







ContentBasedAlgorithm.py(基于电影推荐电影的算法)
ContentBasedAlgorithm.py(基于电影推荐电影的算法)
这个模块是基于内容计算相似度的模块,内容分为计算类型的相似度,计算年份的相似度,评估分数,得到推荐电影。
init函数
初始化,k是指knn中的k值,默认值是40
def __init__(self,k=40,sim_option={}):
AlgoBase.__init__(self)
self.k=k
similarityBasedOnGenre函数
计算类别的相似度,计算电影类别与电影类别之间的相似度
注:本次数据集有18个genres
相似指标使用𝐶𝑜𝑠𝑆𝑖𝑚(𝑥, 𝑦)计算
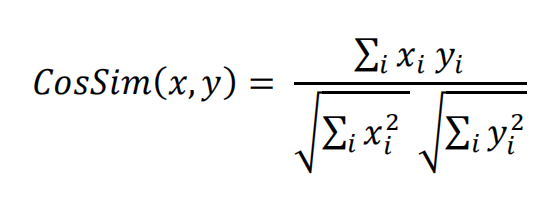
例子: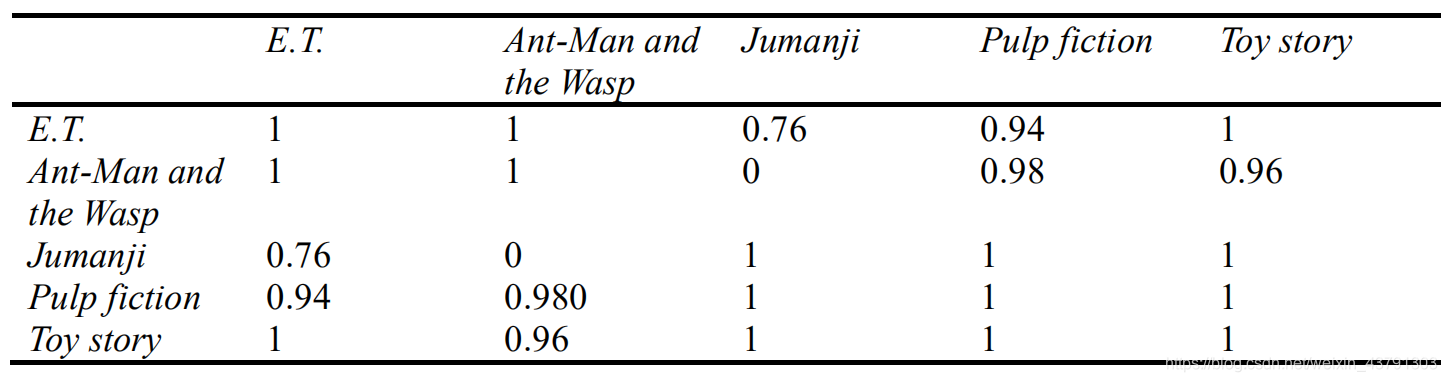
def similarityBasedOnGenre(self,movie1,movie2,genres):
genres1 = genres[movie1]
genres2 = genres[movie2]
sumxx, sumxy,sumyy = 0,0,0
for i in range(len(genres1)):
x = genres1[i]
y = genres2[i]
sumxx += x * x
sumyy += y * y
sumxy += x * y
genreSim = sumxy/math.sqrt(sumxx*sumyy)
return genreSim
similarityBasedOnYear函数
计算电影年份与电影年份之间的相似度
计算函数为f(x)=e ^(-|x-y|/5)
def similarityBasedOnYear(self,movie1,movie2,years):
diff = abs(years[movie1] - years[movie2])
sim = math.exp(-diff / 5.0)
return sim
fit函数
每个派生类都将此方法称为训练算法的第一步。参数为train_set(训练集),返回值为self。
这个派生类中则是将数据集的类别和年份的相似度计算出来,返回到self.similarities之中。
注:self.similarities为一开始为空矩阵,后面为对角矩阵。
def fit(self,trainset):
AlgoBase.fit(self, trainset)
ml = MovieLens()
genres = ml.getGenres()
years = ml.getYears()
print("Computing content-based similarity matrix")
# Compute genre distance for every movie combination as a 2x2 matrix
# create a matrix with all zeros and size of all entries in the dataset
self.similarities = np.zeros((self.trainset.n_items,self.trainset.n_items))
for this_rating in range(self.trainset.n_items):
if (this_rating % 1000 == 0):
print(this_rating, " of ", self.trainset.n_items)
for next_rating in range(this_rating+1,self.trainset.n_items):
this_movieId = int(self.trainset.to_raw_iid(this_rating))
other_movieId = int(self.trainset.to_raw_iid(next_rating))
genreSimilarity = self.similarityBasedOnGenre(this_movieId, other_movieId, genres)
yearSimilarity = self.similarityBasedOnYear(this_movieId, other_movieId, years)
self.similarities[this_rating, next_rating] = genreSimilarity * yearSimilarity
self.similarities[next_rating, this_rating] = self.similarities[this_rating, next_rating]
return self
estimate函数
在此电影与用户评价的所有电影之间建立相似度评分,接着提取前K个最相似的评分(默认为40),最后计算按用户评分加权的K个邻居的平均得分
def estimate(self, u, i):
if not (self.trainset.knows_user(u) and self.trainset.knows_item(i)):
raise PredictionImpossible('User and/or item is unkown.')
# Build up similarity scores between this item and everything the user rated
neighbors = []
for rating in self.trainset.ur[u]:
genreSimilarity = self.similarities[i,rating[0]]
neighbors.append( (genreSimilarity, rating[1]) )
# Extract the top-K most-similar ratings
k_neighbors = sorted(neighbors,key = lambda x:x[1], reverse=True)[:self.k]
# Compute average sim score of K neighbors weighted by user ratings
simTotal = weightedSum = 0
for (simScore, rating) in k_neighbors:
if (simScore > 0):
simTotal += simScore
weightedSum += simScore * rating
if (simTotal == 0):
raise PredictionImpossible('No neighbors')
predictedRating = weightedSum / simTotal
return round(predictedRating,1)
总结
这个python文件主要是完成电影与用户评价的所有电影建立相似度再计算分数,最后得到分数再推荐电影,这个python文件的算法就是表示通过你看过的电影评估其他电影来统计分数,再给出推荐电影。















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









