







影刀RPA的核心功能包括数据抓取、解析、校验和自动填表,还支持可视化流程设计器、Python和JavaScript脚本接入,以及流程录制等功能,帮助用户快速搭建自动化流程。影刀RPA结合AI技术,支持机器视觉、自然语言处理等高级功能,进一步提升自动化能力。影刀RPA广泛应用于电商、金融、制造等行业,帮助客户实现订单处理、客户数据录入、财务对账等任务的自动化。
1.实战目标

采集字段:
- 采集时间
- 商品ID
- 商品标题
- 标价
- 商品链接
采集的第一个品 可通过钉钉分享给好友
PC端
移动端

也可以通过钉钉群通知指令,发送到指定群

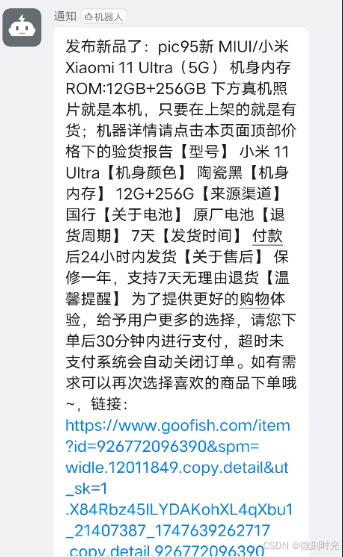
2.实战代码
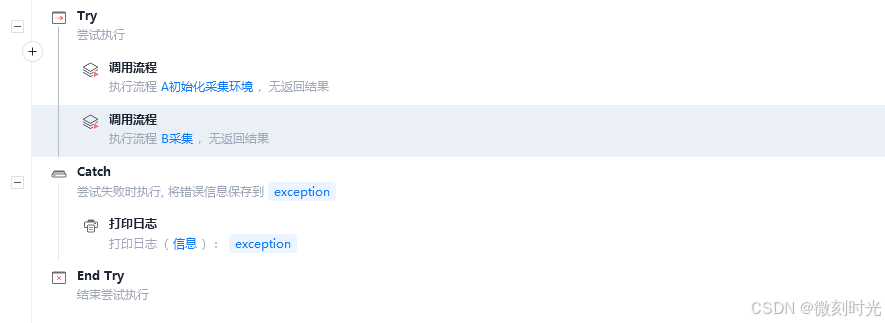
2.1 主体代码
2.2 采集初始化
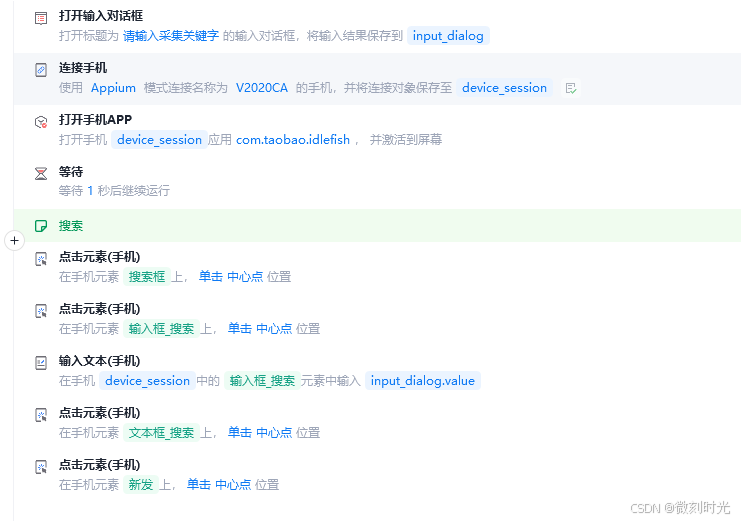
- 先初始化环境
这一步骤主要是连接手机,能使用影刀RPA操作闲鱼APP
输入搜索关键字,定位到采集列表
初始化运行后,先提示需要输入采集关键字
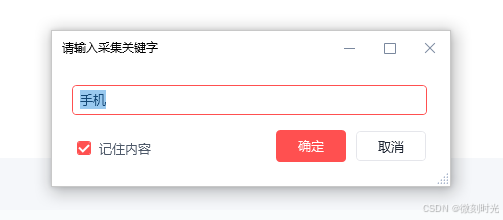
- 搜索关键字
在输入框中,输入关键字,搜索出指定商品

2.3 商品列表
指定滑动页码,每次当前页循环采集后,开始滑动手机,

循环体:
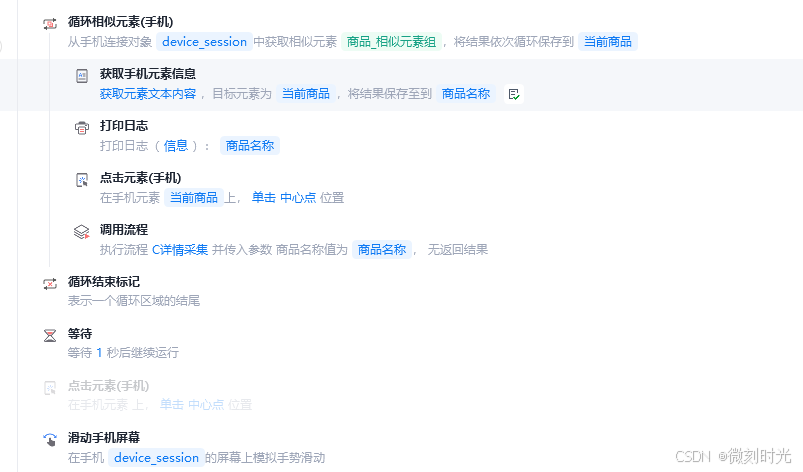
2.3 商品采集
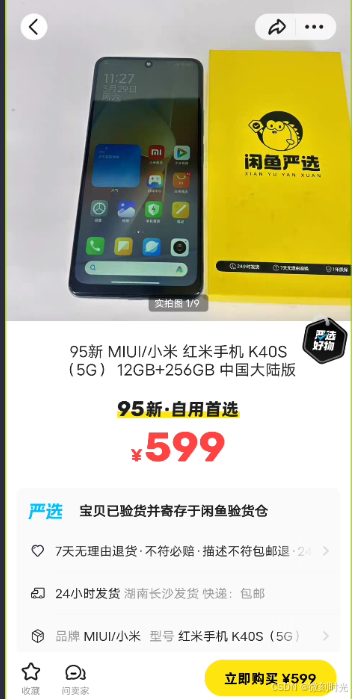
获取商品链接地址
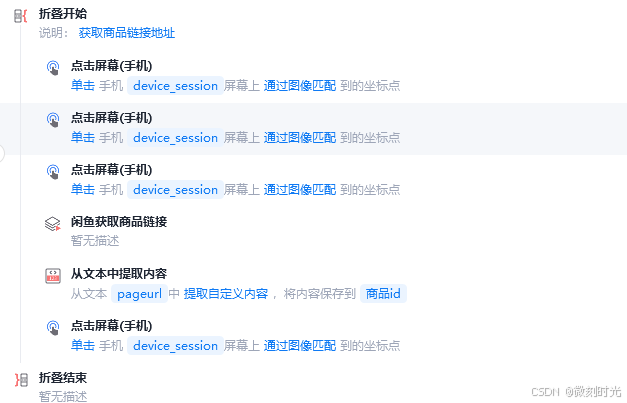
分享钉钉
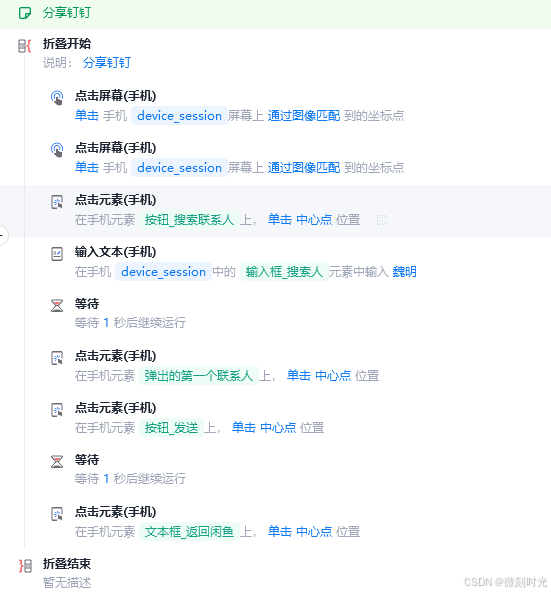
钉钉群通知
商品价格
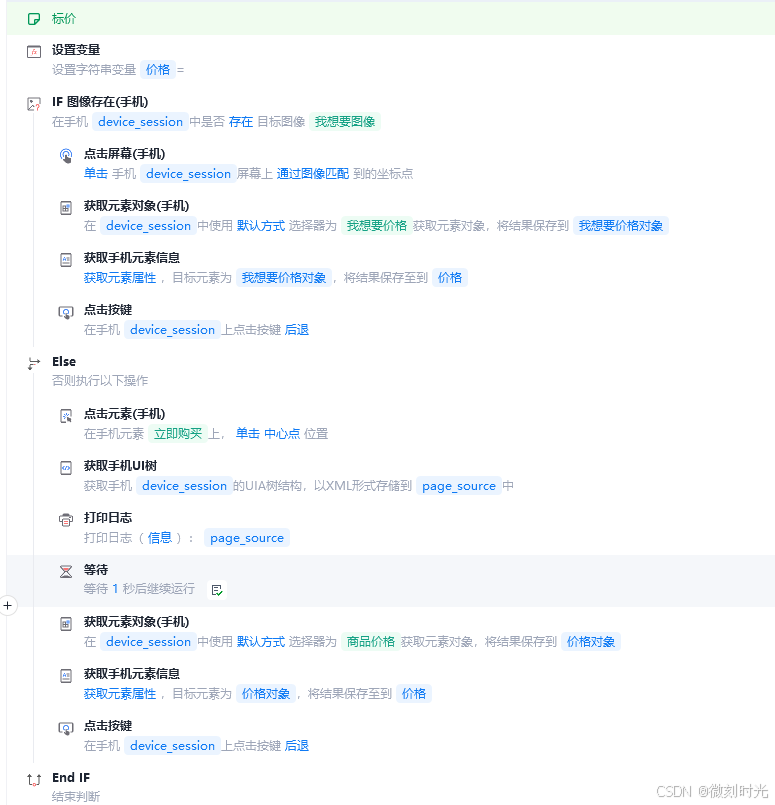
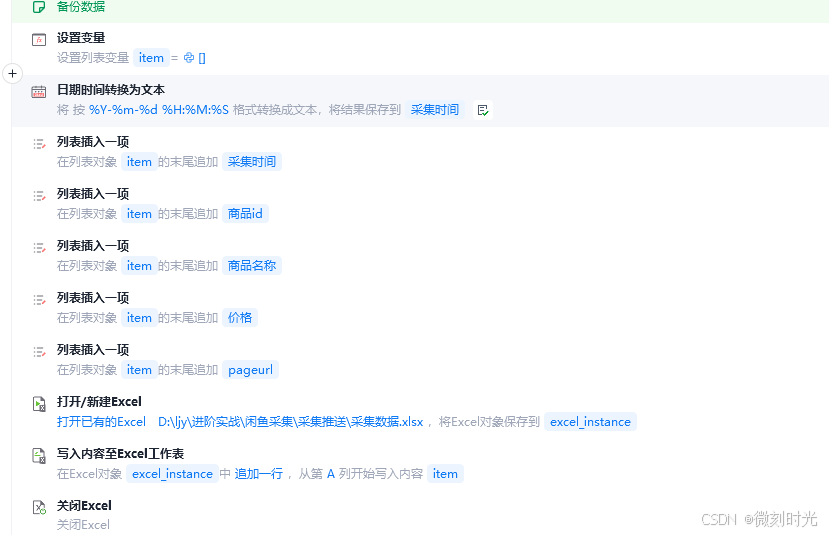
2.4 写入文件
主要写入excel,备份本次采集数据。

3.影刀拖拽指令做爬虫
感谢大家

影刀RPA是一款零代码的自动化工具,通过拖拽指令可以实现网页爬虫功能,适合编程基础薄弱的用户。以下是使用影刀RPA拖拽指令进行爬虫的基本步骤:
打开网页
-
使用“打开网页”指令,输入目标网页的URL。
-
确保选择已安装影刀插件的浏览器。
捕获元素
-
使用“捕获元素”功能,定位网页中的目标元素。
-
可以通过元素库选择已捕获的元素,或通过“捕获新元素”来定位新的网页元素。
数据提取
-
使用“批量数据抓取”指令,选择要抓取的内容。
-
如果需要抓取多页数据,可以设置“下一页”按钮和抓取的页数。
循环处理
-
使用“ForEach列表循环”指令,循环处理网页中的相似元素。
-
在循环体中,可以进一步提取每个元素的具体信息。
数据存储
-
使用“写入内容至表格数据”指令,将抓取的数据存储到Excel表格中。
-
可以设置数据存储的起始位置,避免重复写入。
处理反爬机制
-
如果遇到滑块验证,可以使用“拖拽元素(web)”指令,模拟人工拖动滑块。
-
对于需要逆向处理的加密数据,可以使用“执行js脚本”指令。
定时采集
-
将搭建好的爬虫应用发布并设置定时触发器,实现定时采集。
影刀RPA通过封装复杂的操作逻辑,将爬虫任务简化为简单的拖拽指令,大大降低了学习成本


















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











