







使用pytorch实现线性回归
第五讲随笔
广播机制
例如不同形状矩阵之间相加,则会进行广播,扩张到同样的形状再进行运算
广播前:
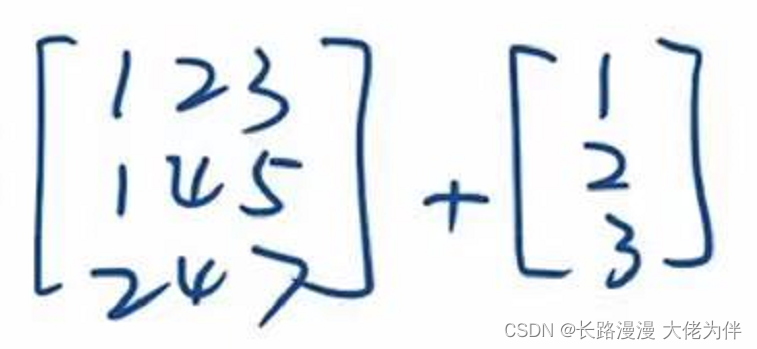
广播后:

下面也是采用了广播机制,y1,y2,y3并非一个向量,而是一个矩阵,因此w需要进行广播,再与x1,x2,x3进行数乘
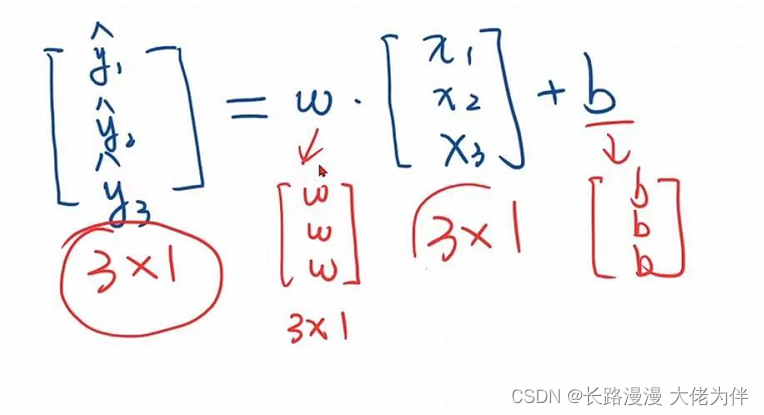
init构造函数
init构造函数用来初始化对象
简述 init、new、call 方法
用Module构造的对象,会自动根据计算图,实现backward的过程
使用pytorch实现线性回归
需要注意一些问题
- 1.#Module 中实现了forward,因此下方需要重写forward函数覆盖掉Module中的forward,因此LinearModel必须重写forward
# Module 中实现了forward,因此下方需要重写forward函数覆盖掉Module中的forward
# Linear 也构造于 Module,因此也是可调用对象
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
#torch.nn.Linear实际上在构造一个对象,包含了权重和偏置,继承自Module
# (1,1)是指每一个输入样本x和每一个输出样本y的特征维度,这里数据集中的x和y的特征都是1维的
# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
#self.linear(x) 在对象后面加()意味着实现了一个可调用对象
y_pred = self.linear(x)
return y_pred
- 如果将torch.nn.MSELoss的参数设置为size_average=False,在pycharm中会报错size_average and reduce args will be deprecated, please use reduction=‘sum’ ,可能是因为编译器的原因导致

# 构造损失函数和优化器MSE
# MSELoss也继承自 nn.Module
#criterion = torch.nn.MSELoss(size_average=False)中不能设置size_average=False,会出现以下报错
#UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # model.parameters()自动完成参数的初始化操作
- 模型训练的次数问题
如果需要减少训练集的损失,可以加大训练次数,即 for epoch in range(1000)
但是这种做法存在危险,因为训练集上的损失越来越小,测试集上的损失可能越来越大,产生过拟合问题
线性回归实现代码
import torch
# prepare dataset
# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
# Module 中实现了forward,因此下方需要重写forward函数覆盖掉Module中的forward
# Linear 也构造于 Module,因此也是可调用对象
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
#torch.nn.Linear实际上在构造一个对象,包含了权重和偏置,继承自Module
# (1,1)是指每一个输入样本x和每一个输出样本y的特征维度,这里数据集中的x和y的特征都是1维的
# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
#self.linear(x) 在对象后面加()意味着实现了一个可调用对象
y_pred = self.linear(x)
return y_pred
#model是一个callable,即可调用的对象,可以model(x)
model = LinearModel()
# 构造损失函数和优化器MSE
# MSELoss也继承自 nn.Module
#criterion = torch.nn.MSELoss(size_average=False)中不能设置size_average=False,会出现以下报错
#UserWarning: size_average and reduce args will be deprecated, please use reduction='sum' instead.
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # model.parameters()自动完成参数的初始化操作
# 如果需要减少训练集的损失,可以加大训练次数,即 for epoch in range(1000)
# 但是这种做法存在危险,因为训练集上的损失越来越小,测试集上的损失可能越来越大,产生过拟合问题
for epoch in range(100):
y_pred = model(x_data) # forward:predict
loss = criterion(y_pred, y_data) # forward: loss
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward() # backward: autograd,自动计算梯度
optimizer.step() # update 参数,即更新w和b的值
print('w = ', model.linear.weight.item())#weight是一个矩阵,所以取值需要调用item()
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
运行结果
0 35.37689208984375
1 15.92350959777832
2 7.260907173156738
3 3.402086019515991
4 1.6818101406097412
5 0.9135867357254028
6 0.569225549697876
。。。。。。。。。。。。
94 0.08291453868150711
95 0.08172288537025452
96 0.08054838329553604
97 0.07939067482948303
98 0.07824991643428802
99 0.07712534815073013
w = 1.8151198625564575
b = 0.4202759563922882
y_pred = tensor([[7.6808]])














 3621
3621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









