







1 概述
众所周知监控平台对大数据平台是非常重要的,监控是故障诊断和分析的重要辅助利器,在发生事故之前就能预警,最大限度降低系统故障率。
监控系统我们可以分为业务层面,应用层面,系统层面
1.1 业务层面
业务系统是为了达成某种业务目标,因此监控业务系统最有效的方式是从数据上监控业务目标是否达成,因为业务系统的是多样的所以应由各个业务系统实现监控指标开发。
1.2 应用层面
需要对应用的整体运行状况进行了解、把控。一般通过抽象出的统一指标收集组件,收集应用级指标,如JVM堆内存、GC、CPU使用率等。
1.3 系统层面
实时监控服务器工作状态,监控性能、内存消耗、容量和整体系统健康状态等来保证服务器稳定运行。
2 TIGK架构
大部分的监控系统一般为4个模块:数据采集、数据存储、数据展示、告警 。TIGK平台也是按照此规则,TIGK其实本身技术栈为TICK,即Telegraf,InfluxDB,Chronograf,Kapacitor,但是由于Chronograf没有Grafana扩展性和易用性强,所以使用了Grafana作为替代方案形成TIGK。下图为TIGK的整体架构。

监控系统从收集到分析的流程如下
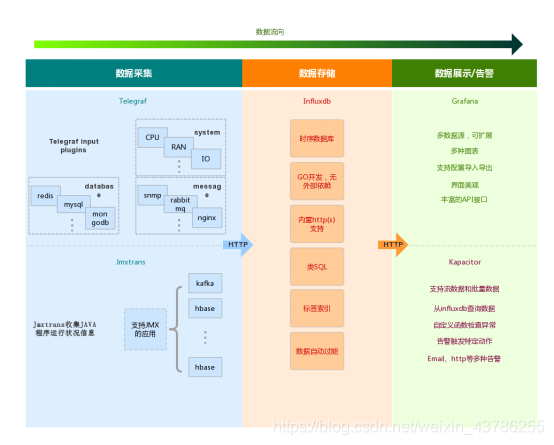
3 TIGK各组件
3.1 Telegraf
Telegraf是一个插件驱动的服务器代理,用于收集和报告度量指标。通过plugin来实现数据的input和output,内置了很多常用服务的插件。
Telegraf通过插件可以直接从它正在运行的系统中获取各种指标,从第三方API获取指标,甚至通过Statsd和Kafka的消费者服务来接收度量指标。它提供的输出插件,将指标发送到各种各样的数据存储、服务和消息队列,包括InfluxDB,Graphite,Kafka,等他组件。
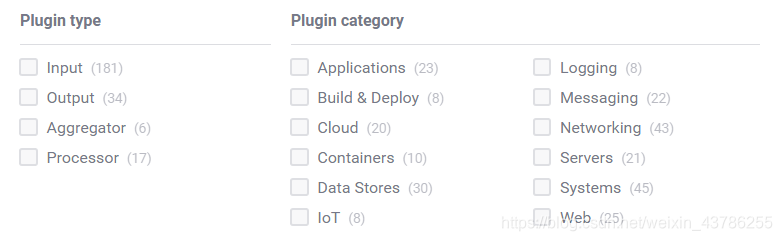
上图为官网所示的支持的插件统计,种类非常多,具体可到官网查看https://docs.influxdata.com/telegraf/v1.14/plugins/plugin-list/
Telegraf有四种类型的插件:
①输入插件(Inputs):收集各种时间序列性指标,包含各种系统信息和应用信息的插件。
②处理插件(Process):对收集到的指标数据流进行简单的处理,如给所有指标添加、删除、修改一个Tag。只是针对当前的指标数据进行。
③聚合插件(Aggregate):聚合插件有别于处理插件,就在于它要处理的对象是某段时间流经该插件的所有数据(所以,每个聚合插件都有一个period设置,只会处理now()-period时间段内的数据),比如取最大值、最小值、平均值等操作。
④输出插件(Outputs):收集到的数据,经过处理和聚合后,输出到数据存储系统,可以是各种地方,如:文件、InfluxDB、各种消息队列服务等等。
3.1.1 Telegraf特性
(1)Go语言编写,编译为一个二进制文件,没有外部依赖。
(2)占用内存小,通过插件开发人员可轻松添加input和output来支持其他服务的扩展
(3)支持众多流行服务大量插件,满足主流监控需求。
3.1.2 Telegraf相关概念
Telegraf工作原理:定时去执行输入插件收集数据,数据经过处理插件和聚合插件,批量输出到数据存储。
数据指标(Metrics):
①指标名(Measurement name):指标描述和命名。
②标签集合(Tags):Key/Value键值对,常用于快速索引和唯一标识。标签在设计的时候,尽量避免各种数值型,尽量使用有限集合。
③字段集合(Fields):Key/Value键值对,包含指标描述的数据类型和值。
④时间戳(Timestamp):此条指标数据的时间戳。
3.2 Influxdb
Influxdb是一个开源的分布式时序、时间和指标数据库,使用go语言编写,无需外部依赖。从创建之初就考虑到处理高的写和查询负载。InfluxDB是一个定制的高性能数据库特别用来存储时间戳数据,包括DevOps监控、应用指标、物联网传感器数据,实时分析。为了节省机器上的存储空间,可以配置InfluxDB保持数据的时间长度,自动到期和从系统中删除任何不需要的数据。InfluxDB还提供与数据交互的SQL的查询语言。
3.2.1 Influxdb特性
(1)时序性(Time Series):与时间相关的函数的灵活使用(诸如最大、最小、求和等);
(2)度量(Metrics):对实时大量数据进行计算;
(3)事件(Event):支持任意的事件数据,换句话说,任意事件的数据我们都可以做操作。
同时,它有以下几大特点:
schemaless(无结构),可以是任意数量的列;
min, max, sum, count, mean, median 一系列函数,方便统计;
Native HTTP API, 内置http支持,使用http读写;
Powerful Query Language 类似sql;
Built-in Explorer 自带管理工具。
3.2.2 数据格式
(1)数据格式
在 InfluxDB 中可以粗略的将要存入的一条数据看作一个虚拟的 key (包括 database, retention policy, measurement, tag sets, field name, timestamp)和其对应的 value(field value)。
行协议指定了写入数据的格式:
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
①database: 数据库名,在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录。
②retention policy: 存储策略,用于设置数据保留的时间,每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久。用户可以自己设置,例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。
③measurement: 测量指标名,也就是表名。
④tag sets: tags 在 InfluxDB 中会按照字典序排序,不管是 tagk 还是 tagv,只要不一致就分别属于两个 key。
⑤tag,标签,在InfluxDB中,tag是一个非常重要的部分,表名+tag一起作为数据库的索引,是“key-value”的形式。
⑥field name: InfluxDB 中支持一条数据中插入多个 fieldName,这其实是一个语法上的优化,在实际的底层存储中,是当作多条数据来存储。
⑦timestamp: 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,以为了优化后续的查询操作。
(3)与关系型数据库(MySQL)的基础概念对比
| 概念 | MySQL | InfluxDB |
|---|---|---|
| 数据库 | database | database |
| 表 | table | measurement |
| 列 | column | t ag(带索引的,非必须)、field(不带索引)、timestemp(唯一主键) |
(3)points
points表示表里面的一行数据,由时间戳time(每个数据记录时间,是数据库中的主索引(会自动生成))、数据field(各种记录值(没有索引的属性))、标签tags(各种有索引的属性)。
(4)Series
Series 相当于是数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
(5)Shard
Shard 它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
(6) 理解series 和 point
假设对不同学校的历年排名情况。首先整个数据是一个 measurement ,它包含了许多数据;然后我们根据学校 名称构建 tag ,把 排名得分作为 field ,那么所有数据行就类似于:
measurement,school=Peking score=2 timestamp
measurement,school=Tsinghua sort=3 timestamp
...
tag set 就是 tag key = tag value 的不同组合,这里的 tag set 有2种school=Peking和school=Tsinghua。
2个 tag set 构成了2个 series ,而每个 point 点就是 series 上具体某个 timestamp 对应的点。
3.2.3 TSM 存储引擎
TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
①Cache:cache 相当于是 LSM Tree 中的 memtabl。插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中。
②WAL:wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
③TSM File:单个 tsm file 大小最大为 2GB,用于存放数据。
④Compactor:compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。主要进行两种操作,一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
3.2.4 目录与文件结构
InfluxDB 的数据存储主要有三个目录。默认情况下是 meta, wal 以及 data 三个目录。
(1)meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
(2)wal 目录存放预写日志文件,以 .wal 结尾
(3)data 目录存放实际存储的数据文件,以 .tsm 结尾。
上面几张图中,_internal为数据库名,monitor为存储策略名称,再下一层目录中的以数字命名的目录是 shard 的 ID 值。
存储策略下有两个 shard,ID 分别为 1 和 2,shard 存储了某一个时间段范围内的数据。再下一级的目录则为具体的文件,分别是 .wal 和 .tsm 结尾的文件。
3.2.5 InfluxDB操作方式:
客户端命令行方式
HTTP API接口
各语言API库
基于WEB管理页面操作
3.3 Grafana
Grafana是一个功能齐全的度量仪表盘软件,支持从多种数据源读取数据用图表显示,界面美观,有冲击力,功能设计方便实用。多用于可视化基础实施和应用分析的时间序列数据,也可应用在其它领域,包括工业传感器、家庭自动化、天气和过程控制。
3.3.1 Grafana特点
(1)展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式。监控dashboard 导入、导出,这个功能比较实用,做好一个比较满意的展示面板,导出后主要修改一下里面的IP等信息,通过导入,其它主机的展示全部搞定。
(2)丰富的数据源接口:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等都能接入;
(3)通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
(4)混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
(5)注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
(6)过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询;
(7)丰富的API接口,方便自动化程序调用。
3.4 Kapacitor
Kapacitor是时序数据分析、处理引擎。它可以处理来自InfluxDB的流数据和批量数据。Kapacitor允许插入用户自定义的逻辑或用户自定义的函数来处理基于动态门限的告警,匹配模式指标,计算统计异常,并根据这些告警执行特定动作,比如动态负载均衡。Kapacitor支持Email,HTTP,TCP,HipChat,OpsGenie,Alerta,Sensu,PagerDuty,Slack等多种方式告警。
3.4.1 特点
(1)可以处理基于InfluxQL的批处理与将数据存储在内存中的流处理,并使用tick脚本来进行处理规则的定义;
(2)按计划从InfluxDB查询数据,或通过line协议从InfluxDB接收数据;
(3)使用InfluxQL对数据做各种转换;将转换后的数据存回InfluxDB,事件输出源还可以是email,http post,tcp, log, telegram,kafka,alerta,MQTT等;
(4)添加用户自定义函数检测异常;
与HipChat, OpsGenie, Alerta, Sensu, PagerDuty, Slack等集成。
3.4.2 相关名词解释
| 名词 | 说明 |
|---|---|
| task | 数据计算规则,由一系列节点node形成的数据处理的有向无环图DAG |
| task template | 通过模版变量来定制task |
| topic | 预警检测程序-如果没有显示在alert中用topic指定,会用程序的alert node来代替 |
| event | 触发的报警事件 |
| handler | 报警事件输出程序 |
| topic handler | 报警事件的输出有两种方式,一种是alert node的属性方法直接调用,一种是通过alert指定topic与yaml描述文件来定义 |
| record | 数据录制 |
| replay | 数据回放 |
| name | 度量名(相当于influxdb的measurement) |
| tags | 标签(相当于influxdb的tag key tag field) |
| columns | 字段(相当于influxdb的 field key) |
| values | 字段值(相当于influxdb的field value) |
| string template | 字符串模版 |
| lambda | 函数表达式 |
3.4.3 数据处理模型
它遵循基于工作流的编程模型。数据流从一个node到另一个node,每个node是一个黑盒的过程,它能以任意方式处理数据。nodes是以有向无环图的方式分布的
Tasks是通过TICK脚本来定义的,有三种状态disabled,enabled not executing,enabled executing
传输数据的数据模型有两种Stream和Batch。①Stream:数据点(由时间戳timestamp,一系列的属性fileds和tags组成)作为单个实体传递。数据立即被transfer,并且每次只transfer一个数据点②Batch:数据点以数据组的形式传递,将多个数据点看作一个整体输入

















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









