







想要抓取一个视频:
1. 找到m3u8 (各种手段)
2. 通过m3u8下载到ts文件
3. 可以通过各种手段(不仅是编程手段) 把ts文件合并为一个mp4文件
第一步找m3u8
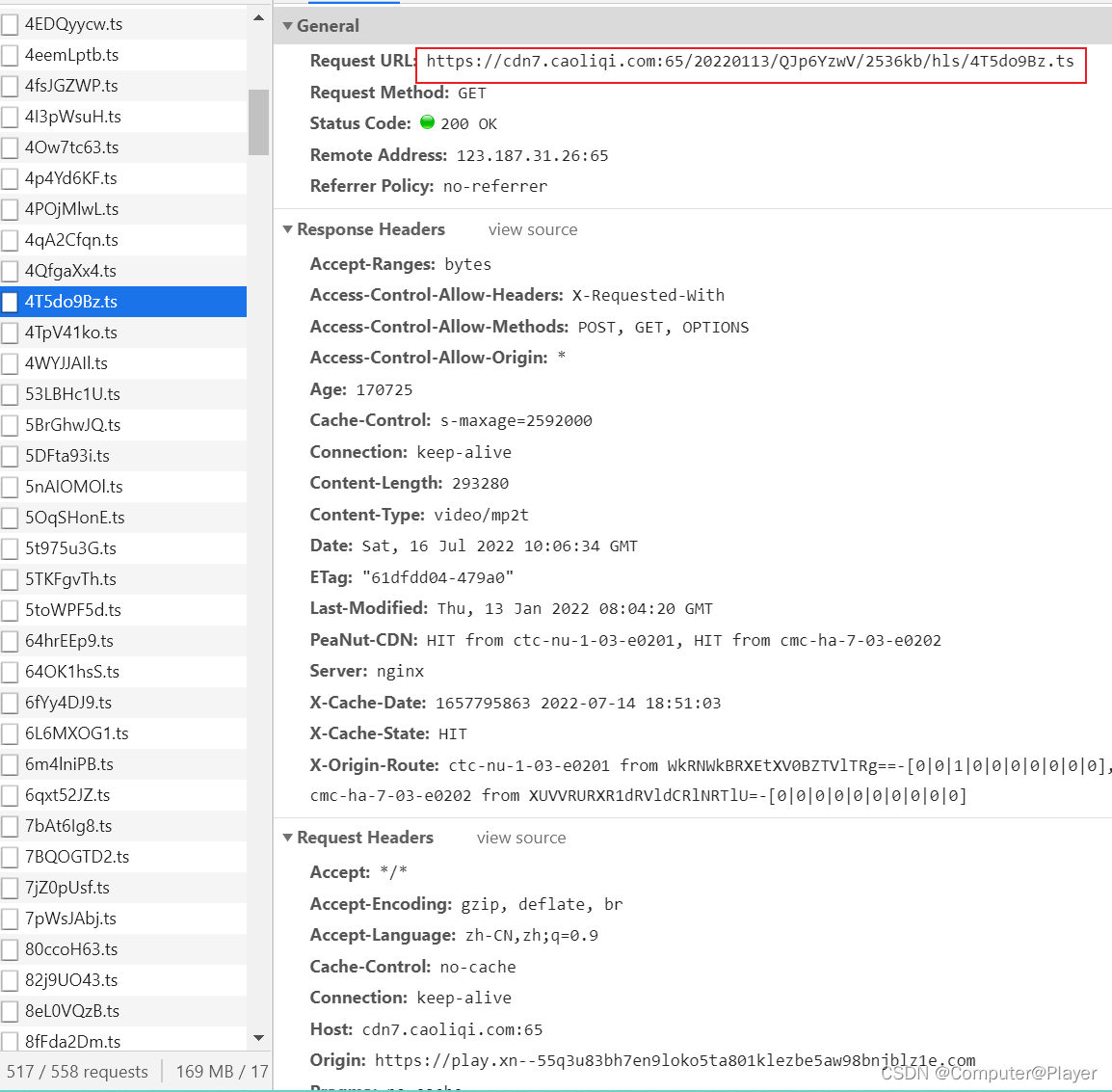
找一个视频网址,F12,点击视频某集,会弹出以下信息:
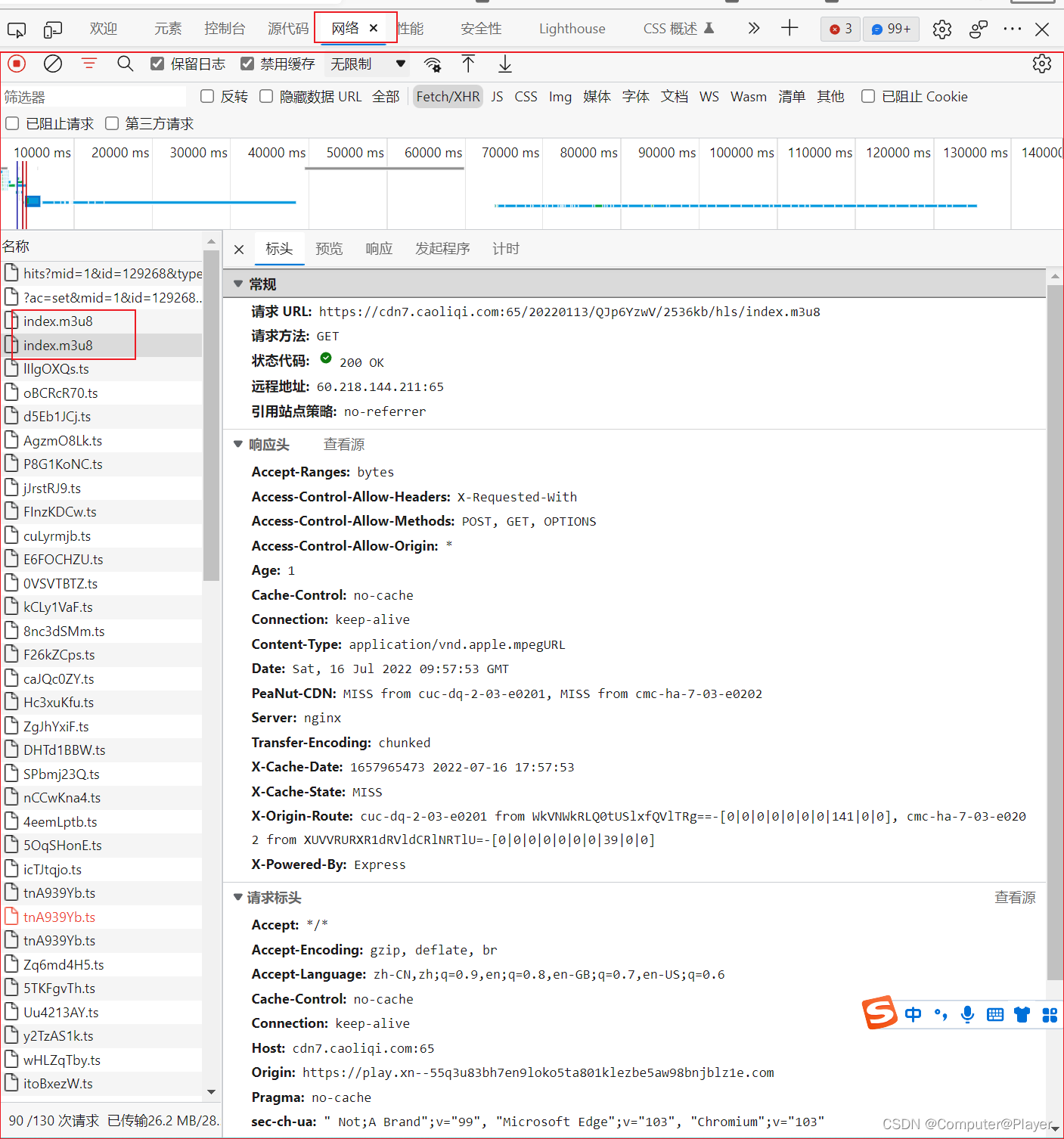
可以看到,找到了:
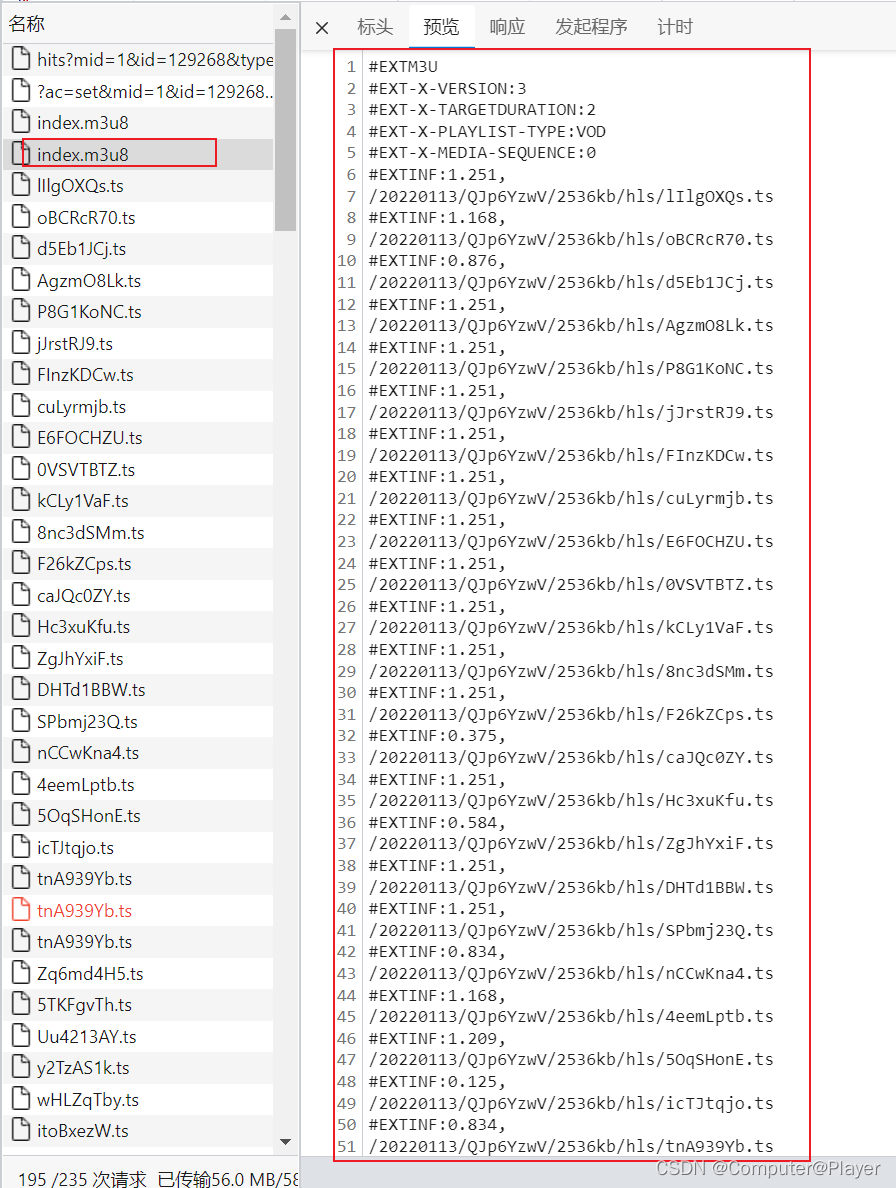
第一步先获取这个文件内容:
url='https://cdn7.caoliqi.com:65/20220113/QJp6YzwV/2536kb/hls/index.m3u8'
# UserAgent伪装
headers = {'User-Agent': str(UserAgent().random)}
resp = requests.post(url, headers=headers)
print(resp.text)
成功获取:

或者进行下载:
url='https://cdn7.caoliqi.com:65/20220113/QJp6YzwV/2536kb/hls/index.m3u8'
# UserAgent伪装
headers = {'User-Agent': str(UserAgent().random)}
resp = requests.post(url, headers=headers)
print(resp.content)
with open('chaoren.m3u8',mode='wb',) as f:
f.write(resp.content)
print('ok')

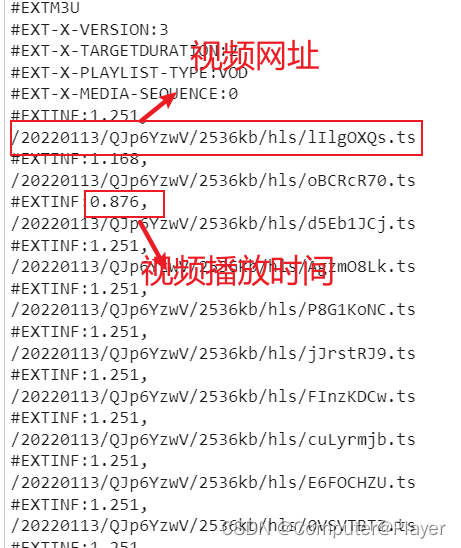
给的下载视频是一截网址
但详细地址可用找到:
可以继续下一步,将使用视频网址保存:
videourl=list()
with open('chaoren.m3u8',mode='r') as f:
for i in f:
if i.startswith('#'):
continue
ur='https://cdn7.caoliqi.com:65'+i.replace('\n','')
videourl.append(ur)
f.close()
print(videourl)

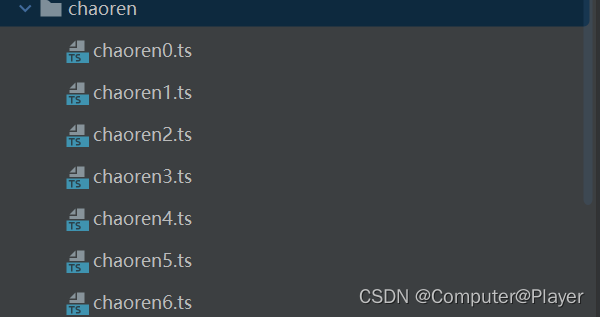
现在可以去下载一下视频:
n=0
for i in videourl:
resp3 = requests.get(i,headers=headers)
titl=f"chaoren/chaoren{n}.ts"
f = open(titl, mode="wb")
f.write(resp3.content)
f.close()
n+=1
if (n>10):
break
















 4915
4915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











