







public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> res = new ArrayList<>();
if (root != null) {
queue.offer(root);
}
List<Integer> list ;
while (!queue.isEmpty()) {
int size = queue.size(); //当前层,元素的数量
list = new ArrayList<>();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll(); //按顺序弹出队列元素,加入集合
list.add(node.val);
if (node.left != null) {
queue.offer(node.left); //当前元素的左子树入队,即把下一层的元素加入队列
}
if (node.right != null) {
queue.offer(node.right); //当前元素的右子树入队,即把下一层的元素加入队列
}
}
if (res.size() % 2 == 1) { //本题中奇数层要翻转下
Collections.reverse(list);
}
res.add(list);
}
return res;
}

import java.util.ArrayList;
import java.util.Arrays;
//leetcode submit region begin(Prohibit modification and deletion)
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
if (nums == null || nums.length <= 2){
return res;
}
Arrays.sort(nums);
if (nums[0] > 0) return res;//如果第一个数就大于0则返回
for (int i = 0; i < nums.length - 2; i++){
if (nums[i] > 0) break;
if (i > 0 && nums[i] == nums[i - 1]) continue;//相同的就跳过
int left = i + 1;
int right = nums.length - 1;
while (left < right){
if (nums[i] + nums[left] + nums[right] == 0) {
res.add(new ArrayList<>(Arrays.asList(nums[i], nums[left], nums[right])));
left++;
right--;
while (left < right && nums[left] == nums[left - 1]) left++;
while (left < right && nums[right] == nums[right + 1]) right--;
}else if (nums[i] + nums[left] + nums[right] < 0){
left++;
}else {
right--;
}
}
}
return res;
}
}
//leetcode submit region end(Prohibit modification and deletion)
二叉树的右视图:

import java.util.ArrayList;
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
List<Integer> res = new ArrayList<>();
public List<Integer> rightSideView(TreeNode root) {
dfs(root,1);
return res;
}
public void dfs(TreeNode root,int level){
if (root == null) return;
if (res.size() == level - 1){
res.add(root.val);
}
dfs(root.right,level + 1);
dfs(root.left,level + 1);
}
}
//leetcode submit region end(Prohibit modification and deletion)
主要是根据结果的个数来确定的,首先得从右边开始遍历,有数据则添加,那为什么右边有数据左边就不用再添加了呢?因为根据结果得个数来确定,当右边有数据得时候,对应的res.size() == level - 1,再添加左边的数据就不符合判断条件了,这个条件就是解决这个题目的关键。

class Solution {
public int trap(int[] height) {
if (height.length == 0) return 0;
int l_max = 0;
int r_max = 0;
int left = 0;
int res = 0;
int right = height.length - 1;
while (left < right){
l_max = Math.max(l_max, height[left]);//计算0-left中最大的值
r_max = Math.max(r_max, height[right]);//计算right-height.length中最大的值
// res+= min(l_max, r_max) - height[i]
if (l_max < r_max){
res += l_max - height[left];
left++;
}else {
res += r_max - height[right];
right--;
}
}
return res;
}
}
解说:比如如下代码:
if (l_max < r_max) {
ans += l_max - height[left];
left++;
}

此时的 l_max 是 left 指针左边的最高柱子,但是 r_max 并不一定是 left 指针右边最高的柱子,这真的可以得到正确答案吗?
其实这个问题要这么思考,我们只在乎 min(l_max, r_max)。对于上图的情况,我们已经知道 l_max < r_max 了,至于这个 r_max 是不是右边最大的,不重要,重要的是 height[i] 能够装的水只和 l_max 有关。

最长递增子序列










class Solution {
public int lengthOfLIS(int[] nums) {
int n = nums.length;
int[] dp = new int[n];
int res = 0;
Arrays.fill(dp,1);
for (int i = 0; i < n; i++){
for (int j = 0; j < i; j++){
if (nums[i] > nums[j]){
dp[i] = Math.max(dp[i],dp[j] + 1);
}
}
res = Math.max(res,dp[i]);
}
return res;
}
}

class Solution {
int max = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
max_gain(root);
return max;
}
public int max_gain(TreeNode root){
if (root == null) {
return 0;
}
// 递归计算左右子节点的最大贡献值
// 只有在最大贡献值大于 0 时,才会选取对应子节点
int left = Math.max(max_gain(root.left),0);
int right = Math.max(max_gain(root.right),0);
// 节点的最大路径和取决于该节点的值与该节点的左右子节点的最大贡献值
int nodeValue = left + right + root.val;
// 更新答案
max = Math.max(max,nodeValue);
// 返回节点的最大贡献值
return node.val + Math.max(left,right);
}
}

class Solution {
public void merge(int[] nums1, int m, int[] nums2, int n) {
int p = m - 1;
int q = n - 1;
int t = n + m - 1;
while (p >= 0 && q >= 0){
if (nums1[p] < nums2[q]){
nums1[t] = nums2[q];
t--;
q--;
}else {
nums1[t] = nums1[p];
t--;
p--;
}
}
while (q >= 0){
nums1[t--] = nums2[q--];
}
}
}
采用双指针的从后面比较填充,可以省略额外的空间。

解析:https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/solution/236-er-cha-shu-de-zui-jin-gong-gong-zu-xian-hou-xu/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null || root == p || root == q) return root;
TreeNode left = lowestCommonAncestor(root.left,p,q);
TreeNode right = lowestCommonAncestor(root.right,p,q);
if (left == null && right == null){
return null;
}
if (left == null) return right;
if (right == null) return left;
return root;
}
}

可以发现的是,我们将数组从中间分开成左右两部分的时候,一定有一部分的数组是有序的。拿示例来看,我们从 6 这个位置分开以后数组变成了 [4, 5, 6] 和 [7, 0, 1, 2] 两个部分,其中左边 [4, 5, 6] 这个部分的数组是有序的,其他也是如此。
这启示我们可以在常规二分搜索的时候查看当前 mid 为分割位置分割出来的两个部分 [l, mid] 和 [mid + 1, r] 哪个部分是有序的,并根据有序的那个部分确定我们该如何改变二分搜索的上下界,因为我们能够根据有序的那部分判断出 target 在不在这个部分:
如果 [l, mid - 1] 是有序数组,且 target 的大小满足 [\textit{nums}[l],\textit{nums}[mid])[nums[l],nums[mid]),则我们应该将搜索范围缩小至 [l, mid - 1],否则在 [mid + 1, r] 中寻找。
如果 [mid, r] 是有序数组,且 target 的大小满足 (\textit{nums}[mid+1],\textit{nums}[r]](nums[mid+1],nums[r]],则我们应该将搜索范围缩小至 [mid + 1, r],否则在 [l, mid - 1] 中寻找。
class Solution {
public int search(int[] nums, int target) {
if (nums.length == 0) return -1;
if (nums.length == 1) return nums[0] == target ? 0 : -1;
int left = 0;
int right = nums.length - 1;
while (left <= right){
int mid = left + (right - left) / 2;
if (nums[mid] == target){
return mid;
}
if (nums[left] <= nums[mid]){
if (nums[left] <= target && target <= nums[mid]){
right = mid - 1;
}else {
left = mid + 1;
}
}else {
if (nums[mid] <= target && target <= nums[right]){
left = mid + 1;
}else {
right = mid - 1;
}
}
}
return -1;
}
}

要点:搜索二叉树的中序遍历就是升序的。
*/
class Solution {
Stack<Integer> stack = new Stack<>();
public boolean isValidBST(TreeNode root) {
if (root == null) return true;
boolean left = isValidBST(root.left);
if (!stack.isEmpty()){
if (root.val <= stack.peek()){
return false;
}
}
stack.push(root.val);
boolean right = isValidBST(root.right);
return left && right;
}
}
具体实现也不复杂,我们定义两个指针 ii 和 jj 分别指向 \textit{num1}num1 和 \textit{num2}num2 的末尾,即最低位,同时定义一个变量 \textit{add}add 维护当前是否有进位,然后从末尾到开头逐位相加即可。你可能会想两个数字位数不同怎么处理,这里我们统一在指针当前下标处于负数的时候返回 00,等价于对位数较短的数字进行了补零操作,这样就可以除去两个数字位数不同情况的处理,具体可以看下面的代码。
class Solution {
public String addStrings(String num1, String num2) {
StringBuilder sb = new StringBuilder();
int i = num1.length() - 1;
int j = num2.length() - 1;
int add = 0;
while (i >= 0 || j >=0 || add != 0){
int a = i >= 0 ? num1.charAt(i) - '0': 0;
int b = j >= 0 ? num2.charAt(j) - '0': 0;
sb.append((a + b + add) % 10 + "");
add = (a + b + add) / 10;
i--;
j--;
}
return sb.reverse().toString();
}
}

当路径超出界限或者进入之前访问过的位置时,则顺时针旋转,进入下一个方向。
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
List<Integer> res = new ArrayList<>();
if(matrix == null || matrix.length == 0 || matrix[0].length == 0) return res;
int l = 0;
int r = matrix[0].length - 1;
int t = 0;
int b = matrix.length - 1;
// ++t :先给t加1,然后用t的新值
// t++ : 先用t的原值,然后t加1;
while (true){
for (int i = l; i <= r; i++){
res.add(matrix[t][i]);
}
if (++t > b) break;
for (int i = t; i <= b; i++){
res.add(matrix[i][r]);
}
if (--r < l) break;
for (int i = r; i >= l; i--){
res.add(matrix[b][i]);
}
if (--b < t) break;
for (int i = b; i >= t; i--){
res.add(matrix[i][l]);
}
if (++l > r) break;
}
return res;
}
}
//leetcode submit region end(Prohibit modification and deletion)

class Solution {
public ListNode swapPairs(ListNode head) {
ListNode h = new ListNode(-1);
h.next = head;
ListNode cur = h;
while (cur.next != null && cur.next.next != null){
ListNode l1 = cur.next;
ListNode l2 = cur.next.next;
ListNode next = l2.next;
l1.next = next;
l2.next = l1;
cur.next = l2;
cur = l1;
}
return h.next;
}
}

采用前序遍历
class Solution {
public void flatten(TreeNode root) {
List<TreeNode> list = new ArrayList<>();
preOrder(root, list);
for (int i = 1; i < list.size(); i++){
TreeNode pre = list.get(i - 1);
TreeNode cur = list.get(i);
pre.left = null;
pre.right = cur;
}
}
public void preOrder(TreeNode root, List<TreeNode> list){
if (root == null) return;
list.add(root);
preOrder(root.left,list);
preOrder(root.right,list);
}
}
//leetcode submit region end(Prohibit modification and deletion)


class Solution {
public int firstMissingPositive(int[] nums) {
int n = nums.length;
for (int i = 0; i < n; ++i) {
if (nums[i] <= 0) {
nums[i] = n + 1;
}
}
for (int i = 0; i < n; ++i) {
int num = Math.abs(nums[i]);
if (num <= n) {
nums[num - 1] = -Math.abs(nums[num - 1]);
}
}
for (int i = 0; i < n; ++i) {
if (nums[i] > 0) {
return i + 1;
}
}
return n + 1;
}
}

方法一:排序
思路
如果我们按照区间的左端点排序,那么在排完序的列表中,可以合并的区间一定是连续的。如下图所示,标记为蓝色、黄色和绿色的区间分别可以合并成一个大区间,它们在排完序的列表中是连续的:

class Solution {
public int[][] merge(int[][] intervals) {
List<int[]> res = new ArrayList<>();
if(intervals == null || intervals.length == 0) return res.toArray(new int[0][]);
Arrays.sort(intervals, (a, b) -> a[0] - b[0]);
int i = 0;
while (i < intervals.length){
int left = intervals[i][0];
int right = intervals[i][1];
while (i < intervals.length - 1 && intervals[i + 1][0] <= right){
i++;
right = Math.max(intervals[i][1], right);
}
res.add(new int[]{left, right});
i++;
}
return res.toArray(new int[0][]);
}
}


class Solution {
public int maxProfit(int[] prices) {
if (prices == null || prices.length == 0) return 0;
int max = 0;
for (int i = 1; i < prices.length; i++){
max += Math.max(0,prices[i] - prices[i - 1]);
}
return max;
}
}


class Solution {
public int findPeakElement(int[] nums) {
int left = 0;
int right = nums.length - 1;
while (left < right){
int mid = left + (right - left) / 2;
if (nums[mid] > nums[mid + 1]){
right = mid;
}else {
left = mid + 1;
}
}
return left;
}
}

回溯法
class Solution {
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
getRes(root, targetSum, new ArrayList<Integer>());
return res;
}
public void getRes(TreeNode root, int targetSum, List<Integer> list){
//节点为空直接返回
if (root == null) return;
list.add(root.val);
//到达叶子节点
if (root.left == null && root.right == null){
if (targetSum == root.val){
res.add(new ArrayList<>(list));
}
//注意别忘了把最后加入的结点值给移除掉,因为下一步直接return了,
//不会再走最后一行的remove了,所以这里在rerurn之前提前把最后
//一个结点的值给remove掉。
list.remove(list.size() - 1);
//到叶子节点之后直接返回,因为在往下就走不动了
return;
}
//如果没到达叶子节点,就继续从他的左右两个子节点往下找,注意到
//下一步的时候,sum值要减去当前节点的值
getRes(root.left, targetSum - root.val, list);
getRes(root.right, targetSum - root.val, list);
//我们要理解递归的本质,当递归往下传递的时候他最后还是会往回走,
//我们把这个值使用完之后还要把它给移除,这就是回溯
list.remove(list.size() - 1);
}
}

class Solution {
public boolean exist(char[][] board, String word) {
if(word == null || word.length() == 0 || board.length == 0 || board == null) return false;
int[][] tool = new int[board.length][board[0].length];
for (int i = 0; i < board.length; i++){
for (int j = 0; j < board[0].length; j++){
if (word.charAt(0) == board[i][j]){
if (helper(board,tool,i,j,word,0) == true){
return true;
}
}
}
}
return false;
}
public boolean helper(char[][] board, int[][] tool, int x, int y, String word, int z){
if (x >= board.length || y >= board[0].length || x < 0 || y < 0 || word.charAt(z) != board[x][y] || tool[x][y] == 1) return false;
if (z == word.length() - 1) return true;
tool[x][y] = 1;
boolean flag = helper(board,tool,x + 1,y,word,z + 1)
|| helper(board,tool,x - 1,y,word,z + 1)
|| helper(board,tool,x ,y + 1,word,z + 1)
|| helper(board,tool,x,y - 1,word,z + 1);
tool[x][y] = 0;
return flag;
}
}

二叉搜索树的中序遍历是升序序列,题目给定的数组是按照升序排序的有序数组,因此可以确保数组是二叉搜索树的中序遍历序列。
给定二叉搜索树的中序遍历,是否可以唯一地确定二叉搜索树?答案是否定的。如果没有要求二叉搜索树的高度平衡,则任何一个数字都可以作为二叉搜索树的根节点,因此可能的二叉搜索树有多个。

如果增加一个限制条件,即要求二叉搜索树的高度平衡,是否可以唯一地确定二叉搜索树?答案仍然是否定的。

直观地看,我们可以选择中间数字作为二叉搜索树的根节点,这样分给左右子树的数字个数相同或只相差 11,可以使得树保持平衡。如果数组长度是奇数,则根节点的选择是唯一的,如果数组长度是偶数,则可以选择中间位置左边的数字作为根节点或者选择中间位置右边的数字作为根节点,选择不同的数字作为根节点则创建的平衡二叉搜索树也是不同的。

确定平衡二叉搜索树的根节点之后,其余的数字分别位于平衡二叉搜索树的左子树和右子树中,左子树和右子树分别也是平衡二叉搜索树,因此可以通过递归的方式创建平衡二叉搜索树。
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return helper(nums, 0, nums.length - 1);
}
public TreeNode helper(int[] nums, int l, int r){
if (l > r) return null;
int mid = l + (r - l) / 2 ;
TreeNode root = new TreeNode(nums[mid]);
root.left = helper(nums, l, mid - 1);
root.right = helper(nums,mid + 1,r);
return root;
}
}

class Solution {
public int maxDepth(TreeNode root) {
if (root == null) return 0;
int left = maxDepth(root.left);
int right = maxDepth(root.right);
return Math.max(left,right) + 1;
}
}



在上面的递归树中,我们可以看到许多子问题被多次计算。例如, F(1)F(1) 被计算了 1313 次。为了避免重复的计算,我们将每个子问题的答案存在一个数组中进行记忆化,如果下次还要计算这个问题的值直接从数组中取出返回即可,这样能保证每个子问题最多只被计算一次。
public class Solution {
public int coinChange(int[] coins, int amount) {
int max = amount + 1;
int[] dp = new int[amount + 1];
Arrays.fill(dp, max);
dp[0] = 0;
for (int i = 1; i <= amount; i++) {
for (int j = 0; j < coins.length; j++) {
if (coins[j] <= i) {
dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);
}
}
}
return dp[amount] > amount ? -1 : dp[amount];
}
}


class Solution {
public int change(int amount, int[] coins) {
int[] dp = new int[amount + 1];
dp[0] = 1;
for (int coin : coins){
for (int j = coin; j <= amount; i++){
dp[j] += dp[j - coin];
}
}
return dp[amount];
}
}

class Solution {
int res = 0;
public int sumNumbers(TreeNode root) {
return dfs(root,0);
}
public int dfs(TreeNode root, int preSum){
if (root == null) return 0;
int sum = preSum * 10 + root.val;
if (root.left == null && root.right == null){
return sum;
}
return dfs(root.left,sum) + dfs(root.right,sum);
}
}

map存该层里面最先出现的index,后来找到该层的结点与最先出现的index的差值的最大值即可。
class Solution {
int max = 0;
Map<Integer,Integer> map = new HashMap<>();
public int widthOfBinaryTree(TreeNode root) {
dfs(root, 1, 1);
return max;
}
public void dfs(TreeNode root, int level, int index){
if (root == null) return;
if (!map.containsKey(level)){
map.put(level, index);
}
max = Math.max(max, index - map.get(level) + 1);
dfs(root.left, level + 1, index * 2);
dfs(root.right, level + 1, index * 2 + 1);
}
}

快慢指针

class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode ans = new ListNode(-1, head);
ListNode first = head;
ListNode second = ans;
for (int i = 1; i <= n; i++){
first = first.next;
}
while (first != null){
first = first.next;
second = second.next;
}
second.next = second.next.next;
return ans.next;
}
}

class Solution {
public ListNode deleteDuplicates(ListNode head) {
ListNode s = new ListNode(-1000000);
s.next = head;
ListNode l = s;
ListNode r = head;
while (r != null){
if (l.val == r.val){
while (r != null && l.val == r.val){
r = r.next;//非常注意,不需要r = r.next;因为下一个循环r就会自动向前走,否则只有【3 3】这种情况的时候,r下一次循环就是null了
}
l.next = r;
}else {
l = l.next;
r = r.next;
}
}
return s.next;
}
}

class Solution {
public void moveZeroes(int[] nums) {
for (int i = nums.length - 1; i >= 0; i--){
if (nums[i] == 0){
int index = i;
while (index + 1 < nums.length && nums[index + 1] != 0){
int tmp = nums[index + 1];
nums[index + 1] = nums[index];
nums[index] = tmp;
index++;
}
}
}
}
}

class Solution {
public String reverseWords(String s) {
s = s.trim();//除去开头和末尾的空格
String[] str = s.split(" ");//对字符串以空格进行分割
List<String> list = Arrays.asList(str);
Collections.reverse(list);
return String.join(" ", list);
}
}



题目分析
本题考察动态规划。经过分析可知:走n步到0的方案数=走n-1步到1的方案数+走n-1步到9的方案数。因此,如果设dp[n][i]为走n步到i的方案数,则动态规划的递推式为:
[公式]: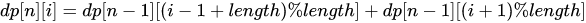
公式之所以取余是因为i-1或i+1可能会超过圆环0~9的范围
代码
public class Yuan {
public static int backToOrigin(int n){
int length = 10;
int[][] dp = new int[length + 1][length + 1];
dp[0][0] = 1;
for (int i = 1; i <= length; i++){
for (int j = 0; j < length; j++){
dp[i][j] = dp[i - 1][(j - 1 + length) % length] + dp[i - 1][(j + 1) % length];
}
}
return dp[n][0];
}
public static void main (String[] args) {
System.out.println(backToOrigin(2));
}
}

一个更简单的表示深度和位置的方法是:用 1 表示根节点,对于任意一个节点 v,它的左孩子为 2v 右孩子为 2v + 1。这就是我们用的规则,在这个规则下,一颗二叉树是完全二叉树当且仅当节点编号依次为 1, 2, 3, … 且没有间隙。
核心关键点:树的size 是否 等于 最后一个节点的indexCode!
class Solution {
int size = 0;
int maxIndex = 0;
public boolean isCompleteTree(TreeNode root) {
getRes(root, 1);
return size == maxIndex;
}
public void getRes(TreeNode root, int index){
if (root == null) return;
size++;
maxIndex = Math.max(maxIndex, index);
getRes(root.left,index * 2);
getRes(root.right,index * 2 + 1);
}
}

distance就是解题的关键
class Solution {
public String minWindow(String s, String t) {
if (s == null || s == "" || t == null || t == "" || s.length() < t.length()) return "";
int[] have = new int[128];
int[] need = new int[128];
int l = 0, r = 0, distance = 0, minLen = s.length() + 1, begin = 0;
for (char c : t.toCharArray()){
need[c]++;
}
while (r < s.length()){
char c = s.charAt(r);
if (need[c] == 0){
r++;
continue;
}
if (have[c] < need[c]){
distance++;
}
have[c]++;
r++;
while (distance == t.length()){
if (minLen > r - l){
minLen = r - l;
begin = l;
}
char d = s.charAt(l);
if (need[d] == 0){
l++;
continue;
}
if (have[d] == need[d]){
distance--;
}
have[d]--;
l++;
}
}
if (minLen == s.length() + 1) return "";
return s.substring(begin, begin + minLen);
}
}

解题的思路:尽量从低位找到最大数与高位的小数进行交换

class Solution {
public int maximumSwap(int num) {
char[] chars = Integer.toString(num).toCharArray();
int[] tmp = new int[chars.length];
int index = chars.length - 1;
tmp[index] = index;
for (int i = chars.length - 1; i >= 0; i--){
if (chars[i] > chars[index]){
index = i;
}
tmp[i] = index;
}
for (int i = 0; i < chars.length; i++){
if (chars[tmp[i]] != chars[i]){
char temp = chars[tmp[i]];
chars[tmp[i]] = chars[i];
chars[i] = temp;
break;
}
}
return Integer.parseInt(new String(chars));
}
}


class Solution {
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> combinationSum(int[] candidates, int target) {
List<Integer> tmp = new ArrayList<>();
dfs(candidates, target, tmp, 0);
return res;
}
public void dfs(int[] candidates, int target, List<Integer> tmp,int index){
if (index == candidates.length) return;
if (target == 0){
res.add(new ArrayList<>(tmp));
return;
}
dfs(candidates,target,tmp,index + 1);
if (target - candidates[index] >= 0){
tmp.add(candidates[index]);
dfs(candidates,target - candidates[index], tmp, index);
tmp.remove(tmp.size() - 1);
}
}
}


用HashMap来实现。
class Solution {
public Node copyRandomList(Node head) {
Map<Node,Node> map = new HashMap<>();
Node node = head;
while (node!=null){
map.put(node,new Node(node.val));
node=node.next;
}
Node q = new Node(-1);
q.next = head;
Node h = new Node(-1);
Node p = h;
while (q != null){
p.next = map.get(q.next);
p.random = map.get(q.random);
p = p.next;
q = q.next;
}
return h.next;
}
}

合并两条有序链表 — 递归,
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
ListNode res = null;
for (ListNode list : lists){
res = mergeTwoList(res, list);
}
return res;
}
//递归合并两个链表
public ListNode mergeTwoList(ListNode l1, ListNode l2){
if (l1 == null) return l2;
if (l2 == null) return l1;
if (l1.val < l2.val){
l1.next = mergeTwoList(l1.next, l2);
return l1;
}
l2.next = mergeTwoList(l1, l2.next);
return l2;
}
}


class Solution {
public void nextPermutation(int[] nums) {
int i = nums.length - 2;
while (i >= 0 && nums[i] >= nums[i + 1]){
i--;
}
if (i >= 0){
int j = nums.length - 1;
while (j >= 0 && nums[i] >= nums[j]){
j--;
}
swap(nums, i, j);
}
reverse(nums, i + 1);
}
public void reverse(int[] nums, int start){
int i = start, j = nums.length - 1;
while (i < j){
swap(nums, i, j);
i++;
j--;
}
}
public void swap(int[] nums, int i, int j){
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}

首先我们知道一条路径的长度为该路径经过的节点数减一,所以求直径(即求路径长度的最大值)等效于求路径经过节点数的最大值减一。
而任意一条路径均可以被看作由某个节点为起点,从其左儿子和右儿子向下遍历的路径拼接得到。

如图我们可以知道路径 [9, 4, 2, 5, 7, 8] 可以被看作以 22 为起点,从其左儿子向下遍历的路径 [2, 4, 9] 和从其右儿子向下遍历的路径 [2, 5, 7, 8] 拼接得到。
假设我们知道对于该节点的左儿子向下遍历经过最多的节点数 LL (即以左儿子为根的子树的深度) 和其右儿子向下遍历经过最多的节点数 RR (即以右儿子为根的子树的深度),那么以该节点为起点的路径经过节点数的最大值即为 L+R+1L+R+1 。
我们记节点 \textit{node}node 为起点的路径经过节点数的最大值为 d_{\textit{node}}d
node
,那么二叉树的直径就是所有节点 d_{\textit{node}}d
node
的最大值减一。
最后的算法流程为:我们定义一个递归函数 depth(node) 计算 d_{\textit{node}}d
node
,函数返回该节点为根的子树的深度。先递归调用左儿子和右儿子求得它们为根的子树的深度 LL 和 RR ,则该节点为根的子树的深度即为
max(L,R)+1
max(L,R)+1
该节点的 d_{\textit{node}}d
node
值为
L+R+1
L+R+1
递归搜索每个节点并设一个全局变量 ansans 记录 d_\textit{node}d
node的最大值,最后返回 ans-1 即为树的直径。
class Solution {
int ans = 0;
public int diameterOfBinaryTree(TreeNode root) {
depth(root);
return ans;
}
public int depth(TreeNode root){
if (root == null) return 0;
int left = depth(root.left);
int right = depth(root.right);
ans = Math.max(ans, left + right);
return Math.max(left, right) + 1;
}
}

/**
* 思路:
*
* (1)由大的随机数 生成小的随机数是方便的,如 rand10 -> rand7
* 只需要用 rand10 生成等概率的 1 ~ 10 ,然后判断生成的随机数 num ,如果 num <= 7 ,则返回即可
*
* (2)如何由小的随机数生成大的随机数呢?
* 考虑这样一个事实:
* randX() 生成的随机数范围是 [1...X]
* (randX - 1) * Y + randY() 可以等概率的生成的随机数范围是 [1, X*Y]
* 因此, 可以通过 (rand7 - 1) * 7 + rand7() 等概率的生成 [1...49]的随机数
* 我们可以选择在 [1...10] 范围内的随机数返回。
*
* (3)上面生成 [1...49] 而 我们需要 [1...10],[11...49]都要被过滤掉,效率有些低
* 可以通过减小过滤掉数的范围来提高效率。
* 比如我们保留 [1...40], 剩下 [41...49]
* 为什么保留 [1...40] 呢? 因为对于要生成 [1...10]的随机数,那么
* 可以等概率的转换为 1 + num % 10 , suject to num <= 40
* 因为 1 ... 40 可以等概率的映射到 [1...10]
* 那么如果生成的数在 41...49 怎么办呢?,这些数因为也是等概率的。
* 我们可以重新把 41 ... 49 通过 num - 40 映射到 1 ... 9,可以把 1...9 重新看成一个
* 通过 rand9 生成 rand10 的过程。
* (num - 40 - 1) * 7 + rand7() -> [1 ... 63]
* if(num <= 60) return num % 10 + 1;
*
* 类似的,[1...63] 可以 划分为 [1....60] and [61...63]
* [1...60] 可以通过 1 + num % 10 等概率映射到 [1...10]
* 而 [61...63] 又可以重新重复上述过程,先映射到 [1...3]
* 然后看作 rand3 生成 rand10
*
* (num - 60 - 1) * 7 + rand7() -> [1 ... 21]
* if( num <= 20) return num % 10 + 1;
*
* 注意:这个映射的范围需要根据 待生成随机数的大小而定的。
* 比如我要用 rand7 生成 rand9
* (rand7() - 1) * 7 + rand7() -> [1...49]
* 则等概率映射范围调整为 [1...45], 1 + num % 9
* if(num <= 45) return num % 9 + 1;
*/
class Solution extends SolBase {
public int rand10() {
while (true){
int num = (rand7() - 1) * 7 + rand7();
if (num <= 40) return num % 10 + 1;
num = (num - 40 - 1) * 7 + rand7();
if (num <= 60) return num % 10 + 1;
num = (num - 60 - 1) * 7 + rand7();
if (num <= 20) return num % 10 + 1;
}
}
}

class Solution {
public int numIslands(char[][] grid) {
int res = 0;
for (int i = 0; i < grid.length; i++){
for (int j = 0; j < grid[0].length; j++){
if (grid[i][j] == '1'){
res++;
getRes(grid, i, j);
}
}
}
return res;
}
public void getRes(char[][] grid, int x, int y){
if (x < 0 || y < 0 || x >= grid.length || y >= grid[0].length || grid[x][y] == '0') return;
grid[x][y] = '0';
getRes(grid ,x + 1, y);
getRes(grid ,x - 1, y);
getRes(grid ,x , y + 1);
getRes(grid ,x , y - 1);
}
}














 2244
2244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









