







一、背景
大众点评评论部分还是值得我们关注的,因为我们上点评网看的也就是评论,通过评论抓取分析,也有利于我们对店铺有更加清晰的定位
二、 抓取分析
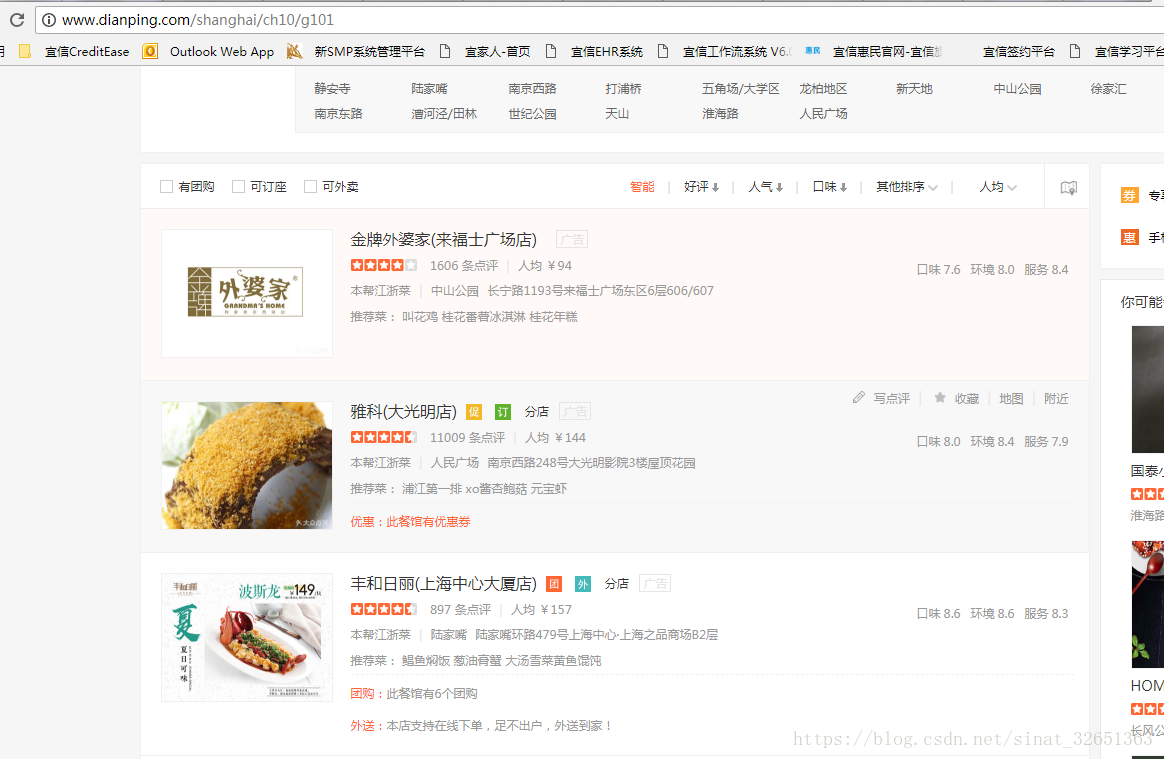
首先通过店铺列表页可以得到各家店铺的URL列表,或者店铺的ID,因为店铺详情页就是通过店铺ID做的相应拼接。如:http://www.dianping.com/shop/2972056/review_all/p; 第一个关键字就是店铺ID,第二个关键字为评论详情页,第三个P则为翻页。注意review_all是关键字。
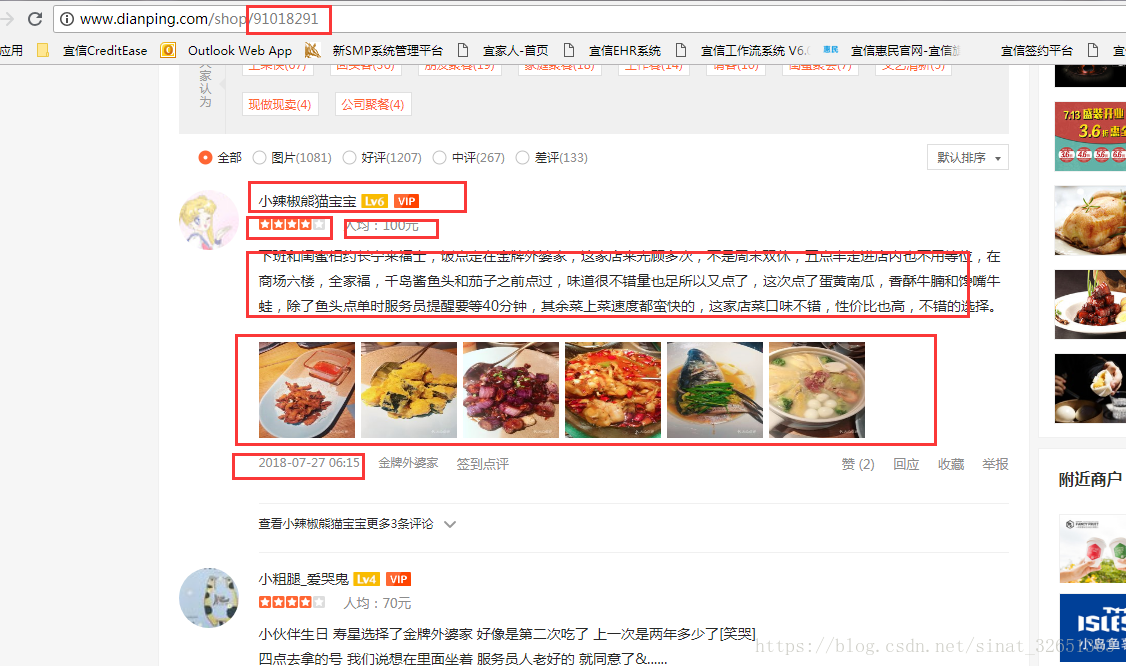
详情页我们抓取了用户名称,用户url链接,以及用户对店铺做的一些相应评价。
三、 数据抓取
该网站好多数据都通过Ajax请求传送,但这部分评论信息没找到,因此通过普通方式抓取,同时它的user-agent很特别,不能带cookie信息,也不能带Referer信息,否则不会给你返回值,但是做大量翻页抓取的时候要不断迭代改变Regerer,这样才不至于被反爬。
代码:
#! 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









