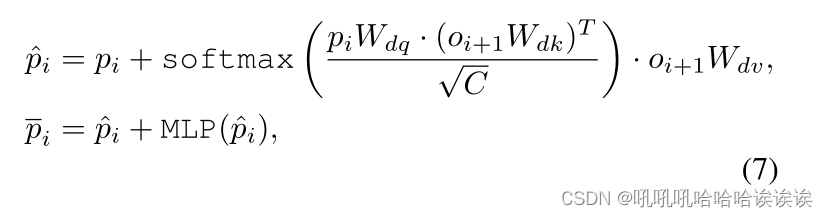
其中Wdq、Wdk和Wdv是三个嵌入层的可学习参数,MLP表示具有两个线性映射的多层感知器。
在将中级目标特征聚合到图像中的每个补丁中之后,我们进一步应用边界敏感上下文不相干建模(BCIM)模块来检测像素级的不一致性,以进行细粒度特征建模。特别是,我们首先将pi∈R2N×C重塑为大小为RHs×Ws×2Cs的2D特征映射Pi。然后我们计算每个像素和周围像素在一个局部窗口内的相似度:
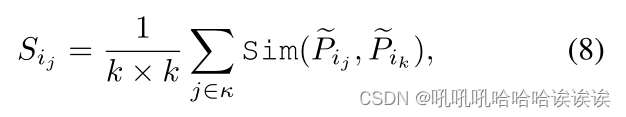
其中,κ表示特征映射Pi中的一个k × k小窗口,Pij是该窗口的中心特征向量,Pik是其在κ内的邻近特征向量。我们使用的相似度度量函数Sim是余弦相似度。然后计算Si∈RHs×Ws×1与Pi之间的元素求和,得到大小为RHs×Ws×2Cs的边界敏感特征图,得到边界敏感特征图,最后将其序列化为patch embedding pi+1∈R2N×C。
请注意,我们以有序顺序使用堆叠对象编码器和图像解码器I次(在本文中我们设置为8次)来交替更新对象表示和补丁特征。最后,我们得到了pout∈R2N×C,它包含了对象级和补丁级的视觉一致性信息。然后,我们将其重塑为二维特征图Gout,然后将其用于操作检测和定位。
3.4. Loss Functions
对于操纵检测,我们在Gout上应用全局平均池化,并使用完全连接层计算最终的二进制预测y。而对于操作定位,我们通过交替卷积层和线性插值操作逐步对Gout进行上采样,以获得预测掩码M。给定真值标签y和掩码M,我们用以下目标函数训练ObjectFormer:
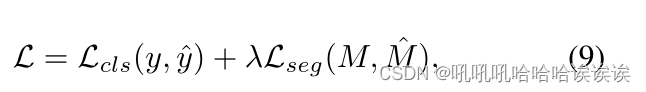
其中Lcls和Lseg都是二元交叉熵损失,λseg是一个平衡超参数。默认情况下,我们设置λseg = 1。
4. Experiments
我们在两个密切相关的任务上评估我们的模型:操作定位和检测。在前一个任务中,我们的目标是在图像中定位被操纵的区域。在后一项任务中,目标是将图像分类为被操纵的或真实的。下面,我们将在4.1节中介绍实验设置,并在4.2节和4.4节中介绍结果,最后,我们将在4.5节中进行消融研究,以证明不同组件的有效性,并在4.6节中展示可视化结果。
4.1. Experimental Settings
Synthesized Pre-training Data :我们合成了一个大规模的图像篡改数据集,并在其上预训练我们的模型。合成数据集包括三个子集:1)FakeCOCO,它建立在MS COCO基础上[21]。受[46]的启发,我们使用MS COCO提供的注释在同一图像中随机复制和粘贴对象,或者将对象从一张图像切片到另一张图像。我们还在源图像和目标图像之间应用泊松混合算法来消除切片边界。2) FakeParis,建立在Paris StreetView[30]数据集上。我们从真实图像中删除一个区域,并采用最先进的修复方法Edgeconnnect[26]来恢复其中的视觉内容。3)原始图像,即上述数据集的原始图像。我们对生成的数据随机添加高斯噪声或应用JPEG压缩算法,以接近真实场景中图像的视觉质量。
Testing Datasets :我们遵循PSCCNet[22]在CASIA[11]数据集、Columbia[35]数据集、Carvalho[42]、Nist Nimble 2016 (NIST16)数据集[27]和IMD20[28]数据集上对我们的模型进行了评估。
CASIA[11]提供了各种物体的拼接和复制移动图像。篡改区域是精心选择的,一些后处理技术,如滤波和模糊也被应用。通过对篡改图像和原始图像的差值进行二值化,得到真实掩码。
Columbia[35]数据集专注于基于未压缩图像的拼接。提供了真实的掩码。
Coverage[42]数据集包含100张由复制移动技术生成的图像,ground-truth mask也可用。
NIST16[27]是一个具有挑战性的数据集,它包含了所有三种篡改技术。此数据集中的操作经过后处理以隐藏可见的痕迹。它们为评估提供了真实的篡改掩码。
IMD20[28],它收集了35000张不同相机型号拍摄的真实图像,并使用多种Inpainting方法生成相同数量的伪造图像。
为了对ObjectFormer进行微调,我们使用与[16,22]相同的训练/测试分割来进行公平的比较。
Evaluation Metrics:我们评估了该方法在图像处理检测任务和定位任务上的性能。对于检测结果,我们采用图像级曲线下面积(Area Under Curve, AUC)和F1分数作为评价指标,而对于定位,我们采用像素级操作掩码上的AUC和F1分数。由于计算F1分数需要二进制掩码和检测分数,因此我们采用等错误率(EER)阈值对它们进行二值化。
Implementation Details:所有图像都被调整为256 × 256。对于我们的骨干网,我们使用在ImageNet[9]上预训练的EfficientNetb4[36]。我们使用Adam进行优化,学习率为0.0001。我们训练了90个epoch的完整模型,批大小为24,学习率每30个epoch衰减10倍。
Baseline Models:我们将我们的方法与各种基线模型进行比较,如下所述:
J-LSTM[2],采用CNN-LSTM混合架构捕捉篡改图像中被篡改区域和未被篡改区域之间的区别特征。
H-LSTM[3],将CNN编码器提取的重采样特征分割成小块,采用LSTM网络对不同小块之间的过渡进行建模,实现篡改定位。
RGB- N[46],采用RGB流和噪声流并行,分别发现图像内的篡改特征和噪声不一致。
ManTraNet[43],它使用特征提取器捕获操纵痕迹和本地异常检测网络来定位被操纵区域。
SPAN[16],它利用金字塔架构,通过自注意块对图像补丁的依赖性进行建模。
PSCCNet[22],采用不同尺度的特征逐步进行图像篡改定位,从粗到精。
4.2. Image Manipulation Localization
与二进制篡改检测任务相比,操作定位更具挑战性,因为它需要模型捕获更精细的伪造特征。根据SPAN[16]和PSCCNet[22],我们在两种设置下将我们的模型与其他最先进的篡改定位方法进行了比较:1)在合成数据集上进行训练,并在完整的测试数据集上进行评估。2)在测试数据集的训练分割上对预训练模型进行微调,并在测试分割上进行评估。
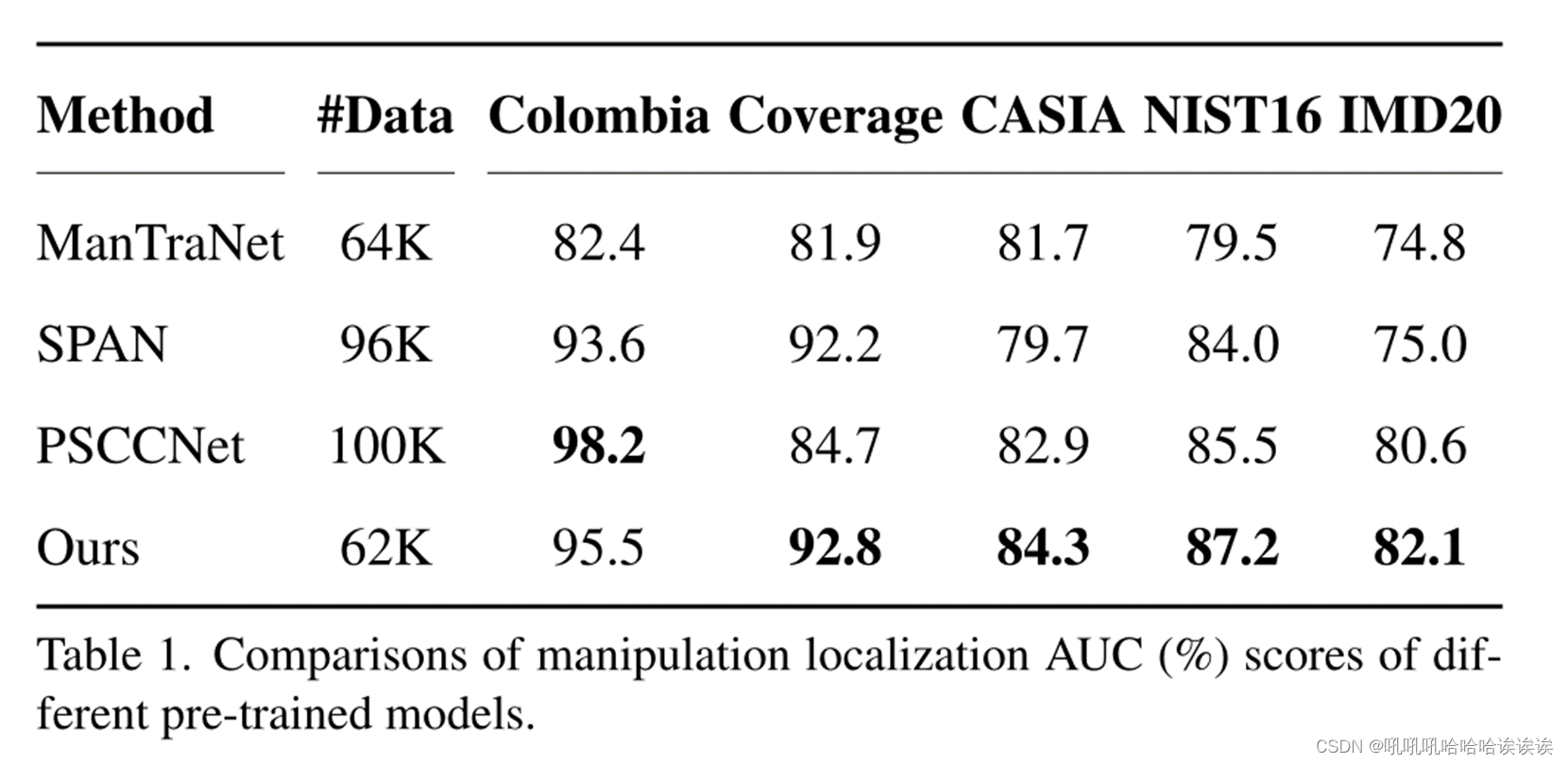
Pre-trained Model:对于预训练模型评估,我们将ObjectFormer与MantraNet[43]、SPAN[16]和PSCCNet[22]进行比较。我们在表1中报告了AUC分数(%),从中我们可以观察到ObjectFormer在大多数数据集上实现了最佳的定位性能。特别是,ObjectFormer在真实数据集IMD20上达到82.1%,比PSCCNet高出1.9%。这表明我们的方法具有较强的篡改特征捕获能力,可以很好地推广到高质量的篡改图像数据集。在Columbia数据集上,我们比SPAN和MaTraNet分别高出2.0%和15.9%,但比PSCCNet落后2.7%。我们认为原因可能是他们的综合训练数据与Columbia数据集的分布非常相似。这可以通过表2中的结果进一步验证,表2表明,如果在Columbia数据集上对模型进行微调,ObjectFormer在AUC和F1分数方面都优于PSCCNet。此外,值得指出的是,与其他方法相比,ObjectFormer使用较少的预训练数据获得了不错的结果。
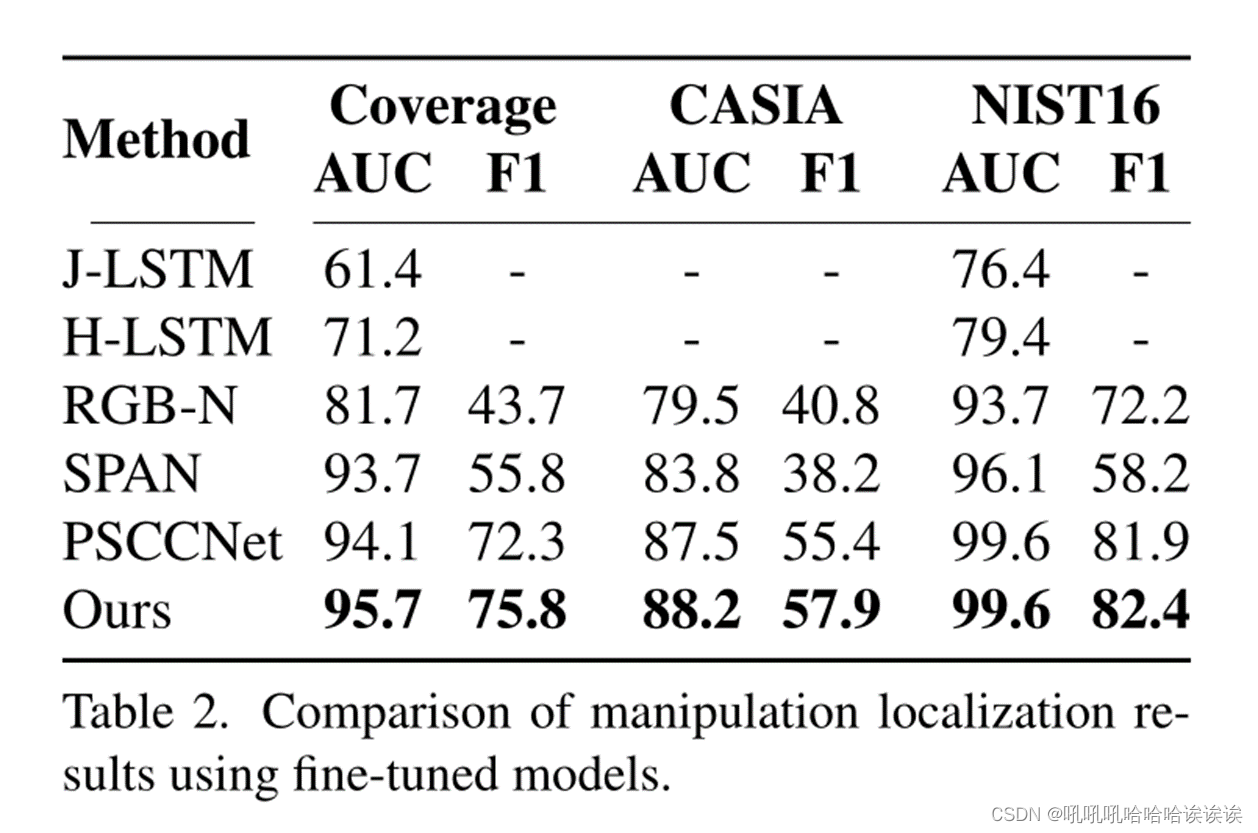
Fine-tuned Model:为了弥补合成数据集和标准数据集在视觉质量上的差异,我们在特定数据集上进一步微调预训练模型,并与表2中其他方法进行比较。我们可以观察到显著的性能提升,这说明ObjectFormer可以通过对象级和补丁级一致性建模以及多模态设计捕获细微的篡改工件。
4.3. Image Manipulation Detection
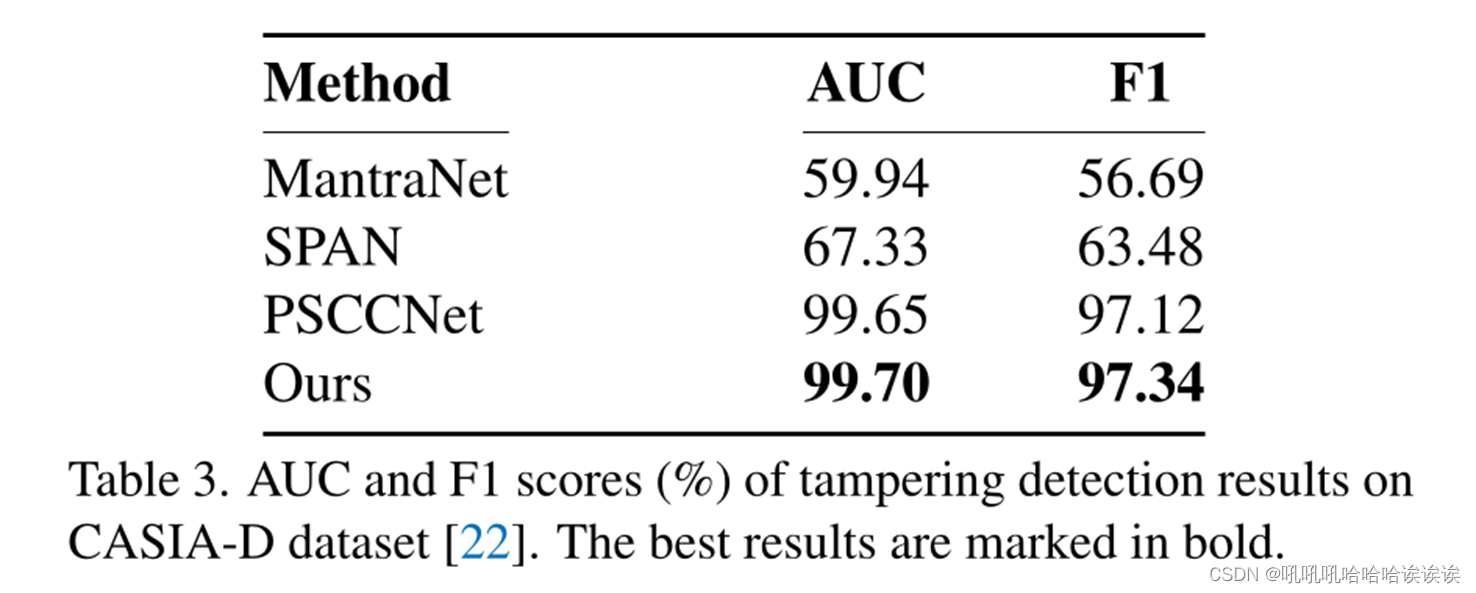
由于以往的研究大多没有考虑篡改检测任务,我们在[22]引入的CASIA-D上对我们的模型进行评估。表3显示了检测被操纵图像的AUC和F1分数(%)。结果表明,我们的模型达到了最先进的性能,即AUC为99.70%,F1为97.34%,这证明了我们的方法捕获操纵伪影的有效性。
4.4. Robustness Evaluation
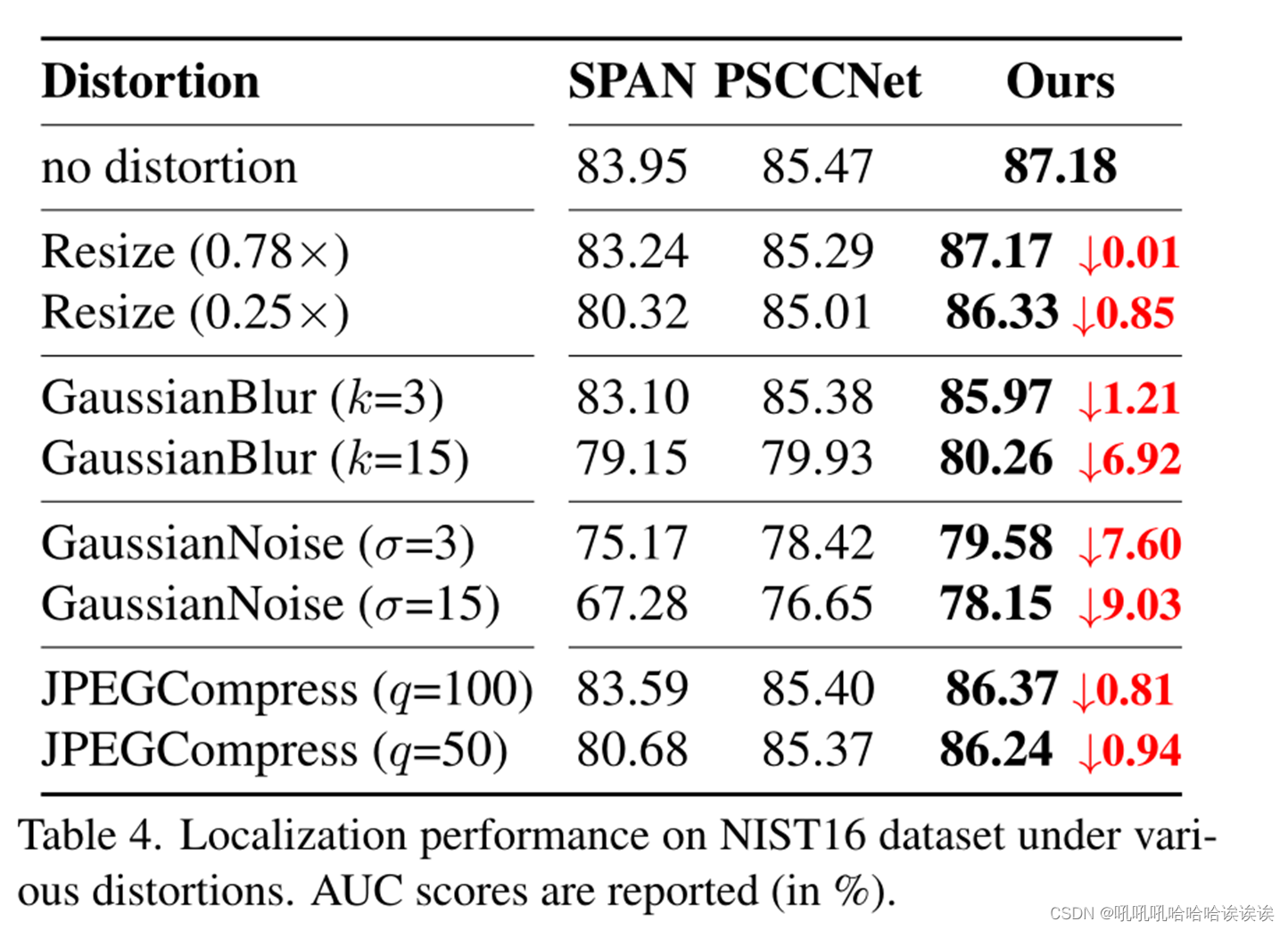
遵循PSCCNet[22],我们对NIST16数据集的原始图像应用了不同的图像失真方法,并评估了我们的ObjectFormer的鲁棒性。失真类型包括:1)不同尺度的图像缩放,2)核大小为k的高斯模糊,3)标准差为σ的高斯噪声,以及4)质量因子为q的JPEG压缩。我们使用SPAN[16]和PSCCNet[22]对这些损坏的数据进行了预处理模型的操作定位性能(AUC分数)的比较,结果如表4所示。ObjectFormer对各种失真技术表现出更好的鲁棒性,特别是在压缩图像上(当质量因子为100时比PSCCNet高1.1%,当质量因子为50时比PSCCNet高1.0%)。
4.5. Ablation Analysis
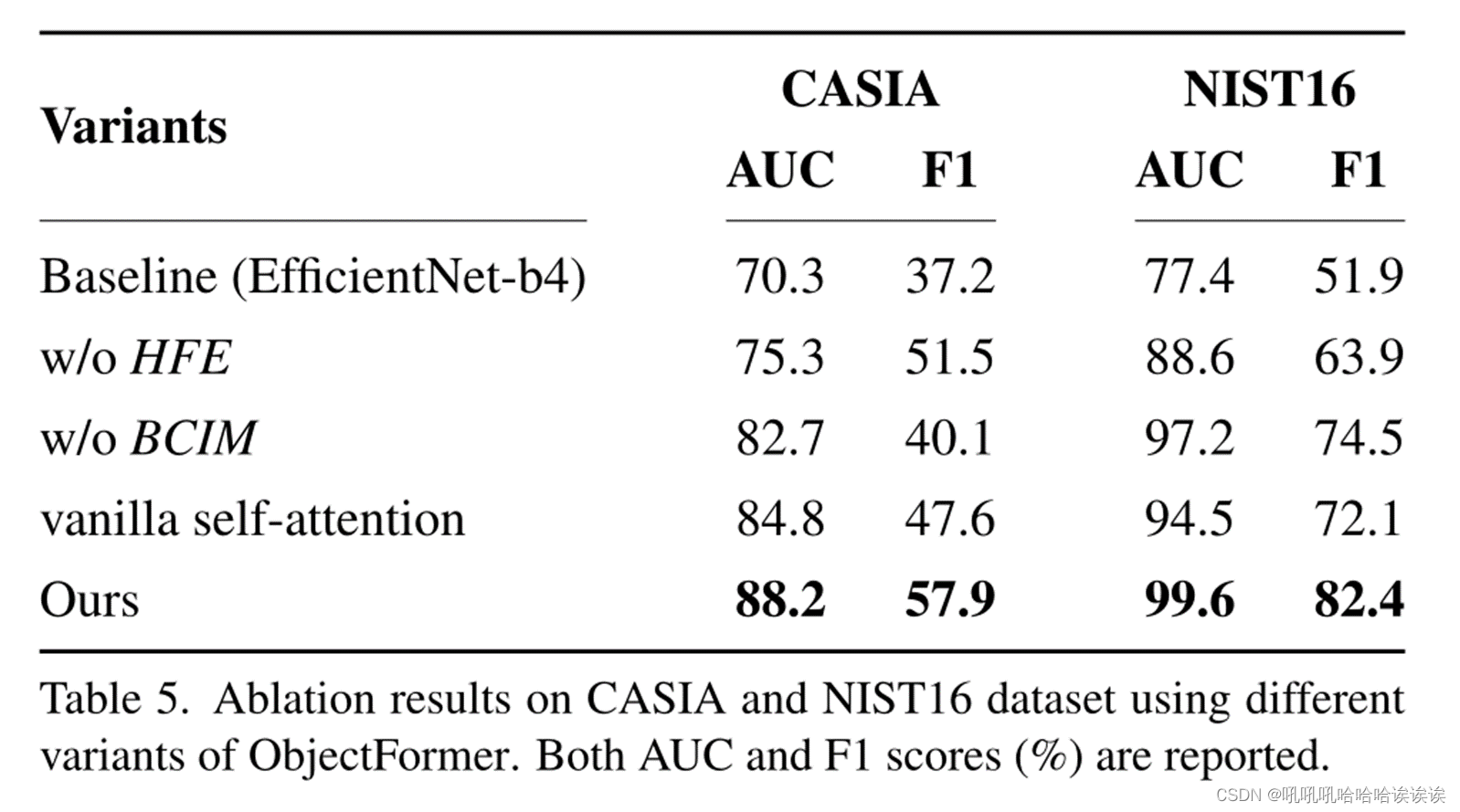
该方法的高频特征提取(HFE)模块用于提取频率域的异常伪造特征,而边界灵敏度上下文不相干建模(BCIM)模块用于提高预测篡改掩模的清晰度。为了评估HFE和BCIM的有效性,我们将它们分别从ObjectFormer中移除,并在CASIA和NIST16数据集上评估篡改定位性能。
定量结果如表5所示。我们可以观察到,在没有HFE的情况下,CASIA的AUC分数下降了14.6%,NIST16的AUC分数下降了11.0%,而没有BCIM的情况下,CASIA的AUC分数下降了6.2%,NIST16的AUC分数下降了2.4%。性能退化验证了HFE和BCIM的使用有效地提高了模型的性能。此外,为了说明ObjectFormer学习到的表示的有效性,我们丢弃了对象表示,并用vanilla自关注块替换堆叠的对象编码器和图像解码器。我们可以在表5的第三行观察到显著的性能下降,即在NIST16数据集上,AUC下降了5%,F1下降了12.5%。
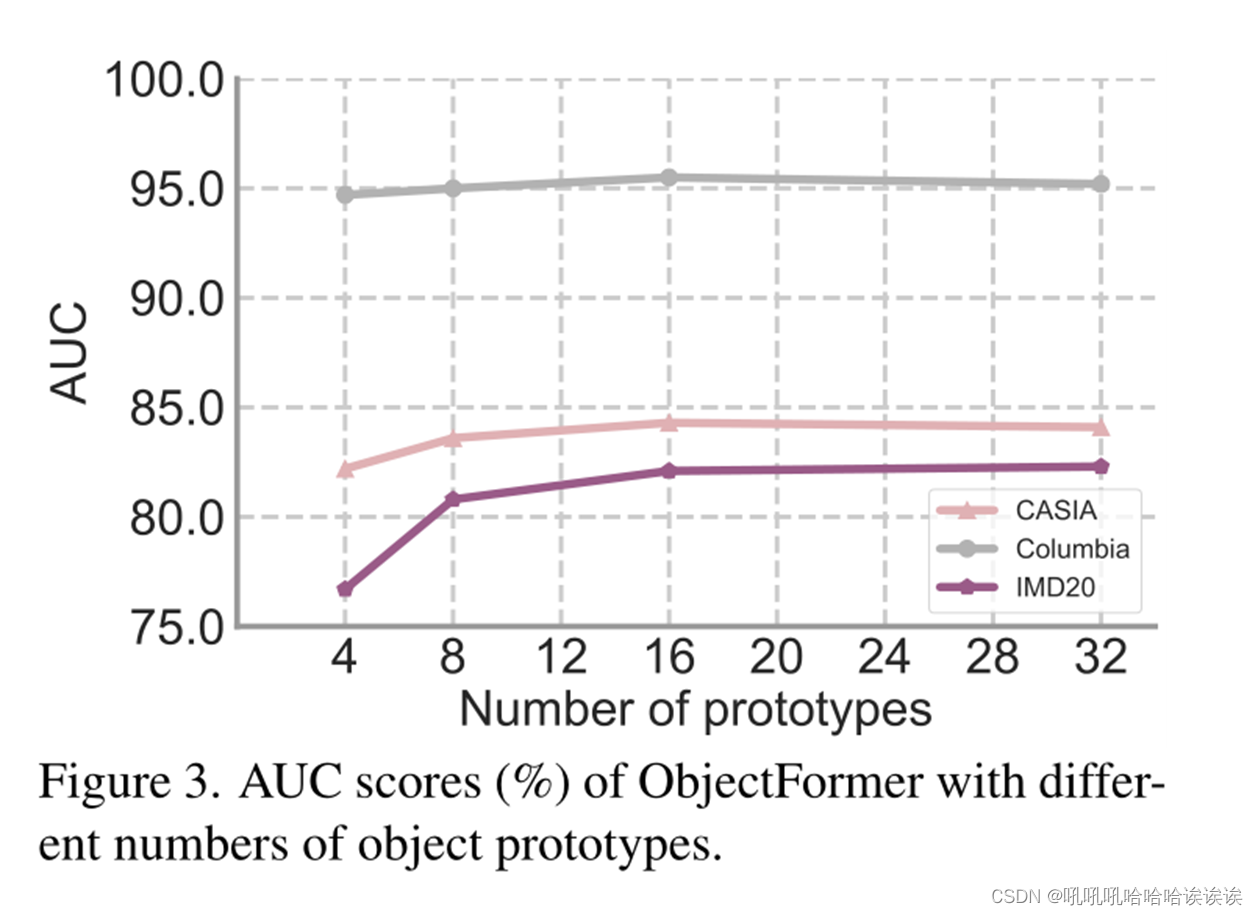
部署对象原型来表示可能出现在图像中的可视元素,这有助于ObjectFormer学习用于对象级一致性建模的中级语义特性。我们进一步进行了实验来研究原型数量(N)对模型性能的影响。如图3所示,随着原型数量的增加,篡改位置性能整体呈增量趋势,当N = 16时,在Columbia和CASIA数据集上达到最佳。
4.6. Visualization Results
Visualization of object encoder :我们进一步定性地研究ObjectFormer的行为。具体来说,我们在第一个对象编码器中取亲和矩阵Ai (Eqn. 3)的所有正面的平均值,然后将其归一化为[0,255]。对于每张图像,我们可视化原始图像(列1),以及由不同对象原型参与的区域,例如,列2和3是两个原型对应于两个前景对象,而列4和5与背景对象相关。图4的结果表明,通过迭代更新,对象表示对应于图像中有意义的区域,从而有助于对象一致性建模。

Qualitative results: 我们在图5中提供了不同方法的预测操作掩码。由于无法获得PSCCNet的源代码[22],因此无法获得他们的预测。结果表明,利用ObjectFormer的不一致建模能力和边界敏感性,该方法不仅可以更准确地定位篡改区域,而且可以形成更清晰的边界。

Visualization of high-frequency features:为了验证频率特征对篡改检测的有用性,我们在图6中使用GradCAM[34](第3.1节)可视化高频成分和HFE特征。结果表明,虽然伪造图像在视觉上是自然的,但在频域上,被篡改的区域与未篡改的区域是可区分的。
4.7. Limitation
ObjectFormer面临一个潜在的限制:当使用预训练模型评估Columbia上篡改定位的性能时,ObjectFormer的AUC得分比PSCCNet[22]低2.7%。可能的原因是他们使用的预训练数据与Columbia数据集中的数据分布非常相似。因此,我们相信这个问题可以通过使用更多的预训练数据来解决。
5. Conclusion
我们介绍了ObjectFormer,一个端到端的多模态框架,用于图像篡改检测和定位。为了检测在RGB域中不再可见的细微操纵工件,ObjectFormer在频域中提取伪造特征作为补充信息,并进一步与RGB特征相结合以生成多模态补丁嵌入。此外,ObjectFormer利用可学习的对象原型作为中间层表示,并交替更新对象原型和补丁嵌入与堆叠的对象编码器和补丁解码器,以模拟图像中的对象级和补丁级视觉一致性。在不同数据集上的大量实验证明了该方法的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









