









基础语法
插入
INSERT INTO mytable(col1, col2)
VALUES(val1, val2);
插入检索出来的数据
INSERT INTO mytable1(col1, col2)
SELECT col1, col2
FROM mytable2;
将一个表的内容插入到一个新表
CREATE TABLE newtable AS
SELECT * FROM mytable;
更新
UPDATE mytable
SET col = val
WHERE id = 1;
删除
DELETE FROM mytable
WHERE id = 1;
TRUNCATE TABLE 可以清空表,也就是删除所有行
TRUNCATE TABLE mytable;
查询
DISTINCT
SELECT DISTINCT col1, col2
FROM mytable;
LIMIT
SELECT *
FROM mytable
LIMIT 5;
SELECT *
FROM mytable
LIMIT 0, 5;
返回第 3 ~ 5 行:
SELECT *
FROM mytable
LIMIT 2, 3;
排序
ASC : 升序(默认)
DESC : 降序
SELECT *
FROM mytable
ORDER BY col1 DESC, col2 ASC;
过滤
SELECT *
FROM mytable
WHERE col IS NULL;
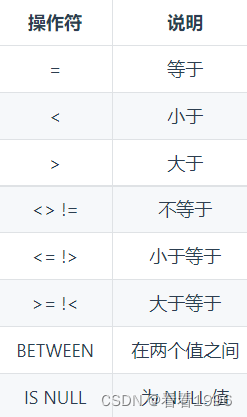
应该注意到,NULL 与 0、空字符串都不同。
AND 和 OR 用于连接多个过滤条件。优先处理 AND,当一个过滤表达式涉及到多个 AND 和 OR 时,可以使用 () 来决定优先级,使得优先级关系更清晰。
IN 操作符用于匹配一组值,其后也可以接一个 SELECT 子句,从而匹配子查询得到的一组值。
NOT 操作符用于否定一个条件
通配符
通配符也是用在过滤语句中,但它只能用于文本字段。
% 匹配 >=0 个任意字符;
_ 匹配 ==1 个任意字符;
[ ] 可以匹配集合内的字符,例如 [ab] 将匹配字符 a 或者 b。用脱字符 ^ 可以对其进行否定,也就是不匹配集合内的字符。
使用 Like 来进行通配符匹配。
SELECT *
FROM mytable
WHERE col LIKE '[^AB]%'; -- 不以 A 和 B 开头的任意文本
计算字段
SELECT col1 * col2 AS alias
FROM mytable;
CONCAT() 用于连接两个字段。许多数据库会使用空格把一个值填充为列宽,因此连接的结果会出现一些不必要的空格,使用 TRIM() 可以去除首尾空格。
SELECT CONCAT(TRIM(col1), '(', TRIM(col2), ')') AS concat_col
FROM mytable;
函数
汇总
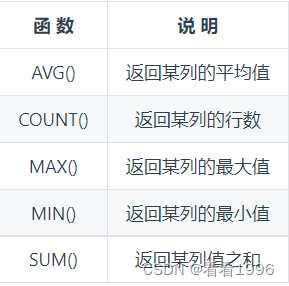
SELECT AVG(DISTINCT col1) AS avg_col
FROM mytable;
文本处理
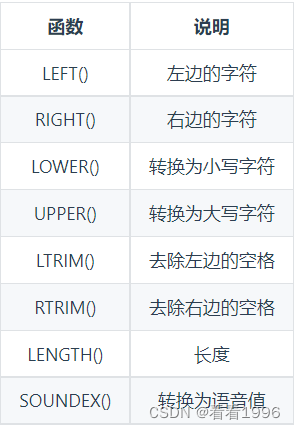
其中, SOUNDEX() 可以将一个字符串转换为描述其语音表示的字母数字模式
SELECT *
FROM mytable
WHERE SOUNDEX(col1) = SOUNDEX('apple')
日期和时间处理
日期格式: YYYY-MM-DD
时间格式: HH:MM:SS
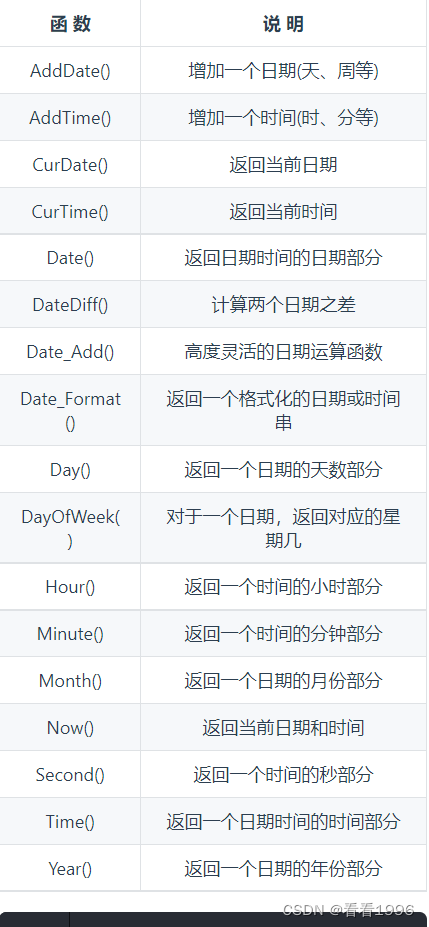
mysql> SELECT NOW();
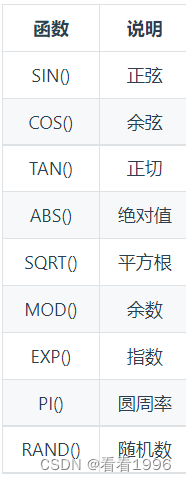
数值处理
分组
分组就是把具有相同的数据值的行放在同一组中。
可以对同一分组数据使用汇总函数进行处理,例如求分组数据的平均值等。
指定的分组字段除了能按该字段进行分组,也会自动按该字段进行排序。
GROUP BY 自动按分组字段进行排序,ORDER BY 也可以按汇总字段来进行排序。WHERE 过滤行,HAVING 过滤分组,行过滤应当先于分组过滤。
SELECT col, COUNT(*) AS num
FROM mytable
GROUP BY col
ORDER BY num
HAVING num >= 2;
分组规定:
- GROUP BY 子句出现在 WHERE 子句之2后,ORDER BY 子句之前;
- 除了汇总字段外,SELECT 语句中的每一字段都必须在 GROUP BY 子句中给出;
- NULL 的行会单独分为一组;
- 大多数 SQL 实现不支持 GROUP BY 列具有可变长度的数据类型。
子查询
SELECT *
FROM mytable1
WHERE col1 IN (SELECT col2
FROM mytable2);
链表查询
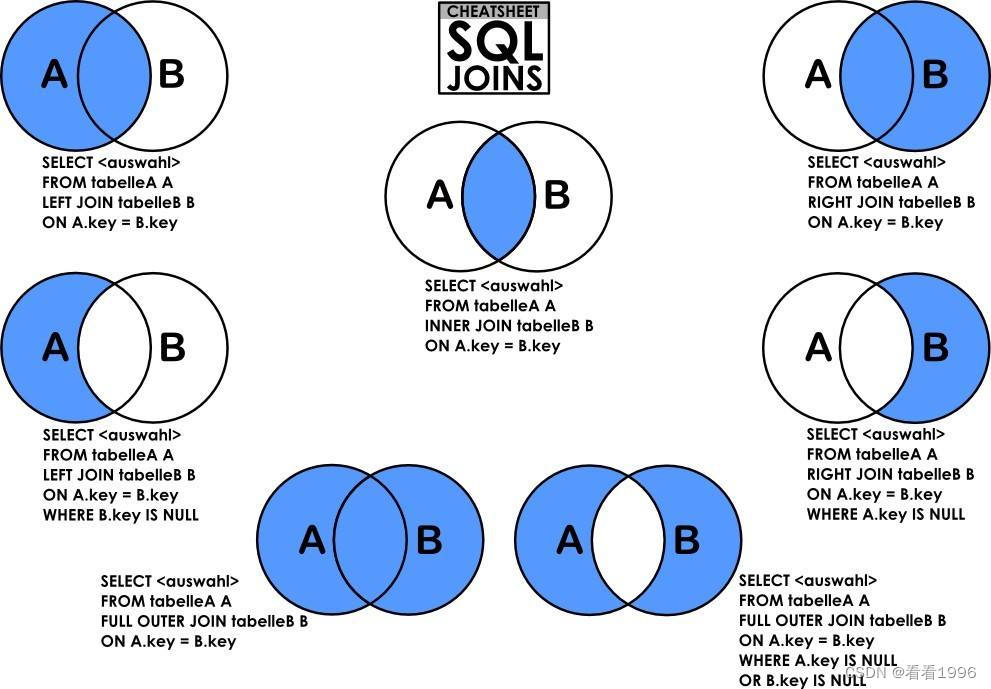
组合查询
使用 UNION 来组合两个查询,如果第一个查询返回 M 行,第二个查询返回 N 行,那么组合查询的结果一般为 M+N 行。
每个查询必须包含相同的列、表达式和聚集函数。
默认会去除相同行,如果需要保留相同行,使用 UNION ALL。
只能包含一个 ORDER BY 子句,并且必须位于语句的最后。
SELECT col
FROM mytable
WHERE col = 1
UNION
SELECT col
FROM mytable
WHERE col =2;
视图
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。
对视图的操作和对普通表的操作一样。
视图具有如下好处:
- 简化复杂的 SQL 操作,比如复杂的连接;
- 只使用实际表的一部分数据;
- 通过只给用户访问视图的权限,保证数据的安全性;
- 更改数据格式和表示。
CREATE VIEW myview AS
SELECT Concat(col1, col2) AS concat_col, col3*col4 AS compute_col
FROM mytable
WHERE col5 = val;
存储过程
存储过程可以看成是对一系列 SQL 操作的批处理。
使用存储过程的好处:
- 代码封装,保证了一定的安全性;
- 代码复用;
- 由于是预先编译,因此具有很高的性能。
命令行中创建存储过程需要自定义分隔符,因为命令行是以 ; 为结束符,而存储过程中也包含了分号,因此会错误把这部分分号当成是结束符,造成语法错误。
包含 in、out 和 inout 三种参数。
给变量赋值都需要用 select into 语句。
每次只能给一个变量赋值,不支持集合的操作。
游标
在存储过程中使用游标可以对一个结果集进行移动遍历。
游标主要用于交互式应用,其中用户需要对数据集中的任意行进行浏览和修改。
使用游标的四个步骤:
- 声明游标,这个过程没有实际检索出数据;
- 打开游标;
- 取出数据;
- 关闭游标;
触发器
触发器会在某个表执行以下语句时而自动执行: DELETE、INSERT、UPDATE。
触发器必须指定在语句执行之前还是之后自动执行,之前执行使用 BEFORE 关键字,之后执行使用 AFTER 关键字。BEFORE 用于数据验证和净化,AFTER 用于审计跟踪,将修改记录到另外一张表中。
INSERT 触发器包含一个名为 NEW 的虚拟表。
性能优化
优化数据访问
减少请求的数据量
- 尽量少用**select ***语句
- 返回必要的行数:使用limit语句限制返回的数据。
- 经常查询的数据要做缓存
减少服务器扫描的行数
最有效的方式是使用索引来覆盖查询。
重构查询方式
切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后将结果在应用程序中进行关联,这样做的好处有:
- 让缓存更高效。
- 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
- 减少锁竞争;
- 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
- 查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效
SELECT * FROM tab
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';
改成
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
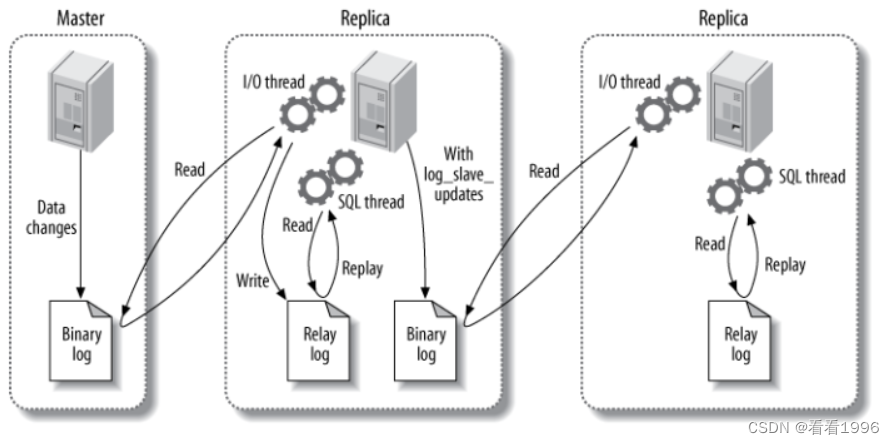
MySQL主从复制(读写分离)
主要涉及三个线程: binlog 线程、I/O 线程和 SQL 线程。
binlog 线程 : 负责将主服务器上的数据更改写入二进制日志中。
I/O 线程 : 负责从主服务器上读取二进制日志,并写入从服务器的中继日志中。
SQL 线程 : 负责读取中继日志并重放其中的 SQL 语句。
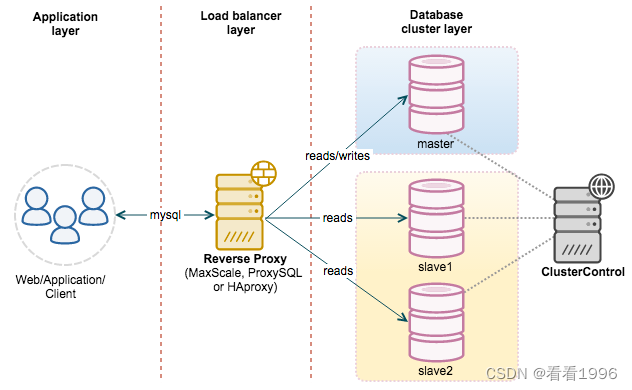
1、客户端访问代理服务器
2、代理服务器写入到主服务器
3、主服务器将增删改写入自己二进制日志
4、从服务器将主服务器的二进制日志同步至自己中继日志
5、从服务器重放中继日志到数据库中
6、客户端读,则代理服务器直接访问从服务器
7、降低负载,起到负载均衡作用
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
读写分离能提高性能的原因在于:
- 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
- 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
- 增加冗余,提高可用性。















 1793
1793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









