







 本文介绍了Kaggle上的信用评分数据集,详细讲述了数据预处理步骤,包括缺失值(如月收入和依赖人数)的处理,采用中位数和knn插值方法。在异常值处理部分,对可利用额度、年龄、债务和收入等变量进行了分析,删除或修正异常值。此外,进行了初步的探索性数据分析(EDA),分析了不同变量的分布和违约率,为后续模型建立奠定基础。
本文介绍了Kaggle上的信用评分数据集,详细讲述了数据预处理步骤,包括缺失值(如月收入和依赖人数)的处理,采用中位数和knn插值方法。在异常值处理部分,对可利用额度、年龄、债务和收入等变量进行了分析,删除或修正异常值。此外,进行了初步的探索性数据分析(EDA),分析了不同变量的分布和违约率,为后续模型建立奠定基础。
背景
信用评分算法,对默认可能性进行猜测,这是银行用来判断贷款是否应该被授予的方法,完成一个评分卡,通过预测某人在未来两年将会经历财务危机的可能性来提高信用评分的效果,帮助贷款人做出最好的决策
本项目主要为申请者评分模型的开发过程。
数据集介绍
数据来源:数据来自Kaggle,cs-training.csv是有15万条的样本数据,下图可以看到这份数据的大致情况。下载地址为:https://www.kaggle.com/c/GiveMeSomeCredit/data
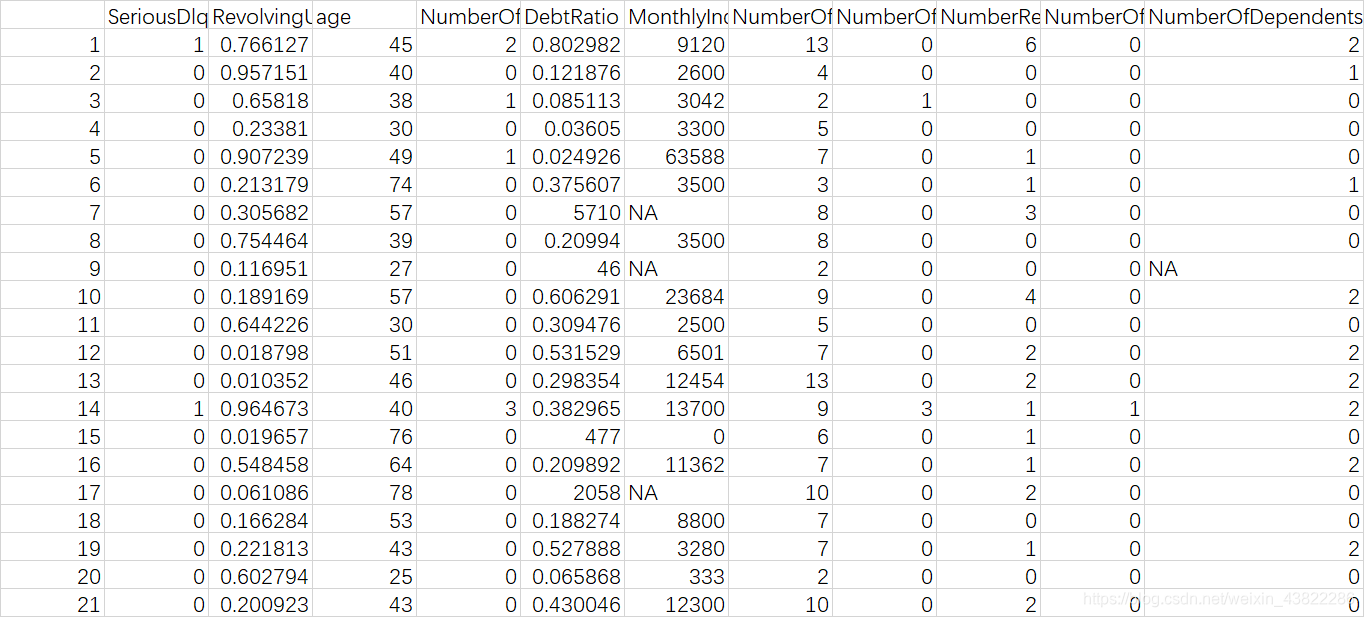
变量解释:
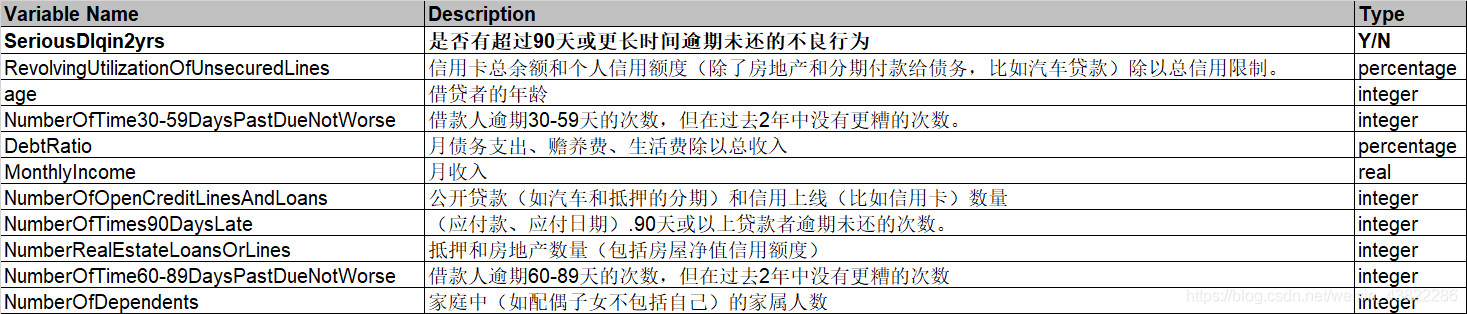
1.数据预处理
首先对数据作大致的了解和处理:
train<-read.csv("cs-training.csv",header=T,stringsAsFactors = F)
test<-read.csv("cs-test.csv",header=T,stringsAsFactors = F)
traindata <- traindata[,-1] #去除第一列序号
str(train)
'data.frame': 150000 obs. of 11 variables:
$ SeriousDlqin2yrs : int 1 0 0 0 0 0 0 0 0 0 ...
$ RevolvingUtilizationOfUnsecuredLines: num 0.766 0.957 0.658 0.234 0.907 ...
$ age : int 45 40 38 30 49 74 57 39 27 57 ...
$ NumberOfTime30.59DaysPastDueNotWorse: int 2 0 1 0 1 0 0 0 0 0 ...
$ DebtRatio : num 0.803 0.1219 0.0851 0.036 0.0249 ...
$ MonthlyIncome : int 9120 2600 3042 3300 63588 3500 NA 3500 NA 23684 ...
$ NumberOfOpenCreditLinesAndLoans : int 13 4 2 5 7 3 8 8 2 9 ...
$ NumberOfTimes90DaysLate : 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2847
2847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









