







Dataset
用于自定义数据集,继承Dataset类,实现init,getitem,len方法。
init完成初始化,保存getitem中可能用到的变量
getitem的输入是索引,用于得到一个图片和对应的label
len是整个数据集的长度
dataset目录形式1:
总文件->train->label->所有该类图片
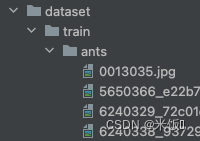
init:得到数据集根目录(用于训练时是到train),读取该目录下所有目录名作为label,打开每个目录保存图片名。
getitem:按照索引取出对应的图片名,根据根目录和图片名拼出图片的完整路径(这里是相对路径),读取图片,返回图片和对应的标签
len:图片总数
from torch.utils.data import Dataset
import os
from PIL import Image
class MyData(Dataset):
# 初始化中确定需要用到的变量是什么,这里用到的是dataset这个文件
# 文件的格式是dataset->train->ants/bees
# 后续(在getitem中)需要用到图片路径和标签,因此需要根目录,标签名字,以及图片数据集所在目录,和所有图片路径
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
# getitem决定通过索引获取数据的方式,返回的应该是图片和对应的标签
# 根据这个数据集的结构,图片是根据图片目录获得的,标签是目录名称
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = 'dataset/train'
ants_label_dir = 'ants'
bees_label_dir = 'bees'
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
# 数据集可以直接这样合并,在自己补充数据集的情况下更简便操作,效果是拼接,前面是蚂蚁后面是蜜蜂
train_dataset = ants_dataset + bees_dataset
dataset目录形式2:
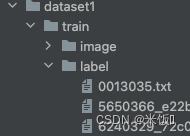
图片和标签分别在两个目录中,标签被保存在与图片同名的文本文件中。
from torch.utils.data import Dataset
import os
from PIL import Image
class MyData(Dataset):
def __init__(self, root_dir, img_dir, label_dir):
self.root_dir = root_dir
self.path = os.path.join(root_dir, img_dir)
self.img_path = sorted(os.listdir(self.path))
self.label_path = os.path.join(root_dir, label_dir)
self.label_path_file = sorted(os.listdir(self.label_path))
self.label = []
for name in self.label_path_file:
full_path = os.path.join(self.label_path, name)
with open(full_path,'r') as f:
self.label.append(f.read())
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.path, img_name)
img = Image.open(img_item_path)
return img, self.label[idx]
def __len__(self):
return len(self.img_path)
root_dir = 'dataset1/train'
img_dir = 'image'
label_dir = 'label'
train_dataset = MyData(root_dir, img_dir, label_dir)
在书写过程中过程中
此处使用的是pycharm
在下方栏的python console中可以将语句依次输入查看中间变量和结果,有助于调试。















 1482
1482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









