







一、JOB详解
1.1 创建JOB
- 通过Job类创建作业
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, “JobName”);
构建job的整个过程(run方法)都在linux中执行(不在YARN) - Configuration类
- 可加载Hadoop中的配置文件
缺省加载core-default.xml和core-site.xml
读取配置文件信息可实现HDFS Java API在Job中的执行 - 可用于临时变量传输
向Configuration对象写入自定义键值对
Job执行后,Job中的Configuration对象会写入Context,可在Map或Reduce等处读写
- 可加载Hadoop中的配置文件
1.2 Job中包含的元素
- 作业所属的主类
setJarByClass(Class<?> cls) - 输入/输出数据类型
setInputFormatClass(Class<? extends InputFormat> cls)
setOutputFormatClass(Class<? extends OutputFormat> cls) - 输出键值对数据类型
setOutputKeyClass(Class<?> theClass)
setOutputValueClass(Class<?> theClass)
应为WritableComparable的子类 - 输入/输出(HDFS)地址
TextInputFormat.addInputPath(Job job, Path path)
TextOutputFormat.addOutputPath(Job job, Path path)
TextInputFormat和TextOutputFormat为静态类
1.3 键值数据类型
- Hadoop中的键值数据类型须使用对应的包装类型,均继承自WritableComparable,内含读写和比较功能
Hadoop提供的主要内置键值数据类型有:- IntWritable、LongWritable、ShortWritable
- FloatWritable、DoubleWritable
- BooleanWritable
- TextWritable
- ArrayWritable
- ByteWritable 、BytesWritable
- EnumSetWritable
- MapWritable、SortedMapWritable
- ObjectWritable
可通过继承重写WritableComparable类实现自定义键值类型。
1.4 设置组件
- Mapper
setMapperClass(Class<? extends Mapper> cls) - Combiner
setCombinerClass(Class<? extends Reducer> cls)
选配,缺省不进行Combiner
使用Reducer类,相当于运行在map本地的reducer - Partitioner
setPartitionerClass(Class<? extends Partitioner> cls)
选配,缺省使用系统默认Partition逻辑 - Sort
setSortComparatorClass(Class<? extends RawComparator> cls)
选配,自定义sort的排序逻辑,缺省使用系统默认排序逻辑 - Reducer
setReducerClass(Class<? extends Reducer> cls)
选配,缺省不进行Reduce
二、MapReduce编程模型
- map所在container过程(MapTask)
input format
record reader
mapper
combiner
partitioner - reduce所在container过程(ReduceTask)
shuffle
sort
reducer
output format
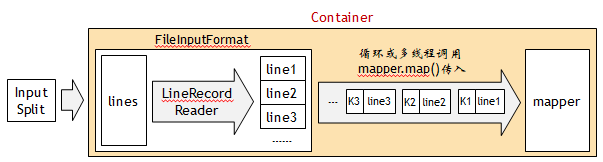
2.1 input format 和 record reader
- RecordReader将输入数据切片,以键值对的方式送入mapper。系统默认的RecordReader是LineRecordReader,按行切分,键为行首字符偏移量,值为行(段落)文本

重写FileInputFormat 类,并继承重写其中的RecordReader类,可实现自定义数据切片方法
2.2 Mapper
- Mapper的子类,用于执行map逻辑
以下组件/类的实例在框架中是一一对应的关系:- Container、InputSplit、FileInputFormat、Mapper、Combiner、Partitioner
问题:
- 一个InputSplit传入FileInputFormat中,缺省情况下会被划分成多行,每一行对应一个键值对(Mapper的输入),而Mapper每次只能接收一个键值对输入
Mapper实例会多次执行,每执行一次,处理一个键值对,直到所有键值对处理完为止。
Mapper类
对各个参数详解:

2.3 上下文对象(Context)
- 是MapReduce中保存信息的一个中介,Mapper和Reducer输出键值对均需要写入Context对象
- Mapper中的Context继承至MapContext,Reducer中的Context继承至ReduceContext
MapContext和ReduceContext中的数据稍有不同 - Configuration在MapContext和ReduceContext对象中均可获得
Configuration conf = context.getConfiguration() - MapContext可获取Mapper对应的FileSplit来自哪个文件
(FileSplit)context.getInputSplit()).getPath().toString()
2.4 Combiner
本地可选的reducer,在map本地实现键聚合,减少shuffle的键值对数量。
2.5 Reduce类
对各个参数详解:

2.6 partitioner
- 用于确定mapper的键值对与reducer的对应关系
- 将mapper数据进行分片(shard),每个分片对应一个reducer,同一个key被分配到同一个reducer
- 可继承Partitioner类并重写partition规则

自定义partitioner
public class ProvicePartitioner extends Partitioner<Text, FlowBean>{
public static HashMap<String, Integer> proviceDict
=new HashMap<String,Integer>(); //定义hash表,用于reduce分配
static {
proviceDict.put("a", 0); //将a分配到reduce0
proviceDict.put("b", 1); //将b分配到reduce1
proviceDict.put("c", 2); //将c分配到reduce2
proviceDict.put("d", 3); //将d分配到reduce3
}
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
String profix = key.toString().substring(0, 1); //取出mapper输出键首字符
//取出key首字符对应的reduce编号,将该key分配到此reduce
return proviceDict.get(profix);
}}
注:在job中设置Reducer数量和自定义Partitioner
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(4);
2.7 倒排索引
在倒排索引中,不同词汇的文章数量相差巨大,为负载平衡,用自定义的partitioner将词汇指派到指定的reducer

2.8 Shuffle 和 Sort
- shuffle
- partitoner之后,在各reducer的container执行shuffle,将各mapper的输出键值对拉取(copy)过来,并且归并(merg)键值对(将相同键合并,值写入数组)
- 此步骤会造成大量的集群内部网络传输和IO操作
- shuffle策略是默认的,不允许定制
- 优化方法:
- 对mapper输出进行数据压缩,减少网络传输量
- mapper后增加combiner,减少shuffle时传输的键值对数量
- 增加shuffle的缓存空间
shuffle接收到键值对时,先将其存入缓存,当数据量超过阈值后就写入磁盘
- partitoner之后,在各reducer的container执行shuffle,将各mapper的输出键值对拉取(copy)过来,并且归并(merg)键值对(将相同键合并,值写入数组)
- sort
对shuffle后的键值对按照键进行排序
sort将按按照键排序好的键值对依次送入reducer- 一次送入一组(Group)键值对,缺省情况下,一个键对应一个组;使用组排序(GroupingComparator)可修改分组策略。


- 一次送入一组(Group)键值对,缺省情况下,一个键对应一个组;使用组排序(GroupingComparator)可修改分组策略。
2.9 reducer
- Reducer的子类,用于执行reduce逻辑
- Shuffle后,数据进入Reducer所在的container,经过Sort后,数据将传入Reducer
- 一个Reducer可能被分配到多个键值对,而Reducer一次只能处理一个键值对,于是就有与Mapper类似的机制,键值对会依次传入Reduer中处理

2.10 Output FoRmat
- 用于MapReduce输出
- 继承至FileOutputFormat类
- 常用OutputFormat类
TextOutputFormat,输出文件,一个键值对一行文本,键和值以 /t 字符隔开
- 缺省情况下每个Reducer对应一个输出文件,全部文件被输出到HDFS的输出目录中
- _SUCCESS:空文件
- part_r_:输出文件,id为reduce的id
- 在没有Reducer的Job中,输出文件规则不变
2.11 临时数据传输和存储
- 通过类成员
由于Map和Reduce是运行在不同的Container中的,故虽然它们都写在同一个类中,但并不能通过类成员变量共享或传输数据 - 通过Configuation
Configuation会被框架写入context,跟随context在Map和 - Reduce对象中传输
Configuation支持自定义键值对的读写
context.getConfiguration().set(“myKey”, “myValue”);
context.getConfiguration().get(“myKey”); - 通过HDFS
MapReduce可通过HDFS Java API读写HDFS文件
注意不能在Map或Reduce中写入同一个HDFS文件,因为HDFS不支持并发写入
三、 Mapreduce框架排序机制
- MapReduce使用Sort对键进行排序
排序方式分为:组(键的分组)排序和键(组内的键)排序 - 例:统计每个用户的消费金额逐日变化量
key为用户名,value为日期和消费金额(Tuple)

3.1 二次排序方案
- 在reduce中对值中的日期进行二次排序
对container内存消耗较大 - 利用框架中的sort进行二次排序,sort针对key进行排序,故须修改键值对的结构

分组(group)排序:修改key的组排序逻辑,以key中的用户进行组排序;再修改键排序逻辑,按日期进行键排序
分区(partition)排序:修改partitioner逻辑,将每个用户映射到不同的Reducer中;修改组排序逻辑,不按组排序(即不分组),再修改key排序逻辑,按日期进行key排序;通常用于全排序
3.2 多值键
每个键包含两个值,除非两个值都一样,否则会被认为是不同的key,缺省情况下,不同的key会被分到不同的组中。

3.3 组排序
- 以key中的用户名进行组排序
即不同的用户会按排序策略排到不同的组中,而相同的用户会被排到同一个组中。

3.4 二次排序

3.5 Reducer迭代器
- 法一

- 法二

3.6 多值键和key排序策略
- 使用自定义WritableComparable子类实现
public class TextPair implements WritableComparable<CodeTimeTuple> {
private LongWritable date = new LongWritable(); //时间属性(省略getter和setter)
private Text user = new Text(); //用户属性(省略getter和setter)
public void write(DataOutput dataOutput) throws IOException {
date.write(dataOutput); //将值写入流,由框架调用
user.write(dataOutput);
}
public void readFields(DataInput dataInput) throws IOException {
date.readFields(dataInput); //从流中读取值,由框架调用
user.readFields(dataInput);
}
public int compareTo(CodeTimeTuple o) { //Key排序比较器
int cmp = this.getUser().compareTo(o.getUser()); //先按User排序
if(cmp != 0) return cmp;
return this.getDate().compareTo(o.getDate()); //如果User相同,再按日期排
}
}
- 使用自定义WritableComparator子类实现,方法1:
public static class Grouping extends WritableComparator {
protected Grouping() {
super(TextPair.class, true);
}
//b1对象1的字节数组,s1对象数据起始偏移量,l1对象数组长度
//b2对象2的字节数组,s2对象数据起始偏移量,l2对象数组长度
//直接比较字节数组,省去了字节数组反序列化为对象的过程,速度更快
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
//b1,s1,8:b1中最开始的8个字节数据,即为日期数据
//b1,s1+8,l1-8:b1中从8个字节后到末尾的数据,即为用户名
int c = WritableComparator.compareBytes(b1, s1 + 8, l1 - 8, b2, s2 + 8, l2 -8);
return c; //若不比较直接return 0,则为不分组(所有Key一个组)
}
}
将组排序策略写入Job:
job.setGroupingComparatorClass(Grouping.class);
- 使用自定义WritableComparator子类实现,方法2:
public static class Grouping extends WritableComparator {
protected Grouping() { super(TextPair.class, true); }
private TextPair key1 = new CodeTimeTuple();
private TextPair key2 = new CodeTimeTuple();
private final DataInputBuffer buffer = new DataInputBuffer();
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
buffer.reset(b1, s1, l1);
key1.readFields(buffer); //从字节序列中反序列化对象(比方法1更慢)
buffer.reset(b2, s2, l2);
key2.readFields(buffer);
}
catch (Exception e){
return 0;
}
return key1.getUser().compareTo(key2.getUser()); //比较前后两个Key的User
}
}
- 使用自定义WritableComparator子类实现,方法3:
public static class Grouping extends WritableComparator {
protected Grouping() {
super(TextPair.class, true);
}
@Override
//由框架将数据反序列化为对象后,从参数传入,速度与方法2等同
public int compare(WritableComparable a, WritableComparable b) {
TextPair key1 = (TextPair)a;
TextPair key2 = (TextPair)b;
//若不比较直接return 0,则为不分组(所有Key一个组)
return key1.getUser().compareTo(key2.getCode());
}
}
3.7 分区排序
- 以全排序为例
现有10亿组数据,数据范围大概在0~1000之间均匀分布,需要对其做全排序
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









