






该篇实现大众点评爬虫操作代码,所有原理都在(上)篇均已详细阐述,让我没想到的是大众点评不仅设置了CSS反爬,在ip限制方面也是十分的凶狠,不得已花了10块钱买了一天代理ip。

大众点评究的反爬竟有多恶心?
1.设置了ip限制
解决方法:花钱买代理获取接口
2.对计算机浏览器进行了识别,频率过高输入验证码
解决方法:网上找数十个User-Agent作随机切换
3.对Cookie 也进行了识别,到达阀值自动停止(这是真恶心)
解决方法:找了几个朋友进行登录获取Cookie作随机切换
拜托我就拿个论文数据你也太凶了吧,写了那么多的爬虫第一次差点被虐哭, 还是要不断学习的呀 ,代码如下,略长,包括读取代理ip的接口我也写在上面了,有需要的朋友尽快爬取,这烦人网站每几天就更新一次反爬呢!
from fontTools.ttLib import TTFont
from lxml import etree
import requests
import random
import time
import json
import csv
import os
import re
os.chdir("E:\\pythonwork\\大众点评")
user_agent = ['Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)']
headers = {
'User-Agent': random.choice(user_agent),
'Cookie':'_lxsdk_cuid=16fc3c57f39c8-0f56d131537ae6-b383f66-100200-16fc3c57f39c8; _lxsdk=16fc3c57f39c8-0f56d131537ae6-b383f66-100200-16fc3c57f39c8; _hc.v=14e8f7af-d069-6e77-9518-a77bcaec53c5.1579537498; s_ViewType=10; ctu=572330a0ea41badf8bf669a97c491bed041c6679a38dfa80b8fd11e69ffa9cab; aburl=1; __utma=205923334.2138749831.1584008233.1584008233.1584008233.1; __utmz=205923334.1584008233.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); looyu_id=c268fc6888d234def2c92f9c5710805232_51868%3A1; cy=224; cye=nanning; _dp.ac.v=c108f647-d852-413d-b71f-293d0ca87f9b; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; dplet=095342bde535b6cb0942b2ebee7d8242; dper=db7e2db9c4b21702e103cf5ed1b3b7fa79c223e47a8e89c36dbce62e8c28bfa6af42c434610d94e8f73cc176b4dd5ff4a322d1bb5739e5b08c3bdbb6130fa8fa77b3bdd99d8013e02c5bbf68393a0c406a9af94f0f6f410bf4c4766fd2350034; ll=7fd06e815b796be3df069dec7836c3df; ua=dpuser_4536684833; _lxsdk_s=170d36cde80-71f-c35-517%7C%7C97'
}
def get_font():
"""
解密数字
:return:
"""
font = TTFont('数字.woff')
font_names = font.getGlyphOrder()
# 这些文字就是在FontEditor软件打开字体文件后看到的文字名字
texts = ['','','1','2','3','4','5','6','7','8','9','0']
font_name = {}
# 将字体名字和它们所对应的乱码构成一个字典
for index,value in enumerate(texts):
a = font_names[index].replace('uni', '&#x').lower() + ";"
font_name[a] = value
return font_name
def get_comment_count(html):
"""
解析出:好中差评数
:param html: 大页的源代码
"""
global proxies
sole_urls = html.xpath("//div[@class='tit']/a[@data-hippo-type='shop']/@href")
good = []
middle = []
bad = []
for i in sole_urls:
sole_url = i +'/review_all'
requests.packages.urllib3.disable_warnings()
response = requests.get(sole_url, headers=headers,verify=False, proxies=random.choice(proxies)).text
# while True:
# try:
# response = requests.get(sole_url,headers=headers,proxies=random.choice(proxies)).text
# break
# except:
# time.sleep(1)
html_review = etree.HTML(response)
# 好中差评数
try:
good_count = int(html_review.xpath("//label[@class='filter-item filter-good']/span/text()")[0].split('(')[1].split(')')[0])
except:
good_count = 0
try:
middle_count = int(html_review.xpath("//label[@class='filter-item filter-middle']/span/text()")[0].split('(')[1].split(')')[0])
except:
middle_count = 0
try:
bad_count = int(html_review.xpath("//label[@class='filter-item filter-bad']/span/text()")[0].split('(')[1].split(')')[0])
except:
bad_count = 0
good.append(good_count)
middle.append(middle_count)
bad.append(bad_count)
time.sleep(4)
zero = 0
for i in good:
if i == 0:
zero += 1
if zero == 15:
print("===================== 注意!======================")
return good,middle,bad
def get_detail(big_url):
"""
解析出:店名、星级、人均价格、口味环境服务评分
:param big_url: 一页的url
"""
global proxies
business_detail = {}
business = []
requests.packages.urllib3.disable_warnings()
response = requests.get(big_url, headers=headers,verify=False, proxies=random.choice(proxies)).text
# while True:
# try:
# response = requests.get(big_url,headers=headers,proxies=random.choice(proxies)).text
# break
# except:
# time.sleep(1)
num = get_font() # 加载字体
# 替换加密数字
for key in num:
if key in response:
response = response.replace(key, str(num[key]))
html = etree.HTML(response)
good_middle_bad = get_comment_count(html)
good_count = good_middle_bad[0] # 列表
middle_count = good_middle_bad[1]
bad_count = good_middle_bad[2]
title = [] # 1店名
titles = html.xpath("//div[@class='tit']//h4/text()")
for t in titles:
title.append(t)
star = [] # 2星级评分
stars = html.xpath("//div[@class='nebula_star']//text()")
for i in stars:
linshi = re.findall(r'\b\d+\b', i)
if linshi:
star.append(linshi[0]+'.'+linshi[1])
taste_rating = [] # 3口味评分
environment_rating = [] # 4环境评分
service_rating = [] # 5服务评分
comment_rating = html.xpath("//span[@class='comment-list']//text()")
string = ''
for i in comment_rating:
string += i
string = string.strip().replace(' ','').replace('\n',';')
string_list = string.replace(';;',';').split(';')
for i in string_list:
if '口味' in i:
taste_rating.append(i.split('味')[1])
elif '环境' in i:
environment_rating.append(i.split('境')[1])
else :
service_rating.append(i.split('务')[1])
# 6人均价格
avg_string = ''
avg = []
rj = html.xpath("//a[@data-click-name='shop_avgprice_click']//text()")
for i in rj:
avg_string += i.replace('\n','').replace(' ','')
avg_list = avg_string.split('人均')
del avg_list[0]
for j in avg_list:
if j == '-':
avg.append('无人均价格')
else:
avg.append(j.split('¥')[1])
for q in range(15):
try:
business_detail['title'] = title[q]
business_detail['star'] = star[q]
business_detail['avg'] = avg[q]
business_detail['taste_rating'] = taste_rating[q]
business_detail['environment_rating'] = environment_rating[q]
business_detail['service_rating'] = service_rating[q]
business_detail['good_count'] = good_count[q]
business_detail['middle_count'] = middle_count[q]
business_detail['bad_count'] = bad_count[q]
except:
business_detail['title'] = '无'
business_detail['star'] = '无'
business_detail['avg'] = '无'
business_detail['taste_rating'] = '无'
business_detail['environment_rating'] = '无'
business_detail['service_rating'] = '无'
business_detail['good_count'] = '无'
business_detail['middle_count'] = '无'
business_detail['bad_count'] = '无'
business.append(business_detail.copy()) # 不加copy则是复制了字典的地址
for bus in business:
save(bus)
def save(big_information):
with open('BeiH.csv', 'a',newline='', encoding='utf-8-sig') as f:
fieldnames = ['title','star','avg','taste_rating','environment_rating','service_rating','good_count','middle_count','bad_count']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writerow(big_information)
def get_ip():
url = 'https://dev.kdlapi.com/api/getproxy/?orderid=918401564263990&num=100&protocol=1&method=2&an_an=1&an_ha=1&sep=%2C'
ip_str = requests.get(url, headers=headers).text
ultimate_ips = []
dic = {}
ips = ip_str.split(',')
for i in ips:
dic['https'] = i
ultimate_ips.append(dic.copy())
return ultimate_ips
if __name__ == '__main__':
global proxies
proxies = get_ip()
for i in range(1,31):
big_url = 'http://www.dianping.com/beihai/ch10/p{}'.format(i)
print(big_url)
get_detail(big_url)
time.sleep(1)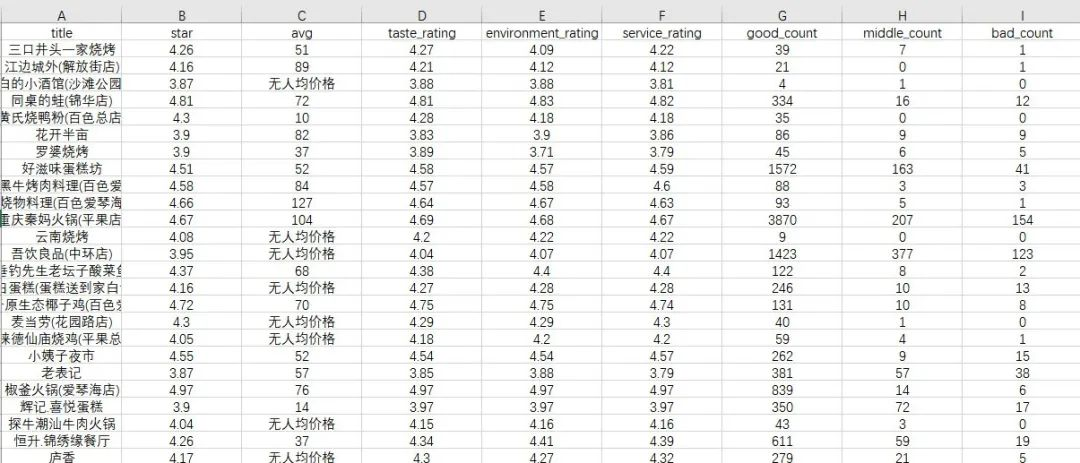
更多原创文章请关注我的公众号:DataUser
一枚数据分析的爱好者~


















 3173
3173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









