






第一题:
已AC,用的sort,这是最容易想到的方法,但是操作数比较大,如何优化还没想好:
class Solution {
public:
TreeNode* getNode(vector<int>& nums) {
if (nums.size() == 0) return nullptr;
if (nums.size() == 1) return new TreeNode(nums[0]);
vector<int> copynums(nums.begin(), nums.end());
sort(copynums.begin(), copynums.end());
TreeNode* root = new TreeNode(copynums.back());
int index = 0;
for (; index < nums.size(); index++) {
if (nums[index] == root->val) break;
}
vector<int> leftTree(nums.begin(), nums.begin() + index);
vector<int> rightTree(nums.begin() + index + 1, nums.end());
root->left = getNode(leftTree);
root->right = getNode(rightTree);
return root;
}
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return getNode(nums);
}
};学习记录:
看了代码随想录才知道的确是find max以后从上到下构造,不过他在原数组的基础上修改的区间替代了新建数组,可以加快代码运行减少内存:
class Solution {
public:
TreeNode* getNode(vector<int>& nums, int left, int right) {
if (left >= right) return nullptr;
int index = left, MaxNum = 0;
for (int i = left + 1; i < right; i++) {
if (nums[i] > nums[index]) {
index = i;
}
}
TreeNode* root = new TreeNode(nums[index]);
root->left = getNode(nums, left, index);
root->right = getNode(nums, index + 1, right);
return root;
}
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return getNode(nums, 0, nums.size());
}
};TIPS:
每次分割不用定义新的数组,而是通过下标索引直接在原数组上操作会更快!
第二题:
已AC:
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if (root1 == nullptr && root2 == nullptr) return nullptr;
else if (root1 == nullptr) return root2;
else if (root2 == nullptr) return root1;
else {
TreeNode* root = new TreeNode(root1->val + root2->val);
root->left = mergeTrees(root1->left, root2->left);
root->right = mergeTrees(root1->right, root2->right);
return root;
}
}
};和代码随想录的差不多,不过我是创建了新节点来存两个节点的和,他是直接用的root1这棵树:
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if (root1 == nullptr && root2 == nullptr) return nullptr;
else if (root1 == nullptr) return root2;
else if (root2 == nullptr) return root1;
else {
root1->val += root2->val;
root1->left = mergeTrees(root1->left, root2->left);
root1->right = mergeTrees(root1->right, root2->right);
return root1;
}
}
};第三题:
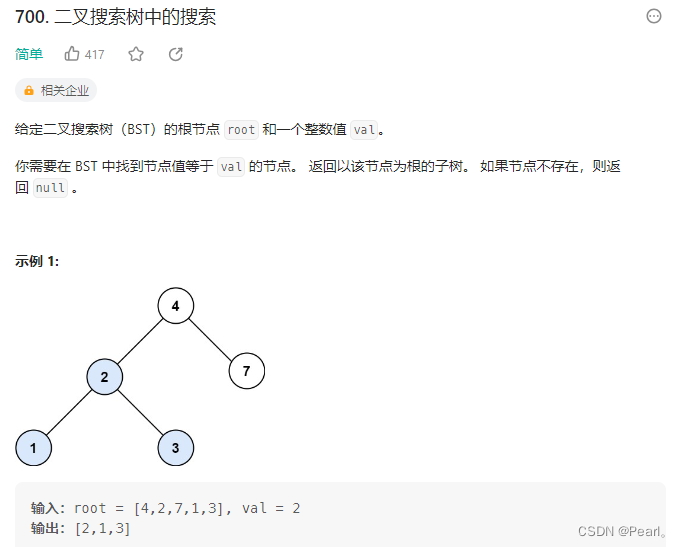
已AC:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == nullptr) return nullptr;
if (root->val == val) return root;
TreeNode* left = searchBST(root->left, val);
if (left) return left;
TreeNode* right = searchBST(root->right, val);
if (right) return right;
return nullptr;
}
};学习记录:
二叉搜索树:根节点的值比左子树所有节点的值都大,比右子树所有节点的值都小;
因此如果val大于根节点的值,那么应该比较root->right->val和val,即右子树递归;如果val小于根节点的值,应该比较root->left->val,即左子树递归:
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if (root == nullptr) return nullptr;
if (root->val == val) return root;
TreeNode* result;
if (root->val > val) result = searchBST(root->left, val);
if (root->val < val) result = searchBST(root->right, val);
return result;
}
};第四题:
对二叉搜索树的概念不熟悉,踩太多坑,没能AC。
学习记录:
二叉搜索树:节点的左子树的所有节点值都小于当前节点值,右子树所有节点值都大于当前节点值。
因此按照中序遍历左中右,会得到一个有序递增的数组。验证二叉搜索树,就相当于变成了判断一个序列是不是递增的。
根据上述分析,可以将中序遍历的节点值存入一个vector,然后判断vector是否为递增序列:
class Solution {
private:
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
public:
bool isValidBST(TreeNode* root) {
vec.clear(); // 不加这句在leetcode上也可以过,但最好加上
traversal(root);
for (int i = 1; i < vec.size(); i++) {
// 注意要小于等于,搜索树里不能有相同元素
if (vec[i] <= vec[i - 1]) return false;
}
return true;
}
};该题容易踩的坑:
- 陷阱1:不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了。我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。
例如下图:
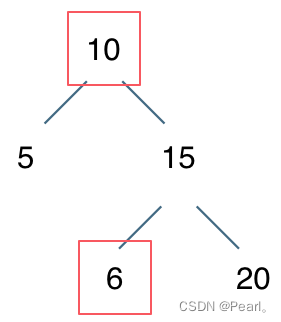
节点10大于左节点5,小于右节点15,但右子树里出现了一个6,因此不是二叉搜索树。
- 陷阱2:如果采用一个int值记录下前一个节点的值,由于样例中最小节点 可能是int的最小值,如果这样使用最小的int来比较也是不行的。
此时可以初始化比较元素为longlong的最小值(LONG_MIN)。
本题相当于在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
递归三部曲:
- 递归函数类型以及参数:bool类型,参数为TreeNode*,还有一个全局变量longlong MaxValue,用来比较遍历的节点是否有序;
- 终止条件:节点为空的时候,也是二叉搜索树,因此 if (root == null) return true;
- 单层递归逻辑:中序遍历,每个节点的值都要与前一个节点的值maxVal进行比较,如果小于前一个节点值则返回false,maxVal要一直更新。
因此可以写出以下代码(我比较喜欢在参数列表里回传要修改的值):
class Solution {
public:
bool isValid(TreeNode* root, long long& MaxVal) {
if (root == nullptr) return true;
//中序遍历
bool left = isValid(root->left, MaxVal);
if (root->val > MaxVal) MaxVal = root->val;
else return false;
bool right = isValid(root->right, MaxVal);
return left && right;
}
bool isValidBST(TreeNode* root) {
long long max = LONG_MIN;
return isValid(root, max);
}
};避免 初始化最小值,如下方法取到最左面节点的数值来比较:
class Solution {
public:
TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
if (pre != NULL && pre->val >= root->val) return false;
pre = root; // 记录前一个节点
bool right = isValidBST(root->right);
return left && right;
}
};这个方法比较好,可以通过pre是否为空排除掉根节点的情况,如果是用val存数值则不好排除!















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









