







文章目录
第26讲:对称矩阵及正定性
对称矩阵
前面我们学习了矩阵的特征值与特征向量,也了解了一些特殊的矩阵及其特征值、特征向量,特殊矩阵的特殊性应该会反映在其特征值、特征向量中。如马尔科夫矩阵,有一特征值为 1 1 1,本讲介绍(实)对称矩阵。
性质
描述
先提前介绍两个对称矩阵的特性:
- 特征值为实数;(对比第21讲介绍的旋转矩阵,其特征值为纯虚数)
- 特征向量相互正交(或者叫垂直prependicular)(当特征值重复时,特征向量也可以从子空间中选出相互正交正交的向量)
典型的状况是,特征值不重复,特征向量相互正交。
证明
现在我们来证明性质1
对于矩阵
A
x
=
λ
x
‾
\underline{Ax=\lambda x}
Ax=λx,对于其共轭部分总有
A
ˉ
x
ˉ
=
λ
ˉ
x
ˉ
\bar A\bar x=\bar\lambda \bar x
Aˉxˉ=λˉxˉ,根据前提条件我们只讨论实矩阵,则有
A
x
ˉ
=
λ
ˉ
x
ˉ
A\bar x=\bar\lambda \bar x
Axˉ=λˉxˉ
将等式两边取转置有
x
ˉ
T
A
=
x
ˉ
T
λ
ˉ
‾
\overline{\bar{x}^TA=\bar{x}^T\bar\lambda}
xˉTA=xˉTλˉ
将“下划线”式两边左乘
x
ˉ
T
\bar{x}^T
xˉT有
x
ˉ
T
A
x
=
x
ˉ
T
λ
x
\bar{x}^TAx=\bar{x}^T\lambda x
xˉTAx=xˉTλx
将“上划线”式两边右乘
x
x
x有
x
ˉ
T
A
x
=
x
ˉ
T
λ
ˉ
x
\bar{x}^TAx=\bar{x}^T\bar\lambda x
xˉTAx=xˉTλˉx
观察发现这两个式子左边是一样的,所以
x
ˉ
T
λ
x
=
x
ˉ
T
λ
ˉ
x
\bar{x}^T\lambda x=\bar{x}^T\bar\lambda x
xˉTλx=xˉTλˉx,则有
λ
=
λ
ˉ
\lambda=\bar{\lambda}
λ=λˉ(这里有个前提条件,
x
ˉ
T
x
≠
0
\bar{x}^Tx\neq 0
xˉTx=0),证毕。
观察这个前提条件, x ˉ T x = [ x ˉ 1 x ˉ 2 ⋯ x ˉ n ] [ x 1 x 2 ⋮ x n ] = x ˉ 1 x 1 + x ˉ 2 x 2 + ⋯ + x ˉ n x n \bar{x}^Tx=\begin{bmatrix}\bar x_1&\bar x_2&\cdots&\bar x_n\end{bmatrix}\begin{bmatrix}x_1\\x_2\\\vdots\\x_n\end{bmatrix}=\bar x_1x_1+\bar x_2x_2+\cdots+\bar x_nx_n xˉTx=[xˉ1xˉ2⋯xˉn]⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤=xˉ1x1+xˉ2x2+⋯+xˉnxn,设 x 1 = a + i b , x ˉ 1 = a − i b x_1=a+ib, \bar x_1=a-ib x1=a+ib,xˉ1=a−ib则 x ˉ 1 x 1 = a 2 + b 2 \bar x_1x_1=a^2+b^2 xˉ1x1=a2+b2,所以有 x ˉ T x > 0 \bar{x}^Tx>0 xˉTx>0。而 x ˉ T x \bar{x}^Tx xˉTx就是 x x x长度的平方。
性质2的证明需看书,此处省略
谱定理,对称矩阵的分解
-
在通常(可对角化)情况下,一个矩阵可以化为: A = S Λ S − 1 A=S\varLambda S^{-1} A=SΛS−1;
-
在矩阵对称的情况下,通过性质2可知,由特征向量组成的矩阵 S S S中的列向量是相互正交的,此时如果我们把特征向量的长度统一化为 1 1 1,就可以得到一组标准正交的特征向量
则对于对称矩阵有 A = Q Λ Q − 1 A=Q\varLambda Q^{-1} A=QΛQ−1,而对于标准正交矩阵,有 Q = Q T Q=Q^T Q=QT,所以对称矩阵可以写为 A = Q Λ Q T (1) A=Q\varLambda Q^T\tag{1} A=QΛQT(1)
观察 ( 1 ) (1) (1)式,我们发现这个分解本身就代表着对称, ( Q Λ Q T ) T = ( Q T ) T Λ T Q T = Q Λ Q T \left(Q\varLambda Q^T\right)^T=\left(Q^T\right)^T\varLambda^TQ^T=Q\varLambda Q^T (QΛQT)T=(QT)TΛTQT=QΛQT
( 1 ) (1) (1)式在数学上叫做谱定理(spectral theorem),谱就是指矩阵特征值的集合(该名称来自光谱,指一些纯事物的集合,就像将特征值分解成为特征值与特征向量)
在力学上称之为主轴定理(principle axis theorem),从几何上看,它意味着如果给定某种材料,在合适的轴上来看,它就变成对角化的,方向就不会重复。
拓展这个性质,当 A A A为复矩阵,根据上面的推导,则矩阵必须满足 A = A ˉ T A=\bar{A}^T A=AˉT时,才有性质1、性质2成立(教授称具有这种特征值为实数、特征向量相互正交的矩阵为“好矩阵”)。 -
继续研究 A = Q Λ Q T = [ q 1 q 2 ⋯ q n ] [ λ 1 ⋯ λ 2 ⋯ ⋮ ⋮ ⋱ ⋮ ⋯ λ n ] [ q 1 T q 2 T ⋮ q 3 T ] = [ q 1 q 2 ⋯ q n ] [ λ 1 q 1 T λ 2 q 2 T ⋮ λ 3 q 3 T ] = λ 1 q 1 q 1 T + λ 2 q 2 q 2 T + ⋯ + λ n q n q n T A=Q\varLambda Q^T=\Bigg[q_1\ q_2\ \cdots\ q_n\Bigg]\begin{bmatrix}\lambda_1& &\cdots& \\&\lambda_2&\cdots&\\\vdots&\vdots&\ddots&\vdots\\& &\cdots&\lambda_n\end{bmatrix}\begin{bmatrix}\quad q_1^T\quad\\\quad q_2^T\quad\\\quad \vdots \quad\\\quad q_3^T\quad\end{bmatrix}=\Bigg[q_1\ q_2\ \cdots\ q_n\Bigg]\begin{bmatrix}\quad \lambda_1 q_1^T\quad\\\quad \lambda_2 q_2^T\quad\\\quad \vdots \quad\\\quad \lambda_3 q_3^T\quad\end{bmatrix}=\lambda_1q_1q_1^T+\lambda_2q_2q_2^T+\cdots+\lambda_nq_nq_n^T A=QΛQT=[q1 q2 ⋯ qn]⎣⎢⎢⎢⎡λ1⋮λ2⋮⋯⋯⋱⋯⋮λn⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡q1Tq2T⋮q3T⎦⎥⎥⎥⎤=[q1 q2 ⋯ qn]⎣⎢⎢⎢⎡λ1q1Tλ2q2T⋮λ3q3T⎦⎥⎥⎥⎤=λ1q1q1T+λ2q2q2T+⋯+λnqnqnT
(最后一个等式是由第3讲矩阵乘法的列乘以行的方法得到的)
这个展开式中的 q q T qq^T qqT, q q q是单位列向量所以 q T q = 1 q^Tq=1 qTq=1,结合我们在第十五讲所学的投影矩阵的知识有 q q T q T q = q q T \frac{qq^T}{q^Tq}=qq^T qTqqqT=qqT是一个投影矩阵
很容易验证其性质,比如平方它会得到 q q T q q T = q q T qq^Tqq^T=qq^T qqTqqT=qqT于是多次投影不变等。
故有结论:
每一个对称矩阵是一些列互相垂直的投影矩阵的组合
对称矩阵特征值的符号
在知道对称矩阵的特征值皆为实数后,我们再来讨论这些实数的符号,因为特征值的正负号会影响微分方程的收敛情况(第23讲,需要实部为负的特征值保证收敛)
直接计算特征值会很麻烦
主元的符号与特征向量的符号一致,因此我们可以用消元法取得矩阵的主元,观察主元的符号来确定特征值的符号。
并且还可以将矩阵平移7个单位矩阵,这样特征值平移了7,然后计算平移后矩阵的主元,就可以知道特征值有多少小于7,多少大于7
如果没有行交换,主元乘积 = 特征值乘积,因为他们都等于行列式
正定性
定义
特征值都是正数的对称矩阵是 正定矩阵(positive definite)
根据上面的性质有矩阵的主元也均为正
例子
举个例子,
[
5
2
2
3
]
\begin{bmatrix}5&2\\2&3\end{bmatrix}
[5223]
由主元乘积为行列式知其主元为
5
,
11
5
5,\frac{11}{5}
5,511
按一般的方法求特征值有
∣
5
−
λ
2
2
3
−
λ
∣
=
λ
2
−
8
λ
+
11
=
0
,
λ
=
4
±
5
\begin{vmatrix}5-\lambda&2\\2&3-\lambda\end{vmatrix}=\lambda^2-8\lambda+11=0, \lambda=4\pm\sqrt 5
∣∣∣∣5−λ223−λ∣∣∣∣=λ2−8λ+11=0,λ=4±5
正定矩阵的另一个性质是,所有子行列式为正
对上面的例子有
∣
5
∣
=
5
,
∣
5
2
2
3
∣
=
11
\begin{vmatrix}5\end{vmatrix}=5, \begin{vmatrix}5&2\\2&3\end{vmatrix}=11
∣∣5∣∣=5,∣∣∣∣5223∣∣∣∣=11。
早期学习的主元、中期学习的的行列式、后期学习的特征值,我们在这节课和后面几节课将把他们融为一体

知其一则知其三
这课的高潮是 在后面的课程,会将 n × n n×n n×n矩阵的这三个概念也融为一体,而不仅仅是对称矩阵
第27讲:复数矩阵和快速傅里叶变换
本讲主要介绍复数向量、复数矩阵的相关知识(包括如何做复数向量的点积运算、什么是复数对称矩阵等),以及傅里叶矩阵(最重要的复数矩阵)和快速傅里叶变换。
复数矩阵运算
先介绍复数向量,我们不妨换一个字母符号来表示:
z
=
[
z
1
z
2
⋮
z
n
]
z=\begin{bmatrix}z_1\\z_2\\\vdots\\z_n\end{bmatrix}
z=⎣⎢⎢⎢⎡z1z2⋮zn⎦⎥⎥⎥⎤,向量的每一个分量都是复数
此时
z
z
z不再属于
R
n
\mathbb{R}^n
Rn实向量空间,它现在处于
C
n
\mathbb{C}^n
Cn复向量空间。
计算复向量的模
对于实向量,我们计算模只需要计算
∣
v
∣
=
v
T
v
\left|v\right|=\sqrt{v^Tv}
∣v∣=vTv即可
而如果对复向量使用
z
T
z
z^Tz
zTz则有
z
T
z
=
[
z
1
z
2
⋯
z
n
]
[
z
1
z
2
⋮
z
n
]
=
z
1
2
+
z
2
2
+
⋯
+
z
n
2
z^Tz=\begin{bmatrix}z_1&z_2&\cdots&z_n\end{bmatrix}\begin{bmatrix}z_1\\z_2\\\vdots\\z_n\end{bmatrix}=z_1^2+z_2^2+\cdots+z_n^2
zTz=[z1z2⋯zn]⎣⎢⎢⎢⎡z1z2⋮zn⎦⎥⎥⎥⎤=z12+z22+⋯+zn2
这里
z
i
z_i
zi是复数,虚部平方后为负,求模时本应相加的运算变成了减法(如向量
[
1
i
]
\begin{bmatrix}1\\i\end{bmatrix}
[1i],左乘其转置后结果为
0
0
0,但此向量的长度显然不是零)
根据上一讲我们知道,应使用 ∣ z ∣ = z ˉ T z \left|z\right|=\sqrt{\bar{z}^Tz} ∣z∣=zˉTz,即 [ z ˉ 1 z ˉ 2 ⋯ z ˉ n ] [ z 1 z 2 ⋮ z n ] \begin{bmatrix}\bar z_1&\bar z_2&\cdots&\bar z_n\end{bmatrix}\begin{bmatrix}z_1\\z_2\\\vdots\\z_n\end{bmatrix} [zˉ1zˉ2⋯zˉn]⎣⎢⎢⎢⎡z1z2⋮zn⎦⎥⎥⎥⎤,使用向量共轭的转置乘以原向量即可(如向量 [ 1 i ] \begin{bmatrix}1\\ i\end{bmatrix} [1i],左乘其共轭转置后结果为 [ 1 − i ] [ 1 i ] = 2 \begin{bmatrix}1&-i\end{bmatrix}\begin{bmatrix}1\\i\end{bmatrix}=2 [1−i][1i]=2)
我们把共轭转置乘以原向量记为 z H z z^Hz zHz, H H H读作埃尔米特(人名为Hermite,形容词为Hermitian)
计算向量的内积
有了复向量模的计算公式,同理可得,对于复向量,内积不再是实向量的
y
T
x
y^Tx
yTx形式,复向量内积应为
y
H
x
y^Hx
yHx
对称性
对于实矩阵,
A
T
=
A
A^T=A
AT=A即可表达矩阵的对称性
而对于复矩阵,我们同样需要求一次共轭
A
ˉ
T
=
A
\bar{A}^T=A
AˉT=A
举个例子
[
2
3
+
i
3
−
i
5
]
\begin{bmatrix}2&3+i\\3-i&5\end{bmatrix}
[23−i3+i5]
这是一个复数情况下的对称矩阵,叫做埃尔米特矩阵,有
A
H
=
A
A^H=A
AH=A
因为转置后对角线元素不变,而取共轭时也不能变,所以对角线元素只能是实数
这种矩阵的特征值是实数,特征向量相互垂直,跟实矩阵的对称矩阵的性质一致
正交性
在第17讲中,我们这样定义标准正交向量: q i T q j = { 0 i ≠ j 1 i = j q_i^Tq_j=\begin{cases}0\quad i\neq j\\1\quad i=j\end{cases} qiTqj={0i=j1i=j。现在,对于复向量我们需要求共轭: q ˉ i T q j = q i H q j = { 0 i ≠ j 1 i = j \bar{q}_i^Tq_j=q_i^Hq_j=\begin{cases}0\quad i\neq j\\1\quad i=j\end{cases} qˉiTqj=qiHqj={0i=j1i=j
第17讲中的标准正交矩阵: Q = [ q 1 q 2 ⋯ q n ] Q=\Bigg[q_1\ q_2\ \cdots\ q_n\Bigg] Q=[q1 q2 ⋯ qn],有 Q T Q = I Q^TQ=I QTQ=I,现在对于复矩阵则有 Q H Q = I Q^HQ=I QHQ=I
就像人们给共轭转置起了个“埃尔米特”这个名字一样,正交性(orthogonal)在复数情况下也有了新名字,酉(unitary)
酉矩阵(unitary matrix)与正交矩阵类似,满足
Q
H
Q
=
I
Q^HQ=I
QHQ=I的性质
傅里叶矩阵
傅里叶矩阵是最著名的复矩阵,同时也是酉矩阵
n n n阶傅里叶矩阵 F n = [ 1 1 1 ⋯ 1 1 w w 2 ⋯ w n − 1 1 w 2 w 4 ⋯ w 2 ( n − 1 ) ⋮ ⋮ ⋮ ⋱ ⋮ 1 w n − 1 w 2 ( n − 1 ) ⋯ w ( n − 1 ) 2 ] F_n=\begin{bmatrix}1&1&1&\cdots&1\\1&w&w^2&\cdots&w^{n-1}\\1&w^2&w^4&\cdots&w^{2(n-1)}\\\vdots&\vdots&\vdots&\ddots&\vdots\\1&w^{n-1}&w^{2(n-1)}&\cdots&w^{(n-1)^2}\end{bmatrix} Fn=⎣⎢⎢⎢⎢⎢⎡111⋮11ww2⋮wn−11w2w4⋮w2(n−1)⋯⋯⋯⋱⋯1wn−1w2(n−1)⋮w(n−1)2⎦⎥⎥⎥⎥⎥⎤
对于每一个元素有
(
F
n
)
i
j
=
w
i
j
i
,
j
=
0
,
1
,
2
,
⋯
,
n
−
1
(F_n)_{ij}=w^{ij}\quad i,j=0,1,2,\cdots,n-1
(Fn)ij=wiji,j=0,1,2,⋯,n−1(注意这里的
i
i
i是从0开始的)
矩阵中的
w
w
w是一个非常特殊的值,满足
w
n
=
1
w^n=1
wn=1,其公式为
w
=
e
i
2
π
/
n
w=e^{i2\pi/n}
w=ei2π/n
w
=
cos
2
π
n
+
i
sin
2
π
n
w=\cos\frac{2\pi}{n}+i\sin\frac{2\pi}{n}
w=cosn2π+isinn2π,易知
w
w
w在复平面的单位圆上

在傅里叶矩阵中,当我们计算
w
w
w的幂时,
w
w
w在单位圆上的角度翻倍
比如在
6
6
6阶情形下,
w
=
e
i
2
π
/
6
w=e^{i2\pi/6}
w=ei2π/6,即位于单位圆上
6
0
∘
60^\circ
60∘角处,其平方位于单位圆上
12
0
∘
120^\circ
120∘角处,而
w
6
w^6
w6位于
1
1
1处
从开方的角度看,它们是
1
1
1的
6
6
6个六次方根,而一次的
w
w
w称为原根。
-
4 4 4阶傅里叶矩阵
我们现在来看 4 4 4阶傅里叶矩阵,它位于单位圆四分之一处,从x轴逆时针旋转90°
先计算 w w w,有 w 0 = 1 , w 1 = i , w 2 = − 1 , w 3 = − i w^0=1,w^1=i,\ w^2=-1,\ w^3=-i w0=1,w1=i, w2=−1, w3=−i
F 4 = [ 1 1 1 1 1 i i 2 i 3 1 i 2 i 4 i 6 1 i 3 i 6 i 9 ] = [ 1 1 1 1 1 i − 1 − i 1 − 1 1 − 1 1 − i − 1 i ] F_4=\begin{bmatrix}1&1&1&1\\1&i&i^2&i^3\\1&i^2&i^4&i^6\\1&i^3&i^6&i^9\end{bmatrix}=\begin{bmatrix}1&1&1&1\\1&i&-1&-i\\1&-1&1&-1\\1&-i&-1&i\end{bmatrix} F4=⎣⎢⎢⎡11111ii2i31i2i4i61i3i6i9⎦⎥⎥⎤=⎣⎢⎢⎡11111i−1−i1−11−11−i−1i⎦⎥⎥⎤
指数等于行序数乘列序数
通过这个4阶矩阵可以得到一个四点傅里叶变换(离散),将其作用于四维向量,向量分别左乘 F 4 F_4 F4或者 F 4 − 1 F_4^{-1} F4−1,一个是傅里叶变换,另一个是傅里叶逆变换 -
F 4 − 1 F_4^{-1} F4−1
矩阵的四个列向量正交,我们验证一下第二列和第四列
c 2 ˉ T c 4 = 1 − 0 + 1 − 0 = 0 \bar{c_2}^Tc_4=1-0+1-0=0 c2ˉTc4=1−0+1−0=0,正交
不过我们应该注意到, F 4 F_4 F4的列向量并不是标准的,我们可以给矩阵乘上系数 1 2 \frac{1}{2} 21(除以列向量的长度)得到标准正交矩阵 F 4 = 1 2 [ 1 1 1 1 1 i − 1 − i 1 − 1 1 − 1 1 − i − 1 i ] F_4=\frac{1}{2}\begin{bmatrix}1&1&1&1\\1&i&-1&-i\\1&-1&1&-1\\1&-i&-1&i\end{bmatrix} F4=21⎣⎢⎢⎡11111i−1−i1−11−11−i−1i⎦⎥⎥⎤
此时有 F 4 H F 4 = I F_4^HF_4=I F4HF4=I
于是该矩阵的逆矩阵就是其共轭转置 F 4 H F_4^H F4H
逆矩阵各列也是正交的
快速傅里叶变换(Fast Fourier transform/FFT)
w
32
w_{32}
w32是
1
1
1的
32
32
32次方根,
w
64
w_{64}
w64是
1
1
1的
64
64
64次方根,因此
w
32
w_{32}
w32的辐角是
w
64
w_{64}
w64的两倍
w
64
=
(
e
i
2
π
/
64
)
2
=
e
i
2
π
/
32
=
w
32
w_{64}=(e^{i2\pi/64})^2=e^{i2\pi/32}=w_{32}
w64=(ei2π/64)2=ei2π/32=w32
所以对于傅里叶矩阵,
F
6
,
F
3
F_6,\ F_3
F6, F3、
F
8
,
F
4
F_8,\ F_4
F8, F4、
F
64
,
F
32
F_{64},\ F_{32}
F64, F32之间存在一定联系
例子
让我们举例来描述这种联系
有傅里叶矩阵
F
64
F_{64}
F64,一般情况下,用一个列向量右乘
F
64
F_{64}
F64需要约
6
4
2
64^2
642次数值乘法,显然这个计算量是比较大的
我们想要减少计算量,于是想到分解
F
64
F_{64}
F64
分解 F 64 F_{64} F64
[ F 64 ] = [ I D I − D ] [ F 32 0 0 F 32 ] [ 1 ⋯ 0 ⋯ 0 ⋯ 1 ⋯ 1 ⋯ 0 ⋯ 0 ⋯ 1 ⋯ ⋱ ⋱ ⋱ ⋱ ⋯ 1 ⋯ 0 ⋯ 0 ⋯ 1 ] \Bigg[F_{64}\Bigg]=\begin{bmatrix}I&D\\I&-D\end{bmatrix}\begin{bmatrix}F_{32}&0\\0&F_{32}\end{bmatrix}\begin{bmatrix}1&&\cdots&&&0&&\cdots&&\\0&&\cdots&&&1&&\cdots&&\\&1&\cdots&&&&0&\cdots&&\\&0&\cdots&&&&1&\cdots&&\\&&&\ddots&&&&&\ddots&&\\&&&\ddots&&&&&\ddots&&\\&&&\cdots&1&&&&\cdots&0\\&&&\cdots&0&&&&\cdots&1\end{bmatrix} [F64]=[IID−D][F3200F32]⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡1010⋯⋯⋯⋯⋱⋱⋯⋯100101⋯⋯⋯⋯⋱⋱⋯⋯01⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
我们从左到右来看等式右侧的这三个矩阵:
-
第一个矩阵由单位矩阵 I I I和对角矩阵 D = [ 1 w w 2 ⋱ w 31 ] D=\begin{bmatrix}1&&&&\\&w&&&\\&&w^2&&\\&&&\ddots&\\&&&&w^{31}\end{bmatrix} D=⎣⎢⎢⎢⎢⎡1ww2⋱w31⎦⎥⎥⎥⎥⎤组成,我们称这个矩阵为修正矩阵,显然其计算量来自 D D D矩阵,对角矩阵的计算量约为 32 32 32即这个修正矩阵的计算量约为 32 32 32,单位矩阵的计算量忽略不计。
-
第二个矩阵是两个 F 32 F_{32} F32与零矩阵组成的,计算量约为 2 × 3 2 2 2\times 32^2 2×322。
-
第三个矩阵通常记为 P P P矩阵,这是一个置换矩阵,其作用是讲将一个矩阵中的奇数列提到偶数列之前,将前一个矩阵从 [ x 0 x 1 ⋯ ] \Bigg[x_0\ x_1\ \cdots\Bigg] [x0 x1 ⋯]变为 [ x 0 x 2 ⋯ x 1 x 3 ⋯ ] \Bigg[x_0\ x_2\ \cdots\ x_1\ x_3\ \cdots\Bigg] [x0 x2 ⋯ x1 x3 ⋯],这个置换矩阵的计算量也可以忽略不计
(这里教授似乎在黑板上写错了矩阵,可以参考FFT、How the FFT is computed做进一步讨论)
至此我们把 6 4 2 64^2 642复杂度的计算化简为 2 × 3 2 2 + 32 2\times 32^2+32 2×322+32复杂度的计算
分解 F 32 F_{32} F32
我们可以进一步化简 F 32 F_{32} F32得到与 F 16 F_{16} F16有关的式子: [ I 32 D 32 I 32 − D 32 ] [ I 16 D 16 I 16 − D 16 I 16 D 16 I 16 − D 16 ] [ F 16 F 16 F 16 F 16 ] \begin{bmatrix}I_{32}&D_{32}\\I_{32}&-D_{32}\end{bmatrix}\begin{bmatrix}I_{16}&D_{16}&&\\I_{16}&-D_{16}&&\\&&I_{16}&D_{16}\\&&I_{16}&-D_{16}\end{bmatrix}\begin{bmatrix}F_{16}&&&\\&F_{16}&&\\&&F_{16}&\\&&&F_{16}\end{bmatrix} [I32I32D32−D32]⎣⎢⎢⎡I16I16D16−D16I16I16D16−D16⎦⎥⎥⎤⎣⎢⎢⎡F16F16F16F16⎦⎥⎥⎤ [ P 16 P 16 ] [ P 32 ] \begin{bmatrix}P_{16}&\\&P_{16}\end{bmatrix}\Bigg[\ P_{32}\ \Bigg] [P16P16][ P32 ]
(两个 P 16 P_{16} P16矩阵的作用分别是,先奇偶分开,再将偶数中的奇偶分开,奇数中的奇偶分开,得到偶数中的偶数 0 , 4 , 8 , 12 , 16 0,4,8,12,16 0,4,8,12,16,偶数中的奇数 2 , 6 , 10 , 14 2,6,10,14 2,6,10,14及奇数中的偶数,奇数中的奇数)
2 × 3 2 2 + 32 2\times 32^2+32 2×322+32的计算量进一步分解为 2 × ( 2 × 1 6 2 + 16 ) 2 + 32 2\times (2\times 16^2+16)^2+32 2×(2×162+16)2+32的计算量
复杂度分析
如此递归分解下去,我们最终得到含有一阶傅里叶矩阵的式子
而每一次分解的修正开销都为 32 32 32,共有 log 2 64 = 6 \log_264 = 6 log264=6 个修正矩阵,故总开销为 32 × 6 32 \times 6 32×6
由此,对于 n n n阶傅里叶变换,无需 n 2 n^2 n2次乘法,只需 1 2 n log 2 n \frac{1}{2}n\log_2n 21nlog2n即可
感受FFT魅力
不妨再看看 n = 10 n=10 n=10的情况,不使用FFT时需要 n 2 = 1024 × 1024 n^2=1024\times 1024 n2=1024×1024次运算,使用FFT时只需要 n 2 log 2 n = 5 × 1024 \frac{n}{2}\log_2n=5\times 1024 2nlog2n=5×1024次运算,运算量大约是原来的 1 200 \frac{1}{200} 2001!
复矩阵讨论完毕,下一讲回到实数上来,研究特征值、特征向量及至关重要的正定矩阵(这是实际应用中最常见的一种矩阵)
第28讲:正定矩阵和最小值
之后我们会将 主元,行列式,特征值还有新知识 不稳定性 融为一体
本讲我们会了解如何完整的测试一个矩阵是否正定,测试
x
T
A
x
x^TAx
xTAx是否具有极小值,最后了解正定的几何意义——椭圆(ellipse)和正定性有关,双曲线(hyperbola)与正定无关
另外,本讲涉及的矩阵均为实对称矩阵。
正定性的判断
方法
我们仍然从二阶说起,有矩阵 A = [ a b b c ] A=\begin{bmatrix}a&b\\b&c\end{bmatrix} A=[abbc],判断其正定性有以下方法:
- 矩阵的所有特征值大于零则矩阵正定: λ 1 > 0 , λ 2 > 0 \lambda_1>0,\ \lambda_2>0 λ1>0, λ2>0;
- 矩阵的所有顺序主子阵(leading principal submatrix)的行列式(即顺序主子式,leading principal minor)大于零则矩阵正定: a > 0 , a c − b 2 > 0 a>0,\ ac-b^2>0 a>0, ac−b2>0;
- 矩阵消元后主元均大于零: a > 0 , a c − b 2 a > 0 a>0,\ \frac{ac-b^2}{a}>0 a>0, aac−b2>0;
- 对任意 x x x,有 x T A x > 0 x^TAx>0 xTAx>0
大多数情况下使用4来定义正定性,而用前三条来验证正定性。
2 × 2 2 \times 2 2×2阶矩阵举例
来计算一个例子: A = [ 2 6 6 ? ] A=\begin{bmatrix}2&6\\6&?\end{bmatrix} A=[266?],在 ? ? ?处填入多少才能使矩阵正定?
“刚好不满足”情形
令
?
=
18
?=18
?=18,此时矩阵为
A
=
[
2
6
6
18
]
A=\begin{bmatrix}2&6\\6&18\end{bmatrix}
A=[26618]
det
A
=
0
\det A=0
detA=0,此时的矩阵是半正定矩阵(positive semi-definite)
矩阵奇异,其中一个特征值必为
0
0
0,从迹得知另一个特征值为
20
20
20
矩阵的主元只有一个,为
2
2
2
计算
x
T
A
x
x^TAx
xTAx,得
[
x
1
x
2
]
[
2
6
6
18
]
[
x
1
x
2
]
=
2
x
1
2
+
12
x
1
x
2
+
18
x
2
2
\begin{bmatrix}x_1&x_2\end{bmatrix}\begin{bmatrix}2&6\\6&18\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix}=2x_1^2+12x_1x_2+18x_2^2
[x1x2][26618][x1x2]=2x12+12x1x2+18x22
这样我们得到了一个关于
x
1
,
x
2
x_1,x_2
x1,x2的函数
f
(
x
1
,
x
2
)
=
2
x
1
2
+
12
x
1
x
2
+
18
x
2
2
f(x_1,x_2)=2x_1^2+12x_1x_2+18x_2^2
f(x1,x2)=2x12+12x1x2+18x22
这个函数不再是线性的,在本例中这是一个纯二次型(quadratic)函数,它没有线性部分、一次部分或更高次部分(
A
x
Ax
Ax是线性的,但引入
x
T
x^T
xT后就成为了二次型)
当 ? ? ?取 18 18 18时,判定1、2、3都是“刚好不满足”。
“一定不满足”情形
令
?
=
7
?=7
?=7,矩阵为
A
=
[
2
6
6
7
]
A=\begin{bmatrix}2&6\\6&7\end{bmatrix}
A=[2667]
行列式变为
−
22
-22
−22,显然矩阵不是正定的
此时的函数为
f
(
x
1
,
x
2
)
=
2
x
1
2
+
12
x
1
x
2
+
7
x
2
2
f(x_1,x_2)=2x_1^2+12x_1x_2+7x_2^2
f(x1,x2)=2x12+12x1x2+7x22
如果取
x
1
=
1
,
x
2
=
−
1
x_1=1,x_2=-1
x1=1,x2=−1则有
f
(
1
,
−
1
)
=
2
−
12
+
7
<
0
f(1,-1)=2-12+7<0
f(1,−1)=2−12+7<0。\
如果我们把
z
=
2
x
2
+
12
x
y
+
7
y
2
z=2x^2+12xy+7y^2
z=2x2+12xy+7y2放在直角坐标系中,图像过原点
z
(
0
,
0
)
=
0
z(0,0)=0
z(0,0)=0,当
y
=
0
y=0
y=0或
x
=
0
x=0
x=0或
x
=
y
x=y
x=y时函数为开口向上的抛物线,所以函数图像在某些方向上是正值;而在某些方向上是负值,比如
x
=
−
y
x=-y
x=−y, 函数图像是一个马鞍面(saddle)
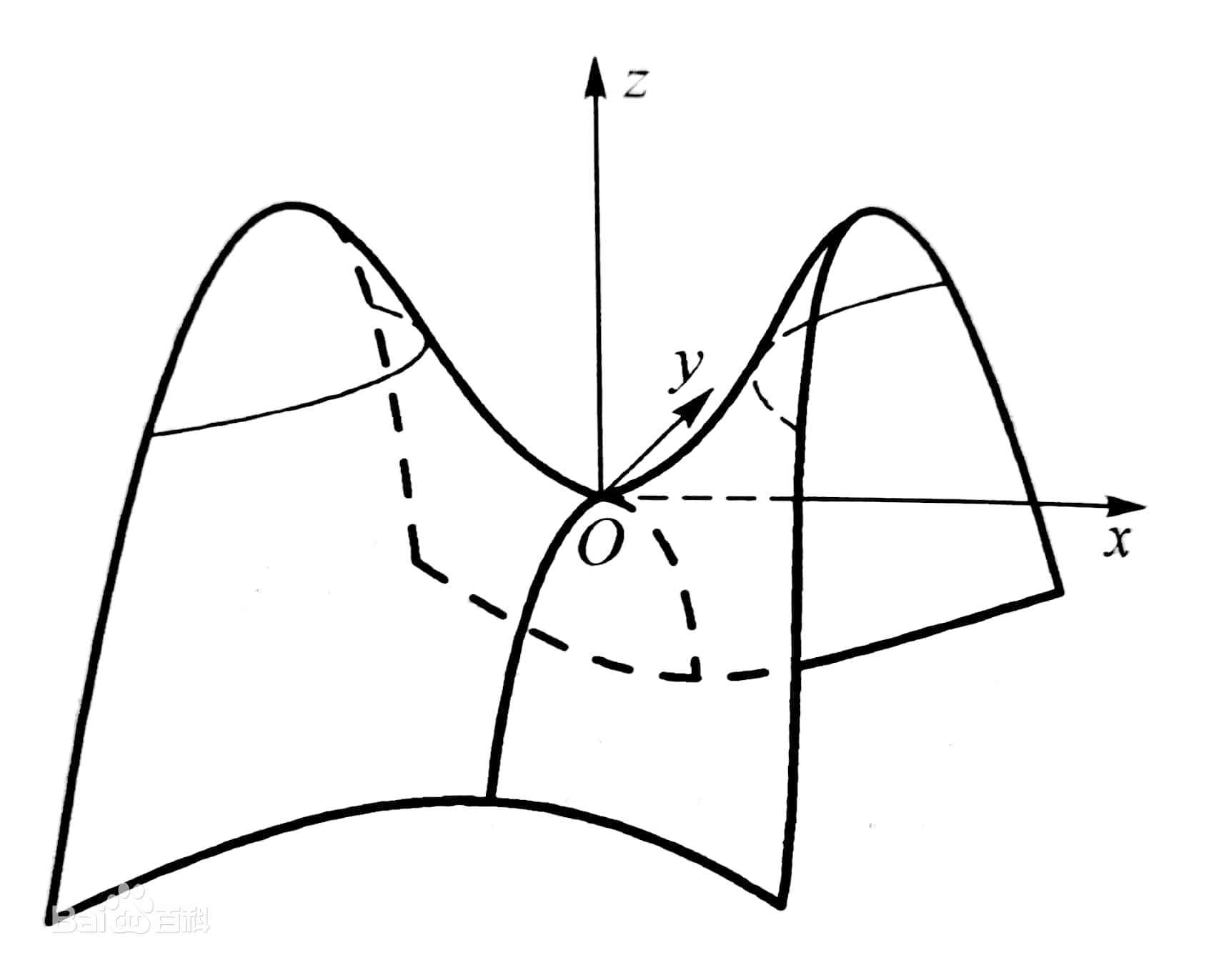
( 0 , 0 , 0 ) (0,0,0) (0,0,0)点称为鞍点(saddle point),它在某些方向上是极大值点,而在另一些方向上是极小值点(实际上函数图像的最佳观测方向是沿着特征向量的方向)
“一定满足”情形
令 ? = 20 ?=20 ?=20,矩阵为 A = [ 2 6 6 20 ] A=\begin{bmatrix}2&6\\6&20\end{bmatrix} A=[26620]
测试正定性
det A = 4 \det A=4 detA=4,迹为 t r a c e ( A ) = 22 trace(A)=22 trace(A)=22,特征值均大于零,矩阵可以通过测试
x T A x x^TAx xTAx图像

此时的函数为
f
(
x
,
y
)
=
2
x
2
+
12
x
y
+
20
y
2
f(x,y)=2x^2+12xy+20y^2
f(x,y)=2x2+12xy+20y2
函数在除
(
0
,
0
)
(0,0)
(0,0)外处处为正
我们来看看
z
=
2
x
2
+
12
x
y
+
20
y
2
z=2x^2+12xy+20y^2
z=2x2+12xy+20y2的图像
该函数的图像为一个开口向上的碗(抛物面/paraboloid)
在
(
0
,
0
)
(0,0)
(0,0)点函数的一阶偏导数均为零,二阶偏导数均为正(马鞍面的一阶偏导数也为零,但二阶偏导数并不均为正)所以,函数在该点取极小值
如果令 z = 1 z=1 z=1,相当于使用 z = 1 z=1 z=1平面截取该函数图像,将得到一个椭圆曲线。另外,如果在 ? = 7 ?=7 ?=7的马鞍面上截取曲线将得到一对双曲线。
x T A x x^TAx xTAx函数表达式分析
在本例中(即二阶情形),如果能用平方和的形式来表示函数,则很容易看出函数是否恒为正
使用配方法得
f
(
x
,
y
)
=
2
x
2
+
12
x
y
+
20
y
2
=
2
(
x
+
3
y
)
2
+
2
y
2
f(x,y)=2x^2+12xy+20y^2=2\left(x+3y\right)^2+2y^2
f(x,y)=2x2+12xy+20y2=2(x+3y)2+2y2
如果是上面的
?
=
7
?=7
?=7的情形,则有
f
(
x
,
y
)
=
2
(
x
+
3
y
)
2
−
11
y
2
f(x,y)=2(x+3y)^2-11y^2
f(x,y)=2(x+3y)2−11y2
如果是
?
=
18
?=18
?=18的情形,则有
f
(
x
,
y
)
=
2
(
x
+
3
y
)
2
f(x,y)=2(x+3y)^2
f(x,y)=2(x+3y)2。
A = L U A=LU A=LU和配方法系数的联系
再来看这个矩阵的消元,
[
2
6
6
20
]
=
[
1
0
3
1
]
[
2
6
0
2
]
\begin{bmatrix}2&6\\6&20\end{bmatrix}=\begin{bmatrix}1&0\\3&1\end{bmatrix}\begin{bmatrix}2&6\\0&2\end{bmatrix}
[26620]=[1301][2062]
这就是
A
=
L
U
A=LU
A=LU,可以发现矩阵
L
L
L中的项与配平方中未知数的系数有关,而
U
U
U的主元则与两个平方项外的系数有关,这也就是为什么正数主元得到正定矩阵。
二阶偏导数矩阵
在微积分中,一元函数取极小值需要一阶导数为零且二阶导数为正 d u d x = 0 , d 2 u d x 2 > 0 \frac{\mathrm{d}u}{\mathrm{d}x}=0, \frac{\mathrm{d}^2u}{\mathrm{d}x^2}>0 dxdu=0,dx2d2u>0
在线性代数中我们遇到了多元函数 f ( x 1 , x 2 , ⋯ , x n ) f(x_1,x_2,\cdots,x_n) f(x1,x2,⋯,xn),要取极小值需要二阶偏导数矩阵为正定矩阵
根据微积分的知识,对于含两个变量的函数,某点存在极小值条件是
1.该点一阶导数为0
2.该点二阶导数大于0
3.该点有
f
x
x
×
f
y
y
>
f
x
y
2
f_{xx} \times f_{yy} > f_{xy}^2
fxx×fyy>fxy2
二阶偏导数矩阵型为
A = [ f x x f x y f y x f y y ] A=\begin{bmatrix}f_{xx}&f_{xy}\\f_{yx}&f_{yy}\end{bmatrix} A=[fxxfyxfxyfyy]
为了满足极小值存在的条件2,3,需要两点:
1.矩阵中的主对角线元素(纯二阶导数)必须为正
2.主对角线元素必须足够大来抵消混合导数的影响
(因为二阶导数的求导次序并不影响结果,所以矩阵是对称的)
结合这两点,极小值判定条件2,3可以合并为:二阶偏导数矩阵必须是正定矩阵
至此,我们可以计算 n × n n\times n n×n阶矩阵了
3 × 3 3 \times 3 3×3阶矩阵举例
接下来计算一个三阶矩阵,
A
=
[
2
−
1
0
−
1
2
−
1
0
−
1
2
]
A=\begin{bmatrix}2&-1&0\\-1&2&-1\\0&-1&2\end{bmatrix}
A=⎣⎡2−10−12−10−12⎦⎤
它是正定的吗?函数
x
T
A
x
x^TAx
xTAx是多少?图像是什么样的?
- 先来计算矩阵的顺序主子式,分别为
2
,
3
,
4
2,3,4
2,3,4
再用顺序主子式来计算主元,分别为 2 , 3 2 , 4 3 2,\frac{3}{2},\frac{4}{3} 2,23,34
计算特征值, λ 1 = 2 − 2 , λ 2 = 2 , λ 3 = 2 + 2 \lambda_1=2-\sqrt 2,\lambda_2=2,\lambda_3=2+\sqrt 2 λ1=2−2,λ2=2,λ3=2+2
满足正定性验证条件 - 计算 x T A x = 2 x 1 2 + 2 x 2 2 + 2 x 3 2 − 2 x 1 x 2 − 2 x 2 x 3 x^TAx=2x_1^2+2x_2^2+2x_3^2-2x_1x_2-2x_2x_3 xTAx=2x12+2x22+2x32−2x1x2−2x2x3,函数表达式在除 ( 0 , 0 , 0 (0,0,0 (0,0,0点外,其他点均大于0
- 图像是四维的抛物面
当我们在 f ( x 1 , x 2 , x 3 ) = 1 f(x_1,x_2,x_3)=1 f(x1,x2,x3)=1处截取该面,将得到一个椭圆体
一般椭圆体有三条轴,特征值的大小决定了三条轴的长度,而特征向量的方向就是三条轴的方向

现在我们可以将矩阵
A
A
A分解,
A
=
Q
Λ
Q
T
A=Q\Lambda Q^T
A=QΛQT(因为是对称矩阵的对角化,所以可以用矩阵的转置替代逆)(
Q
Q
Q:特征向量矩阵,
Λ
\Lambda
Λ特征值矩阵)
我们把这个分解称为主轴定理(principal axis theorem),即特征向量说明主轴的方向、特征值说明主轴的长度。
这个 矩阵分解 是目前特征值理论中最重要的分解
第29讲:相似矩阵和若尔当形
正定矩阵
在本讲的开始,先接着上一讲来继续说一说正定矩阵。
正定性把以前的内容都串联起来
-
正定矩阵的逆矩阵也是正定矩阵
证明:
我们将正定矩阵分解为 A = S Λ S − 1 A=S\Lambda S^{-1} A=SΛS−1,引入其逆矩阵 A − 1 = S Λ − 1 S − 1 A^{-1}=S\Lambda^{-1}S^{-1} A−1=SΛ−1S−1
正定矩阵的特征值均为正值,所以其逆矩阵的特征值也必为正值(即原矩阵特征值的倒数)
所以,正定矩阵的逆矩阵也是正定的。 -
A , B A,\ B A, B均为正定矩阵,那么 A + B A+B A+B也为正定矩阵
证明:
我们可以从判定 x T ( A + B ) x > 0 x^T(A+B)x>0 xT(A+B)x>0入手
根据条件有 x T A x > 0 , x T B x > 0 x^TAx>0,\ x^TBx>0 xTAx>0, xTBx>0
将两式相加即得到 x T ( A + B ) x > 0 x^T(A+B)x>0 xT(A+B)x>0
( x T A x + x T B x = x T ( A x + B x ) = x T ( A + B ) x x^TAx+x^TBx = x^T(Ax+Bx) = x^T(A+B)x xTAx+xTBx=xT(Ax+Bx)=xT(A+B)x)
所以正定矩阵之和也是正定矩阵。 -
有 m × n m\times n m×n矩阵 A A A, A A A各列线性无关,则 A T A A^TA ATA正定
最小二乘法得到的 A T A A^TA ATA(是对称矩阵,方阵)
用数字打比方就像是一个平方,用向量打比方就像是向量的长度平方,而对于矩阵,有 A T A A^TA ATA正定
证明:
在式子两边分别乘 x T x^T xT得到 x T A T A x > 0 x^TA^TAx>0 xTATAx>0
分组得到 ( A x ) T ( A x ) > 0 (Ax)^T(Ax)>0 (Ax)T(Ax)>0
相当于得到了向量 A x Ax Ax的长度平方, ∣ A x ∣ 2 ≥ 0 |Ax|^2\geq0 ∣Ax∣2≥0
在 x ≠ 0 x≠0 x=0时, ∣ A x ∣ 2 > 0 |Ax|^2>0 ∣Ax∣2>0,则需要 A x Ax Ax的零空间中仅有零向量
即 A A A的各列线性无关时,( A A A各列线性相关则半正定)即可保证在 x ≠ 0 x≠0 x=0时, ∣ A x ∣ 2 > 0 |Ax|^2>0 ∣Ax∣2>0, A T A A^TA ATA正定
(可联系16讲 A T A A^TA ATA可逆的证明) -
A T A A^TA ATA是正定矩阵为计算提供了很多便利
在矩阵数值计算中,正定矩阵消元不需要进行“行交换”操作,也不必担心主元过小或为零,正定矩阵具有良好的计算性质
接下来进入本讲的正题
相似矩阵
定义
A , B A,B A,B是两个 n × n n\times n n×n矩阵,对于某矩阵 M M M满足 B = M − 1 A M B=M^{-1}AM B=M−1AM时,称 A , B A,\ B A, B互为相似矩阵。
例子
特征值无重复
对于在对角化一讲(第二十二讲)中学过的式子 S − 1 A S = Λ S^{-1}AS=\Lambda S−1AS=Λ,则有 A A A相似于 Λ \Lambda Λ。
- 举个例子,
A
=
[
2
1
1
2
]
A=\begin{bmatrix}2&1\\1&2\end{bmatrix}
A=[2112]
容易通过迹和行列式得到相应的对角矩阵 Λ = [ 3 0 0 1 ] \Lambda=\begin{bmatrix}3&0\\0&1\end{bmatrix} Λ=[3001]
另外,可以随意构造一个矩阵 M = [ 1 4 0 1 ] M=\begin{bmatrix}1&4\\0&1\end{bmatrix} M=[1041]
则 B = M − 1 A M = [ 1 − 4 0 1 ] [ 2 1 1 2 ] [ 1 4 0 1 ] = [ − 2 − 15 1 6 ] B=M^{-1}AM=\begin{bmatrix}1&-4\\0&1\end{bmatrix}\begin{bmatrix}2&1\\1&2\end{bmatrix}\begin{bmatrix}1&4\\0&1\end{bmatrix}=\begin{bmatrix}-2&-15\\1&6\end{bmatrix} B=M−1AM=[10−41][2112][1041]=[−21−156]。
我们来计算这几个矩阵的的特征值(利用迹与行列式的性质), λ Λ = 3 , 1 \lambda_{\Lambda}=3,\ 1 λΛ=3, 1、 λ A = 3 , 1 \lambda_A=3,\ 1 λA=3, 1、 λ B = 3 , 1 \lambda_B=3,\ 1 λB=3, 1。
对角阵的特征向量矩阵为 单位矩阵:
S S S为 I I I时满足 S − 1 Λ S = Λ S^{-1}\Lambda S=\Lambda S−1ΛS=Λ
上三角矩阵求逆:
用分块矩阵方法求逆
A = [ B C 0 D ] A=\begin{bmatrix}B&C\\0&D\end{bmatrix} A=[B0CD]
当 B , D B,D B,D可逆时 A A A也可逆, 且
A − 1 = [ B − 1 B − 1 C D − 1 0 D − 1 ] A^{-1} = \begin{bmatrix}B^{-1}&B^{-1}CD^{-1}\\0&D^{-1}\end{bmatrix} A−1=[B−10B−1CD−1D−1]
可得结论:相似矩阵有相同的特征值。
- 继续上面的例子,特征值为 3 , 1 3,\ 1 3, 1的这一族矩阵都是相似矩阵,如 [ 3 7 0 1 ] \begin{bmatrix}3&7\\0&1\end{bmatrix} [3071]、 [ 1 7 0 3 ] \begin{bmatrix}1&7\\0&3\end{bmatrix} [1073],其中最特殊的是 Λ \Lambda Λ。
现在我们来证明这个结论:
有
A
x
=
λ
x
,
B
=
M
−
1
A
M
Ax=\lambda x,\ B=M^{-1}AM
Ax=λx, B=M−1AM
第一个式子化为
A
M
M
−
1
x
=
λ
x
AMM^{-1}x=\lambda x
AMM−1x=λx
接着两边同时左乘
M
−
1
M^{-1}
M−1得
M
−
1
A
M
M
−
1
x
=
λ
M
−
1
x
M^{-1}AMM^{-1}x=\lambda M^{-1}x
M−1AMM−1x=λM−1x
进行适当的划分得
(
M
−
1
A
M
)
M
−
1
x
=
λ
M
−
1
x
\left(M^{-1}AM\right)M^{-1}x=\lambda M^{-1}x
(M−1AM)M−1x=λM−1x
即
B
M
−
1
x
=
λ
M
−
1
x
BM^{-1}x=\lambda M^{-1}x
BM−1x=λM−1x。
由
B
M
−
1
=
λ
M
−
1
x
BM^{-1}=\lambda M^{-1}x
BM−1=λM−1x可得
结论:
B
B
B的特征值也为
λ
\lambda
λ,而特征向量变为
M
−
1
x
M^{-1}x
M−1x
以上就是我们得到的一组特征值为 3 , 1 3,\ 1 3, 1的矩阵,它们具有相同的特征值。接下来看特征值重复时的情形。
特征值有重复
-
特征值重复可能会导致特征向量短缺
来看一个例子,设 λ 1 = λ 2 = 4 \lambda_1=\lambda_2=4 λ1=λ2=4
写出具有这种特征值的两个矩阵 [ 4 0 0 4 ] \begin{bmatrix}4&0\\0&4\end{bmatrix} [4004], [ 4 1 0 4 ] \begin{bmatrix}4&1\\0&4\end{bmatrix} [4014]
其实,具有这种特征值的矩阵可以分为两族
1.第一族仅有一个矩阵 [ 4 0 0 4 ] \begin{bmatrix}4&0\\0&4\end{bmatrix} [4004],它只与自己相似
(因为 M − 1 [ 4 0 0 4 ] M = 4 M − 1 I M = 4 I = [ 4 0 0 4 ] M^{-1}\begin{bmatrix}4&0\\0&4\end{bmatrix}M=4M^{-1}IM=4I=\begin{bmatrix}4&0\\0&4\end{bmatrix} M−1[4004]M=4M−1IM=4I=[4004],所以无论 M M M如何取值该对角矩阵都只与自己相似)
2.另一族就是剩下的诸如 [ 4 1 0 4 ] \begin{bmatrix}4&1\\0&4\end{bmatrix} [4014]的矩阵,它们都是相似的
它们只有一个特征向量,因此它们不能对角化
在这个“大家族”中, [ 4 1 0 4 ] \begin{bmatrix}4&1\\0&4\end{bmatrix} [4014]是“最好”的一个矩阵,称为若尔当标准形。 -
继续上面的例子,我们在给出几个这一族的矩阵 [ 4 1 0 4 ] , [ 5 1 − 1 3 ] , [ 4 0 17 4 ] \begin{bmatrix}4&1\\0&4\end{bmatrix},\ \begin{bmatrix}5&1\\-1&3\end{bmatrix},\ \begin{bmatrix}4&0\\17&4\end{bmatrix} [4014], [5−113], [41704],我们总是可以构造出一个满足 t r a c e ( A ) = 8 , det A = 16 trace(A)=8,\ \det A=16 trace(A)=8, detA=16的矩阵,这些矩阵总是在这一个“家族”中
对于无法对角化的矩阵,我们都可以通过特殊的方法完成近似“对角化”,变成若尔当标准形
若尔当形在过去是线性代数的核心知识,但现在不是了(现在是下一讲的奇异值分解),因为它并不容易计算。
若尔当形
仅仅是特征向量的数目相同还不够
我们再来看一个更加“糟糕”的例子:特征向量数目也相同但不相似
-
矩阵 [ 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 ] \begin{bmatrix}0&1&0&0\\0&0&1&0\\0&0&0&0\\0&0&0&0\end{bmatrix} ⎣⎢⎢⎡0000100001000000⎦⎥⎥⎤
其特征值为四个 0 0 0。
很明显矩阵的秩为 2 2 2,所以其零空间的维数为 4 − 2 = 2 4-2=2 4−2=2,即该矩阵有两个特征向量
在所有的 对角线上方第一个元素,每让一个 0 0 0变为 1 1 1,特征向量个数就减少一个。可以发现这个矩阵有两个 1 1 1,特征向量个数减2 -
矩阵 [ 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 ] \begin{bmatrix}0&1&0&0\\0&0&0&0\\0&0&0&1\\0&0&0&0\end{bmatrix} ⎣⎢⎢⎡0000100000000010⎦⎥⎥⎤
从特征向量的数目看来这两个矩阵是相似的,其实不然。若尔当认为第一个矩阵是由一个 3 × 3 3\times 3 3×3的块与一个 1 × 1 1\times 1 1×1的块组成的
[ 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 ] \left[\begin{array}{ccc|c}0&1&0&0\\0&0&1&0\\0&0&0&0\\\hline0&0&0&0\end{array}\right] ⎣⎢⎢⎡0000100001000000⎦⎥⎥⎤
而第二个矩阵是由两个 2 × 2 2\times 2 2×2矩阵组成的
[ 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 ] \left[\begin{array}{cc|cc}0&1&0&0\\0&0&0&0\\\hline0&0&0&1\\0&0&0&0\end{array}\right] ⎣⎢⎢⎡0000100000000010⎦⎥⎥⎤
这些分块被称为若尔当块。
若尔当块: i i i阶的若尔当块 J i J_i Ji,只有一个重复的特征值 λ i \lambda_i λi,仅有一个特征向量

上面的例子中,虽然特征向量的数目相同,但是分块的大小不同,我们便认为这两个矩阵不相似
若尔当定理:
每一个矩阵
A
A
A都相似于一个若尔当阵
J
=
[
J
1
J
2
⋱
J
d
]
J=\left[\begin{array}{c|c|c|c}J_1&&&\\\hline&J_2&&\\\hline&&\ddots&\\\hline&&&J_d\end{array}\right]
J=⎣⎢⎢⎡J1J2⋱Jd⎦⎥⎥⎤
若尔当块个数=矩阵特征向量个数(每一块对应一个特征向量)
n
n
n阶方阵有
n
n
n个不同的特征值时
它可以对角化,所以它的若尔当矩阵就是
Λ
\Lambda
Λ,共
n
n
n个特征向量,有
n
n
n个若尔当块。
这是我们关注的情况
特征值重复的情况我们不怎么重视(求若尔当阵比较困难,这里没有给出)
不过我们最关心的还是正定矩阵
第30讲:奇异值分解(SVD)
SVD是矩阵最终和最好的分解
本讲我们介绍将一个矩阵分解为
A
=
U
Σ
V
T
A=U\varSigma V^T
A=UΣVT
分解的因子分别为正交矩阵、对角矩阵、正交矩阵
与前面几讲的分解不同的是,这两个正交矩阵通常是不同的,而且这个式子可以对任意矩阵使用,不限于方阵、可对角化的方阵等。
对比之前的分解
-
正定矩阵分解:
在正定一讲中(第28讲)我们知道一个正定矩阵可以分解为 A = Q Λ Q T A=Q\Lambda Q^T A=QΛQT的形式
由于 A A A的对称性,其特征向量是正交的。并且 Λ \Lambda Λ矩阵中的元素皆为正,这就是正定矩阵的奇异值分解
在这种特殊的分解中,我们只需要一个正交矩阵 Q Q Q就可以使等式成立。 -
矩阵对角化:
在对角化一讲中(第22讲),我们知道可对角化的矩阵能够分解为 A = S Λ S T A=S\Lambda S^T A=SΛST的形式
其中 S S S的列向量由 A A A的特征向量组成,但 S S S并不是正交矩阵,所以这不是我们希望得到的奇异值分解
理论概述
我们现在要做的是
在
A
A
A的列空间中找到一组标准正交基
v
1
,
v
2
,
⋯
,
v
r
v_1,v_2,\cdots,v_r
v1,v2,⋯,vr
这组基在
A
A
A的作用下可以转换为
A
A
A的行空间中的一组标准正交基
u
1
,
u
2
,
⋯
,
u
r
u_1,u_2,\cdots,u_r
u1,u2,⋯,ur。
用矩阵语言描述为
A
[
v
1
v
2
⋯
v
r
]
=
[
σ
1
u
1
σ
2
u
2
⋯
σ
r
u
r
]
=
[
u
1
u
2
⋯
u
r
]
[
σ
1
σ
2
⋱
σ
n
]
A\Bigg[v_1\ v_2\ \cdots\ v_r\Bigg]=\Bigg[\sigma_1u_1\ \sigma_2u_2\ \cdots\ \sigma_ru_r\Bigg]=\Bigg[u_1\ u_2\ \cdots\ u_r\Bigg]\begin{bmatrix}\sigma_1&&&\\&\sigma_2&&\\&&\ddots&\\&&&\sigma_n\end{bmatrix}
A[v1 v2 ⋯ vr]=[σ1u1 σ2u2 ⋯ σrur]=[u1 u2 ⋯ ur]⎣⎢⎢⎡σ1σ2⋱σn⎦⎥⎥⎤
即
A
v
1
=
σ
1
u
1
,
A
v
2
=
σ
2
u
2
,
⋯
,
A
v
r
=
σ
r
u
r
Av_1=\sigma_1u_1,\ Av_2=\sigma_2u_2,\cdots,Av_r=\sigma_ru_r
Av1=σ1u1, Av2=σ2u2,⋯,Avr=σrur,其中
σ
\sigma
σ是缩放因子,而在
A
A
A的左零空间和零空间体现是
σ
\sigma
σ为
0
0
0
另外,如果算上左零、零空间,我们同样可以对左零、零空间取标准正交基,然后写为
A [ v 1 v 2 ⋯ v r v r + 1 ⋯ v m ] = [ u 1 u 2 ⋯ u r u r + 1 ⋯ u n ] [ σ 1 ⋱ σ r [ 0 ] ] A\Bigg[v_1\ v_2\ \cdots\ v_r\ v_{r+1}\ \cdots\ v_m\Bigg]=\Bigg[u_1\ u_2\ \cdots\ u_r\ u_{r+1}\ \cdots \ u_n\Bigg]\left[\begin{array}{c c c|c}\sigma_1&&&\\&\ddots&&\\&&\sigma_r&\\\hline&&&\begin{bmatrix}0\end{bmatrix}\end{array}\right] A[v1 v2 ⋯ vr vr+1 ⋯ vm]=[u1 u2 ⋯ ur ur+1 ⋯ un]⎣⎢⎢⎡σ1⋱σr[0]⎦⎥⎥⎤
此时 U U U是 m × m m\times m m×m正交矩阵, Σ \varSigma Σ是 m × n m\times n m×n对角矩阵, V T V^T VT是 n × n n\times n n×n正交矩阵。
最终可以写为
A
V
=
U
Σ
AV=U\varSigma
AV=UΣ
可以看出这十分类似对角化的公式:矩阵
A
A
A被转化为对角矩阵
Σ
\varSigma
Σ,我们也注意到
U
,
V
U,\ V
U, V是两组不同的正交基(在正定的情况下,
U
,
V
U,\ V
U, V都变成了
Q
Q
Q)
进一步可以写作
A
=
U
Σ
V
−
1
A=U\varSigma V^{-1}
A=UΣV−1,因为
V
V
V是标准正交矩阵所以还可写为
A
=
U
Σ
V
T
A=U\varSigma V^T
A=UΣVT
例子
N ( A ) N(A) N(A)只有零向量
目标
分解 A = [ 4 4 − 3 3 ] A=\begin{bmatrix}4&4\\-3&3\end{bmatrix} A=[4−343],我们需要找到:
- 行空间 R 2 \mathbb{R}^2 R2的标准正交基 v 1 , v 2 v_1,v_2 v1,v2;
- 列空间 R 2 \mathbb{R}^2 R2的标准正交基 u 1 , u 2 u_1,u_2 u1,u2;
- σ 1 > 0 , σ 2 > 0 \sigma_1>0, \sigma_2>0 σ1>0,σ2>0。
思路
在 A = U Σ V T A=U\varSigma V^T A=UΣVT中有两个标准正交矩阵需要求解,我们希望一次只解一个,如何先将 U U U消去来求 V V V?
这个技巧经常出现在长方形矩阵中(最小二乘法):求
A
T
A
A^TA
ATA
这是一个对称正定矩阵(至少是半正定矩阵)
于是有
A
T
A
=
V
Σ
T
U
T
U
Σ
V
T
A^TA=V\varSigma^TU^TU\varSigma V^T
ATA=VΣTUTUΣVT
由于
U
U
U是标准正交矩阵,所以
U
T
U
=
I
U^TU=I
UTU=I
而
Σ
T
Σ
\varSigma^T\varSigma
ΣTΣ是对角线元素为
σ
2
\sigma^2
σ2的对角矩阵
现在有
A
T
A
=
V
[
σ
1
2
σ
2
2
⋱
σ
n
2
]
V
T
A^TA=V\begin{bmatrix}\sigma_1^2&&&\\&\sigma_2^2&&\\&&\ddots&\\&&&\sigma_n^2\end{bmatrix}V^T
ATA=V⎣⎢⎢⎡σ12σ22⋱σn2⎦⎥⎥⎤VT
所以
V
V
V即是
A
T
A
A^TA
ATA的特征向量矩阵而
Σ
2
\varSigma^2
Σ2是
A
T
A
A^TA
ATA的特征值矩阵
同理,我们只想求 U U U时,用 A A T AA^T AAT消掉 V V V即可。
具体计算
求解 Σ \varSigma Σ和 V T V^T VT
我们来计算
A
T
A
=
[
4
−
3
4
3
]
[
4
4
−
3
3
]
=
[
25
7
7
25
]
A^TA=\begin{bmatrix}4&-3\\4&3\end{bmatrix}\begin{bmatrix}4&4\\-3&3\end{bmatrix}=\begin{bmatrix}25&7\\7&25\end{bmatrix}
ATA=[44−33][4−343]=[257725]
对于简单的矩阵,特征向量可以直接观察得到:
A
T
A
[
1
1
]
=
32
[
1
1
]
,
A
T
A
[
1
−
1
]
=
18
[
1
−
1
]
A^TA\begin{bmatrix}1\\1\end{bmatrix}=32\begin{bmatrix}1\\1\end{bmatrix},\ A^TA\begin{bmatrix}1\\-1\end{bmatrix}=18\begin{bmatrix}1\\-1\end{bmatrix}
ATA[11]=32[11], ATA[1−1]=18[1−1]
化为单位向量有
σ
1
=
32
,
v
1
=
[
1
2
1
2
]
,
σ
2
=
18
,
v
2
=
[
1
2
−
1
2
]
\sigma_1=32,\ v_1=\begin{bmatrix}\frac{1}{\sqrt{2}}\\\frac{1}{\sqrt{2}}\end{bmatrix},\ \sigma_2=18,\ v_2=\begin{bmatrix}\frac{1}{\sqrt{2}}\\-\frac{1}{\sqrt{2}}\end{bmatrix}
σ1=32, v1=[2121], σ2=18, v2=[21−21]。
到目前为止,我们得到 [ 4 4 − 3 3 ] = [ u ? u ? u ? u ? ] [ 32 0 0 18 ] [ 1 2 1 2 1 2 − 1 2 ] \begin{bmatrix}4&4\\-3&3\end{bmatrix}=\begin{bmatrix}u_?&u_?\\u_?&u_?\end{bmatrix}\begin{bmatrix}\sqrt{32}&0\\0&\sqrt{18}\end{bmatrix}\begin{bmatrix}\frac{1}{\sqrt{2}}&\frac{1}{\sqrt{2}}\\\frac{1}{\sqrt{2}}&-\frac{1}{\sqrt{2}}\end{bmatrix} [4−343]=[u?u?u?u?][320018][212121−21]
求解 U U U
接下来继续求解 U U U。
A A T = U Σ V T V Σ T U T = U Σ 2 U T AA^T=U\varSigma V^TV\varSigma^TU^T=U\varSigma^2U^T AAT=UΣVTVΣTUT=UΣ2UT,求出 A A T AA^T AAT的特征向量即可得到 U U U
[ 4 4 − 3 3 ] [ 4 − 3 4 3 ] = [ 32 0 0 18 ] \begin{bmatrix}4&4\\-3&3\end{bmatrix}\begin{bmatrix}4&-3\\4&3\end{bmatrix}=\begin{bmatrix}32&0\\0&18\end{bmatrix} [4−343][44−33]=[320018]
观察得 A A T [ 1 0 ] = 32 [ 1 0 ] , A A T [ 0 1 ] = 18 [ 0 1 ] AA^T\begin{bmatrix}1\\0\end{bmatrix}=32\begin{bmatrix}1\\0\end{bmatrix},\ AA^T\begin{bmatrix}0\\1\end{bmatrix}=18\begin{bmatrix}0\\1\end{bmatrix} AAT[10]=32[10], AAT[01]=18[01]
但是我们不能直接使用这一组特征向量
因为式子
A
V
=
U
Σ
AV=U\varSigma
AV=UΣ明确告诉我们,一旦
V
V
V确定下来,
U
U
U也必须取能够满足该式的向量
所以此处
A
v
2
=
[
0
−
18
]
=
u
2
σ
2
=
[
0
−
1
]
18
Av_2=\begin{bmatrix}0\\-\sqrt{18}\end{bmatrix}=u_2\sigma_2=\begin{bmatrix}0\\-1\end{bmatrix}\sqrt{18}
Av2=[0−18]=u2σ2=[0−1]18,则
u
1
=
[
1
0
]
,
u
2
=
[
0
−
1
]
u_1=\begin{bmatrix}1\\0\end{bmatrix},\ u_2=\begin{bmatrix}0\\-1\end{bmatrix}
u1=[10], u2=[0−1]。(这个问题在本讲的官方笔记中有详细说明)
我们发现 A T A A^TA ATA与 A A T AA^T AAT特征值相同
补充: A B AB AB的特征值与 B A BA BA的特征值相同
证明:
1.取 A B AB AB的特征值 λ ≠ 0 \lambda\neq 0 λ=0, v v v是 A B AB AB在特征值取 λ \lambda λ时的特征向量
则有 B v ≠ 0 Bv\neq 0 Bv=0
并有 λ B v = B ( λ v ) = B ( A B v ) = ( B A ) B v \lambda Bv=B(\lambda v)=B(ABv)=(BA)Bv λBv=B(λv)=B(ABv)=(BA)Bv
所以 B v Bv Bv是 B A BA BA在特征值取同一个 λ \lambda λ时的特征向量。
2.取 λ = 0 \lambda=0 λ=0
则 0 = det A B = det A det B = det B A 0=\det{AB}=\det{A}\det{B}=\det{BA} 0=detAB=detAdetB=detBA,所以 λ = 0 \lambda=0 λ=0也是 B A BA BA的特征值,得证。
(证明来自Are the eigenvalues of AB equal to the eigenvalues of BA? (Citation needed!))
最终,我们得到 [ 4 4 − 3 3 ] = [ 1 0 0 − 1 ] [ 32 0 0 18 ] [ 1 2 1 2 1 2 − 1 2 ] \begin{bmatrix}4&4\\-3&3\end{bmatrix}=\begin{bmatrix}1&0\\0&-1\end{bmatrix}\begin{bmatrix}\sqrt{32}&0\\0&\sqrt{18}\end{bmatrix}\begin{bmatrix}\frac{1}{\sqrt{2}}&\frac{1}{\sqrt{2}}\\\frac{1}{\sqrt{2}}&-\frac{1}{\sqrt{2}}\end{bmatrix} [4−343]=[100−1][320018][212121−21]
N ( A ) N(A) N(A)不止有零向量
A
=
[
4
3
8
6
]
A=\begin{bmatrix}4&3\\8&6\end{bmatrix}
A=[4836]
这是个秩一矩阵,有零空间
A
A
A的行空间为
[
4
3
]
\begin{bmatrix}4\\3\end{bmatrix}
[43]的倍数,
A
A
A的列空间为
[
4
8
]
\begin{bmatrix}4\\8\end{bmatrix}
[48]的倍数。
- 标准化向量得 v 1 = [ 0.8 0.6 ] , u 1 = 1 5 [ 1 2 ] v_1=\begin{bmatrix}0.8\\0.6\end{bmatrix},\ u_1=\frac{1}{\sqrt{5}}\begin{bmatrix}1\\2\end{bmatrix} v1=[0.80.6], u1=51[12]。
-
A
T
A
=
[
4
8
3
6
]
[
4
3
8
6
]
=
[
80
60
60
45
]
A^TA=\begin{bmatrix}4&8\\3&6\end{bmatrix}\begin{bmatrix}4&3\\8&6\end{bmatrix}=\begin{bmatrix}80&60\\60&45\end{bmatrix}
ATA=[4386][4836]=[80606045]
由于 A A A是秩一矩阵,则 A T A A^TA ATA也不满秩,所以必有特征值 0 0 0,则另特征值一个由迹可知为 125 125 125 - 继续求零空间的特征向量,有 v 2 = [ 0.6 − 0 , 8 ] , u 2 = 1 5 [ 2 − 1 ] v_2=\begin{bmatrix}0.6\\-0,8\end{bmatrix},\ u_2=\frac{1}{\sqrt{5}}\begin{bmatrix}2\\-1\end{bmatrix} v2=[0.6−0,8], u2=51[2−1]
最终得到 [ 4 3 8 6 ] = [ 1 2 ‾ 2 − 1 ‾ ] [ 125 0 0 0 ‾ ] [ 0.8 0.6 0.6 ‾ − 0.8 ‾ ] \begin{bmatrix}4&3\\8&6\end{bmatrix}=\begin{bmatrix}1&\underline {2}\\2&\underline{-1}\end{bmatrix}\begin{bmatrix}\sqrt{125}&0\\0&\underline{0}\end{bmatrix}\begin{bmatrix}0.8&0.6\\\underline{0.6}&\underline{-0.8}\end{bmatrix} [4836]=[122−1][125000][0.80.60.6−0.8],其中下划线部分都是与零空间相关的部分。
总结
在四个基本子空间选出合适的基:
- v 1 , ⋯ , v r v_1,\ \cdots,\ v_r v1, ⋯, vr是行空间的标准正交基;
- u 1 , ⋯ , u r u_1,\ \cdots,\ u_r u1, ⋯, ur是列空间的标准正交基;
- v r + 1 , ⋯ , v n v_{r+1},\ \cdots,\ v_n vr+1, ⋯, vn是零空间的标准正交基;
- u r + 1 , ⋯ , u m u_{r+1},\ \cdots,\ u_m ur+1, ⋯, um是左零空间的标准正交基。
A
v
i
=
σ
i
u
i
Av_i=\sigma_iu_i
Avi=σiui
向量
v
v
v之间没有耦合,
u
u
u也没有
A
A
A乘以每个
v
v
v都能对应一个
u
u
u的方向
在课程最后,我们会更深入了解SVD
第31讲:线性变换及对应矩阵
定义
如何判断一个操作是不是线性变换?线性变换需满足以下两个要求:
T ( v + w ) = T ( v ) + T ( w ) T ( c v ) = c T ( v ) T(v+w)=T(v)+T(w)\\ T(cv)=cT(v) T(v+w)=T(v)+T(w)T(cv)=cT(v)
即变换
T
T
T需要同时满足加法和数乘不变的性质
将两个性质合成一个式子为:
T
(
c
v
+
d
w
)
=
c
T
(
v
)
+
d
T
(
w
)
T(cv+dw)=cT(v)+dT(w)
T(cv+dw)=cT(v)+dT(w)
例子
反例
例1
二维空间的平移操作,即平面平移:

比如,上图中向量长度翻倍,再做平移,明显与向量平移后再翻倍的结果不一致。
有时我们也可以用一个简单的特例判断线性变换,比如是否满足检查
T
(
0
)
=
0
T(0)=0
T(0)=0
该例零向量平移后结果并不为零
所以平面平移操作并不是线性变换。
例2
求模运算,
T
(
v
)
=
∥
v
∥
,
T
:
R
3
→
R
1
T(v)=\|v\|,\ T:\mathbb{R}^3\to\mathbb{R}^1
T(v)=∥v∥, T:R3→R1
这显然不是线性变换
虽然我们将向量翻倍则其模翻倍
但如果我们将向量翻倍的倍数取负,而其模不能为负,就会不满足条件
所以
T
(
−
v
)
≠
−
T
(
v
)
T(-v)\neq -T(v)
T(−v)=−T(v)
正例
例3
二维空间中的投影操作,
T
:
R
2
→
R
2
T: \mathbb{R}^2\to\mathbb{R}^2
T:R2→R2
它可以将某向量投影在一条特定直线上
检查一下投影操作,如果我们将向量长度翻倍,则其投影也翻倍
两向量相加后做投影与两向量做投影再相加结果一致
所以投影操作是线性变换。
例4
旋转
4
5
∘
45^\circ
45∘操作,
T
:
R
2
→
R
2
T:\mathbb{R}^2\to\mathbb{R}^2
T:R2→R2
也就是将平面内一个向量映射为平面内另一个向量
检查可知,如果向量翻倍,则旋转后同样翻倍
两个向量先旋转后相加,与这两个向量先相加后旋转得到的结果一样。
所以从上面的例子我们知道,投影与旋转都是线性变换。
例5
矩阵乘以向量,
T
(
v
)
=
A
v
T(v)=Av
T(v)=Av
这也是一个(一系列)线性变换
不同的矩阵代表不同的线性变换
根据矩阵的运算法则有
A
(
v
+
w
)
=
A
(
v
)
+
A
(
w
)
,
A
(
c
v
)
=
c
A
v
A(v+w)=A(v)+A(w),\ A(cv)=cAv
A(v+w)=A(v)+A(w), A(cv)=cAv
比如取
A
=
[
1
0
0
−
1
]
A=\begin{bmatrix}1&0\\0&-1\end{bmatrix}
A=[100−1],作用于平面上的向量
v
v
v,会导致
v
v
v的
x
x
x分量不变,而
y
y
y分量取反,也就是图像沿
x
x
x轴翻转。
对应矩阵
线性变换的核心,就是该变换使用的对应的矩阵。
比如我们需要做一个线性变换,将一个三维向量降至二维,
T
:
R
3
→
R
2
T:\mathbb{R}^3\to\mathbb{R}^2
T:R3→R2
则在
T
(
v
)
=
A
v
T(v)=Av
T(v)=Av中,
v
∈
R
3
,
T
(
v
)
∈
R
2
v\in\mathbb{R}^3,\ T(v)\in\mathbb{R}^2
v∈R3, T(v)∈R2
所以
A
A
A应当是一个
2
×
3
2\times 3
2×3矩阵。
一个线性变换对应一个矩阵 原理
如果我们希望知道线性变换
T
T
T对整个输入空间
R
n
\mathbb{R}^n
Rn的影响
我们可以找到空间的一组基
v
1
,
v
2
,
⋯
,
v
n
v_1,\ v_2,\ \cdots,\ v_n
v1, v2, ⋯, vn
检查
T
T
T对每一个基的影响
T
(
v
1
)
,
T
(
v
2
)
,
⋯
,
T
(
v
n
)
T(v_1),\ T(v_2),\ \cdots,\ T(v_n)
T(v1), T(v2), ⋯, T(vn)
由于输入空间中的任意向量都满足:
v = c 1 v 1 + c 2 v 2 + ⋯ + c n v n (1) v=c_1v_1+c_2v_2+\cdots+c_nv_n\tag{1} v=c1v1+c2v2+⋯+cnvn(1)
所以我们可以根据 T ( v ) T(v) T(v)推出线性变换 T T T对空间内任意向量的影响,得到:
T ( v ) = c 1 T ( v 1 ) + c 2 T ( v 2 ) + ⋯ + c n T ( v n ) (2) T(v)=c_1T(v_1)+c_2T(v_2)+\cdots+c_nT(v_n)\tag{2} T(v)=c1T(v1)+c2T(v2)+⋯+cnT(vn)(2)
现在我们需要考虑,如何把一个与坐标无关的线性变换变成一个与坐标有关的矩阵呢?
在
1
1
1式中,
c
1
,
c
2
,
⋯
,
c
n
c_1,c_2,\cdots,c_n
c1,c2,⋯,cn就是向量
v
v
v在基
v
1
,
v
2
,
⋯
,
v
n
v_1,v_2,\cdots,v_n
v1,v2,⋯,vn上的坐标
比如分解向量
v
=
[
3
2
4
]
=
3
[
1
0
0
]
+
2
[
0
1
0
]
+
4
[
0
0
1
]
v=\begin{bmatrix}3\\2\\4\end{bmatrix}=3\begin{bmatrix}1\\0\\0\end{bmatrix}+2\begin{bmatrix}0\\1\\0\end{bmatrix}+4\begin{bmatrix}0\\0\\1\end{bmatrix}
v=⎣⎡324⎦⎤=3⎣⎡100⎦⎤+2⎣⎡010⎦⎤+4⎣⎡001⎦⎤
式子将向量
v
v
v分解在一组标准正交基
[
1
0
0
]
,
[
0
1
0
]
,
[
0
0
1
]
\begin{bmatrix}1\\0\\0\end{bmatrix},\begin{bmatrix}0\\1\\0\end{bmatrix},\begin{bmatrix}0\\0\\1\end{bmatrix}
⎣⎡100⎦⎤,⎣⎡010⎦⎤,⎣⎡001⎦⎤上
当然,我们也可以选用矩阵的特征向量作为基向量,基的选择是多种多样的。
例子
选取投影的特征向量作为基
我们打算构造一个矩阵
A
A
A用以表示线性变换
T
:
R
n
→
R
m
T:\mathbb{R}^n\to\mathbb{R}^m
T:Rn→Rm
我们需要两组基,一组用以表示输入向量,一组用以表示输出向量
令
v
1
,
v
2
,
⋯
,
v
n
v_1,v_2,\cdots,v_n
v1,v2,⋯,vn为输入向量的基,这些向量来自
R
n
\mathbb{R}^n
Rn
令
w
1
,
w
2
,
⋯
,
w
m
w_1,w_2,\cdots,w_m
w1,w2,⋯,wm作为输出向量的基,这些向量来自
R
m
\mathbb{R}^m
Rm。
我们用二维空间的投影矩阵作为例子:
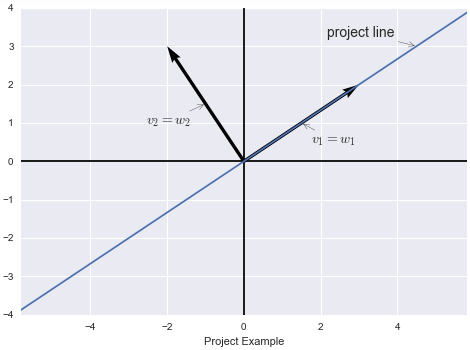
设输入向量的基为
v
1
,
v
2
v_1,v_2
v1,v2,
v
1
v_1
v1就在投影上,而
v
2
v_2
v2垂直于投影方向
输出向量的基为
w
1
,
w
2
w_1,w_2
w1,w2
而
v
1
=
w
1
,
v
2
=
w
2
v_1=w_1,v_2=w_2
v1=w1,v2=w2
那么如果输入向量为
v
=
c
1
v
1
+
c
2
v
2
v=c_1v_1+c_2v_2
v=c1v1+c2v2
则输出向量为
T
(
v
)
=
c
1
v
1
T(v)=c_1v_1
T(v)=c1v1
也就是线性变换去掉了法线方向的分量
输入坐标为
(
c
1
,
c
2
)
(c_1,c_2)
(c1,c2),输出坐标变为
(
c
1
,
0
)
(c_1,0)
(c1,0)。
找出这个矩阵并不困难, A v = w Av=w Av=w,则有 [ 1 0 0 0 ] [ c 1 c 2 ] = [ c 1 0 ] \begin{bmatrix}1&0\\0&0\end{bmatrix}\begin{bmatrix}c_1\\c_2\end{bmatrix}=\begin{bmatrix}c_1\\0\end{bmatrix} [1000][c1c2]=[c10]。
本例中我们选取的基极为特殊
一个沿投影方向,另一个沿投影法线方向
其实这两个向量都是投影矩阵的特征向量(
A
x
=
λ
x
Ax=\lambda x
Ax=λx,向量投影后和原向量同向,故只有投影方向和法线方向的向量可以)
所以我们得到的线性变换矩阵是一个对角矩阵,这是一组很好的基。
结论:如果以线性变换的特征向量作为基,则得到的矩阵将是一个包含特征值的对角矩阵。
选取标准基作为基
继续这个例子,我们不再选取特征向量作为基,而使用标准基
v
1
=
[
1
0
]
,
v
2
=
[
0
1
]
v_1=\begin{bmatrix}1\\0\end{bmatrix},v_2=\begin{bmatrix}0\\1\end{bmatrix}
v1=[10],v2=[01]
我们继续使用相同的基作为输出空间的基,即
v
1
=
w
1
,
v
2
=
w
2
v_1=w_1,v_2=w_2
v1=w1,v2=w2
此时投影矩阵为
P
=
a
a
T
a
T
a
=
[
1
2
1
2
1
2
1
2
]
P=\frac{aa^T}{a^Ta}=\begin{bmatrix}\frac{1}{2}&\frac{1}{2}\\\frac{1}{2}&\frac{1}{2}\end{bmatrix}
P=aTaaaT=[21212121]
这个矩阵明显没有上一个矩阵“好”,不过这个矩阵也是一个不错的对称矩阵。
总结通用的确定线性变换矩阵 A A A的方法:
- 确定输入空间的基 v 1 , v 2 , ⋯ , v n v_1,v_2,\cdots,v_n v1,v2,⋯,vn,确定输出空间的基 w 1 , w 2 , ⋯ , w m w_1,w_2,\cdots,w_m w1,w2,⋯,wm;
- 计算 T ( v 1 ) = a 11 w 1 + a 21 w 2 + ⋯ + a m 1 w m T(v_1)=a_{11}w_1+a_{21}w_2+\cdots+a_{m1}w_m T(v1)=a11w1+a21w2+⋯+am1wm,求出的系数 a i 1 a_{i1} ai1就是矩阵 A A A的第一列;
- 继续计算 T ( v 2 ) = a 12 w 1 + a 22 w 2 + ⋯ + a m 2 w m T(v_2)=a_{12}w_1+a_{22}w_2+\cdots+a_{m2}w_m T(v2)=a12w1+a22w2+⋯+am2wm,求出的系数 a i 2 a_{i2} ai2就是矩阵 A A A的第二列;
- 以此类推计算剩余向量直到 v n v_n vn;
- 最终得到矩阵 A = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ] A=\left[\begin{array}{c|c|c|c}a_{11}&a_{12}&\cdots&a_{1n}\\a_{21}&a_{22}&\cdots&a_{2n}\\\vdots&\vdots&\ddots&\vdots\\a_{m1}&a_{m2}&\cdots&a_{mn}\\\end{array}\right] A=⎣⎢⎢⎢⎡a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn⎦⎥⎥⎥⎤。
求导也是一种线性变换
最后我们介绍一种不一样的线性变换, T = d d x T=\frac{\mathrm{d}}{\mathrm{d}x} T=dxd:
-
设输入为 c 1 + c 2 x + c 3 x 2 c_1+c_2x+c_3x^2 c1+c2x+c3x2,基为 1 , x , x 2 1,x,x^2 1,x,x2;
-
则输出为导数: c 2 + 2 c 3 x c_2+2c_3x c2+2c3x,基为 1 , x 1,x 1,x;
所以我们需要求一个从三维输入空间到二维输出空间的线性变换,目的是求导
求导运算其实是线性变换
因此我们只要知道少量函数的求导法则(如 sin x , cos x , e x \sin x, \cos x, e^x sinx,cosx,ex),就能求出它们的线性组合的导数。有 A [ c 1 c 2 c 3 ] = [ c 2 2 c 3 ] A\begin{bmatrix}c_1\\c_2\\c_3\end{bmatrix}=\begin{bmatrix}c_2\\2c_3\end{bmatrix} A⎣⎡c1c2c3⎦⎤=[c22c3],从输入输出的空间维数可知, A A A是一个 2 × 3 2\times 3 2×3矩阵, A = [ 0 1 0 0 0 2 ] A=\begin{bmatrix}0&1&0\\0&0&2\end{bmatrix} A=[001002]。
最后,矩阵的逆相当于对应线性变换的逆运算
矩阵的乘积相当于线性变换的乘积
实际上矩阵乘法也源于线性变换
下节我们将继续讨论这个问题
第32讲:基变换和图像压缩
图像压缩
背景
本讲我们介绍一种图片有损压缩的一种方法:JPEG
假设我们有一张图片,长宽皆为
512
512
512个像素,我们用
x
i
x_i
xi来表示第
i
i
i个像素,如果是灰度照片,通常
x
i
x_i
xi可以在
[
0
,
255
]
[0,255]
[0,255]上取值,也就是8 bits
对于承载这张图片信息的向量
x
x
x来说,有
x
∈
R
n
,
n
=
51
2
2
x\in\mathbb{R}^n, n=512^2
x∈Rn,n=5122
而如果是彩色照片,通常需要三个量来表示一个像素,则向量长度也会变为现在的三倍。
如此大的数据不经过压缩很难广泛传播
教学录像采用的压缩方法就是JPEG(Joint Photographic Expert Group,联合图像专家组)
该方法采用的就是基变换的方式压缩图像
比如说一块干净的黑板,其附近的像素值应该非常接近,此时如果一个像素一个像素的描述黑白灰度值就太浪费空间了,所以标准基在这种情况下并不能很好的利用图片的特性
标准基和别的基
我们知道,标准基是
[
1
0
⋮
0
]
[
0
1
⋮
0
]
⋯
[
0
0
⋮
1
]
\begin{bmatrix}1\\0\\\vdots\\0\end{bmatrix}\begin{bmatrix}0\\1\\\vdots\\0\end{bmatrix}\cdots\begin{bmatrix}0\\0\\\vdots\\1\end{bmatrix}
⎣⎢⎢⎢⎡10⋮0⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡01⋮0⎦⎥⎥⎥⎤⋯⎣⎢⎢⎢⎡00⋮1⎦⎥⎥⎥⎤
但我们想寻找一个更好的基。
我们试试使用别的基描述图片,比如:
- 基中含有的一个向量 [ 1 1 ⋯ 1 ] T \begin{bmatrix}1&1&\cdots&1\end{bmatrix}^T [11⋯1]T,即分量全为 1 1 1的向量,一个向量就可以完整的给出所有“像素一致图像”的信息;
- 另一个向量 [ 1 − 1 ⋯ 1 − 1 ] T \begin{bmatrix}1&-1&\cdots&1&-1\end{bmatrix}^T [1−1⋯1−1]T,正负交替出现,比如描述国际象棋棋盘;
- 第三个个向量 [ 1 1 ⋯ − 1 − 1 ] T \begin{bmatrix}1&1&\cdots&-1&-1\end{bmatrix}^T [11⋯−1−1]T,一半正一半负,比如描述一半亮一半暗的图片;
傅里叶基
现在我们来介绍傅里叶基,以 8 × 8 8\times 8 8×8傅里叶基为例(这表示我们每次只处理 8 × 8 8\times 8 8×8像素的一小块图像):
F
n
=
[
1
1
1
⋯
1
1
w
w
2
⋯
w
n
−
1
1
w
2
w
4
⋯
w
2
(
n
−
1
)
⋮
⋮
⋮
⋱
⋮
1
w
n
−
1
w
2
(
n
−
1
)
⋯
w
(
n
−
1
)
2
]
,
w
=
e
i
2
π
/
n
,
n
=
8
F_n=\begin{bmatrix}1&1&1&\cdots&1\\1&w&w^2&\cdots&w^{n-1}\\1&w^2&w^4&\cdots&w^{2(n-1)}\\\vdots&\vdots&\vdots&\ddots&\vdots\\1&w^{n-1}&w^{2(n-1)}&\cdots&w^{(n-1)^2}\end{bmatrix},\ w=e^{i2\pi/n},\ n=8
Fn=⎣⎢⎢⎢⎢⎢⎡111⋮11ww2⋮wn−11w2w4⋮w2(n−1)⋯⋯⋯⋱⋯1wn−1w2(n−1)⋮w(n−1)2⎦⎥⎥⎥⎥⎥⎤, w=ei2π/n, n=8
我们不需要深入
8
8
8阶傅里叶基的细节,先看看使用傅里叶基的思路是怎样的。
每次处理 8 × 8 8\times 8 8×8的一小块时,会遇到 64 64 64个像素,也就是 64 64 64个基向量, 64 64 64个系数,在 64 64 64维空间中利用傅里叶向量做基变换:
-
改变基(无损)
输入信号 x x x为 64 64 64维标准基向量 → 基 变 换 \xrightarrow{基变换} 基变换输出信号 c c c为 x x x在傅里叶基下的 64 64 64个系数。(注意这里做的都是无损的步骤,我们只是重新选了 R 64 \mathbb{R}^{64} R64的一组基,接着把信号用这组基表达出来)
-
压缩(有损)
一种方法是扔掉较小的系数,这叫做阈值量化(thresholding)
我们设定一个阈值,任何不在阈值范围内的基向量、系数都将丢弃
虽然有信息损失,但是只要阈值设置合理,肉眼几乎无法区别压缩前后的图片
经由此步处理,向量 c c c变为 c ^ \hat c c^,而 c ^ \hat c c^将有很多 0 0 0。在平滑信号中
通常 [ 1 1 ⋯ 1 ] T \begin{bmatrix}1&1&\cdots&1\end{bmatrix}^T [11⋯1]T向量很难被丢弃,它通常具有较大的系数
但是 [ 1 − 1 ⋯ 1 − 1 ] T \begin{bmatrix}1&-1&\cdots&1&-1\end{bmatrix}^T [1−1⋯1−1]T向量的系数就比较小了
前一个向量称作低频信号,频率为 0 0 0
后一个向量称作高频信号,也是我们能够得到的最高频率的信号,如果信号是噪音或抖动,它的系数就比较大了。比如讲课的视频图像信号,这种平滑的情形下输出的大多是低频信号,很少出现噪音。
-
重构信号
用系数 c ^ \hat c c^乘以对应的基向量并求和得 x ^ = ∑ c ^ i v i \hat x=\sum \hat{c}_iv_i x^=∑c^ivi
但是这个求和不再是 64 64 64项求和了,因为压缩后的系数中有很多零存在
假如我们压缩后 c ^ \hat c c^中仅有三个非零项,那么压缩比将近达到 21 : 1 21:1 21:1。
我们再来提一下视频压缩:
视频是一系列连续图像,且相邻的帧其向量表示非常接近,而我们的压缩算法就需要利用这个相近性质(在实际生活中,从时间与空间的角度讲,事物不会瞬间改变)
小波基
接下来介绍另一组基,它是傅里叶基的竞争对手,名为小波(wavelets),以
R
8
\mathbb{R}^8
R8为例:
[
1
1
1
1
1
1
1
1
]
[
1
1
1
1
−
1
−
1
−
1
−
1
]
[
1
1
−
1
−
1
0
0
0
0
]
[
0
0
0
0
1
1
−
1
−
1
]
[
1
−
1
0
0
0
0
0
0
]
[
0
0
1
−
1
0
0
0
0
]
[
0
0
0
0
1
−
1
0
0
]
[
0
0
0
0
0
0
1
−
1
]
\begin{bmatrix}1\\1\\1\\1\\1\\1\\1\\1\end{bmatrix} \begin{bmatrix}1\\1\\1\\1\\-1\\-1\\-1\\-1\end{bmatrix} \begin{bmatrix}1\\1\\-1\\-1\\0\\0\\0\\0\end{bmatrix} \begin{bmatrix}0\\0\\0\\0\\1\\1\\-1\\-1\end{bmatrix} \begin{bmatrix}1\\-1\\0\\0\\0\\0\\0\\0\end{bmatrix} \begin{bmatrix}0\\0\\1\\-1\\0\\0\\0\\0\end{bmatrix} \begin{bmatrix}0\\0\\0\\0\\1\\-1\\0\\0\end{bmatrix} \begin{bmatrix}0\\0\\0\\0\\0\\0\\1\\-1\end{bmatrix}
⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡11111111⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡1111−1−1−1−1⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡11−1−10000⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡000011−1−1⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡1−1000000⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡001−10000⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡00001−100⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡0000001−1⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
可以看出傅里叶基中频率最高的向量为小波后四个基向量之和。
在标准基下的一组(按八个一组计算,
P
∈
R
8
P\in\mathbb{R}^8
P∈R8)
像素
P
=
[
p
1
p
2
⋮
p
8
]
=
c
1
w
1
+
c
2
w
2
+
⋯
+
c
n
w
n
=
[
w
1
w
2
⋯
w
n
]
[
c
1
c
2
⋮
c
n
]
P=\begin{bmatrix}p_1\\p_2\\\vdots\\p_8\end{bmatrix}=c_1w_1+c_2w_2+\cdots+c_nw_n=\Bigg[w_1\ w_2\ \cdots\ w_n\Bigg]\begin{bmatrix}c_1\\c_2\\\vdots\\c_n\end{bmatrix}
P=⎣⎢⎢⎢⎡p1p2⋮p8⎦⎥⎥⎥⎤=c1w1+c2w2+⋯+cnwn=[w1 w2 ⋯ wn]⎣⎢⎢⎢⎡c1c2⋮cn⎦⎥⎥⎥⎤
即
P
=
W
C
P=WC
P=WC
我们需要计算像素向量在另一组基下系数,所以有
C
=
W
−
1
P
C=W^{-1}P
C=W−1P。
此时我们发现,如果选取“好的基”会使得逆矩阵的求解过程变简单,所谓“好的基”:
-
计算快
我们需要大量使用 P = W C , C = W − 1 P P=WC,C=W^{-1}P P=WC,C=W−1P来计算整幅图在另一个基下的表达
在傅里叶变换中我们学习了快速傅里叶变换(FFT),同样的在小波变换中也有快速小波变换(FWT);另外的,我们需要计算其逆矩阵,所以这个逆矩阵计算也必须快
观察小波基不难发现基向量相互正交,假设我们已经对小波基做了标准化处理,则小波基是一组标准正交基,所以有 W − 1 = W T W^{-1}=W^T W−1=WT。 -
仅需少量向量即可最大限度的重现图像
仅仅是计算快是不够的,标准基计算最快,但我们丢弃一些系数时,会丢掉大量的像素值导致图像损坏过于严重
因为在图像压缩时,我们会舍弃较小的系数,比如 c 5 , c 6 , c 7 , c 8 c_5,c_6,c_7,c_8 c5,c6,c7,c8,所以后四个的基向量都会被舍弃,重现图像时仅使用前四个基向量的线性组合,而好的基选取会在使用较少基的前提下保证图像质量不会有较大损失。
题外话:JPEG2000标准会将小波基纳入压缩算法。我们上面介绍的是最简单的一组小波基,而FBI的指纹识别或JPEG2000的压缩算法纳入的是更加平滑的小波基,不会使用像上面介绍的那种直接从 1 1 1变为 − 1 -1 −1的基。
要想继续了解小波基,可以参考一篇非常精彩的文章能不能通俗的讲解下傅立叶分析和小波分析之间的关系?——“咚懂咚懂咚“的答案
基变换
定义
将目标基的基向量按列组成矩阵
W
W
W,则基变换就是
[
x
]
→
x
=
W
c
[
c
]
\Bigg[x\Bigg]\xrightarrow{x=Wc}\Bigg[c\Bigg]
[x]x=Wc[c]

基变换对线性变换的影响
看一个例子,有线性变换
T
:
R
8
→
R
8
T:\mathbb{R}^8\to\mathbb{R}^8
T:R8→R8
在第一组基
v
1
,
v
2
,
⋯
,
v
8
v_1,v_2,\cdots,v_8
v1,v2,⋯,v8上
T
T
T对应的线性变换矩阵为
A
A
A
在第二组基
w
1
,
w
2
,
⋯
,
w
8
w_1,w_2,\cdots,w_8
w1,w2,⋯,w8上
T
T
T对应的线性变换矩阵为
B
B
B
先说结论,矩阵
A
,
B
A,B
A,B是相似的,也就是有
B
=
M
−
1
A
M
B=M^{-1}AM
B=M−1AM,而
M
M
M就是基变换矩阵
基变换后会发生两件事:
-
每个向量都会有一组新的坐标,而 x = W c x=Wc x=Wc就是新旧坐标的关系;
-
每个线性变换都会有一个新的对应矩阵,而 B = M − 1 A M B=M^{-1}AM B=M−1AM就是新矩阵之间的联系。
再来回顾一下什么是 A A A矩阵:
对于第一组基 v 1 , v 2 , ⋯ , v 8 v_1,v_2,\cdots,v_8 v1,v2,⋯,v8,要完全了解线性变换 T T T,只需要知道 T T T作用在基的每一个向量上会产生什么结果即可
因为在这个基下的每一个向量都可以写成 x = c 1 v 1 + c 2 v 2 + ⋯ + c 8 v 8 x=c_1v_1+c_2v_2+\cdots+c_8v_8 x=c1v1+c2v2+⋯+c8v8的形式,所以 T ( x ) = c 1 T ( v 1 ) + c 2 T ( v 2 ) + ⋯ + c 8 T ( v 8 ) T(x)=c_1T(v_1)+c_2T(v_2)+\cdots+c_8T(v_8) T(x)=c1T(v1)+c2T(v2)+⋯+c8T(v8)。而且 T ( v 1 ) = a 11 v 1 + a 21 v 2 + ⋯ + a 81 v 8 , T ( v 2 ) = a 12 v 1 + a 22 v 2 + ⋯ + a 82 v 8 , ⋯ T(v_1)=a_{11}v_1+a_{21}v_2+\cdots+a_{81}v_8,\ T(v_2)=a_{12}v_1+a_{22}v_2+\cdots+a_{82}v_8,\ \cdots T(v1)=a11v1+a21v2+⋯+a81v8, T(v2)=a12v1+a22v2+⋯+a82v8, ⋯
则矩阵 [ A ] = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ] \begin{bmatrix}A\end{bmatrix}=\left[\begin{array}{c|c|c|c}a_{11}&a_{12}&\cdots&a_{1n}\\a_{21}&a_{22}&\cdots&a_{2n}\\\vdots&\vdots&\ddots&\vdots\\a_{m1}&a_{m2}&\cdots&a_{mn}\\\end{array}\right] [A]=⎣⎢⎢⎢⎡a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn⎦⎥⎥⎥⎤这些都是上一讲结尾所涉及的知识。
例子
最后我们以一个最好的基收场
设
v
1
,
v
2
,
⋯
,
v
n
v_1,v_2,\cdots,v_n
v1,v2,⋯,vn是一组特征向量,也就是
T
(
v
i
)
=
λ
1
v
i
T(v_i)=\lambda_1v_i
T(vi)=λ1vi(
T
(
v
i
)
T(v_i)
T(vi)和
v
i
v_i
vi同向)
那么矩阵
A
A
A是什么?
继续使用线性变换中学到的
输入的第一个向量
v
1
v_1
v1经由
T
T
T加工后得到
λ
1
v
1
\lambda_1v_1
λ1v1
第二个向量
v
2
→
T
λ
2
v
2
v_2\xrightarrow{T}\lambda_2v_2
v2Tλ2v2
继续做下去,最终有
v
n
=
v
n
→
T
λ
n
v
n
v_n=v_n\xrightarrow{T}\lambda_nv_n
vn=vnTλnvn
对
v
i
v_i
vi来说,变换后,除了
λ
i
v
i
\lambda_iv_i
λivi外的其他基向量都变为
0
0
0,因此
矩阵
A
=
[
λ
1
λ
2
⋱
λ
n
]
A=\begin{bmatrix}\lambda_1&&&\\&\lambda_2&&\\&&\ddots&\\&&&\lambda_n\end{bmatrix}
A=⎣⎢⎢⎡λ1λ2⋱λn⎦⎥⎥⎤
这是一个非常完美的基,我们在图像处理中最想要的就是这种基
但是找出像素矩阵的特征向量代价太大
所以我们找了一些代价小同时效果也不错的基,比如小波基、傅里叶基等等。
第33讲:复习三
在上一次复习中,我们已经涉及了求特征值与特征向量(通过解方程 det ( A − λ I ) = 0 \det(A-\lambda I)=0 det(A−λI)=0得出 λ \lambda λ,再将 λ \lambda λ带入 A − λ I A-\lambda I A−λI求其零空间得到 x x x)
我们学了什么
- 解微分方程 d u d t = A u \frac{\mathrm{d}u}{\mathrm{d}t}=Au dtdu=Au,并介绍了指数矩阵 e A t e^{At} eAt;
- 介绍了对称矩阵的性质
A
=
A
T
A=A^T
A=AT
了解了其特征值均为实数且总是存在足量的特征向量(即使特征值重复特征向量也不会短缺,总是可以对角化)
同时对称矩阵的特征向量正交,所以对称矩阵对角化的结果可以表示为 A = Q Λ Q T A=Q\Lambda Q^T A=QΛQT - 接着我们学习了正定矩阵;
- 然后学习了相似矩阵,
B
=
M
−
1
A
M
B=M^{-1}AM
B=M−1AM,矩阵
A
,
B
A,B
A,B特征值相同
其实相似矩阵是用不同的基表示相同的东西
B k = M − 1 A k M B^k=M^{-1}A^kM Bk=M−1AkM - 最后我们学习了奇异值分解 A = U Σ V T A=U\varSigma V^T A=UΣVT。
习题
-
解方程 d u d t = A u = [ 0 − 1 0 1 0 − 1 0 1 0 ] u \frac{\mathrm{d}u}{\mathrm{d}t}=Au=\begin{bmatrix}0&-1&0\\1&0&-1\\0&1&0\end{bmatrix}u dtdu=Au=⎣⎡010−1010−10⎦⎤u(这里未给出 u 0 u_0 u0,就不完全解出来了)
①解的形式
首先通过 A A A的特征值/向量求通解 u ( t ) = c 1 e λ 1 t x 1 + c 2 e λ 2 t x 2 + c 3 e λ 3 t x 3 u(t)=c_1e^{\lambda_1t}x_1+c_2e^{\lambda_2t}x_2+c_3e^{\lambda_3t}x_3 u(t)=c1eλ1tx1+c2eλ2tx2+c3eλ3tx3,很明显矩阵是奇异的,所以有 λ 1 = 0 \lambda_1=0 λ1=0;②解特征值
继续观察矩阵会发现 A T = − A A^T=-A AT=−A,这是一个反对称矩阵(anti-symmetric)或斜对陈矩阵(skew-symmetric)
这与我们在第21讲介绍过的旋转矩阵类似,它的特征值应该为纯虚数(特征值在虚轴上),所以我们猜测其特征值应为 0 ⋅ i , b ⋅ i , − b ⋅ i 0\cdot i,\ b\cdot i,\ -b\cdot i 0⋅i, b⋅i, −b⋅i
通过解 det ( A − λ I ) = 0 \det(A-\lambda I)=0 det(A−λI)=0验证一下:
[ − λ − 1 0 1 − λ − 1 0 1 λ ] = λ 3 + 2 λ = 0 , 解 得 λ 1 = 0 , λ 2 = 2 i , λ 3 = − 2 i \begin{bmatrix}-\lambda&-1&0\\1&-\lambda&-1\\0&1&\lambda\end{bmatrix}=\lambda^3+2\lambda=0, 解得\lambda_1=0,\lambda_2=\sqrt 2i, \lambda_3=-\sqrt 2i ⎣⎡−λ10−1−λ10−1λ⎦⎤=λ3+2λ=0,解得λ1=0,λ2=2i,λ3=−2i。③状态
此时 u ( t ) = c 1 + c 2 e 2 i t x 2 + c 3 e − 2 i t x 3 u(t)=c_1+c_2e^{\sqrt 2it}x_2+c_3e^{-\sqrt 2it}x_3 u(t)=c1+c2e2itx2+c3e−2itx3
e 2 i t e^{\sqrt 2it} e2it始终在复平面单位圆上,所以 u ( t ) u(t) u(t)及不发散也不收敛,但它具有周期性
u ( 0 ) = c 1 + c 2 + c 3 u(0)=c_1+c_2+c_3 u(0)=c1+c2+c3,如果使 e 2 i T = 1 e^{\sqrt 2iT}=1 e2iT=1,即 2 i T = 2 π i \sqrt 2iT=2\pi i 2iT=2πi则也能得到 u ( T ) = c 1 + c 2 + c 3 u(T)=c_1+c_2+c_3 u(T)=c1+c2+c3,周期 T = π 2 T=\pi\sqrt 2 T=π2④使用指数矩阵来解方程 u ( t ) = e A t u ( 0 ) u(t)=e^{At}u(0) u(t)=eAtu(0)
如果矩阵可以对角化(在本例中显然可以)
则 A = S Λ S − 1 , e A t = S e Λ t S − 1 = S [ e λ 1 t e λ 1 t ⋱ e λ 1 t ] S − 1 A=S\Lambda S^{-1}, e^{At}=Se^{\Lambda t}S^{-1}=S\begin{bmatrix}e^{\lambda_1t}&&&\\&e^{\lambda_1t}&&\\&&\ddots&\\&&&e^{\lambda_1t}\end{bmatrix}S^{-1} A=SΛS−1,eAt=SeΛtS−1=S⎣⎢⎢⎡eλ1teλ1t⋱eλ1t⎦⎥⎥⎤S−1
这个公式在能够快速计算 S , λ S,\lambda S,λ时很方便求解。另外,反对称矩阵同对称矩阵一样,具有正交的特征向量
让我们想想当矩阵满足什么条件时,其特征向量相互正交?
答案是必须满足 A A T = A T A AA^T=A^TA AAT=ATA
对称矩阵 A = A T A=A^T A=AT满足此条件,同时反对称矩阵 A = − A T A=-A^T A=−AT也满足此条件,而正交矩阵 Q − 1 = Q T Q^{-1}=Q^T Q−1=QT同样满足此条件,这三种矩阵的特征向量都是相互正交的 -
已知矩阵的特征值 λ 1 = 0 , λ 2 = c , λ 3 = 2 \lambda_1=0,\lambda_2=c,\lambda_3=2 λ1=0,λ2=c,λ3=2,特征向量 x 1 = [ 1 1 1 ] , x 2 = [ 1 − 1 0 ] , x 3 = [ 1 1 − 2 ] x_1=\begin{bmatrix}1\\1\\1\end{bmatrix},x_2=\begin{bmatrix}1\\-1\\0\end{bmatrix},x_3=\begin{bmatrix}1\\1\\-2\end{bmatrix} x1=⎣⎡111⎦⎤,x2=⎣⎡1−10⎦⎤,x3=⎣⎡11−2⎦⎤:
(1) c c c如何取值才能保证矩阵可以对角化?
其实可对角化只需要有足够的线性无关的特征向量即可,而现在特征向量已经足够
所以 c c c可以取任意值。(2) c c c如何取值才能保证矩阵对称?
我们知道
对称矩阵的特征值均为实数
且这里给出的特征向量是正交的
有了实特征值及正交特征向量,我们就可以得到对称矩阵
所以 c c c取实数即可(3) c c c如何取值才能使得矩阵正定?
已经有一个零特征值了,所以矩阵不可能是正定的
但如果 c c c取非负实数,可以是半正定的,(4) c c c如何取值才能使得矩阵是一个马尔科夫矩阵?
在第二十四讲我们知道马尔科夫矩阵的性质:
必有一特征值等于 1 1 1,其余特征值均小于 1 1 1
所以 A A A不可能是马尔科夫矩阵。(5) c c c取何值才能使得 P = A 2 P=\frac{A}{2} P=2A是一个投影矩阵?
我们知道投影矩阵的一个重要性质是 P 2 = P P^2=P P2=P
所以有对其特征值有 λ 2 = λ \lambda^2=\lambda λ2=λ,即 λ = 0 , 1 \lambda=0,1 λ=0,1
所以 c = 0 , 2 c=0,2 c=0,2题设中的特征向量正交意义重大
如果没有正交这个条件,则矩阵 A A A不会是对称、正定、投影矩阵
因为特征向量的正交性我们才能直接去看特征值的性质 -
复习奇异值分解, A = U Σ V T A=U\varSigma V^T A=UΣVT:
先求正交矩阵 V V V: A T A = V Σ T U T U Σ V T = V ( Σ T Σ ) V T A^TA=V\varSigma^TU^TU\varSigma V^T=V\left(\varSigma^T\varSigma\right)V^T ATA=VΣTUTUΣVT=V(ΣTΣ)VT
所以 V V V是矩阵 A T A A^TA ATA的特征向量矩阵,而矩阵 Σ T Σ \varSigma^T\varSigma ΣTΣ是矩阵 A T A A^TA ATA的特征值矩阵,即 A T A A^TA ATA的特征值为 σ 2 \sigma^2 σ2(奇异值就是这些 σ 2 \sigma^2 σ2)接下来应该求正交矩阵 U U U: A A T = U Σ T V T V Σ U T = U ( Σ T Σ ) U T AA^T=U\varSigma^TV^TV\varSigma U^T=U\left(\varSigma^T\varSigma\right)U^T AAT=UΣTVTVΣUT=U(ΣTΣ)UT (可以发现 A A A对称时 U = V U=V U=V)
但是请注意,我们在这个式子中无法确定特征向量的符号
我们需要使用 A v i = σ i u i Av_i=\sigma_iu_i Avi=σiui,通过已经求出的 v i v_i vi来确定 u i u_i ui的符号( A V = U Σ AV=U\varSigma AV=UΣ),进而求出 U U U已知 A = [ u 1 u 2 ] [ 3 0 0 2 ] [ v 1 v 2 ] T A=\bigg[u_1\ u_2\bigg]\begin{bmatrix}3&0\\0&2\end{bmatrix}\bigg[v_1\ v_2\bigg]^T A=[u1 u2][3002][v1 v2]T
从已知的 Σ \varSigma Σ矩阵可以看出, A A A矩阵是非奇异矩阵,因为它没有零奇异值
如果把 Σ \varSigma Σ矩阵中的 2 2 2改成 − 5 -5 −5,则题目就不再是奇异值分解了,因为奇异值不可能为负
如果将 2 2 2变为 0 0 0,则 A A A是奇异矩阵,它的秩为 1 1 1,零空间为 1 1 1维, v 2 v_2 v2在其零空间中(可验算得 [ u 1 u 2 ] [ 3 0 0 2 ] [ v 1 v 2 ] T v 2 = 0 \bigg[u_1\ u_2\bigg]\begin{bmatrix}3&0\\0&2\end{bmatrix}\bigg[v_1\ v_2\bigg]^Tv_2=0 [u1 u2][3002][v1 v2]Tv2=0)
SVD虽然消耗不少时间,但它展示了矩阵具备的一切优良特性 -
A A A是正交对称矩阵
(1)它的特征值具有什么特点
首先,对于对称矩阵,有特征值均为实数
然后是正交矩阵,直觉告诉我们
∣
λ
∣
=
1
|\lambda|=1
∣λ∣=1
来证明一下,对于
Q
x
=
λ
x
Qx=\lambda x
Qx=λx,我们两边同时取模有
∥
Q
x
∥
=
∣
λ
∣
∥
x
∥
\|Qx\|=|\lambda|\|x\|
∥Qx∥=∣λ∣∥x∥,而正交矩阵不会改变向量长度,所以有
∥
x
∥
=
∣
λ
∣
∥
x
∥
\|x\|=|\lambda|\|x\|
∥x∥=∣λ∣∥x∥,因此
λ
=
±
1
\lambda=\pm1
λ=±1

(2)
A
A
A是正定的吗?
并不一定,因为特征向量可以取
−
1
-1
−1。
(3)
A
A
A的特征值没有重复吗?
不是,因为特征值只能取
±
1
\pm1
±1,如果矩阵大于
2
2
2阶则必定有重复特征值。
(4)
A
A
A可以被对角化吗?
是的,任何对称矩阵(
Λ
=
I
−
1
Λ
I
\Lambda = I^{-1} \Lambda I
Λ=I−1ΛI)、任何正交矩阵(
A
=
Q
−
1
Λ
Q
A = Q^{-1} \Lambda Q
A=Q−1ΛQ)都可以被对角化。
(5)
A
A
A是非奇异矩阵吗?
是的,正交矩阵都是非奇异矩阵。
因为它的特征值只能取
1
,
−
1
1,-1
1,−1,不能
0
0
0
(6)证明 P = 1 2 ( A + I ) P=\frac{1}{2}(A+I) P=21(A+I)是投影矩阵
法一:使用投影矩阵的性质证明
①首先由于
A
A
A是对称矩阵,则
P
P
P一定是对称矩阵
②接下来需要验证
P
2
=
P
P^2=P
P2=P
1
4
(
A
2
+
2
A
+
I
)
=
1
2
(
A
+
I
)
\frac{1}{4}\left(A^2+2A+I\right)=\frac{1}{2}(A+I)
41(A2+2A+I)=21(A+I)
A
A
A是正交矩阵则
A
T
=
A
−
1
A^T=A^{-1}
AT=A−1,而
A
A
A又是对称矩阵则
A
=
A
T
=
A
−
1
A=A^T=A^{-1}
A=AT=A−1,所以
A
2
=
I
A^2=I
A2=I
带入原式有
1
4
(
2
A
+
2
I
)
=
1
2
(
A
+
I
)
\frac{1}{4}(2A+2I)=\frac{1}{2}(A+I)
41(2A+2I)=21(A+I),得证
法二:使用特征值验证
A
A
A的特征值可以取
±
1
\pm1
±1,则
A
+
I
A+I
A+I的特征值可以取
0
,
2
0,2
0,2,所以
1
2
(
A
+
I
)
\frac{1}{2}(A+I)
21(A+I)的特征值为
0
,
1
0,1
0,1
特征值满足投影矩阵且它又是对称矩阵,得证。
第34讲:左右逆和伪逆
前面我们涉及到的逆(inverse)都是指左、右乘均成立的逆矩阵,即
A
−
1
A
=
I
=
A
A
−
1
A^{-1}A=I=AA^{-1}
A−1A=I=AA−1。在这种情况下
m
×
n
m\times n
m×n矩阵
A
A
A满足
m
=
n
=
r
a
n
k
(
A
)
m=n=rank(A)
m=n=rank(A),也就是满秩方阵。
左逆(left inserve)
r , m , n r,m,n r,m,n关系
记得我们在最小二乘一讲(第16讲)介绍过列满秩的情况,也就是列向量线性无关,但行向量通常不是线性无关的。常见的列满秩矩阵 A A A满足 m > n = r a n k ( A ) m>n=rank(A) m>n=rank(A)。
A x = b Ax=b Ax=b的解的情形
列满秩时,列向量线性无关,所以其零空间中只有零解
方程
A
x
=
b
Ax=b
Ax=b
1.可能有一个唯一解(
b
b
b在
A
A
A的列空间中,此特解就是全部解,因为通常的特解可以通过零空间中的向量扩展出一组解集,而此时零空间只有列向量)
2.也可能无解(
b
b
b不在
A
A
A的列空间中)(行向量可以不是线性无关的,因此右端项在消元后有时不会出现
0
=
0
0=0
0=0)
另外,此时行空间属于 R n \mathbb{R}^n Rn,也正印证了与行空间互为正交补的零空间中只有零向量
A l e f t − 1 A^{-1}_{left} Aleft−1
现在来观察
A
T
A
A^TA
ATA
也就是在
m
>
n
=
r
a
n
k
(
A
)
m>n=rank(A)
m>n=rank(A)的情况下,
n
×
m
n\times m
n×m矩阵乘以
m
×
n
m\times n
m×n矩阵,结果为一个满秩的
n
×
n
n\times n
n×n矩阵,所以
A
T
A
A^TA
ATA是一个可逆矩阵
也就是说
(
A
T
A
)
−
1
A
T
⏟
A
=
I
\underbrace{\left(A^TA\right)^{-1}A^T}A=I
(ATA)−1ATA=I成立
而大括号部分的
(
A
T
A
)
−
1
A
T
\left(A^TA\right)^{-1}A^T
(ATA)−1AT称为长方形矩阵
A
A
A的左逆
A l e f t − 1 = ( A T A ) − 1 A T A^{-1}_{left}=\left(A^TA\right)^{-1}A^T Aleft−1=(ATA)−1AT
顺便复习一下最小二乘一讲
通过关键方程
A
T
A
x
^
=
A
T
b
A^TA\hat x=A^Tb
ATAx^=ATb,
A
l
e
f
t
−
1
A^{-1}_{left}
Aleft−1被当做一个系数矩阵乘在
b
b
b向量上
求得
b
b
b向量投影在
A
A
A的列空间之后的解
x
^
=
(
A
T
A
)
−
1
A
T
b
\hat x=\left(A^TA\right)^{-1}A^Tb
x^=(ATA)−1ATb
如果我们强行给矩阵
A
A
A右乘一个左逆,得到的矩阵就是投影矩阵
P
=
A
(
A
T
A
)
−
1
A
T
P=A\left(A^TA\right)^{-1}A^T
P=A(ATA)−1AT (来自
p
=
A
x
^
=
A
(
A
T
A
)
−
1
A
T
p=A\hat x=A\left(A^TA\right)^{-1}A^T
p=Ax^=A(ATA)−1AT,它将右乘的向量
b
b
b投影在矩阵
A
A
A的列空间中)
再来观察 A A T AA^T AAT矩阵,这是一个 m × m m\times m m×m矩阵,秩为 r a n k ( A A T ) = n < m rank(AA^T)=n<m rank(AAT)=n<m,也就是说 A A T AA^T AAT是不可逆的,那么接下来我们看看右逆。
右逆(right inverse)
r , m , n r,m,n r,m,n关系
可以与左逆对称的看,右逆也就是研究
m
×
n
m\times n
m×n矩阵
A
A
A行满秩的情况,此时
n
>
m
=
r
a
n
k
(
A
)
n>m=rank(A)
n>m=rank(A)
对称的,其左零空间中仅有零向量,即没有行向量的线性组合能够得到零向量。
A x = b Ax=b Ax=b的解的情形
行满秩时,矩阵的列空间将充满向量空间 C ( A ) = R m C(A)=\mathbb{R}^m C(A)=Rm( m = r m=r m=r),所以方程 A x = b Ax=b Ax=b总是有解集,由于消元后有 n − m n-m n−m个自由变量,所以方程的零空间为 n − m n-m n−m维。
A r i g h t − 1 A^{-1}_{right} Aright−1
与左逆对称,再来观察
A
A
T
AA^T
AAT
在
n
>
m
=
r
a
n
k
(
A
)
n>m=rank(A)
n>m=rank(A)的情况下,
m
×
n
m\times n
m×n矩阵乘以
n
×
m
n\times m
n×m矩阵,结果为一个满秩的
m
×
m
m\times m
m×m矩阵
所以此时
A
A
T
AA^T
AAT是一个满秩矩阵,也就是
A
A
T
AA^T
AAT可逆
所以
A
A
T
(
A
A
T
)
⏟
=
I
A\underbrace{A^T\left(AA^T\right)}=I
A
AT(AAT)=I,大括号部分的
A
T
(
A
A
T
)
A^T\left(AA^T\right)
AT(AAT)称为长方形矩阵的右逆
A r i g h t − 1 = A T ( A A T ) A^{-1}_{right}=A^T\left(AA^T\right) Aright−1=AT(AAT)
同样的,如果我们强行给右逆右乘矩阵
A
A
A,将得到另一个投影矩阵
P
=
A
T
(
A
A
T
)
A
P=A^T\left(AA^T\right)A
P=AT(AAT)A
与上一个投影矩阵不同的是,这个矩阵的
A
A
A和
A
T
A^T
AT互换了
所以这是一个能够将右乘的向量
b
b
b投影在
A
A
A的行空间中。
伪逆(pseudo inverse)
r , m , n r,m,n r,m,n关系
前面我们提及了逆(方阵满秩),并讨论了左逆(矩阵列满秩)、右逆(矩阵行满秩),现在看一下第四种情况, m × n m\times n m×n矩阵 A A A不满秩的情况
有 m × n m\times n m×n矩阵 A A A,满足 r a n k ( A ) < m i n ( m , n ) rank(A)\lt min(m,\ n) rank(A)<min(m, n),则
- 列空间 C ( A ) ∈ R m , dim C ( A ) = r C(A)\in\mathbb{R}^m,\ \dim C(A)=r C(A)∈Rm, dimC(A)=r,左零空间 N ( A T ) ∈ R m , dim N ( A T ) = m − r N\left(A^T\right)\in\mathbb{R}^m,\ \dim N\left(A^T\right)=m-r N(AT)∈Rm, dimN(AT)=m−r,列空间与左零空间互为正交补;
- 行空间 C ( A T ) ∈ R n , dim C ( A T ) = r C\left(A^T\right)\in\mathbb{R}^n,\ \dim C\left(A^T\right)=r C(AT)∈Rn, dimC(AT)=r,零空间 N ( A ) ∈ R n , dim N ( A ) = n − r N(A)\in\mathbb{R}^n,\ \dim N(A)=n-r N(A)∈Rn, dimN(A)=n−r,行空间与零空间互为正交补。
在基本子空间中的意义
现在任取一个向量
x
x
x,乘上
A
A
A后结果
A
x
Ax
Ax一定落在矩阵
A
A
A的列空间
C
(
A
)
C(A)
C(A)中
而
x
x
x维度为
r
r
r,
A
x
Ax
Ax维度也为
r
r
r
那么我们现在猜测,输入向量
x
x
x全部来自矩阵的行空间,而输出向量
A
x
Ax
Ax全部来自矩阵的列空间,并且是一一对应的关系
也就是
R
n
\mathbb{R}^n
Rn的
r
r
r维子空间到
R
m
\mathbb{R}^m
Rm的
r
r
r维子空间的映射。
而矩阵
A
A
A现在有这些零空间存在,其作用是将某些向量变为零向量,这样
R
n
\mathbb{R}^n
Rn空间的所有向量都包含在行空间与零空间中,所有向量都能由行空间的分量和零空间的分量构成
但如果我们只看行空间中的向量,那就全部变换到列空间中了。
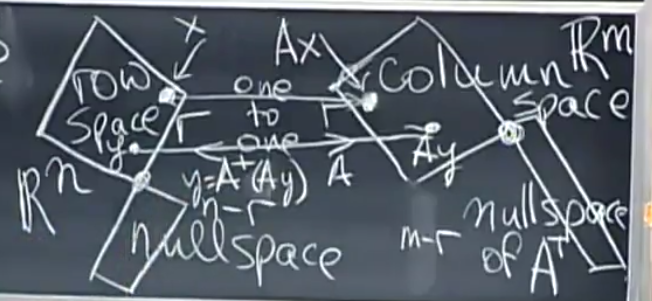
那么,我们现在只看行空间与列空间,在行空间中任取两个向量
x
,
y
∈
C
(
A
T
)
x,\ y\in C(A^T)
x, y∈C(AT),有
A
x
≠
A
y
Ax\neq Ay
Ax=Ay
所以从行空间到列空间,变换
A
A
A是个不错的映射
如果限制在这两个空间上,
A
A
A可以说“是个可逆矩阵”,那么它的逆就称作伪逆,而伪逆的作用就是将列空间的向量一一映射回行空间中
通常,伪逆记作
A
+
A^+
A+,因此
A
x
=
(
A
x
)
,
y
=
A
+
(
A
y
)
Ax=(Ax),\ y=A^+(Ay)
Ax=(Ax), y=A+(Ay)。
现在我们来证明对于
x
,
y
∈
C
(
A
T
)
,
x
≠
y
x,y\in C\left(A^T\right),\ x\neq y
x,y∈C(AT), x=y,有
A
x
,
A
y
∈
C
(
A
)
Ax,Ay\in C(A)
Ax,Ay∈C(A),则
A
x
≠
A
y
Ax\neq Ay
Ax=Ay
反证法:
- 假设 A x = A y Ax=Ay Ax=Ay,则有 A ( x − y ) = 0 A(x-y)=0 A(x−y)=0,即向量 x − y ∈ N ( A ) x-y\in N(A) x−y∈N(A);
- 另一方面,向量 x , y ∈ C ( A T ) x,y\in C\left(A^T\right) x,y∈C(AT),所以两者之差 x − y x-y x−y向量也在 C ( A T ) C\left(A^T\right) C(AT)中,即 x − y ∈ C ( A T ) x-y\in C\left(A^T\right) x−y∈C(AT);
- 此时满足这两个结论要求的仅有一个向量,即零向量,同时属于这两个正交的向量空间,从而得到 x = y x=y x=y,与题设中的条件矛盾,得证。
应用
背景
伪逆在统计学中非常有用,以前我们做最小二乘需要矩阵列满秩这一条件,只有矩阵列满秩才能保证 A T A A^TA ATA是可逆矩阵,而统计中经常出现重复测试,会导致列向量线性相关,在这种情况下 A T A A^TA ATA就成了奇异矩阵,这时候就需要伪逆。
计算伪逆 A + A^+ A+
其中一种方法是使用奇异值分解
-
A = U Σ V T A=U\varSigma V^T A=UΣVT,其中的对角矩阵型为 Σ = [ σ 1 ⋱ σ 2 [ 0 ] ] \varSigma=\left[\begin{array}{c c c|c}\sigma_1&&&\\&\ddots&&\\&&\sigma_2&\\\hline&&&\begin{bmatrix}0\end{bmatrix}\end{array}\right] Σ=⎣⎢⎢⎡σ1⋱σ2[0]⎦⎥⎥⎤,对角线非零的部分来自 A T A , A A T A^TA,\ AA^T ATA, AAT比较好的部分,剩下的来自左/零空间。
-
我们先来看一下 Σ \varSigma Σ矩阵的伪逆是多少
这是一个 m × n m\times n m×n矩阵, r a n k ( Σ ) = r rank(\varSigma)=r rank(Σ)=r, Σ + = [ 1 σ 1 ⋱ 1 σ r [ 0 ] ] \varSigma^+=\left[\begin{array}{c c c|c}\frac{1}{\sigma_1}&&&\\&\ddots&&\\&&\frac{1}{\sigma_r}&\\\hline&&&\begin{bmatrix}0\end{bmatrix}\end{array}\right] Σ+=⎣⎢⎢⎡σ11⋱σr1[0]⎦⎥⎥⎤
左乘伪逆和右乘伪逆有个小区别:
Σ \varSigma Σ是一个 n × m n\times m n×m矩阵
则有 Σ Σ + = [ 1 ⋱ 1 [ 0 ] ] m × m \varSigma\varSigma^+=\left[\begin{array}{c c c|c}1&&&\\&\ddots&&\\&&1&\\\hline&&&\begin{bmatrix}0\end{bmatrix}\end{array}\right]_{m\times m} ΣΣ+=⎣⎢⎢⎡1⋱1[0]⎦⎥⎥⎤m×m
Σ + Σ = [ 1 ⋱ 1 [ 0 ] ] n × n \varSigma^+\varSigma=\left[\begin{array}{c c c|c}1&&&\\&\ddots&&\\&&1&\\\hline&&&\begin{bmatrix}0\end{bmatrix}\end{array}\right]_{n\times n} Σ+Σ=⎣⎢⎢⎡1⋱1[0]⎦⎥⎥⎤n×n -
观察 Σ Σ + \varSigma\varSigma^+ ΣΣ+和 Σ + Σ \varSigma^+\varSigma Σ+Σ不难发现
Σ Σ + \varSigma\varSigma^+ ΣΣ+是将向量投影到列空间上的投影矩阵
而 Σ + Σ \varSigma^+\varSigma Σ+Σ是将向量投影到行空间上的投影矩阵
我们不论是左乘还是右乘伪逆,得到的不是单位矩阵,而是投影矩阵
该投影将向量带入比较好的空间(行空间和列空间,而不是左/零空间) -
接下来我们来求 A A A的伪逆:
U − 1 = U T U^{-1}=U^T U−1=UT, ( V T ) − 1 = V (V^T)^{-1}=V (VT)−1=V,所以:
A + = V Σ + U T A^+=V\varSigma^+U^T A+=VΣ+UT
( U , V U,V U,V求逆就是取转置,对角矩阵 Σ \varSigma Σ求逆就是求倒数,可见奇异值分解的魅力
第35讲:期末复习
依然是从以往的试题入手复习知识点。
-
已知 m × n m\times n m×n矩阵 A A A,有 A x = [ 1 0 0 ] Ax=\begin{bmatrix}1\\0\\0\end{bmatrix} Ax=⎣⎡100⎦⎤无解; A x = [ 0 1 0 ] Ax=\begin{bmatrix}0\\1\\0\end{bmatrix} Ax=⎣⎡010⎦⎤仅有唯一解
(1) 求关于 m , n , r a n k ( A ) m,n,rank(A) m,n,rank(A)的信息首先,最容易判断的是 m = 3 m=3 m=3
根据第一个条件可知,矩阵不满秩,有 r < m r<m r<m
根据第二个条件可知,零空间仅有零向量,也就是矩阵消元后没有自由变量,列向量线性无关,所以有 r = n r=n r=n。综上,有 m = 3 > n = r m=3>n=r m=3>n=r。
(2)写出一个矩阵 A A A的例子
A = [ 0 0 1 0 0 1 ] A=\begin{bmatrix}0&0\\1&0\\0&1\end{bmatrix} A=⎣⎡010001⎦⎤
(3)判断题(填T或F)
① det A T A = det A A T \det A^TA=\det AA^T detATA=detAAT
(F)
因为 A T A A^TA ATA可逆而 A A T AA^T AAT不可逆,可逆时行列式为 0 0 0,不可逆不为 0 0 0,所以行列式不可能相等(但是对于方阵,由于 det A B = det A det B = det B A \det AB=\det A\det B=\det BA detAB=detAdetB=detBA,所以成立)② A T A A^TA ATA可逆
(T)
因为 r = n r=n r=n, A T A A^TA ATA是 n × n n \times n n×n矩阵,且秩也为 r r r③ A A T AA^T AAT正定
(F)
因为 A A T AA^T AAT是一个 3 3 3阶方阵,而 A A T AA^T AAT秩为 2 2 2,有一特征值为 0 0 0,所以不是正定矩阵。不过 A A T AA^T AAT一定是半正定矩阵
证明:
要证明对称矩阵 A A A半正定, x T A x ≥ 0 x^TAx≥0 xTAx≥0即可
x T ( A A T ) x = ( A T x ) T ( A T x ) x^T(AA^T)x = (A^Tx)^T(A^Tx) xT(AAT)x=(ATx)T(ATx)
这是 A T x A^Tx ATx的内积, 恒有 A T x ≥ 0 A^Tx≥0 ATx≥0
所以 A A T AA^T AAT 半正定(4)求证 A T y = c A^Ty=c ATy=c有无数个解
因为 A A A的列向量线性无关,所以 A T A^T AT的行向量线性无关,所以至少有一个解
dim N ( A T ) = m − r > 0 \dim N\left(A^T\right)=m-r>0 dimN(AT)=m−r>0,零空间不止有零向量,所以有无数个解 -
设 A = [ v 1 v 2 v 3 ] A=\Bigg[v_1\ v_2\ v_3\Bigg] A=[v1 v2 v3]
(1) A x = v 1 − v 2 + v 3 Ax=v_1-v_2+v_3 Ax=v1−v2+v3,求 x x x。按列计算矩阵相乘,有 x = [ 1 − 1 1 ] x=\begin{bmatrix}1\\-1\\1\end{bmatrix} x=⎣⎡1−11⎦⎤。
(2)若 A x = v 1 − v 2 + v 3 = 0 Ax=v_1-v_2+v_3=0 Ax=v1−v2+v3=0,则解是唯一的吗?为什么?
如果解是唯一的,则零空间中只有零向量
而在此例中 x = [ 1 − 1 1 ] x=\begin{bmatrix}1\\-1\\1\end{bmatrix} x=⎣⎡1−11⎦⎤就在零空间中,所以解不唯一(3)若 v 1 , v 2 , v 3 v_1,v_2,v_3 v1,v2,v3是标准正交向量,那么怎样的线性组合 c 1 v 1 + c 2 v 2 c_1v_1+c_2v_2 c1v1+c2v2能够最接近 v 3 v_3 v3?
此问是考察投影概念
由于是正交向量, v 3 v_3 v3在由 v 1 , v 2 v_1,v_2 v1,v2确定的平面内的投影为 0 0 0向量
所以 c 1 = 0 , c 2 = 0 c_1=0,c_2=0 c1=0,c2=0时最接近 v 3 v_3 v3 -
马尔科夫矩阵 A = [ . 2 . 4 . 3 . 4 . 2 . 3 . 4 . 4 . 4 ] A=\begin{bmatrix}.2&.4&.3\\.4&.2&.3\\.4&.4&.4\end{bmatrix} A=⎣⎡.2.4.4.4.2.4.3.3.4⎦⎤
(1)求其特征值前两列之和为第三列的两倍,所以是奇异矩阵
奇异矩阵总有一个特征值为 0 0 0,而马尔科夫矩阵总有一个特征值为 1 1 1,剩下一个特征值从矩阵的迹得知为 − 0.2 -0.2 −0.2。(2) u k = A k u 0 , u 0 = [ 0 10 0 ] u_k=A^ku_0, u_0=\begin{bmatrix}0\\10\\0\end{bmatrix} uk=Aku0,u0=⎣⎡0100⎦⎤,求其稳态
先代入特征值 λ 1 = 0 , λ 2 = 1 , λ 3 = − 0.2 \lambda_1=0,\ \lambda_2=1,\ \lambda_3=-0.2 λ1=0, λ2=1, λ3=−0.2查看稳态 u k = c 1 λ 1 k x 1 + c 2 λ 2 k x 2 + c 3 λ 3 k x 3 u_k=c_1\lambda_1^kx_1+c_2\lambda_2^kx_2+c_3\lambda_3^kx_3 uk=c1λ1kx1+c2λ2kx2+c3λ3kx3
得知,当 k → ∞ k\to\infty k→∞,第一项与第三项都会消失,剩下 u ∞ = c 2 x 2 u_\infty=c_2x_2 u∞=c2x2我们再求出 λ 2 \lambda_2 λ2对应的特征向量
带入特征值求解 ( A − I ) x = 0 (A-I)x=0 (A−I)x=0
有 [ − . 8 . 4 . 3 . 4 − . 8 . 3 . 4 . 4 − . 6 ] [ ? ? ? ] = [ 0 0 0 ] \begin{bmatrix}-.8&.4&.3\\.4&-.8&.3\\.4&.4&-.6\end{bmatrix}\begin{bmatrix}?\\?\\?\end{bmatrix}=\begin{bmatrix}0\\0\\0\end{bmatrix} ⎣⎡−.8.4.4.4−.8.4.3.3−.6⎦⎤⎣⎡???⎦⎤=⎣⎡000⎦⎤
可以消元得,也可以直接观察得到 x 2 = [ 3 3 4 ] x_2=\begin{bmatrix}3\\3\\4\end{bmatrix} x2=⎣⎡334⎦⎤剩下就是求 c 2 c_2 c2了,可以通过 u 0 u_0 u0一一解出每个系数,但是这就需要解出每一个特征向量
另一种方法是,我们可以通过马尔科夫矩阵的特性知道,对于马尔科夫过程的每一个 u k u_k uk都有其分量之和与初始值分量之和相等(联想麻省和加州人口迁移的例子,人的总量不会增加也不会减少)
所以对于 x 2 = [ 3 3 4 ] x_2=\begin{bmatrix}3\\3\\4\end{bmatrix} x2=⎣⎡334⎦⎤, 3 + 3 + 4 = 10 3+3+4=10 3+3+4=10,所以有 c 2 = 1 c_2=1 c2=1
所以最终结果是 u ∞ = [ 3 3 4 ] u_\infty=\begin{bmatrix}3\\3\\4\end{bmatrix} u∞=⎣⎡334⎦⎤ -
对于二阶方阵,根据给出的性质,给出一个方阵实例或者说明不存在这样的方阵
(1)求投影在直线 a = [ 4 − 3 ] a=\begin{bmatrix}4\\-3\end{bmatrix} a=[4−3]上的投影矩阵
应为 P = a a T a T a P=\frac{aa^T}{a^Ta} P=aTaaaT。(2)特征值特征向量 λ 1 = 2 , x 1 = [ 1 2 ] , λ 2 = 3 , x 2 = [ 2 1 ] \lambda_1=2,\ x_1=\begin{bmatrix}1\\2\end{bmatrix},\lambda_2=3,\ x_2=\begin{bmatrix}2\\1\end{bmatrix} λ1=2, x1=[12],λ2=3, x2=[21]
从对角化公式得 A = S Λ S − 1 = [ 1 2 2 1 ] [ 0 0 0 3 ] [ 1 2 2 1 ] − 1 A=S\Lambda S^{-1}=\begin{bmatrix}1&2\\2&1\end{bmatrix}\begin{bmatrix}0&0\\0&3\end{bmatrix}\begin{bmatrix}1&2\\2&1\end{bmatrix}^{-1} A=SΛS−1=[1221][0003][1221]−1,解之即可。(3) A A A是一个实矩阵,且对任意矩阵 B B B, A A A都不能分解成 A = B T B A=B^TB A=BTB
我们知道 B T B B^TB BTB是对称的,所以给出一个非对称矩阵 A A A即可。(4)矩阵 A A A有正交的特征向量,但 A A A不是对称矩阵
我们在33讲提到过,满足 A A T = A T A AA^T=A^TA AAT=ATA的矩阵特征向量正交
所以反对称矩阵特征向量正交,有 A = [ 0 1 − 1 0 ] A=\begin{bmatrix}0&1\\-1&0\end{bmatrix} A=[0−110]
正交矩阵也满足,也有特征向量正交,有 A = [ cos θ − sin θ sin θ cos θ ] A=\begin{bmatrix}\cos\theta&-\sin\theta\\\sin\theta&\cos\theta\end{bmatrix} A=[cosθsinθ−sinθcosθ](这个矩阵也是旋转矩阵)
这些矩阵都具有复数域上的正交特征向量组 -
最小二乘问题, [ 1 0 1 1 1 2 ] [ C D ] = [ 3 4 1 ] ( A x = b ) \begin{bmatrix}1&0\\1&1\\1&2\end{bmatrix}\begin{bmatrix}C\\D\end{bmatrix}=\begin{bmatrix}3\\4\\1\end{bmatrix}(Ax=b) ⎣⎡111012⎦⎤[CD]=⎣⎡341⎦⎤(Ax=b)
(1)求其最优解
解得 [ C ^ D ^ ] = [ 11 3 − 1 ] \begin{bmatrix}\hat C\\\hat D\end{bmatrix}=\begin{bmatrix}\frac{11}{3}\\-1\end{bmatrix} [C^D^]=[311−1](2)求 b b b到矩阵列空间的投影 p p p
向量 p = A x ^ p=A\hat x p=Ax^
所以 p = [ 1 0 1 1 1 2 ] [ C ^ D ^ ] = [ 1 0 1 1 1 2 ] [ 11 3 − 1 ] p=\begin{bmatrix}1&0\\1&1\\1&2\end{bmatrix}\begin{bmatrix}\hat C\\\hat D\end{bmatrix}=\begin{bmatrix}1&0\\1&1\\1&2\end{bmatrix}\begin{bmatrix}\frac{11}{3}\\-1\end{bmatrix} p=⎣⎡111012⎦⎤[C^D^]=⎣⎡111012⎦⎤[311−1](3)求拟合直线的图像
y = C ^ + D ^ x y=\hat C+\hat Dx y=C^+D^x即 y = 11 3 − x y=\frac{11}{3}-x y=311−x

(4)求一个非零向量 b b b使得最小二乘求得的 [ C ^ D ^ ] = [ 0 0 ] \begin{bmatrix}\hat C\\\hat D\end{bmatrix}=\begin{bmatrix}0\\0\end{bmatrix} [C^D^]=[00]
我们知道最小二乘求出的向量
[
C
^
D
^
]
\begin{bmatrix}\hat C\\\hat D\end{bmatrix}
[C^D^]使得
A
A
A列向量的线性组合最接近
b
b
b向量(即
b
b
b在
A
A
A列空间中的投影)
如果这个线性组合为
0
0
0向量(即投影为
0
0
0),则
b
b
b向量与
A
A
A的列空间正交
所以可以取
b
=
[
1
−
2
1
]
b=\begin{bmatrix}1\\-2\\1\end{bmatrix}
b=⎣⎡1−21⎦⎤,同时正交于
A
A
A的两个列向量

















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









