






import logging
import math
import os
import numpy as np
from PIL import Image
from torchvision import datasets
from torchvision import transforms
import torch
from torch.utils.data import Dataset, DataLoader
from config import config
from dataset.randaugment import RandAugmentMC
import cv2
logger = logging.getLogger(__name__)
cifar10_mean = (0.4914, 0.4822, 0.4465)
cifar10_std = (0.2471, 0.2435, 0.2616)
cifar100_mean = (0.5071, 0.4867, 0.4408)
cifar100_std = (0.2675, 0.2565, 0.2761)
normal_mean = (0.5, 0.5, 0.5)
normal_std = (0.5, 0.5, 0.5)
def get_breast():
transform_labeled = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=512),
transforms.ToTensor(),
transforms.Normalize(mean=cifar10_mean, std=cifar10_std)
]) #有标签数据集的标准化
transfortm_val = transforms.Compose([
transforms.CenterCrop(size=512),
transforms.ToTensor(),
transforms.Normalize(mean=cifar10_mean, std=cifar10_std)
]) #验证集的标准化
labeled_path=config.breast_labeled_path
train_labeled_dataset=breastSet(labeled_path,transform=transform_labeled)
unlabeled_path=config.breast_Unlabeled_path
train_unlabeled_dataset = breastSet(unlabeled_path,transform=TransformFixMatch(mean=cifar100_mean, std=cifar100_std))
test_path=config.breast_test
test_dataset=breastSet(test_path,transform=transfortm_val)
return train_labeled_dataset,train_unlabeled_dataset,test_dataset
def get_images_and_labels(dir_path):
images_list = [] # 文件名列表
labels_list = [] # 标签列表
for i in os.listdir(dir_path):
images_list.append(i)
print("images_list_len:",len(images_list))
for i in images_list:
if 'malignant' in i:
labels_list.append(1)
elif 'benign' in i:
labels_list.append(0)
elif 'normal' in i:
labels_list.append(2)
print("labels_list_len:",len(labels_list))
return images_list, labels_list
class breastSet(Dataset):
def __init__(self, dir_path, transform=None):
self.dir_path = dir_path # 数据集根目录
print("dir_path:",self.dir_path)
self.transform = transform
self.images, self.labels = get_images_and_labels(self.dir_path)
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_name= self.images[index]
img_path=os.path.join(self.dir_path,img_name)
img = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8),cv2.IMREAD_COLOR) # 读取图片,np.fromfile解决路径中含有中文的问题
# img = torch.from_numpy(img) # Numpy需要转成torch之后才可以使用transform
# img = img.permute(2, 0, 1)
img = Image.fromarray(img) # 实现array到image的转换,Image可以直接用transform
img=self.transform(img) #重点!!!如果为无标签的一致性正则化,那么此处会返回两个图 img即为一个list
label = self.labels[index]
return img,label
class TransformFixMatch(object):
def __init__(self, mean, std):
self.weak = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=512)]) #弱增强
self.strong = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=512),
RandAugmentMC(n=2, m=10)]) #强增强,比弱增强多了两种图像失真处理
self.normalize = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)])
def __call__(self, x):
weak = self.weak(x)
strong = self.strong(x)
#将弱增强后的图 强增强的图 分别进行标准化
return self.normalize(weak), self.normalize(strong) #返回一对弱增强、强增强
if __name__ == '__main__':
labeled_dataset,unlabeled_dataset,test_dataset=get_breast()
labeled_trainloader = DataLoader(
labeled_dataset,
batch_size=4,
drop_last=True)
unlabeled_trainloader = DataLoader(
unlabeled_dataset,
batch_size=4,
drop_last=True)
test_trainloader = DataLoader(
test_dataset,
batch_size=1,
drop_last=True)
for i,(img,label) in enumerate(labeled_trainloader):
print("load labeled_datatset!")
print(img.shape,label)
for (img1,img2),y in unlabeled_trainloader:
print("load unlabeled_datatset!")
print(img1.shape,img2.shape,y)
for (img,label) in test_trainloader:
print("load test_datatset!")
print(img.shape,label)重点:重写部分 继承torch.utils.data 中的Dataset
class breastSet(Dataset):
def __init__(self, dir_path, transform=None):
self.dir_path = dir_path # 数据集根目录
print("dir_path:",self.dir_path)
self.transform = transform
self.images, self.labels = get_images_and_labels(self.dir_path)
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_name= self.images[index]
img_path=os.path.join(self.dir_path,img_name)
img = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8),cv2.IMREAD_COLOR) # 读取图片,np.fromfile解决路径中含有中文的问题
# img = torch.from_numpy(img) # Numpy需要转成torch之后才可以使用transform
# img = img.permute(2, 0, 1)
img = Image.fromarray(img) # 实现array到image的转换,Image可以直接用transform
img=self.transform(img) #重点!!!如果为无标签的一致性正则化,那么此处会返回两个图 img即为一个list
label = self.labels[index]
return img,label记住:最后要返回的结果就是一对 (img,label)
重写中的要点:a.在初始化中,需要定义images_list , labels_list用于装 所有图像(或图像的文件名称),所有标签
b.基于得到的self.images,self.labels
在继承函数def __getitem__(self, index):中,进行索引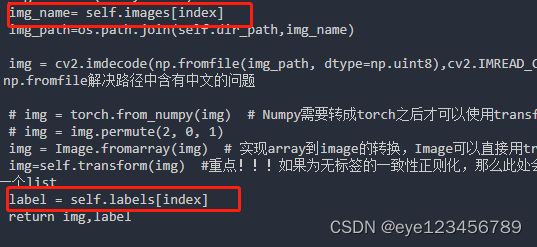
在降噪网络中的dataset.py中的 class EvalSet(NoiseImageDataSet):
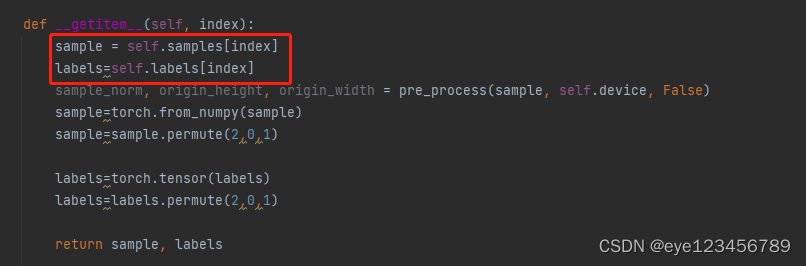
c.如何读取到img,根据路径读取

d.如何进行图像标准化。直接使用transform(img)
两种情况,读取出来的图为 Image对象,则可以直接使用transform
读取出来为numpy,则需要mat=torch.from_numpy(mat) #Numpy需要转成torch之后才可以使用transform















 9586
9586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









