







 本文详细介绍了如何使用Python的PyPDF2库处理银行网站下载的多页PDF,包括读取PDF页数、获取指定页的宽高、裁剪单页和批量裁剪的功能,旨在提供一个模块化的代码基础,供开发者根据需求进行个性化调整。
本文详细介绍了如何使用Python的PyPDF2库处理银行网站下载的多页PDF,包括读取PDF页数、获取指定页的宽高、裁剪单页和批量裁剪的功能,旨在提供一个模块化的代码基础,供开发者根据需求进行个性化调整。

1. 背景📑
接PyPDF2模块推荐博文中提到的实际需求(将银行网站下载来的多页且单页多张回单的PDF裁剪成每张单据独立一个PDF文件),我决定将项目所做操作的模块化源码分享给大家
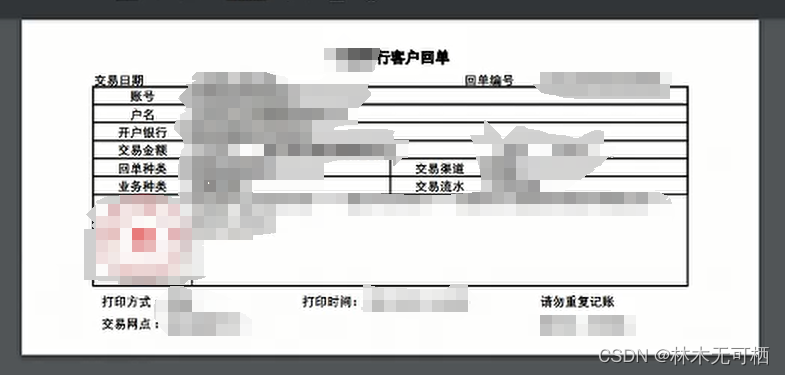
原PDF

裁剪后PDF
2. 源码模块解析📑
2.1 读取PDF页数
因为数据范围是动态的,所以每次处理的PDF页数也是不同的,操作一个回单PDF首先需要知道他有多少页
def get_page_num(pdf_path) -> int:
"""
获取PDF文件页数
params:
pdf_path: 需要读取页数的PDF文件路径
return:
_pages_count: PDF文件的页数
"""
with open(pdf_path, 'rb') as _pdf_file:
# 读取PDF文件
_pdf_file = PyPDF2.PdfReader(_pdf_file)
# 获取总页数
_pages_count = len(_pdf_file.pages)
return _pages_count
2.2 获取指定页的宽高尺寸
裁剪前肯定需要知道原尺寸,然后根据原尺寸初步三等分,再做微调,最终实现银行回单的等分
def get_page_wh(pdf_path, page_num) -> list:
"""
获取PDF文件指定页的宽高数据
params:
pdf_path: 需要读取宽高的PDF文件路径
page_num: 需要读取宽高的是哪一页,页码
return:
_width: PDF文件指定页的宽度
_height: PDF文件指定页的高度
"""
with open(pdf_path, 'rb') as _pdf_file:
# 读取PDF文件
_pdf_file = PyPDF2.PdfReader(_pdf_file)
# 获取PDF指定页信息
_pdf_info = _pdf_file.pages[int(page_num) - 1]
# 获取PDF指定页宽
_width = float(_pdf_info.mediabox.width)
# 获取PDF指定页高
_height = float(_pdf_info.mediabox.height)
return [_width, _height]
2.3 裁剪单页PDF
下面就是需求的核心功能——裁剪了(需要注意的是,我这里是根据需求将裁剪后的每一张回单放在同一个输出PDF文件中,如果需要每一张回单都为一个独立PDF文件,可以自行调整代码)
def split_pdf(input_path, output_path, page_num, upper_left, upper_right, lower_left, lower_right):
"""
裁剪指定单页PDF的区域,并另存为一个独立的文件到output_path
注意:
当PDF单页的 宽width < 高height 的时候,即文件是竖向的时候,左下角为坐标原点
当PDF单页的 宽width > 高height 的时候,即文件是横向的时候,右下角为坐标原点
params:
input_path: 需要裁剪的PDF文件路径
output_path: 输出路径
page_num: 需要裁剪的是哪一页,页码
upper_left: 裁剪区域的左上角坐标
upper_right: 裁剪区域的右上角坐标
lower_left: 裁剪区域的左下角坐标
lower_right: 裁剪区域的右下角坐标
"""
with open(input_path, 'rb') as _input_file:
# 读取PDF文件
_input_file = PyPDF2.PdfReader(_input_file)
# 创建输出PDF对象
_that_page = PyPDF2.PdfWriter()
# 获取PDF文件指定页对象
_this_page = _input_file.pages[int(page_num) - 1]
# 划定裁剪区域
_this_page.mediabox.upper_left = tuple(upper_left)
_this_page.mediabox.upper_right = tuple(upper_right)
_this_page.mediabox.lower_left = tuple(lower_left)
_this_page.mediabox.lower_right = tuple(lower_right)
# 为输出PDF对象添加裁剪页
_that_page.add_page(_this_page)
with open(output_path, 'wb') as _output_file:
# 将输出PDF对象写入输出路径文件
_that_page.write(_output_file)
2.4 批量裁剪PDF
因为原需求是一个回单PDF中由格式相同的多页回单组成的,所以我直接写了一个批量裁剪整个多页PDF文件的函数(同样需要注意的是,我这里根据需求写的是将裁剪后的每一张回单放在同一个输出PDF文件中,如果需要每一张回单都为一个独立PDF文件,可以自行调整代码)
def batch_split_pdf(input_path, output_path, crop_area_list):
"""
循环PDF文件每一页,裁剪出每一页所有裁剪区域列表中指示的区域,并且裁剪后输出到同一个PDF文件内
注意:
当PDF单页的 宽width < 高height 的时候,即文件是竖向的时候,左下角为坐标原点
当PDF单页的 宽width > 高height 的时候,即文件是横向的时候,右下角为坐标原点
params:
input_path: 需要裁剪的PDF文件路径
output_path: 输出路径
crop_area_list: 需要裁剪的区域列表(三维列表)
"""
with open(input_path, 'rb') as _input_file:
# 读取PDF文件
_input_file = PyPDF2.PdfReader(_input_file)
# 获取总页数
_pages_count = len(_input_file.pages)
# 创建输出PDF对象
_that_page = PyPDF2.PdfWriter()
# 循环每一页
for _page_num in range(_pages_count):
# 循环要裁剪的区域列表
for _crop_area in crop_area_list:
# 获取PDF文件指定页对象
_this_page = _input_file.pages[_page_num]
# 划定裁剪区域
_this_page.mediabox.upper_left = tuple(_crop_area[0])
_this_page.mediabox.upper_right = tuple(_crop_area[1])
_this_page.mediabox.lower_left = tuple(_crop_area[2])
_this_page.mediabox.lower_right = tuple(_crop_area[3])
# 为输出PDF对象添加裁剪页
_that_page.add_page(_this_page)
with open(output_path, 'wb') as _output_file:
# 将输出PDF对象写入输出路径文件
_that_page.write(_output_file)
总结📑
以上就是关于银行回单PDF裁剪需求涉及到的源代码了,抛砖引玉,大家可以根据自己更强的实力对代码做自己的个性化调整,冲💪!















 97
97











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









