







MySQL
目录
16.3 用EXISTS替代IN、用NOT EXISTS替代NOT IN
1 数据与数据库
数据:客观存在记录信息并且可以鉴别的符号
数据存储的目的:为了方便检索
数据库(DB:DATA BASE):按某种数据结构存储的数据的仓库
数据库分为关系型数据库和非关系型数据库两类:
| 关系型数据库 | 存储数据以一张二维表结构方式来进行存储 |
| 非关系型数据库 | 不是以二维表结构方式存储 |
数据库管理系统(DBMS:DATA BASE MANAGEMENT SYSTEM):用于操作和管理数据库的软件系统
数据库管理系统分为关系型数据库管理系统(RDBMS)和非关系型数据库管理系统(NoSQL):
| 关系型数据库管理系统(RDBMS) | ①Oracle:大型分布式的关系型数据库管理系统,使用免费,服务收费 ②MySQL:中小型关系型管理系统,开源免费,支持GPL协议 ③SQLServer:Mircrosoft公司产品 ④DB2:IBM的产品 |
| 非关系型数据库管理系统(NoSQL) | ①Redis:高性能的key-value数据库 ②MongoDB:基于分布式文件存储的数据库 ③HBase:结构化数据的分布式存储系统 |
2 MySQL简介
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。关系型数据库将数据保存在不同的表中,而不是放在一个大仓库内,增加了访问速度提高了灵活性。MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。体积小,速度快,成本低,支持千万级数据,成为中小型网站开发的主流选择。
2.1 MySQL存储引擎:
MySQL数据库准备多种了不同的引擎。在5.0之前默认的数据库引擎是MyISAM,在5.5版本之后InnoDB成为了默认数据库引擎。
| 数据库引擎 | 描述 |
| InnoDB | 支持ACID事务,支持行级锁定 |
| MyISAM | 拥有较高的插入,查询速度,但不支持事务 |
| BDB | 事务型数据库的另一种选择,支持Commit 和Rollback 等其他事务特性 |
| Memory | 基于内存的,拥有极高的插入,更新和查询效率,但是会占用和数据量成正比的内存空间。 |
| MRG_MYISAM | 基于MRG_MYISAM存储引擎实现的分表机制,比较适用于插入和查询频率较高的场景。 |
| BLACKHOLE | 黑洞引擎,写入的任何数据都会消失,一般用于记录 binlog 做复制的中继 |
| CSV | 逻辑上由逗号分割数据的存储引擎。它会在数据库子目录里为每个数据表创建一个 .csv 文件,不支持索引。 |
| ARCHIVE | 非常适合存储大量的独立的,作为历史记录的数据,插入效率高,但查询慢 |
| PERFORMANCE_SCHEMA | 主要用于收集数据库服务器性能参数 |
| FEDERATED | 将不同的 MySQL 服务器联合起来,逻辑上组成一个完整的数据库。非常适合分布式应用 |
2.2 常用命令
| 命令 | 描述 |
| show databases | 查看所有的数据库 |
| use 数据库名 | 切换数据库 |
| show tables | 查看当前数据库中所有的表 |
| \h | 查看帮助 |
| exit/quit | 退出 |
| net start 服务名 | 开启服务 |
| net stop 服务名 | 停止服务 |
3 SQL简介
SQL(Structured Query Language):结构化的查询语言,用于操作和管理数据库。
SQL分类如下:
| DDL数据定义语言 | create/drop/alter/rename/truncate |
| DML数据操作语言 | insert/delete/update/select(DQL) |
| DCL数据控制语言 | grant/revoke |
| TCL事务控制语言 | start transaction/commit/rollback |
4 数据表
数据表就是一张二维表,一行也叫做一条“记录”,一列(域)也叫做一个“字段”或“属性”。
可以将一张表理解为一个类,表中的字段对应类中的属性。
4.1 数据类型
(1)数字类型
| 整型 | TINYINT | 大小:1字节 有符号范围:(-2^7,2^7-1) 无符号范围(0,255) |
| SAMLLINT | 小:2字节 有符号范围:(-2^15,2^15-1) | |
| MEDIUMINT | 小:3字节 有符号范围:(-2^23,2^23-1) | |
| INT | 小:4字节 有符号范围:(-2^31,2^31-1) | |
| BIGINT | 小:8字节 有符号范围:(-2^63,2^63-1) | |
| 浮点型(m:代表长度,n:代表小数的位数) | FLOAT(m,n) | 单精度 |
| DOUBLE(m,n) | 双精度 | |
| 定点型 | DECIMAL(m,n) | 用于存放对精度有要求的数据 |
注意:int(n)n代表的是表示 SELECT 查询结果集中的显示宽度,并不影响实际的取值范围,默认为11。
浮点型的计算结果可能不精确:如1.12454525451+1.25441424= 1.37212512105451.
浮点型的(m,n)省略的话按实际值计算,定点型省略的话按默认的(10,0)
(2)常用字符串
| CHAR(n) | 定长, 若存入字符数小于n,则以空格补于其后,查询之时再将空格去掉。所以 char 类型存储的字符串末尾不能有空格 |
| VARCHAR(n) | 变长 |
| TEXT | 可变,用于大文本 |
char(n) 与varchar(n)区别: name char(10) abc会出现7个空字符;name varchar(10) abc 只用3个空间不出现空字符
(3)日期类型
| DATE | 年月日 |
| TIME | 时分秒 |
| DATETIME | 年月日时分秒 |
| TIMESTAMP | 时间戳 |
| YEAR | 年份 |
(4)特殊类型
| SET() | 在·此范围内取任意个值 |
| ENUM() | 在此范围内取任意一个值 |
| BIT | 0/1 |
5 常用的一些DDL数据定义语言
5.1 操作数据库
创建库语法:CREATE DATABASE [IF NOT EXISTS] 数据库名
删除库语法:DROP DATABASE [IF EXISTS] 数据库名
5.2 操作表
创建表语法:CREATE TABLE [IF NOT EXISTS] 表名 (列名1 类型(长度) 约束,列名1 类型(长度) 约束)
删除表:DROP TABLE [IF EXISTS] 表名
查询表结构:DESC 表名
表结构添加新列:ALTER TABLE 表名 ADD 列名 类型(长度) 约束 (FIRST(表的第一个位置)|ALTER(指定字段后)|默认最后一个位置)
表结构中列的删除:ALTER TABLE 表名 DROP 列名
表结构的修改:ALTER TABLE 表名 CHANGE 原列名 新列名 类型(长度)
修改表名:RENAME TABLE 原表名 TO 新表名
清空表中的数据:TRUNCATE [TABLE] 表名
6 完整性约束
完整性约束是为了保证数据表中的数据是准确有效的
6.1 实体完整性
实体完整性约束的是是行(一条记录),确保这一条记录是唯一不可重复的。
(1)主键约束(唯一的标识)
①创建表结构时添加主键
CREATE TABLE IF NOT EXISTS student
(
sid int PRIMARY KEY,
`name` VARCHAR(20) NOT NULL,
)
CREATE TABLE IF NOT EXISTS student
(
sid int NOT NULL,
`name` VARCHAR(20) NOT NULL,
PRIMARY KEY(sid)
)②修改表结构时添加主键
ALTER TABLE student
ADD CONSTRAINT pk_sid PRIMARY KEY(sid)③组合主键(多个列组成主键)
ALTER TABLE student
ADD CONSTRAINT pk_sid_name PRIMARY KEY(sid,name)(2)唯一约束
①创建表结构时添加唯一约束
CREATE TABLE IF NOT EXISTS student
(
sid INT PRIMARY KEY,
`name` VARCHAR(20) NOT NULL,
scard CHAR(18) UNIQUE
)
CREATE TABLE IF NOT EXISTS student
(
sid int NOT NULL,
`name` VARCHAR(20) NOT NULL,
scard CHAR(18),
UNIQUE(scard)
)②修改表结构时添加唯一约束
ALTER TABLE student
CHANGE icard icard CHAR(18) UNIQUE(3)自增长:不能单独使用,必须配合索引一起使用,并且数据类型必须是整型的。实现自增的原理是该列的最大值+1,把最大值的列删除了,下一个添加进来的数据仍然在原来最大值的基础上+1。默认的起始值是1,可以给自增长的列插入数据改变初始值。如果要重置起始值需要 TRUNCATE TABLE 表
CREATE TABLE IF NOT EXISTS student
(
sid INT PRIMARY KEY AUTO_INCREMENT
)
主键约束与唯一约束的区别:主键不能为空,唯一约束可以为空。
6.2 域完整性
保证列的数据准确有效
(1)列的类型
(2)非空约束 NOT NULL
(3)默认约束DEFAULT ‘默认值’
创建表结构时添加约束
CREATE TABLE [IF NOT EXISTS] student
(
sid INT PRIMARY KEY AUTO_INCREMENT
sname VARCHAR(10) NOT NULL,
gender CHAR(1) DEFAULT '男'
)修改表时添加
ALTER TABLE student CHANGE gender gender CHAR(1) DEFAULT '女'6.3 引用完整性
约束两个表或多个表中的关联数据
语法:
ALTER TABLE 外键表 ADD CONSTRAINT 外键约束名 FOREIGN KEY(外键表的列名)
REFERENCES 主键表(主键表主键列)
6.4 自定义完整性
mysql不支持
支持的数据库使用CHECK关键字实现,如限定年龄18-24岁的学生
| ALTER TABLE student ADD CONSTRAINT ck_age CHECKE age>=18 and age<=24 |
7 运算符
7.1 算术运算符
| 算术运算符 | 描述 |
| + (加) | SELECT 1+2 #3 |
| - (减) | SELECT 2-1 #1 |
| * (乘) | SELECT 1*2 #2 |
| / (除,按实际值) | SELECT 1/2 #0.5 |
| div (除,取整) | SELECT 3 div 2 #1 |
| % (取余) | SELECT 3%2 #1 |
| mod (取模) | SELECT 3 mod 2 #1 |
注意:在java中%取余是向0取整,mod取模是向下取整,但在mysql中他们的结果是一样的
7.2 比较运算符
| 比较运算符 | 案例 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
| = | 等于 |
| != | 不等于 |
| <> | 不等于 |
| IS TRUE/IS NOT TRUE | 判断是否正确/是否不正确 |
| IS NULL/IS NOT NULL | 判断是否为空/是否不为空 |
| BETWEEN...AND... | 判断是否在两者之间 |
| IN/NOT IN | 判断是IN列表里的值/不是IN列表里的值 |
| LIKE | 通配符匹配 |
| REGEXP | 正则表达式匹配 |
7.3 逻辑运算符
| 逻辑运算符 | 描述 |
| AND | 逻辑与,非0非空则为1,有0则为0 |
| OR | 逻辑或,有1则1,非0非空,值为1,全0为0,全空为空 |
| NOT | 逻辑非,0则为1,1则为0,空值为空 |
7.4 位运算符
| 位运算符 | 描述 |
| | | 按位与 |
| & | 按位或 |
| ^ | 位异或 |
| << | 位左移 |
| >> | 位右移 |
| ~ | 位反转 |
8 DML数据操作语言

下列操作的表结构基于这张表,表名是student
8.1 增加数据
语法:INSERT INTO 表名[(列名1,列名2...)] VALUES(列值1,列值2...)
(1)全列插入(列值对应没一个列名)
| INSERT INTO student VALUES(10,'小明',18,'男') |
(2)指定列名插入
| INSERT INTO student(sname,age) VALUES('小红',20) |
(3)批量插入
| INSERT INTO student(sname,age) VALUES('小刚',19),VALUES('小朋',21) |
(4)选择表数据插入(数据备份)
| INSERT INTO student_bak SELECT * FROM student; INSERT INTO studet_bak(sname,age) SELECT sname,age FROM student; |
(5)创建表插入(有数据)
| CREATE TABLE student_new SELECT * FROM student |
(6)创建表插入(无数据,复制数据结构)
| CREATE TABLE student_new SELECT *FROM student WHERE 1=2 |
8.2 删除数据
语法:DELETE FROM 表名 WHERE 条件
(1)删除所有数据
| DELETE FROM student_bak TRUNCATE TABLE student_bak; |
(2)删除指定数据
| DELETE FROM student_bak WHERE sname='小明' |
注意:DELETE删除表与TRUNCATE删除表的区别:
①DELETE删除:一行一行的删除,效率低,不会重置自增长
②TRUNCATE删除:一次性删除所有数据,会重置自增长
8.3 修改数据
语法:UPDATE 表名 SET 列名1=列值[,列名2=列值] WHERE 条件
| UPDATE student_bak SET sname='欢欢',age=18 WHERE gender='' |
8.4 查询数据
语法:SELECT 列名1,列名2.. FROM 表名
[WHERE 条件]
[GROUP BY 分组的筛选条件]
[HAVING 分组后的筛选条件]
[ORDER BY 排序的字段 (ASC|DESC) 默认(ASC)升序]
[LIMIT index,len index:起始值(默认0) len: 长度 ]
MySQL的执行顺序和SQL的内部执行机制除了别名的引用外是一样的
SQL执行顺序:①FROM-->②ON-->③JOIN-->④WHERE-->⑤GROUP BY(select中的别名从这可以使用,他返回的是一个游标,而不是一个表,所以在where中不可以使用select中的别名,而having却可以使用)-->⑥AVG,SUM-->⑦HAVING-->⑧SELECT-->⑨DISTINCT-->⑩ORDER BY-->⑪LIMIT
(1)查询所有数据,如查询所有学生信息
| SELECT * FROM student |
(2)查询指定列的数据,如查询学生的姓名和年龄
| SELECT sname,age FROM student |
(3)条件查询(当一),如:查询年龄大于16岁学生
| SELECT * FROM student WHERE age>16 |
(4)条件查询(多),如:查询年龄大于16岁的男学生
| SELECT * FROM student WHERE age>16 AND gender='男' |
(5)设置别名
| SELECT sid as 编号,sname 名字 FROM student s WHERE age>16 AND gender='男 |
(6)去重distinct,如去重年龄与姓名一样的学生
| SELECT DISTINCT sname,age FROM student |
(7)模糊查询 LIKE,%代表匹配任意个字符,如查询所有名字含s的学生
| SELECT sid,sname,age,gender FROM student WHERE sname LIKE '%s%' |
(8)模糊查询 LIKE,_代表匹配一个字符,如名字的第二为为s的学生
| SELECT sid,sname,age,gender FROM student WHERE sname LIKE '_s%' |
(9)非空查询,如性别不为空
| SELECT sid,sname,age,gender FROM student WHERE gender<>'' AND gender IS NOT NULL |
(10)范围查询,如年龄再16-24岁之间的学生
| SELECT sid,sname,age,gender FROM student WHERE age>=16 AND age <=24 #等价于 SELECT sid,sname,age,gender FROM student WHERE age BETWEEN 16 AND 24 |
(11)集合插叙,IN关键字
| SELECT sid,sname,age,gender FROM student WHERE sname IN('小明','小红','小张') #等价于 SELECT sid,sname,age,gender FROM student WHERE sname='小明' OR sname='小红' OR sname='小张' |
(12)排序,如按年龄升序排序,如果年龄一样按编号降序排序
| SELECT sid,sname,age,gender FROM student ORDER BY age ,sid DESC |
(13)限制查询结果集,LIMIT关键字
| #LIMIT m,n:m代表开始索引(默认从0开始),n代表长度 SELECT sid,sname,age,gender FROM student ORDER BY age ,sid DESC LIMIT 2,2 |
9 单行函数
(1)常用数学函数
| 数学函数 | 描述 |
| ABS() | 绝对值 |
| CEILING()/CEIL() | 向上取整,最接近并且大于等于该值的整数 |
| FLOOR() | 向下取整,最接近并且小于等于该值的整数值 |
| MOD(m,n) | m对n取模 |
| POW(m,n) | 取m的n次方 |
| RAND() | 取随机值 |
| ROUND(m,n) | 四舍五入,保留n位的小数,位数不够则补零,n为负数则保留小数点左边n位 |
| TRUNCATE(m,n) | 截取m小数后n位 |
注意:java中的Math.round(m)的四舍五入的原理是在参数上加0.5然后进行下取整。
(2)常用字符函数
| 字符函数 | 描述 |
| ASCII(str) | 获取str的ASCII码值 |
| LOWER(字段/表达式) | 将字符串转换为小写 |
| UPPER(字段/表达式) | 将字符串转换为大写 |
| LENGTH(字段/表达式) | 获得字符串的长度 |
| SUBSTRING(str,index,len) | 截取str,index为起始位置,len为长度 |
| CONCAT(str1,str2...) | 将字符串连接 |
| REPLACE(str,old,new) | 将str中的old替换成new |
| LPAD(str,len,s) | str的长度不够len,用s左填充 |
| RPAD(str,len,s) | str的长度不够len,用s右填充 |
(3)常用日期函数
| 日期函数 | 描述 |
| NOW()/SYSDATE() | 获取当前日期时间 |
| CURRENT_DATE()/CURDDATE() | 获取当前系统日期 |
| CURRENT_TIME()/CURDTIME | 获取当前系统时间 |
| DATE_ADD(date,INTERVAL expr unit) | 日期装换,返回一个新的日期 |
| DATEDIFF(expr1,expr2) | 两个日期差,返回天数差 |
| DAY(date) | 获取date,所在月的天数 |
| MONTH(date) | 获取date所在年的月份 |
| YEAR(date) | 获取date所在的年份 |
| WEEK(date) | 返回一年的周数 |
| WEEKDAY(date) | 返回date所在周的第几天(0-6) |
| LAST_DAY(date) | 获取date所在月的最后一天 |
DATE_ADD(date,INTERVAL expr unit):interval:时间间隔类型关键字 expr:时间间隔类型对应的表达式 unit:”时间间隔类型。SELECT DATE_ADD(SYSDATE(),INTERVAL -2 DAY); 表示当前日期时间减2天。
10 分组函数
(1)常用聚合函数
| 函数名 | 描述 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| COUNT() | 统计() |
注意:sum,avg,max,min对NULL是忽略的是不进行统计的;count(*)和count(1)是对表中的函数统计,而不管一行中是否有null,count(列名)对特定列进行统计会忽略null值。
count(*),count(1),count(列名)的区别:
有 Where 条件的 count,会根据扫码结果count 一下所有的行数,其性能更依赖于你的 Where 条件,所以以下没有 Where 的情况进行说明。
count的含义:对SELECT的结果集进行计数,但是需要参数不为NULL。count(*) ,他不关心这个返回值是否为空都会计算他的count,因为 count(1) 中的 1 是恒真表达式,也不关系返回值是否为空,那么 count(*) 还是 count(1) 都是对所有的结果集进行 count,所以他们本质上没有什么区别。
count(column) 也是会遍历整张表,但是不同的是它会拿到 column 的值以后判断是否为空,然后再进行累加,那么如果针对主键需要解析内容,如果是二级所以需要再次根据主键获取内容,又是一次 IO 操作,所以 count(column) 的性能肯定不如前两者喽,如果按照效率比较的话:count(*)=count(1)>count(primary key)>count(column)
总结:在表没有主键时,count(1)比count(*)快;有主键时,主键作为计算条件,count(主键)效率最高;若表格只有一个字段,则count(*)效率较高。
(2)分组处理
GROUP BY 分组字段
HAVING 分组后的筛选
11 高级查询
此章节所操作的表如下

employee员工表
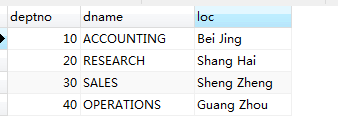
department部门表
11.1 关联查询(连接查询)
(1)笛卡尔积
A表中的数据*B表中的数据
| SLECT * FROM employee,department |
(2)内联查询
找两表等值条件数据,与主从表无关
①内联查询 WHERE
| #查询员工信息及其对应的部门信息 SELECT * FROM employee e,department d WHERE e.deptno=d.deptno |
②INNER JOIN...ON... (表名 INNER JOIN 表名 ON 主.主键=外.外键)
| #查询员工信息及其对应的部门信息 SELECT * FROM employee e INNER JOIN department d ON e.deptno=d.deptno |
③USING()两表中有同名的主外键
| #查询员工信息及其对应的部门信息 SELECT * FROM employee e INNER JOIN department d USING(deptno) |
注意:内联查询和INNER JOIN...ON...会保留两表中的关联字段,使用USING()生成的表会去掉重复列
(3)自然连接查询
寻找两表中相同字段名称相等的字段进行连接,会自动去掉重复列。关键字NATURAL
| SELECT * FROM employee NATURAL JOIN department |
(4)外连接查询
有主从表之分,与连接顺序有关。以驱动表为依据,匹配表一次进行查询;匹配表中找不到数据则用NULL填充
左外连接:LEFT [OUTER] JOIN ...ON... 左边为驱动表
| #查询部门中员工信息,员工表为驱动表 SELECT * FROM employee e LEFT OUTER JOIN department d ON e.deptno=d.deptno |
右外连接:RIGHT [OUTER] JOIN ...ON... 右边为驱动表
| #查询部门中员工信息,部门表为驱动表 SELECT * FROM employee e RIGHT OUTER JOIN department d ON e.deptno=d.deptno |
(5)自查询
自查询需要两张表,只不过他的驱动表和匹配表都是自己,做连接查询的时候是自己和字节连接,分别给两个表区不同的名字。
| #查询员工及其上级姓名 SELECT e1.ename 员工,e2.ename 上级 FROM employee e1,employee e2 WHERE e1.mgr=e2.empno#会丢失没有上级的员工 SELECT e1.ename 员工,e2.ename 上级 FROM employee e1 LEFT JOIN employee e2 ON e1.mgr=e2.empno#输出全部员工 |
11.2 子查询
子查询即嵌套查询,将一个查询结果作为另一个查询条件或组成部分的查询
(1)单行子查询:子查询中只查出一行一列的数据,返回值可以用< > <= >= =
| #查询工资大于6698号员工的所有员工信息 SELECT * FROM employee WHERE sal>(SELECT sal FROM employee WHERE empno='6698') #查询超过其所在部门平均工资的员工信息 SELECT * FROM employee e1 ,(SELECT deptno,avg(sal) avg FROM employee e2 GROUP BY employee ) e2 WHERE e1.deptno=e2.deptno AND e1.sal>e2.avg #等同于 SELECT * FROM employee e1 WHERE e1.sal>(SELECT avg(sal) avg FROM employee e2 WHERE e1.deptno=e2.deptno) #等同于 SELECT * FROM employee e1 WHERE e1.sal>(SELECT avg(sal) FROM employee e2 GROUP BY e2.deptno HAVING e1.deptno=e2.deptno) |
(2)多行子查询:子查询中查出多行一列的值,返回值可以用 IN,ANY,ALL
=ANY相当于IN,<ANY 小于最大值,>ANY大于最小值
<>ALL相当于NOT,<ALL小于最小值,>ALL大于最大值
| #查询10号部门的员工工资(不包含最高工资)的员工信息 SELECT * FROM employee WHERE <ANY(SELECT sal FROM employee WHERE deptno=10) AND deptno=10 #查询大于10号部门最高工资的的员工信息 SELECT * FROM employee WHERE sal>ALL(SELECT sal FROM employee WHERE deptno=10) #等价于 SELECT * FROM employee WHERE sal>(SELECT MAX(sal) FROM employee WHERE deptno=10) |
(3)EXISTS
EXISTS用于查询子查询是否最少返回一条数据,该子查询实际并不返回任何数据,而是返回TRUE或FALSE。如果父查询有n条数据,EXISTS就是将这n条数据逐条取出,然后判断n遍EXISTS条件。
| SELECT * FROM employee WHERE EXISTS(SELECT 1) #对employee表的记录逐条取出,由于SELECT 1永远能返回记录行,那么employee的所有记录都将被加入结果集,所以与SELECT * FROM employee是一样的 |
有两表A(小表),B(大表)。大小表,查询大表用EXISTS,小表用IN。这样效率更高。
| SELECT * FROM B WHERE abc IN(SELECT abc FROM A)#用到B表上的abc列索引 SELECT * FROM A WHERE EXISTS(SELECT abc FROM B WHERE abc=A.abc)#用到B表上的abc列索引 |
IN与EXISTS的区别:
(1)IN先进行子查询再父查询,EXISTS先进行父查询再进行子查询
(2)当两表的大小差不多时用IN和EXISTS差别不大。如果是大小表,查询大表用EXISTS,小表用IN。
(3)NOT IN和NOT EXISTS:如果查询用到NOT IN内外表都需要进行全表扫描,索引失效,而NOT EXISTS的子查询依然可以使用索引,所以NOT EXISTS比NOT IN快。
11.3 联合查询
UNION(去重)/UNION ALL(包含重复项)
适用于要查询的结果来自多个表,并且多个表没有直接的连接关系,但是查询信息一直。
特点:要求查询语句的列数是一致的;要求多条查询语句的每一列的类型和顺序最好一致,
| #查询员工工资大于3000,或部门编号为10的员工姓名 SELECT ename FROM employee WHERE sal>3000 UNION SELECT ename FROM employee WHERE deptno=10 |
12 事务
12.1 什么是事务
事务(Transaction):用于保证数据的一致性,由一组DML操作组成,该组的SQL语句要么同时成功要么同时失败
12.2 事务的ACID特性
(1)原子性(Atomicity):在事务中的SQL语句是一个整体,要么同时成功,要么同时失败
(2)一致性(Consistency):事务在执行前后保持一致性
(3)隔离性(Isolation):并发时事务之间是彼此独立的
(4)持久性(Durability):数据操作完成,数据会永久保存
12.3 并发事务产生的问题
(1)脏读:一个事务中读到另一个事务中未提交的数据
(2)不可重复读:在一个显式事务中,一个事务读到另一个事务已修改的提交数据,导致两次读取数据不一致
(3)幻读:在一个显式事务中,一个事务读到另一个事务已添加的数据
不可重复读与幻读的区别:两者产生的结果都是前后数据不一致,但对于不可重复读可以针对查询的那条语句加锁,即行锁,保证只有当前事务能对这条记录进行更新,删除等,就可以重复读。要消灭幻读则要锁住整张表,保证当前操作的时候不会有其他事务对表进行INSERT操作
12.4 事务的隔离级别
(1)读未提交
(2)读已提交:可解决脏读,oracle默认
(3)可重复读:可解决脏读和不可重复读,mysql默认
(4)串行化:可解决所有并发产生的问题,但是性能低
12.5 修改事务的隔离级别
查看数据库的隔离级别select @@tx_isolation
语法:SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}
mysql> set global transaction isolation level read committed; //全局的
mysql> set session transaction isolation level read committed; //当前会话
12.6 修改事务提交方式
查看提交方式:show variable like 'autocommit'
设置提交方式为手动提交(隐式事务):set Autocommit=0
设置提交方式为手动提交(显式事务):start transaction(打开显式事务) commit(提交事务) rollback(回滚)
13 存储程序
是指一组存储和执行在数据库服务端的程序。程序的存储总是在服务器的进程或线程的内存中执行。
程序存储分为:
(1)存储过程:类似于java中的方法,有输入输出参数,可以执行一组SQL语句
(2)存储函数:有一个返回值,可以对SQL进行有效的扩张
(1)触发器:指事件响应,比如执行INSERT语句后执行另外一个动作
13.1 存储过程
语法:
| DELIMITER // #申明存储语句结束符,用于区分; CREATE PROCEDURE 存储过程名([[IN |OUT |INOUT ] 参数名 数据类形…])) #声明存储过程 BEGIN #存储过程开始 ... #存储过程体 END // #存储过程结束 SET @参数名=值 #变量赋值 [DECLARE 参数名 数据类型 UNSIGNED DEFAULT 100] #变量定义 |
存储过程的参数有三种,IN,OUT,INOUT,形式如下:
CREATE PROCEDURE 存储过程名([[IN |OUT |INOUT ] 参数名 数据类形…]))
IN:输入参数,表示该的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值
OUT:输出参数,该值可在存储过程内部被改变,并可返回
INOUT:输入输出参数调用时指定,并且可被改变和返回
#根据部门编号查询部门信息
DELIMITER //
CREATE PROCEDURE InfoEmp(dno INT) #默认IN输入参数
BEGIN
SELECT * FROM employee WHERE deptno=dno;
END; //
CALL InfoEmp(10) #调用#根据部门编号查询部门名称
DELIMITER //
CREATE PROCEDURE dnameEmp(dno INT,OUT dept_name VARCHAR(25)) #默认IN输入参数
BEGIN
SELECT dname INTO dept_name FROM department WHERE deptno=dno;
END; //
CALL dnameEmp(10,@dname); #调用
SELECT @dname;#根据用户编号查询用户工资
DELIMITER //
CREATE PROCEDURE querysal(INOUT result INT)
BEGIN
DECLARE num INT; #定义变量
SET num=10; #给变量赋值
SELECT sal INTO result FROM employee WHERE empno=result;
END; //
SET @num=6120;
CALL querysal(@num); #调用
SELECT @num
查看数据库中的过程函数命令:SHOW PROCEDURE STATUS WHERE db='数据库名';
查询过程函数详细信息:SHOW PROCEDURE STATUS 数据库名.存储过程名;
13.2 存储过程的控制语句
(1)分支结构:if …. then ….end if
DELIMITER //
CREATE PROCEDURE scoreLevel(num INT)
BEGIN
DECLARE level VARCHAR(20);
IF num>90 THEN
SET level = '优秀';
ELSEIF num>80 THEN
SET level = '良好';
ELSEIF num>70 THEN
SET level = '中';
ELSEIF num>60 THEN
SET level = '及格';
ELSE
SET level = '不及格';
END IF;
SELECT level;
END;//
#调用
CALL scoreLevel(80)(2)循环结构:①while… do …end while;②loop …..end loop ;③repeat …. end repeat;
#输出1-N的奇数和
DELIMITER //
CREATE PROCEDURE sumUneven(num INT,OUT numSum INT)
BEGIN
DECLARE sum INT;
DECLARE i INT;
SET sum=0;
SET i=1;
WHILE i<num DO
IF(i%2<>0) THEN
SET sum =sum + i;
END IF;
SET i = i+1;
END WHILE;
SET numSum=sum;
END;//
#调用
CALL sumUneven(10,@sum);
SELECT @sum;
②loop …..end loop ;
loop循环不需要初始条件,这点和while 循环相似,同时和repeat循环一样不需要结束条件, leave语句的意义是离开循环。
DELIMITER //
CREATE PROCEDURE sumLoop(num INT,OUT numSum INT)
BEGIN
DECLARE sum INT;
DECLARE i INT;
SET sum=0;
SET i=1;
a:LOOP #a:标记
IF(i%2<>0) THEN
SET sum =sum + i;
END IF;
IF i>=num THEN
LEAVE a;
END IF;
SET i = i+1;
END LOOP;
SET numSum=sum;
END;//
CALL sumLoop(10,@sum);
SELECT @sum;③repeat …. end repeat;
它在执行操作后检查结果,而while则是执行前进行检查。
DELIMITER //
CREATE PROCEDURE sumRepeat(num INT,OUT numSum INT)
BEGIN
DECLARE sum INT;
DECLARE i INT;
SET sum=0;
SET i=1;
REPEAT #a:标记
IF(i%2<>0) THEN
SET sum =sum + i;
END IF;
SET i = i+1;
UNTIL i>=num
END REPEAT;
SET numSum=sum;
END;//
CALL sumRepeat(10,@num);
SELECT @num;13.3 存储函数
只有一个输入类型,必须要有一个返回值,用于sql语句操作。
语法
| DELIMITER // #申明存储语句结束符,用于区分; CREATE FUNCTION 存储函数名(参数名 数据类形…])) #声明存储过程 RETURNS 返回类型 BEGIN #存储函数开始 ... #存储函数体 END // #存储函数结束 |
DELIMITER //
CREATE FUNCTION changeUpper(str VARCHAR(20))
RETURNS VARCHAR(20)
BEGIN
DECLARE newStr VARCHAR(20);
SELECT UPPER(str) INTO newStr;
RETURN newStr;
END;//
SELECT changeUpper(ename) FROM employee;1.3.4 存储函数与存储过程的区别
(1)返回值不同:存储过程可以返回一个或多个结果集,或者用来实现某种效果或动作而无需返回值。存储函数只能向调用者一个结果值。
(2)调用方式不同:存储过程一般是作为一个独立的部分来执行( EXECUTE 语句执行)只能通过call语句调用。存储函数嵌入在SQL使用,可以在SELECT中调用,就像内建函数一样,由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面,如MAX(),COS()等。SQL语句中不可用存储过程,而可以使用函数。
(3)参数不同:存储过程的参数类型有三种IN,OUT,INOUT。存储函数的参数类型类似于IN类型。
(4)限制不同:存储函数限制较多如不能使用临时表,只有使用表变量,还有一些函数不可用等,而存储过程则限制相对较少,一般存储过程实现的的功能要复杂一下,而存储函数实现的功能针对性较强。
13.5 触发器
触发器是一类特殊的事务,可以监视某种数据操作(INSERT/UPDATE/DELETE),并触发相关相关操作(INSERT/UPDATE/DELETE)。
创建触发器语法四要素:监视地点(TABLE),监视时间(AFTER/BEFORE),监视事件(INSERT/UPDATE/DELETE),触发事件(INSERT/UPDATE/DELETE)。
语法:
| CREATE TRIGGER 触发器名称 AFTER/BEFORE #触发时间 INSERT/UPDATE/DELETE #监视事件 ON 表名 #监视地址 FOR EACH ROW BEGIN sql1; ... sqlN; END |
#删除后保存到备份表
CREATE TRIGGER delStudent
AFTER DELETE
ON student FOR EACH ROW
BEGIN
INSERT INTO student_bak VALUES(OLD.sid,OLD.sname,OLD.age);
END;
#执行删除操作
DELETE from student where sid = 1;触发器引用行变量总结:对于INSERT操作而言,本来并没有数据,插入了数据那行就是新的,只能用NEW来引用;而对于DELETE而言,原本这行是有的,删除了就没有了,所以曾经这行就叫做OLD,并且只能用OLD来引用;对于UPDATE而言这一行由旧到新,所以这一行曾经的数据用OLD来引用,UPDATE之后的数据用NEW来引用。另外OLD是只读的,而NEW则可以在触发器中使用 SET 赋值
触发器尽量少的使用,因为不管如何,它还是很消耗资源,如果使用的话要谨慎的使用,确定它是非常高效的:触发器是针对每一行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源。
查看触发器命令:SHOW TRIGGERS。查看具体触发器命令:SELECT * FROM information_schema.triggers。删除触发器命令:DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name。
14 视图
(1)什么是视图:通俗的讲,视图就是一条SELECT语句执行后返回的结果集。视图是一张虚拟表,并不在数据库中以存储数据集的方式存在,在引用过程中依赖于基本表中动态生成。基本表数据发生了改变,视图也会跟着改变,可以跟基本表一样,进行增删改查操作但是有限制
(2)视图的作用(好处):①方便操作,特别是查询操作,减少复杂的SQL语句,增加可读性,提高效率;②更加安全,数据库授权命令不能限定到指定的行和列,但通过合理创建视图,可以把权限限定到行列级别。③可以定制数据;④可以和其他表关联操作
(3)使用场景:①关键信息来源多个复杂的关联表,可以创建视图提取我们想要的信息,简化操作;②权限控制的时候不希望用户访问表中的某些敏感信息的列。
(4)创建视图表:
语法格式:
| CREATE [OR REPLACE] [ALGORITHM={UNDEFIEND | MERGE | TEMPTABLE}] VIEW view_name [(column_list)]
参数说明 |
CREATE OR REPLACE VIEW v_emp
AS
SELECT * FROM emp WHERE deptno=10
WITH CHECK OPTION注意:如查创建视图时有where条件则 with check option 子名可以保证只能视图条件之内对视图进行修改(修改后要视图查询的到,查询不到不能修改)。如·UPDATE v_graph SET deptno =10 WHERE empno=’6270’ #不能修改会报错
UPDATE v_graph SET ename =’aa’ WHERE empno=’6270’ #可以修改。

多表联查生成视图的时候不能有同名的字段,INNER JOIN..ON..这样就不行,用INNER JOIN ...USING()...就可以
15 索引
(1)什么是索引:索引表中一列或多列的值进行排序的一种存储结构,它是表中一列或多列的值的集合,而且其中包含了对应表中记录的引用指针。就像书的目录一样,提高了查询效率。
注意:索引也是表的组成部分,太多的索引将会影响更新和插入的速度,因为它需要同样更新每个索引文件。对于一个经常需要更新和插入的表格,就没有必要为一个很少使用的where字句单独建立索引了,对于比较小的表,排序的开销不会很大,也没有必要建立索引。
(2)索引的分类:索引是在存储引擎中实现的,不同的存储引擎使用不同的索引。
MyISAM和InnoDB存储引擎:只支持BTREE索引, 不能更换(InnoDB:叶子节点存“数据”。MyISAM:叶子节点存“地址”)
MEMORY/HEAP存储引擎:支持HASH和BTREE索引。
将索引我们分为四类单列索引(普通索引,唯一索引,主键索引)、组合索引、全文索引、空间索引。
①单列索引:一个索引只包含单个列,但一个表中可以有多个单列索引。
a:普通索引:基本索引类型,没什么限制,允许在定义索引的列中插入重复值和空值。
b:主键索引:是一种特殊的唯一索引,不允许有空值。创建完主键约束会默认添加主键索引
c:唯一索引:索引列中的值必须是唯一的,但是允许为空值。创建唯一约束默认也会添加唯一索引
②组合索引:在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合。
③全文索引:在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT等字符类型字段上使用全文索引,就是在一堆文字中,通过其中的某个关键字等,就能找到该字段所属的记录行
④空间索引:空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有四种,GEOMETRY、POINT、LINESTRING、POLYGON。在创建空间索引时,使用SPATIAL关键字。要求,引擎为MyISAM,创建空间索引的列,必须将其声明为NOT NULL。
(3)创建索引:
语法:
| CREATE [TABLE 表名][字段名 数据类型] [UNIQUE|FULLTEXT|SPATIAL|...] [INDEX|KEY] [索引名字] (字段名[length]) [ASC|DESC]
[CREATE TABLE 表名][字段名 数据类型]:普通建表语句 [UNIQUE|FULLTEXT|SPATIAL|...] :设置什么样的索引(唯一、全文等) [INDEX|KEY] :索引关键字 [索引名字] :索引名字 (字段名[length]) :对哪个字段进行索引 [ASC|DESC] :对索引进行排序 |
a:创建单例索引: CREATE UNIQUE INDEX 索引名 ON 表名(字段名(length)); 或ALTER TABLE 表名 ADD UNIQUE (字段名)
#创建普通索引
CREATE INDEX in_ename ON emp(ename)
等同于
ALTER TABLE emp ADD INDEX in_ename(ename)
#创建唯一索引
CREATE UNIQUE INDEX in_ename ON 表名(列名)
#主键索引一般在建表的时候创建b:组合索引:CREATE INDEX 索引名 ON 表名(字段名(length),字段名(length),...);
CREATE INDEX in_ename_job_sal ON emp(ename, job, sal);这个组合索引实际上包含了三个索引,查询的时候遵循mysql组合索引的"最左前缀"。
①不按索引最左列开始查询(多列索引) 例如index(index_1, index_2, index_3) where index_2= ‘abc’ 不使用索引,where index_2 = `abc` and index_3=`cba` 不能使用索引;②查询中某个列有范围查询,则其右边的所有列都无法使用查询(多列查询)Where index_1= ‘abc’ and index_2 like = ‘a%’ and index_3=’cda’ 改查询只会使用索引中的前两列,因为like是范围查询③不能跳过某个字段来进行查询,这样利用不到索引.
c:全文索引:ALTER TABLE 表名 ADD FULLTEXT(列1, 列2)。文本字段上(text)如果建立的是普通索引,那么只有对文本的字段内容前面的字符进行索引,其字符大小根据索引建立索引时申明的大小来规定.。如果文本中出现多个一样的字符,而且需要查找的话,那么其条件只能是 where column lick '%x%' 这样做会让索引失效。有了全文索引,就可以用SELECT查询命令去检索那些包含着一个或多个给定单词的数据记录了。
(4)删除索引::DORP INDEX 索引名 ON 表名
16 MySQL优化
16.1 避免索引失效
(1)Not Null/Null 如果某列建立索引,当进行Select * from emp where deptno is not null/is null。 则会是索引失效。
(2)索引列上不要使用函数, 如:SELECT Col FROM tbl WHERE substr(name ,1 ,3 ) = ‘ABC’(不使用,导致索引失效) SELECT Col FROM tbl WHERE name LIKE ‘%ABC%’ (不使用,导致索引失效)。SELECT Col FROM tbl WHERE name LIKE ‘ABC%’ (使用)。
(3)索引列上不能进行计算 如SELECT sal FROM emp WHERE sal/10 > 10 则会使索引失效
(4)索引列上不要使用NOT ( != 、 <> )如:SELECT sal FROM emp WHERE sal ! = 10 应该 改成:union。
16.2 用UNION代替OR(适用于索引列)
UNION:是将两个查询的结果集进行追加在一起,它不会引起列的变化。 由于是追加操作,需要两个结果集的列数应该是相关的,并且相应列的数据类型也应该相当的。UNION是去重的,如果不需要去重用UNOIN AL。
有多个索引列时,通常用UNION替换WHERE子句中的OR将会起到较好的效果. 对索引列使用OR将造成全表扫描。column没有被索引, 查询效率可能会因为你没有选择OR而降低
16.3 用EXISTS替代IN、用NOT EXISTS替代NOT IN
在子查询中, NOT IN子句将执行一个内部的排序和合并. 无论在哪种情况下, NOT IN都是最低效的(因为它对子查询中的表执行了一个全表遍历)。为了避免使用NOT IN, 我们可以把它改写成外连接(Outer Joins)或NOT EXISTS















 2078
2078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









