







Spark Streaming 接收外部数据的高级API,有Flume、Kafka、Kinesis,这篇文章简单实操,接收Flume的数据,通过Push模式。要注意,这种方式是不可靠的,在生产上更倾向于使用pull模式,该模式见文章 spark streaming使用pull模式读取数据。
组件环境:
- Spark 2.4.4
- Flume 1.6.0
- Scala 2.11.8
- JDK 1.8.0_121
- IDEA 2017.2
- redhat 7.4
Flume安装在Redhat服务器上,IP为172.16.13.143;本地开发在windows10 的IDEA,maven工程下,windows10 的IP为192.168.15.229,且redhat服务器和windows10是互通的(虽然不在同一网段,但要注意windows10的防火墙以防端口被拦截)。
一、flume采集数据的配置文件
stream-agent.sources = netcat-source
stream-agent.channels = memory-channel
stream-agent.sinks = avro-sink
## sources,数据从哪里产生,从redhat服务器的8888端口接收数据
stream-agent.sources.netcat-source.type=netcat
stream-agent.sources.netcat-source.bind=172.16.13.143
stream-agent.sources.netcat-source.port=8888
## channels
stream-agent.channels.memory-channel.type=memory
stream-agent.channels.memory-channel.capacity=1000
stream-agent.channels.memory-channel.transactionCapacity=100
## sinks,要发送到的目的地,这里是我的window10,所以填window10的IP
stream-agent.sinks.avro-sink.type=avro
stream-agent.sinks.avro-sink.hostname=192.168.15.229
stream-agent.sinks.avro-sink.port=8989
## bind sources、channels、sinks
stream-agent.sources.netcat-source.channels=memory-channel
stream-agent.sinks.avro-sink.channel=memory-channel
使用netcat source收集数据,当然也可以使用exec source或者spooling directory source收集数据。
二、Spark Streaming代码
Spark Streaming接收Flume过来的数据,并且进行词频统计。首先maven工程下加入Streaming操作Flume的依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>2.4.4</version>
</dependency>
代码使用Scala编写
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePushWordCount {
def main(args: Array[String]): Unit = {
//参数判断,参数必须为两个,hostname/IP 和 端口号
if(args.length != 2) {
System.err.println("Usage: FlumePushWordCount <hostname> <port>")
System.exit(1)
}
val Array(hostname,port) = args
// 本地测试
val sparkconf = new SparkConf().setMaster("local[*]").setAppName("FlumePushWordCount")
// 服务器上运行
//val sparkconf = new SparkConf()
val ssc = new StreamingContext(sparkconf,Seconds(5))
// TODO... 使用SparkStreaming 整合Flume
val flumeStream = FlumeUtils.createStream(ssc,hostname,port.toInt)
flumeStream.map(x => new String(x.event.getBody.array()).trim) // 获取flume上发送过来的信息
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) // 对接收到的信息进行wordCount
.print() // 打印结果
ssc.start()
ssc.awaitTermination()
}
}
仅在本地测试,在服务器上运行需要把sparkconf一行改为被注释的那行。
三、本地启动测试
Spark Streaming直接采集flume的avro sink过来的数据,因为使用的是push模式,所以需要先启动streaming端,再启动flume。
IDEA上启动Spark Streaming程序,需要先添加两个参数:

然后直接启动。
Flume启动(在flume home目录下):
./bin/flume-ng agent --name stream-agent \
--conf ./conf \
--conf-file ./conf/netcat-memory-avro.conf \
-Dflume.root.logger=INFO,console &
然后启动netcat(只要跟redhat服务器网络相通,安装有telnet客户端即可发送数据):
telnet 172.16.13.143 8888
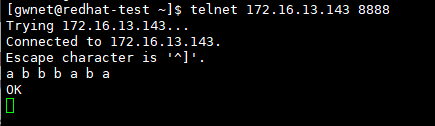
在netcat窗口下发送数据,以空格分隔,观察IDEA中运行的情况,能出现结果说明成功了。
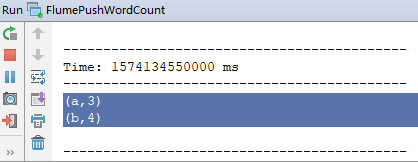
四、在服务器上运行
在服务器运行前提,spark streaming代码中已经把spark conf改为了集群运行;已经搭建好了spark集群,其中一台机器是172.16.13.151,spark-submit运行在这上面。
- IDEA中打包maven项目,在idea界面,View -> Tool Windows -> maven project ,调出maven界面,双击package
这里要注意两点:a.pom.xml文件中最好不要指定main class,在提交的时候再指定,免得以后忘记改主类;b.可以在pom.xml文件中设置打成两个包,一个有依赖,一个无依赖。这里只要flume-streaming的依赖,spark core、spark streaming相关jar已经在spark集群中。 - 把打包的jar文件上传到spark集群
- spark-submit 提交,这里master只能是local,不能是yarn,因为后续的flume要绑定某个具体的host
spark-submit --class project.weblog.ylqdh.bigdata.sparkstreaming.FlumePushWordCount --master local[*] ./Spark2.11-bigdata-flume-jar-with-dependencies.jar 0.0.0.0 8989
默认的日志级别是INFO,会有很多日志,输出的结果很难看到,可以设置日志级别是WARN,比较好观察输出结果
4. flume 运行,注意这里的 netcat-memory-avro.conf 中已经把sink发送到的hostname改为了172.16.13.151
./bin/flume-ng agent --name stream-agent --conf ./conf --conf-file ./conf/netcat-memory-avro.conf -Dflume.root.logger=INFO,console
- 在安装有telnet 的客户端的机器上运行
telnet 172.16.13.143 8888
测试完成!!















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









