






arxiv'2024
paper: https://arxiv.org/pdf/2408.02306
code:
Abstract
随着人脸处理技术的进步,多人脸场景下的图像伪造正逐渐成为一个更加复杂和现实的挑战。尽管如此,这种多人脸操作的检测和定位方法仍然不发达。传统的操作定位方法要么间接地从定位掩码中获得检测结果,导致检测性能受限,要么采用朴素的双分支结构同时获得检测和定位结果,由于两个任务之间的交互作用有限,无法有效地提高定位能力。本文提出了一个专门针对多人脸操作检测和定位的新框架,即MoNFAP。MoNFAP主要引入了两个新颖的模块:伪造感知的统一预测器(FUP)模块和混合噪声模块(MNM)。FUP通过token学习策略和多个伪造感知transformers将检测和定位任务集成在一起,便于使用分类信息来增强定位能力。此外,由于噪声信息在伪造检测中的关键作用,基于混合experts的概念,MNM利用多个噪声提取器来增强一般RGB特征,进一步提高了框架的性能。最后,我们建立了一个综合的多人脸检测和定位基准,所提出的MoNFAP取得了显著的性能。这些代码将被提供。
索引术语:多人脸操作,人脸操作定位,expert混合,掩码注意。
I. INTRODUCTION
人脸操作技术[1]-[5]迅速发展,取得越来越逼真的效果。近年来,在现实需求的驱动下,伪造的重点从单人脸伪造转向多人脸伪造[6]-[8],导致了虚假信息、欺诈等严重的恶意滥用。多人脸处理图像具有显著的伪造和改变一张或多张人脸的语义身份或表达属性的能力,这增加了检测的难度,并给局部篡改区域的定位带来了新的挑战。因此,开发有效的多人脸操作检测和定位方法至关重要。
在最近的发展中,几种方法[7],[9]-[11]已经做出了显著的努力来解决检测多人脸操纵图像的挑战。然而,这些方法主要强调图像级分类,无法在像素级精确定位篡改人脸区域。为了解决多人脸伪造定位,[6]引入了一个名为OpenForensics的开创性多人脸数据集,并利用基于实例分割的管道[12]来解决这些挑战。不幸的是,该数据集完全由伪造数据组成,缺乏相应的真实图像。这导致最近基于该数据集的研究工作[6],[13]仅限于定位被篡改图像中的篡改面部区域,而不适合执行图像级别的真假检测。在现实场景中,图像级检测和像素级定位在分析多人脸伪造数据中起着至关重要的作用。然而,同时解决这两项任务的方法仍未得到充分探索。
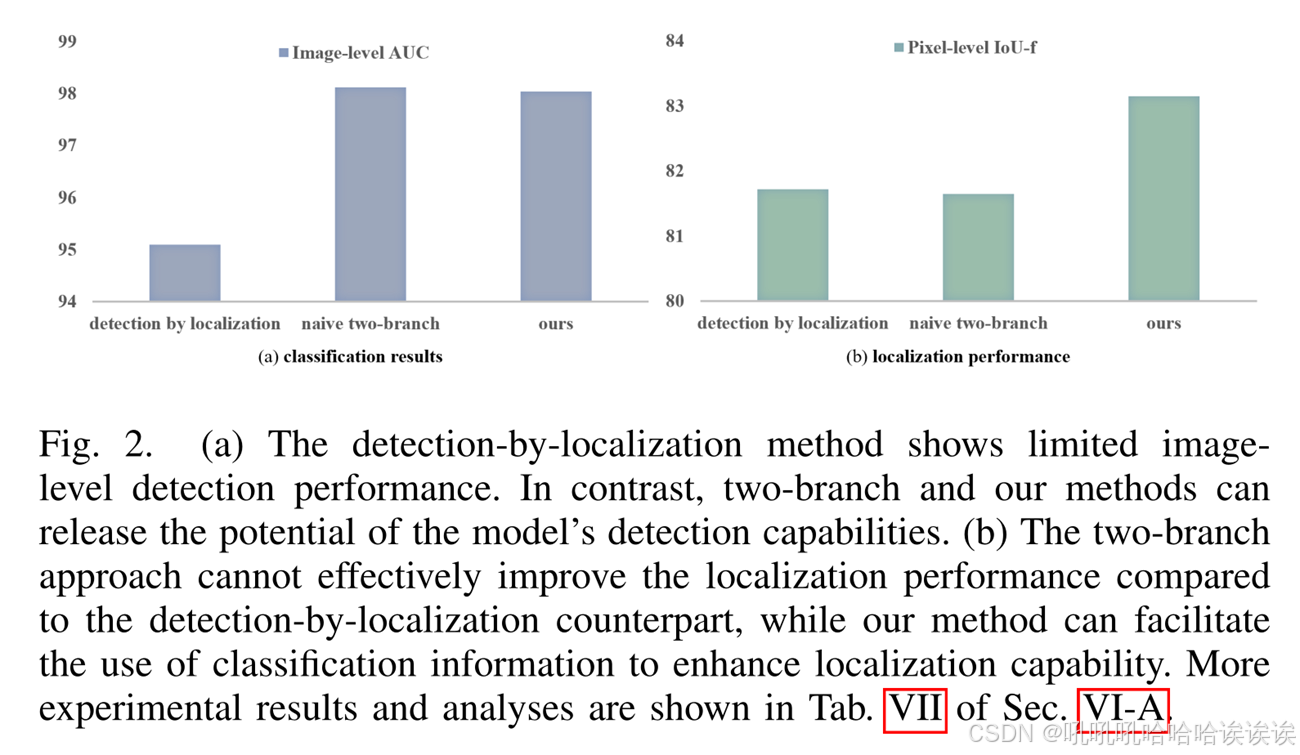
传统的图像取证方法[14]-[17]采用定位检测范式,通过像素级掩码间接获得图像级检测结果(见图1(a))。检测结果严重依赖于定位质量,导致检测性能受限(见图2(a))。最近的一些图像取证方法[18]-[22]利用双分支架构同时获得图像级检测和像素级定位结果(见图1(b)),从而释放了模型检测能力的潜力。然而,由于分类分支和定位分支之间的交互有限,定位能力很难从具有共享主干的单独分类分支和定位分支的设计中获益(见图2(b))。
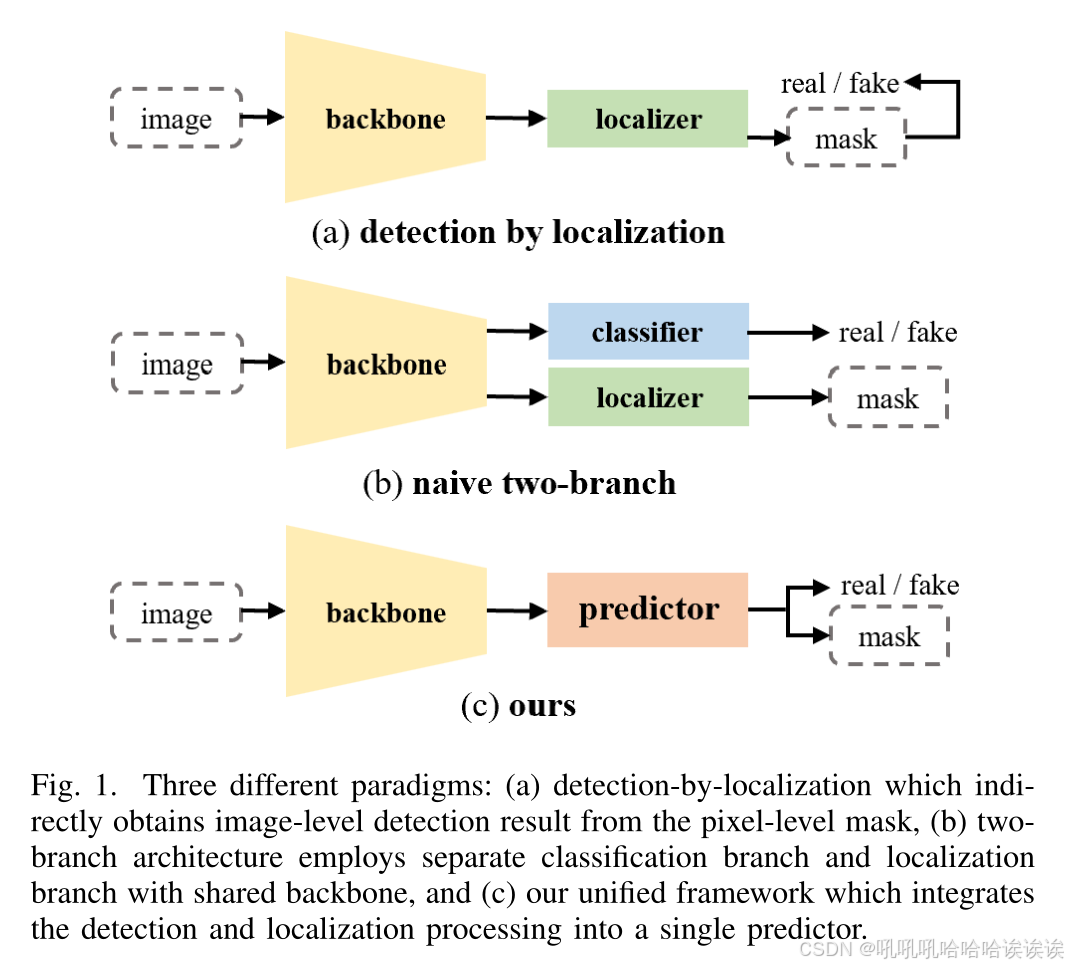
本文提出了一种伪造感知统一预测器(FUP),将像素级定位和图像级分类结果联合预测(见图1(c)),可以有效利用分类信息增强定位能力。具体来说,FUP引入了token学习策略以及多个伪造感知transformer(FAT)模块,在检测和定位任务之间建立了强大的连接。在FAT模块中,我们合并了两个分别表示真实和虚假类别的可学习的tokens。这些tokens以及图像特征通过token自注意和token-image 交叉注意(即,tokens到图像特征,反之亦然)双向更新,有效地编码全局上下文信息。然后,通过监督学习采用直接的图像级分类,真假token增强了它们在伪造图像中捕获和表达关键信息的能力,特别是与被操纵区域有关的信息。该功能显著提高了FAT模块内掩码预测的准确性。此外,我们在FAT模块中实现了伪造感知掩码注意,这大大限制了对假查询token和真实查询token的预测掩码的伪造和非伪造区域的交叉注意。这种创新的方法允许全局真假token专注于微观伪造线索,提高模型对细小操作的敏感性。同时,考虑到局部和细微伪造人脸区域的普遍存在,FUP采用多尺度策略在特征金字塔结构中提取特征。最后,FUP可以通过推理输出标记与图像特征之间的关系,同时产生最终的检测和定位结果集。与之前的工作相比,我们的FUP简化了检测和定位任务管道,并利用了这两个任务的互补信息,特别是提高了定位性能。
此外,考虑到之前的各种噪声提取器[23]-[27]在图像取证和深度伪造检测领域显示出令人印象深刻的结果,我们引入了混合噪声提取器(MoNE)模块,灵感来自mixture-of-experts (MoE)哲学[28],利用不同噪声类型的好处来增强RGB特征的伪造线索模式。MoNE模块采用多种噪声提取器,对普通图像特征提取多样、全面的伪造线索。与独立的噪声提取器不同,我们的MoNE模块试图在训练期间利用具有不同属性的噪声信息的组合。为了自然地适应FUP的架构,我们提出了混合噪声模块(MNM),通过利用多个MoNE模块来处理各种分辨率的特征。随后,每个分辨率的多尺度噪声模式被馈送到FUP的相应FAT层,这有助于模型定位小伪造区域。
同时,由于现有的多人脸相关数据集要么缺乏相应的真实数据[6],要么不适合多人脸检测和定位任务[7],[8],目前多人脸操纵检测和定位领域缺乏完善的多人脸伪造基准。为了弥补这一差距,我们从现有数据集中收集多人脸数据,以策划多人脸操作检测和定位基准数据集,包括不同的现实世界场景,如电影,戏剧,新闻广播,综艺节目和采访。基于整理的数据集,我们构建了综合基准来评估多人脸操作检测和定位方法的泛化和鲁棒性。
总的来说,在这项工作中,我们做出了以下主要贡献:
•我们提出了一个统一的框架,即MoNFAP,用于多人脸操作检测和定位任务,它主要包括两个新颖的模块:伪造感知统一预测器(FUP)模块和混合噪声模块(MNM)。
•提出的FUP使用tokens学习策略和多个伪造感知transformers集成检测和定位任务,这有助于使用分类信息来增强定位能力。
•受MoE概念的启发,所提出的MNM利用多个噪声experts提取器来提取更一般和鲁棒的噪声痕迹,从而增强了FUP的普通图像特征。
•我们构建了全面的多人脸操作检测和定位基准,所提出的方法达到了最先进的性能。
II. RELATED WORK
A. Face Manipulation Detection and Localization
该领域的早期方法利用来自cnn的手工制作的生物线索[29]来区分真实和虚假的面孔。然而,当代方法主要采用数据驱动的方法[27],[30]-[39],直接在真实和虚假图像上训练深度网络。此外,某些技术利用频域[40]-[45]、不一致性[46]或空间模式[47]-[52]机制中的广义伪影来提高人脸伪造检测的整体性能。最近的研究[7],[9]解决了使用多实例学习和视频级别标签的多人脸伪造检测。FITER[10]利用多张脸中的面部关系来增强多人脸伪造检测。然而,这些方法缺乏篡改人脸区域的像素级定位。
先前的FFD[53]使用网络的注意力图进行篡改区域检测,但缺乏全局上下文。其他方法[54]、[55]采用分割分支来定位被操纵区域。现有的全合成假图像定位方法[56]不适合人脸操作数据。最近的方法[6],[13]利用实例分割管道为多人脸操作图像定位篡改和真实的人脸区域,但没有解决图像级别的真假分类问题。MSCCNet[57]通过多谱信息学习语义不可知特征。在本文中,我们提出了MoNFAP,通过同时处理来自输入图像的多个人脸来有效地检测和定位多人脸伪造图像。
B. Manipulation Noise Artifacts
图像编辑和篡改中的低级伪影可以通过噪声提取模块突出显示。这些模块通过抑制语义内容将输入图像从RGB空间转换为语义不可知噪声空间。HFConv[23]引入了可训练的高通滤波器用于图像取证,频域信息在人脸操纵检测中很有效[21],[58]。SRMConv[14],[24]学习边缘和边界特征,而不依赖于预定义的操作伪影,使其适合于噪声敏感分析。BayarConv[25]能够在训练过程中直接学习操纵痕迹,以提取伪造噪声模式,并应用于许多方法中[14],[59]。CDConv[26]利用中心差分算子捕捉人脸操纵检测[27]中的伪造线索和表征。然而,现有方法通常只使用一个或两个噪声提取器,未能充分发挥其潜在优势,导致性能不佳。此外,噪声提取器通常用作数据增强技术或合并在单级特征中,忽略了多级特征和有价值的信息,以提高检测和定位精度。为了提高语义不可知篡改痕迹特征的泛化能力,本文提出了多层集成的混合噪声提取器(MoNE)模块。
C. Image Manipulation Detection and Localization
在图像取证中,集成图像级检测和像素级定位对于现实世界的应用至关重要。
大多数现有方法只关注定位,忽略了图像级分类[23],[60]-[62]。以前的方法通过从定位掩码中提取全局决策统计量来计算分类分数,将定位优先于检测[14],[16],[17],[22]。最近的一些方法通过合并真实数据和使用图像级分类损失来明确地解决检测问题,但它们可能会阻碍高级语义信息的学习,导致分类性能低于标准[59]。其他方法[18]-[22]引入了额外的分类分支,但没有充分探索分类和定位任务之间的特征级交互。在本文中,我们提出了伪造感知统一预测器(FUP),它优化了检测和定位管道,并利用分类信息来提高定位器的性能。
III. METHOD
在本节中,我们首先提供MoNFAP框架的全面概述(第iii - a节)。然后,我们分别介绍了伪造感知统一预测器(第iii - b节)和混合噪声模块(第iii - c节)的详细介绍。最后,我们描述了我们的框架中用于优化模型性能的损失函数(见第iii - d节)。
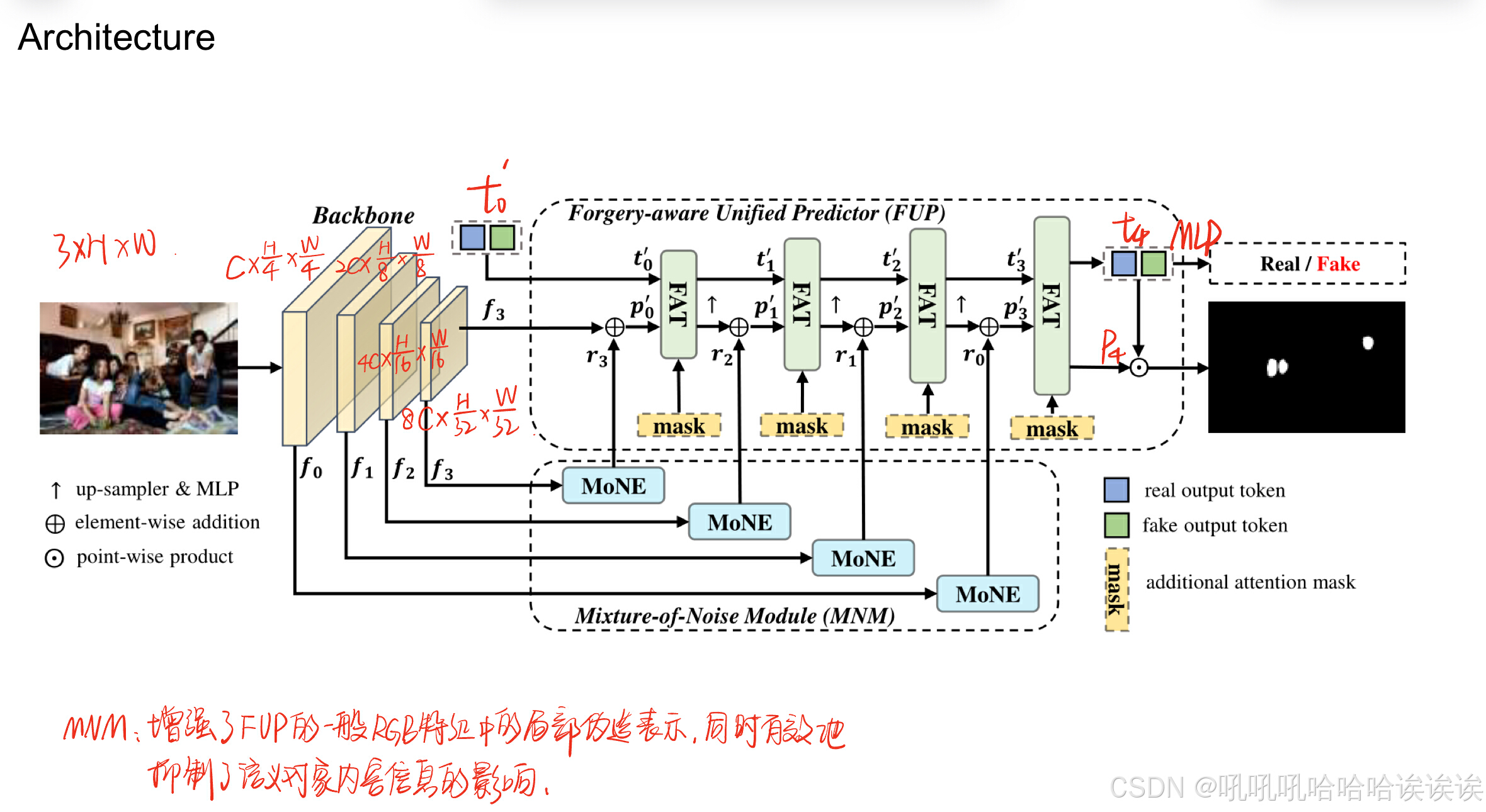

A. Overview
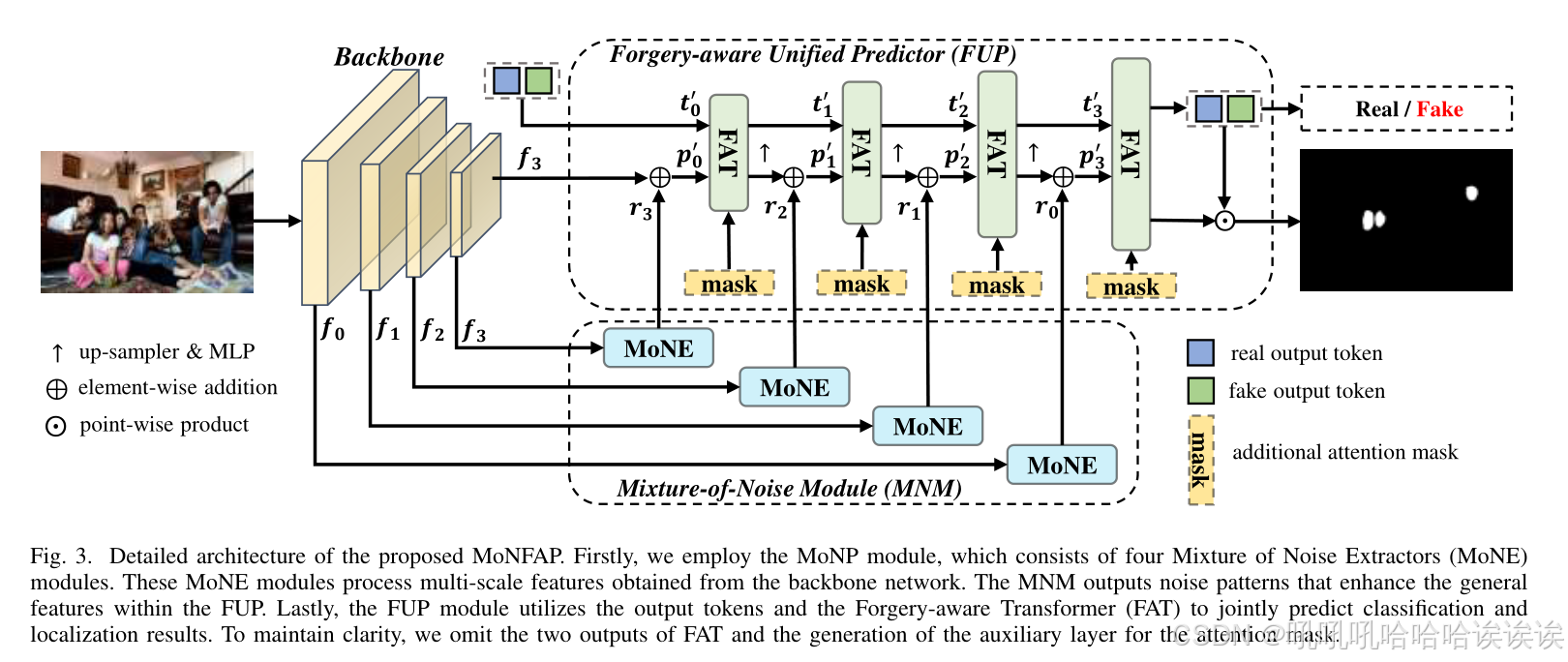
如图3所示,提出的MoNFAP框架包括三个主要组件:骨干网络、混合噪声模块和伪造感知统一预测器。给定输入图像I∈R3×H×W,首先利用骨干网络提取多尺度特征F ={f0 ∈ RC× H/4 × W/4 , f1 ∈ R2C× H/8 × W/8 , f2 ∈ R4C× H/16 × W/16 , f3 ∈R8C× H/32 × W/32 },其中,H ×W为图像分辨率,C为特征通道。在此之后,mixture-of-Noise模块的结构是利用四个不同的混合噪声提取器(MoNE)来处理F,以提取相关的噪声特征,表示为R = {r0, r1, r2, r3}。值得注意的是,R与F共享相同的维度,并且旨在为后续的伪造感知统一预测器充当伪造噪声线索。具体地说,我们的预测器被分为四个阶段,每个阶段都由一个伪造感知transformer(FAT)层组成。对于每个阶段i∈[0,3],过程为:
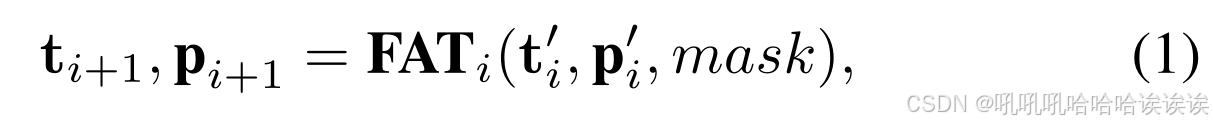
其中ti包含两个可学习的tokens,即真token和假token,t 'i = MLPi(ti), p 'i = UPi(pi)⊕r3 - i, s.t.i.≥1,mask是源自辅助层的粗预测分割掩码。符号⊕表示元素加法运算。MLPi表示用于同步可学习tokens特征通道的全连接层,UPi表示用于同步阶段i图像特征形状的上采样器。在该过程开始时,我们对t ' 0∈R2×8C进行随机初始化,同时设置p ' 0 = f3⊕r3。FATi的体系结构主要包括自注意层和交叉注意层,便于t 'i和p 'i的交互和更新。最后,利用t4和p4分别得到图像级分类结果Y∈R2和像素级定位掩码M∈r2xH/4 × W/4,方法如下:
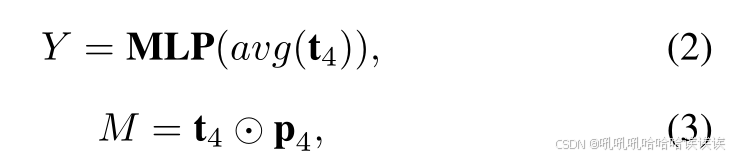
其中avg表示平均池化操作,⊙表示空间逐点积。
B. Forgery-aware Unified Predictor
在本文中,我们提出了一种直接集预测方法,即伪造感知统一预测器(FUP),它包括两个可学习的输出tokens,四个伪造感知transformers(FAT)层和三个上采样层,如图3所示。为了有效地处理小的伪造区域,我们采用了一种多尺度策略,以轮询的方式将不同阶段的连续噪声线索特征(参见第iii - c节)馈送到连续的FAT层,从而允许模型捕获细粒度的伪造细节。连续的FAT层有效地映射图像特征、噪声提示特征和可学习的输出tokens,以生成局部伪造区域掩码和真假分类结果。因此,所提出的FUP演变成一个特征金字塔结构,能够以不同的分辨率处理噪声线索和图像特征。在接下来的章节中,我们将详细解释这些改进。
1) Forgery-Aware Transformer (FAT): 受基于transformer的架构[63],[64]成就的启发,我们发现多人脸伪造图像中的真假类别区域可以表示为对象查询(即真假输出tokens)。因此,我们引入两个可学习的输出tokens,即真实token和假token,数学上表示为t 'i, i∈[0,3]。transformer网络可以处理可学习的tokens和图像特征来预测定位和分类结果。为此,我们提出了伪造感知transformer(FAT)模块,该模块在两个方向(token到图像嵌入,反之亦然)上采用普通自注意、掩码交叉注意和普通交叉注意来处理输出tokens(t 'i)和增强的图像特征(p 'i),如图4(a)所示。经过以上两次操作后,我们再次使用掩码交叉注意,使真假tokens更加关注图像特征。
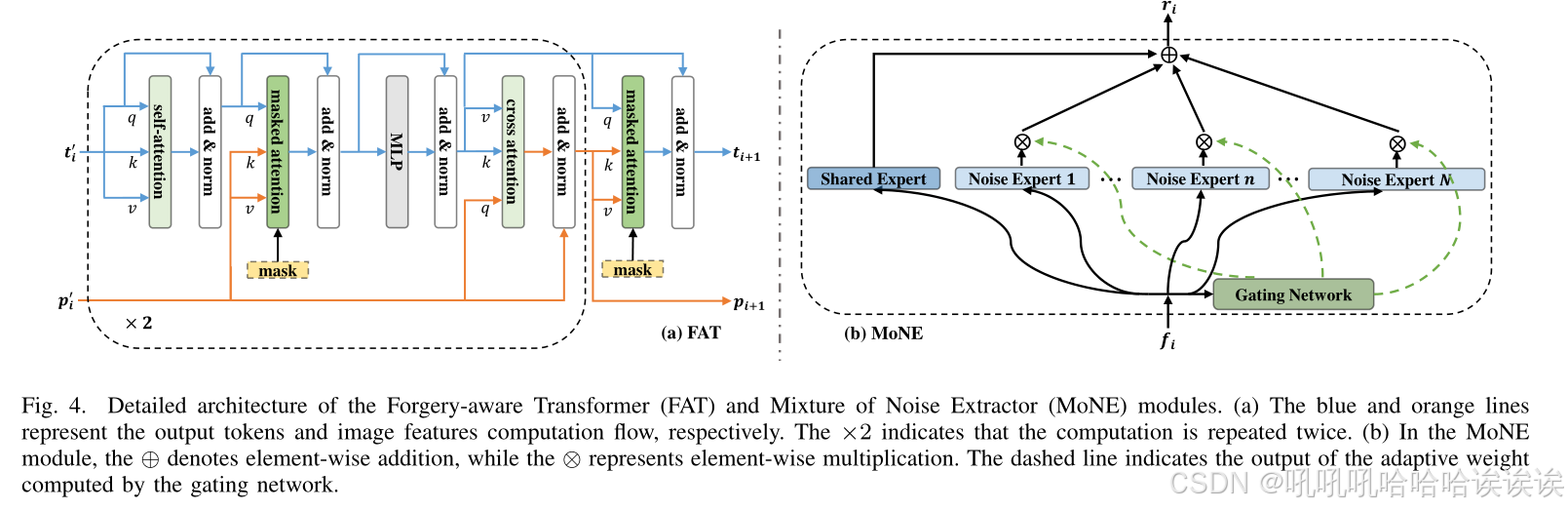
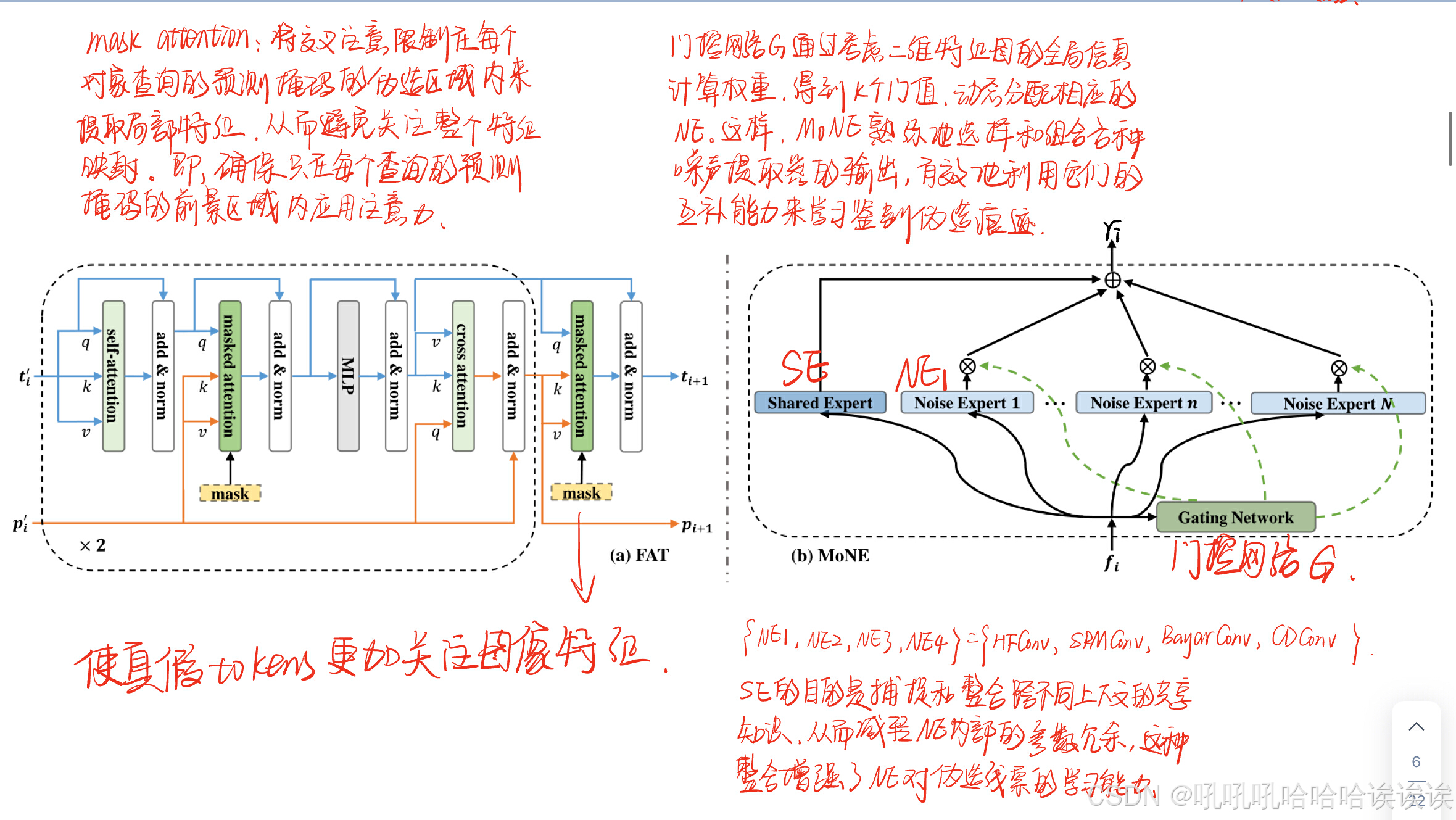
我们的FAT的关键组成部分是一个掩码注意力机制。掩码注意通过将交叉注意限制在每个对象查询的预测掩码的操作区域内来提取局部特征,从而避免了关注整个特征映射的传统做法。具体来说,这种机制确保只在每个查询的预测掩码的前景区域内应用注意力。数学上可以表示为:
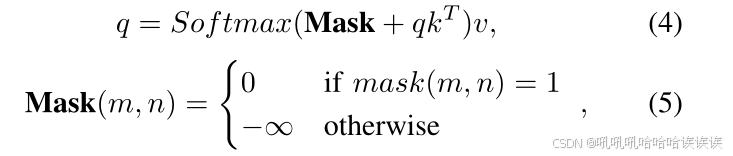
其中q为真假输出tokens,k, v为图像特征。特征位置坐标记为(m, n)。该掩码二值化阈值为0.5,由辅助定位器的预测掩码resize得到。
全局上下文在图像分割任务中起着至关重要的作用[63],[64]。然而,它经常包含大量的语义客观特征,这可能会损害语义不可知性的伪造区域[59],[65]。因此,我们引入了一种掩码交叉注意机制,以增强对transformer模块内局部伪造区域的关注,并减轻背景全局上下文的影响。
2) Multi-scale Strategy (MSS): 在多人脸操纵图像中,伪造人脸所占的区域通常比整幅图像所占的比例要小,这使得局部和细微伪造特征的建模变得非常困难。为了更好地处理小的伪造人脸区域,我们引入了一种多尺度策略来增强RGB图像特征,使用从低到高分辨率的噪声线索。具体来说,我们利用MNM产生的多尺度噪声线索(见第III-C节),其分辨率为原始RGB图像的1/32、1/16、1/8和1/4,作为FUP的输入。不同尺度的噪声线索在FUP中与相应的RGB图像特征一起逐元素添加,以增强伪造线索,如图3所示。在每个尺度上,增强的RGB图像特征和输出tokens由FAT模块更新,以输入到下一阶段。这种多尺度过程确保了输出tokens、噪声线索和RGB图像特征之间有效的信息交换。FUP利用对象之间的成对关系对所有对象进行全局推理,同时增强了伪造检测和定位任务的表示和判别能力。在运行连续多尺度FAT层后,一个线性的MLP将最终的真假输出tokens映射到图像级分类,而最终RGB图像特征和真假输出tokens之间的空间逐点乘积产生像素级掩码。
C. Mixture-of-Noises Module
受到Mixture-of-Experts方法[28]、[66]、[67]在计算效率和表示学习方面所展示的卓越能力的启发,我们引入了一个特制的混合噪声提取器(MoNE)模块。该模块通过综合利用不同的噪声提取器来提取各种伪造线索。为了捕获不同级别特征的噪声模式,我们在MoNFAP框架内的多个阶段无缝集成了MoNE模块(如图3所示)。这种集成导致了混合噪声模块的创建,增强了FUP的一般RGB特征中的局部伪造表示,同时有效地抑制了语义对象内容信息的影响。在下面的小节中,我们将深入研究这些模块的详细体系结构和功能。
1) Preliminaries of the Mixture-of-Experts (MoE): 广泛采用的MoE架构[28]通常用于语言建模和机器翻译任务。它包括N个专业网络的集合,表示为{E1,···,En,···,En},以及一个 softmax gating 网络G。当提供输入x时,基本MoE层产生的输出y可以表示为:

Eq.(6)中的独立专业En是神经网络。门控网络G(x)在softmax之前包含了空域和噪声分量,其中G(x)n是专业En的权值。在式(8)中,H(x)引入了可调高斯噪声。SN()为标准正态分布,softplus为激活函数,Wg和Wnoise为可训练权重矩阵。Wnoise是负载平衡的噪声项。TopK (v, k)只保留v的前k个值,其余设置为−∞,以确保相应的门值为0。
2) Mixture of Noise Extractors (MoNE): 所提出的 Mixture of Noise Experts (MoNE)模块通过利用不同类型的噪声提取器自适应捕获各种伪造痕迹,如图4(b)所示。具体来说,我们将前面提到的噪声提取器HFConv[23]、SRMConv[24]、BayarConv[25]和CDConv[26]分别命名为NE1、NE2、NE3和NE4。在这些提取器的基础上,我们构建了多个噪声专用网络,分别表示为{NE1, NE2, NE3, NE4}。此外,不同的噪声 experts可以获得重叠的知识或信息,从而导致专用网络中的参数冗余和关注点降低[67],[68]。为了解决这个问题,我们以普通卷积层的形式引入了共享expert(SE)。SE的目的是捕获和整合跨不同上下文的共享知识,从而减轻噪声expert内部的参数冗余。这种整合增强了噪声experts对伪造线索的学习能力。因此,提议的MoNE模块可以表述如下:
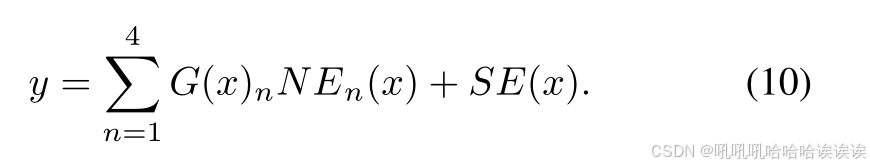
考虑到原始的MoE层主要是为一维序列数据设计的,而不是直接适用于二维图像,我们提出了一种改进方法,将来自输入x的全局信息纳入H(x)函数中。这是通过使用全局平均池化(avg)和线性层(Fg和Fnoise)来实现的。因此,将式(8)的更新形式为:
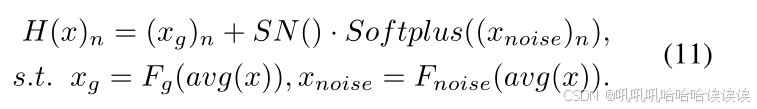
为了使用不同的噪声提取专用网络处理多人脸伪造图像,我们用Eq.(10)和(11)代替Eq.(6)和(8)。门控网络G通过考虑输入二维特征图的全局信息计算权重,得到k个门值,动态分配相应的噪声experts。这样,所提出的MoNE模块熟练地选择和组合各种噪声提取器的输出,有效地利用它们的互补能力来学习鉴别伪造痕迹。在我们的实现中,我们设置k = 4,允许门控网络自适应控制四个噪声experts来处理不同的样本。这使得提取更一般化的伪造模式成为可能。
3) Importance Loss: 在训练过程中,门控网络经常收敛到有偏差状态,始终如一地将大权重分配给一小部分experts[28],[69],[70]。根据[28],我们使用重要性损失项Lim,计算为重要性值的变异系数(CV)的平方乘以缩放因子wim。在数学上,我们有:
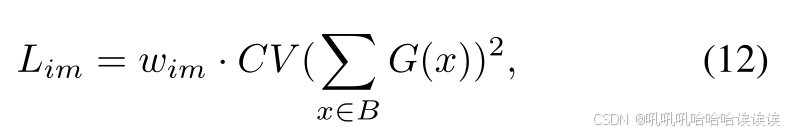
其中B为训练阶段的批大小。这种额外的损失鼓励网络中每个experts做出更平衡的贡献。在多层次线索过程中,总的MoNE损失如下:
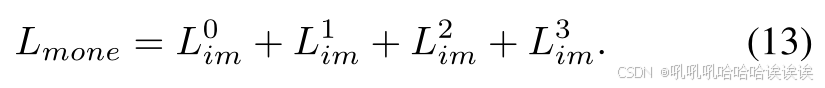
D. Loss Functions
我们首先应用交叉熵(CE)损失函数,表示为Limg,对真实的或被操纵的人脸进行分类。为了解真实和伪造像素类别之间的不平衡,我们提出了一个样本级加权CE函数用于MoNFAP中的定位预测。像素级损失(Lpix)定义如下:
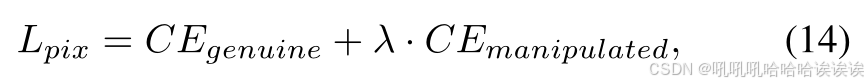
这里,CEgenuine只计算真实样本的CE函数,而CEmanipulated则相反,只计算被操纵样本的CE函数。加权因子λ在样本级上平衡这两个类别的贡献。在我们的实现中,我们设置λ = 10。对于产生掩码注意的辅助定位器,我们用与Laux相同的方式定义损失。
对于MoNE重要性损失(Lmone)在第2节III-C中描述。最后,利用多任务损失函数loss对模型参数进行联合优化:
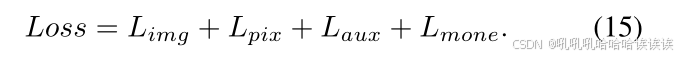
IV. BENCHMARKS
A. Datasets
我们收集新的多人脸数据,并从已有的数据集中选择多人脸图像,如表1和图5所示。
1) OFV2: OpenForensics[6]支持多人脸伪造分割,为伪造区域提供详细的像素级注释。它包括由GAN模型[4][5]生成的44,122张训练图像,7,308张验证图像和18,895张test-development图像,然后进行复杂的后处理。虽然它包含了多种高分辨率的多人脸图像,但它也有一个局限性:它只包含了经过处理的图像,而没有对应的真实图像,这使得它不适合图像级的真假分类。为了解决这个问题,我们从Open images[71]数据集中收集真实图像,手动过滤掉噪声样本以创建新的多人脸操作数据集OpenForensics-V2 (OFV2),如图5所示。
2) FFIW: FFIW[7]包括使用三种深度伪造方法[1]-[3]的视频级人脸操作,提供像素级注释。每个伪造的视频都与真实的视频配对,数据集被分为训练(16000个视频)、验证(500个视频)和测试(3500个视频)集。然而,只有一些视频样本包含多人脸操作。为了解决这个问题,我们过滤视频来识别每帧的人脸数,每隔一定时间采样10帧(至少有两个人脸)。这个过程创建了一个新的多人脸伪造图像数据集,该数据集来源于FFIW(见图5)。
3) Manual-Fake: Manual-Fake[8]由5种deepfake方法生成的1000个原始视频和1000个假视频组成。考虑到在线社交网络对传播Deepfake视频的影响,它包括通过Facebook、WhatsApp、TikTok、youttube和微信等主要平台传播的版本。由于它与FFIW有相同的问题,我们应用相同的处理和采样方法来创建一个新的多人脸伪造图像数据集(见图5)。由于其osn传输的内容,Manual-Fake可以作为一个未见过的测试集,增强其对真实场景的表示。

B. Baseline Models
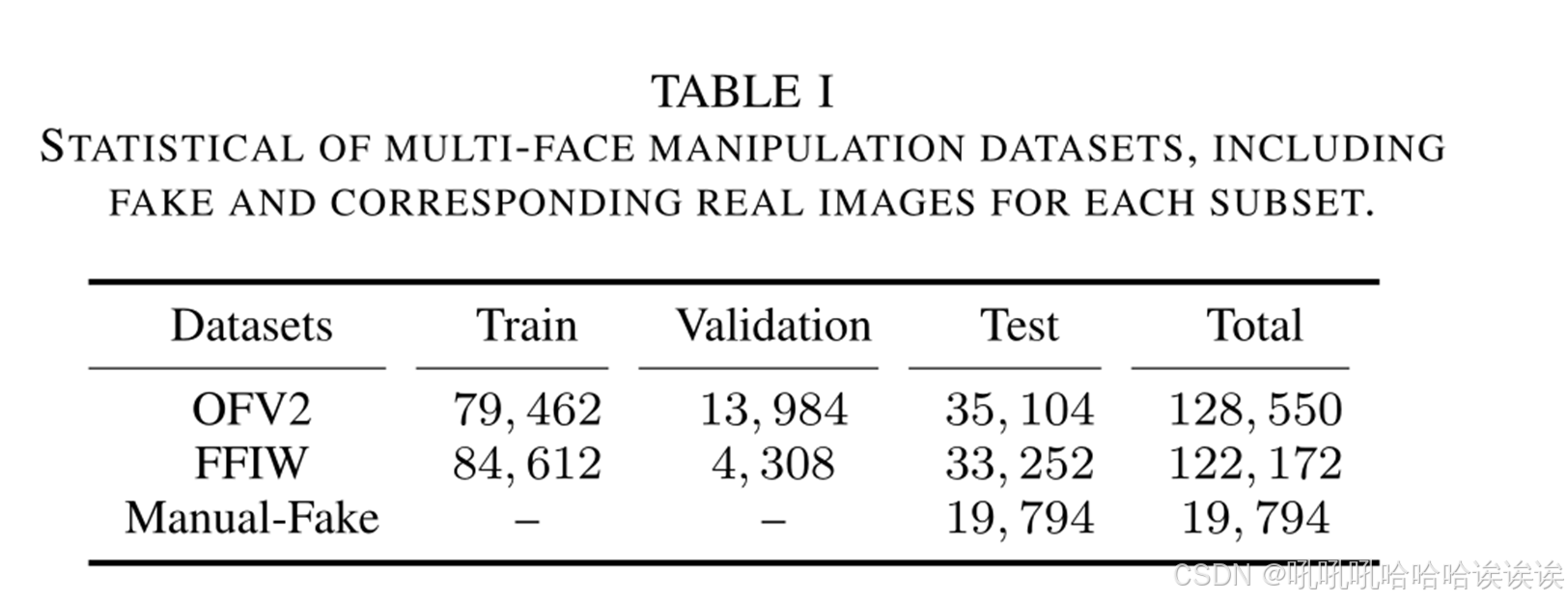
我们对多人脸操作检测和定位进行了全面的基准测试,评估了不同场景下各种最先进的(SOTA)方法。我们的基准包括定量和定性评估,以进行严格和可重复的比较。为了确保公平,我们整理了大量公开可用的源代码方法,分为两种类型:1)定位检测:HPFCN [23], ManTra-Net[14]和MVSS[59]。2)双分支网络:CATNet[72]、DOA-GAN[20]、HiFi-Net[19]。
C. Evaluation Protocols and Metrics
1) Evaluation Protocols: 为了全面评估多人脸伪造检测和定位方法,我们建立了三种评估协议:a)数据集内:在OFV2和FFIW数据集上训练和测试模型。b)跨数据集:模型在OFV2和FFIW上进行训练,并在未见的Manual-Fake数据集上进行测试,评估对不同面部操作方法和数据源的泛化。c)真实世界扰动:我们在OFV2和FFIW的测试集中引入各种扰动来模拟真实世界的场景,分为五个部分:颜色、边缘、图像损坏、卷积掩码变换和外部影响。这些扰动随机组合并应用于增强测试图像,如下[6]。
2) Evaluation Metrics: 对于多人脸操作检测评估,我们报告了准确度(ACC)和曲线下面积(AUC)。为了评估定位性能,我们专门为伪造样本的假类别计算F1-score (F1)和Intersection over Union (IoU),分别表示为F1-f和IoU-f。
D. Implementation Details
我们使用ConvNeXtV2-atto[73]和ResNet-50[74]作为骨干网络,分别称为MoNFAP-C和MoNFAP-R。所有MoNFAP模型都使用AdamW优化器进行训练,初始学习率为0.00006,beta为(0.9,0.999),权重衰减为0.01,使用“poly”学习率策略:(1 - iter/ totaliter)^0.9。输入图像的大小调整为512×512像素。对于其他基准方法,除非另有说明,否则我们遵循原始训练协议。随机水平翻转是训练期间使用的唯一数据增强,PyTorch 2.0.1的同步批处理归一化用于多gpu训练。
V. COMPARISON EXPERIMENTS
A. Intra-datasets Evaluation
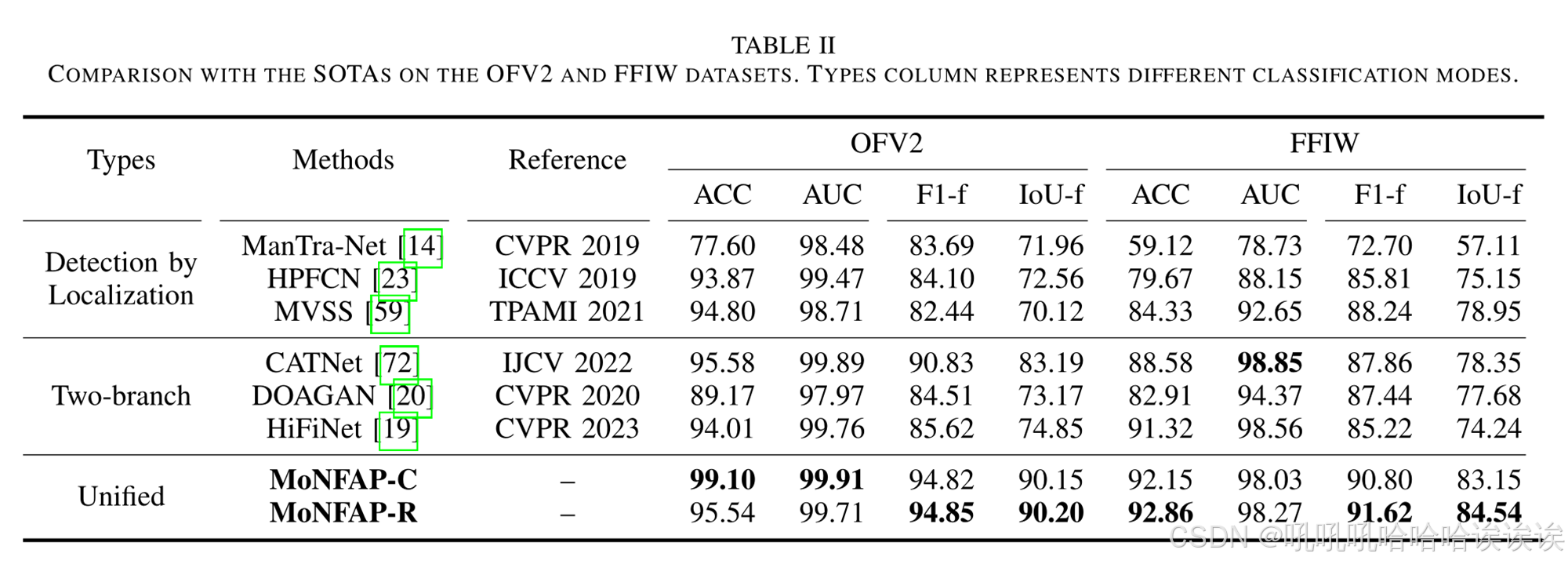
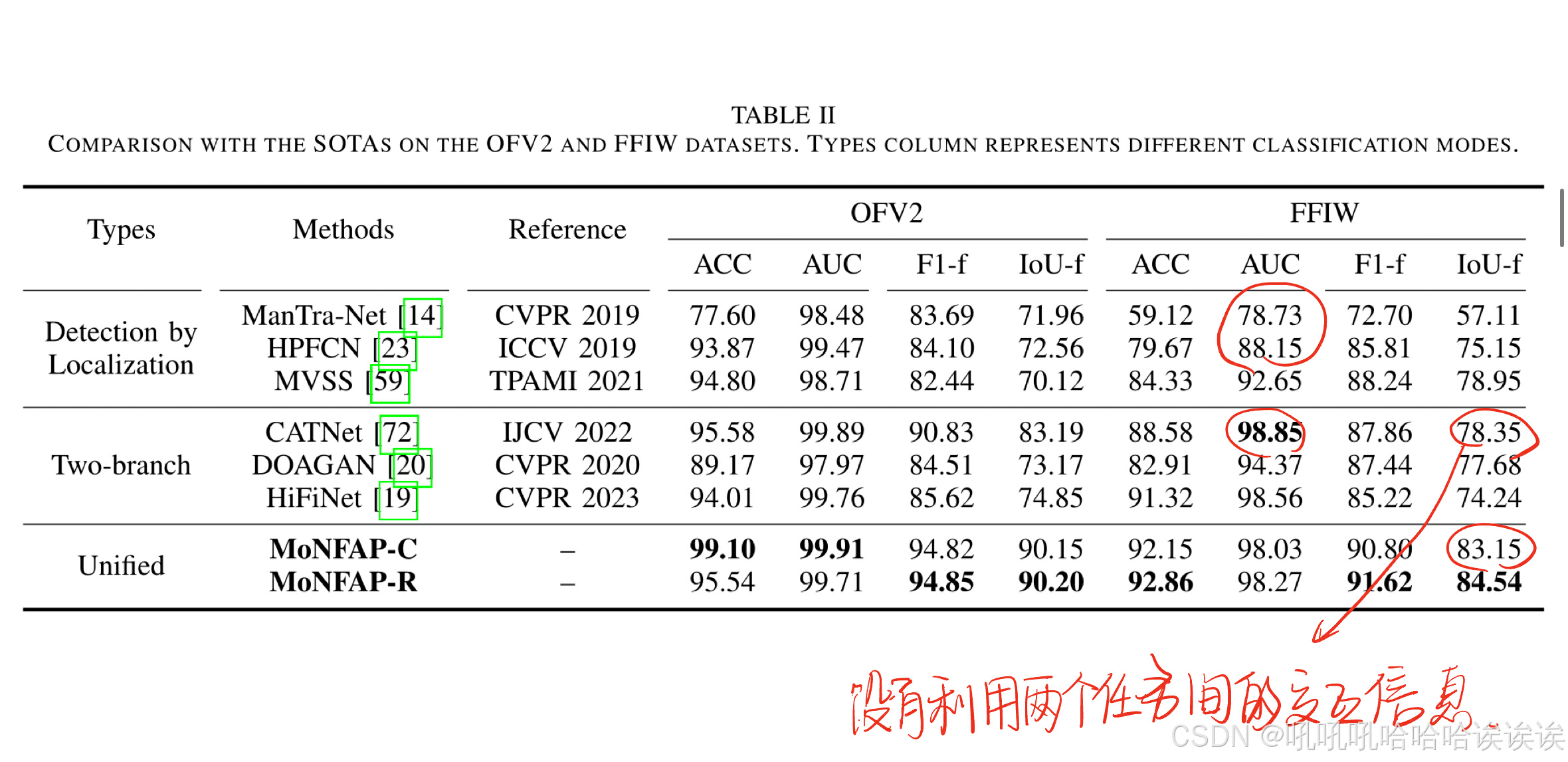
我们首先评估了基准方法在FFIW和OFV2数据集上的检测和定位性能,这是一个与现实世界场景相一致的重大挑战,在之前的文献中没有广泛探讨过。在表2中,HPFCN[23]和ManTra-Net[14]在图像级分类方面表现不佳,特别是在FFIW数据集上的AUC度量方面。这是由于图像级结果是定位任务的副产品,缺乏相应的设计优化。相反,MVSS[59]结合了额外的图像级损失监督,增强了图像级分类性能。双分支方法[19],[20],[72]提高了图像分类性能,但在定位方面的收益有限。例如,在FFIW数据集上,CATNet[72]在主干更大的情况下实现了98.85%的分类AUC,但其定位性能(IOU -f)比我们的轻量级MoNFAP-C低4.8%。这种差异源于它没有利用两个任务之间的交互信息。我们的MoNFAP框架利用token学习策略同时产生分类和定位结果,将分类信息充分集成到定位器中,提高了定位性能。
B. Generalization to Cross-datasets
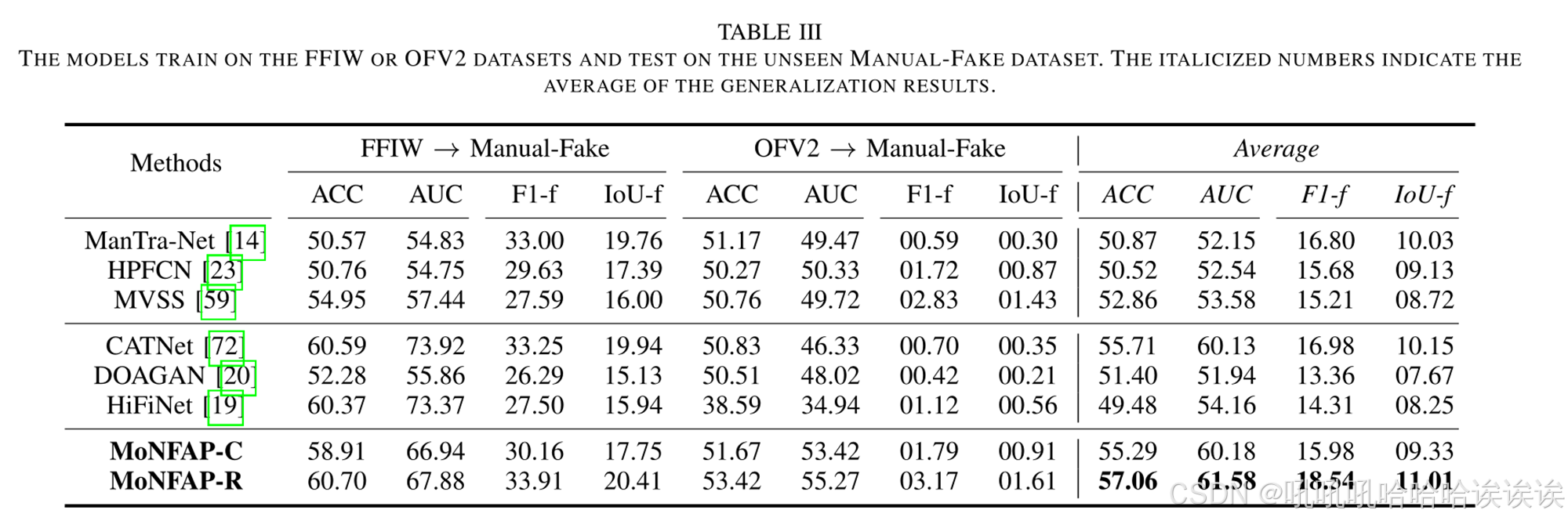
我们通过跨数据集实验来评估模型的泛化能力,即在FFIW或OFV2数据集上进行训练,并在未见过的Manual-Fake数据集上进行测试。不可见的数据集意味着使用基于未知源数据的匿名伪造方法,这为评估模型性能提供了一个具有挑战性的场景。表3展示了这些跨数据集实验的结果,为模型推广到不可见的数据分布和伪造技术的能力提供了有价值的见解。所有方法的性能都明显下降。模型的泛化能力随训练集的不同而不同。例如,当模型在OFV2数据集上进行训练时,它在未见过的Manual-Fake数据集上进行测试时表现不佳。这表明OFV2和Manual-Fake数据集之间存在显著的分布差异。具体来说,Manual-Fake数据集主要由新闻广播场景组成,而OFV2数据集几乎不包含这种性质的数据。因此,未知数据仍然是多人脸操作定位方法面临的重大挑战。我们的MoNFAP优于其他最先进的方法,特别是在平均定位性能方面,这归功于特别设计的FUP和MNM模块。
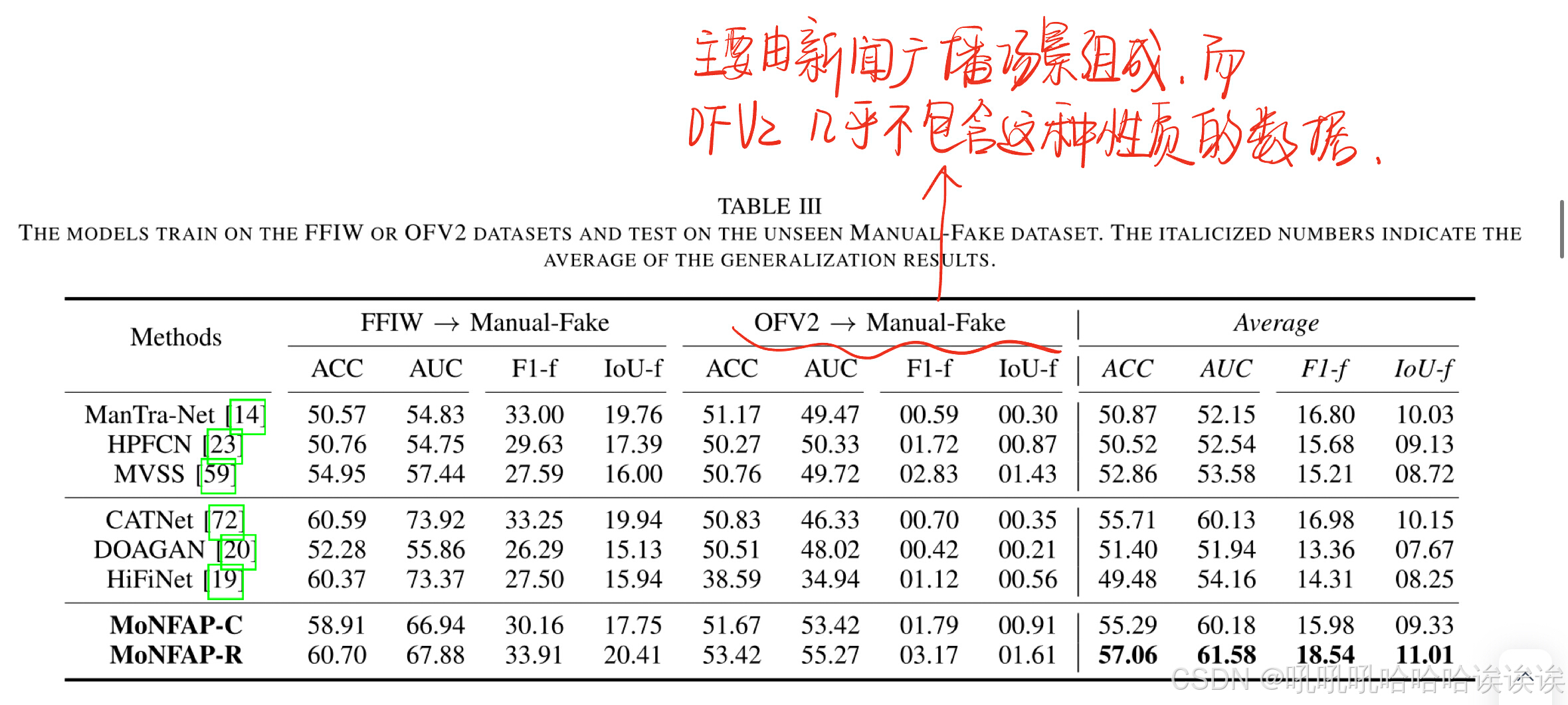
C. Robustness to Real-world Perturbations
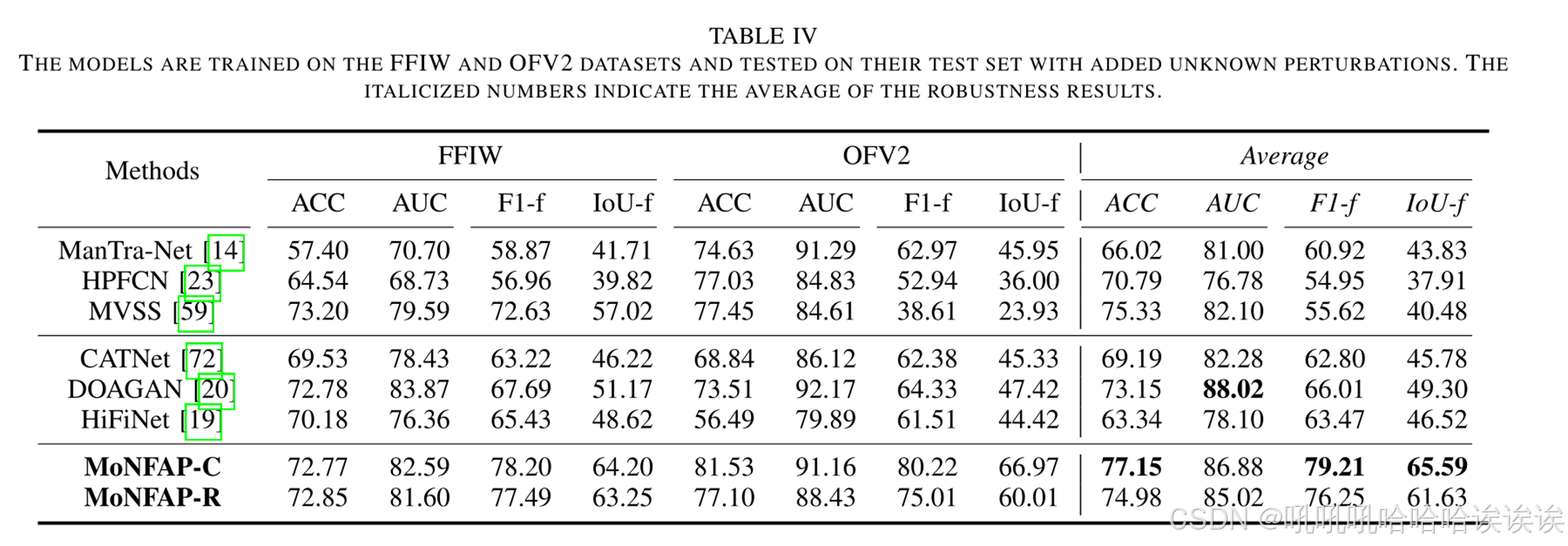
在现实世界中,被操纵的图像的存在引入了各种扰动,破坏了操纵痕迹,增加了检测和定位的难度。为了评估模型的鲁棒性,我们在OFV2和FFIW数据集的测试集上引入了一系列噪声和模糊操作,模拟了现实世界的环境。在表4中评估的方法中,许多方法在看不见的扰动数据上表现出最显著的定位性能下降。在检测的AUC性能方面,我们的方法优于基于定位的检测(detection by Localization)类别[14]、[23]、[59]中的模型,并取得了与Two-Branch类别[19]、[20]、[72]相当的结果。然而,我们的MoNFAP在定位性能上明显超过了现有的最先进的方法。这一改进归功于我们的方法创新地结合了MoE概念来学习多尺度混合噪声线索,从而增强了模型在定位任务中的鲁棒性。
D. Visualization Experiment
如图6所示,我们将FFIW和OFV2数据集上的定位预测掩码可视化。FFIW列中的样本从FFIW数据集的测试集中随机抽取,模型在FFIW训练集上进行训练。这同样适用于OFV2列。不同方法的可视化结果表明,我们的MoNFAP方法能够更好地识别多个伪造人脸和较小的篡改区域,而其他方法的性能较差。例如,HiFiNet[19]不仅预测了伪造的面部区域,而且错误地定位了真实的面部特征,这表明HiFiNet在没有学习伪造线索的情况下过度拟合了面部特征。
为了证明模型的泛化能力,我们将未见的ManualFake数据集上的定位预测结果可视化,如图6所示。值得注意的是,该模型是在FFIW数据集上训练的,并且仅在看不见的Manual-Fake数据集上进行测试。可视化结果表明,该方法对未知数据具有一定的定位能力,但对于较小的目标伪造区域,还需要进一步改进。

E. Extend Experiment
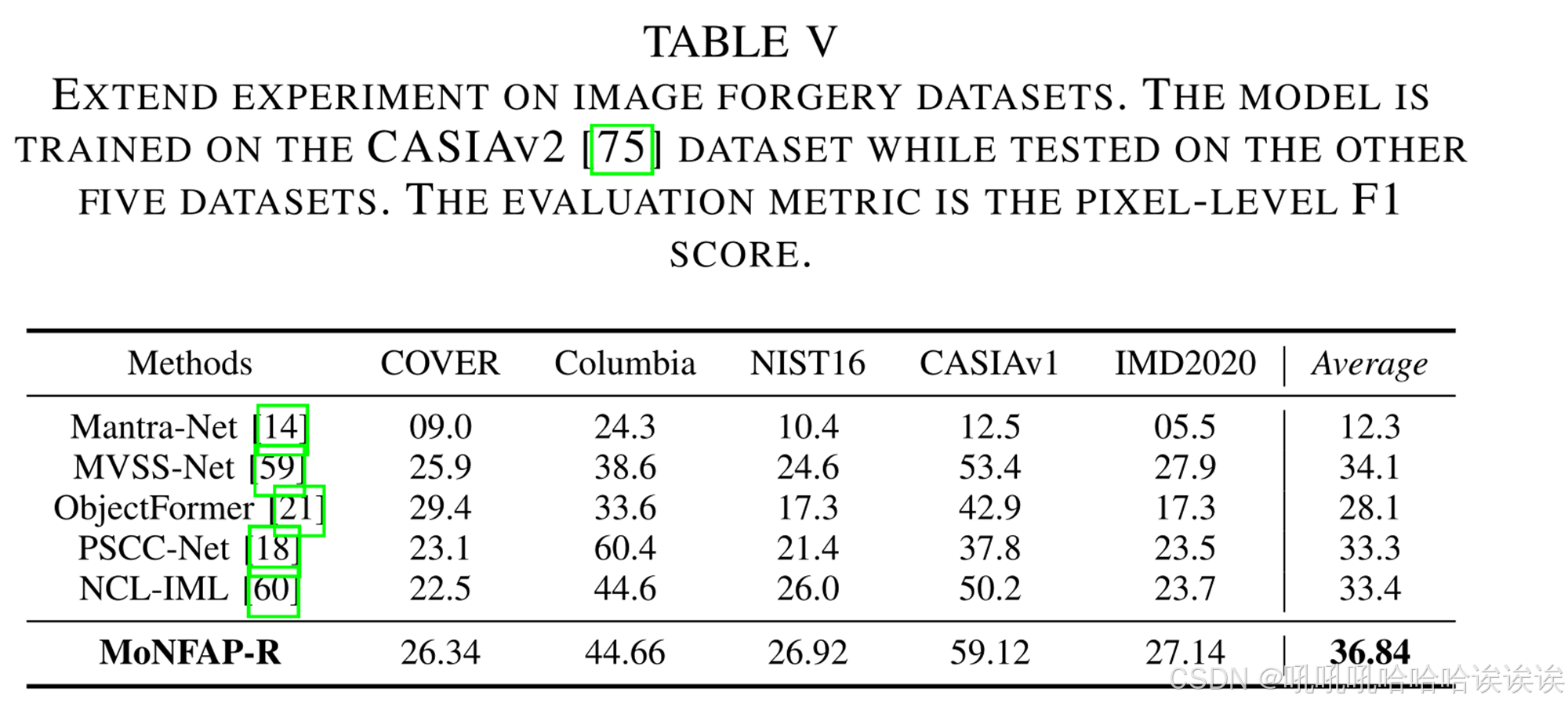
为了进一步验证我们方法的有效性,我们根据[76]在图像伪造数据集上进行了实验。通常,模型在CASIAv2[75]数据集上进行训练,并在CASIAv1[77]、COVER[78]、IMD2020[79]、NIST16[80]和Columbia[81]等5个未见过的测试数据集上进行测试。如表5所示,其他方法的定位结果来源于[76],评估指标仅关注伪造图像的像素级F1分数。结果表明,我们的MoNFAP在所有五个未见过的数据集上都明显优于其他传统的图像篡改定位方法,展示了我们的模型对传统手工图像编辑技术的适用性。
VI. ABLATION STUDIES
为了节省资源和加快训练速度,我们选择轻量级的ConvNeXtV2-atto[73]作为骨干网络,模型在FFIW[7]数据集上进行训练和测试,以图像级ACC和AUC以及像素级F1-f和 IOU-f 作为评价指标。
A. Analysis on the MoNF AP
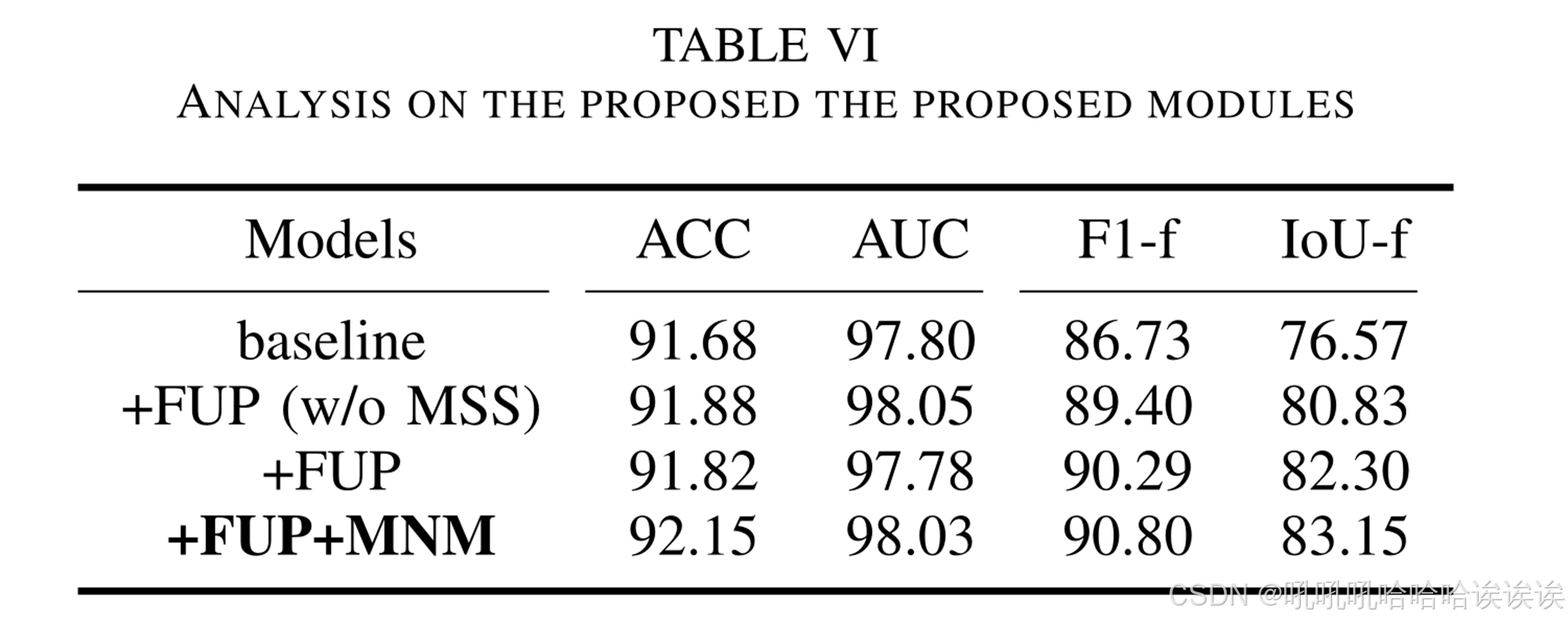
1) Impact of the Proposed Modules: 表6展示了我们对MoNFAP中不同模块的实验分析。“baseline”是指使用ConvNeXtV2-atto[73]作为骨干网的FCN方法。‘ +FUP (w/o MSS) ’表示只有FUP模块而没有多尺度策略的基线模型。‘ +FUP ’表示同时具有FUP模块和多尺度策略的基线模型。‘+FUP+MNM ’表示最终提出的MoNFAP框架。与基线模型相比,FUP模块和多尺度策略提高了性能,特别是在定位能力方面。此外,MNM提高了分类和定位性能,证明了混合噪声线索的有效性。
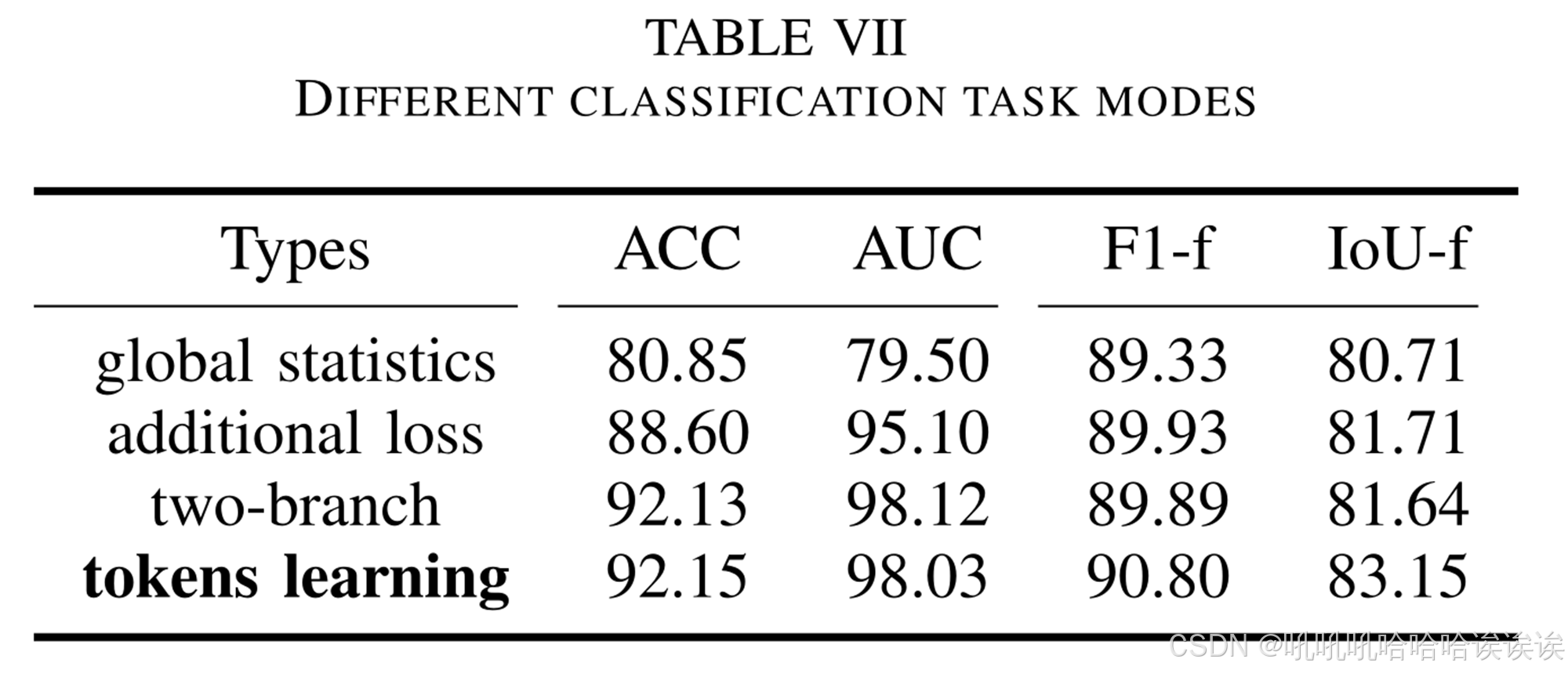
2) Task Mode: 表7说明了四种不同的分类任务模式,构建这些模式是为了公平地评价它们的特点。“global statistics”是指在不存在分类损失的情况下,从FUP预测的定位掩码中选择最大值得到的分类结果。“additional loss”表示在训练过程中,增加了基于FUP预测的定位掩码最大值的图像级分类损失监督,测试过程与“global statistics”相同。以上两种模式统称为“detection by
localization”,如图1(a)所示。“two-branch”表示在FUP之外应用独立的分类分支,分类结果中不考虑FUP中的输出tokens。结果表明,由于分类监督的作用,“additional loss”的分类性能优于“global statistics”。虽然“two branch”取得了很好的分类结果,但由于两个任务之间缺乏交互,导致定位性能没有提高。我们的“token learning”显示出与“two-branch”相似的分类性能,但我们的定位性能在IoU-f方面超过了它1.51%。这表明我们的方法有效地提高了定位器的能力。
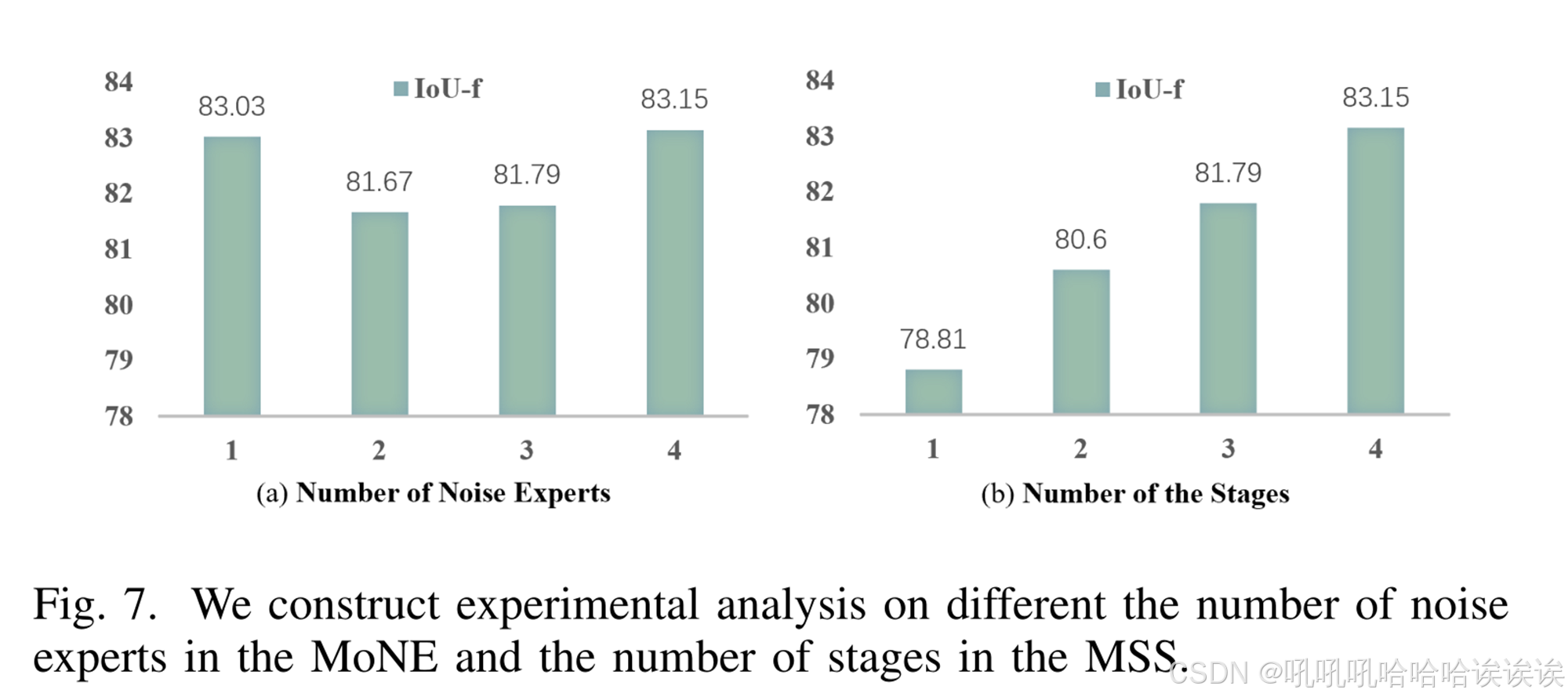
3) Number of Feature Scales: 如图7(b)所示,我们使用不同数量的特征尺度进行实验。从实验结果可以看出,使用4个尺度时性能最优,说明多尺度特征有助于提高模型的定位能力。
B. Analysis on the MoNE
1) Number of Noise Experts: 我们比较了不同的变体,以找到最佳的噪声提取器数量,如图7(a)所示。我们观察到,具有4种不同噪声提取器的变体在定位性能方面优于其他变体。由于门控网络的权重分配优势,4种不同的噪声提取器以最优的方式处理一批不同的样本来模拟伪造线索。其他数量的变体学习的特征不够全面和通用,导致性能较差。
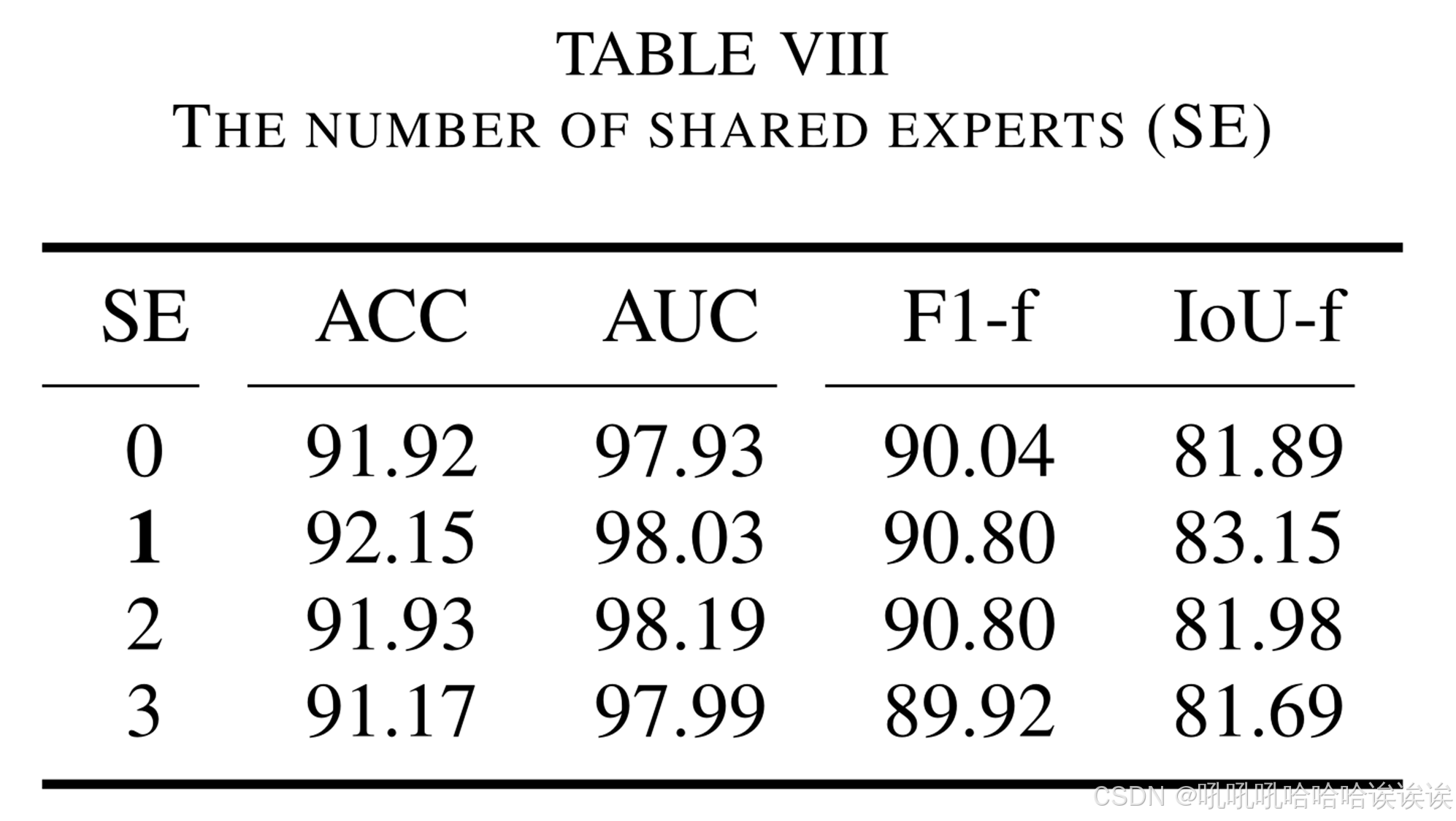
2) Number of Shared Experts: 共享experts可以学习冗余知识,减轻不同噪声experts的学习负担。如表8所示,一个共享的expert是最优的。当值为“0”时,表示没有共享experts,导致噪声experts之间的知识冗余,性能较差。另一方面,experts数量过多导致参数增加,优化难度加大。
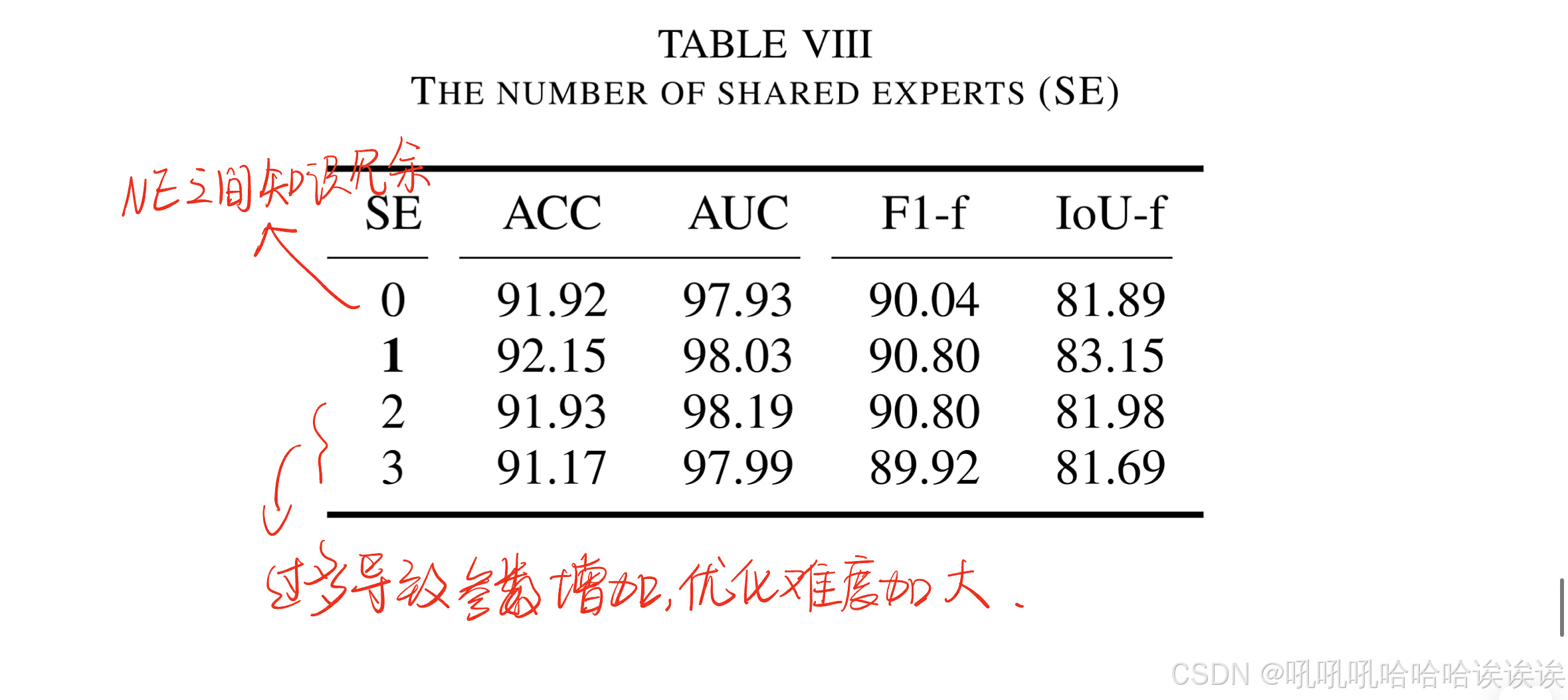
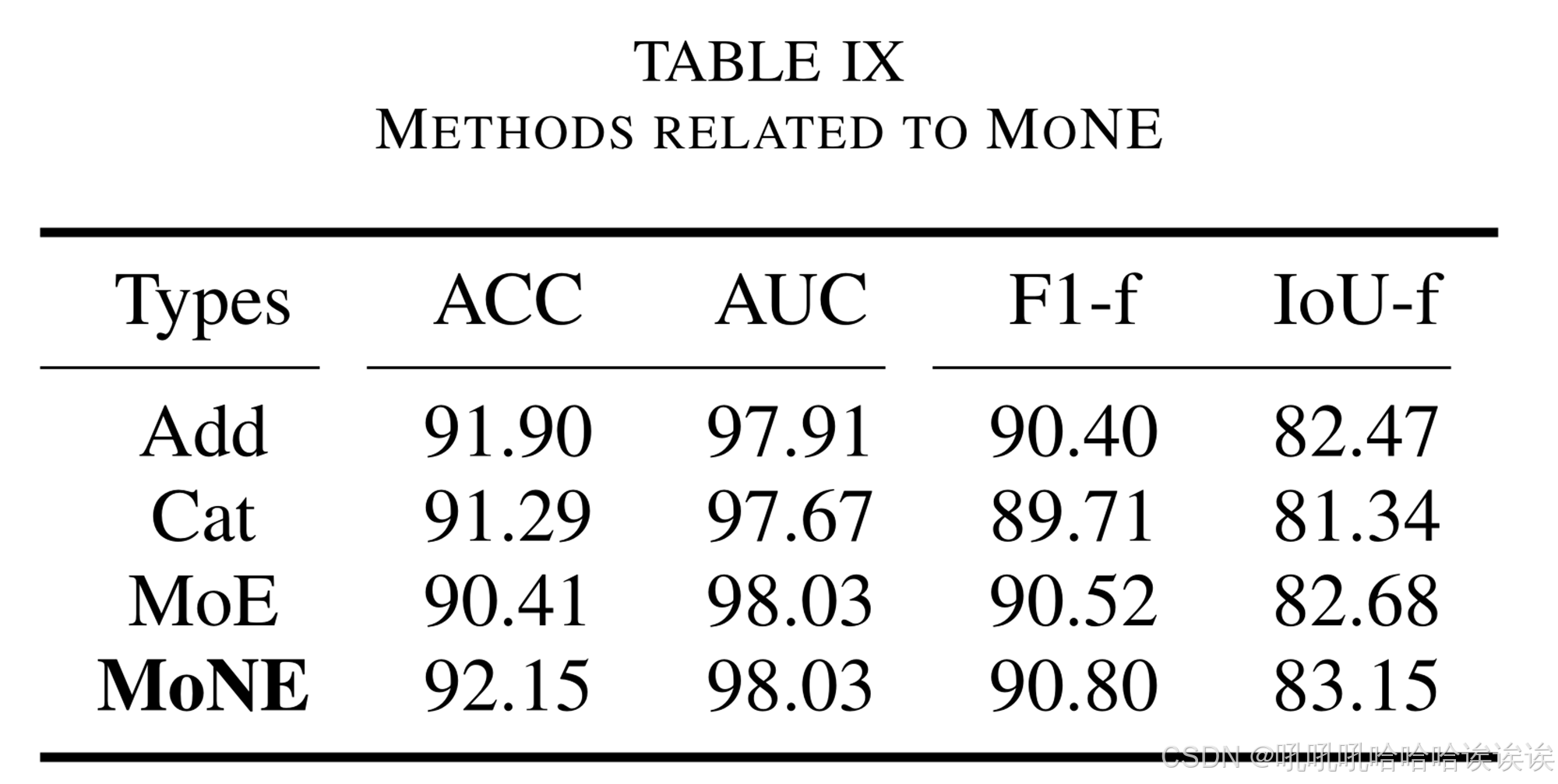
3) Analysis of Structure Similar to MoNE: 如表9所示,为了证明MoNE的优势,我们进行了类似结构的消融实验。“Add”表示四种不同噪声的元素相加,“Cat”表示四种不同噪声沿通道维度的拼接,“MoE”表示原始混合expert结构。我们的MoNE为不同的噪声experts分配自适应权重,以处理不同的样本,整合各自的优势,优于其他方法。
C. Analysis on Importance Loss Function
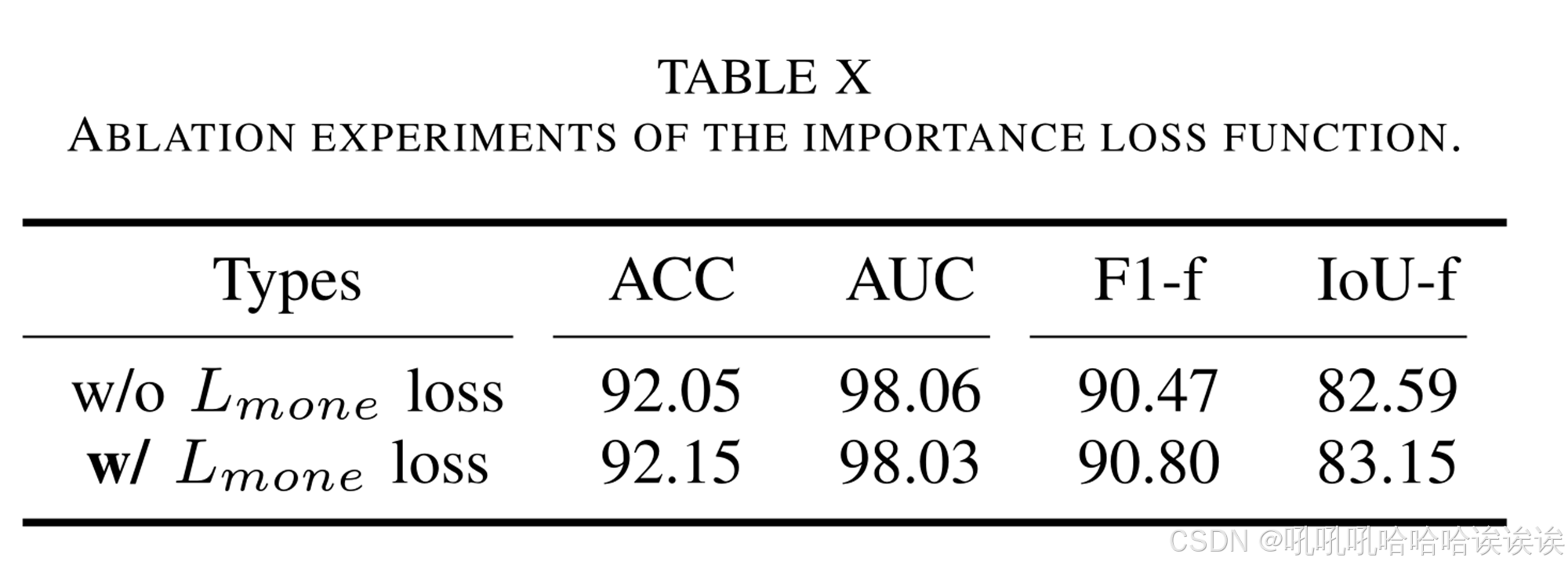
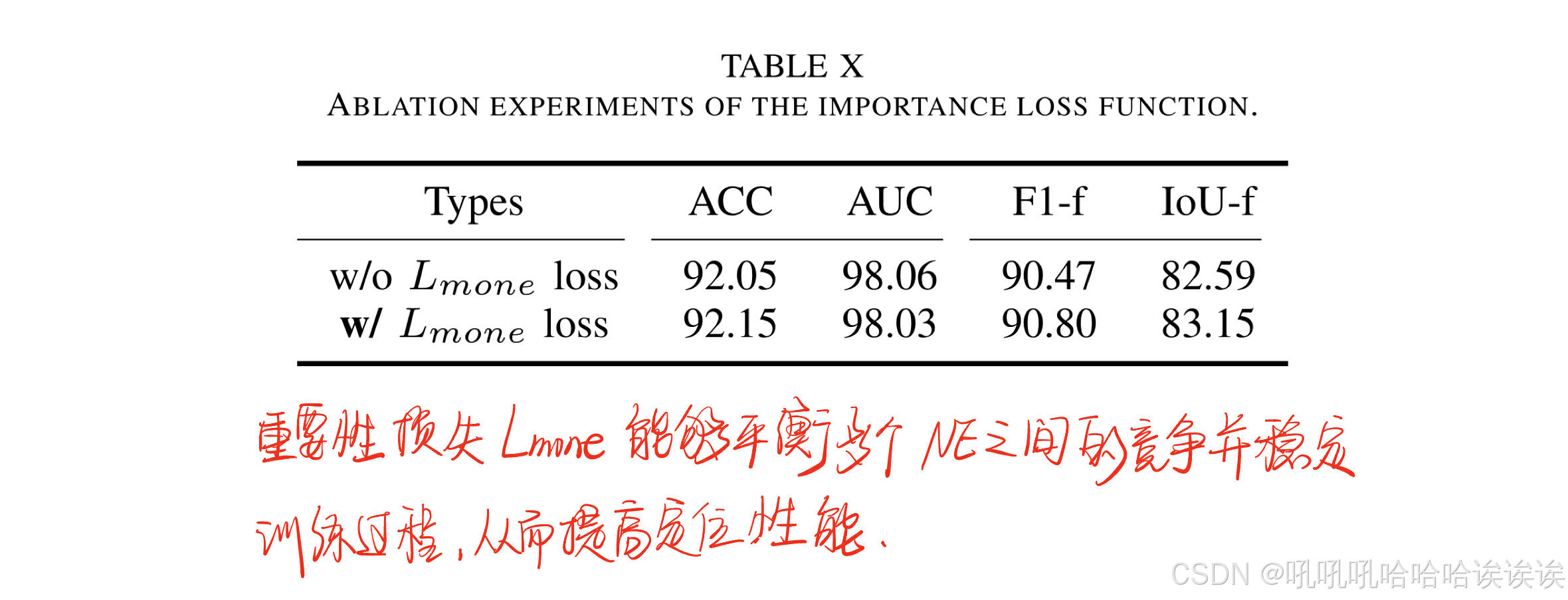
如表10所示,“w/o Lmone loss”表示不存在重要性损失,而“w/ Lmone loss”表示相反。结果表明,Lmone损失能够平衡多个噪声experts之间的竞争并稳定训练过程,从而提高了定位性能。
D. Analysis on Weighting Factor λ
在Eq.(15)中,使用加权因子λ来调整真假样本的定位损失的不同权重,其中λ = 1表示真假样本的定位损失权重相等,λ大于1表示假样本的定位损失权重较大。如表11所示,λ = 10时性能最优,因此我们将其作为其他实验的参数。
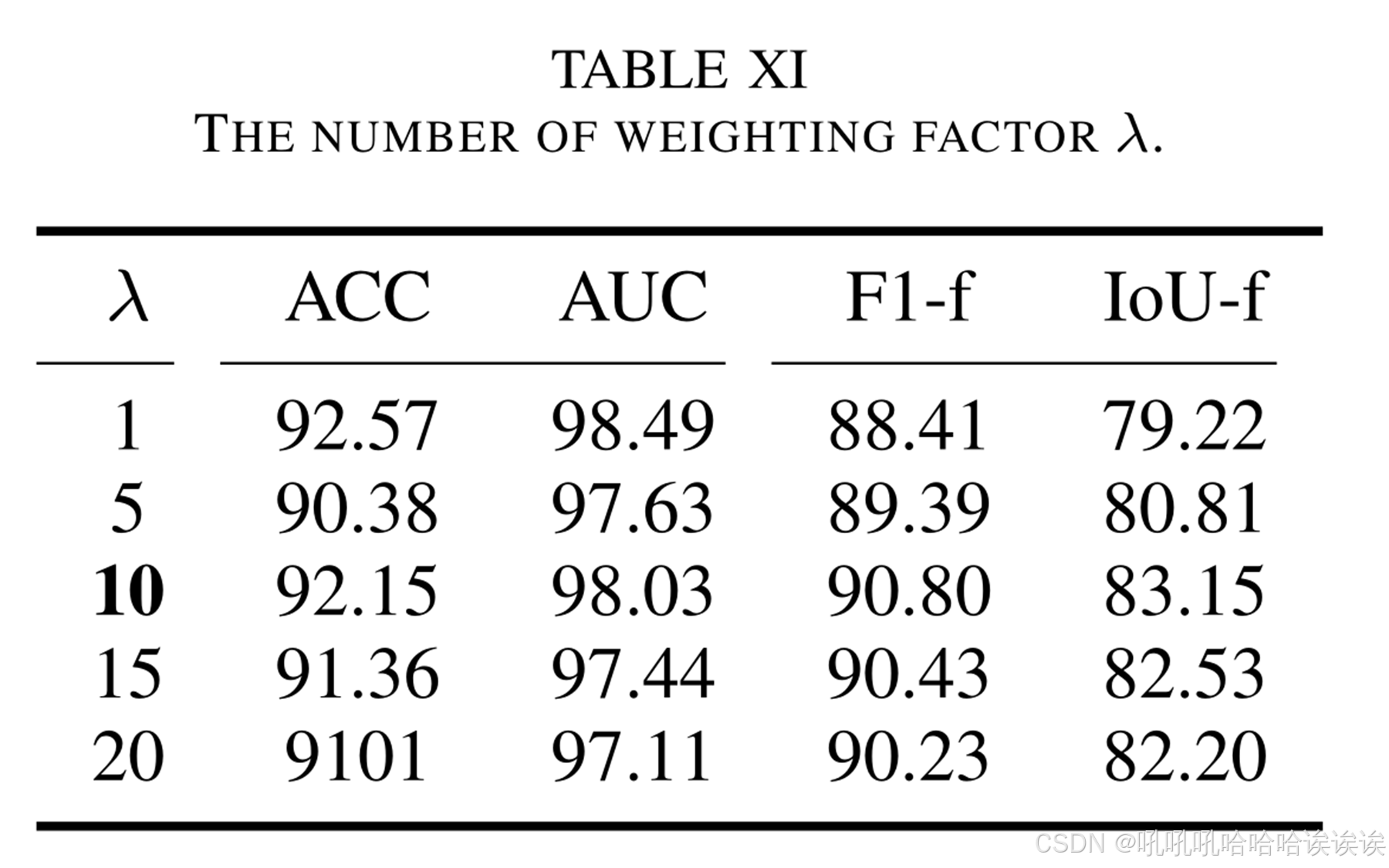
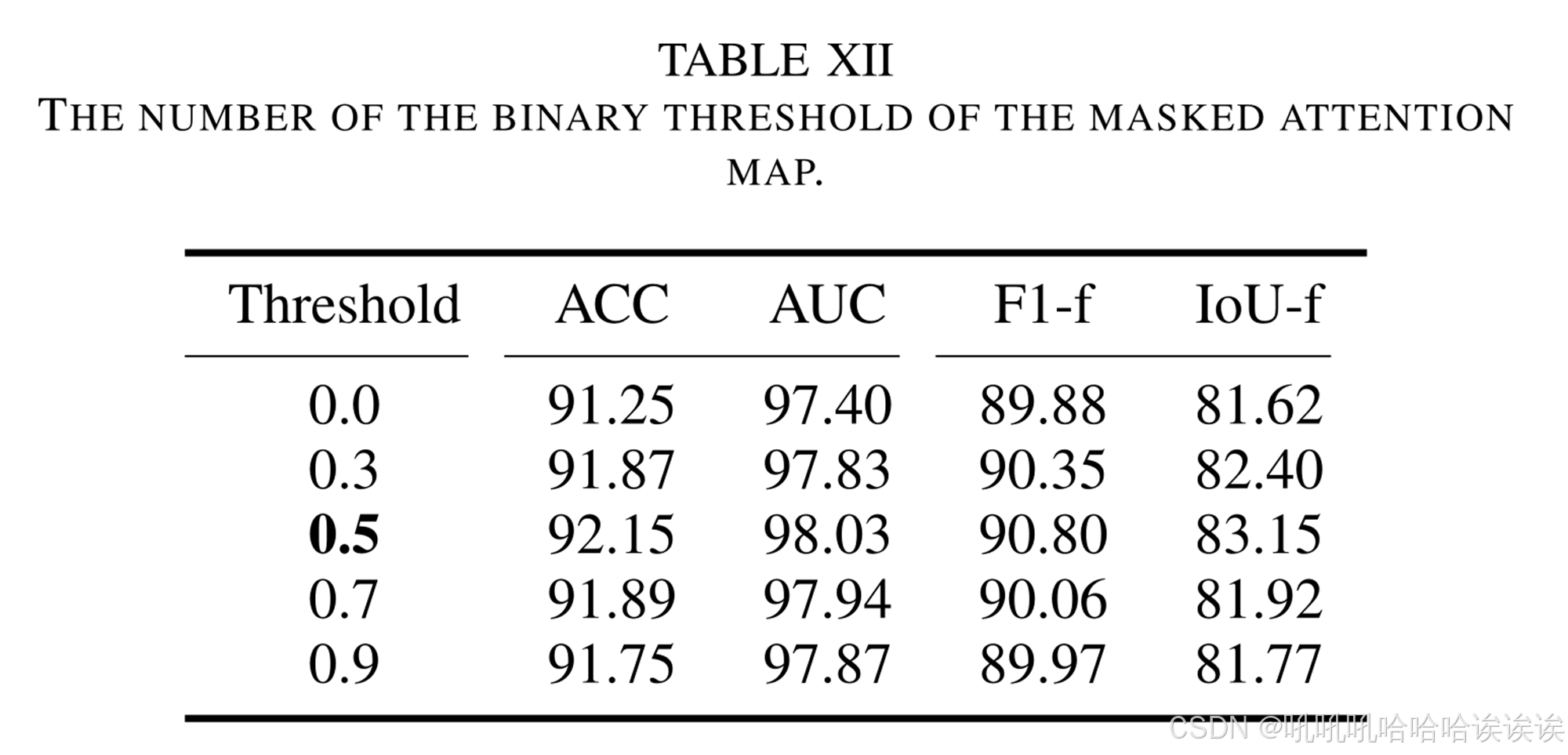
E. Analysis on the Threshold of the Masked Attention Map
FAT模块中的掩码交叉注意方法利用额外的定位层提供掩码注意图,如Eq.(4)所示。我们对掩码二值化进行了不同阈值的实验,如表12所示。其中,0表示不存在掩码注意策略,而0.3、0.5、0.7和0.9表示不同的二值化阈值。实验结果表明,阈值为0.5可获得最佳性能。
VII. CONCLUSION AND DISCUSSION
A. Conclusion
本文介绍了混合噪声增强伪造感知统一预测器MoNFAP,解决了先前在更广泛的伪造研究界对多人脸伪造检测和定位研究中的空白。我们提出了一种token学习策略和伪造感知Transformer模块,通过推理真假tokens与图像特征之间的关系,共同预测分类和定位结果。该过程通过加入分类信息,有效地提高了定位器的能力。此外,我们还引入了一个混合噪声模块,该模块利用了混合experts的概念。该模块聚合了不同类型的噪声线索,增强了广义RGB特征。最后,我们建立了一个综合基准来评估最先进的方法,并且所提出的MoNFAP取得了显着的性能。
B. Discussion
目前,在人脸伪造研究领域还没有同时实现像素级定位和图像级检测的方法。本文介绍了这两个任务的基准,并提出了一种新的联合预测方法。我们的目标是推动多人脸伪造定位领域的发展。
本研究中的多人脸数据集来源于Open Images[71]、OpenForensics[6]、FFIW[7]和Manual-Fake[8]。所有图像均符合各自数据集的许可和规定。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









