









字符串
字符串匹配算法
KMP
问题定义
有主字符串s和匹配字符串m,找出s的子串能和m匹配上时s的下标
示例:
s: ababababca
m: abababca
下标:2
leetcode:28. 实现 strStr()
算法解析
说明
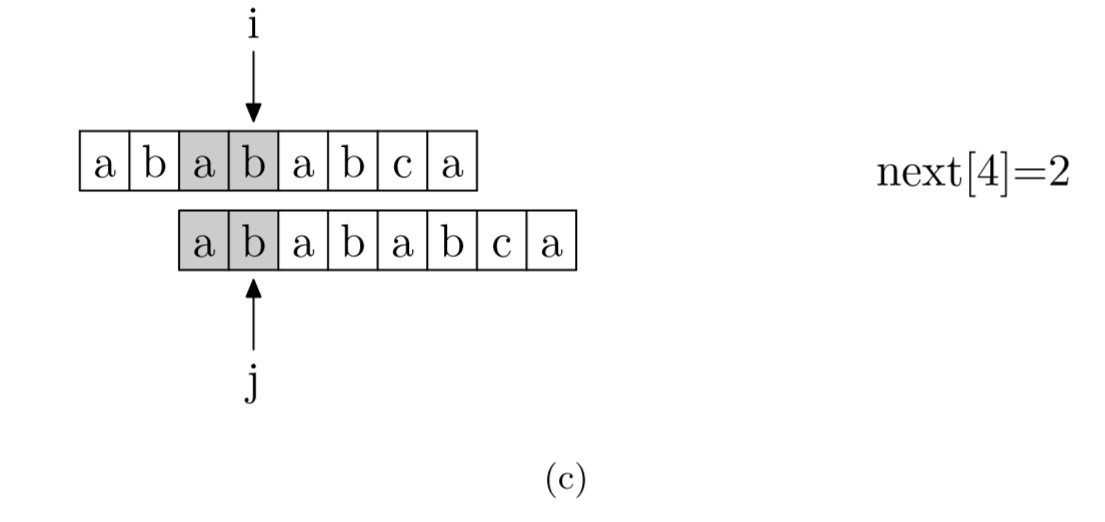
next[j]的含义为 “m[0:j] (不包括m[j])的前缀集合与后缀集合的交集中最长元素的长度”
补充说明:
- m[0:j] 不包括m[j]
- 串本身不算是串的前缀和后缀
- next[0]默认为-1
m[6] = 4举例说明:
ababab的
前缀集合{”a”, ”ab”, ”aba”, ”abab”,“ababa"}
后缀集合{“babab”,“abab”,“bab”,“ab”,“b”}
这两个集合的交集为{“ab”,“abab”}
其中最长的元素为"abab",长度为4
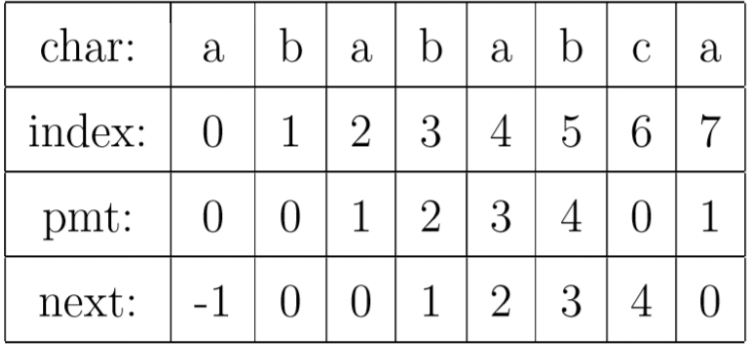
(pmt[i]为next[i-1],不用管)
KMP算法
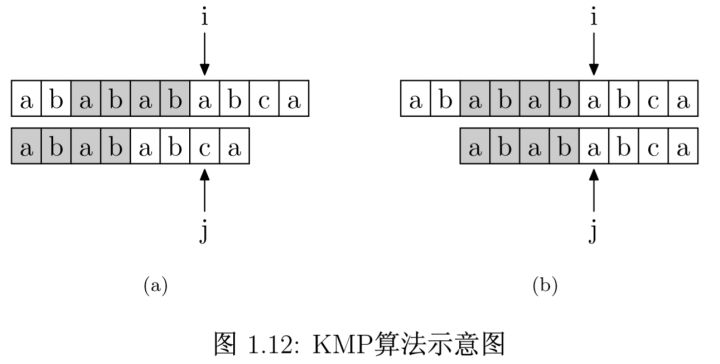
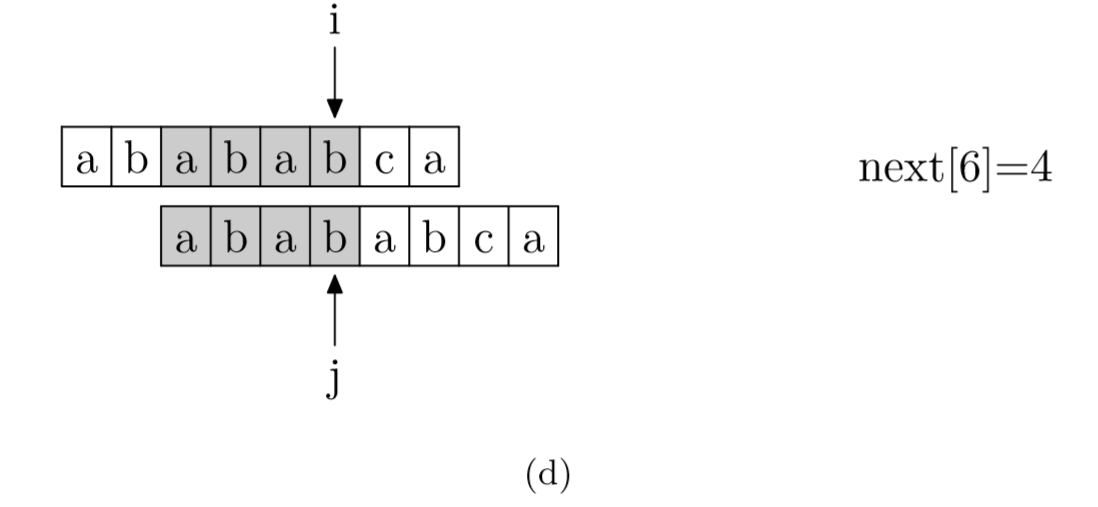
以图中的例子来说,在 i 处失配,那么主字符串和模式字符串的前边6位就是相同的。又因为模式字符串的前6位,它的前4位前缀和后4位后缀是相同的(因为next[6]为4),所以我们推知主字符串i之前的4位和模式字符串开头的4位是相同的。就是图中的灰色部分。那这部分就不用再比较了。
因此,我们只需要把j退回到next[j]处,再重新比较s[j],m[j],如此循环
// N >= M
public static int getIndexOf(String str, String pattern) {
if(pattern.equals("")){
return 0;
}
if (str == null || pattern.length() < 1 || str.length() < pattern.length()) {
return -1;
}
char[] s = str.toCharArray();
char[] m = pattern.toCharArray();
int i = 0;
int j = 0;
int[] next = getNextArray(m); // O (M)
// O(N)
while (i < s.length && j < m.length) {
if (s[i] == m[j]) {
i++;
j++;
} else if (next[j] == -1) { // m中比对的位置已经无法往前跳了
i++;
} else {
j = next[j];
}
}
// i 越界 或者 j越界了
return j == m.length ? i - j : -1;
}
求next数组
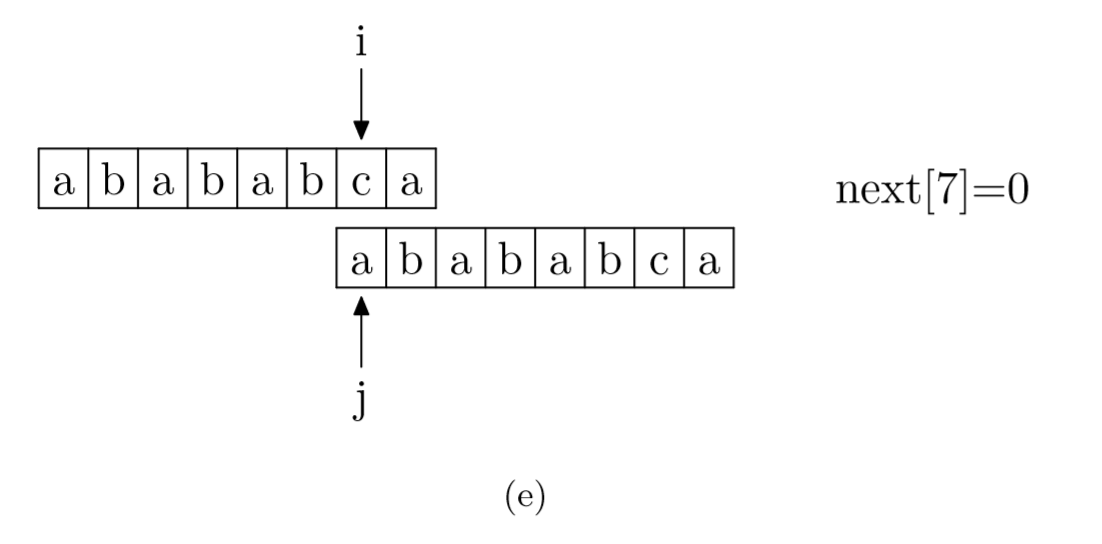
求next数组的过程完全可以看成字符串匹配的过程,即以模式字符串为主字符串,以模式字符串的前缀为目标字符串,一旦字符串匹配成功,那么当前的next值就是匹配成功的字符串的长度
具体来说,就是从模式字符串的第一位(注意,不包括第0位)开始对自身进行匹配运算。 在任一位置,能匹配的最长长度就是当前位置的next值。如下图所示。
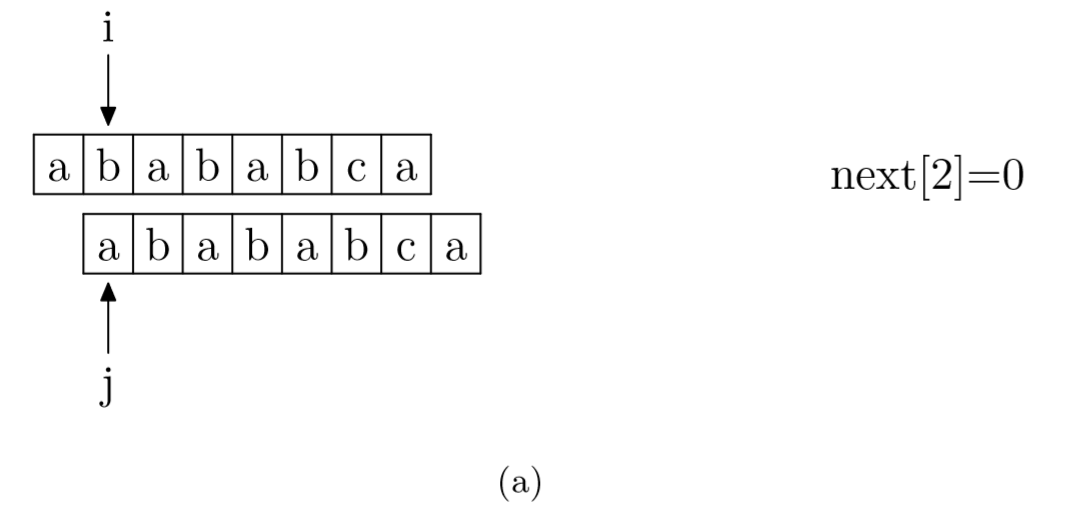
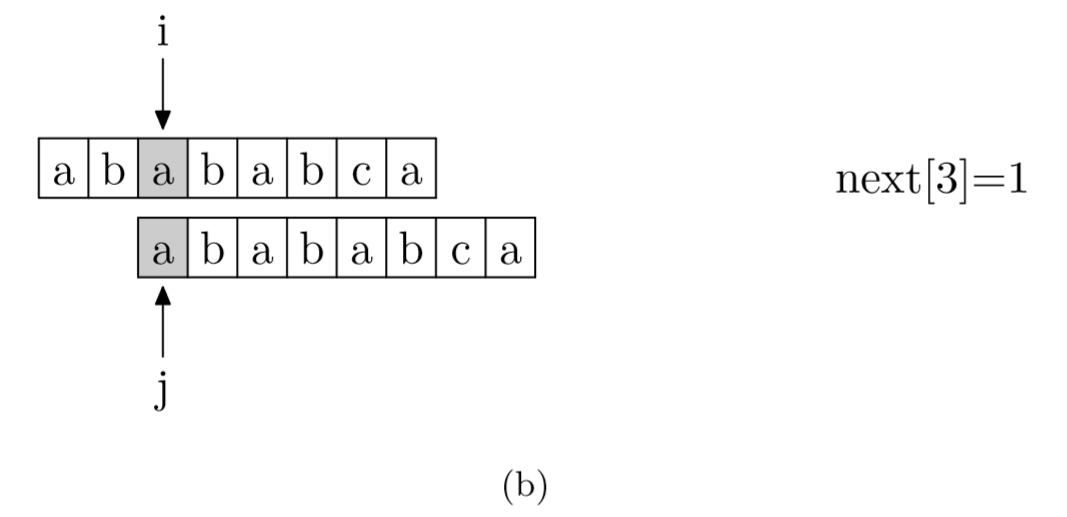
public static int[] getNextArray(char[] m) {
if (m.length == 1) {
return new int[] { -1 };
}
int[] next = new int[m.length];
next[0] = -1;
next[1] = 0;
int i = 2; // next数组的位置
int j = 0;
while (i < next.length) {
if (m[i - 1] == m[j]) {
next[i++] = ++j;
} else if (j > 0) { // 当前跳到cn位置的字符,和i-1位置的字符配不上
j = next[j];
} else {
next[i++] = 0;
}
}
return next;
}
完整代码:
public class KMP {
// N >= M
public static int getIndexOf(String str, String pattern) {
if(pattern.equals("")){
return 0;
}
if (str == null || pattern.length() < 1 || str.length() < pattern.length()) {
return -1;
}
char[] s = str.toCharArray();
char[] m = pattern.toCharArray();
int i = 0;
int j = 0;
int[] next = getNextArray(m); // O (M)
// O(N)
while (i < s.length && j < m.length) {
if (s[i] == m[j]) {
i++;
j++;
} else if (next[j] == -1) { // m中比对的位置已经无法往前跳了
i++;
} else {
j = next[j];
}
}
// i 越界 或者 j越界了
return j == m.length ? i - j : -1;
}
public static int[] getNextArray(char[] m) {
if (m.length == 1) {
return new int[] { -1 };
}
int[] next = new int[m.length];
next[0] = -1;
next[1] = 0;
int i = 2; // next数组的位置
int j = 0;
while (i < next.length) {
if (m[i - 1] == m[j]) {
next[i++] = ++j;
} else if (j > 0) { // 当前跳到cn位置的字符,和i-1位置的字符配不上
j = next[j];
} else {
next[i++] = 0;
}
}
return next;
}
public static void main(String[] args) {
String str = "abcabcababaccc";
String match = "ababa";
System.out.println(getIndexOf(str, match));
}
}
时间复杂度
最坏:O(n+m)
参考来源
算法解析:https://www.zhihu.com/question/21923021
代码:取自左程云左神《算法入门与基础》,牛客上的一门算法课
BM
排序
快速排序

public class QuickSort {
private static void swap(int[] data, int i, int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
private static void subSort(int[] data, int start, int end) {
if (start < end) {
int base = data[start];
int low = start;
int high = end + 1;
while (true) {
while (low < end && data[++low] - base <= 0)
;
while (high > start && data[--high] - base >= 0)
;
if (low < high) {
swap(data, low, high);
} else {
break;
}
}
swap(data, start, high);
subSort(data, start, high - 1);//递归调用
subSort(data, high + 1, end);
}
}
public static void quickSort(int[] data){
subSort(data,0,data.length-1);
}
public static void main(String[] args) {
int[] data = { 9, -16, 30, 23, -30, -49, 25, 21, 30 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
quickSort(data);
System.out.println("排序之后:\n" + java.util.Arrays.toString(data));
}
}















 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









