







DataLoader
参数:

常用参数:
dataset(Dataset):之前dataset类型的数据集
batch_size(int):每个batch的大小
shuffle(bool):是否打乱
num_workers(int): 多少子进程同时运行,0代表主进程,windows下如果出现brokenpipe情况,改为0
drop_last(bool): 是否丢掉最后一个不够batch_size的batch,True为丢掉
sampler: 采样的方法,如果使用了就不能指定shuffle参数,默认情况下shuffle=True对应随机采样、shuffle=False对应顺序采样
batch_sampler:与sampler相同,但返回的是一个batch个数的索引
运行示例:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10('./data', train=False, transform= torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter('dataloader')
# epoch循环用来查看shuffle的效果
for epoch in range(2):
# 正常读取就是对DataLoader做for循环
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images('epoch: {}'.format(epoch), imgs, step)
step += 1
writer.close()
DataLoader的实现
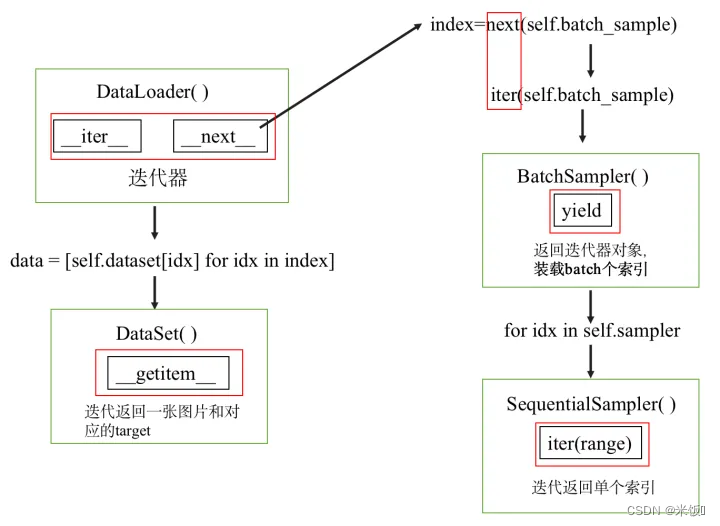
整体过程是,sampler规定抽取单个索引的方法,batchsampler调用sampler抽取batchsize个索引,
在dataloader的__next__中调用batchsampler取出batchsize个的索引所对应的图片和标签并返回
相当于dataloader根据dataset的getitem函数,按照batchsize大小进行分组,然后按组返回数据和标签。
具体细节可参考















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









