







实验具体说明6.824 Lab 1: MapReduce (mit.edu)
目前windows还不支持go build指令,所以需要在linux平台运行。跟着课程官网的说明,可以成功跑起来mrsequential.go,也就是串行的mapreduce程序,需要实现伪分布式的mapreduce程序。(在同一台机子上用多个线程模拟多台机器)
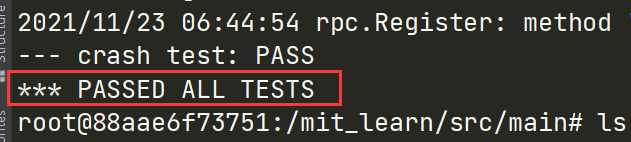
在your jobs中已经说得很清楚了,只需要实现自己的coordinator.go worker.go rpc.go即可,剩下的代码都不要修改。完成代码后运行test-mr.sh即可进行评测,如果所有场景的测试都通过,最后控制台会输出:
之后就是课程网站给的一些提示,对于写代码非常有帮助,大概翻译记录一下:
-
map阶段应该把key分到nReduce个桶中,这个nReduce是在mrcoordinator.go中指定的10
-
worker应该把第X个reduce task的输出写入mr-out-X中
-
mr-out-X文件的内容应该是"%v %v",可以参照mrsequential.go中是怎么写入mr-out的
-
coordinator.go应该实现一个Done()方法,如果map和reduce都完成了,该方法应该返回true,然后mrcoordinator.go就可以正常退出。为了方便检查两个任务是否完成,可以考虑在实现的时候设置两个bool值mapDone和reduceDone。因为看mrcoordinator.go中是在一个死循环中每隔一秒调用Done()任务,根据返回的bool值判断是否退出的,所以Done函数中最好不要做复杂的操作。
-
当所有的任务都完成后,worker进程应该退出,一个简单的实现方法是通过call()方法的返回值来退出,如果返回false,那么说明任务完成了,可以直接退出。或者coordinator返回的状态中有一个Exit,告诉worker可以退出了。具体看自己的实现方式。
-
第一步可以从worker向coordinator请求任务写起,然后coordinator收到请求后,应该有一系列的逻辑判断(比如任务是否完成了,应该分配哪个任务),之后返回文件名,worker收到文件名之后就可以读文件,进行下一步操作
-
因为是在本机上跑的,所以map和reduce任务可以同时看到所有的文件,如果需要在真的多机上跑,则需要分布式文件系统,比如GFS
-
中间文件的命名最好遵循mr-X-Y,X是map task index,Y是reduce task index
-
中间文件应该用一种方便写入读取的格式,txt就不太合适,因为只能按行读取解析然后新建结构体KeyValue并赋值,官方给的建议是json,并且给出了代码样例:

可以看到可以直接把键值对decode到kv中,然后append,非常方便
-
map阶段需要将键放到不同的桶中,已经实现好了ihash()函数,通过ihash(key) % nReduce,就可以确定放到哪个桶中
-
coordinator作为rpc服务端,会有多个worker访问,会产生竞态,不要忘了上锁。后续可以用chan,写起来会更优雅一些。
-
worker有时候需要wait,比如reduce必须等到所有的map都完成后才能开始,一个可能的实现方式是worker周期性向coordinator请求任务,可以根据返回的状态等待一秒或者每次请求之间间隔一秒。
-
coordinator不能区分worker到底是运行得慢还是崩了,还是网络有问题导致消息没有及时传递。所以最好的办法是coordinator设置一个等待的阈值,如果超过这个时长任务还在运行中,那么就把这个任务重新分配给请求任务的worker,对于这个实验,这个阈值可以设置为10s。所以除了需要为每个任务维护一个状态,表示未分配、运行中、已完成之外,还需要维护任务的开始时间,这样当请求任务的时候,就方便判断是否超时,代码可以大概写成这样:
func taskAvailable(task Task) bool { isIdle := task.State == Idle isInProgress := task.State == InProgress timeLimit := task.StartTime.Add(10 * time.Second) timeLimitReached := time.Now().After(timeLimit) return isIdle || (isInProgress && timeLimitReached) }只要满足这个布尔判断,就表明当前的任务是可以分配的
-
为了确保宕机的情况下没人能观察到破损的文件,论文中多次提到用临时文件(ioutil.TempFile)来存储结果,然后在执行成功并告知coordinator的时候,由coordinator完成重命名(os.Rename)操作,确保结果的正确性。
初步设计worker
按照课程网站的建议,应该从worker请求任务开始写起,参考课堂上给的rpc样例代码,就不可避免的需要有Args参数和Reply参数,那么就应该思考这两个结构体里应该有什么变量,才能方便worker和coordinator交换信息。
请求任务的话,仔细想一下应该是没有什么变量的,因为现在是伪分布式系统,所有的worker都在一台机子上,不区分是mapWorker还是reduceWorker,所以对于请求什么任务是不清楚的,只能由coordinator根据当前状态,判断应该派发什么任务,Args是空的就行。
然后是Reply,首先应该有一个任务类型TaskType,表明这次返回的是什么任务,根据课程网站的提示,可以设置为四个type:MAP、Reduce、Wait、Exit。worker启动后就应该在一个死循环里一直请求任务,直到coordinator返回Exit,worker才退出。Wait状态则是之前提到的任务都已经派发了但是还没执行完的时候,需要等待下一阶段。所以worker中的Worker方法的代码大致是这样的:
var mapf func(string, string) []KeyValue
var reducef func(string, []string) string
// Worker
// main/mrworker.go calls this function.
//
func Worker(mapfunc func(string, string) []KeyValue,
reducefunc func(string, []string) string) {
mapf = mapfunc
reducef = reducefunc
for {
reply, ok := requestTask()
if !ok {
return
}
switch reply.TaskType {
case Map:
handleMapTask(reply)
case Reduce:
handleReduceTask(reply)
case Wait:
time.Sleep(time.Second)
case Exit:
return
default:
log.Fatalf("Unrecognized task type!")
}
}
}
按照上面的初步设定,Args和Reply也可以写出来,这段最好放rpc.go中,毕竟和rpc调用相关:
const (
Map = "Map"
Reduce = "Reduce"
Wait = "Wait" // no task currently available
Exit = "Exit" // all tasks done
)
type Args struct {
}
type Reply struct {
TaskType string
}
然后就是请求任务的代码了,可以参考课堂给出的rpc代码写,call方法和coordinatorSock方法是原本的代码中就包含的,不用更改:
func requestTask() (Reply, bool) {
args := Args{}
reply := Reply{}
ok := call("Coordinator.DispatchTask", &args, &reply)
return reply, ok
}
//
// send an RPC request to the coordinator, wait for the response.
// usually returns true.
// returns false if something goes wrong.
//
func call(rpcname string, args interface{}, reply interface{}) bool {
// c, err := rpc.DialHTTP("tcp", "127.0.0.1"+":1234")
sockname := coordinatorSock()
c, err := rpc.DialHTTP("unix", sockname)
if err != nil {
log.Fatal("dialing:", err)
}
defer c.Close()
err = c.Call(rpcname, args, reply)
if err == nil {
return true
}
fmt.Println(err)
return false
}
初步设计coordinator
既然worker请求任务了,那么coordinator就要处理请求,并派发任务。由于worker是stateless的,所以大量判断都集中在coordinator中,我们应该实现一个DispatchTask方法来派发任务。
实现该方法之前,还是应该思考一下coordinator中应该存一些什么状态,来帮助它判断应该派发什么任务。
- 首先肯定要有锁,因为会有多个worker请求
- 然后还有上面提到的mapDone和recudeDone两个布尔值,用于Done()方法判断任务是否完成
- 最后肯定要存map任务和reduce任务,用数组或者哈希表都可以,这里就用简单的数组了
- 可以把任务再抽成一个结构体,因为里面要存任务TaskType,StartTime,State
type Coordinator struct {
mutex sync.Mutex
nMap int
nReduce int
mapDone bool
reduceDone bool
mapTasks []Task
reduceTasks []Task
}
type Task struct {
TaskType string
State string
StartTime time.Time
// used by map task
FileName string
}
const (
Idle = "Idle"
InProgress = "In progress"
Completed = "Completed"
)
通过看test-mr.sh脚本和mrcoordinator.go,可以看到coordinator启动的时候会把所有的inputfile传进来,并指定nReduce的个数,所以需要在Task结构体中加入文件名,不然给worker指定任务的时候,worker不知道读哪个文件。(reduce任务其实就不需要指定文件名了,因为它读入的文件名是mr-X-Y,只要指定map和reduce任务的index就可以)
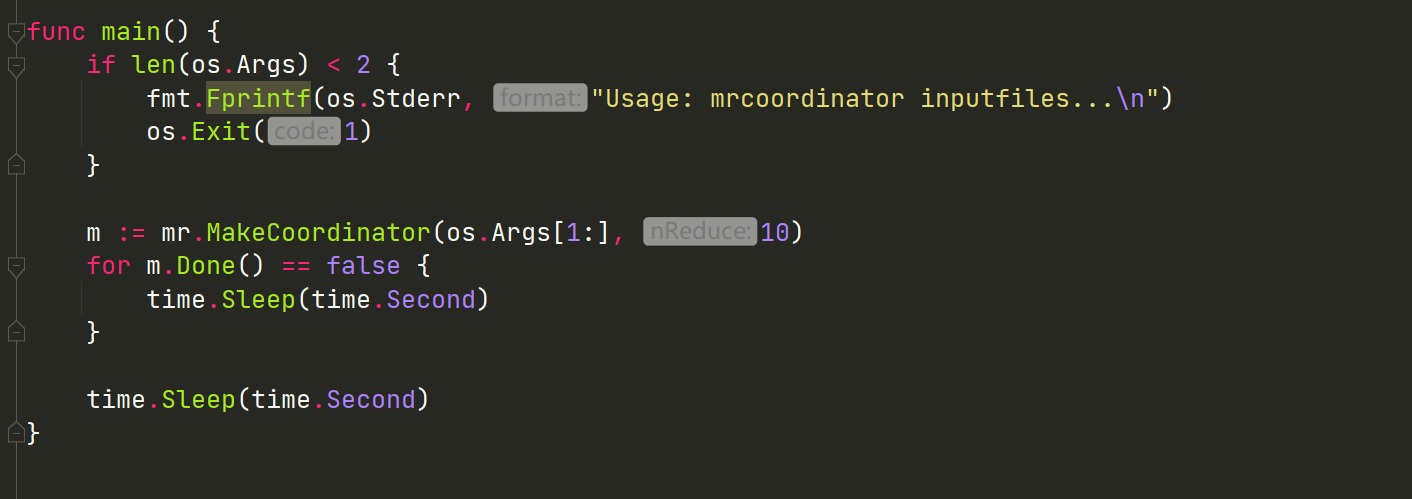
那么服务端初始化的时候就要根据传入的文件和nReduce相应地初始化:
// MakeCoordinator
// create a Coordinator.
// main/mrcoordinator.go calls this function.
// nReduce is the number of reduce tasks to use.
//
func MakeCoordinator(files []string, nReduce int) *Coordinator {
coordinator := Coordinator{}
coordinator.nMap = len(files)
coordinator.nReduce = nReduce
coordinator.mapDone = false
coordinator.reduceDone = false
coordinator.mapTasks = make([]Task, coordinator.nMap)
for i := 0; i < len(files); i++ {
coordinator.mapTasks[i] = Task{
TaskType: Map,
State: Idle,
FileName: files[i]
}
}
coordinator.reduceTasks = make([]Task, coordinator.nReduce)
for i := 0; i < coordinator.nReduce; i++ {
coordinator.reduceTasks[i] = Task{
TaskType: Reduce,
State: Idle,
}
}
coordinator.server()
return &coordinator
}
下面就需要开始写派发任务的方法了,大致的流程应该是这样的:
- 先上锁并defer解锁
- 如果两个都完成了,直接告诉worker任务为Exit并退出
- map任务没完成,轮询所有map任务,看有没有可以分配的,如果都分配了但没有完成,就让worker睡一秒,也就是Wait。如果遍历一遍发现都完成了,就修改mapDone为true
- map都完成了,再轮询所有reduce任务,看有没有可以分配的,如果都分配了但没有完成,也让worker睡一秒。如果都完成了,就修改reduceDone为true,并告诉worker Exit
func (c *Coordinator) DispatchTask(args *Args, reply *Reply) error {
c.mutex.Lock()
defer c.mutex.Unlock()
if c.mapDone && c.reduceDone {
reply.TaskType = Exit
return nil
}
if !c.mapDone {
...
}
if !c.reduceDone {
...
}
reply.TaskType = Exit
return nil
}
DispatchTask
分别补充map和reduce的任务派发代码即可,写的时候就会发现之前Reply中的变量太少了,不足以让worker明白读哪个文件,写入哪个文件。
首先map任务需要指定文件名,其次需要指定mapTask的index,和nReduce。因为map任务的结果需要写入mr-X-Y,必须知道自己的index,并且要把结果通过ihash函数写入对应的桶中,必须要知道nReduce。所以之前rpc.go中的Reply需要补充一些变量:
type Reply struct {
TaskType string
// Used by map task
MapTaskIndex int
FileName string
NReduce int
}
if !c.mapDone {
for i := 0; i < c.nMap; i++ {
if c.mapTasks[i].State == Completed {
continue
}
if taskAvailable(c.mapTasks[i]) {
reply.TaskType = Map
reply.MapTaskIndex = i
reply.FileName = c.mapTasks[i].FileName
reply.NReduce = c.nReduce
c.mapTasks[i].State = InProgress
c.mapTasks[i].StartTime = time.Now()
return nil
}
}
}
这么写好像没有考虑Wait的情况:在for遍历的时候,假如不是所有的state都是completed的,那么不论之后是给worker派发任务还是发现正在执行的任务没有超时,都表明还有任务正在执行,这种情况下就应该返回Wait,让worker睡一秒再来请求任务,可以用一个bool变量来实现这个功能:
if !c.mapDone {
uncompleted := false
for i := 0; i < len(c.mapTasks); i++ {
if c.mapTasks[i].State == Completed {
continue
}
uncompleted = true
if taskAvailable(c.mapTasks[i]) {
reply.TaskType = Map
reply.MapTaskIndex = i
reply.FileName = c.mapTasks[i].FileName
reply.NReduce = c.nReduce
c.mapTasks[i].State = InProgress
c.mapTasks[i].StartTime = time.Now()
return nil
}
}
// All map tasks assigned, but some are not done
if uncompleted {
reply.TaskType = Wait
return nil
}
c.mapDone = true
}
如果最终走到c.mapDone = true,就表明map任务全都完成了,可以派发reduce任务了。
上面补充的Reply的参数是针对map任务的,reduce任务同样需要补充。同样需要reduce任务的index,同时还需要nMap,因为所有的map任务都会把结果写到各个桶中,假设map任务有15个也就是输入文件有15个,nReduce为10,那么1号reduce需要收集mr-0-1, mr-1-1, mr-2-1…mr-14-1,生成最终的mr-out-1。所有的任务完成后,最终生成的文件是mr-out-0, mr-out-1… mr-out-9。
type Reply struct {
TaskType string
// Used by map task
MapTaskIndex int
FileName string
NReduce int
// Used by reduce task
ReduceTaskIndex int
NMap int
}
reduce任务的派发和map差不多:
if !c.reduceDone {
uncompleted := false
for i := 0; i < len(c.reduceTasks); i++ {
if c.reduceTasks[i].State == Completed {
continue
}
uncompleted = true
if taskAvailable(c.reduceTasks[i]) {
reply.TaskType = Reduce
reply.ReduceTaskIndex = i
reply.NMap = c.nMap
c.reduceTasks[i].State = InProgress
c.reduceTasks[i].StartTime = time.Now()
return nil
}
}
if uncompleted {
reply.TaskType = Wait
return nil
}
c.reduceDone = true
}
handleMapTask
其实根据mrsequential.go中的代码,已经可以知道大概的流程怎么写了:
- 读文件
- 调用mapf
- 写入中间变量,sequential是写入数组中了,这里就需要写入中间文件了
- reduce读所有的中间文件写入数组中
- sort数组
- 计数并写入最终文件中
func handleMapTask(reply RequestTaskReply) {
// Read file content
file, err := os.Open(reply.FileName)
if err != nil {
log.Fatalf("cannot open %v", reply.FileName)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", reply.FileName)
}
file.Close()
// Call Map function
kva := mapf(reply.FileName, string(content))
pwd, _ := os.Getwd()
files := make([]*os.File, reply.NReduce)
for i := 0; i < len(files); i++ {
tempInterFileName := fmt.Sprintf("mr-%v-%v-*", reply.MapTaskIndex, i)
tempInterFile, err := ioutil.TempFile(pwd, tempInterFileName)
if err != nil {
log.Fatalf("Cannot create temp inter file: %v\n", tempInterFileName)
}
files[i] = tempInterFile
}
// write intermediate result
for _, kv := range kva {
reduceIndex := ihash(kv.Key) % reply.NReduce
interFile := files[reduceIndex]
// Write intermediate keys to file
encoder := json.NewEncoder(interFile)
err = encoder.Encode(kv)
if err != nil {
log.Fatalf("Cannot encode %v: %v", kv, err)
}
}
for i := 0; i < len(files); i++ {
err := files[i].Close()
if err != nil {
log.Fatalf("Cannot close %v: %v", files[i].Name(), err)
}
}
}
其实只是多了tempfile,所以比mrsequential.go稍微复杂一些。
handleReduceTask
和sequential的差不多,假设我们已经完成了coordinator重命名map生成的临时文件的代码,那么reduce读的就应该是mr-X-Y个文件,没有临时文件的后缀。
func handleReduceTask(reply RequestTaskReply) {
// Read from intermediate files
var intermediate []KeyValue
for i := 0; i < reply.NMap; i++ {
fileName := fmt.Sprintf("mr-%d-%d", i, reply.ReduceTaskIndex)
file, err := os.Open(fileName)
if err != nil {
log.Fatalf("Cannot open %s", fileName)
}
decoder := json.NewDecoder(file)
for {
var kv KeyValue
if err := decoder.Decode(&kv); err != nil {
break
} else {
}
intermediate = append(intermediate, kv)
}
}
// Sort intermediate KVs
sort.Sort(ByKey(intermediate))
// Write to output file
pwd, _ := os.Getwd()
tempOutputFileName := fmt.Sprintf("mr-out-%d-*", reply.ReduceTaskIndex)
tempOutputFile, err := ioutil.TempFile(pwd, tempOutputFileName)
if err != nil {
log.Fatalf("Cannot create temp file %s", tempOutputFileName)
}
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
var values []string
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
fmt.Fprintf(tempOutputFile, "%v %v\n", intermediate[i].Key, output)
i = j
}
tempOutputFile.Close()
}
notifyTaskDone
上面已经完成了worker执行任务的代码,执行完成后需要告诉coordinator当前任务完成,让其完成后续的收尾工作:重命名临时文件、修改任务状态。还是要通过rpc调用。这里请求的时候就不能再用之前的Args和Reply了。因为这次请求肯定要携带参数的:TaskType,TaskIndex这两个是必不可少的,coordinator必须靠这两个参数修改对应数组中指定任务的状态。
除此之外,coordinator还必须知道要重命名的文件的名字,因为生成的临时文件的后缀是随机的,如果让coordinator只根据index去匹配,可能能匹配到好多个,这样就乱套了(因为同一个任务可能因为超时被分给多个worker执行)。
至于reply是空的就可以了,因为worker没必要知道coordinator的处理结果:**如果是网络问题,那reply也收不到;如果是coordinator自己处理失败了,worker也没辙。**等着任务重分配就行了,也减少了代码量。
type TaskDoneArgs struct {
TaskType string
TaskIndex int
FileNames []string // Single element for reduce task
}
type TaskDoneReply struct {
}
rpc调用这块就比较好写了,和之前差不多:
func notifyTaskDone(taskType string, TaskIndex int, fileNames []string) {
args := TaskDoneArgs{taskType, TaskIndex, fileNames}
reply := TaskDoneReply{}
ok := call("Coordinator.TaskDone", &args, &reply)
if !ok {
log.Println("Call Coordinator.TaskDone returns FALSE")
}
}
然后handleMap和handleReduce在最后都调用一下这个函数就可以了。handleMap需要稍微加一点代码,在for循环创建临时文件的时候用一个数组记录一下临时文件的名字用来最后传递;handleReduce比较简单,因为只有一个临时文件,直接传[]string{tempOutputFileName}就可以。
TaskDone
其实非常简单就是上面提到的重命名和改状态,只是要注意碰到重复提交的时候直接略过就行。
func (c *Coordinator) TaskDone(args *TaskDoneArgs, reply *TaskDoneReply) error {
c.mutex.Lock()
defer c.mutex.Unlock()
if args.TaskType == Map {
if c.mapTasks[args.TaskIndex].State == Completed {
return nil
}
c.mapTasks[args.TaskIndex].State = Completed
for i := 0; i < c.nReduce; i++ {
name := fmt.Sprintf("mr-%v-%v", args.TaskIndex, i)
os.Rename(args.FileNames[i], name)
}
} else {
if c.reduceTasks[args.TaskIndex].State == Completed {
return nil
}
c.reduceTasks[args.TaskIndex].State = Completed
name := fmt.Sprintf("mr-out-%v", args.TaskIndex)
os.Rename(args.FileNames[0], name)
}
return nil
}















 2765
2765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









