







什么是ES
ES是高性能分布式搜索引擎
安装ES
docker run -d --name es -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -e "discovery.type=single-node" -v /mydata/es/data:/usr/share/elasticsearch/data -v /mydata/es/plugins:/usr/share/elasticsearch/plugins --privieged -p 9200:9200 -p 9300:9300 elasticsearch:7.12.1
安装kibana
docker run -d --name kibana -e ELASTICSEARCH_HOST=http://es:9200 -p 5601:5601 kibana:7.12.1
倒排索引
es采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成词语
正向索引:
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 299 |
倒排索引:
| 词条(term) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
IK分词器下载
https://github.com/infinilabs/analysis-ik/releases/tag/v7.12.1
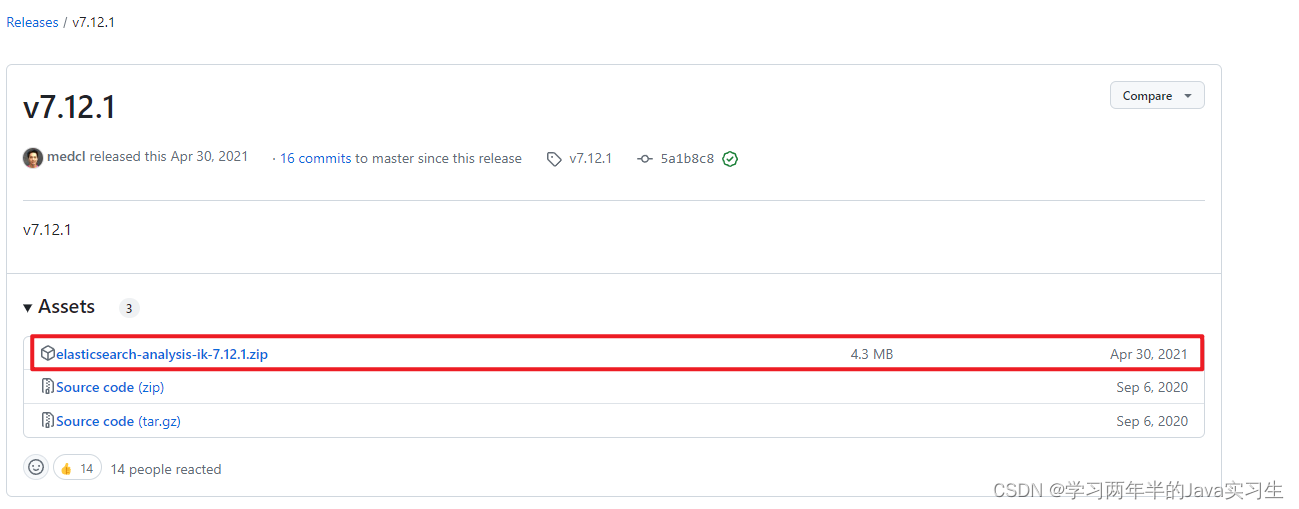
IK分词器安装
- 将上面的压缩包通过ftp解压到对应es的插件目录挂载卷
- 改名成ik
- 重启es

IK分词器测试
标准分词器
POST /_analyze
{
"analyzer": "standard",
"text": "banny学习Java太棒了"
}
reason:
{
"tokens" : [
{
"token" : "banny",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "学",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "习",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "太",
"start_offset" : 11,
"end_offset" : 12,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "棒",
"start_offset" : 12,
"end_offset" : 13,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "了",
"start_offset" : 13,
"end_offset" : 14,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
ik分词器smart
POST /_analyze
{
"analyzer": "ik_smart",
"text": "banny学习Java太棒了"
}
reason:
{
"tokens" : [
{
"token" : "banny",
"start_offset" : 0,
"end_offset" : 5,
"type" : "ENGLISH",
"position" : 0
},
{
"token" : "学习",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 2
},
{
"token" : "太棒了",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 3
}
]
}
ik分词器max
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "banny学习Java太棒了"
}
reason:
{
"tokens" : [
{
"token" : "banny",
"start_offset" : 0,
"end_offset" : 5,
"type" : "ENGLISH",
"position" : 0
},
{
"token" : "学习",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 2
},
{
"token" : "太棒了",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "太棒",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "了",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 5
}
]
}
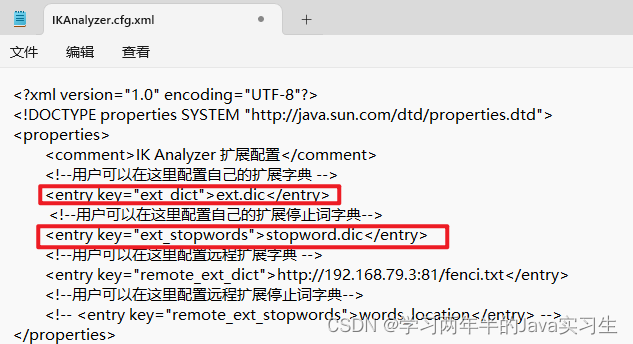
IK分词器配置扩展词典
在插件目录下的config的IKAnalyzer.cfg.xml进行配置
基础概念
-
索引库(index):相同类型文档的集合,相当于MySQL的表
-
映射(mapping):索引中文档的字段约束信息,相当于表的结构约束
| MySQL | ES | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document)。就是一条条的数据,类似数据库的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束,类似数据库的表结构(Schema) |
| SQL | DSL | DSL是es提供的JSON风格的请求语句,用来定义搜索 |
Mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
-
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
-
- 数值:long、integer、short、byte、double、float
-
- 布尔:boolean
-
- 日期:date
-
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
索引库操作(Kibana版本)
es提供的所有API都是Restful的接口,遵循Restful的基本规范:
| 接口类型 | 请求方式 | 请求路径 | 请求参数 |
|---|---|---|---|
| 查询用户 | GET | /users/{id} | 路径中的id |
| 新增用户 | POST | /users | json格式对象 |
| 修改用户 | PUT | /users/{id} | 1. 路径中的id 2. json格式对象 |
| 删除用户 | DELETE | /users/{id} | 路径中的id |
创建索引库和mapping的请求语法如下:
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名1": {
"type": "text".
"analyzer": "ik_smart"
},
"字段名2": {
"type": "keyword".
"index": "false"
},
"字段名3": {
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
示例:
PUT /study
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"age":{
"type": "byte"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName": {
"type": "keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}
reason:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "study"
}
查看索引库语法:
GET /索引库名
示例:
GET /study
reason:
{
"study" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "byte"
},
"email" : {
"type" : "keyword",
"index" : false
},
"info" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"name" : {
"properties" : {
"firstName" : {
"type" : "keyword"
},
"lastName" : {
"type" : "keyword"
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1719771023308",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "nyfJaLYNRfifAcXM-MVrDg",
"version" : {
"created" : "7040299"
},
"provided_name" : "study"
}
}
}
}
删除索引库的语法:
DELETE /索引库名
示例:
DELETE /study
reason:
{
"acknowledged" : true
}
索引库不允许修改,只允许新增字段
PUT /study/_mapping
{
"properties":{
"age":{
"type": "byte"
}
}
}
文档操作(Kibana版本)
新增文档的请求格式如下:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
示例:
POST /study/_doc/1
{
"info": "banny金牌讲师",
"email": "bannyLai@163.com",
"name":{
"firstName": "banny",
"lastName": "Lai"
}
}
reason:
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
查询文档的请求格式如下:
GET /索引库名/_doc/文档id
示例:
GET /study/_doc/1
reason:
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
}
}
删除文档的请求格式如下:
DELETE /索引库名/_doc/文档id
示例:
DELETE /study/_doc/1
reason:
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
修改文档
方式一:全量修改,会删除旧文档,添加新文档
PUT /索引库名/_doc/文档id
示例:
PUT /study/_doc/1
{
"info": "Banny金牌讲师"
}
reason:
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_version" : 5,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 1
}
方式二:增量修改,修改指定字段值
POST /索引库名/_update/文档id
示例:
POST /study/_update/1
{
"doc": {
"info": "Banny金牌讲师"
}
}
reason:
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_version" : 13,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 12,
"_primary_term" : 1
}
批量处理
POST /_bulk
{"index" :{"_index":"索引库名","_id":"1"}}
{"字段1":"值1","字段2": "值2"}
{"index" :{"_index":"索引库名","_id":"1"}}
{"字段1":"值1","字段2": "值2"}
{"index" :{"_index":"索引库名","_id":"1"}}
{"字段1":"值1","字段2": "值2"}
{"delete":{"_id":"1","_index":"test"}}
{"update" :{"_id":"1","_index":"test"}}
{"doc":"field2":"value2"}
JavaRestClient
引入es的RestHightLevelClient的依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
因为SpringBoot默认的ES版本是7.17.0,所以需要覆盖默认的ES版本
<properties>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
初始化RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.79.3:9200")));
索引库操作(java版本)
创建索引库的JavaAPI
void testCreateIndex() throws IOException {
//1. 准备request对象
CreateIndexRequest request = new CreateIndexRequest("items");
//2. 准备请求参数
request.source(MAPPING_TEMPLATE, XContentType.JSON);
//3. 发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
查询索引库的JavaAPI
void testGetIndex() throws IOException {
//1. 准备request对象
GetIndexRequest request = new GetIndexRequest("items");
//2. 发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("exists = " + exists);
}
删除索引库的JavaAPI
void testDeleteIndex() throws IOException {
//1. 准备request对象
DeleteIndexRequest request = new DeleteIndexRequest("items");
//2. 发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
文档操作(java版本)
新增文档的JavaAPI
void testIndexDocument() throws IOException {
//1. 准备request对象
IndexRequest request = new IndexRequest("study").id("2");
//2. 准备请求参数
request.source("{\n" +
" \"info\": \"banny金牌讲师\",\n" +
" \"email\": \"bannyLai@163.com\",\n" +
" \"name\": {\n" +
" \"firstName\": \"banny\",\n" +
" \"lastName\": \"Lai\"\n" +
" }\n" +
"}", XContentType.JSON);
//3. 发送请求
client.index(request, RequestOptions.DEFAULT);
}
查询文档的JavaAPI
void testGetIndexDocument() throws IOException {
//1. 准备request对象
GetRequest request = new GetRequest("study", "2");
//2. 发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String source = response.getSourceAsString();
System.out.println(source);
}
删除文档的JavaAPI
void testDeleteIndexDocument() throws IOException {
//1. 准备request对象
DeleteRequest request = new DeleteRequest("study", "2");
//2. 发送请求
client.delete(request, RequestOptions.DEFAULT);
}
修改文档的JavaAPI
方式一:全量更新。和新增的请求方式一样
void testIndexDocument() throws IOException {
//1. 准备request对象
IndexRequest request = new IndexRequest("study").id("2");
//2. 准备请求参数
request.source("{\n" +
" \"info\": \"banny金牌讲师\",\n" +
" \"email\": \"bannyLai@163.com\",\n" +
" \"name\": {\n" +
" \"firstName\": \"banny\",\n" +
" \"lastName\": \"Lai\"\n" +
" }\n" +
"}", XContentType.JSON);
//3. 发送请求
client.index(request, RequestOptions.DEFAULT);
}
方式二:增量更新
void testUpdateIndexDocument() throws IOException {
//1. 准备request对象
UpdateRequest request = new UpdateRequest("study", "2");
//2. 准备请求参数
request.doc(
"age", 18
);
//3. 发送请求
client.update(request, RequestOptions.DEFAULT);
}
批处理
void testBulkIndexDocument() throws IOException {
//1. 准备request对象
BulkRequest request = new BulkRequest();
//2. 准备请求参数
request.add(new IndexRequest("study")
.id("3").source("{\n" +
" \"info\": \"banny金牌讲师\",\n" +
" \"email\": \"bannyLai@163.com\",\n" +
" \"name\": {\n" +
" \"firstName\": \"banny\",\n" +
" \"lastName\": \"Lai\"\n" +
" }\n" +
"}", XContentType.JSON));
request.add(new IndexRequest("study")
.id("4").source("{\n" +
" \"info\": \"banny金牌讲师\",\n" +
" \"email\": \"bannyLai@163.com\",\n" +
" \"name\": {\n" +
" \"firstName\": \"banny\",\n" +
" \"lastName\": \"Lai\"\n" +
" }\n" +
"}", XContentType.JSON));
//3. 发送请求
client.bulk(request, RequestOptions.DEFAULT);
}
DSL查询(Kibana版本)
查询语法:
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"条件值"
}
}
}
示例:
GET /study/_search
{
"query": {
"match_all": {}
}
}
reason:
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
}
]
}
}
叶子查询(Kibana版本)
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去词条列表中匹配。例如:-
- match_query
- multi_match_query
精确查询:不对用户输入内容分词,直接精确匹配,一般是查找keyword、数值、日期、布尔等类型。例如:
- ids
- range
- term
地理(geo)查询:用于搜索地理位置,搜索方式很多。例如:
- geo_distance
- geo_bounding_box
match查询:全文检索查询的一种,会对用户输入内容分词,然后取倒排索引库检索,语法:
GET /索引库名/_search
{
"query":{
"match":{
"FIELD":"TEXT"
}
}
}
示例:
GET /study/_search
{
"query":{
"match":{
"age":18
}
}
}
reason:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
}
]
}
}
multi_match:与match查询类似,只不过允许同时查询多个字段,语法:
GET /索引库名/_search
{
"query":{
"multi_match":{
"query":"TEXT",
"fields":["FIELD1","FIELD2"]
}
}
}
示例:
GET /study/_search
{
"query":{
"multi_match":{
"query":"banny",
"fields":["info","name"]
}
}
}
reason:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.105360515,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.105360515,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.105360515,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.105360515,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.105360515,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
}
]
}
}
term查询,语法:
GET /索引库名/_search
{
"query":{
"term":{
"FIELD":{
"value": "VALUE"
}
}
}
}
示例:
GET /study/_search
{
"query":{
"term":{
"age":{
"value": "18"
}
}
}
}
reason:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
}
]
}
}
range查询,语法:
GET /索引库名/_search
{
"query":{
"range":{
"FIELD":{
"gte": 10,
"lte": 20
}
}
}
}
示例:
GET /study/_search
{
"query":{
"range":{
"age":{
"gte": 10,
"lte": 20
}
}
}
}
reason:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
}
]
}
}
ids查询,语法:
GET /索引库名/_search
{
"query": {
"ids": {
"values": ["1","2"]
}
}
}
示例:
GET /study/_search
{
"query": {
"ids": {
"values": ["1","2"]
}
}
}
reason:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
}
]
}
}
复合查询(Kibana版本)
第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
- bool
第二类:基于某种算法修改查询时的文档的相关性算分,从而改变文档排名。例如:
- function_score
- dis_max
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似”与“
- should:选择性匹配子查询,类似”或“
- must_not:必须不匹配,不参与算分,类似”非“
- filter:必须匹配,不参与算分
GET /study/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name.firstName": "banny"
}
}
],
"filter": {
"term": {
"age": 18
}
}
}
}
}
reason:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.105360515,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.105360515,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.105360515,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
}
}
]
}
}
排序和分页(Kibana版本)
默认是根据_score来排序,也可以指定字段排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。语法:
GET /索引库名/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"FIELD": "desc"
}
]
}
示例:
GET /study/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"age": "desc"
}
]
}
reason:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
},
"sort" : [
18
]
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
},
"sort" : [
18
]
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "3",
"_score" : null,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
},
"sort" : [
-9223372036854775808
]
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "4",
"_score" : null,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
},
"sort" : [
-9223372036854775808
]
}
]
}
}
分页:默认只显示前10的数据。可以修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
语法:
GET /索引库名/_search
{
"query":{
"match_all": {}
},
"from": 0,
"size": 2,
"sort": [
{
"age": "desc"
}
]
}
示例:
GET /study/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 2,
"sort": [
{
"age": "desc"
}
]
}
reason:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
},
"sort" : [
18
]
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
},
"sort" : [
18
]
}
]
}
}
深度分页问题:es的数据一般采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。查询数据时需要汇总各个分片的数据
- search after模式
高亮显示(Kibana版本)
高亮显示:就是在搜索结果中把搜索关键字突出显示。语法:
GET /索引库名/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 高亮的前置标签
"post_tags": "</em>" // 高亮的后置标签
}
}
}
}
示例:
GET /study/_search
{
"query": {
"match": {
"name.firstName": "banny"
}
},
"highlight": {
"fields": {
"name.firstName": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}
reason:
{
"took" : 29,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.105360515,
"hits" : [
{
"_index" : "study",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.105360515,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
},
"highlight" : {
"name.firstName" : [
"<em>banny</em>"
]
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.105360515,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
},
"highlight" : {
"name.firstName" : [
"<em>banny</em>"
]
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.105360515,
"_source" : {
"info" : "banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
}
},
"highlight" : {
"name.firstName" : [
"<em>banny</em>"
]
}
},
{
"_index" : "study",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.105360515,
"_source" : {
"info" : "Banny金牌讲师",
"email" : "bannyLai@163.com",
"name" : {
"firstName" : "banny",
"lastName" : "Lai"
},
"age" : 18
},
"highlight" : {
"name.firstName" : [
"<em>banny</em>"
]
}
}
]
}
}
DSL查询(Java版本)
- 构建并发起请求
- 解析查询结果
void testMatchAll() throws IOException {
//1. 准备request
SearchRequest request = new SearchRequest("study");
//2. 组织DSL参数
request.source()
.query(QueryBuilders.matchAllQuery());
//3. 发起请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4. 解析结果
SearchHits searchHits = response.getHits();
//4.1 总条数
long value = searchHits.getTotalHits().value;
System.out.println(value);
//4.2 命中的数据
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
//4.2.1 获取source结果
String json = hit.getSourceAsString();
System.out.println(json);
}
}
构建查询条件(Java版本)
全文检索的查询条件构造API如下:
// 单字段查询
QueryBuilders.matchQuery("name", "banny");
// 多字段查询
QueryBuilders.multiMatchQuery("banny","name","info");
精确查询的查询条件构造API如下:
// 词条查询
QueryBuilders.term Query("name","banny");
// 范围查询
QueryBuilder.rangeQuery("age").gte(10).lte(20);
布尔查询的查询条件构造API如下:
// 创建布尔查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 添加must条件
boolQuery.must(QueryBuilders.termQuery("name","banny"));
// 添加filter条件
boolQuery.filter(QueryBuilders.rangeQuery("age").lte(20));
排序和分页(Java版本)
// 查询
request.source().query(QueryBuilders.matchAllQuery());
// 分页
request.source().from(0).size(5);
// 价格排序
request.source().sort("age",SorOrder.ASC);
高亮显示(Java版本)
request.source().highlighter(
SearchSourceBuilder.highlight()
.field("name")
.preTags("<em>")
.postTags("</em>")
);
聚合(Kibana版本)
GET /索引库名/_search
{
"query": {"match_all": {}},
"size" : 0,
"aggs": {
"nameAgg": {
"terms": {
"field": "name",
"size": 20
}
}
}
}
示例:
GET /study/_search
{
"query": {"match_all": {}},
"size": 0,
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
}
}
}
reason:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 18,
"doc_count" : 2
}
]
}
}
}
度量
GET /索引库名/_search
{
"query": {"match_all": {}},
"size" : 0,
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 20
},
"aggs":{
"ageStats":{
"stats":{
"field": "age"
}
}
}
}
}
}
示例:
GET /study/_search
{
"query": {"match_all": {}},
"size" : 0,
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 20
},
"aggs":{
"ageStats":{
"stats":{
"field": "age"
}
}
}
}
}
}
reason:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 18,
"doc_count" : 2,
"ageStats" : {
"count" : 2,
"min" : 18.0,
"max" : 18.0,
"avg" : 18.0,
"sum" : 36.0
}
}
]
}
}
}
聚合(Java版本)
request.source().size(0);
request.source().aggregation(
AggregationBuilders
.terms("ageAgg")
.field("age)
.size(20)
)
void testAgg() throws IOException {
//1. 准备request
SearchRequest request = new SearchRequest("study");
//2. 组织DSL参数
request.source().size(0).aggregation(
AggregationBuilders
.terms("ageAgg")
.field("age")
.size(20)
);
//3. 发起请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4. 解析结果
Aggregations aggregations = response.getAggregations();
Terms ageAgg = aggregations.get("ageAgg");
List<? extends Terms.Bucket> buckets = ageAgg.getBuckets();
for (Terms.Bucket bucket : buckets) {
String age = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
System.out.println(age);
System.out.println(docCount);
}
}















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









