







随机森林算法详解
随机森林(Random Forest)是一种集成学习方法,通过构建多个决策树并将它们的预测结果结合起来,来提高模型的准确性和稳定性。随机森林在分类和回归任务中都表现出色,广泛应用于各类机器学习问题。本文将详细介绍随机森林的原理、特点、优缺点、常见应用场景以及示例代码。
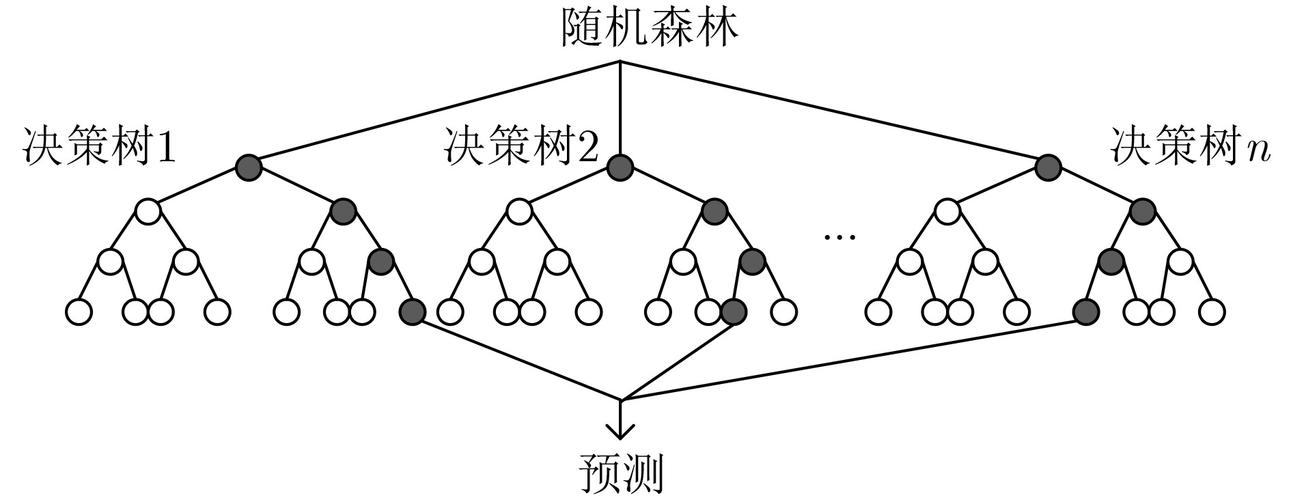
随机森林原理
随机森林的核心思想是通过构建多个决策树并将它们的预测结果结合起来,从而减少单个模型的过拟合,提高模型的泛化能力。其基本步骤如下:
- 样本采样:通过Bootstrap抽样方法,从原始训练集中有放回地随机抽取多个子集,每个子集用于训练一个决策树。
- 特征采样:在构建每个决策树时,对于每次分裂,只随机选择部分特征进行分裂选择,增加模型的多样性。
- 决策树训练:对于每个子集,构建一棵决策树。决策树的深度通常较大,不进行剪枝。
- 结果融合:对于分类问题,采用多数投票法将所有树的预测结果进行投票;对于回归问题,取所有树的预测平均值。
核心机制
- Bootstrap抽样:通过从原始数据集中有放回地抽样,生成多个不同的训练子集,确保每个决策树的训练数据不同。
- 随机特征选择:在每次分裂时随机选择部分特征,增加了树的差异性,降低了过拟合的风险。
- 多数投票与平均值:通过将多个决策树的结果进行融合,平滑了单个树的噪声,提高了模型的稳定性和准确性。
随机森林特点
优点
- 抗过拟合能力强:通过构建多个决策树并进行结果融合,随机森林有效降低了过拟合的风险。
- 处理高维数据:随机特征选择机制使得随机森林能够处理高维数据,尤其在特征数量远大于样本数量的情况下表现优异。
- 稳定性强:对训练数据的噪声和异常值不敏感,具有较高的鲁棒性。
- 易于并行化:每棵树可以独立训练,天然适合并行计算,训练速度较快。
- 特征重要性评估:能够评估各个特征的重要性,提供有用的特征选择信息。
缺点
- 计算资源消耗大:训练和预测过程中需要构建和存储大量决策树,对内存和计算资源要求较高。
- 模型解释性差:相比单棵决策树,随机森林的结果较难解释,不容易理解每个特征对结果的具体影响。
- 高维稀疏数据处理较差:在处理高维稀疏数据时,随机森林的表现可能不如线性模型和基于梯度的模型。
常见应用场景
随机森林适用于各种需要高准确性和稳定性的任务,包括但不限于:
- 分类任务:如文本分类、图像分类、医学诊断等。
- 回归任务:如房价预测、销售额预测、天气预报等。
- 特征选择:通过评估特征的重要性,帮助选择最有价值的特征,提高其他模型的性能。
- 异常检测:在金融、网络安全等领域,用于检测异常行为。
随机森林的参数详解
使用随机森林时,了解和调优其参数非常重要。以下是一些关键参数的详细介绍:
| 参数名称 | 含义 | 默认值 |
|---|---|---|
n_estimators |
森林中树的数量 | 100 |
max_features |
每次分裂时考虑的最大特征数 | ‘auto’ |
max_depth |
每棵树的最大深度 | None |
min_samples_split |
内部节点再划分所需最小样本数 | 2 |
min_samples_leaf |
叶子节点最少样本数 | 1 |
bootstrap |
是否使用Bootstrap抽样法 | True |
oob_score |
是否使用袋外样本评估模型 | False |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











