







正则表达式
本来我们只有一个问题,当我们想到了用正则表达式可以解决,那么就产生了两个问题
一. 什么是正则表达式
正则表达式(Regular Expression)是一种描述文本内容组成规律的表示方式。它处理文本的能力非常强。比如可以校验手机号和邮箱是否符合规则,还可以从文本和网页中提取自己想要的内容,还能做文本替换、切割等操作。
二. 元字符
元字符就是在正则表达式中具有特殊意义的字符。正则就是由一系列的元字符组成的。例如在一个普通的文本中,使用ctrl + f组合何以查询一个字符串,例如下面这样:
 但是如果想要找到所有的数字就不是那么容易了,这时候就需要正则表达式了,例如:
但是如果想要找到所有的数字就不是那么容易了,这时候就需要正则表达式了,例如:

这里的\d和{11}就是元字符。
元字符分为以下几种:
- 特殊的单独字符
- 空白符号
- 表示范围
- 量词
- 断言
2.1 特殊单字符
主要常用的有\d、\w、\s以及\D、\W、\S
\d表示任意的单个数字\w表示任意的单个数字或者字母或者下划线_\s表示任意单个空白符,空格换行这些- 大写代表它们与之相反的意思,例如
\D表示任意的单个非数字字符
2.2 空白符号
主要有换行符\n、tab制表符\t等,大部分时候使用\s即可。
\r回车符\n换行符\t制表符\f换页符空格(英文空格即可)\v垂直制表符\s任意空白字符
2.3 量词
当我们想让一个字符多次重复匹配的时候,就需要量词。比如想要匹配5个数字可以写\d\d\d\d\d,但是100次就没办法了。
在正则中,*代表出现零次到多次,+代表 一次到多次,?代表零次到一次,{m,n}代表出现m到n次。(*等价于{0,})
比如,如下的写法可以匹配到四种结果:

首先123456和1234匹配上了两次,因为*可以匹配0次,所以在第一行和第二行的结尾出匹配到了两个空的数字情况
2.4 范围
范围的功能就是从多个字符里面任选其一,例如在某个文本位置上想要1-3的数字,这时候上面的量词和元字符也没办法实现。范围主要分以下几种:
- 或的情况,
|,比如ab|bc代表这个位置既可以是ab,也可以是bc,都能匹配上 [...]多选一,括号中写几个元素,比如[123]就是在当前匹配位置上是它们三个之一即可[a-z]表示匹配a到z中的任意一个元素,这里是按照ASCII表来的,如果写[A-z]会把一些乱七八糟的字符也包含进去(这里只是打个比方)[^...]表示不是当前括号中的元素即可,例如[^123]表示这个匹配位置不是123就行
三. 正则的模式
正则主要分为三种模式:
- 贪婪匹配
- 非贪婪匹配
- 独占模式
这些模式会改变量词!的匹配行为,例如匹配长度是尽可能长还是尽可能短
3.1 贪婪模式
正则中默认的量词匹配是贪婪的,会按照最大长度去匹配(注意看的时候要符合文本的规则,不然很容易看乱)
比如上面的数字案例,\d*可以匹配到0个,但是他还是按照最长的匹配办法去匹配到了123456,这种就是贪婪模式
3.2 非贪婪模式
使用的方法是在量词的后面加上?,示例如下:

这里就是在符合整体文本条件的规则下尽可能的让匹配长度短,每个间隔也符合条件(零个),能匹配一个数字就直接过,去进行下一次匹配。
3.3 独占模式
前两种模式中需要发生回溯完成相应的功能,部分情况不需要回溯,就可以使用独占模式
什么是回溯?
比如说贪婪模式中
在匹配r的时候,前两次正常匹配上了,然后读入文本的y,此时发现和第三个r不匹配,那么就会将文本的y吐出来,正则的第三个r也会被放弃掉,走到正则的y处和文本的y匹配
同理,非贪婪匹配中第一个r匹配上了,正则就会走到y,匹配文本的r,这时候发现匹配不上,那么就会发生回溯,让前面的r再去匹配,然后用掉两个r时候再用y去匹配文本的y
PS:一个好的理解方法是将重心放在正则上,回溯就是在贪或不贪的基础上不断试错,例如贪,如果后面匹配不上了,前面就得少贪。不贪匹配不上了前面就得多贪尝试。

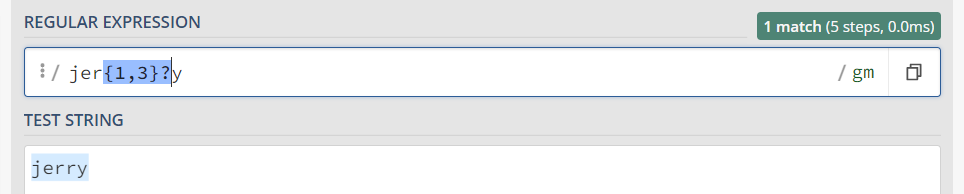
独占模式的使用方法是在量词后面加上+,独占模式也是尽可能多的去匹配,只不过失败就结束而不会回溯,稍微修改一下上面的例子(贪婪模式下):

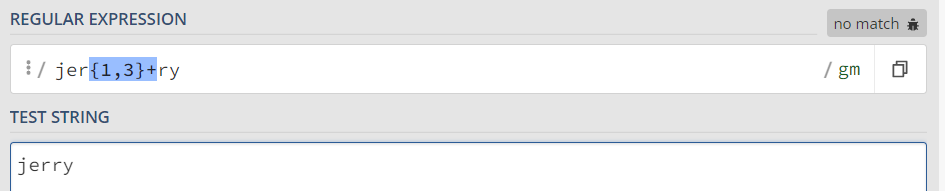
依然可以匹配上,因为在贪的基础上正则倒数第二个r匹配不上了,那么前面带量词的r就会回溯吐出来一个,给后面尝试匹配。但是独占模式这个不会回溯,那这个文本的r就吐不出来,正则也就无法匹配了。
需要注意的点:
Go的标准库不支持独占模式- 独占模式性能较好,因为不会发生大量回溯,但是可能完不成功能
四. 分组与引用
在量词中?表示出现0次或者1次。同时这个符号也表示非贪婪匹配。那么如果想要表达下面这个场景该怎么办?
选出连续的15个数字或者18个数字:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









