







1、源码走读
(1)当Driver中的SchedulerBackend(Standalone模式为CoarseGrainedSchedulerBackend)给ExecutorBackend(Standalone模式为CoarseGrainedExecutorBackend)发送LaunchTask之后,CoarseGrainedExecutorBackend在收到LaunchTask消息后,Executor会通过TaskRunner在ThreadPool来运行具体的Task,TaskRunner内部会做一些准备工作:例如反序列化Task,然后通过网络来获取需要的文件,jar等。
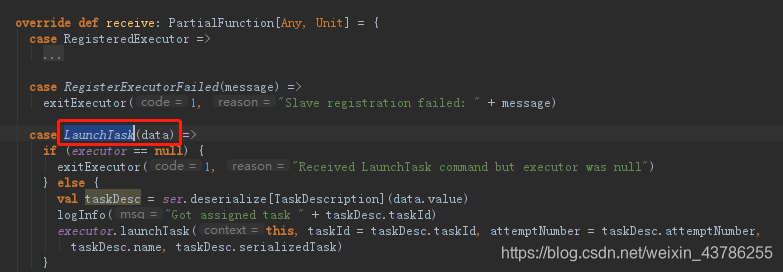
CoarseGrainedExecutorBackend在收到LaunchTask消息后首先看下Executor存不存在,不存在则系统直接退出,然后反序列化我们的任务,反序列的是TaskDescription,反序列化之后就launchTask。
注意:在执行具体Task的业务逻辑前会进行4次反序列化:①TaskDescription的反序列化②Task的反序列化③RDD的反序列化④反序列化task的依赖
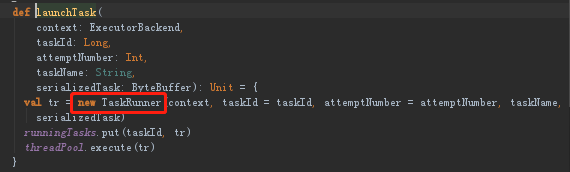
(2)进入到executor的launchTask方法中,在这内部有个TaskRunner
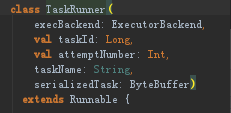
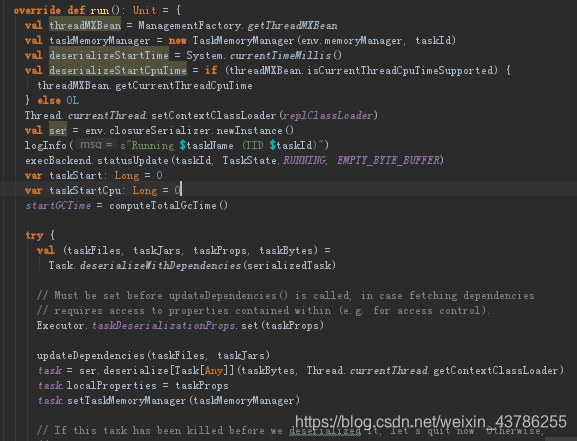
TaskRunner本身是个Runnable接口,在这个内部要运行核心肯定是run方法,在run方法里面定义一些属性:taskMemoryManager内存管理,deserializeStartTime反序列开始时间等。因为要加载具体的类所以要ClassLoaderThread.currentThread. setContextClassLoader(replClassLoader)。调用execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER),他是ExecutorBackend的方法,ExecutorBackend通过statusUpdate方法其实是给driver发信息汇报自己状态的。有了(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)这些状态,告诉driver说现在任务开始运行了。在然后这个反序列化得到的tasktuple包括任务运行的文件,jars,Bytes等等都会被反序列过来
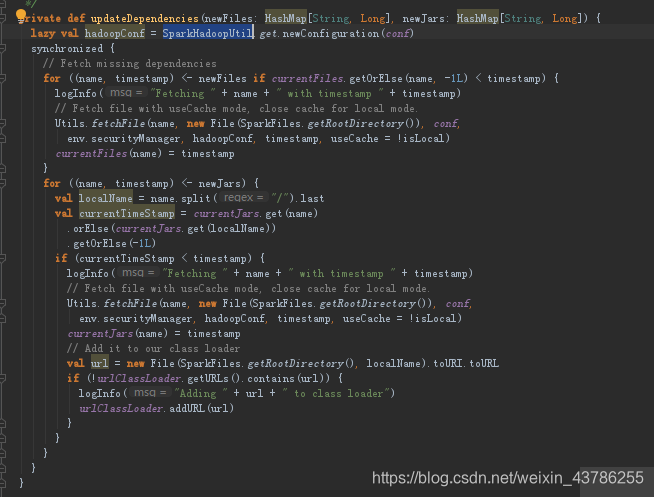
进入到updateDependencies方法中。这里下载我们task运行需要的所有依赖文件,获得hadoop的Configuration。这里下载文件用了synchronized关键字,因为我们每一个taskrunner运行在线程中,这个方法会被多个线程调用,方法在全局中,所以需要加锁。下载文件,所有的依赖都有之后就反序列化任务即task本身。
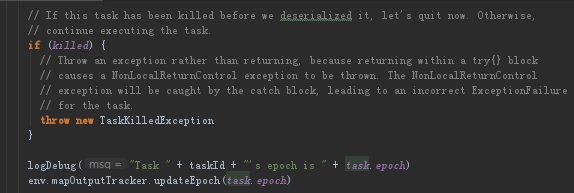
回到run方法中,接下来判断任务是否被killed

判断任务是否被killed
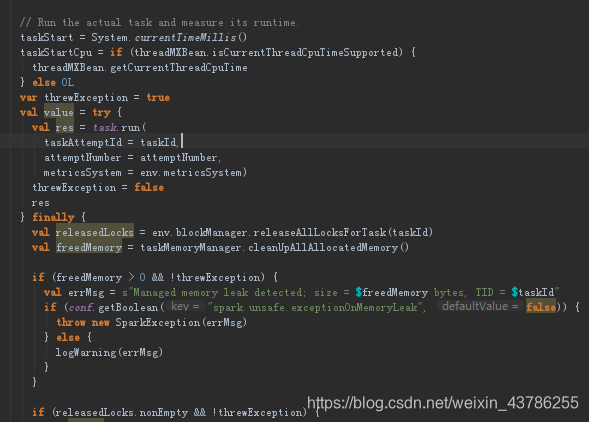
再然后,调用反序列化后的task.run获得执行结果
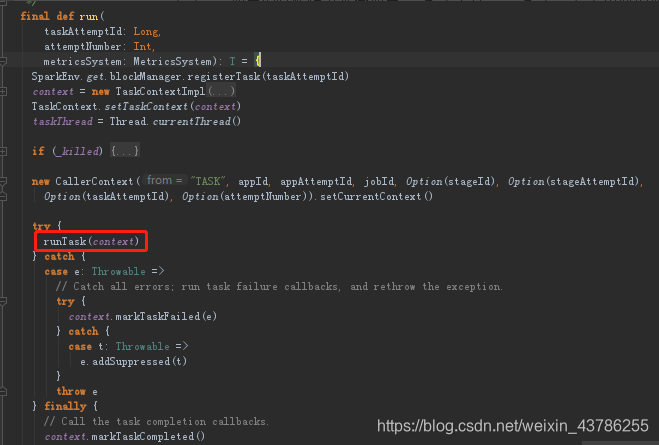
task.run调用的时候转过来会调用runTask方法,runTask是task里面的抽象方法,task主要有两种类型:ShuffleMapTask和ResultTask。
①下面的ShuffleMapTask的runTask,实际内部执行的时候会通过调用rdd的iterator针对我们Partition进行计算。我们的ShuffleMapTask在计算具体的Partition之后会通过ShuffleManager获得ShuffleWrite把当前task计算的结果根据具体的ShuffleManager的实现来写入到具体的文件,操作完成后会把MapStatus发送给DAGScheduler。把MapStatus向DAGScheduler里面的MapOutputTracker汇报。
在rdd的iterator方法中,ShuffleMapTask先看一下cache memory中有没有曾经的数据

最终计算的时候就是调用这个rdd的compute,这里有个TaskContext类型的参数这里面维持了很多上下文信息
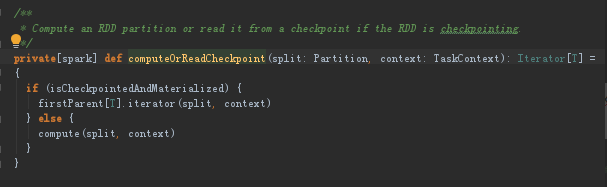
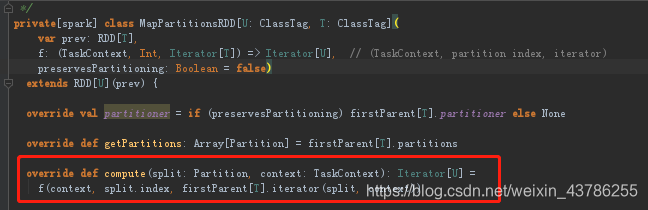
看个具体的RDD的compute实现,任何的RDD的compute返回的都是Iterator
![]()
这个f是个函数一般是自己写的,对他分配处理的业务逻辑,因为有些RDD是系统自动生成的所以可能是系统调用的逻辑。这个就是自己写的业务逻辑了,只不过一个Stage从后往前推他会把所有的RDD合并最后变成一个,函数链条也会展开成一个很大的函数
回到runtask中,这个writer要看不同的Shuffle
![]()
②ResultTask是根据前面Stage的执行结果进行Shuffle产生整个job最后的结果。这个是ResultTask,在反序列化RDD的时候直接去调func。
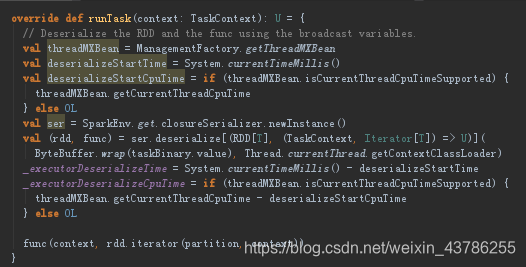
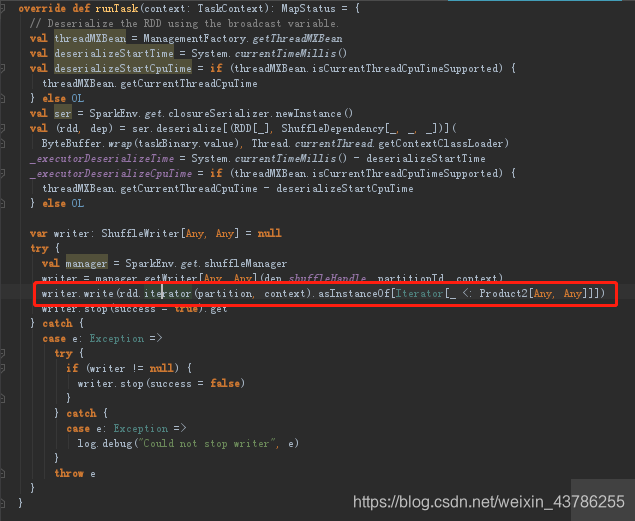
(3)回到run方法中,这个序列化的value是前面task.run获得的执行结果,之所以记录这么多时间是为了在web控制台可以看到这些信息
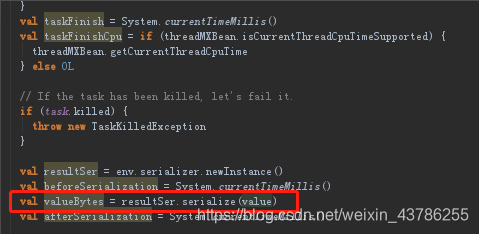
(4)在Executor的run方法的task执行完之后会调用CoarseGrainedExecutorBackend的statusUpdate。其实就是给我们的driver发一个信息。
![]()
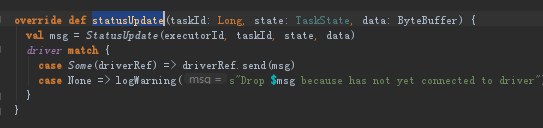
(5)CoarseGrainedSchedulerBackend收到statusUpdate消息后,它会调用Scheduler.statusUpdate,会释放相关的资源,如果没有什么问题的话空闲资源中就加上曾经想消耗的东西,再次进行资源调度。
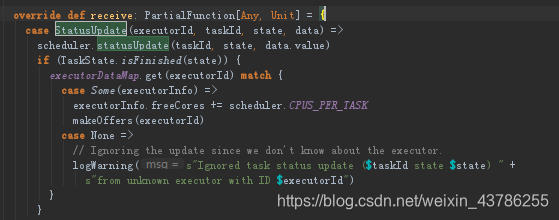
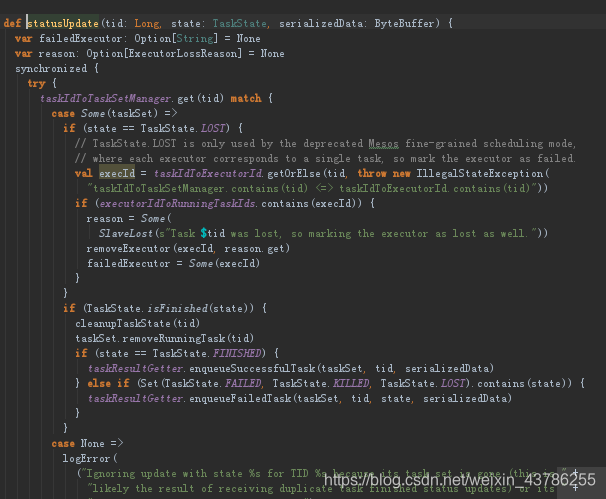
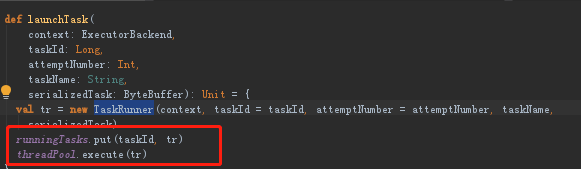
(6)回到launchtask方法中,把他交给runningTasks这样一个数据结构中,放入taskid以及业务逻辑,然后交给ThreadPool。
2、总结
(1)CoarseGrainedExecutorBackend在收到 CoarseGrainedSchedulerBackend发送的LaunchTask消息后反序列化TaskDescription
(2)通过executor的launchTask方法中执行Task,在launchTask内部会创建TaskRunner,在TaskRunner内部会做一些准备工作,如反序列化task,task依赖,获取jar等
(3)TaskRunner在ThreadPool具体运行Task;
(4)TaskRunner中会调用反序列化的Task.run方法执行并获得执行结果。在调用run方法的时候会调用Task的抽象方法runTask。在runTask内部会调用RDD的iterator()方法,在处理的内部会迭代Partition的元素并给我们自定义函数进行处理。对于ShuffleMapTask,首先要对RDD以及其依赖关系进行反序列化,最终会调用RDD的compute方法
(5)把执行结果序列化,并根据大小判断不同的姐夫哦传回给Driver的方式
(6)CoarseGrainedExecutorBackend给DriverEndPoint发送StatusUpdate传输执行结果,DriverEndPoint把执行结果传给TaskSchedulerImpl处理然后交给TaskResultGetter内部通过线程去分别处理Task执行成功和失败的不同情况,然后返回DAGScheduler任务处理结束的状况。














 598
598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









