






一、操作准备
-
原理:
Hive表的元数据库中,描述了有哪些database、table、以及表有多少列,每一列是什么类型,以及表的数据保存在hdfs的什么位置
执行HQL时,先到MySQL元数据库中查找描述信息,然后解析HQL并根据描述信息生成MR任务,简单来说Hive就是将SQL根据MySQL中元数据信息转成MapReduce执行,但是速度慢。
使用SparkSQL整合Hive其实就是让SparkSQL去加载Hive 的元数据库,然后通过SparkSQL执行引擎去操作Hive表
所以首先需要开启Hive的元数据库服务,让SparkSQL能够加载元数据 -
API
在Spark2.0之后,SparkSession对HiveContext和SqlContext在进行了统一
可以通过操作SparkSession来操作HiveContext和SqlContext。
1.1 SparkSQL整合Hive MetaStore
默认Spark 有一个内置的 MateStore,使用 Derby 嵌入式数据库保存数据【上面案例】,但是这种方式不适合生产环境,因为这种模式同一时间只能有一个 SparkSession 使用,所以生产环境更推荐使用 Hive 的 MetaStore
SparkSQL 整合 Hive 的 MetaStore 主要思路就是要通过配置能够访问它,并且能够使用 HDFS保存WareHouse,所以可以直接拷贝Hadoop和Hive的配置文件到Spark的配置目录。
1.3 使用SparkSQL操作集群Hive表
如下为HiveContext的源码解析:

在PyCharm中开发应用,集成Hive读取表的数据进行分析,构建SparkSession时需要设置HiveMetaStore服务器地址及集成Hive选项:
范例演示代码如下:
# -*- coding: utf-8 -*-
# Program function:
from pyspark.sql import SparkSession
import os
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
# _SPARK_HOST = "spark://node1:7077"
_SPARK_HOST = "local[3]"
_APP_NAME = "test"
spark = SparkSession.builder \
.master(_SPARK_HOST) \
.appName(_APP_NAME) \
.enableHiveSupport() \
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
#PROJECT_ROOT = os.path.dirname(os.path.realpath(__file__)) # 获取项目根目录
# print(PROJECT_ROOT)#/export/pyfolder1/pyspark-chapter03_3.8/main
#path = os.path.join(PROJECT_ROOT, "data\\edge\\0_fuse.txt") # 文件路径
# 查看有哪些表
spark.sql("show databases").show()
spark.sql("use sparkhive").show()
spark.sql("show tables").show()
# 创建表
spark.sql(
"create table if not exists person (id int, name string, age int) row format delimited fields terminated by ','")
# 加载数据, 数据为当前目录下的person.txt(和src平级)
spark.sql("LOAD DATA LOCAL INPATH '/export/pyfolder1/pyspark-chapter03_3.8/data/student.csv' INTO TABLE person")
# 查询数据
spark.sql("select * from person ").show()
print("===========================================================")
import pyspark.sql.functions as fn
spark.read \
.table("person ") \
.groupBy("name") \
.agg(fn.round(fn.avg("age"), 2).alias("avg_age")) \
.show(10, truncate=False)
spark.stop()
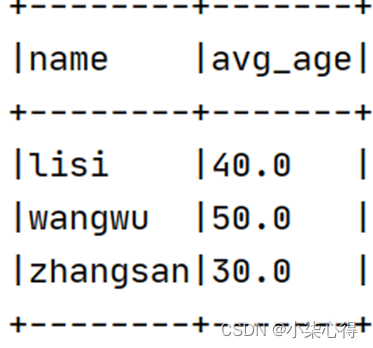
运行程序结果如下:















 2408
2408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









