






目录
五、测试用例的设计步骤(功能用例、接口用例、性能用例,安全测试用例)
5.python+request+unittest分层测试自动化框架
十四、jenkins
一、软件测试基础与理论
1.什么是软件测试?
需求测试、界面测试、功能测试、安全性测试、可靠性测试、可移植性测试、兼容性测试、易用性测试、压力测试
2.常见基本术语
软件与硬件,pc机,物理机,便携机;OS、dos命令与图形化界面,共享,备份;文件与文件夹,目录与路径;客户机与服务器,浏览器与服务器;单机软件与共享软件,app;项目与项目需求,客户与客户需求,项目角色;(项目组成员、软件测试工程到师TE、测试组长TL、测试经理TPM)
3.为什么要测试?
1)软件的非正常运行或其自身的缺陷(BUG)会引发很多问题。
2)软件是由代码和文档组成的,而这些都是由“人”来设计和编写的,人都有可能犯错。
3)环境也会影响软件,以致出现软件"失效”现象。
4)软件测试活动只是关键的质量保证活动之一。
4.什么是测试?
·制造业的定义:“以检验产品是否满足需求为目标”
·软件行业的定义,有多种说法:a:验证软件的正确性 b:发现软件中的缺陷
·“发现软件测试中的缺陷”的3种观点:
1)测试是为了证明程序有错
2)一个好的测试用例:在于它能发现以前未发现的错误
3)一个成功的测试:能发现前所未有的错误的测试
5.软件生命周期概念?
·软件生命周期别称:软件生存周期或软件开发生命周期
·指的是软件从产生到报废的整个过程,是一种时间的概念。
·例:举一个生活的例子:一部手机的寿命
6.通常软件生命周期包括哪些阶段?
1)客户问题引入或定义
2)可行性分析(涉及经济(商业论证),政治,法律,技术等)
3)项目招投标
4)项目立项
5)需求分析
6)开发阶段(设计,编码,测试)
7)维护
7.典型的软件生命周期模型有哪些?
瀑布模型(waterfall)、V模型、W模型、H模型、敏捷开发模型、迭代开发模型、增量开发模型
瀑布模型

V模型
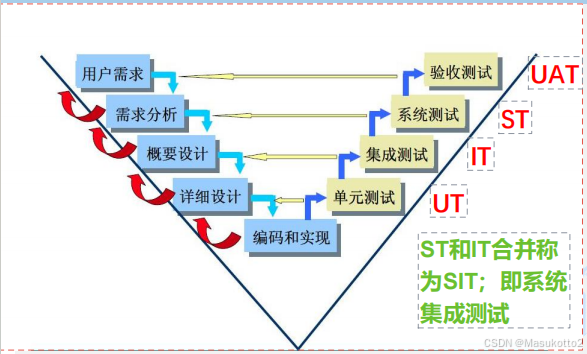
W模型
是V模型的补充,它贯穿整个软件产品周期,但是还是认为是串行的开发模式。
优点:
1.将测试贯穿到整个软件的生命周期中,且除了代码要测试,需求、设计等文档都要测试。
2.更早的介入到软件开发中,能尽早的发现缺陷,并进行修复。
3.测试与开发独立起来,并与开发并行。
缺点:
1.对有些项目,开发过程中根本没有文档产生,故W模型无法使用。
2.对于需求和设计的测试技术要求很高,实践起来很困难
H模型
在H模型中,软件测试过程活动完全独立,贯穿于整个产品的周期,与其他流程并发地进行,某个测试点准备就绪时,就可以从测试准备阶段进行到测试执行阶段;软件测试可以尽早的进行;软件测试可以根据被测物的不同而分层次进行。
敏捷开发模型
这是一种新的模型,前面的几种都是属于传统型。它能适应快速需求变化,交付周期短,轻量级的开发模式。
增量开发模型
项目被划分为一系列的增量,每一个增量都交付整个项目需求中的一部分功能。需求按优先级进行划分增量的交付。
迭代开发模型
项目被分为大量迭代过程,一次迭代就是一个完整的开发循环是一个可以发布的可执行的产品属于软件开发周期中最终产品的个子集。
8.测试的基本原则
- 1)测试的标准是用户需求
- 2)测试不仅仅是单纯的软件本身的测试
- 3)软件外在没有失效不代表软件系统是可用的
- 4)软件的完美度没有完全正确的,测试只能帮助软件更加完美,更加正确。
- 5)穷尽测试是不可能的(有些条件组合非常多,穷尽测试是不可能的)
- 6)测试应该尽早介入(早期引入的问题占到整问题数目的50%以上)
- 7)二八原则(80%的缺陷或错误会集中出现在20%的区域中)
- 8)杀虫剂效应(也就是说要不断更新用例,因为反复的执行相同的测试用例将会发现新缺陷的能力几乎为零)
- 9)测试活动依赖测试对象(测试的关注点不一样,有的更多关注安全和性能的测试)
- 10)尽量选择第三方测试(避免自己测试自己发的程序)
9.测试活动的生命周期
测试计划(测试准入)与控制 → 测试分析与设计 → 测试实现与执行 → 测试报告(测试准出) → 测试过程资产归档(测试总结)
10.测试分类
1)按开发阶段划分:1.单元测试 2.集成测试 3.系统测试 4.验收测试
2)按查看代码划分:
1.黑盒测试
定义:黑盒测试也是功能测试,测试中把被测试的软件当成一个黑盒子,不关心盒子的内部结构是什么,只关心软件的输入数据和输出数据
比如:计算器当作黑盒子:输入1+2=输出:3结果 就是对
2.白盒测试
白盒测试又称结构测试,透明测试,逻辑驱动测试,或基于代码测试。
白盒测试是指打开盒子去研究里面的源代码和程序结果
3.灰盒测试
灰盒测试是介于白盒测试和黑盒测试之间一种,灰盒测试多用于集成测试阶段,不仅关注输入,输出的正确性,同时也关注程序内部的情况。
3)按是否运行划分
1.静态测试
静态测试是指不运行被测程序本身,仅通过分析和检查源代码的语法,结构,来检查程序的正确性;(包括:需求,软件设计说明书等)
比如:灯泡不通电,检查
2.动态测试
动态测试:是指通过运行被测试程序,检查运行结果与预期结果的差异,并分析运行效率,正确性,健壮性等。
比如:灯泡通电,发光
4)按测试对象划分:1.功能性测试 2.性能测试 3.安全测试 4.兼容测试
5)按测试实施对象组织划分:1.alpha测试 2.beta测试 3.第三方(被调公司:)
6)按是否手工执行测试
1.手工测试:手工测试就是人一个个的执行用例,然后关注结果和测试用例相对应。
缺点:执行效率慢,量大容易出错
2.自动化测试:通过工具,或代码代替手工测试【ui自动化、接口自动化】
7)按测试区域划分
1.本地化测试(中国)
2.国际化测试:1.日期 2.金额 3.度量单位 4.语言 5.外观 ...等
11.用例设计(常用的方法):
1.等价类【重点】
指的是某个输入域的集合,在集合中各个输入的条件都是等效的。
通常等价类划分为2种情况:
- 有效等价类:对程序规格说明有意义的,合理的输入数据
- 无效等价类:对程序规格说明无意义的,不合理的输入数据
等价类划分的设计用例思路:
- 找输入条件
- 为每个输入条件找有效,无效等价类
- 为每个等价类编号
- 用最少的用例覆盖最多的有效等价类
- 每一个无效等价类都是一条单独的用例
- 并非所有的有效等价类都有无效【如:单选框:男 女 ===》必选项,有且只能选择一个】
- 等价类的覆盖是可以重复覆盖的
abc___ ===>1,2,4
ab12___ ===》1,2,3,4
等价类设计用例覆盖原则:
- 1.每个用例尽可能多的覆盖多个有效等价类
- 2.每个用例只能覆盖一个无效等价类
写用例的注意点:
- 1.用例以验证开头
- 2.验证标题需要和步骤内容相呼应
- 3.用例的标题需要和预期结果相呼应
- 4.等价类划分法用例设计方法的描述一般是用:大于,小于,在某某之间
- 5.用例标题不能重复
常见的能够划分等价类的地方:
1.数值范围
如:1-100分之内的数值
2.重复次数
如:银行卡密码输入超过5次就锁定
3.字符串长度
如:输入字符串长度为5
4.字符串中字符的个数
如:有一个列表有很多个字符串:["duoceshi","dcs46","hello"]
5.文件命名
如:用.txt结尾的都是有效等价类 .zip .tar .tar.gz
6.文件大小
如:上传1-200MB文件 有效:20mb 无效:201MB
7.屏幕的颜色
如:规定为,红色,黄色,绿色 其他颜色就是一个无效等价类
8.超时时间
一个程序超过30秒没有响应则报错
数据的合理性:
- 有效等价类:
123456
1234567891
abcdef
asdfghjklo
______ (6个下划线)
__________(10个下划线 )
abc123
123___
abc___
ab12__ - 无效等价类
1.从长度违反
12345 ==》小于6位
12345678911====》大于10位
abcde
aaaaaaaaaaa
_____
___________
2.从类型上违反
特殊字符:#¥%……&*()
中文字符:多测师第四十六
3.数据为空 ===》异常场景
等价类的优缺点:
优点:是考虑了单个输入域的各类情况,避免了盲目或随机选取输入数据的不完整性和覆盖的不稳定性。
缺点:方法虽然简单易用,但是没有对组合情况进行充分的考虑。需要结合其他测试用例设计的方法进行补充。比如边界值
2.边界值【重点】
边界点定义
上点:边界上的点
离点:离上点最近的点(即上点左右两边最邻近的点)
内点:在域范围内的点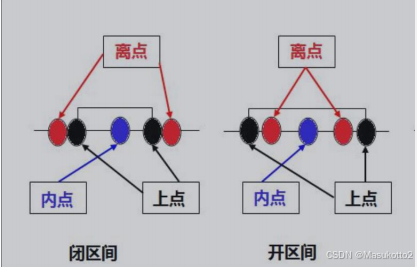
边界条件分析:
1.输入条件明确了二个值的取值范围或规定了值的个数
2.输入条件明确了一个有序集合
边界值分析原则:
1.如果输入(输出)条件规定了取值范围,则应该以该范围的边界内及边界附近的值作为测试用例
2.如果输入(输出)条件规定了值的个数,则用最大个数,最小个数,比最小个数少一,比最大个数多一的数作为测试数据
3.如果程序规格说明中提到的输入或输出是一个有序集合应该注意选取有序集合的第一个和最后一个元素作为测试数据
需求举例:
需求:在输入框中对考试成绩在1-100分之内进行打分并且为正整数
上点:1,100 正常场景
离点:0,101 异常场景
内点:区域内的点 88 正常场景
闭区间【1-100】
上点:1,100
离点:0,101
内点:88
开区间(1-100)
上点:2,99
离点:1,100
内点:55
半开半闭:(1-100】
上点:2,100
离点:1,101
内点:55
半闭半开【1-100)
上点:1,99
离点:0,100
内点:55
需求1:美团外卖3-8公里包邮
正常:3,8,6
异常:2,9
需求2:用户名是由11为纯数字字符的手机号组成===》10,11,12
边界值的描述:
验证在输入框输入11位纯数字字符组成的手机号码
验证在输入框输入10位纯数字字符组成的手机号码
验证在输入框输入12位纯数字字符组成的手机号码
等价类的描述:
验证在输入框输入小于11位纯数字字符组成的手机号码
验证在输入框输入大于11位纯数字字符组成的手机号码
验证在输入框输入等于11位纯数字字符组成的手机号码
档案管理:
上点:199001-204912 离点:199000-204903 内点:200001 201512
3.判定表【1-5】
判定表定义:分析和表达多逻辑条件下执行不同操作的情况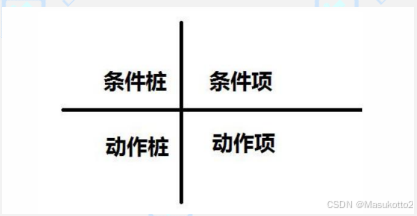
判定表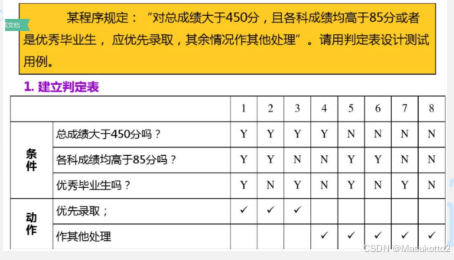
案例:
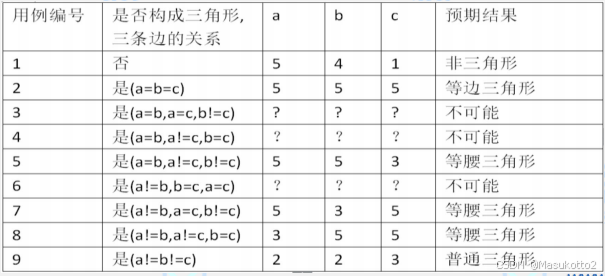
输入三个正整数a、b、c,分别作为三角形的三条边,通过程序判断三条边是否能构成三角形?如果能构成三角形,判断三角形的类型(等边三角形、等腰三角形、一般三角形)。
(1)条件桩
C1:a,b,c构成三角形?
C2:a=b?
C3:a=c?
C4:b=c?
(2)规则数
共有四个条件,每个条件的取值为“是”或“否”,因此有24=16条规则。
(3)动作桩
A1:非三角形;
A2:不等边三角形;
A3:等腰三角形;
A4:等边三角形;
A5:不可能;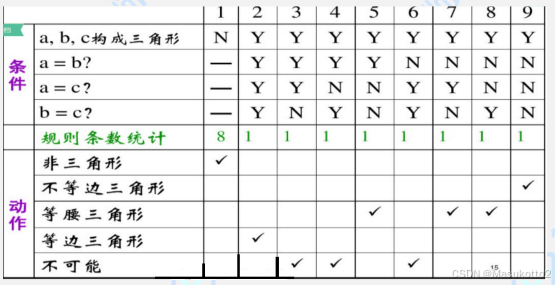
结构:由4个部分组成
1)条件桩(condition stub):列出问题的所有条件(通常条件次序无关紧要)
2)条件项(condition entry):列出针对它条件的取值(所有情况下的真假值)
3)动作桩(action stub):列出问题规定可采取的动作(顺序无约束)
4)动作项(action entry):列出条件各种情况的应采取的动作。
创建步骤:
1)确定规则的个数:若有N个条件,每个条件下有2个值,则有2^n种规则。
2)列出所有条件桩与动作桩。
3)输入条件项。
4)输入动作项得到初始判定表。
5)简化(合并相似规侧则)
6)编写测试用例
判定表的作用:
利用判定表将复杂的问题按照各种可能的情况全部列举出来,能针对不同逻辑条件的组合值,分别执行不同的操作。
4.因果图
因果图提供了一个把规格转化为判定表的系统化方法,从该图中可以产生测试数据。其中,原因是表示输入条件,结果是对输入执行的一系列计算后得到的输出。
因果图方法最终生成的就是判定表。它适合于检查软件输入条件的各种组合情况
因果图的基本符号
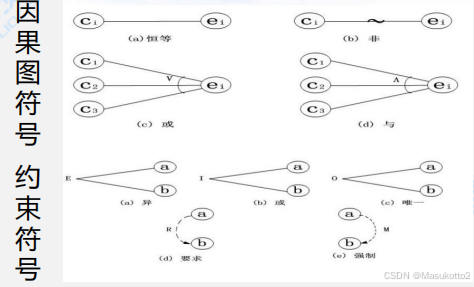
因果图的步骤:
1.把大的系统规格划分解成可以测试的规格片段
2.分析分解后待测的系统规格,找出哪些是原因哪些是结果
3.画出因果图
4.把因果图转换成判定表
5.简化判定表
6.用判定表中的每一列生成测试用例
因果图案例:
一个处理单价为5角钱的饮料的自动售货机。其规格说明如下:
若投入5角钱或1元钱的硬币,押下【橙汁】或【啤酒】的按钮,则相应的饮料就送出来。若售货机没有零钱找,则一个显示【零钱找完】的红灯亮,这时在投入1元硬币并押下按钮后,饮料不送出来而且1元硬币也退出来,若有零钱找,则显示【零钱找完】的红灯灭在送出饮料的同时退还5角硬币。
找出原因结果并进行编号: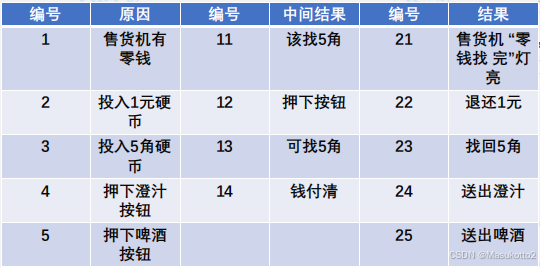
画出因果图: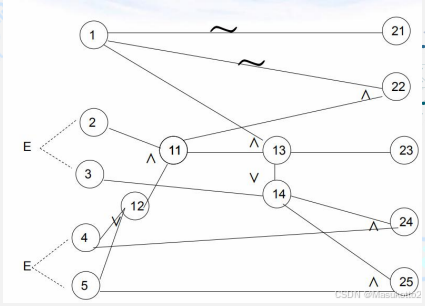
因果图转换判定表的方法:
1.将因果图中的所有条件(因)填入判定表的条件桩中;
2.将因果图中的所有动作(果)填入判定表的动作桩中;
3.根据因果图确定各个条件组合对应的动作,并且确定判定表中各个规则的条件项和动作项,在需要时优化判定表。
因果图中的约束
在实际问题中输入状态相互之间、输出状态相互之间可能存在某些依赖关系,称为"约束”。对于输入条件的约束有E、1、O、R四种约束,对于输出条件的约束只有M约束。
- 约束(异):a和b中最多有一个可能为1,即a和b不能同时为1。
- 约束(或):a、b、c中至少有、一个必须为1,即a、b、c不能同时为0。∅O约束(唯一):a和b必须有一个且仅有一个为1。
- R约束(要求):a是1时,b必须是1,即a为1时,b不能为0。
- M约束(强制):若结果a为1,则结果b强制为0。
因果图中的4种基本关系
在因果图的基本符号中,图中的左结点c表示输入状态(或称原因),右结点ei表示输出状态(或称结果)。ci与ei取值0或1,0表示某状态不出现,1则表示某状态出现。
恒等:若c1是1,则e1也为1,否则e1为0。
非:若c1是1,则e1为0,否则e1为1。
或:若c1或c2或c3是1,则e1为1,否则e1为0。
与:若c1和c2都是1,则e1为1,否则e1为0。
因果图的优点/缺点
优点:
1.等价类法尽管各个输入条件可能出错的情况都考虑到了,但是多个输入条件组合起来出错的情况却被忽略了
2.因果图法能够帮助我们按照一定步骤,高效的选择测试用,设计多个输入条件组合用例
3.因果图分析还能为我们指出,程序规格说明描述中存在什么问题
缺点:
1.输入条件与输出结果的因果关系,有时难以从软件需求规格说明书得到
2.即使得到了这些因果关系,也会因为因果关系复杂导致因果图非常庞大,测试用例数目及其庞大
5.正交表
6.场景法
7.状态迁移法
12.根据经验的测试技术方法
一、错误推测法
基于经验的测试技术之错误推测法
错误推测法也叫错误猜测法,就是根据经验猜想,已有的缺陷,测试经验和失败数据等可能有什么问题并依此设计测试用例.
二、异常分析法
基于经验的测试技术之异常分析法
系统异常分析法就是针对系统有可能存在的异常操作、软硬件缺陷引起的故障进行分析,依此设计测试用例。
主要针对系统的容错能力、故障恢复能力进行测试
比如:红米,华为 ,ios
三、随机测试
基于经验的测试技术之随机测试
随机测试指的是测试中的所有的输入数据都是随机生成的,其目标是模拟用户的操作。真实环境中,尤其是软件刚刚发布时,会有成千上万的人在上面乱敲乱试;
因此在发布软件前,用模拟用户的随机测试就可能发现其它方式漏掉的软件缺陷
总结:
10种方法:7种黑盒设计用例方法,3种基于经验的测试方法
7种:等价类、边界值、判定表、因果图、场景法、正交法、状态迁移法
3种:错误推测法、异常分析法、随机测试
作用:
等价类、边界值主要针对 单个功能测试设计 (账号)
判定表、因果图、正交法 多组合情况(比如:账号,密码、记住密码)
场景法:测试整个项目流程
状态法: 针对状态变更
四、使用各种测试方法思路(重点)
1.在任何情况下都必须使用边界值分析方法,经验表明用这种方法设计出测试用例发现程序错误的能力最强;
2.必要时用等价类划分方法补充一些测试用例;
3.用错误推测法再追加一些测试用例(依靠经验);
4.如果程序的功能说明中含有输入条件组合情况,则可选用因果图/判定表;
5.对业务流程场景清晰的系统,使用场景法贯穿;
6.检查已设计的测试用例的覆盖程度;
7.最后要考虑异常分析,再进行综合使用。
五、测试用例的设计步骤(功能用例、接口用例、性能用例,安全测试用例)
1.构造根据设计规格得出的基本功能测试用例
2.边界值测试用例
3.状态转换测试用例
4.错误猜测测试用例
5.异常测试用例
6.其它测试类型测试用例(如性能测试,易用测试,安全测试等)
六、优化测试用例的方法
利用设计测试用例的10种方法不断的对测试用例进行分解与合并
13.白盒测试方法
白盒测试技术
(1)白盒测试(结构测试或者逻辑驱动测试)
定义:白盒测试也叫透明盒测试,检查程序内部结构及路径一是否符合规格说明,二是否符合其代码规范。
(2)白盒测试常见方法:
a.语句覆盖;
b.判断覆盖(也称“分支覆盖”);
c. 条件覆盖;
d.判断、条件覆盖;
e.条件组合覆盖;
f.路径覆盖 (分为:z路径和独立路径)
(3)详解白盒测试方法:
1、语句覆盖:指设计若干个测试用例,使得程序运行时,每个可执行语句至少被执行一次
2、判断覆盖(分支覆盖):指设计若干个测试用例,使得程序运行时,每个判断条件的真假分支至少被执行一次
3、条件覆盖:指设计若干个测试用例,使得程序运行时,每个判断条件中的每个判断式的真、假值至被执行一次
4、判断、条件覆盖:指设计若干个测试用例,使得程序运行时,每个判断条件中真、假值分支至少被执行一次,且每个判断条件的内部判断式的真、假值至少被执行一次。
5、条件组合覆盖:指设计若干个测试用例,使得程序运行时,每个判断条件的内部判断式的各种真假组合都至少被执行一次;是逻辑覆盖测试中“覆盖能力”最强的。
6、路径覆盖:
1)旨在保证程序中每一个特定的路径方案都能正常运行。
常见的路径覆盖方法:2种
A:独立路径覆盖
定义:即覆盖所有的独立路径的测试,所谓独立路径应至少包含一条在其它路径中从未有过的边。
B:Z路径覆盖
是一种将实际项目中复杂的程序减少其循环次数的路径覆盖方法,即:不考虑循环体实际需要执行多少次,只考虑通过循环体0次和1次这两种情况。
0次循环:直接跳过循环体,从循环体入口直接到出口
1次循环:通过一次循环体即可
备注: &&(短路与), ||(短路或),
(4)白盒测试方法的优点:
1.深入程序内部,测试粒度较细。
2.是测试用例设计方法的组成部分,也是黑盒测试方法的有力补充。
3.为自动化测试与性能测试奠定基础。
(5)白盒测试方法的缺点:
1.过分关注代码本身,容易偏离SRS实际需求
2.对相应的编程语言要求较高,人力成本较大
针对用例设计方法小结:黑盒测试+白盒测试+基于经验的测试
14.测试用例要素
用例编号,用例标题,前置条件,测试步骤,预期结果,优先级 (必写)
系统名称、模块名称、用例创建时间,实际结果,用例类型,执行时间,执行状态等(非必填项)
- 用例编号
可以称为:用例id,测试编号,编号等
(1)系统命名_模块名称_编号 (一般情况系统和模块名称是大写,间隔用 __ 下滑线)(2)公司中的用例编号根据公司规定
-
用例标题
又称为:测试内容,测试名称,测试标题等
用例标题:描述用例验证什么
注意事项:
1、用例标题是永远唯一的,不存在两条相同的用例
案例:
a.验证微信发送红包失败(零钱余额不足)
b.验证微信发送红包失败(无网络)
c.验证微信发送红包失败(密码错误)
2、标题描述,简单,易懂,清晰
3、标题能加上“验证”尽量加上验证
4、用例标题和预期结果相呼应
5、用例标题要写清楚验证的点
6、用例标题是陈述句,不能用判断句或者选择范围,用是否,不能写疑问句
7、不能把bug 写成测试用例
8、一个无效等价类就是一条用例,不能多个无效等价类写成一条用例 - 优先级
优先级有三个级别:
高:核心功能测试用例(冒烟测试用例),会阻碍大部分其他测试的用例,基本功能测试
举例:
死机,白屏,卡顿,闪退,
中:异常测试,边界,中断,弱网
举例:删位置,除,返回,取消,刷新,更新,翻页等
低:字体,颜色,色差,易用性等
举例:ui样式、颜色,大小,排版
场景设法设计的用例,基本流, 高级用例
场景法设计的用例,备选流,中级用例
因果图设计的用例,有效用例,选一条为高级,其他的为中级
等级类和错误推测法, 设计的有效用例 中级
等价类和错误推测法,设计的无效用例 低级用例优先级对应我们bug等级:
致命bug(1级bug)
严重bug(2级bug)
一般bug(3级bug)
建议性bug(4级bug) - 前置条件:执行操作之前的准备工作
案例:
1、准备两台手机,
2、两个微信账号
3、银行卡,余额充足
4、已连接网络 - 测试步骤
测试步骤:验证“测试标题”的具体步骤
(1)测试的流程步骤按序号编写:1,2,3,4,5 换行(alt+回车 换行)
(2)测试步骤的开头都是动词
(3)测试步骤一般不超过8个步骤(简化步骤)【前期动作可以写在整体的一句话上】
(4)不能把上一个用例的步骤,用来做下一个步骤的前置条件(每一条用例都是独立) - 预期结果
预期结果:达到预期的目标
(1)预期结果要详细
(2)预期结果要注意隐藏结果
(3)页面跳转
(4)订单状态的变更
(5)预期结果,不能只写成功,失败
(6)页面提示,提示语
(7)结果涉及到页面提示,数据变化,必须明确说明提示内容和变化内容
(8)结果涉及到数据需要明确数据库中的表和字段的变化。
---------------------------------------------------------------------------------------------------------------------------------
可靠性测试:能否在规定的时间内完成规定的事情
可用性测试:只要事情能够完成就行,不需要考虑时间的问题(可用包含可靠)
可移植性测试:不同的环境下能否正常使用
兼容性测试:
- 不同的操作系统:android ios 鸿蒙 windows macos linux
- 不同的系统版本:ios 17 16 15 14 android 13 12 11
- 不同的机型兼容:流海屏 曲面屏 挖孔屏幕
- 不同的手机厂商的机型兼容:华为 小米 oppo vivo iphone15 14 13 8
- 浏览器的兼容:chrome safari firefox EDGE IE
易用性测试:站在用户使用体验感上的测试
性能测试:
- 压力测试:有个人举重,100斤是临界值,从一个较小的压力开始不断的增加压力,看这究竟能举到多少斤
- 负载测试:有个人举重,100斤是临界值,就举100斤,看能举多长时间
pc机:个人电脑
物理机:高配置的计算机(服务器)
便携机:方便携带的高配置计算机
OS:操作系统
dos命令: win+r 窗口上输入cmd,按下enter键,进入dos命令行操作页面
软件的基础架构:客户机 ---- 服务器、Client -----Server
·C/S架构的软件
优点:方便携带,安全性高,上传下载速度快
缺点:消耗手机内存,安装比较麻烦,维护比较麻烦
采用C/S架构的软件:京东,淘宝,抖音,微信
·浏览器 —— 服务器
Browser —— Server
B/S架构的软件
优点:不用下载,资源比较多,维护比较方便
缺点:安全性不高,不方便携带,上传下载速度较慢
采用B/S架构的软件:京东,淘宝,4399小游戏,官方网站
开发环境:给到开发人员使用的环境,编写代码和调试代码使用
测试环境:给到测试人员使用的环境,在测试环境上进行sit系统集成测试
预生产环境:一般给到产品进行验收测试的环境
生产环境:也可以称之为线上环境,又可以称之为真实环境,是给到普通用户使用的环境
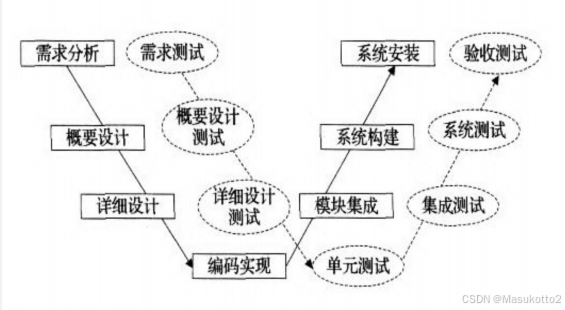
V模型:项目的阶段(项目开展的过程中需要经历的阶段)
准入 准出
需求分析阶段 产品输出需求文档 需求规格说明书(SRS)
概要设计阶段(HLD) 根据SRS编写概要设计 概要设计说明书
详细设计阶段(LLD) 根据概设编写详细设计 详细设计说明书
编码阶段 根据详设编写项目代码 项目的代码包(.war .jar .zip)
单元测试阶段 开发对代码包进行自测 单元测试报告
系统集成测试阶段 测试对项目进行测试 系统集成测试报告
验收测试阶段 产品/客户对项目进行验收测试 验收测试报告
验收测试分2轮验收:
1、α(阿尔法)验收:产品经理模拟用户的行为对软件进行验收测试,这个时候是有开发人员和测试人员在场的,如果发现了bug,可以直接提交给到开发人员进行修复
2、β(贝塔)验收:软件已经交付给到客户手中,由客户进行验收测试,如果发现了bug,由客户统一收集所有的bug,然后以邮件的形式发送给到当前项目组中与之相关的同事,然后开发进行修复并跟进
H模型:项目的流程
- 基线化文档:表示当前这个文档的状态已经终结,随时进入到下一个阶段
- TC:Test Case 测试用例
用例评审:
- 交叉评审:测试组内对用例进行评审
- 组内评审:项目组内(项目经理,产品经理,开发,测试)对用例进行评审
- 会议评审:会有客户参与的评审
testlink:用例管理工具
禅道:项目管理工具(可以用来管理测试用例)
提测(转测):开发将代码包提交给到测试人员
冒烟测试:对软件的主体功能进行测试
项目与产品的区别 ===》 先有项目,再有产品
项目与版本的区别 ===》先有项目,再有版本
---------------------------------------------------------------------------------------------------------------------------------
面试题:
1.一条测试用例包含哪些内容?
2.常用的用例设计方法有哪些?
3.结合你的项目及测试用例讲一下测试点
4.给你一个xxxx(路灯,小汽车,给你一个app)你说一下测试点
5.如何保证用例的覆盖率?1.评审好需求,按照需求梳理测试点,按照测试点编写测试用例,已经及时的进行用例的评审
在公司中-====》拿到需求文档===》提炼测试点===》根据测试点写用例
什么地方可以写成用例:
一个状态的变更
一个页面的跳转
页面的变化
作业:
1.众安保险编写35条用例
2.微信发朋友圈的测试点==》40条 ==》测试点中会包含“是否”
- 例子1:
- 在微信朋友圈界面进行下拉操作是否可以刷新朋友圈
- 在微信朋友圈点击封面图是否会出现换封面
- 点击朋友圈朋友的头像是否会跳转到朋友的详情信息界面
3.支付宝支付功能的测试点写25条
- 例子1:
- 在支付宝首页 点击扫一扫是否会进入到扫描二维码界面
二、Linux
1.Linux常用目录
- home目录:普通用户家目录
- root目录:管理员家目录
- usr/八local目录:用户自行安装的软件存放路径
- etc目录:配置文件存放路径
- var目录:存放经常变化的文件
2.Linux常用命令
用户切换:su + 用户名称
普通用户->管理员:su root
普通->超级管理员:su ivan
查看IP地址:ifconfig
查看当前目录下的文件和目录命令:ls
查看目录下的文件和目录详情:ls -l
查看目录下所有文件和目录(包含隐藏文件):ls -a
进入一个目录:cd
进入根目录:cd /
进入指定目录:cd dir
进入当前目录下:cd ./
进入上一级目录:cd ..
进入home目录:cd ~
创建空文件:touch file
创建空目录:mkdir dir
递归创建空目录:mkdir -p
复制文件:cp + 原文名称 +新文件名称 eg.cp file1 file2
复制目录:cp -r + 原目录 + 新目录
移动文件:mv + 移动的文件 + 移动后的路径 eg.mv file1 ./dir1
文件重命名:mv + 原文件名称 + 新文件名称 eg.mv file1 file2
cp命令:
cp bb.txt cc.txt ===》复制粘贴bb.txt文件并改名为cc.txt
cp -r aa bb ===》复制粘贴aa目录并改名为bb目录 (bb目录不存在)
cp -r aa bb ===》复制粘贴aa目录到bb目录下面 (bb目录存在)mv命令:当目标目录不存在时,mv命令是改名,当目标目录存在时,则是移动
mv cc.txt aa ===》将cc.txt文件移动到当前目录下的aa目录中
mv cc.txt bb.txt ===>当bb.txt文件不存在时,mv命令是将cc.txt文件改名为bb.txt
查看文件:cat + 文件名称 eg.cat file1
cat命令:
cat + 文件名 ===》查看文件内容
cat -n aa.txt ====》带行号显示文件内容 n代表的number
cat aa.txt |grep "duoceshi" ==》| 代表的是管道符,管道符左边的输出等于右边的输入,
grep ===》关键词搜索,对于文件和文本的处理
less aa.txt ===》查看文件内容 文字内容比较多时,按下空格键进行翻页,ctrl+z退出查看页面
more /head_tail.txt ===》百分比查看文件的内容
nl aa.txt ===》带行号显示文件内容
文件翻页:less + 文件名称 more + 文件名称
重定向符号:
1. > 覆盖 eg.cat file1 > file2 把file1文件中的内容覆盖到file2
2. >> 追加 eg.cat file1 >> file2 把file1文件中的内容追加到file2文件末尾
当目标文件不存在的时候:
> 一个重定向
cat aa.txt > bb.txt ===》当目标文件不存在的情况下,会新建一个文件并且把源文件内容复制到目标文件中
>> 两个重定向
cat aa.txt >> cc.txt ===》当目标文件不存在的情况下,会新建一个文件并且把源文件内容复制到目标文件中
当目标文件存在的时候
> 一个重定向
cat aa.txt > qq.txt ===》当目标文件存在的情况下,会将目标文件的内容覆盖>> 两个重定向
cat aa.txt >> ww.txt ===》当目标文件存在的情况下,会将源文件的内容追加到目标文件的内容后面
查看文件前指定行的数据:head + 文件名称【默认查看前十行数据】
指定行数,查看数据:-n eg.head -n 5 file1
查看文件末尾指定行数数据:tail + 文件名称【默认查看文件末尾十行数据】
指定行数,查看文件末尾的数据:-n eg.tail -n 5 file1
通过文件/目录名称查找绝对路径:find / -name 文件名/目录名
eg.从home目录下查找:find /home -name file1
head和tail命令
head head_tail.txt ===》默认查看文件的前十行内容
tail head_tail.txt ===》默认查看文件的后十行内容
tail -f +文件名 ===》实时查看文件内容 ===》面试题:怎么实时查看日志? tail -f +文件名
head -n +5 head_tail.txt =====>查看前5行内容
head -n -5 head_tail.txt ===》后五行不看
tail -n +5 head_tail.txt ===》从第五行开始查看
tail -n -5 head_tail.txt ===》查看后五行内容tail -n +5 head_tail.txt | head -n 6 ===>查看5-10行的内容
head head_tail.txt | tail -n 6 ===>查看5-10行的内容
搜索字符命令:grep + 字符串
【ps】常和cat命令组合使用: cat file1 | grep "字符串"
grep:
grep -A 2 "15" head_tail.txt ===》-A after 在什么什么之后 搜索出文件中带有关键字“15”的后两行内容
grep -B 2 "15" head_tail.txt ===》-B before before 在什么什么之前 搜索出文件中带有关键字“15”的前两行内容
grep -C 2 "15" head_tail.txt ===》-C center 中心 搜索出文件中带有关键字“15”前后两行的内容
修改文件/目录的权限:chmod eg.chmod + 755 + 文件名称
r:读权限,用数字4表示
w:写权限,用数字2表示
X:执行权限,用数字1表示
总共有10位
第1位"-"代表这是一个文件
前3位,代表着用户主拥有的权限
中3位,代表着用户组拥有的权限
后3位,代表着其他人拥有的权限,
chmod :改变权限
chown:改变文件的或者目录的属主 (owner 主)
chgrp:改变文件或者目录的数组 (group 组)
-rw-r--r--. 1 root root 45 Aug 18 23:30 aa.txt
- 代表文件
r 代表的是read 读 权限为4
w 代表的是write 写 权限为2
x 代表的是excute 执行 权限为1
前三位rwx:代表的是属主的权限 u (user)
中间三位rwx:代表的是属组的权限 g (group)
后面三位rwx:代表的是其他用户的权限 o (other)上面的解释:
属主(文件的创建者)对aa.txt文件具有读写执行的权限,属组对aa.txt文件只有读的权限,既不是属主也不是属组的其他用户对aa.txt文件只有读的权限
对文件改变权限:
chmod 777 aa.txt ===》改变aa.txt文件的权限,属主,属组和其他用户对aa.txt文件都具有读写执行的权限
对目录改变权限:
chmod -R 777 dcs46 ===》改变目录的权限,属主,属组和其他用户对dcs46目录都具有读写执行的权限(目录里面的目录和文件对应的权限都会改变)
r :cat less more nl head tail
w:vim touch
x:sh bash
权限的设置只对普通用户生效chown dcs46 aa.txt ===》将aa.txt文件的属主改变为dcs46这个用户
chgrp dcs46 aa.txt ====》将aa.txt文件的属组改变为dcs46这个用户
chown root.root aa.txt ===》把aa.txt文件的属主和属组改为root用户
chown dcs46:dcs46 aa.txt ===》把aa.txt文件的属主和属组改为dcs46用户
chmod u+rwx aa.txt ===》给属主单独加上读写执行的权限
chmod u-rwx aa.txt ===》给属主单独去掉读写执行的权chmod g+rwx aa.txt ===》给属组单独加上读写执行的权限
chmod g-rwx aa.txt ===》给属组单独去掉读写执行的权
chmod o+rwx aa.txt ===》给其他用户单独加上读写执行的权限
chmod o-rwx aa.txt ===》给其他用户单独去掉读写执行的权
chmod -R u+rwx aa.txt ===>递归修改目录
修改文件拥有者:chown + 拥有者 + 文件名称
eg.chown ivan file1 修改fle1文件拥有者为ivan
chgrp ivan file1 修改file1文件群拥有者为ivan
常用参数 -R 递归修改目录下所有的子目录,文件的拥有者
添加用户:useradd + 普通用户名称
【ps】添加的用户可以在/etc/password文件中查看
添加用户指定组:useradd + 用户 -g + 组名
删除用户:userdel -r + 用户名
【ps】删除用户需要加-参数,否则在删除用户的时候不会删除干净
添加用户组:groupadd + 组名
【ps】添加的用户组可以在/etc/group文件中查看
passwd + 用户名称
创建用户与密码:
cat /etc/passwd ===》查看有哪些用户,存储了系统中所有的用户
0 代表的是超级用户 root
1-499 :代表的是linux的系统的用户,不能用来登录
500及以上代表自己创建的用户---这个用户可以用来进行登录useradd dcs1 ===>创建一个叫做dcs1的普通用户
adduser dcs2 ===>创建一个叫做dcs2的普通用户
passwd dcs1 ===》给dcs1这个用户创建密码userdel dcs2 ==》删除一个用户dcs2
userdel -r -f dcs1 ===>强制删除dcs1这个用户,包括home目录下的文件夹
tar安装/卸载tar包
tar打包:tar -cvf +xxx.tar xxx
tar解包:tar -xvf +xxxx.tar
参数:-c 打包 -v 显示打包进度 -f 指定文件 -x 解包
zip文件打包:zip xxxx.zip xxxx
zip目录打包:zip -r xxxx.zip 目录
zip解包:unzip xxxx.zip
在线下载安装:yum yum install + 应用名
安装rpm包:rpm -ivh xxxx.rpm
参数:-i 安装 -v 显示安装进度
Llinux与Windows文件互传工具:WinSCP、xftp
查看磁盘使用情况:df
常用参数:-h 带单位显示磁盘使用情况
持续查看cpu使用情况:top
常用参数:-d eg.top -d + 秒 设定间隔时间查看资源使用情况
查看内存使用情况:free
查看进程命令:ps
查看所有用户的进程:ps aux
查看某个服务的进程:ps -ef | grep + 服务名称
杀进程命令:kill
强制杀进程:kill -9 + 进程号
查看所有已经开启的端口:netstat -ntlp命令
查看占用的端口:lsof -i : 端口号 eg.lsof -i:8080 查看占用8080端口的服务
查看在线登录用户:who
查看当前操作用户:whoami
查看主机名称:hostname
查看内核信息(32位/64位):getconf LONG_BIT命令
查看当前文件目录的大小:du -sh 命令
查看某个文件/目录的大小:du -sh + 文件/目录
重启Linux系统:reboot
关机:shutdown now,init 0
重启网卡:service network restart
连接xshell:
第一步:打开xshell
第二步:在centos中输入:ifconfig查看ip地址
第三步:在xshell中输入:ssh + ip地址(192.168.13.128)
第四步:在弹框内输入超级用户的账号:root 点击确定后再输入密码:123456
无法连接时处理方法:
1.重启网卡:service network restart
2.重启sshd服务:/etc/init.d/sshd restart
3.再次尝试连接xshell
yum命令:在线下载并安装
yum install lrzsz ===>在线下载并安装lrzsz文件传输工具
rz ====》将win系统 的文件传输到linux系统中
sz + 文件名 ===》将linux系统中的文件传输到win系统当中
rz 和sz 一般只用于拉去0-500兆的文件
xftp工具:作用是用来在linux和Windows系统之间传输文件的(一般适用于500兆之上的)
取别名:alias
查看历史:history
重置屏幕:reset
清空屏幕:clear
显示多少行,将详细信息也显示:nl
创建链接文件:In
参数:-s 软链接(接绝对路径,可以针对文件和目录创建软链接)
-d 硬链接(只能针对文件,不能对目录操作,相当于就是备份)
Vim文本编辑器的使用 Vim编辑器拥有的3种模式
作用:用于编辑一个文件 1.命令模式
用法:vim+文件名称 作用:用于键盘输入命令
例子:编辑一个file1文件 2.编辑模式
vim file1 作用:用于编辑文本,修改文本
3.末行模式
作用:用于输入末行命令
【ps】vim+文件名称,文件不存在,会先创建文件,再进行编辑。
vim命令模式下的常用命令:
1.a命令:从命令模式进入到编辑模式,在光标所在位置后进行输入
2.A命令:从命令模式进入到编辑模式,在光标所在行尾进行输入
3.i命令:从命令模式进入到编辑模式,在光标所在位置前进行输入
4.I命令:从命令模式进入到编辑模式,在光标所在行首进行输入
5.o命令:从命令模式进入到编辑模式,在光标所在行下一行输入
6.O命令:从命令模式进入到编辑模式,在光标所在行上一行输入
7.x命令:对光标所在的字符进行删除
8.X命令:对光标所在前的单个字符进行删除
9.dd命令:删除光标所在行
10.D命令:删除光标所在字符到行尾的内容
11.yy命令:复制光标所在行的内容
12.3yy命令:复制包含光标所在行的指定行数
13.p命令:在光标所在行的下一行进行粘贴
14.P命令:在光标所在行的上一行进行粘贴
vim未行模式:
1):wq命令----保存并退出
2):W命令----保存
3):wq!----强制保存,退出
4):qp----强制退出
5):set nu----设置行号/显示行号
6):set nonu----取消行号显示
7):m,ny命令----复制m~n行
8):m,nw+文件名称----指定m~n行,写入到一个新文件
9):/字符串----匹配的字符串高亮显示
10):noh----取消高亮显示效果
vim命令:
编辑文件:vim + 文件名
编辑内容步骤:
1.进入界面后按下字母键:i (i代表的是insert 插入的意思) 从命令模式切换到编辑模式
2.输入完成后按下ctrl+c切换到命令模式
3.输入冒号:wq! 强制保存并退出(按下esc按钮 打开字母大写按钮,按下:ZZ)
4.查看文件的内容:cat aa.txt
useradd dcs1 ===》创建一个用户默认是在自己的组中
useradd dcs2 -g dcs1 ===》创建一个dcs2用户并放在dcs1这个组当中
groups dcs2 =====》查看dcs2在那个组中
groupadd aaa ====》创建一个叫做aaa的组
cat /etc/group ====>查看有哪些组gpasswd -a dcs2 aaa ===》把dcs2这个用户放在aaa这个组(不仅可以移进空组,非空的组也能移动进去)
gpasswd -d dcs2 aaa ===》把dcs2这个用户从aaa这个组中移除
groupdel aaa ====》删除aaa这个组打包命令
1.tar包的打包与解压(可以对目录和文件进行打包和解压)
tar -cvf aa.tar aa.txt ==>将aa.txt文件打包成一个叫做aa.tar的包
tar -xvf aa.tar ===》将aa.tar包进行解压2.tar.gz包的打包和解压(可以对目录和文件进行打包和解压)
tar -zcvf dcs46.tar.gz dcs46 ===》将dcs46这个目录打包成一个tar.gz包
tar -zxvf dcs46.tar.gz ===》将dcs46.tar.gz包进行解压3.zip包的打包和解压
对文件进行打包
zip aa.zip aa.txt ==》将aa.txt文件打包成一个zip包
对目录进行打包’
zip -r kk.zip dcs46 ==》将dcs46目录打包成一个zip包对文件和目录的压缩包进行解压
unzip aa.zip ==>将aa.zip包进行解压
4.gzip打包(对文件进行打包,不能对目录进行打包)
gzip aa.txt ====>对文件打包,打包后源文件会消失,只剩下打包后的gz包
gunzip aa.txt.gz ====>对压缩包进行解压rpm命令:
rpm -ivh jdk-8u121-linux-i586.rpm ===>安装rpm包
java -version ===>有内容输出,就代表安装成功jdk :在linux系统中运行java语言编写的应用程序就需要jdk的支持(翻译官)
scp命令:远程拷贝
scp /head_tail.txt root@192.168.13.129:/ ===》远程拷贝根目录下的head_tail.txt文件到192.168.13129服务器2的根目录下
scp root@192.168.13.129:/xiaozhou.txt / ===》从服务器(192.168.13.129)根目录下拿xiazhou.txt文件到服务器1(192.168.13.128)的根目录df命令
df ===》查看磁盘的使用情况
df -h =====>带单位展示磁盘的使用情况top命令
top ===>实时查看资源使用情况,ctrl+c结束查看状态free命令
free ==》查看内存的使用情况
free -m ===>查看内存的使用情况ps 命令
ps ====>查看进程的命令,查看的是瞬间的进程
ps -ef =====》查看linux系统中所有正在运行的进程
ps aux ===》查看所有的进程
ps -ef |grep linux ===》查看linux的进程
ps -ef|grep grep ===》反向过滤grep进程kill 进程id ==>杀死进程
kill -9 进程id ===>强制杀死进程netstat -nltp ====》查看所有已经开启的端口号
netstat -tpln |grep 22 ===》查看22端口的信息
lsof -i:22 ===》查看22端口号被谁占用
who ===》查看在线登录用户
whoami ====》查看当前登录 用户
hostname ===》查看主机名称
getconf LONG_BIT ===>查看内核信息
du -sh ===》查看目录大小
du -sh aa.txt ===》查看aa.txt的文件的大小
reboot ===>重启
shutdown now ===>关机
init 0 ===》关机
service network restart ===>重启网卡
alias :取别名
history ======》查看历史输入命令
clear ===>清空屏幕
reset ===>清除屏幕
软硬链接:相当于创建了一个桌面快捷方式,删除 源文件,软链接会失效
ln -s /aa.txt /hs ===》在根目录下给aa.txt文件创建一个叫做hs的软链接,操作hs相当于操作aa.txt
硬链接:相当于备份,删除源文件不影响备份后的文件
ln -d /aa.txt /qqq ==》在更目录下给aa.txt文件创建一个叫做qqq的硬链接vim编辑
i ====>在光标所在位置的前方添加数据
I ===》从命令模式进入到编辑模式,在光标所在行的行首进行输入
a ===>从命令模式进入到编辑模式,在光标所在位置的后面进行输入
A ====>从命令模式进入到编辑模式,,在光标所在行的行位进行输入
o====>从命令模式进入到编辑模式,,在光标所在行的下一行进行输入
O ====>从命令模式进入到编辑模式,,在光标所在行的上一行进行输入
x ====》删除光标所在位置的字母
X ===>对光标所在前的字符进行删除
dd =====>删除光标所在行
yy =====>复制光标所在行
3yy ===》复制三行(复制光标所在行的的指定行数)
p ====》在光标所在行的下一行进行粘贴
P ====》在光标所在行的上一行进行粘贴
G ====>移动到最后一行
gg ====>移动到最上面一行
:wq ===>保存并退出
:wq! ====》强制保存并退出
:w ===>保存
:q ====》退出
:set nu ===>设置行号
:8 ===》光标指向第八行
:set nonu ===》取消行号展示
:x,my ===》复制x-m行
:/字符 ===》高亮展示
:noh ===>取消高亮展示
:e bb.txt ===>打开指定的文件
:r bb.txt ====》将指定的文件内容插入到当前光标所在位置的下一行
:%s/dcs/jdk ===>替换每一行第一次出现的dcs为jdk
:%s/jdk/dcs/g ===>g代表全局替换,替换内容将jdk替换为dcs
:%s/dcs/jdk/gc ===>替换内容将dcs替换为jdk 替换前会询问,按下y或者n进行是否替换
:%norm Ixxx ====>对每一行执行Ixxx命令,I为行首 xxxx为插入的内容
:%norm Axxx ====>对每一行执行Axxx命令,A为行尾 xxxx为插入的内容
:sort ===》对当前文件所有的内容进行排序
:g/jdk ===》显示所有包含jdk的行
:v/jdk ====》显示所有不包含jdk的行
:undo ===>撤销上一次的操作
:redo ===>重做上一次的操作
:1,$s/xxx/222/g =====>全局替换,从第一行替换到最后一行
三、MySQL数据库
1.数据库介绍
1、什么是数据库?定义:数据库是存放数据的电子仓库。
2、是以某种方式存储百万条,上亿条数据,提供多个用户访问共享。
3、每个数据有一个或多个api用于创建,访问,管理和复制所保存的数据。
4、系统中很多动态数据都存储在数据库中,需要通过访问数据库才能显示;
2.数据库的类型
1、关系型数据库
定义:数据库中表与表之间存在某种关系,数据存储在不同的表中
常见的关系型数据库:
(1)db2 IBM 公司
(2)oracle oracle 公司
(3)mysql oracle公司收购 (我们学习的mysql)
(4)sql server
特点:
a、安全
b、保持数据的一致性
c、实现对表与表进行复杂的数据查询
2、非关系型数据库
定义:通常数据是以对象的形式存储在数据库中
常见的非关系性数据库:
1、hbase (列模型)
2、redis (键值对存储)
3、mongodb (文档类型)
特点:
a、效率高
b、容易扩展
c、使用更加灵活
3.MySQL介绍
1、mysql的定义:
mysql是关系型数据库管理系统,我们常说的xxx数据库就是指xx数据库管理系统。
2、mysq数据库是有瑞典mysql db公司开发,目前属于oracle 公司,
3、在web应用方面(bs架构上),mysql是最好的关系型数据管理系统
4、特点:
a.体积小
b.开源,免费
c.使用c++编写
d.支持多系统
e.支持多引擎
f.msyql与其他工具组合可以搭建免费的网站系统
lamp=linux+apache+mysql+php
lnmp=linux+nginx+mysql+php
5、mysql的应用结构:
(1)单点数据库:使用于小规模应用(我们现在学的)
(2)复制:适用于中小规模的应用
(3)数据库集群,适合大规模的应用
比如:mgr集群,三主三从,一主三从;
6、数据库中术语:
(1)数据库
(2)数据表
(3)列
(4)行
(5)值
(6)字段名
(7)字符类型
(8)冗余
(9)主键
(10)外键
(11)视图
(12)索引
(13)单表
(14)多表
(15)存储
4.数据库常用命令
创建数据库:create database + 库名
显示所有数据库:show databases
进入某个数据库:use + 库名
删除某个数据库:drop database + 库名
创建表名:create table + 表名(
字段1名称,数据类型,约束,
字段2名称,数据类型,约束,
字段3名称,数据类型,约束,
)
查看表结构:desc + 表名
修改表名:alter table + 表名 rename +新表名
修改表字段:alter table + 表名 change + 原字段名 数据类型,约束
添加表字段,并放到第一个字段前:alter table + 表名 add + 字段名 数据类型 约束 first
添加表字段,并放到某个字段后:alter table + 表名 add + 字段名 数据类型 约束 after + 字段名【】
删除表字段:alter table + 表名 drop + 字段
修改主键id为自增长:alter table + 表名 +change 字段名 字段名 数据类型 auto_increment
删除表:drop table + 表名
表中插入数据:insert into + 表名 values(字段1value,字段2value,字段3value...)
对表中指定字段插入数据:insert into + 表名(字段1,字段2) values(字段1值,字段2值)
删除表中指定数据:delete from + 表名 where 条件
删除表数据:truncate + 表名
删除表:drop table + 表名
注:TRUNCATE,DELETE,DROP放在一起比较:
truncate table:删除表中所有行,表结构,>列,约束保存不变。
delete table:按条件删除表数据
drop table:删除表结构和表数据
更新表中指定字段数据:update + 表名 set 字段名=值 where 条件
备份表,创建一个表与某个表相同:create table + 表1 like + 表2
备份数据,把一个表的数据插入到另一个表:insert into + 表名 select * from + 表名
注意点:插入的表必须要存在
把一个表的某些字段插入到一个新表中:insert into + 表1(字段1,字段2) select 字段1,字段2 from 表2
注意点
1.插入的表必须存在
2.插入的表是新表没有数据。
备份数据库:mysqldump -uroot -p 数据库名 >脚本名
还原数据库:mysql -u root -p + 数据库 <脚本名
查询表中所有数据:select * from + 表名
查询某个字段的数据:select 字段 from + 表名
查询多个字段的数据:select 字段1,字段2 from + 表名
查询满足某个条件的所有数据:select * from + 表名 where 字段=值
查询不满足某个条件的所有数据:select * from + 表名 where 字段!=值
【】
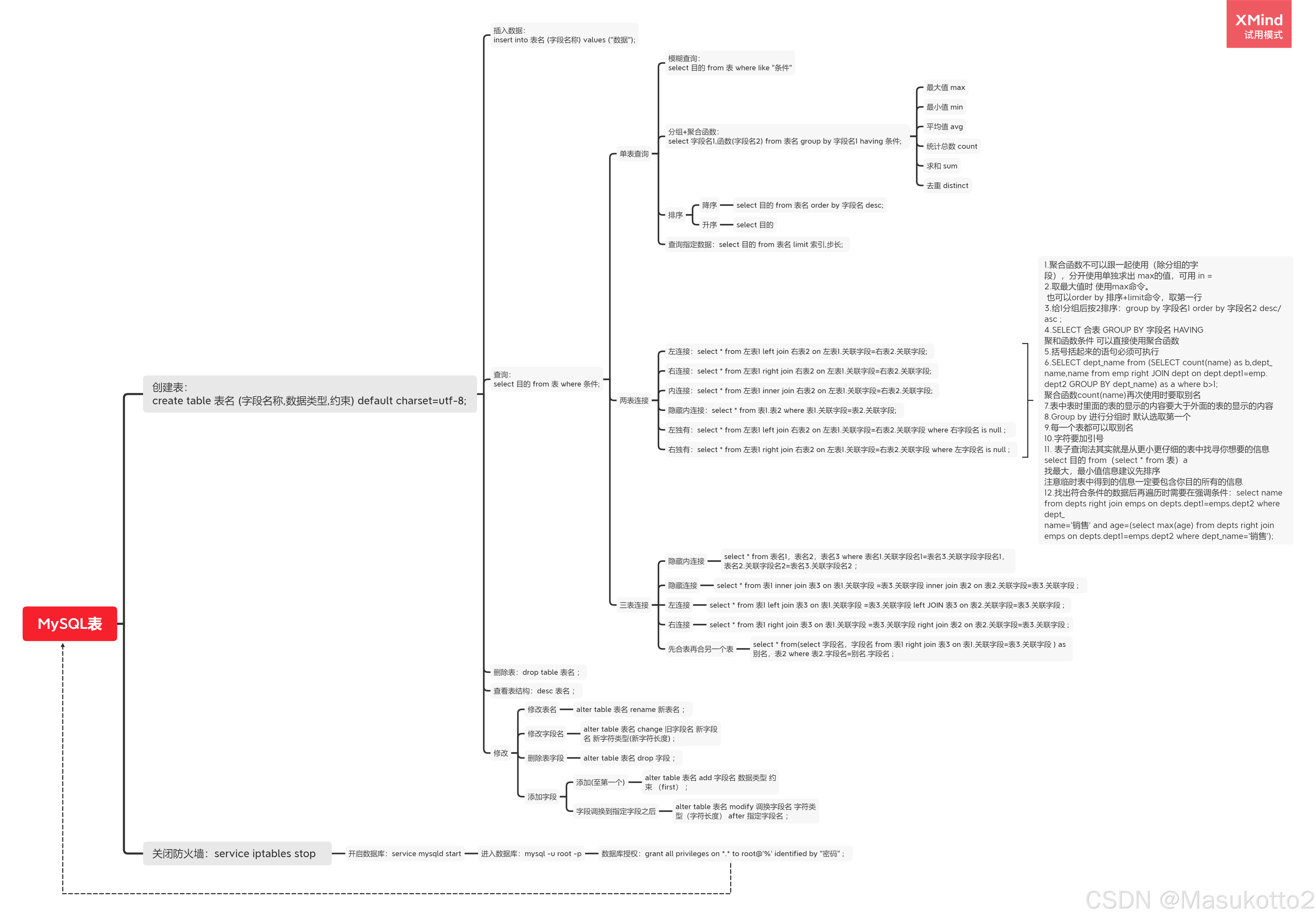
5.MySQL表思维导图
--------------------------------------------------------------------------------------------------------------------------------
【多表作业】
已知2张基本表:部门表:dept (部门号,部门名称);员工表 emp(员工号,员工姓名,年龄,入职时间,收入,部门号)
1:dept表中有4条记录:
部门号(dept1) 部门名称(dept_name )
101 财务
102 销售
103 IT技术
104 行政
2:emp表中有6条记录:
员工号 员工姓名 年龄 入职时间 收入 部门号对应字段名称为: (sid name age worktime_start incoming dept2)
1789 张三 35 1980/1/1 4000 101
1674 李四 32 1983/4/1 3500 101
1776 王五 24 1990/7/1 2000 101
1568 赵六 57 1970/10/11 7500 102
1564 荣七 64 1963/10/11 8500 102
1879 牛八 55 1971/10/20 7300 103
1.列出每个部门的平均收入及部门名称;
2.财务部门的收入总和;
3.It技术部入职员工的员工号
4.财务部门收入超过2000元的员工姓名
emp incoming>2000
dept 财务
5.找出销售部收入最低的员工的入职时间;
emp
dept
max
6.找出年龄小于平均年龄的员工的姓名,ID和部门名称
7.列出每个部门收入总和高于9000的部门名称
8.查出财务部门工资少于3800元的员工姓名
财务 dept
incoming emp
name
<
9.求财务部门最低工资的员工姓名;
min
dept dept_name
emp incoming min
10.找出销售部门中年纪最大的员工的姓名
11.求收入最低的员工姓名及所属部门名称:
12.求李四的收入及部门名称
13.求员工收入小于4000元的员工部门编号及其部门名称
14.列出每个部门中收入最高的员工姓名,部门名称,收入,并按照收入降序;
15.求出财务部门收益最高的俩位员工的姓名,工号,收益
16.查询财务部低于平均收入的员工号与员工姓名:
17.列出部门员工数大于1个的部门名称;
18.列出部门员工收入不超过7500,且大于3000的员工年纪及部门编号;
19.求入职于20世纪70年代的员工所属部门名称;
20.查找张三所在的部门名称;
21.列出每一个部门中年纪最大的员工姓名,部门名称;
22.列出每一个部门的员工总收入及部门名称;
23.列出部门员工收入大于7000的员工号,部门名称;
24.找出哪个部门还没有员工入职;
25.先按部门号大小排序,再依据入职时间由早到晚排序员工信息表 ;
26.求出财务部门工资最高员工的姓名和员工号
27.求出工资在7500到8500之间,年龄最大的员工的姓名和部门名称。
---------------------------------------------------------------------------------------------------------------------------------
关系型数据库:
oracle ===》收钱,大型的公司
msyql ===》开源的 免费的
sql server ===>微软
非关系型数据库:
hbase ===>大数据‘
Redis
mangdb
下载mysql:
yum install mysql
yum install mysql-server
rpm -qa |grep -i mysql ===》查看数据库有没有安装好
service mysqld restart ===>重启数据库 ===>mysql后面的d代表是一个守护进程daemon
service mysqld start ====》启动数据库
service mysqld stop ===>关闭数据库
mysql -uroot -p ====》u是用户 -p 是密码
exit ===》等同于ctrl+c 退出数据库界面
mysqladmin -uroot password "123456" ===》修改数据库密码为123456
数据库sql
show databases; ====》查看所有的库
create database dcs46; ===》创建一个仓库叫做dcs46
drop database dcs46; ===》删除dcs46这个库
use dcs46; ===》进入dcs46这个库
select database(); ===》查看当前在那个库
create table test(id int(20) primary key auto_increment,score float(20,2) not null
,name varchar(10),phone bigint(20) default 15377894561,time date);
上面建表的语句解释
创建一个叫做test的表,表里面有id字段 score字段,name字段 phone字段 time字段
desc test; ===》查看表结构
mysql> desc test;
+-------+-------------+------+-----+-------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+-------------+----------------+
| id | int(20) | NO | PRI | NULL | auto_increment |
| score | float(20,2) | NO | | NULL | |
| name | varchar(10) | YES | | NULL | |
| phone | bigint(20) | YES | | 15377894561 | |
| time | date | YES | | NULL | |
+-------+-------------+------+-----+-------------+----------------+Field ==》字段
Type ===>数据类型
Null ===》是否可以为空
Key ===》primary key 主键
Default ===》默认值
Extra ==》额外的备注
数据库中常用的数据类型:
数值型:
int ===》整数 最大的存储值为:2147483647
bigint ====>可以存储超过2147483647这个数字
float ===》浮点型
文本型:【varchar类型和char类型存的数据需要加上双引号或单引号】
varchar ===>存字符串(不管是中文还是英文 都占2个字节 空格也是一个字符)
char ====》存字符串(英文占1个字节,中文占2两个字节 空格不算字符只能算占位符)
日期型:【日期型的数据也需要加上单引号或者双引号】
date ===>"2024-08-23"
数据库中的约束有哪些?
not null ===>非空约束
primary key ===>主键约束,里面的数据不能重复必须是唯一的
default ====>默认值约束 不填写就用默认值
auto_increment ===>自增长约束 1 ====》1+1 前面四个约束是对表数据的约束
foreign key ===>外键约束 对表和表之间的约束
对表结构的操作:alter table +表名
show tables; ===》查看当前库下有哪些表
alter table test1 rename dcs111; ===》将test1这个表的名字改为dcs111
alter table test change id sid int(10); ===>将test表中的id字段改为sid 并去掉自增长
alter table test change sid id int(10) auto_increment; ===>将test表中的sid字段改为id 并加上自增长
alter table test add class int(10); ===》加上一个class字段(默认放在最后面)
alter table test add sex int(10) first; ===》加上一个sex字段放在最前面
alter table test add sex1 int(10) after id;===》添加一个sex1字段放在id字段后面
alter table test modify class int(10) after id; ==》将已经存在的class字段移动到id字段后面
alter table test add(age1 int(10),age2 int(10)); ==》同时添加两个字段
alter table test drop sex1,drop age1,drop age2; ===》删除字段
drop table test; ==》删除test表
插入数据:
insert into 表
insert into test(id,score,name,phone,time)values(1,88.88,"zhangsan",17326056700,"2024-08-24");
insert into test values(2,98.02,"lisi",17326056800,'2024-08-25'); ===》第二种插入数据的方式
insert into test(id,score,name,phone,time)values(3,78.00,"zhaoliu",17326056900,"2024-08-23"),(4,66.66,'xiaozhou',17326056400,"2024-01-02");=====》批量插入数据
insert into test(score,name,time)values(88.88,"zhangsan","2024-08-24"); ===》给指定字段插入数据
0不等于null ,null指的是一个空的属性,0代表的是一个值
面试题:给你一张表里面的一个字段怎么测试?
数据类型
约束类型
存储值的边界值
删除:delete from +表名
delete from test; ===》删除表中数据
delete from test where id=10; ==》删除指定数据,删除id为10的这条数据
truncate test; ====》快速删除表中数据
drop table test ===》删除test这张表
truncate,delete from,drop的区别
truncate:快速删除表中所有的数据,适用于删除大量的数据
delete from ===》根据条件删除数据,如果不接where会删除表中所有的数据,但是执行的速度没有truncate快
drop ====>删除表和表结构
修改表中数据:update
update student set math=81 where id=10; ===》修改id字段为10 的这个人的分数为81
查的sql:
1.不等于
select * from student where id<>2; ===>查询id不等于2的所有信息
select * from student where id!=2; ===>查询id不等于2的所有信息2.同时满足多个条件,至少满足一个条件
select * from student where age>24 and age<31; ===》查询年龄大于24.小于31岁的信息
select * from student where age=28 or age=27; ===》查询年龄等于28或者年龄等于27的信息
3.包含和不包含
select * from student where class in (1833,1835); ==》查询班级为1833或1835的信息
select * from student where class not in (1833,1835); ==》查询班级不是1833或1835的信息
4.在.....之间 between的值包含自身
select * from student where age between 24 and 31; ==》查询年龄在24-31之间的信息
5.为空 不为空
select * from student where class is null; ==》查询班级为空的
select * from student where class is not null; ==》查询班级不为空的
6.查询指定行数
select * from student limit 5; ===》查询前五行的内容 等同于 limit 0,5
select * from student limit 2,5; ===》查询3-7行的数据 3-1=2 7-2=5
7.模糊匹配
select * from student where name like "xi%"; ===>查询姓名以xi开头的信息
select * from student where name like "%qi"; ====》查询姓名以qi结尾的信息
select * from student where name like "%ao%";-===》姓名中带有ao的信息
select * from student where name like "xiaoli_"; ===》_表示一个字符
8.排序
select * from student order by math; ===》order by 默认是升序排序
select * from student order by math desc; ===》desc是降序排序
select * from student order by math asc; =====》acs是升序排序9.分组 group by +字段 ==> 分组函数 group by
select count(*),class from student group by class; ====>求每个班级的人数
select count(*) as "班级",class as "人数" from student group by class; ===》给查询出来的字段取别名
select count(*) a,class b from student group by class; ===》给查询出来的字段取别名
select * from (select max(math)a from student )b where a>90;
常用的聚合函数:
count(*) 统计
sum(math) 求和
avg(math) 求平均
max(math) 求最大值
min(math) 求最小值
distinct(math) 去重
注意点:group by
1.分组函数 group by 只能和聚合函数一起使用,还有分组的字段
2.where后面可以接group by 但是group by后面不能接where
3.group by 前面加where是为了先过滤在分组,where条件中不能包含聚合函数 统计,求和.....
4.where后面接group by 是为了先过滤在分组,having是跟group by连在一起用的,放在group by的后面,此时having的作用是先分组在过滤
1.求出每个班级数学成绩大于80分的人数
select class,count(*) from student where math>80 group by class;
2.求出每个班级性别为1的数学总成绩
select class,sum(math) from student where sex=1 group by class;
3.求出每个班数学总成绩大于200的班级和成绩信息
select class,sum(math) from student group by class having sum(math)>200;
四、HTML+CSS
1. html的基本格式
<!DOCTYPE html>
<html> #html文档的开始
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body> #html文档的体部
</body>
</html>2.基本标签
p标签:段落标签,自动换行 <p></p>
标题标签:h1标题最大,h6标题最小 h1-h6
em标签:斜体 <em></em>
i标签:斜体 <i></i>
br标签:换行 <br></br>
b标签:加粗 <b></b>
strong标签:加粗 <strong></strong>
s标签:表示删除线 <s></s>
u标签:下划线 <u></u>
font标签:颜色 <font color="red"></font>
sub标签:下标 <sub></sub>
sup标签:上标 <sup></sup>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>标签认识</title>
</head>
<p>p标签,也叫段落标签</p>
<p>p标签,也叫段落标签</p>
<h1>标题标签老大</h1>
<h2>标题标签老二</h2>
<h3>标题标签老三</h3>
<h4>标题标签老四</h4>
<h5>标题标签老五</h5>
<h6>标题标签老六</h6>
<em>em标签,斜体</em><br />
<i>i标签,表示斜体</i>
<b>b标签,加粗</b><br />
<strong>strong标签,表示加粗</strong><br />
<s>删除线</s><br />
<u>u标签 ,表示下划线</u>
<font color="red">中国人</font>
<sub>下标</sub>
<sup>上标</sup>
<body>
</body>
</html>3.图片标签
(1)导入本地图片连接
(2)引用网上图片连接
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>图片标签</title>
</head>
<body>
<p>图片展示</p>
<img src="../img/QQ图片20231212113147.png"/>
<p>引用网上图片</p>
<img src="https://am.zdmimg.com/202408/14/66bc9331583a97117.jpg_e1080.jpg"/ width="100" height="100">
</body>
</html>Hbuilder编辑界面输入html页面的基本结构快捷键:shift + !+ tab
页面字体的放大缩小:鼠标+滚轮
空格: 或者 shift + 7
4.链接标签
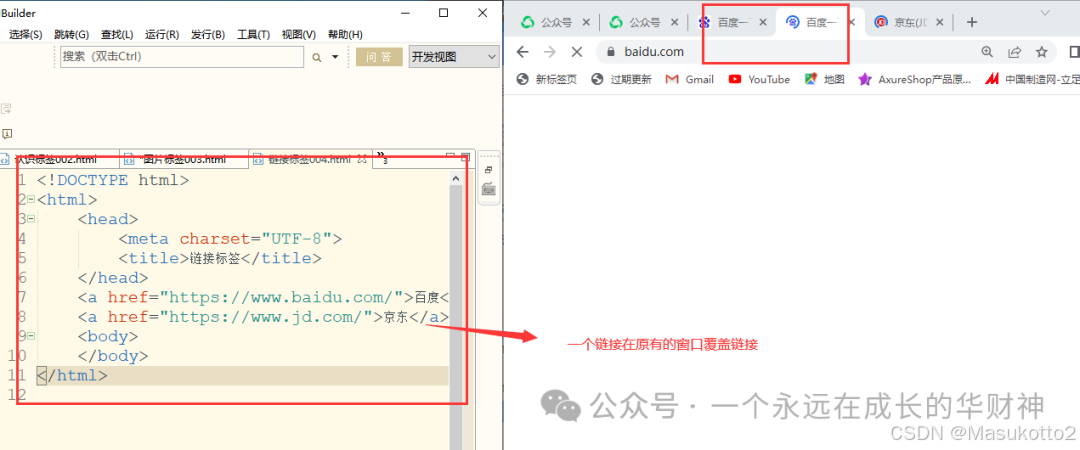
定义:一个网页指向另一个网页的目的地。
四种方式:
- 在原有的窗口覆盖
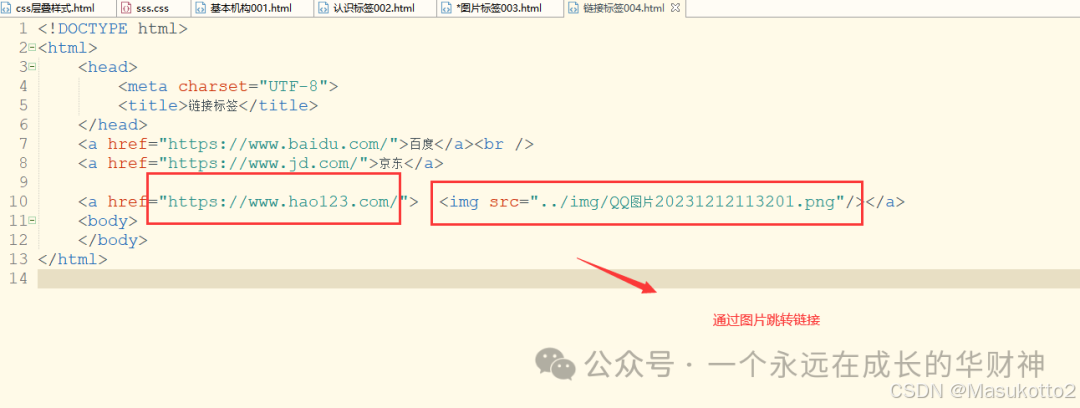
- 通过图片跳转链接
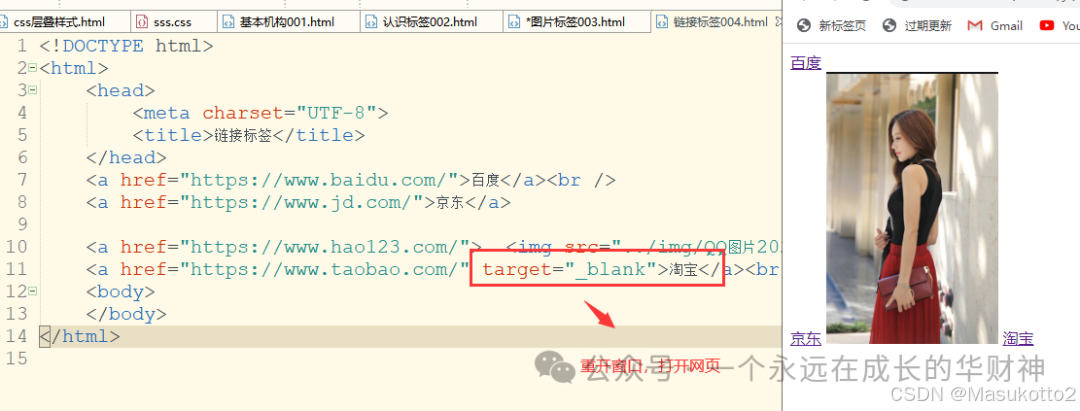
- 重开一个窗口
详解:
target=属性
(1) target=“_blank” 表示将连接的画面内容,在新的浏览器窗口中打开;(打开新窗口)重点
(2)target=“_self” 表示将连接画面内容,显示在目前的窗口中;
(3)target=“_top” 表示将连接画面内容,显示在没有框架的视窗中;
(4)target=“_parent” 表示将连接画面内容,当成文件的上一个画面;
(5)target=“_search” 表示将连接画面内容,搜索区装载的文档
5.死链接
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>链接标签</title>
</head>
<a href="https://www.baidu.com/">百度</a><br />
<a href="https://www.jd.com/">京东</a>
<a href="https://www.hao123.com/">
<img src="../img/QQ图片20231212113201.png"/></a>
<a href="https://www.taobao.com/" target="_blank">淘宝</a><br />
<a href="#">死链接</a>
<body>
</body>
</html>6.列表
(1)有序列表 ol (order lists 简称ol)有序排序的方法
快速生成多个有序列表:ul*3>li*2 按tab键
(2)无序列表 (unorder lists 简称:ul)无序的排序
快速生成多个无序列表:ol*2>li*2 按tab键
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>列表</title>
</head>
<body>
<ol type=""
<li>活动室</li>
<li>买菜</li>
</ol>
<ol>小孩
<li>游乐场</li>
<li>上学</li>
</ol>
<ul type=""
<li>跑车</li>
<li>手表</li>
</ul>
<ul>女
<li>化妆品</li>
<li>服装</li>
</ul>
<ul>
<li></li>
<li></li>
</ul>
<ul>
<li></li>
<li></li>
</ul>
<ul>
<li></li>
<li></li>
</ul>
ol*2>li*2
</body>
</html>7.表格标签
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>表格标签</title>
</head>
<body>
<table border="10" align="center" cellspacing="" cellpadding="" height="100" width="100">
<tr>
<th>编号</th>
<th>姓名</th>
<th>手机号</th>
</tr>
<tr>
<td>1</td>
<td>zs</td>
<td>15949613302</td>
</tr>
<tr>
<td>2</td>
<td>ls</td>
<td>15949613303</td>
</tr>
</table>
</body>
</html>认识表中的一些常用单词:
border 边距
align 格式 ‘ center’ 对齐
cellspacing 单元格与单元格的距离
cellpadding 单元格与内容的距离
wedth 宽度
height 高度
tr 表示:行
th 表示:表头
td :表示列
- 输入tab + 回车\
合并行:rowspan = "2" 2是代表合并的行数
合并列:colspan = "2"
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>表格标签</title> </head> <body> <table border="10" align="center" cellspacing="" cellpadding="" height="100" width="100"> <tr> <th>编号</th> <th>姓名</th> <th>手机号</th> </tr> <tr> <td>1</td> <td>zs</td> <td >15949613302</td> </tr> <tr> <td>2</td> <td colspan="2">ls</td> </tr> </table> </body> </html>
8.表单
(1)熟悉表单的单词
表单标签格式:form
开始网址:action
get和post等等:method
表单标签:主要用来收集用户输入信息如:登入、注册、搜索商品等
用户名格式:text (明文)
密码格式:password (密文)
性别:radio 性别格式 性别是单选,单选类型是radio,注意name要加上sex
复选框:checkbox
文本框:textarea
上传文件:file
下拉选择框:select
按钮:button
重置:reset
提交:submit
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>表单标签</title>
</head>
<body>
<form action="https://www.baidu.com/" method="post">
<p> 用户名:
<input type="text" name="" id="" value="" />
</p>
<p> 密码:
<input type="password" id="" value="" />
</p>
<p> 性别:
<input type="radio" name="sex" id="" value="" />男
<input type="radio" name="sex" id="" value="" />女
</p>
<p>学习内容:
<input type="checkbox" name="" id="" value="" />mysql
<input type="checkbox" name="" id="" value="" />linux
<input type="checkbox" name="" id="" value="" />html
</p>
<p>
自我介绍: <br />
<textarea name="" rows="10" cols="20"></textarea>
</p>
<p>
<input type="file" name="" id="" value="" />
</p>
<p>学历
<select name="">
<option value="">本科</option>
<option value="">专科</option>
<option value="">高中</option>
</select>
</p>
<input type="button" value="按钮"/>
<input type="reset" value="重置"/>
<input type="submit" value="提交"/>
</form>
</body>
</html>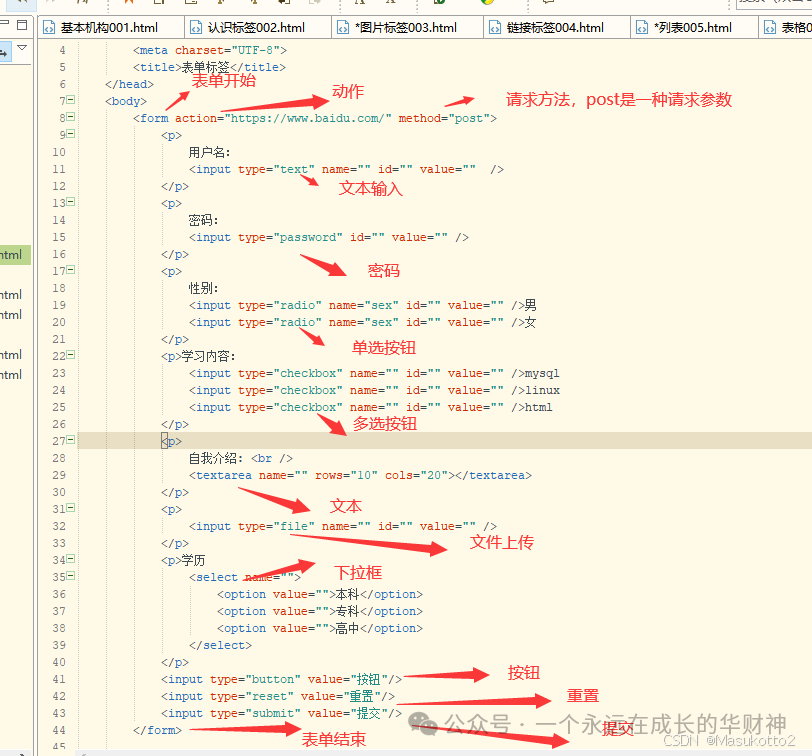
9.CSS样式
css 层叠样式有两种方式:
(1)通过<style type="text/css">方法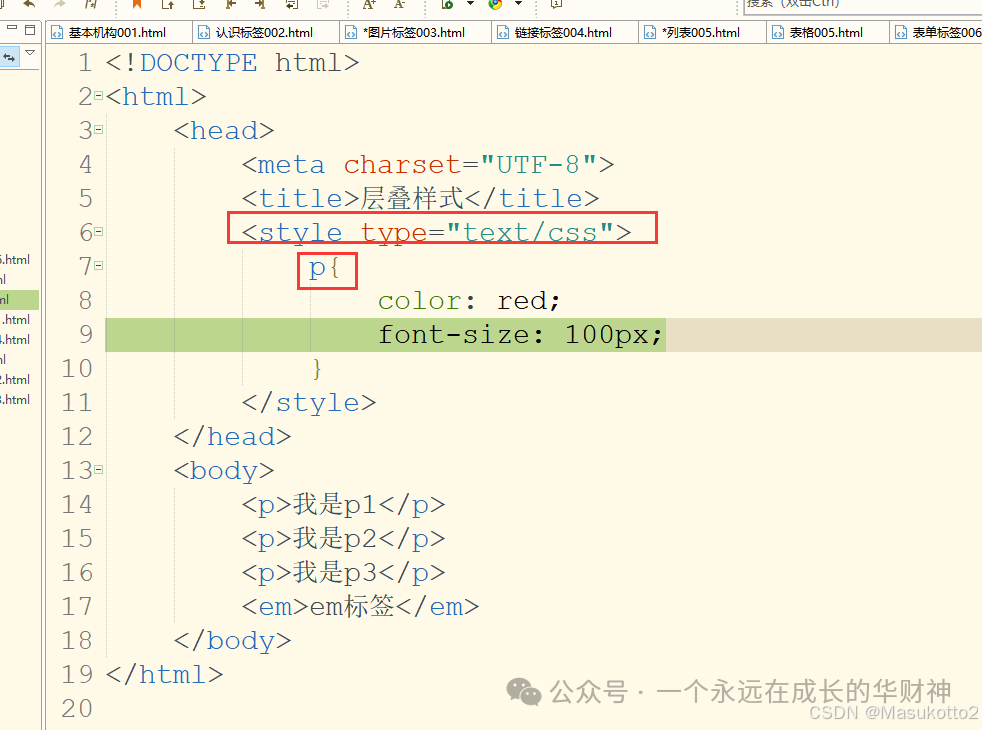
(2)通过外链的方式
-新建一个css文件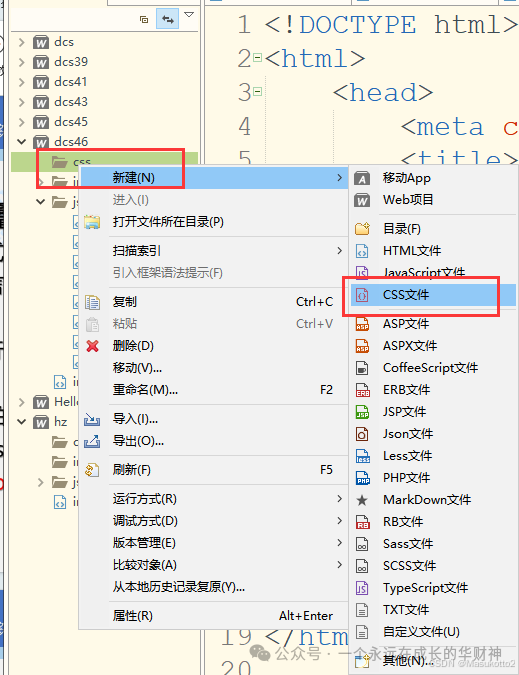
-编辑css文件
-引用这个css文件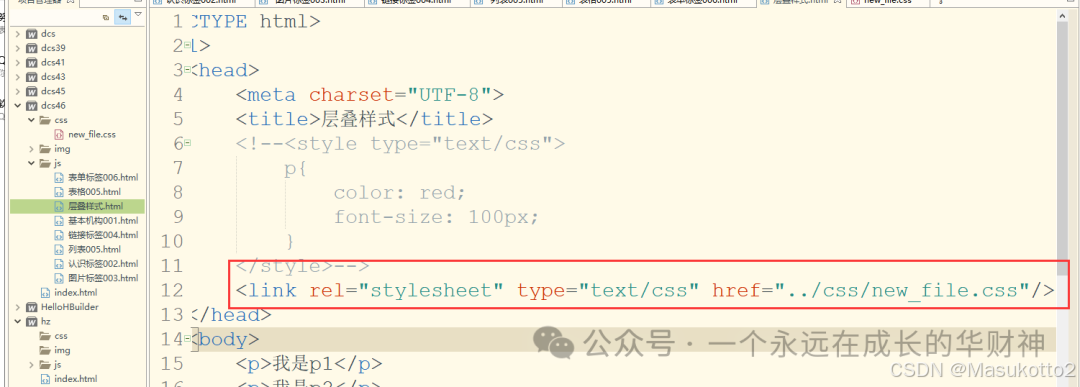
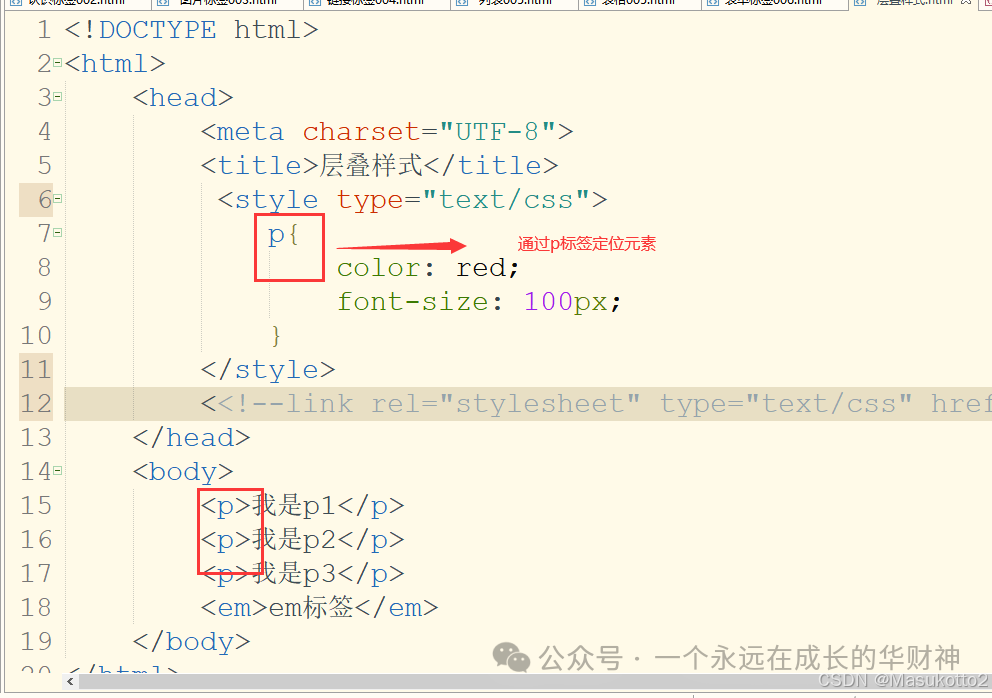
10.选择器
- 通过标签定位元素
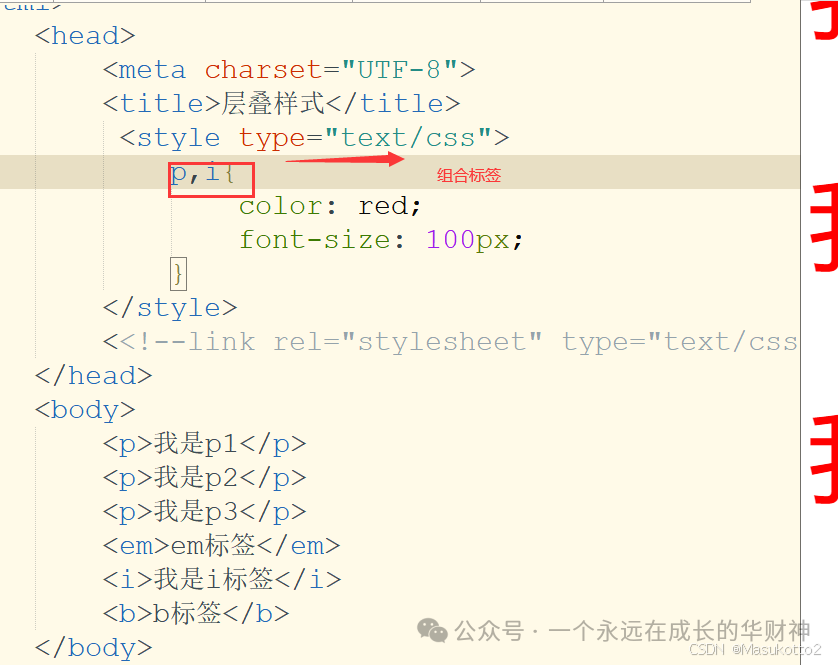
p{ color:red; font-size:100px; } - 通过组合标签
p,i{ color:red; font-size:100px; } - 通过id选择器(#) id属性前加上#

#dcs{ color:red; font-size:100px; } <b id="dcs">标签</b> - class定位: . (点)
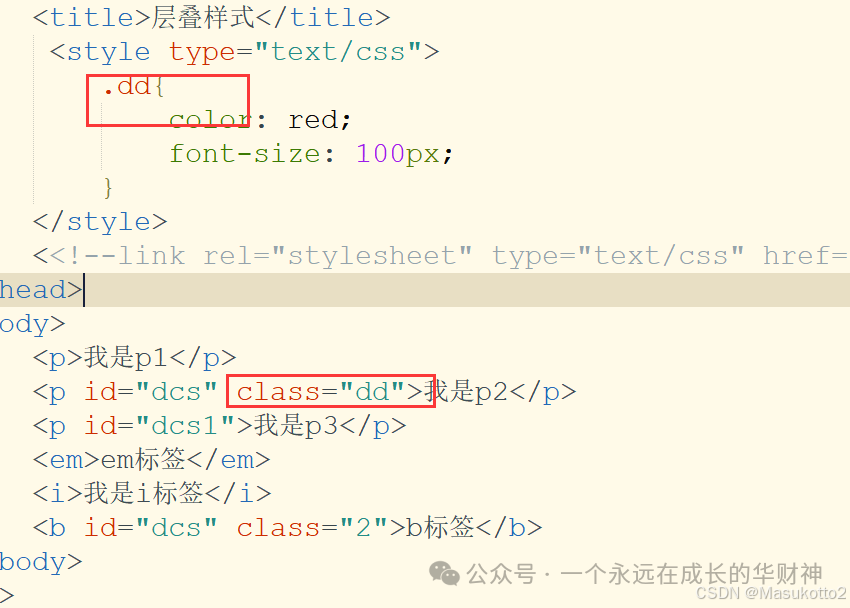
.dd{ color:red; font-size:100px; } <p id="dcs1" class="dd">dcs</p> - 伪类选择器
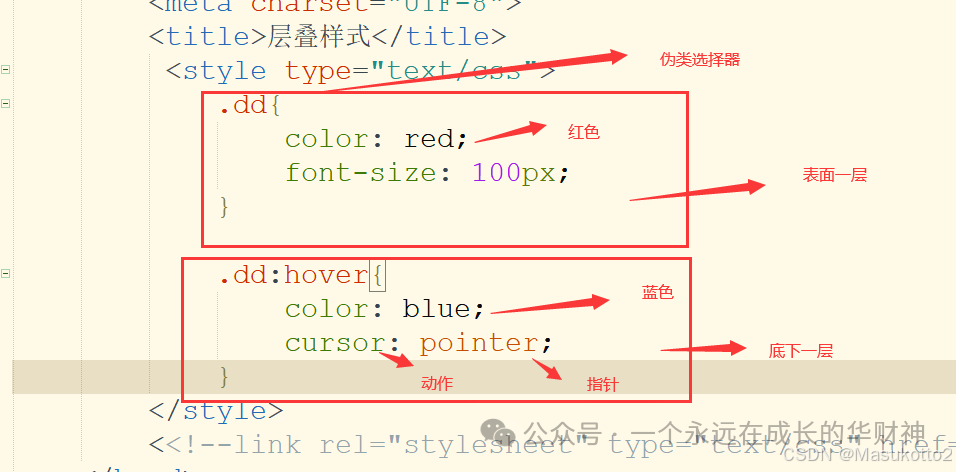
<style type="text/css"> .dd{ color: red; font-size: 100px; } .dd:hover{ color: blue; cursor: pointer; } </style> - 字体合文本样式

<style type="text/css"> .dd{ color: red; font-size: 100px; font-family: "微软雅黑"; font-style: italic; font-weight: bold; text-decoration: underline; text-align: center; cursor: pointer; } .dd:hover{ color: blue; cursor: pointer; } </style>
五、Python
(1)python是一个解释性语言、编译性语言、互动性和面向对象。
python也叫"胶水语言"
python中一切皆对象
人类 (类)===xx (对象)
(2)python优点:
- a、简单
- b、易学
- c、免费、开源
- d、可移植性强
- e、可拓展性墙
- f、丰富地方库和类
(3)python应用的领域:测试自动化脚本、开发、人工智能、ai、网络爬虫等
(4)python开发的软件:豆瓣、youtube、知乎
(5)目前使用版本:3.7版本,最新3.12
1.python中的输出语句
- 1、Python输出语句
- print (hello duoceshi')
- 2、Python格式化输出:
- %s:字符串(采用str0的显示)
- %c:单个字符
- %d:十进制整数
- %:十进制整数
- %0:八进制整数
- %X.十六进制整数
- %f浮点数
- %%:字符"%”
2.python中的注释
- 1、单行注释:采用#号
- 2、单引号、双引号、三引号注释:
- print ('dcs is number one')
- print ("dcs is number one")
- print ('"dcs is number one"")
3.python中的变量命名规则
1、变量由字母,数字,下划线组成,但必须是字母或下划线开头,区分大小写,不能由数字开头
2、下划线和大写字母开头的标识符有特殊意义:
a.单下划线开头标识符XXx不能用于from xxx import*,即保护类型只能允许其本身与子类进行访问;
b._ _xxx双下划线的表示的是私有类型的变量。只能是允许这个类本身进行访问了,连子类也不可以。
c.大写字母开头的在Python中一般表示类比如:People
4.python中的输入语句
input() 函数会把任何用户输入的内容、转换成字符串存储,在需要其它类型的数据时,调用相应的函数进行转换
name=input('请输入您的用户名:')
if name == 'duoceshi';
print ('VIP用户')
else:
print('普通用户')
5.运算符和格式化输出
运算符
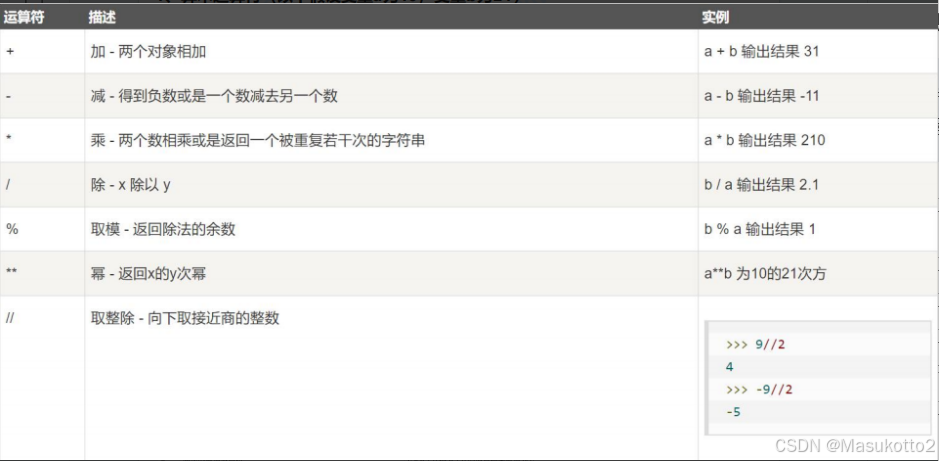
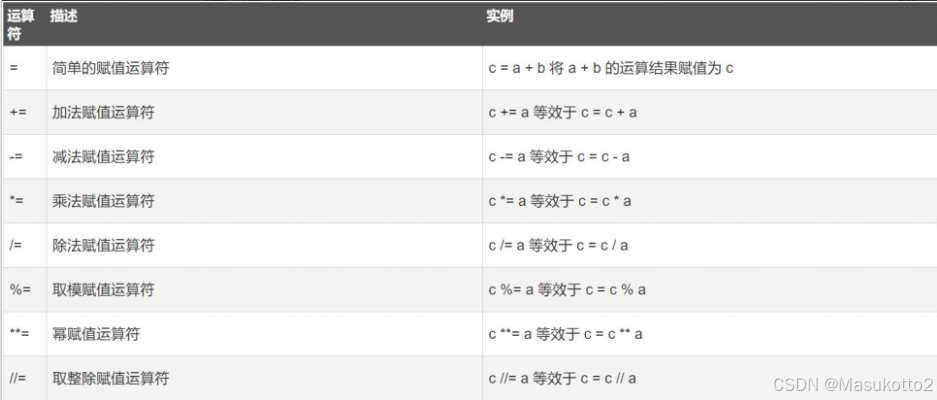
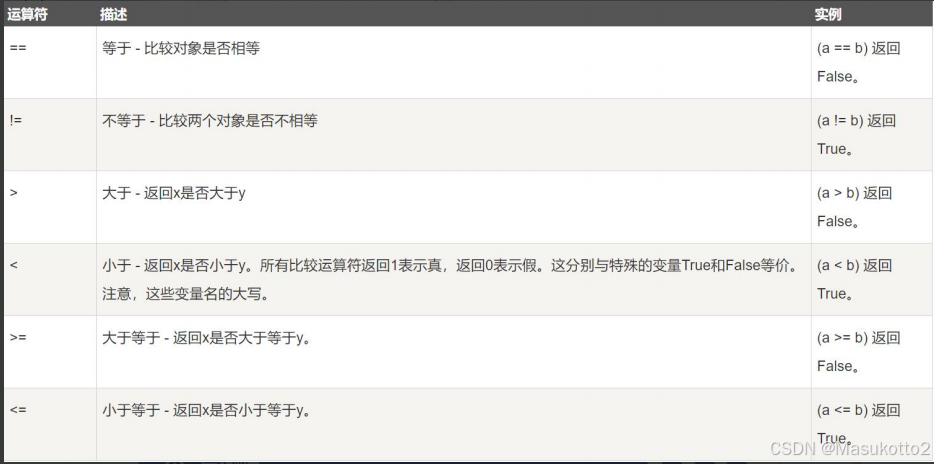
Python支持算术运算符、赋值运算符、位运算符、比较运算符、逻辑运算符、字符串运算符、成员运算符和身份运算符等基本运算符。
- 算术运算符(以下假设为10,变量b为21)
- 赋值运算符(以下假设变量a为10,变量b为20)
- 比较运算符(以下假设变量a为10,变量b为20)
- 逻辑运算符(以下假设变量a为10,b为20)

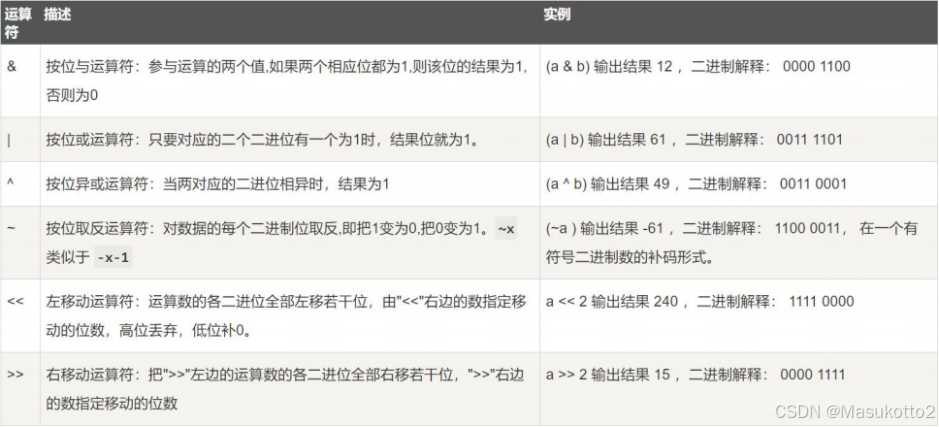
- 位运算符(位操作符主要操作二制码再转换成十进制)
- 成员运算符(in和not in操作)

1、算术运算符
+,-,* ,/,%,**, // a=10 b=8 print(a+b) #18 print(a-b) #2 print(a*b)#80 print(a/b) #1.25 print(a%b) #2 除法中的余数 print(a**b) #100000000 print(a//b) #1 除法中的商2、赋值运算
= 、+=、-=、*=、/=、%=、**=、//= 案例1: += a=10 b=3 a+=b #a=a+b print(a) print(b) 案例2:-= a=10 b=3 a-=b #a=a-b print(a) print(b) 案例3:*= a=10 b=3 a*=b #a=a*b print(a) print(b) 案例4:/= a=10 b=3 a/=b #a=a/b print(a) print(b) 案例5: %= a=10 b=3 a%=b #a=a%b print(a) print(b) 案例6:**= a=10 b=3 a**=b #a=a**b print(a) print(b) 案例7://= a=10 b=3 a//=b #a=a//b print(a) print(b3、比较运算符
== 、!=、>、<、>=、<= 返回的结果是布尔值: False True 案例: a=10 b=3 c=5 print(a==b)#False #等于 print(a>b) #True #大于 print(c<a) #True #小于 print(a>=b) #True 大于等于 print(b<=c) #True 小于等于 print(a!=b) #True 不等于4、成员运算符:
in not in 案例 list=[1,3,3,5,7,8,9] print(1 in list) #True print(6 in list) #False print(1 not in list) #False print(6 not in list) # True5、逻辑运算符
and 、or 、not 案例: a=10 b=3 c=5 print(a>b and b<c) #True print(a>b and b>c) #False print(a>b or b>c) #True print(a<b or b>c) #False print(not(a>b)) #False print(not(b>a)) #True6、位运算
& ,|,^,~,<< ,>>
二进制来进行计算:
(1)熟悉进制方法1
1111 1111进制 0表示占位,1表示不占位
2的2次方=4 2的1次方=2 2的0次方=1
5的二进制:2的2次方+2的0次方 =4+1=5
0000 0101
8的二进制:2的3次方 =8
0000 1000
13的二进制:8+4+1 2的3次方+ 2的2次 方+2 的0次方
0000 1101
(2)熟悉进制方法:查看进制表
(3)通过换算(除以2)a=9
b=4
9的进制: 8+1 000 0 1001
4 的进制:0000 0100
a、按位与
案例:
a=9 b=4 print(a&b) #09的进制:0000 1001
4 的进制:0000 0100
0000 0000
规则:两两为真取,一真一假不取
b、按位或
a=9 b=4 print(a|b) #139的进制:0000 1001
4 的进制:0000 0100
0000 1101 8+4+1=13
规则:
一真一假取,一假一真取,两两为真取,
两两为假不取,
c、按位异^
a=9 b=4 print(a^b)规则:
9的进制:0000 1001
4 的进制:0000 0100
0000 1101
一真一假取,一假一真取,两两为真不取,两两为假不取,
d、按位取反:~
-(变量名+1)
a=9 print(~a) #-10 -(9+1)e、向左移动
a=9 b=4 print( a>>b) #09的进制: 0000 1001
9的进制移动4位: 0000 0000
f、向右移动
a=9 b=4 print(a<<b) #1449的进制: 0000 1001
9的进制移动4位:1001 0000 16+128=144
练习
a=7
b=3
7的进制:0000 0111
3的进制:0000 0011
a=7 b=3 print(a&b) #3 print(a|b) #7 print(a^b) #4 print(~a) #-8
格式化输出
1、格式化输出
%s :字符串 (采用str()的显示)
%c :单个字符
%d:十进制整数
%i :十进制整数
%o:八进制整数
%x:十六进制整数
%f:浮点数
%% :字符"%"
(1)熟悉进制的转化
(2)案例
s=12
# print(type(s)) #<class 'int'>
# print(type("%s"%s)) #<class 'str'>
# print("%c"%s)
print("%d"%s) #12
print("%i"%s) #12
print("%o"%s) #14
print("%x"%s) #c
print("%f"%s) #12.000000
print("%d%%"%s) #12%转换成二进制:s=15
print(bin(s)) #结果:0b11112、input 语句
(1)input输入语句
语句:
name=str(input("请输入账号:"))
if name=="dcs":
print("上线")
else:
print("无效账号")
(2)if语句的嵌套
语句:
name=str(input("请输入账号:"))
if name=="dcs":
mn=input("请输入密码:")
if mn=="123456":
print("登录成功")
else:
print("密码错误")
else:
print("错误账号")
6.查看python中的字符类型
python的打印方法 :print()
打印字符、数字、汉字
打印字符和汉字药使用引号,数字可以直接打印
print(a)
print("b")
print(1)
print("中国")
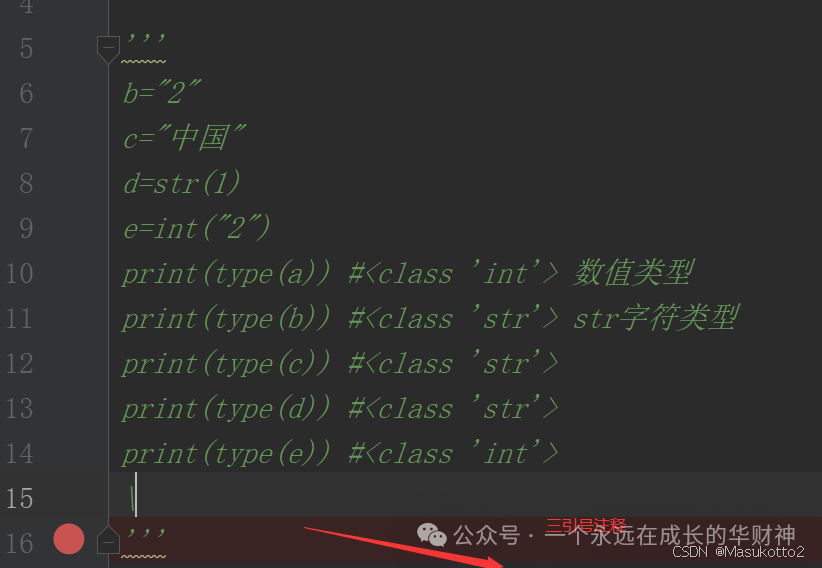
print(中国)type 查看字符类型
c="中国"
print(type(a)) #<class 'int'> 数值类型
print(type(b)) #<class 'str'> str字符类型
print(type(c)) #<class 'str'>字符类型和数值类型互相转换
a=1
b="2"
c="中国"
d=str(1)
e=int("2")
print(type(a)) #<class 'int'> 数值类型
print(type(b)) #<class 'str'> str字符类型
print(type(c)) #<class 'str'>
print(type(d)) #<class 'str'>
print(type(e)) #<class 'int'>注释
多行注释:ctrl+/ 选择注释的行
取消多行注释:ctrl+/ 选择注释的行
多行注释:三引号
单行注释 :shift+#
取消注释:删除#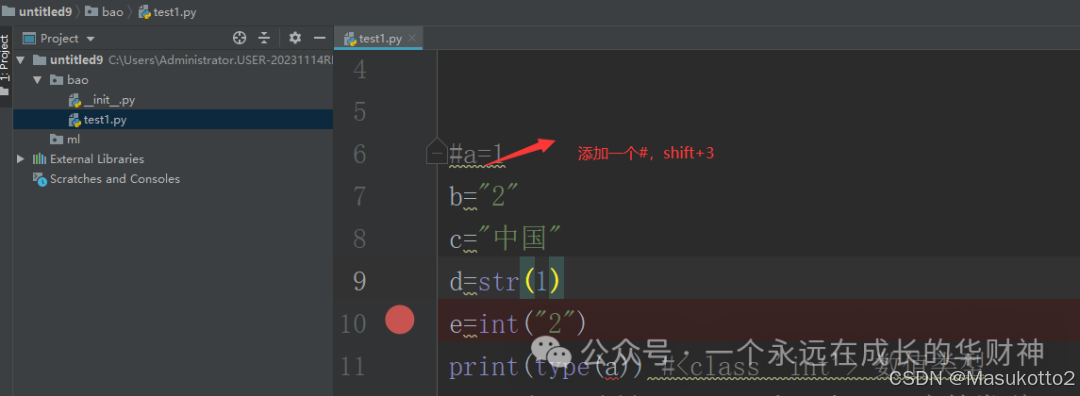
引号的使用:单引号、双引号、三引号
# print('abc') # abc 单引号能单独使用
# # print('abc(d'j'je)fgc') 单引号不能包含单引号
# print('abc(d"j"je)fgc') #单引号能包含双引号
# # print('abc(d'''j'''je)fgc') 单引号不能包含三引号
# print("abc") #双引号能单独使用
# print("abc(d'j'je)fgc") #双引号能包含单引号
# # print("abc(d"j"je)fgc") #双引号不能包含双引号
# print("abc(d'''j'''je)fgc") #双引号能包含三引号
print('''abc''') #三引号能单独使用
print('''abc(d'j'je)fgc''') #三引号能包含单引号
print('''abc(d"j"je)fgc''') #三引号能包含双引号
print('''abc(d'''j'''je)fgc''') #三引号不能包含三引号总结:
1、单引号、双引号、三引号都能单独使用
2、单引号、双引号、三引号都不能包含自己
3、单引号可以包含双引号,不能包含单引号和三引号
双引号可以包含单引号,三引号,不能包含单引号
三引号可以包含单引号、双引号,不包含三引号
变量名设置
通过格字符代表数值或值
a=10 a就是变量 python中一个等于叫赋值 ,两个==才是等于
定义变量有:数字、字符、下划线
变量不能用数字开头,要以字符或下滑线开头
a=2 #字符单独定义变量
a1=3 ##字符+数字定义变量
a_1=4 #字符+数字+下划线定义变量
a_=5 #字符+下划线定义变量
_=6 ##下划线单独定义变量
_1=6 #下划线+数字定义变量
_1a=7 #下划线+数字+字母定义变量
_a=8 #下划线+字母定义变量
1=a 数字开头不能定义变量
1a=57. python中的数据结构
(1)索引
定义:我们可以直接使用索引来访问序列中的元素,同时索引可分为正向和负向两种,而切片也会用到索引,下面放上一个图,有助于大家理解正、负向索引的区别,如图所示: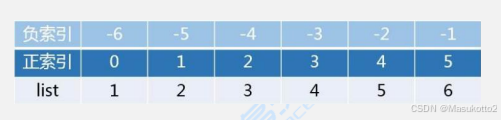
Python中的序列,包括字符串(String)列表(List)、元组(Tuple)
(2)切片
定义:切片是指对操作的对象截取其中一部分的操作,字符串、列表、元组都支持切片操作。
切片的语法:[start index:end index:step]
解释说明:start index表示起始索引
end index表示结束索引
step表示步长,步长不能为0,且默认值为1
注意:切片操作是指按照步长,截取从起始索引到结束索引,但不包含结束索引(也就是结束索引减1)的所有元素。
str='abcdefghjkl'
print(str[0:3])
print (str[1:3])
print(str[:-1])
print (str[2:-1])
print
(str[2:])
print (str[1:6:3])
print (str[::1])
print(str[:1]):反转输出面试题常遇
print(str[-2:-5:-1])(3)字符串
字符串是Pythont中最常用的数据类型。我们可以使用单引号"或者双引号""来创建字符串。
str1 = 'hello duoceshi'
str2 = "hello duoceshi"
字符串常用函数:
1、capitalize():首字符大写
str = 'abcd'
print (str.capitalize())
2、count():统计具体字符出现的次数
str = 'abcad'
print (str.count('a'))
3、join():把集合中的字符按自定义的分隔符连接在起
str ="abcad"
print ('-'join(str))
4、split():把字符串通过指定标识符进行分割
str ="abcad"
print (str.split('b'))
5、strip(ab):删除字符串开头和结尾有a或b的字符
str ="abcad"
print (str.strip('ab'))
6、Istrip(ab):删除字符串开头有ab序列字符
str ="abcad"
print (str.lstrip('a'))
7、rstrip(ab):删除字符串结尾有ab序列字符
str ="abcad"
print(str.rstrip('d'))
8、startswith():判断字符串是否以什么开始
str ="abcad"
print(str.startswith('a)#这里输出结果为true或false
9、endswith():判断字符串是否以什么结束
str ="abcad"
print(str.endswith(d')#这里输出结果为true或false
10、find() / rfind():字符串查询find0是左边开始查,rfind0从右边开始查,结果显示下标
str1 ="duoceshitest"
print (str1.find("e"))
print (str1.rfind("e"))
11、replace():replace(substring,newstring,max)substring表示被替换的字符串,newstring要替换字符串,max表示替换的次数
str1 ="duoceshitest"
print (str1.replace("t","a")) #把t替换成a,这全部替换
str1 ="duoceshitest"
print(str1.replace("t","a",2)) #替换两个,从前往后
12、lower():方法转换字符串中所有大写字符为小写
str='ADFASDF'
print(str.lower())
13、upper():将字符串中的所有小写字符转换为大写字母输出
str='ASDFDSsdfsdfSDFDSFSF'
print (str.upper())
14、isdigit():判断字符串中是否全为数字
str='abcd'
print(str.isdigit())
15、isalpha(0:判断字符串中是否全为字母
str='abcd'
print(str.isalpha())
16、isalnum():判断字符串当中是否全都为数字,全为字母,或者数字字母组合返回布尔值:True和False如果有特殊符号就是否
str='1234aa@#$'
print (str.isalnum())
17、istitle():判断字符串中首字母是否为大写,其他是否为小写,其他不为小写则为否
str='A1234'
print (str.istitle())
18、isupper() / islower():is开头的就是判断一个字符串是否展示为都是大写或者都是小写
str.isupper()
str.islower()
(4)列表
定义:列表(Iist)是一组有序存储的数据,也是python常见的序列之一,序列中的每个元素都分配一个索引,第一个元素索引是0,第二个元素索引是1,依此类推。序列都可以进行的操作包括索引,切片,加,乘,检查成员。
列表表达符为:[]
定义列表的两种方法:
方法一:list1=[1,2,3,4] #直接通过如进行定义
方法二:list2=list('1234') #使用list()方法进行定义
列表中对应的函数
1、索引和切片赋值
list1 = [1,88,'test','duoceshi']
list1[0] = 666
list1[2:] = list('123’)
2、列表中文打印乱码解决方法
a=[1,2,3,"中国"]
print(str(a).decode('string_escape‘))
decode():指定编码格式
string-escape:编码格式,能解决因为被转义的问题
3、append函数:添加一个元素
Iist1=[1,2,3,4]
list1.append('duoceshi')
print (list1)
4、extend函数:连接两个列表
Iist1=[1,2,3,4,5]
list2=[6,7,8]
list1.extend(list2)
print (list1)
注意:extend与append方法的相似之处在于都是将新接收到参数放置到已有列表的后面
append方法可以接收任意数据类型的参数,并且追加到list尾部
extend方法一般和列表还有字符串进行拼接。
5、insert(index,value)函数:在指定位置插入一条数据
Iist1=[1,2,3,4]
list1.insert(0,'test')
6、removel函数:移除元素
list1=[1,2,3,4,1]
list1.remove(1),结果为:[2,3,4,1]
总结:如果列表中有多个相同的元素,会删除前面那个
7、索引删除值
list1=[1,2,3,4]
del list1[0] #结果为[2,3,4]
8、index函数:在列表中查找元素所对应的索引值
Iist1=[1,2,3,4]
print (list1.index(1))
9、sort函数:实现列表的升序排列
list1=[1,2,3,4,1]
list1.sort()
print (list1)
10、sorted函数:实现降序排列
list1=[1,2,3,4,1]
print(sorted(list1,reverse=True))
#reverse=False是升序排序
11、reversel函数:列表元素反转
Iist1=[1,2,3,4]
list1.reverse()
12、pop函数:
list1=[1,2,3,4]
print (list1.pop(0))
1.默认移除列表最后一个元素,并返回元素的值
2.移除指定位置的元素list1.pop(0)表示移除第一个元素
3.在列表中p0p函数是唯一一个既能改变列表元素又有返回值
(5)元组
定义:元组(tuple)是Python中常用的一种数据结构。元组由不同的元素组成,每个元素可以存储不同类型的数据,如字符串、数字、甚至元组。元组是'写保护'的,即元组中元素作为一个整体,创建后不能再做任何修改操作。
元组表达符为:0
元组的定义:tuple1=(1,2,3)
注意:当元组只有一个元素时,后面要加逗号,如:tuple1=(1,)
元组中常见的操作
1、元组转换为列表
tuple1 (a','b','c','d')
list1 = list(tuple1)
print(list1,type(list1))
2、列表转换为元组
list1=[1,2,3,4]
tuple1=tuple(list1)
print (tuple1,type(tuple1))
3、元组中的值是不可以直接改变的
tuple1=(a','b','c")
tuple1.insert(0,'d')
print(tuple1)
4、元组中的值是可以间接来改变
tuple1 = ('a','b','c','d')
list1=list(tuple1) #先改成列表
list1[1] = 'test' #通过列表改值
tuple1 = tuple(list1) #在转换成元组
print(tuple1)
5、元组和列表的区别
相同:
a、都是序列类型的容器对象,可以存放任何类型的数据
b、支持切片、迭代等操作
不同:
a、list是可变的对象,元组tuple是不可变的对象
b、tuple不可变,所以使用tuple可以使代码更安全
(6)字典
定义:
1、字典(dict)是另一种可变容器模型,且可存储任意类型对像。字典的每个键值key:value对用冒号:分割,每个键值对之间用逗号分割,整个字典包括在大括号{}中
2、字典同时是无序,字典都是以键值对的形式存在,先键后值,键是唯一的,值且不唯一
字典表达符:{}
字典的定义方式:
方式一:
dict1={'name':'duoceshi','age':18} #通过{}直接定义
方式二:
dict1=[('a',1),('b',2),('c',3)]
dict2 = dict(dict1) #通过dict()方法定义
字典中常见的函数
1、添加一个键值对
dict1 = {"name":"xiaowang","age":"10"}
dict1['sex']=1 如果字典里已经有这个键,旧数据将会替换
print (dict1)
2、取出键返回列表
dict1 = {"name":"xiaowang","age":"10"}
print(dict1.keys())
3、取出值返回列表
dict1 = {"name":"xiaowang","age":"10"}
print(dict1.values())
4、取出具体键的值
dict1 = {"name":"xiaowang","age":"10"}
print(dict1['name'])
5、字典添加元素setdefault()
dict1 = {'name':xiaowang,'age':18}
dict1.setdefault('sex','1')
print (dict1)
注:如果插入数据键已经在字典里,插入是不生效的,默认值为空时,插入数据为None
6、删除字典
dict1 = {"name":"xiaowang","age":"18","sex":"1"}
del (dict1)
print(dict1)
7、删除指定的键,连同值也删除
dict1 = {"name":"xiaowang","age":"18","sex":"1"}
del (dict1["name"])
print (dict1)
8、字典的遍历:for...in...遍历字典
dict1 = {'name':xiaowang,'age':18}
for key in dict1:
print (key,dict1[key])
9、使用litems()完成遍历
dict1 = {'name':xiaowang,'age':18}
for key,value in dict1.items():
print (key,value)
10、pop(key)函数,删除指定键并返回删除的值
dict1 = ("name":"xiaowang","age":"18","sex":"1")
print(dict1.pop("name"))
12、clear()清空字典所有项
dict = ['name':xiaowang,'age':18]
dict.clear()
print(dict)
13、get(key)方法,通过key获取值,当键不存在,返回None
dict = {'name':xiaowang,'age':18}
print(dict.get('name'))
14、fromkeysi函数可以给具体的键指定值
dict1 = {'name':xiaowang,'age':18}
print ({}.fromkeys(['name','age'])) #不指定默认值
print({}.fromkeys('name,'age'],'duoceshi) #指定默认值为'duoceshi’
15、has_key函数检查字典是否有指定的键,有返回True,没有返回False
dict1 = {'name':xiaowang,'age':18}
print(dict1.has_key('name')) #返回true,因为键存在
16、popitem函数随机返回并删除字典中的键值对(一般删除末尾对)
如果字典已经为空,却调用了此方法,就报出KeyError异常
dict1 = {'name':xiaowang,'age':18,'class':24}
print(dict1.popitem())
print(dict1)
17、update函数利用一个字典更新另外一个字典
dict1 = {'name':xiaowang,'age':18}
dict2 = {"sex":1}
dict1.update(dict2)
print(dict1)
注意:如果要更新的元素项在原字典里存在,则把原来的项覆盖
(7)集合
集合:最重要的功能就是去重
1、可变集合set
list1 = [1,1,1,88,88,'duoceshi,'dcs']
set1 = set(list1)
set1.add('dcs')
set1.remove('dcs')
set1.pop() #把最前面这个给删除了
set1.clear()
print(set1)
2、不可变集合frozenset
test = 'hello'
a = frozenset(test)
b = a.copy()
b.add('888') #报错AttributeError:'frozenset' object has no attribute 'add'
print(b)
8.判断循环语句
(1)if语句
1、if条件判断语句单分支
单分支格式:
if 判断条件:
语句块1.…
else:
语句块2..
2、if条件判断语句多分支
多分支格式
if 判断条件1:
语句块1…
elif 判断条件2:
语句块2…
elif 判断条件3:
语句块3.…
else:
语句块n
3、if条件判断语句中的三目运算
三目运算基本格式:
name = input('请输入您的用户名:")
print('在上海'if name=='xiaowang'else'在深圳)
4、if语句之if的嵌套语句(if中包含if)
嵌套语句格式
if判断条件1:
语句块1
if判断条件2:
语句块2
else:
语句块3
else:
语句块4
(2)while循环语句
while语句的格式:
while条件表达式:
循环体语句
while什么时候进入循环?当循环条件成立时,进入循环
while什么时候退出循环?当循环条件不成立时,退出循环
注意:在写while循环语句时一定要让循环条件发生变化,否认很容易陷入死循环中
i=1
sum=0
while i<=10
sum+=
i+=1
print (sum)
i=1
while i<=5:
print("我是第%d次循环"%i
i+=1
else:
print("结束循环")(3)for循环
1、for循环的语法格式如下:
for ...in...
语句块
2、先熟悉下range()函数:如果需要遍历一个数字序列,可以使用oython中内建的函数range()
for i in range (10) #打印0到9、不包含10
for i in range (1,10) #打印1到9、不包含10
for i in range(0,10,2) #打印结果:0,2,4,6,8不包含10
i=1
sum 0
for i in range(1,11):
sum+=1
print (sum)
实例二:可以遍历字符串、列表、元组、字典、集合
list1 ['xiaowang','xiaochen','xiaoliu']
for i in list1:
print (i)
else:
print"循环遍历结束"(4)continue语句
用法:continue语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
list=[1,2,3,4,5,6,7,8,9]
for i in list:
if i==6:
continue
print (i)
(5)break语句
用法:语句会立即退出循环,在其后边的循环代码不会被执行。
list=[1,2,3,4,5,6,7,8,9]
for i in list:
if i==6:
break
print (i)
9.函数
(1)什么是函数
定义:函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Pytho提供了许多内建函数,比如prit0。但你也可以自己创建函数,这被叫做用户自定义函数。
(2)函数的声明和调用函数
1、可以使用def关键字来创建Python自定义函数,其基本语法结构如下:
def 函数名(参数列表)
函数体
函数名() #调用函数
2、参数列表可以为空,即没有参数,也可以包含单个参数、多个参数、默认参数、可变长参数、参数之间使用逗号分隔。
3、函数中无参数:
def func()
函数体
func() #调用函数
4、函数的三种调用方式
a、在本模块中调用
b、if _ _name_ _=='_ _main_ _':主函数调用
c、在其他模块中调用
主函数的解释:
解释:
if _ _name_ _ =='_ _main_ _': 是函数的入口,也称为主函数
_ _name_ _是当前模块名,当模块被直接运行时模块名为_ _main_ _,这句话的意思就是,当模块被直接运行时,以下代码块将被运行,当模块是被导入时,代码块不被运行。
5、函数中有单个参数
def func(name):
print "欢迎"+name+"来到多测师"
func("大家") #调用函数
6、函数中有多个参数
def func(action,name):
print action+name+"来到多测师"
func("欢迎","大家") #调用函数
7、函数定义时带上默认参数(缺省参数)
def func(action,name,where="多测师"):
print action+name+"来到"+where
func("欢迎","大家") #调用函数未给默认参数传新值,则函数使用默认值
func("欢迎","大家","上海多测师) #调试函数给默认参数传新值,则函数使用新值
注意:当多种参数同时出现在函数中,默认参数要放在最后的位置
8、可变长参数中的可变长元组"*"表示的是可变长元组
def func(*name):
for i in name:
print i
func("duoceshi","dcs","xiaowang")
9、可变长参数中的可变长字典"*"表示的是可变长字典
def func(**name):
for i in name.items():
print i
dict1 {"name":"xiaowang","age":18}
fun5(**dict1)
注意:当可变长元组和可变长字典同时出现时,默认将可变长字典放后面
(3)函数的变量和作用域
1、在函数中也可以定义变量,在函数中定义的变量被称之为局部变量,局部变量只在定义它的函数内部有效。
2、在函数体之外定义的变量,我们称之为全局变量。
实例讲解一:
定义的函数内部的变量名如果是第一次出现,且在=符号前,那么就可以认为是被定义为局部变量。在这种情况下,不论全局变量中是否用到该变量名,函数中使用的都是局部变量。例如:
num=100#全局变量
def func():
num=200 #局部变量
print num #打印局部变量
func() #函数调的是局部变量
print num #打印全局变量
实例讲解二:
函数内部的变量名如果是第一次出现,且出现在=符号后面,且在之前已被定义为全局变量,则这里将引用全局变量。例如:
num=100
def func():
sum num+100 #引用全局变量
print sum
func()
实例讲解三:
在函数中将某个变量定义为全局变量时需要使用关键字global、例如:
num=100
def func():
global num #声明成一个全局变量、原有全局变量的值会被覆盖
num=200
print num
func()
print num
(4)函数的返回值
Python中,用def语句创建函数时,可以用return语句指定应该返回的值,该返回值可以是任意类型。需要注意的是,retum语句在同一函数中可以出现多次,但只要有一个得到执行,就会直接结束函数的执行。
函数中,使用retum语句的语法格式如下:
return [返回值]
其中,返回值参数可以指定,也可以省略不写(将返回空值None)。
返回值的作用
1、在程序开发中,有时候会希望一个函数执行程序结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理。
2、返回值是函数完成工作后,最后给到调用者的一个结果。
3、在函数中使用return关键字可以返回结果。
4、调用函数的一方可以使用变量来接收函数的返回结果。
(5)内置函数
format()函数是一种格式化字符串的函数,该函数增强了字符串格式化的功能。
基本语法:是通过{}来代替以前的%
1、不设置指定位置,按默认顺序
a="{}{}".format("hello","duoceshi")
2、设置指定索引位置输出
a="{0}{1}{0}".format("hello","duoceshi")
3、设置参数输出
a="姓名:{name,年龄:{url}".format(name="duoceshi",age=18)
4、对列表进行格式化
a=['多测师','www.duoceshi.com']
大括号里面的0代表的是列表、中括号里面的0和1是列表元素对应的索引位
b="网站名:{0[0]},地址{0[1]}".format(a)
5、对字典进行格式化"*“表示可变长字典
a=("name":"多测师","url":"www.duoceshi..com"}
b="网站名:{name},地址:{url}".format(**dic)
zip()函数
1、zip() 函数用于将可迭代的对象作为参数,将对像中对应的元素打包成一个个元组,然后返回由这些元组组成的列表,如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
实例讲解:
a=['name,'url']
b=['duoceshi','www.duoceshi.cn']
c=zip(a,b) #通过zip方法转换成元组放入列表当中
d=dict(c) #利用字典的方法转换成字典
open()函数
open0函数用于打开一个文件,创建一个file对象
语法:open(file,mode),模式有r(只读),w(写入覆盖),a(写入追加)
1、读的模式:r(只读)
o=open("C:\\aa.txt",'r');
a=o.read() #读取文件中所有内容返回字符串
b=o.readline() #读取文件中第一行内容
c=o.readlines() #读取文件中所有内容返回列表
2、读相关函数文件中包含中文字符的解决方法
o open(r'C:\aa.txt",'r')
all o.read()
print all..decode('gbk') #进行解码为gbk编码
3、路径中包含中文字符的解决方法
path=unicode(r'C:\多测师aa.txt',encoding='utf-8‘)
o open(path,'r’)
a o.read()
print a
4、写的模式:w(写入覆盖)
o=open("C:\\aa.txt",'w');
o.write("hello duoceshi")
o.writelines("hello duoceshi")
o.close() #关闭文件
open()函数扩展用法
with open("C:\\aa.txt",'r')as f:
a = f.read()
b = f.readline()
c = f.readlines()
d = f.write()
e = f.writelines()
用with语句的好处,就是到达语句末尾时,会自动关闭文件,即便出现异常。
10.模块
模块的定义
Python模块(Module),是一个Python文件,以.py结尾,包含了Python对象定义和Pythoni语句。
模块让你能够有逻辑地组织你的Python代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
(1)模块的导入
1、import语句
模块定义好后,可以使用ipot语句来引入模块,语法如下:
import module1,module2.....module N
比如要引用模块time,就可以在文件最开始的地方用import time来引入
在调用time模块中的函数时,必须这样引用:
模块名.函数名(如:time.sleep(2))
注意:一个模块只会被导入一次,不管你执行了多少次import,这样可以防止导入模块被一遍又一遍地执行
注意点:模块导入1次就可以,模块未被调用,就是置灰,调用就是高亮
2、from...import * 语句
这里提供了一个简单的方法来导入一个模块中的所有项目
例如我们想一次性引入time模块中所有的东西
语法如下:
导入time模块中的所有类、函数变量等等
from time import *
#格式:from 模块名 impot 函数名 / from 模块名 impot 所有的函数
from time import sleep
print(1)
sleep(10)
print(2)3、from...import...语句
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中语法如下:
from modname import name1,name2...nameN
要导入time模块的sleep函数,使用如下语句:
from time import sleep
要导入time模块中的sleep函数并取别名,使用如下语句:
from time import sleep as s
#模块与模块之间的调用
#aa文件
def hs3():
print(3)
def hs4():
print(4)
#bb文件
from bao.aa import *
hs4()
hs3()
#通过路径调用模块
#aa文件
def hs3():
print(3)
def hs4():
print(4)
#通过模块的别名调用
#bb文件
from bao.aa import hs3 as f
f()(2)time模块
time模块中常见的方法:
time() #1970到现在的经过的秒数
ctime() #固定格式的当前时间
sleep(3) #休眠单位是秒
asctime() #转换为asc码显示当前时间
strftime() #时间格式化
from time import *
print(time()) #1726278734.3321135
print(ctime()) #Sat Sep 14 09:52:33 2024
sleep(2) # 强制等待
print(asctime()) #Sat Sep 14 09:53:17 2024
print(strftime(" %H-%M-%S %y-%m-%d ")) # 09-54-37 24-09-14
import time
print(time.time()) #1726278734.3321135
print(time.ctime()) #Sat Sep 14 09:52:33 2024
time.sleep(2) # 强制等待
print(time.asctime()) #Sat Sep 14 09:53:17 2024
print(time.strftime(" %H-%M-%S %y-%m-%d ")(3)random模块
生成随机浮点数、整数、字符串,甚至帮助你随机选择列表序列中的一个元素,打乱
组数据等
random模块中常见的方法:
random.random() #该方法是生成0-1之间的浮点数,但是能取到0,但是取不到1
random.randint(x,y) #该方法生成指定范围内整数,包括开始和结束值
random.randrange(x,y,step) #生成指定范围内的奇数,不包括结束值
random.randrange(x,y,step) #生成指定范围内的偶数,不包括结束值
random.sample(seq,n) #从序列seq中选择n个随机且独立的元素
random.choice(test) #生成随机字符
random.shuffle(list) #洗牌(随机数列)
hashlib.md50 #MD5加密
import randomprint(random.random()) #0-1之间的小数
print(random.randint(1,10)) #指定一个范围内的一个随机数 整数
print(random.randrange(1,100,2)) #生成指定范围的奇数
print(random.randrange(0,100,2)) #生成指定范围的偶数
list=["zs","lisi"," 王五","牛八","刘十"]
print(random.sample(list,3)) #随机生成一个集合,多个数
print(random.choice(list)) #随机生成一个字符
random.shuffle(list) #洗牌
print(list)---------------------------------------------------------------------------------------------------------------------------------
课堂练习:
1、使用random模块随机生成手机号码、自己定义手机号码开头的前三位
2、用random模块随机生成6位数验证码
3、通过d5加密算法把随机生成的6位数验证码进行加密返回16进制的字符串
---------------------------------------------------------------------------------------------------------------------------------
(4)os模块
os模块提供了多数操作系统的功能接口函数。当os模块被导入后,它会自适应于不同的操作系统平台,根据不同的平台进行相应的操作,在python编程时,经常和文件、目录打交道,所以离不了os模块。
os模块是对平台中的文件、目录进行操作。
os模块中常见的方法:
os.getcwd() 获取当前执行命令所在目录
os.path.isfile() 判断是否文件
os.path.isdir() #判断是否是目录
os.path.exists() #判断文件或目录是否存在
os.listdir(dirname) #列出指定目录下的目录或文件
os.path.split(name) #分割文件名与目录
os.path,join(path,name) #连接目录与文件名或目录
os.mkdir(dir) #创建一个目录
os.rename(old,new) #更改目录名称
import os
url1=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\bao"
url2=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\bao\test4.py"
url3=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\bao\test5.py"
url4=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\bao\dcs.py"
url5=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\bao\dcs1.py"
url6=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\bao\aa.py"
print(os.getcwd()) #相对路径,当前执行模块的所有目录
print(os.path.isfile(url1)) #False 判断是否文件
print(os.path.isfile(url2)) #True
print(os.path.isdir(url1)) #True
print(os.path.isdir(url2)) #False 判断是否目录
print(os.path.exists(url2)) #True 判断文件是否存在
print(os.path.exists(url3)) #False 判断文件是否存在
print(os.listdir(url1)) #列出指定目录下的目录和文件
print(os.path.split(url2)) #分割文件和目录
print(os.path.join(url1,"dcs.py")) #拼接一个路径
# os.mkdir(url4)# 创建目录
# os.rename(url4,url5)
os.remove(url6) #删除文件python os模块 对文件夹、文件(文件操作函数)
os.getcwd() #返回当前工作路径
os.path.isabs() #判断是否是绝对路径
os.path.isfile() #检验给出的路径是否是一个文件
os.path.isdir() #检验给出的路径是否是一个目录
os.sep #文件的路径分隔符 如:在windows上是 '\' 而在Linux上是 '/'
os.walk() #文件遍历
如:def file_name(file_dir):
for root, dirs, files in os.walk(file_dir):
print('root_dir:', root) # 当前目录路径
print('sub_dirs:', dirs) # 当前路径下所有子目录
print('files:', files) # 当前路径下所有非目录子文件
file_name('E:/vmware')
os.path.splitext() #分离扩展名
os.system() #运行shell命令:
os.path.exists() #检验给出的路径是否真地存:
os.getenv() 与os.putenv() #读取和设置环境变量
os.linesep #给出当前平台使用的行终止符 如: windowss使用'\r\n' ,Linux使用'\n'而Mac使用'\r'
os.name #指示你正在使用的平台: 如:对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'
os.chmod(file) #修改文件权限与时间戳
os.exit() #终止当前进程
对目录的操作:
os.makedirs("file1/file2/file3") #创建文件夹目录. 创建多级目录
os.mkdir("file") # 创建文件夹. 但是上级目录必须存在
os.copy("oldfile","newfile") #oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
os.rename("oldname","newname") #重命名文件(目录) 文件或目录都是使用这条命令
os.removedirs() # 删除多级目录, 要求必须是空的
os.rmdir("dir") #只能删除空目录
os.listdir() #返回指定目录下的所有文件和目录名
os.path.split(path) #返回一个路径的目录名和文件名
os.path.dirname() #获取路径名
os.path.basename() #获取文件名
os.path.getsize(filename) #获取文件大小
os.chdir("path") 换路径
Python文件读写操作
os.remove() #删除文件 或空文件夹
os.stat() #获取文件属性
with open("abc.txt",mode="w",encoding="utf-8") as f: #写文件,当文件不存在时,就直接创建此文件
pass
encoding #文件编码
mode #打开模式
name #文件名
关于open 模式:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
lines = object_file.readlines( ) #读第一行
os.remove() #删除文件 或空文件夹
os.stat() #获取文件属性
with open("abc.txt",mode="w",encoding="utf-8") as f: #写文件,当文件不存在时,就直接创建此文件
pass
encoding #文件编码
mode #打开模式
name #文件名
lines = object_file.read( ) #读所有的内容
lines = object_file.readline( ) #读第一行
lines = object_file.readlines( ) #读第一行,以列表的格式
for line in file_object: #如果文件是文本文件,还可以直接遍历文件对象获取每行:
print(line)
(5)re正则模块
1、正则匹配,使用re模块
2、正则表达式是一种对字符和特殊字符操作的逻辑公式,用正则表达字符来过滤的逻辑
3、re正则表达式作用:快速高效查找和分析字符,进行匹配如:查找、比对、匹配、替换、插入、添加、删除等
实现一个编译查找,一般在日志处理或者文件处理时用的比较多正则表达式主要用于模式匹配和替换工作。
预定义字符集匹配:
\d:数字0-9
\D:非数字
\s:空白字符
\n:换行符
\r:回车符
re模块数量词匹配:
符号^:表示的匹配字符以什么开头
符号$:表示的匹配字符以什么结尾
符号*:匹配*前面的字符0次或n次
eg: ab* 能匹配a 匹配ab 匹配abb
符号+:匹配+前面的字符1次或n次
符号?:匹配?前面的字符0次或1次
符号{m}:匹配前一个字符m次
符号{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是正整数
re模块相关函数
1、match
从第一个字符开始匹配,如果第一个字符不是要匹配的类型、则匹配失败并报错
注意:如果规则带了'+',则匹配1次或者多次,无'+'只匹配一次
import re
str1="abcdeefgamn"
s=re.match("b",str1)
print(s) #None2、search
从第一个字符开始查找、一找到就返回第一个字符串,找到就不往下找,找不到则报错
#案例:
import re
str1="abcdeefgamn"
s=re.search("a",str1)
print(s) #<re.Match object; span=(0, 1), match3、findal
从第一个字符开始查找,找到全部相关匹配为止,找不到返回一个列表[]
#案例:
import re
str1="abcdeefgamn"
s=re.findall("e",str1)
print(s) #4、compile
编译模式生成对象,找到全部相关匹配为止,找不到返回一个列表[]
Python中常见的模块:
time模块
random模块
hashlib模块
os模块
re模块
string模块
xlrd模块
json模块
sys模块
(6)String模块
import string
print(string.digits) #0123456789
print(string.hexdigits) #0123456789abcdefABCDEF
print(string.ascii_uppercase) #ABCDEFGHIJKLMNOPQRSTUVWXYZ
print(string.ascii_lowercase) #abcdefghijklmnopqrstuvwxyz
print(string.ascii_letters) #abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
print(string.ascii_letters+string.digits) #abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789
#案例:生成一个6位数的验证码(包含大小写,数字)
#方法1:
import random
import string
nr=string.ascii_letters+string.digits
print(''.join(random.sample(nr,6)))
#方法2:
import random
import string
nr=string.ascii_letters+string.digits
for i in range(6):
s=random.choice(nr)
print(s,end="")(7)加密模块
md5、rsa、AES ,DES.BASE
在线加解密:ttp://encode.chahuo.com/
1、bash64 模块
import base64
a=base64.b64encode(b"123456")
print(a) #b'MTIzNDU2'
b=base64.b64decode(b'MTIzNDU2')
print(b)2、md5
hashlib 模块
python3将MD5 归纳到hashlib 模块,译作:‘散列’,直译为‘哈希’。
#案例1:
import hashlib
m=hashlib.md5()
m.update(b"123456")
print(m.hexdigest()) #e10adc3949ba59abbe56e057f20f883e
#案例2:
import hashlib
m=hashlib.sha512()
m.update(b"123456")
print(m.hexdigest()) #e10adc3949ba59abbe56e057f20f883e
#练习:将验证码进行加密
import hashlib
nr=string.ascii_letters+string.digits
str=[]
for i in range(6):
s=random.choice(nr)
str.append(s)
yzm=''.join(str)
m=hashlib.md5()
m.update(yzm.encode("utf-8"))
print(m.hexdigest()) #8050115c4fdaebaa102edcb4fd30bbdf【实操】
案例: \d:数字0-9 import re str1="abcd1eefga3m6n" s=re.findall("\d",str1) print(s) #\D:非数字案例: import re str1="abcd1eefga3m6n" s=re.findall("\D",str1) print(s) #\s:空白字符import re str1="abcd1 eefg a3 m6n" s=re.findall("\s",str1) print(s) #\n:换行符import re str1="abcd1 ee\nfg a3 m6\n n" s=re.findall("\n",str1) print(s) #\r:回车符re模块数量词匹配: #符号^:表示的匹配字符以什么开头 import re str1="abcd" s=re.findall("^a",str1) print(s) # #符号$:表示的匹配字符以什么结尾 import re str1="abcd" s=re.findall("d$",str1) print(s) # #符号*:匹配*前面的字符0次或n次 import re str1="abcd" s=re.findall("a*",str1) print(s) # #['a', '', '', '', ''] #eg:ab* 能匹配a 匹配ab 匹配abb符号+:匹配+前面的字符1次或n次 import re str1="abaaaacaad" s=re.findall("a+",str1) print(s) # ['a', 'aaaa', 'aa'] #符号?:匹配?前面的字符0次或1次 import re str1="abaaaacaad" s=re.findall("a?",str1) print(s) # ['a', '', 'a', 'a', 'a', 'a', '', 'a', 'a', '', ''] #符号{m}:匹配前一个字符m次 import re str1="abaaaacaad" s=re.findall("a{3}",str1) print(s) # ['aaa'] #符号{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是正整数 import re str1="aassaaabaaaacaaaaad" s=re.findall("a{3,5}",str1) print(s) # ['aaa']\w匹配[A-Za-z0-9] import re str1="aass!!aa#aa1aa1d" s=re.findall("\w",str1) print(s) # ['aaa']\W匹配非[A-Za-z0-9]import re str1="aass!!aa#aa1aa1d" s=re.findall("\W",str1) print(s) # ['aaa']
(8)json模块
(1)python中的json格式是轻量级的文本数据交互格式
(2)json和字典以一样
一、将python数据类型换成字典
json.dump
json.dumps
二、将json格式转换成python类型
(1)dumps 将python类型转换成json格式
import json
d={"name":"zs","age":18}
print(type(d)) #<class 'dict'>
print(d) #{'name': 'zs', 'age': 18}
js=json.dumps(d)
print(js) #{"name": "zs", "age": 18}
print(type(js)) #<class 'str'>(2)dump
将python类型转换成json格式保存为json文件中
import json
d={"name":"zs","age":18}
print(type(d)) #<class 'dict'>
print(d) #{'name': 'zs', 'age': 18}
js=json.dump(d,open(r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\bao\ss.json","w"))(3)loads 将json格式转换成python类型对象
import json
str1='{"name": "zs", "age": 18}'
print(type(str1)) #<class 'str'> json格式
d=json.loads(str1)
print(d) #{'name': 'zs', 'age': 18}
print(type(d)) #<class 'dict'>(4)load 将文件中的json格式转换成python类型对象
import json
d=json.load(open(r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\bao\ss.json","r"))
print(d) #{'name': 'zs', 'age': 18}
print(type(d)) #<class 'dict'>总结:
1、将python字符类型转化成json格式
dumps 、dump
2、将json格式转换成python字符类型
loads 、load
3、python字符类型:
字符串、字典、元组、列表、集合
(9)xlrd模块
下载方式
方式一:在dos下,输入pip install xlrd==1.2.0
方式二:在pycharm中,file-setting-project 工程项目名-project interpreter-python3.7-【+】-xlrd-勾选specific version-选版本-install package
在python模块中导入xlrd模块
新建一个xlsx的表格并编辑内容 或者 选择一个已有内容的xls表格
通过语句读取:路径:E:\ls\kk\aa.xlsx 确定页面:sheet1 ,sheet2等
案例:
import xlrd
data=xlrd.open_workbook(r"E:\ls\kk\aa.xlsx")
# print(data.sheet_names()) #获取页面名称['Sheet1', 'Sheet2', 'Sheet3']
# print(data.sheet_by_index(0)) #第一页的而对象
# print(data.sheet_by_name("bg"))
ym=data.sheet_by_name("bg")
# print(ym.row_values(1)) #获取第一行中的所有数据 0是索引,第一行
# print(ym.row_values(0,1,2)) #0表示第一行,1表示索引第2列,不包含结束列表
# print(ym.row_values(5,0,1)) #5
# print(ym.row_values(8,1,2)) #['a8']
# # print(ym.col_values(0)) #通过索引0 第一列
# print(ym.col_values(0,3,6)) #0表示列,3表示
for i in range(ym.nrows):
print(ym.row_values(i)[0]) #遍历一列值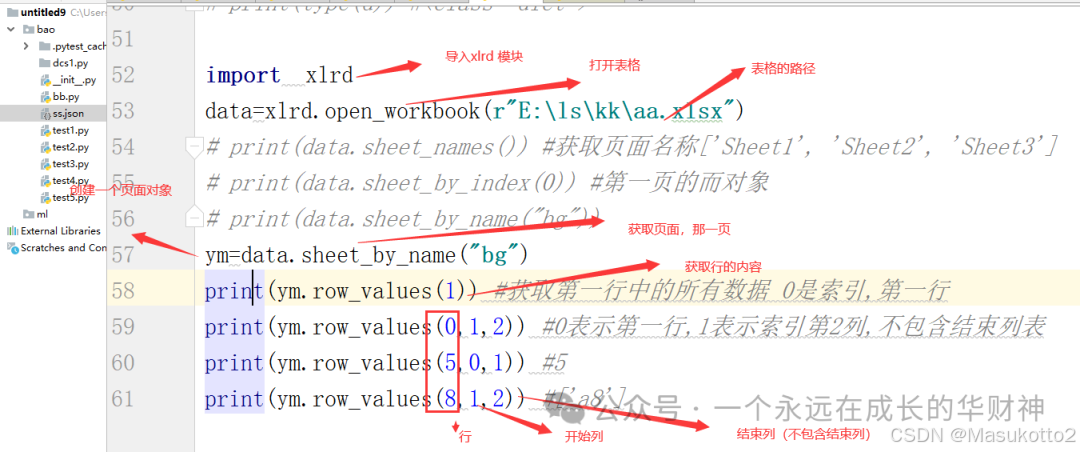
for i in range(ym.nrows):
print(ym.row_values(i)[0]) #遍历一列值11.类与对象
类的定义
(1)类用来描述具有相同的属性和方法的对象的集合。
人类===张三(两个眼睛、一个鼻子等)
(2)对象、实例变量、类变量、方法、实例、
(1)面向对象的基本概念
类(class):用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对像是类的实例。
实例化:创建一个类的实例,类的具体对象。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
方法:类中定义的函数
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。
类变量通常不作为实例变量使用。
(2)定义和使用类
在Python中,可以使用class:关键字来声明一个类,基本语法如下:
class People(object): #新式类
def __init__(self,name): #构造函数又称为构造方法
self.name = name #创建一个对像p
p = People('xiaowang')
#定义一个类
class Hz(object): #新式类
pass
class Hz1():
pass
class Hz2:
pass
#类的格式
class Hz(object): #创建类名
name="lisi"#类变量
def __init__(self,name,age): #构造函数
self.name=name # 实例变量
self.age=age ## 实例变量
def a(self): #一个函数,也叫方法
print(self.name)
def b(self): #方法
print(self.age)
def c(self):
print(self.name,self.age)
if __name__ == '__main__':
dx=Hz("zs",18) #创建类的对象dx ,调用函数
dx.a() #通过类的对象调用方法
dx.b()#通过类的对象调用方法
dx.c()__init__是一个构造函数,该函数是两个下划线开头和两个下划线结束,其作用就是当创建类的对象和实例时系统会自动调用构造函数,通过构造函数对类进行初始化操作。
(3)根据类创建对象
对象是类的实例,我们把人类理解成一个类的话,那么在人类中的具体的一个人就成了这个类的一个对象,所以说只要在类中定义了对象才能使用类。创建对象方法如下:
对象名 = 类名()
class People: #经典类
def __init__(self,name): #构造函数又称为构造方法
self.name = name #实例变量
p = People('xiaowang') #创建一个对象p
名词解释:
1、定义类的时候iit是一个构造函数,该函数是两个下划线开头和两个下划线结束,其作用就是当创建类的对象和实例时系统会自动调用构造函数,通过构造函数对类进行初始化操作
2、定义类的时候init方法中有一个参数self,这也是类中的方法与普通函数的区别,类的中的方法必须有之个参数sf,而且位于参数列表的开头,在类中self就是代表类的当前类的实例(对象)自身,在python调用时无需传值,python会将对象自动传给self接受
(4)类中的类变量、实例变量
在整个类里面有的属于类的,有的属于对象的,那么属于类的属性叫类变量,属于对象的属性叫做实例变量。
class People(object):
head=1 #类变量
def __init__(self,name):
self.name=name #实例变量
#创建对象
p = People('xiaowang')
(5)类中的实例方法、动态方法、静态方法
class People(object):
def_init_(self,name):
self.name=name #实例变量
def play(self): #实例方法
print(self.name + '打篮球')
#创建对象
p = People('xiaowang')
People.play() #类调用实例方法
p.play() #对象调用实例方法
#类方法
@classmethod
def func1(cls):
cs.name1='我是一个类方法' #定义一个类变量
print(cls.name1)
#静态方法
@staticmethod
def func2():
print('我是一个静态方法')
#实例方法(self)、类的动态方法(cls)、静态方法(无)
class Hz1(object):
name=10
def __init__(self,name):
self.name=name #实例变量
def a(self):
print(self.name)
@classmethod #类方法
def b(cls): #
print(cls.name)
@staticmethod #静态方法也叫私有方法
def c():
print("wo是独立方法")
if __name__ == '__main__':
dx=Hz1("20")
dx.a()
dx.b()
dx.c()(6)类的三大特性
封装特性
1、类里面不光有属性还有方法。
2、这种将属性通过方法直接在类内部操作的形式叫做封装。这里的封装是把属性封装在类内部。
具体代码如下:
class People(object):
def __init__(self,name):
self.__name = name
def setName(self,newname)
self.name = newname
def getName(self):
return self.__name
p = People("xiaowang")
print(p._name) #报错
p.setName("xiaoxiaoming")
print(p.getName())(1)封装分为私有封装、公用封装
私有封装方法:
class Hz1(object): name=10 def __init__(self,name): self.name=name #实例变量 def a(self): print(self.name) def __f(self): print("f") def m(self): print(self.__f()) @classmethod #类方法 def b(cls): # print(cls.name) @staticmethod #静态方法也叫私有方法 def c(): print("wo是独立方法") if __name__ == '__main__': dx=Hz1("20") dx.a() dx.b() dx.c() # dx.f() dx.m()私有封装实例变量:
class Hz1(object): name=10 def __init__(self,name,age): self.__name=name #实例变量 self.__age=age def a(self): print(self.name) def __f(self): print("f") def m(self): print(self.__f()) @classmethod #类方法 def b(cls): # print(cls.name) @staticmethod #静态方法也叫私有方法 def c(): print("wo是独立方法") if __name__ == '__main__': dx=Hz1("20",18) print(dx.name) print(dx.age)
继承特性
1、继承:类的继承是面向对象程序设计的一个重要思想,继承时子类可以继承父类的内容,包括成员变量和成员函数。
2、在继承中一个类被另外一个类继承这个类称之为父类也称之为基类,则另外一个类则为子类也称之为派生类。
具体代码如下:
class Father(object): #Father继承object类
def rich man(self):
print'有钱'
class Son(Father):
def __init__(self):
Father.__init__(self) #继承父类的构造函数
def car(self):
print'喜欢跑车
s = Son() #根据子类创建对象单继承:
class F(object): def fh(self): print("富豪") class M(): def fp(self): print("富婆") class S(F): def qg(self): print("乞丐") if __name__ == '__main__': s=S() s.qg() s.fh()多继承:
class F(object): def fh(self): print("富豪") class M(): def fp(self): print("富婆") class S(F,M): def qg(self): print("乞丐") if __name__ == '__main__': s=S() s.qg() s.fh() s.fp()
多态特性
1、多态是以继和重写父类方法为前提,对所有子类实例化产生的对象调用相同的方法,执行产生不同的执行结果。
2、例如同样是人,但是当问起一个人的职业时会有不同的结果,可能是软件测试工程师,可能是HR
3、一个对象的属性和行为不是由他所继承的父类决定的,而是由其本身包含的属性和方法决定的。
class Animal(object):
def talk(self):
print(我是动物)
class Cat(Animal):
def talk(self):
print('喵喵)
class Dog(Animal):
def talk(self):
print(汪汪)
c Cat()
c.talk()多态:
class Hz(object): def __init__(self,a): self.a=a def ss(self): print(self.a) if __name__ == '__main__': dx=Hz("中国") dx.ss()
拓展:
1、装饰器
2、深浅拷贝
3、闭包
4、生成器、迭代器
5、is 和==的区别
六、UI自动化测试
selenium
1、selenium是python中的一个第三方库(讲课3.141.0版本)
2、通过python中的webdriver+selenium进行二次封装的库selenium2
3、特点:免费、安装简单、支持多语言、多平台、多浏览器
4、selenium安装:两种方式
1)dos中下载 >pip install selenium==3.141.0
2)在pycahrm中settin中的解释器下点击+号下载
5、安装浏览器驱动:
浏览器+对应版本的驱动
将驱动放到python下
存放的路径python路径下
对应版本镜像链接1:http://chromedriver.storage.googleapis.com/index.html
对应版本镜像链接2:https://registry.npmmirror.com/binary.html?path=chromedriver/
谷歌下载低版本:https://downzen.com/en/windows/google-chrome/versions/ 不同版本的谷歌#调试代码: from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 dx.maximize_window() #窗口最大化 time.sleep(2) #休眠2s dx.find_element_by_id("kw").send_keys("dcs")#通过id定位,输入dcs报错:
一、打开浏览器 (get)
案例1:打开一个浏览器
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度案例2:打开两个网址(覆盖)
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(2) dx.get("https://www.jd.com/")(3)打开两个网址(重开窗口)
import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(2) w="window.open('https://www.jd.com/')" dx.execute_script(w)二、时间等待
1、强制等待(不管能不能查找元素,都要等待规定的时间)
sleep
案例:
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(1) dx.get("https://www.baidu.com/")2、隐式等待(所在规定范围等待时间,如果提前找到元素,就节省时间)
语句:implicitly_wait
案例:
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 dx.implicitly_wait(10) dx.get("https://www.baidu.com/")3、显性等待
等待元素出现后,在进行下一步操作
三、refresh()刷新
语句:
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(3) dx.refresh() #刷新四、back 返回上一页
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(3) dx.get("https://www.jd.com/") time.sleep(3) dx.back() #返回上一页五、forward切换到下一页
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(3) dx.get("https://www.jd.com/") time.sleep(3) dx.back() #返回上一页 time.sleep(3) dx.forward() # 切换到下一页六、set_window_size设置页面窗口大小
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(3) dx.set_window_size(200,200)七、maximize_window() 窗口最大化
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(3) dx.maximize_window() #窗口最大化八、get_screenshot_as_file 截屏
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 time.sleep(3) dx.get_screenshot_as_file(r"E:\ls\cd\bd.png九、close 关闭当前窗口
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 print(dx.title) #查看标题 time.sleep(3) w="window.open('https://www.jd.com/')" dx.execute_script(w) print(dx.title) #查看标题 time.sleep(2) dx.close() # 关闭当前窗口十、quit 关闭所有的窗口
from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 print(dx.title) #查看标题 time.sleep(3) w="window.open('https://www.jd.com/')" dx.execute_script(w) print(dx.title) #查看标题 time.sleep(2) dx.quit() #关闭所有的窗口11、打印当前的抬头from selenium import webdriver #导入selenium这个模块中webdriver import time dx=webdriver.Chrome() #创建一个webdriver对象 dx.get("https://www.baidu.com/") #通过对象调用get打开百度 print(dx.title) #查看标题 time.sleep(3) w="window.open('https://www.jd.com/')" dx.execute_script(w) print(dx.title) #查看标题 time.sleep(2)
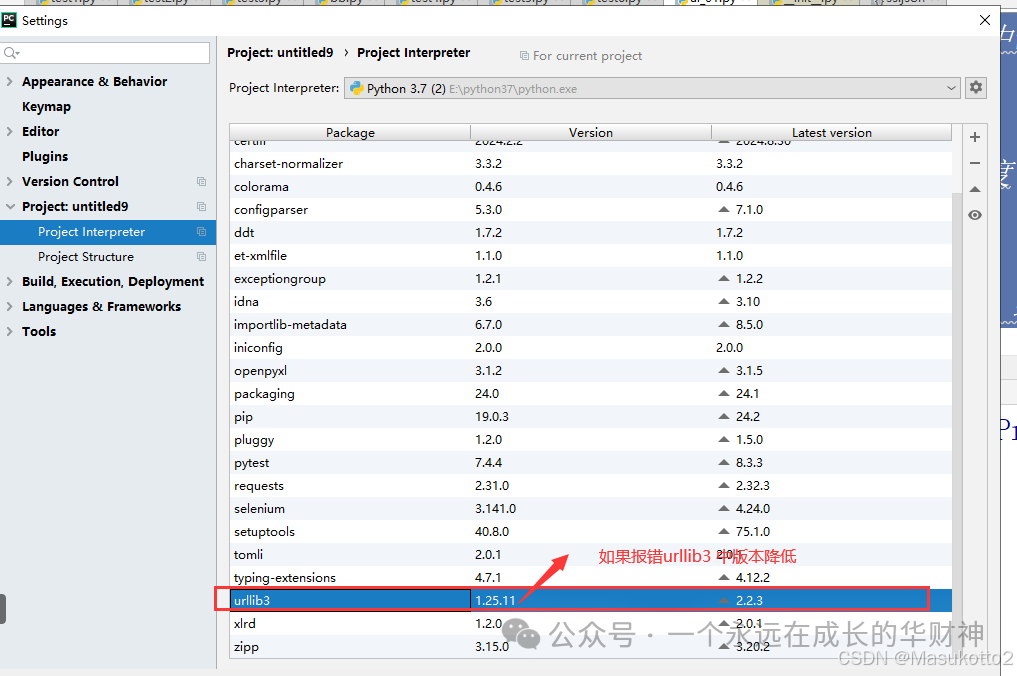
1.UI自动化测试理论基础
1、什么是UI自动化测试
原本用手工操作用户U页面的方式,用代码去实现自动化操作和验证的行为。
2、U自动化的优点
a.解决重复性的功能测试和验证
b.减少测试人员在回归测试时用例漏测和验证点漏测
c.减少回归测试的人力,时间的成本,提高测试效率
3、什么样的项目适合做自动化测试
a.需求比较稳定,需求变更不能大频繁
b.项目周期比较长
c.UI控件和页面元素不频繁变更
4、UI自动化测试的场景和作用
用来做回归测试
5、U自动化的覆盖率
a.用例数量覆盖率:占当前迭代版本功能测试用例总数的15-20%
b.场景覆盖率:占当前迭代版本功能场景的70-80%
6、面试题:U自动化测试和功能测试哪个更加重要?
答:都重要
a.功能测试是基础、只有在熟悉功能的前提下才能做好ui自动化测试
b.ui自动化可以帮助功能测试更加完善、节省人力、提高效率
2.元素定位
总结的5种定位方法:id定位、name定位、class定位、xpath定位、css定位
方法一:id定位
假如把一个元素看成是一个人的话,id可以看成是一个人的身份证,这里的id是指通过元素id属性进行定位
方法二:name定位
name属性好比一个人的名字,可能会重复,也可能会唯一。
方法三:class定位
class定位和name差不多,可能会重复,也可能会唯一。
方法四:xpath定位
xpath定位是通过路径进行定位元素。假如你想找一个人,这个人没有身份证,没有姓名,我们只知道他是xx省xx市x镇xx村x号的一个人。path就是通过这种层级关系找到元素。
path的绝对路径
我们从最底层开始,省市/镇/村/号,一级一级锁定想找的元素称为绝对路径
xpath的相对路径
相对路径是指从某一个层级开始查找元素,比如说已知这个人是某个镇的,那么我们可以从这个镇向下一级一级找到元素
xpath相对路径下通过元素本身属性定位 xpath = //*[@id = 'kw']
//表示某个层级下,*表示某个标签名,@id=kw表示这个元素有一个id属性,属性值是kw
xpath相对路径找上级定位
当一个刚出生的婴儿没有身份证,没有姓名,我们可以通过他的父亲定位他。只要能唯一的定位到他的父亲,就可以找到这个婴儿。
找上级
通过span标签定位input标签
xpath = //span[@class='bg s_ipt_wr']/input
找上上级
通过form标签定位input标签
xpath = //form[@id='form']/span[1]/input[1]
方法五:CSS定位
css定位方法更灵活,因为他用到更多的匹配符和规则
同样以百度输入框为例,我们来看csS如何定位
id选择器定位
css = #kw
class选择器定位
css=.s_ipt
其他属性定位
css=[name=wd]
父子定位
css=span>input
3.selenium2常用关键字

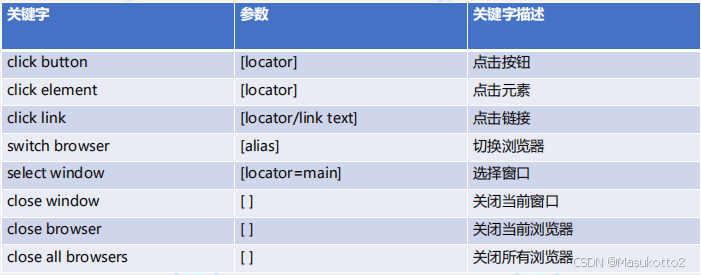
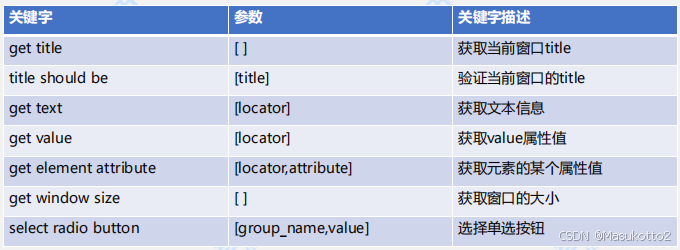
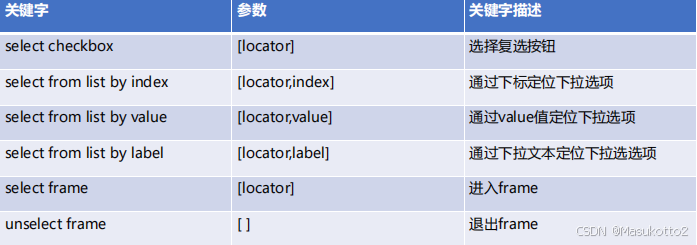
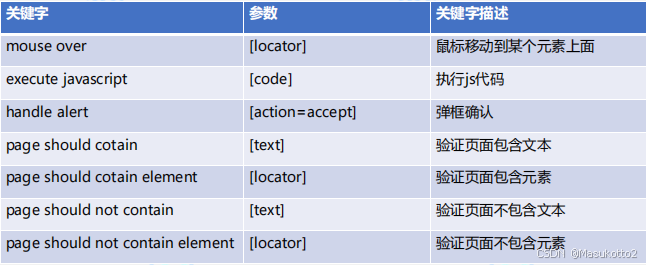
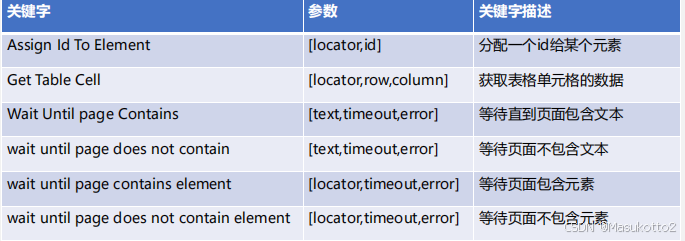
七、接口自动化测试
1、接口测试的定义
接口测试是对系统或组件之间的接口进行测试,主要是校验数据的交换,传递,以及交互逻辑依赖关系。
2、接口自动化测试的定义
通过自动化测试工具,编写代码实现对接口的测试。
3、接口自动化的优点
相比UI自动化测试,接口自动化测试收益更大,容易实现,维护成本低,高收益
4、接口自动化测试流程
需求分析=》用例设计=》脚本开发=》执行脚本=》结果分析
5、robot framework中使用什么库实现接口测试
答:RequestsLibrary)库
6、接口自动化达到的目的
1)提高回归测试的效率,提高测试场景覆盖率和代码覆盖率
2)解决项目中重复构造测试数据,可以进行参数化设置,实现数据驱动测试
7、RequestsLibrary常用关键字
1、当接口2需要使用接口1的cookies,我们需要先获取接口1请求成功返回的cookies,然后再提供给接口22、获取接口1的cookies的方法
${response.headers}返回响应头对象
${response.headers['set-cookie']}返回set-cookie的值
通过fetch from left,fetch from right关键字得到最终的cookies值最终使用create dictionary关键字把cookiest设置为字典


八、UI自动化测试--selenium
1.selenium的介绍
selenium是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)
使用selenium的优点
- 1、工具免费
- 2、安装简单,小巧,selenium其实就是一个包
- 3、支持多语言java,python)+selenium完成自动化测试
- 4、支持多平台(window,linux)
- 5、支持多浏览器(ie,firefox,chrome)
2.selenium工具原理
Selenium2的核心是webdriver
webdriver是按照client-serveri设计原理设计
client:简单来说就是我们写的代码,以http请求的方式发送给server端,server端接收请求,执行相应操作,并返回给clienti端。
server:客户端的脚本启动后,被控制的浏览器就是serveri端,职责就是等待client端发送请求并作出响应。
使用的协议:
JSON Wire protocol(作用是可以让同一个浏览器驱动处理不同编程语言的脚本)
3.selenium安装
- 在dos窗口用pip命令安装selenium(Python3用pip3)
命令:pip3 install selenium - 配置谷歌驱动文件
把chromedriver.exe放置在C:\Python.37\Scripts目录下面
4.selenium中元素定位
要实现UI自动化,就必须学会定位web页面元素,Selenium核心webdrivert模块提供了9种定位元素方法
通过按 Fn + f12 或 f12 或开发工具,查看元素的属性
1、id定位
#通过id定位到百度输入框然后往百度输入框输入duoceshi
driver.find_element_by_id('kw').send_keys('duoceshi')
2、name定位
driver.find_element_by_name('wd').send_keys('duoceshi')
3、class定位
driver.find_element_by_class_name('s_ipt').send_keys('duoceshi')
4、link_text定位
#click()点击方法准确的匹配
driver.find_element_by_link_text('hao123').click()
5、partial_link_text定位
模糊匹配
driver.find_element_by_partial link text('ao1').click()
6、JavaScript定位
js = 'var a = document.getElementByld("kw").value="duoceshi"'
driver.execute_script(js)
7、tag_name定位(标签名定位)
driver.find_element_by_tag_name('input')
s = driver.find_elements_by_tag_name('input') #定位到所有的input标签
for i in s:
#当i这个input标签中有个id属性的值为kw就表示已经定位到了百度输入框
if i.get_attribute('id') == 'kw':
i.send_keys('duoceshi')
注意点:使用单独的标签名很难一次性定位到我们想要的元素,有的时候需要跟for循环组合使用
#实践代码
#1、id定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
dx.find_element_by_id("kw").send_keys("id定位")
#2、name定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
dx.find_element_by_name("wd").send_keys("name定位")
#3、class定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
dx.find_element_by_class_name("s_ipt").send_keys("class定位")
#4、link_text 链接定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
dx.find_element_by_link_text("hao123").click()
#5、find_element_by_partial_link_text 模糊匹配案例
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
dx.find_element_by_partial_link_text("hao").click()
#6、xpath定位
#复制的xpath://*[@id="kw"]
#案例:from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
dx.find_element_by_xpath('//*[@id="kw"]').send_keys("xpath定位")
#7、css定位
#复制css :#kwfrom selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
dx.find_element_by_css_selector("#kw").send_keys("css定位方法")
#8、js定位方法案例;
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
js="document.getElementById('kw').value='js定位'"
dx.execute_script(js)
#9、tag_name 标签名称定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
sleep(2)
dx.maximize_window()
inputs=dx.find_elements_by_tag_name("input")
for i in inputs:
if i.get_attribute("name")=="wd":
i.send_keys("tag_name定位")
8、xpath定位
网址:https://www.baidu.com/
相对定位:xpath相对路径 符号://
案例://*[@id="kw"]
绝对路径:
/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
语法://标签名[@属性名=属性值]
driver.find_element_by_.xpath('/*[@id="kw"]').send_keys(u'多测师')
driver.find_element_by_xpath('//input[@name="wd"]').send_keys(u'多测师')
#案例:
#(1)xpath中id定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_xpath('//*[@id="kw"]').send_keys("xpath中的id定位")
#(2)xpath中的name定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_xpath('//*[@name="wd"]').send_keys("xpath中name定位")
#(3)xpath中的class定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_xpath('//*[@class="s_ipt"]').send_keys("xpath中class定位")
#(4)xpath中通过标签名定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_xpath('//input[@id="kw"]').send_keys("xpath中的标签定位")
#(5)xpath中其他元素定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_xpath("//*[@autocomplete='off']").send_keys('xpath中其他属性定位')
#(6)组合属性定位(and)
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_xpath('//*[@autocomplete="off" and @id="kw" ]').send_keys('xpath中的组合属性定位')
#(7)xpath中的层级定位
#上一层:'//*[@id="form"]/span[1]'
#下一层:'//*[@id="form"]/span[1]/input[1]'
#层级:(上一级)
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_xpath('//*[@id="form"]/span[1]/input[1]').send_keys("层级定位")
#层级:(上二级)
xpth=//*[@id="form"]
#input路径:
xpth=//*[@id="form"]/span[1]/input[1]9、css定位
通过id选择器定位
driver.find_element_by_css_selector('#kw').send_keys(u'多测师')
通过class选择器定位
driver.find_element_by_css_selector('.s_ipt').send_keys(u'多测师')
#一、css中的id定位
#(1)id简写定位(#)
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_css_selector("#kw").send_keys("css中id简写定位#")
#(2)id全称定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_css_selector("[id='kw']").send_keys("css中id的全称定位#")
#二、css中的class定位
#(1)css中class简写定位(.)
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_css_selector(".s_ipt").send_keys("css中class的简写定位.")
#(2)class中全称定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_css_selector("[class='s_ipt']").send_keys("css中class的全称定位.")
#(3)css中的name定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_css_selector("[name='wd']").send_keys("css中name的全称定位.")
#(4)css中的其他属性定位@autocomplete='off'
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_css_selector("[autocomplete='off']").send_keys("css中其他属性定位.")
#(5)css中的组合属性定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_css_selector("[autocomplete='off'][name='wd']").send_keys("css中组合属性定位")
#(6)层级定位:
3上一级:
#form > span.bg.s_ipt_wr.new-pmd.quickdelete-wrap
#上两级:
#form
#a、上一级定位
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
dx.find_element_by_css_selector("#form > span.bg.s_ipt_wr.new-pmd.quickdelete-wrap>input").send_keys("css中上一级定位")
#b、上两级
#form > 下一级> 下两级python+selenium实现自动化元素定位总结
在这9种常用的定位方法中,优先顺序
- 1)有id优先使用id定位
- 2)没有id,考虑使用name或者class定位。
- 3)如果没有id,name,class再考虑用xpath,css定位。
- 4)如果是链接可以考虑使用link text,partial link text定位。
- 5)tag_name和JavaScripti还是用的比较少的。
我们根据实际情况,具体问题具体分析
5.selenium常用控件定位
1、定位文本框,密码框
a.先使用web元素定位方法定位文本框,密码框,再使用send_keys()方法进行文本密码输入
driver = webdriver.Chrome()
driver.get('http://test.duoceshi.cn/cms/manage/login.do')
driver.find_element_by_id("userAccount").send keys('admin')
driver.find_element_by_id('loginPwd').send_keys('123456)b.send_keys()方法进行输入,输入中文需要在文本内容前面加1个u,否测会报错
c.send_keys()方法可用于上传文件的操作,参数可以直接是文件的路径。
#1、文本框、密码框、输入、点击、 按钮
#网址:http://cms.duoceshi.cn/manage/login.do
#案例:
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("http://cms.duoceshi.cn/manage/login.do")
dx.maximize_window()
sleep(2)
dx.find_element_by_id("userAccount").send_keys("admin")
sleep(2)
dx.find_element_by_id("loginPwd").send_keys("123456")
sleep(2)
dx.find_element_by_id("loginBtn").click()
#2、链接网址:https://www.baidu.com/
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
dx.get("http://baidu.com")
dx.maximize_window()
sleep(2)
dx.find_element_by_link_text("hao123").click()
#3、隐藏框
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("http://baidu.com")
dx.maximize_window()
sleep(2)
wz=dx.find_element_by_link_text("更多")
ActionChains(dx).move_to_element(wz).perform()
dx.find_element_by_xpath('//*[@id="s-top-more"')
## ctrl+shift+c 键查看标签更多
#案例:
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("http://baidu.com")
dx.maximize_window()
sleep(2)
wz=dx.find_element_by_id("s-usersetting-top")
ActionChains(dx).move_to_element(wz).perform()
dx.find_element_by_link_text("关闭预测").click()
#4、获取元素的文本(text)
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("http://baidu.com")
dx.maximize_window()
sleep(2)
wb=dx.find_element_by_link_text("登录").text
if wb=="登录":
print("断言成功")
else:
print("断言失败")
#5、断言(if 、assert)
#(1)if断言:
#(2)assert 断言
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("http://baidu.com")
dx.maximize_window()
sleep(2)
wb=dx.find_element_by_link_text("登录").text
assert wb=="登录qq"
print(1)
#常用的场景:日志
#6、获取窗口的大小(get_window_size())
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("http://baidu.com")
dx.maximize_window()
sleep(2)
dx.get_window_size()#{'width': 1616, 'height': 886}
2、定位普通按钮,链接,隐藏框
方法:先使用web元素定位方法定位元素,再使用click()方法进行点击。
例子:
1)点击百度一下按钮
driver.find_element_by_id('su').click()2)点击百度新闻链接
driver.find_element_by_link_text('hao123').click()3、鼠标移动到某个元素上
1)定位百度首页的设置按钮
2)定位下拉的高级搜索按钮,先把鼠标移动到设置按钮上,再点击高级搜索按钮
代码如下:
from selenium.webdriver.support.common.action chains import ActionChains
ActionChains(driver).move to element(元素).perform()方法:
1)move_to_element() #移动鼠标到某个网页元素上
2)perform() #为鼠标移动后的确认
4、selenium中的三种等待方式
1)强制等待:
设置固定的线程休眠时间为5秒
time.sleep(5)
2)隐式等待
driver.implicitly_wait(5)
隐式等待是全局的针对所有元素,设置等待时间如5秒,如果5秒内出现,则继续向下,否则抛异常。可理解为在5秒内,不停刷新看元素是否加载出来
3)显式等待:
是单独针对某个元素,设置一个等待时间如5秒,每隔0.5秒检查一次是否出现,如果在5秒之前任何时候出现,则继续向下,超过5秒尚未出现则抛异常
WebDriverWait(driver,5,0.5).until(EC.presence_of_element_located(By.ID,'kw')).sendkeys(u'多测师')
显式等待详细解释:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
from selenium.webdriver..support..wait import WebDriverWait #导入模块driver:浏览器驱动
timeout:最长超时时间,默认以秒为单位
poll_frequency:检测的间隔步长,默认为0.5s
ignored_exceptions:超时后的抛出的异常信息,默认抛出NoSuchElementException.异常。
5、获取元素的文本
方法:先使用web元素定位方法定位元素,再使用text获取文本
value = driver.find_element_by_id('s-usersetting-top').text
if value == u'设置':
print '断言成功'
else:
print '断言失败'6、获取窗口title
获取窗口title,用于断言当前窗口是否打开
方法:driver.title
例子:百度首页title获取并断言
assert driver.title==u'百度一下,你就知道'
注意点:
assert为断言,判断获取的title是否和预期的'百度一下,你就知道'相同。
7、窗口最大化
方法:maximize_window()
例子:句柄.maximize_window()
8、窗口刷新
方法:refresh()
例子:句柄.refresh()
9、返回上一步
方法:back()
例子:driver.back()
10、获取窗口的尺寸
方法:get_window_size()
例子:句柄.get_window_size()
11、关闭当前浏览器
方法:close()
例子:句柄.close()
12、关闭所有的浏览器
方法:quit()
例子:句柄.quit()
13、切换窗口
场景:在打开多个窗口时,需要定位新窗口中的元素,我们需要进行窗口切换。
方法:方法是先获取窗口句柄,再通过switch to.window()方法进行窗口切换。
handle=driver.current_window_handle #获取当前窗口的句柄
handles=driver.window_handles #获取所有窗口的句柄
driver.switch_to.window(handles[index]) #通过句柄的索引l进行切换
解释:
对象nandles是一个列表,列表中的元素就是一个个窗口句柄。窗口句柄是一个系统内部数据结构的引用。通过这个句柄,我们就可以控制这个窗口,对这个窗口进行放大,缩小,切换等操作。
#一、切换窗口
#(1) 获取当前句柄(current_window_handle)
#获取所有的句柄 (window_handles)
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("http://baidu.com")
print(dx.title)
dx.maximize_window()
sleep(2)
w='window.open("http://jd.com")'
dx.execute_script(w)
print(dx.title)
jb=dx.current_window_handle #获取当前窗口句柄
print(jb)
jbs=dx.window_handles #获取所有窗口句柄
print(jbs)
#(2)通过句柄切换窗口(两个窗口的排序0,1)
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
print(dx.title)
dx.maximize_window()
sleep(2)
w='window.open("https://www.jd.com/")'
dx.execute_script(w)
print(dx.title)
jb=dx.current_window_handle #获取当前窗口句柄
print(jb) #CDwindow-279E9F0F55B7B2F2AFA9245B9A580D86
jbs=dx.window_handles #获取所有窗口句柄
print(jbs)
dx.switch_to.window(jbs[1])
sleep(2)
dx.find_element_by_link_text("我的订单").click()
#(2)通过句柄切换窗口(三个窗口的排序0,2,1)
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
print(dx.title)
dx.maximize_window()
sleep(2)
w='window.open("https://www.jd.com/")'
dx.execute_script(w)
print(dx.title)
w1='window.open("https://www.hao.com/")'
dx.execute_script(w1)
jb=dx.current_window_handle #获取当前窗口句柄
print(jb) #CDwindow-279E9F0F55B7B2F2AFA9245B9A580D86
jbs=dx.window_handles #获取所有窗口句柄
print(jbs)
dx.switch_to.window(jbs[2])
sleep(2)
dx.find_element_by_link_text("我的订单").click()
#(3)如果有多个窗口通过for 循环判断,确定窗口
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains
dx=webdriver.Chrome()
dx.get("https://www.baidu.com/")
print(dx.title)
dx.maximize_window()
sleep(2)
w='window.open("https://www.jd.com/")'
dx.execute_script(w)
print(dx.title)
w1='window.open("https://www.hao.com/")'
dx.execute_script(w1)
jb=dx.current_window_handle #获取当前窗口句柄
print(jb) #CDwindow-279E9F0F55B7B2F2AFA9245B9A580D86
jbs=dx.window_handles #获取所有窗口句柄
for i in jbs:
dx.switch_to.window(i)
if "京东(JD.COM)-正品低价、品质保障、配送及时、轻松购物!" in dx.title:
break
print(dx.title)
sleep(2)
dx.find_element_by_link_text("我的订单").click()
14、获取下拉框选项
引入类:Select()
from selenium.webdriver.support.select import Select
实战网址:https://www.ctrip.com/
1)select_by_index() #通过下标定位下拉选项
2)select_by_value() #通过value属性值定位下拉选项
3)select_by_visible_text() #通过下拉文本内容内容
#网址:https://yz.chsi.com.cn/zsml/zyfx_search.jsp
from selenium import webdriver
from time import *
from selenium.webdriver.support.select import Select
dx=webdriver.Chrome()
dx.get("https://yz.chsi.com.cn/zsml/zyfx_search.jsp")
print(dx.title)
dx.maximize_window()
sleep(2)
wz=dx.find_element_by_id("ssdm")
# Select(wz).select_by_index(2) #通过索引选择
# Select(wz).select_by_value("12") #通过value值选择
Select(wz).select_by_visible_text("(12)天津市")15、弹框处理
三种弹框的处理方法:警告型,确认型,输入型弹框
t=driver.switch to.alert() #切换进入alert()弹框
t.text() #获取弹框的上面的文本
t.accept() #点击确定按钮
t.dismiss() #点击取消按钮
send_keys() #输入型弹框可以在弹框上面进行文本输入
#一、alert 弹框
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
url=r"file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/alert%E5%BC%B9%E6%A1%86.html"
dx.get(url)
print(dx.title)tk=dx.switch_to.alert #切换到弹框中
tk.dismiss() #取消
#二、确认性弹框
url=file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/enter.html
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
url=r"file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/enter.html"
dx.get(url)
print(dx.title)
dx.find_element_by_class_name("alert").click()
tk=dx.switch_to.alert
tk.dismiss()
#(三)输入型弹框
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
url=r"file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/prompt.html"
dx.get(url)
print(dx.title)
dx.find_element_by_class_name("alert").click()
tk=dx.switch_to.alert
tk.send_keys("dcs")
tk.accept()
#(四)上传文件类型弹框url=file:///E:/dcs/two/selenium/%E5%BC%B9%E
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
url="file:///E:/dcs/two/selenium/%E5%BC%B9%E6%A1%86/upload_file.html"
dx.get(url)
print(dx.title)
dx.find_element_by_id("file").send_keys(r"E:\az\f\ck\ddd.txt")
#(五)iframe框链接:https://graph.qq.com/oauth2.0/show?which=Login&display=pc&response_type=code&state=5DFCF10A905CCC9B086DD961CBBE1C550A9F09C40DA8C60F5B10F90423E4722D2956CD16E74FEF942C44EBB8ACC6F914&client_id=100273020&redirect_uri=https%3A%2F%2Fqq.jd.com%2Fnew%2Fqq%2Fcallback.action%3Fuuid%3Dbff66901b7ce422fb351b3b36ec54a4c
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
url=r"https://graph.qq.com/oauth2.0/show?which=Login&display=pc&response_type=code&state=5DFCF10A905CCC9B086DD961CBBE1C550A9F09C40DA8C60F5B10F90423E4722D2956CD16E74FEF942C44EBB8ACC6F914&client_id=100273020&redirect_uri=https%3A%2F%2Fqq.jd.com%2Fnew%2Fqq%2Fcallback.action%3Fuuid%3Dbff66901b7ce422fb351b3b36ec54a4c"
dx.get(url)
print(dx.title)
k=dx.find_element_by_id("ptlogin_iframe")
dx.switch_to.frame(k) #进入frame框
sleep(2)
dx.find_element_by_link_text("密码登录").click()
sleep(2)
dx.switch_to.default_content() #退出frame框
dx.find_element_by_link_text("服务协议").click()16、iframe框处理
定位的元素在iframe标签里面,需要先进入iframe,再进行元素定位
进入iframe框方法:switch_to.frame()
退出iframe框方法:switch_to.default content()
实战案例一:https://mail.163.com/
实战案例二:用QQ登录京东网站
方法:可以通过xpath,tag_name,索引等方法定位iframe框
注意:定位的iframe里面包含iframe,我们需要使用多次switch_to.frame(),从外一层一层进入,退出的时候使用一次switch_to.default_content()就可退出到最外面一层
17、滚动条定位
滚动条是由js代码编写的
方法:execute script()
代码如下:
js1=window.scrollTo(0,20000) #向下滚动20000px
driver.execute_script(js1)
js2=window.scrollTo(0,0) #从底部滚动到顶部
driver.execute_script(js2)
#(1)
from selenium import webdriverfrom time import *
dx=webdriver.Chrome()
url="https://www.jd.com/"
dx.get(url)
j='window.scrollTo(0,2000)'
dx.execute_script(j)
sleep(3)
j1='window.scrollTo(0,0)' #滚动到原始点
dx.execute_script(j1)
#(2)
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
url="https://www.jd.com/"
dx.get(url)
dx.maximize_window()
sleep(2)
js="var d=document.documentElement.scrollTop=2000"
dx.execute_script(js)
sleep(3)
js1="var d=document.documentElement.scrollTop=0"
dx.execute_script(js1)
#(3)
from selenium import webdriver
from time import *
dx=webdriver.Chrome()
url="https://www.jd.com/"
dx.get(url)
dx.maximize_window()
sleep(2)
n=0
while n<5000:
n+=1000
js="var d=document.documentElement.scrollTop="+str(n)
dx.execute_script(js)
sleep(3)
18、Keys类
from selenium.webdriver.common.keys import Keys
删除单个字符:Keys.BACK_SPACE
全选:Keys.CONTROL,'a'
剪切:Keys.CONTROL,'x'
粘贴:Keys.CONTROL,'v'
点击确定:Keys.ENTER
进阶:可以把相同的步聚封装在一个函数里面
def find element(locator,*value):
"封装个函数"
return driver.find_element_by_id(locator).send_keys(*value)
if __name__=='__main__':
find_element('kw','duoceshii')
find_element('kw',Keys.BACK_SPACE)
find element('kw',(Keys.CONTROL,'a'))
find_element('kw',(Keys.CONTROL,'x'))快捷键 网址:https://www.baidu.com/
#(1) 输入、全选、剪切、粘贴、确认
from selenium import webdriver
from time import *
from selenium.webdriver.common.keys import Keys
dx=webdriver.Chrome()
url="https://www.baidu.com/"
dx.get(url)
dx.maximize_window()
dx.find_element_by_id("kw").send_keys("dcs")
sleep(2)
dx.find_element_by_id("kw").send_keys(Keys.CONTROL,"a")
sleep(2)
dx.find_element_by_id("kw").send_keys(Keys.CONTROL,"x")
sleep(2)
dx.find_element_by_id("kw").send_keys(Keys.CONTROL,"v")
sleep(2)
dx.find_element_by_id("kw").send_keys(Keys.ENTER)
#(2)通过封装(简化代码)
from selenium import webdriver
from time import *
from selenium.webdriver.common.keys import Keys
dx=webdriver.Chrome()
url="https://www.baidu.com/"
dx.get(url)
dx.maximize_window()
def kj(lj,*a):
dx.find_element_by_id(lj).send_keys(*a)
sleep(3)
if __name__ == '__main__':
kj("kw","dcs")
kj("kw", Keys.CONTROL,"a")
kj("kw", Keys.CONTROL, "x")
kj("kw", Keys.CONTROL, "v")
kj("kw", Keys.ENTER)6.selenium的用例编写和封装
自动化用例 案例:过期更新
一、编写用例
(1)登录
from selenium import webdriver from time import * from selenium.webdriver.common.keys import Keys dx=webdriver.Chrome() url="http://cms.duoceshi.cn/manage/login.do" dx.get(url) dx.maximize_window() dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) dx.find_element_by_id("loginBtn").click()(2)登录=用户中心=用户管理
from selenium import webdriver from time import * from selenium.webdriver.common.keys import Keys dx=webdriver.Chrome() url="http://cms.duoceshi.cn/manage/login.do" dx.get(url) dx.maximize_window() dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) dx.find_element_by_id("loginBtn").click() sleep(2) dx.find_element_by_xpath('//*[@id="menu-user"]/dt/i').click() sleep(2) dx.find_element_by_link_text("用户管理").click()(3)登录==系统管理==栏目设置
from selenium import webdriver from time import * from selenium.webdriver.common.keys import Keys dx=webdriver.Chrome() url="http://cms.duoceshi.cn/manage/login.do" dx.get(url) dx.maximize_window() dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) dx.find_element_by_id("loginBtn").click() sleep(2) dx.find_element_by_xpath('//*[@id="menu-system"]/dt/i').click() sleep(2) dx.find_element_by_link_text("栏目设置").click()二、封装
(1)每个用例都是独立(运行前调用登录)
from selenium import webdriver from time import * class Cms(object): def __init__(self): pass def dl(self): self.dx=webdriver.Chrome() url="http://cms.duoceshi.cn/manage/login.do" self.dx.get(url) self.dx.maximize_window() self.dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) self.dx.find_element_by_id("loginBtn").click() sleep(3) def yhgl(self): c=self.dl() self.dx.find_element_by_xpath('//*[@id="menu-user"]/dt/i').click() sleep(2) self. dx.find_element_by_link_text("用户管理").click() def lmcx(self): c = self.dl() self.dx.find_element_by_xpath('//*[@id="menu-system"]/dt/i').click() sleep(2) self.dx.find_element_by_link_text("栏目设置").click() if __name__ == '__main__': d=Cms() # d.dl() # d.yhgl() d.lmcx()(2)每个用例执行前都会运行构造函数下登录
from selenium import webdriver from time import * class Cms(object): def __init__(self): self.dx=webdriver.Chrome() url="http://cms.duoceshi.cn/manage/login.do" self.dx.get(url) self.dx.maximize_window() self.dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) self.dx.find_element_by_id("loginBtn").click() sleep(3) def yhgl(self): self.dx.find_element_by_xpath('//*[@id="menu-user"]/dt/i').click() sleep(2) self. dx.find_element_by_link_text("用户管理").click() def lmcx(self): self.dx.find_element_by_xpath('//*[@id="menu-system"]/dt/i').click() sleep(2) self.dx.find_element_by_link_text("栏目设置").click() if __name__ == '__main__': d=Cms() # d.yhgl() d.lmcx()(3)
from selenium import webdriver from time import * class Cms(object): def __init__(self): self.dx = webdriver.Chrome() url = "http://cms.duoceshi.cn/manage/login.do" self.dx.get(url) self.dx.maximize_window() def dl(self): self.dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) self.dx.find_element_by_id("loginBtn").click() sleep(3) def yhgl(self): c=self.dl() self.dx.find_element_by_xpath('//*[@id="menu-user"]/dt/i').click() sleep(2) self. dx.find_element_by_link_text("用户管理").click() def lmcx(self): c = self.dl() self.dx.find_element_by_xpath('//*[@id="menu-system"]/dt/i').click() sleep(2) self.dx.find_element_by_link_text("栏目设置").click() if __name__ == '__main__': d=Cms() d.dl() # d.yhgl() d.lmcx()
三、实践操作
运行的是自己在linux环境中搭建的项目,网址可以用这个 http://cms.duoceshi.cn/manage/login.do
a.用例编写:
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains #动作链
from selenium.webdriver.support.select import Select #选择器
from selenium.webdriver.common.by import By
dx=webdriver.Chrome()
dx.get("http://192.168.137.243:8080/cms/manage/login.do")
# dx.maximize_window()
# sleep(3)
# ------1-------
# 登录
dx.find_element_by_id("userAccount").send_keys("admin")
# sleep(2)
dx.find_element_by_id("loginPwd").send_keys("123456")
# sleep(2)
dx.find_element_by_id("loginBtn").click()
# ------2--------添加栏目
# 点击系统管理
dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click()
sleep(3)
# 点击栏目设置
lmsz=dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[1]/a').click()
sleep(3)
#进 栏目设置 的iframe框,点击 添加栏目
dx.switch_to.frame('/cms/manage/article-class.html')
dx.find_element_by_css_selector('body > div > div.cl.pd-5.bg-1.bk-gray.mt-20 > span.l > a').click()
sleep(2)
#进 添加栏目 的iframe框
tjlm=dx.find_element_by_xpath('//*[@id="xubox_iframe1"]')
# # sleep(3)
dx.switch_to.frame(tjlm)
# # sleep(2)
# 在 添加栏目 框里输入 栏目名称、栏目目录,点击保存
dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("789")
dx.find_element_by_xpath('//*[@id="categoryCode"]').send_keys("789")
dx.find_element_by_xpath('//*[@id="submitBtn"]').click()
dx.switch_to.default_content() #退出 栏目管理 的iframe框
# --------3--------添加资讯
# 点击 文章管理
dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[2]/a').click()
#进 文章管理 的iframe框,点击 全部分类
dx.switch_to.frame('/cms/manage/article-list.html')
dx.find_element_by_css_selector('#categoryId').click()
# 点击 全部分类,展开下拉框,点击 123
qbfl=dx.find_element_by_xpath('//*[@id="categoryId"]')
sleep(3)
ActionChains(dx).move_to_element(qbfl).perform()
sleep(2)
# dx.find_element_by_link_text("123").click()
dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click()
# 点击 添加资讯
dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click()
# 进 添加资讯 的iframe框,选择 文章栏目,输入 资讯标题、资讯描述、选择是否发布,输入 内容,点击 确定
tjzx=dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # '/cms/manage/article-add.html'
dx.switch_to.frame(tjzx)
wzlm=dx.find_element_by_xpath('//*[@id="categoryId"]')
sleep(2)
ActionChains(dx).move_to_element(wzlm).perform()
sleep(1)
dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click()
dx.find_element_by_name('articleTitle').send_keys("test2")
dx.find_element_by_name('articleDesc').send_keys("test22")
# 点击单选框:发布/下架
fb_btn=dx.find_element_by_css_selector('#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(1)').click()
# fb_btn=dx.find_element_by_css_selector('#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(2)').click()
# 进编辑 内容 的iframe框,输入内容
nr=dx.find_element_by_id("ueditor_0")
dx.switch_to.frame(nr)
dx.find_element_by_css_selector('body > p:nth-child(1)').send_keys("12346567899")
dx.switch_to.default_content() #退出frame框
# print(1)
#进 文章管理 的iframe框
dx.switch_to.frame('/cms/manage/article-list.html')
#移动 添加资讯 的iframe框,鼠标按下、拖动到指定位置、释放鼠标
zx=dx.find_element_by_xpath('//*[@id="xubox_layer1"]/div/div')
ActionChains(dx).click_and_hold(zx).perform() #按下鼠标
sleep(2)
# print(1)
ActionChains(dx).drag_and_drop_by_offset(zx,600,1500) #移动位置,移到(600,1500)的位置
# print(2.1)
ActionChains(dx).perform() #执行鼠标的移动位置操作
# print(2.2)
# ActionChains(dx).release() #释放鼠标
# ActionChains(dx).perform()
ActionChains(dx).move_to_element(zx).perform() #鼠标移动到目标位置
# print(3)
# sleep(2)
ActionChains(dx).click().perform() #点击一下【可能移了跟没移一样,鼠标点击一下空白处,位置就更新了】
# print(4)
#进 添加资讯 的iframe框
dx.switch_to.frame(tjzx)
#向下滑动右侧滚动条---找元素定位
j='window.scrollTo(0,2000)'
dx.execute_script(j)
#输入作者、来源,点击确定
dx.find_element_by_xpath('//*[@id="articleAuthor"]').send_keys("asd99")
sleep(2)
dx.find_element_by_css_selector('#articleSource').send_keys("asd666")
sleep(2)
dx.find_element_by_xpath('//*[@id="submitBtn"]').click()
# ------4------搜资讯
#先退出 添加资讯 的iframe框,再进 文章管理 的iframe框
dx.switch_to.default_content()
#进 文章管理 的iframe框
dx.switch_to.frame('/cms/manage/article-list.html')
#刷新资讯列表
dx.find_element_by_css_selector('body > nav > a > i').click()
#在 资讯标题 输入框里输入内容
dx.find_element_by_name("articleTitle").send_keys("cs")
#点击 搜资讯 按钮
dx.find_element_by_xpath('//*[@id="searchBtn"]').click()
# ------5-------删除资讯
#刷新资讯列表
dx.find_element_by_css_selector('body > nav > a > i').click()
#点击 删除
dx.find_element_by_css_selector('#articleTable > tr:nth-child(2) > td.f-14.article-manage > a:nth-child(3)').click()
#弹窗询问,确定 删除
dx.find_element_by_css_selector('#xubox_layer1 > div.xubox_main > span.xubox_botton > a.xubox_yes.xubox_botton2').click()
sleep(2)
#------6------- 修改 资讯 的发布状态,下架<->发布
#刷新资讯列表
dx.find_element_by_css_selector('body > nav > a > i').click()
#点击 下架<->发布
dx.find_element_by_xpath('//*[@id="articleTable"]/tr[7]/td[8]/a[1]/i').click()
#关闭浏览器
dx.quit()b.用例封装:
from selenium import webdriver
from time import *
from selenium.webdriver.common.action_chains import ActionChains #动作链
class cms(object):
def __init__(self):
pass
def dl(self): #登录
self.dx=webdriver.Chrome()
url="http://192.168.137.243:8080/cms/manage/login.do"
self.dx.get(url)
self.dx.find_element_by_id("userAccount").send_keys("admin")
# sleep(2)
self.dx.find_element_by_id("loginPwd").send_keys("123456")
# sleep(2)
self.dx.find_element_by_id("loginBtn").click()
def tjlm(self): #添加栏目
c = self.dl()
# 点击系统管理
self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click()
sleep(3)
# 点击栏目设置
lmsz = self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[1]/a').click()
sleep(3)
# 进 栏目设置 的iframe框,点击 添加栏目
self.dx.switch_to.frame('/cms/manage/article-class.html')
self.dx.find_element_by_css_selector('body > div > div.cl.pd-5.bg-1.bk-gray.mt-20 > span.l > a').click()
sleep(2)
# 进 添加栏目 的iframe框
tjlm = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]')
# # sleep(3)
self.dx.switch_to.frame(tjlm)
# # sleep(2)
# 在 添加栏目 框里输入 栏目名称、栏目目录,点击保存
self.dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("789")
self.dx.find_element_by_xpath('//*[@id="categoryCode"]').send_keys("789")
self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click()
self.dx.switch_to.default_content() # 退出 栏目管理 的iframe框
# self.dx.quit()
def tjzx(self):
c = self.dl()
# 点击系统管理
self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click()
sleep(3)
# 点击 文章管理
self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[2]/a').click()
# 进 文章管理 的iframe框,点击 全部分类
self.dx.switch_to.frame('/cms/manage/article-list.html')
self.dx.find_element_by_css_selector('#categoryId').click()
# # 点击 全部分类,展开下拉框,点击 123
# qbfl = self.dx.find_element_by_xpath('//*[@id="categoryId"]')
# sleep(3)
# ActionChains(self.dx).move_to_element(qbfl).perform()
# sleep(2)
# # dx.find_element_by_link_text("123").click()
# self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click()
# 点击 添加资讯
self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click()
# 进 添加资讯 的iframe框,选择 文章栏目,输入 资讯标题、资讯描述、选择是否发布,输入 内容,点击 确定
tjzx = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # '/cms/manage/article-add.html'
self.dx.switch_to.frame(tjzx)
wzlm = self.dx.find_element_by_xpath('//*[@id="categoryId"]')
sleep(2)
ActionChains(self.dx).move_to_element(wzlm).perform()
sleep(1)
self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click()
self.dx.find_element_by_name('articleTitle').send_keys("test2")
self.dx.find_element_by_name('articleDesc').send_keys("test22")
# 点击单选框:发布/下架
fb_btn = self.dx.find_element_by_css_selector(
'#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(1)').click()
# fb_btn=dx.find_element_by_css_selector('#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(2)').click()
# 进编辑 内容 的iframe框,输入内容
nr = self.dx.find_element_by_id("ueditor_0")
self.dx.switch_to.frame(nr)
self.dx.find_element_by_css_selector('body > p:nth-child(1)').send_keys("12346567899")
self.dx.switch_to.default_content() # 退出frame框
# print(1)
# 进 文章管理 的iframe框
self.dx.switch_to.frame('/cms/manage/article-list.html')
# 移动 添加资讯 的iframe框,鼠标按下、拖动到指定位置、释放鼠标
zx = self.dx.find_element_by_xpath('//*[@id="xubox_layer1"]/div/div')
ActionChains(self.dx).click_and_hold(zx).perform() # 按下鼠标
sleep(2)
# print(1)
ActionChains(self.dx).drag_and_drop_by_offset(zx, 600, 1500) # 移动位置,移到(600,1500)的位置
# print(2.1)
ActionChains(self.dx).perform() # 执行鼠标的移动位置操作
# print(2.2)
# ActionChains(dx).release() #释放鼠标
# ActionChains(dx).perform()
ActionChains(self.dx).move_to_element(zx).perform() # 鼠标移动到目标位置
# print(3)
# sleep(2)
ActionChains(self.dx).click().perform() # 点击一下【可能移了跟没移一样,鼠标点击一下空白处,位置就更新了】
# print(4)
# 进 添加资讯 的iframe框
self.dx.switch_to.frame(tjzx)
# 向下滑动右侧滚动条---找元素定位
j = 'window.scrollTo(0,2000)'
self.dx.execute_script(j)
# 输入作者、来源,点击确定
self.dx.find_element_by_xpath('//*[@id="articleAuthor"]').send_keys("asd99")
sleep(2)
self.dx.find_element_by_css_selector('#articleSource').send_keys("asd666")
sleep(2)
self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click()
# self.dx.quit()
if __name__ == '__main__':
d=cms()
d.dl()
d.tjlm()
d.tjzx()其他案例:
#案例1: from selenium import webdriver from time import sleep class Cms(object): def __init__(self): self.dx=webdriver.Chrome() self.dx.get("http://cms.duoceshi.cn/manage/login.do") # self.dx.maximize_window() sleep(2) self.dx.find_element_by_id("userAccount").send_keys('admin') # 输入账号 sleep(2) self.dx.find_element_by_id("loginPwd").send_keys('123456') # 输入密码 sleep(2) self.dx.find_element_by_id("loginBtn").click() # 点击登录 sleep(2) def yhgl(self): # self.lodin() self.dx.find_element_by_xpath('//*[@id="menu-user"]').click()#点击用户中心 self.dx.find_element_by_link_text("用户管理").click() #点击用户管理 sleep(2) def ex(self): # self.lodin() self.dx.find_element_by_xpath('/html/body/header/span[2]/a').click() #退出登录 def rqfw(self): self.yhgl() w=self.dx.find_element_by_name("/manage/user-list.html") self.dx.switch_to.frame(w) sleep(2) self.dx.find_element_by_id("datemin").send_keys("2024-09-20") #筛选2024-09-20后的信息 sleep(2) self.dx.find_element_by_id("searchBtn").click() #点击搜索 def gdt(self): w = self.dx.find_element_by_xpath('//*[@id="iframe_box"]/div/iframe') self.dx.switch_to.frame(w) js1="window.scrollTo(0,2000)" self.dx.execute_script(js1) sleep(3) js2="window.scrollTo(0,0)" self.dx.execute_script(js2) def yhm(self): self.yhgl() w = self.dx.find_element_by_xpath('//*[@id="iframe_box"]/div[2]/iframe') #定位链接框 self.dx.switch_to.frame(w) sleep(3) self.dx.find_element_by_xpath('//*[@id="sysUserTab"]/tr[1]/td[3]/u').click() #打开一个用户详情 sleep(3) self.dx.find_element_by_class_name('xubox_setwin').click() #关闭一个用户详情 if __name__ == '__main__': c=Cms() c.yhgl() #进入用户管理 # c.ex() #退出登录 # c.rqfw() #查询日期筛选用户信息 # c.gdt() #滚轮 # c.yhm() #点击用户名查看用户信息,然后退出 #案例2:# 测试用例1:是否能进入文章管理界面 # from selenium import webdriver # from time import * # from selenium.webdriver.support.select import Select # class Cms(object): # def __init__(self): # self.dx = webdriver.Chrome() # url = "http://cms.duoceshi.cn/manage/login.do" # self.dx.get(url) # self.dx.maximize_window() # def dl(self): # self.dx.find_element_by_id("userAccount").send_keys("admin") # sleep(2) # self.dx.find_element_by_id("loginPwd").send_keys("123456") # sleep(2) # self.dx.find_element_by_id("loginBtn").click() # sleep(3) # def wzgl(self): # c = self.dl() # self.dx.find_element_by_xpath('//*[@id="menu-system"]').click() # sleep(2)#进入系统管理 # self.dx.find_element_by_css_selector('#menu-system > dd > ul > li:nth-child(2) > a').click() # sleep(2)#进入文章管理 # # self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click() # # self.dx.find_element_by_link_text("添加资讯").click() # # if __name__ == '__main__': # d=Cms() # d.wzgl() #测试用例2:是否能进入添加咨询界面 from selenium import webdriver from time import * from selenium.webdriver.support.select import Select class Cms(object): def __init__(self): self.dx = webdriver.Chrome() url = "http://cms.duoceshi.cn/manage/login.do" self.dx.get(url) self.dx.maximize_window() def dl(self): self.dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) self.dx.find_element_by_id("loginBtn").click() sleep(3) def wzgl(self): c = self.dl() self.dx.find_element_by_xpath('//*[@id="menu-system"]').click() sleep(2)#进入系统管理 self.dx.find_element_by_css_selector('#menu-system > dd > ul > li:nth-child(2) > a').click() sleep(2)#进入文章管理 # self.dx.find_element_by_id("categoryId").click()#点击全部分类 # self.dx.find_element_by_link_text("添加资讯").click() #点击添加咨询 self.dx.switch_to.frame('/manage/article-list.html') self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click() if __name__ == '__main__': d=Cms() d.wzgl()#测试用例3:栏目设置全部分类选择 from selenium import webdriver from time import * from selenium.webdriver.support.select import Select class Cms(object): def __init__(self): self.dx = webdriver.Chrome() url = "http://cms.duoceshi.cn/manage/login.do" self.dx.get(url) self.dx.maximize_window() def dl(self): self.dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) self.dx.find_element_by_id("loginBtn").click() sleep(3) def wzgl(self): c = self.dl() self.dx.find_element_by_xpath('//*[@id="menu-system"]').click() sleep(2)#进入系统管理 self.dx.find_element_by_css_selector('#menu-system > dd > ul > li:nth-child(2) > a').click() sleep(2)#进入文章管理 self.dx.switch_to.frame('/manage/article-list.html') wz=self.dx.find_element_by_id("categoryId")#点击全部分类 # self.dx.find_element_by_link_text("添加资讯").click() #点击添加咨询 Select(wz).select_by_value("6") #通valu添加内容 if __name__ == '__main__': d=Cms() d.wzgl() #测试用例4:文章管理中对数据进行翻页 from selenium import webdriver from time import * from selenium.webdriver.support.select import Select class Cms(object): def __init__(self): self.dx = webdriver.Chrome() url = "http://cms.duoceshi.cn/manage/login.do" self.dx.get(url) self.dx.maximize_window() def dl(self): self.dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) self.dx.find_element_by_id("loginBtn").click() sleep(3) def wzgl(self): c = self.dl() self.dx.find_element_by_xpath('//*[@id="menu-system"]').click() sleep(2)#进入系统管理 self.dx.find_element_by_css_selector('#menu-system > dd > ul > li:nth-child(2) > a').click() sleep(2)#进入文章管理 self.dx.switch_to.frame('/manage/article-list.html')#进入数据栏目 self.dx.find_element_by_id("pageNav")#进入翻页管理栏目 self.dx.find_element_by_xpath('//*[@id="pageNav"]/a[7]').click()#定位下一页并翻页 # wz=self.dx.find_element_by_id("categoryId")#点击全部分类 # Select(wz).select_by_value("6") #通valu添加内容 if __name__ == '__main__': d=Cms() d.wzgl() #案例: from selenium import webdriver from time import * class Cms(object): def __init__(self): pass def ceshi(self): self.dx = webdriver.Chrome() url = r"http://cms.duoceshi.cn/manage/login.do" self.dx.get(url) self.dx.maximize_window() def dengli(self,usename,password): c =self.ceshi() self.dx.find_element_by_id('userAccount').send_keys(usename) self.dx.find_element_by_id('loginPwd').send_keys(password) self.dx.find_element_by_id('loginBtn').click() print(self.dx.title) sleep(2) def tianjia(self,name,sex,phone,email,usename,password,n_password): self.dx.find_element_by_id('menu-user').click() sleep(1) self.dx.find_element_by_xpath('//*[@id="menu-user"]/dd/ul/li[1]/a').click() k=self.dx.find_element_by_name("/manage/user-list.html") self.dx.switch_to.frame(k) sleep(1) self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click() l = self.dx.find_element_by_id('xubox_iframe1') self.dx.switch_to.frame(l) sleep(1) self.dx.find_element_by_xpath('//*[@id="userName"]').send_keys(name) sleep(1) if sex == 1: self.dx.find_element_by_xpath('//*[@id="sysUserForm"]/table/tbody/tr[2]/td/label[1]').click() else: self.dx.find_element_by_xpath('//*[@id="sysUserForm"]/table/tbody/tr[2]/td/label[2]').click() self.dx.find_element_by_xpath('//*[@id="user-tel"]').send_keys(phone) if email != '': self.dx.find_element_by_xpath('//*[@id="user-email"]').send_keys(email) else: self.dx.find_element_by_xpath('//*[@id="user-email"]').send_keys('12356789@qq.com') self.dx.find_element_by_xpath('//*[@id="userAccount"]').send_keys(usename) self.dx.find_element_by_xpath('//*[@id="loginPwd"]').send_keys(password) self.dx.find_element_by_xpath('//*[@id="confirmPwd"]').send_keys(n_password) self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() sleep(1) self.dx.switch_to.default_content() sleep(1) self.dx.switch_to.default_content() sleep(5) self.dx.close() def shanchu(self,name): self.dx.find_element_by_id('menu-user').click() sleep(1) self.dx.find_element_by_xpath('//*[@id="menu-user"]/dd/ul/li[1]/a').click() k = self.dx.find_element_by_name("/manage/user-list.html") self.dx.switch_to.frame(k) sleep(1) usename =self.dx.find_elements_by_xpath('//*[@id="sysUserTab"]/tr/td[3]/u') for index, i in enumerate(usename): if i.text == name: self.dx.find_elements_by_xpath(f'//*[@id="sysUserTab"]/tr[{index+1}]/td[1]/input')[0].click() break self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[1]').click() if __name__ == '__main__': d = Cms() d.dengli('admin','123456') # d.tianjia('wdx',1,'17565643332','','wangdongxu','wangdongxu123','wangdongxu123') d.shanchu('wdx') #案例4: from selenium import webdriver from time import * class Cms(object): def __init__(self): self.dx = webdriver.Chrome() url = "http://cms.duoceshi.cn/manage/login.do" self.dx.get(url) self.dx.maximize_window() def dl(self): self.dx.find_element_by_id("userAccount").send_keys("admin") sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") sleep(2) self.dx.find_element_by_id("loginBtn").click() sleep(3) def yhgl(self): c=self.dl() self.dx.find_element_by_xpath('//*[@id="menu-user"]/dt/i').click() sleep(2) self. dx.find_element_by_link_text("用户管理").click() def lmcx(self): c = self.dl() self.dx.find_element_by_xpath('//*[@id="menu-system"]/dt/i').click() sleep(2) self.dx.find_element_by_link_text("栏目设置").click() sleep(3) url="/manage/article-class.html" self.dx.switch_to.frame(url) self.dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("1") sleep(2) self.dx.find_element_by_xpath('//*[@id="searchBtn"]').click() def lmtj(self): c = self.dl() self.dx.find_element_by_xpath('//*[@id="menu-system"]/dt/i').click() sleep(2) self.dx.find_element_by_link_text("栏目设置").click() sleep(3) url="/manage/article-class.html" self.dx.switch_to.frame(url) self.dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("1") sleep(2) self.dx.find_element_by_xpath('/html/body/div/div[1]/span[1]/a').click() url="xubox_iframe1" self.dx.switch_to.frame(url) self.dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("2") self.dx.find_element_by_xpath('//*[@id="categoryCode"]').send_keys("2") self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() if __name__ == '__main__': d=Cms() # d.dl() # d.yhgl() # d.lmcx()#栏目查询 d.lmtj()#栏目添加 #案例5: from selenium import webdriver from time import sleep from selenium.webdriver.support.select import Select class cms(object): def __init__(self): pass def dl(self): #登录超级用户 self.dx=webdriver.Chrome() self.dx.get("http://cms.duoceshi.cn/manage/login.do") self.dx.find_element_by_id('userAccount').send_keys('admin') self.dx.find_element_by_id('loginPwd').send_keys('123456') self.dx.find_element_by_id('loginBtn').click() def tcyh(self): #退出用户 self.dl() sleep(2) self.dx.find_element_by_xpath('/html/body/header/span[2]/a').click() def yhtj(self): #用户添加 self.dl() sleep(2) self.dx.find_element_by_xpath('//*[@id="menu-user"]/dt').click()#用户中心 sleep(2) self.dx.find_element_by_xpath('//*[@id="menu-user"]/dd/ul/li[1]/a').click()#用户管理 sleep(2) k=self.dx.find_element_by_name('/manage/user-list.html') self.dx.switch_to.frame(k) sleep(2) self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click() #用户添加 sleep(2) tj=self.dx.find_element_by_id('xubox_iframe1') self.dx.switch_to.frame(tj) sleep(2) self.dx.find_element_by_xpath('//*[@id="userName"]').send_keys('zyx') sleep(2) self.dx.find_element_by_id('userSex').click() sleep(2) self.dx.find_element_by_xpath('//*[@id="user-tel"]').send_keys('15179534085') sleep(2) self.dx.find_element_by_xpath('//*[@id="user-email"]').send_keys('1175016730@qq.com') sleep(2) self.dx.find_element_by_xpath('//*[@id="userAccount"]').send_keys('zccczyx') self.dx.find_element_by_xpath('//*[@id="loginPwd"]').send_keys('111222') self.dx.find_element_by_xpath('//*[@id="confirmPwd"]').send_keys('111222') sleep(2) self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() def yhss(self): #用户搜索 self.dl() sleep(2) self.dx.find_element_by_xpath('//*[@id="menu-user"]/dt').click()#用户中心 sleep(2) self.dx.find_element_by_xpath('//*[@id="menu-user"]/dd/ul/li[1]/a').click()#用户管理 sleep(2) k=self.dx.find_element_by_name('/manage/user-list.html') self.dx.switch_to.frame(k) sleep(2) self.dx.find_element_by_xpath('//*[@id="searchValue"]').send_keys('admin') sleep(2) self.dx.find_element_by_xpath('//*[@id="searchBtn"]').click() def lmcx(self): #栏目查询 self.dl() sleep(2) self.dx.find_element_by_xpath('//*[@id="menu-system"]/dt').click() sleep(2) self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[1]/a').click() sleep(2) lm=self.dx.find_element_by_name('/manage/article-class.html') self.dx.switch_to.frame(lm) sleep(2) sjlm=self.dx.find_element_by_xpath('//*[@id="parentId"]') Select(sjlm).select_by_visible_text('多测师') sleep(2) self.dx.find_element_by_xpath('//*[@id="searchBtn"]').click() if __name__ == '__main__': d=cms() #d.dl() d.yhtj() #d.tcyh() #d.yhss() #d.lmcx() #案例6: from selenium import webdriver from time import * from selenium.webdriver.common.keys import Keys def dl(): dx=webdriver.Chrome() dx.get("http://192.168.60.128:8080/cms/manage/login.do") dx.find_element_by_id('userAccount').send_keys('admin') sleep(2) dx.find_element_by_id('loginPwd').send_keys('123456') sleep(2) dx.find_element_by_id('loginBtn').click() sleep(3) def dlhoutuichu(): dx = webdriver.Chrome() dx.get("http://192.168.60.128:8080/cms/manage/login.do") dx.find_element_by_id('userAccount').send_keys('admin') sleep(1) dx.find_element_by_id('loginPwd').send_keys('123456') sleep(1) dx.find_element_by_id('loginBtn').click() sleep(4) dx.find_element_by_xpath('/html/body/header/span[2]/a').click() sleep(5) def yhgl(): dx=webdriver.Chrome() dx.get("http://192.168.60.128:8080/cms/manage/login.do") dx.find_element_by_id('userAccount').send_keys('admin') sleep(1) dx.find_element_by_id('loginPwd').send_keys('123456') sleep(1) dx.find_element_by_id('loginBtn').click() sleep(2) dx.find_element_by_id('menu-user').click() sleep(2) dx.find_element_by_xpath('//*[@id="menu-user"]/dd/ul/li[1]/a').click() sleep(4) dx.find_element_by_xpath('//*[@id="min_title_list"]/li[2]/i').click() sleep(4)
7.自动化测试框架-unittest
1)自动化测试框架
1、常用的测试框架:unittest 框架(今天的讲)、po框架、pytest框架
2、框架的作用:管理和组织测试用例
3、unittest框架中运用的类:unittest_Testcase 测试用例测试前准备工作
setupclass 类的开始 (整个类中执行一次)
setup 方法开始 (每条用例都执行一次)测试结束工作:
teardownclass 类的开结束 (整个类中执行一次)
teardown 方法结束 (每条用例都执行一次)测试中识别用例:
以test开头的用例
运用用例:
unittest .texttestrunner .run 运行用例
用例路径:
unittest.testloader 测试路径
测试部分用例
unittest.suite() 测试套件
addtest 添加一条用例
addtests 添加多条用例
2)框架的结构
import unittest #导入unittest 框架,python自带的框架
class Jk(unittest.TestCase): #创建一个类,继承unittest.case的类
@classmethod
def setUpClass(cls) -> None:
print("类的开始")
@classmethod
def tearDownClass(cls) -> None:
print("类的结束")
def setUp(self) -> None:
print("方法开始")
def tearDown(self) -> None:
print("方法结束")
def test1(self):
print(1)
def test3(self):
print(3)
def test2(self):
print(2)
def testa(self):
print("a")
def testA(self):
print("A")
def testb(self):
print("b")
def du(self):
print("独有")
if __name__ == '__main__':
unittest.main() #调用所有的用例结果:
类的开始
.方法开始
1
方法结束
.方法开始
2
方法结束
.方法开始
3
方法结束
.方法开始
A
方法结束
.方法开始
a
方法结束
.方法开始
b
方法结束
类的结束
总结:
1、类的开始和类的结束 在类中值运行一次(可以省略不写)
2、方法的开始和方法结束在每条用例都会执行
3、用例必须test开头:按照ascll的顺序排序:0-9A-Z,a-z
3)运行方法(4种)
(一)第一种方法:运行所有的用例
unittest.main() 执行所有的用例
案例:
class Jk(unittest.TestCase): #创建一个类,继承unittest.case的类
@classmethod
def setUpClass(cls) -> None:
print("类的开始")
@classmethod
def tearDownClass(cls) -> None:
print("类的结束")
def setUp(self) -> None:
print("方法开始")
def tearDown(self) -> None:
print("方法结束")
def test1(self):
print(1)
def test3(self):
print(3)
def test2(self):
print(2)
def testa(self):
print("a")
def testA(self):
print("A")
def testb(self):
print("b")
def du(self):
print("独有")
if __name__ == '__main__':
unittest.main() #调用所有的用例(二)第二种方法:运行部分用例
unittest.suite() 测试套件
addtest 添加一条用例
addtests 添加多条用例
注意点:运行用当前模块,修改环境变量
复制路径:找到 project 下 python包里的 .py文件,右键 - Copy PathC:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\uizdx\kj1.py
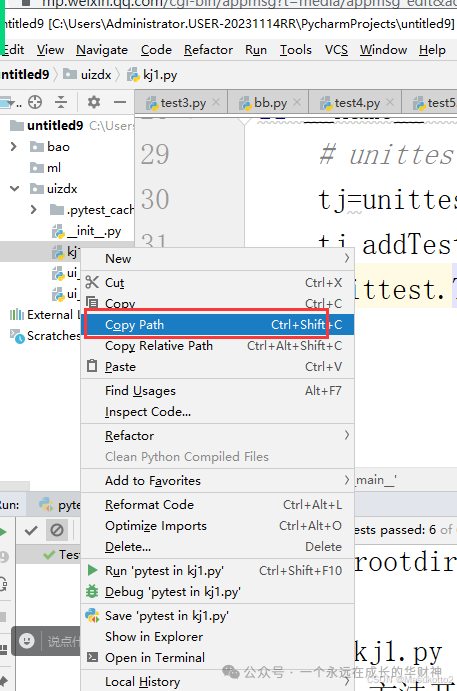
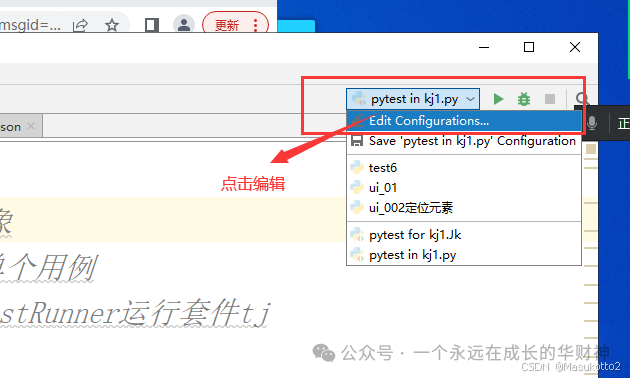
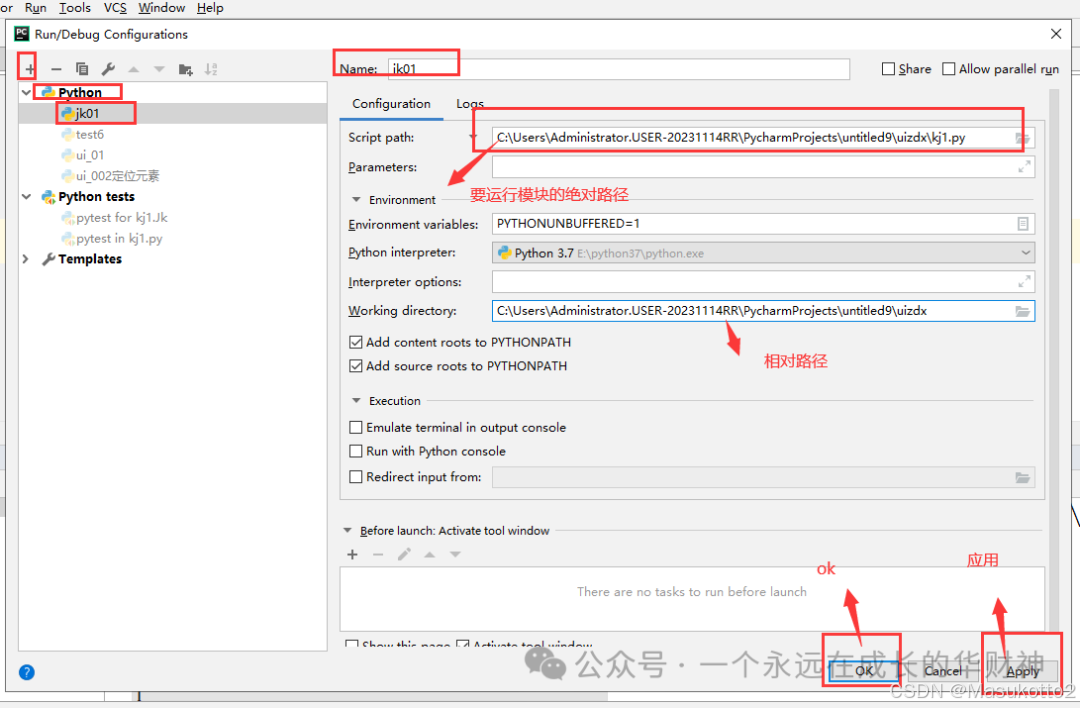
#(1)运行单条用例
import unittest #导入unittest 框架,python自带的框架
class Jk(unittest.TestCase): #创建一个类,继承unittest.case的类
@classmethod
def setUpClass(cls) -> None:
print("类的开始")
@classmethod
def tearDownClass(cls) -> None:
print("类的结束")
def setUp(self) -> None:
print("方法开始")
def tearDown(self) -> None:
print("方法结束")
def test1(self):
print(1)
def test3(self):
print(3)
def test2(self):
print(2)
def testa(self):
print("a")
def testA(self):
print("A")
def testb(self):
print("b")
def du(self):
print("独有")
if __name__ == '__main__':
# unittest.main() #调用所有的用例
tj=unittest.TestSuite() #创建一个套件的对象
tj.addTest(Jk("testa")) #通过addtest 添加单个用例
unittest.TextTestRunner().run(tj) # #TextTestRunner运行套件tj
#(2)运行多条用例import unittest #导入unittest 框架,python自带的框架
class Jk(unittest.TestCase): #创建一个类,继承unittest.case的类
@classmethod
def setUpClass(cls) -> None:
print("类的开始")
@classmethod
def tearDownClass(cls) -> None:
print("类的结束")
def setUp(self) -> None:
print("方法开始")
def tearDown(self) -> None:
print("方法结束")
def test1(self):
print(1)
def test3(self):
print(3)
def test2(self):
print(2)
def testa(self):
print("a")
def testA(self):
print("A")
def testb(self):
print("b")
def du(self):
print("独有")
if __name__ == '__main__':
# unittest.main() #调用所有的用例
tj=unittest.TestSuite() #创建一个套件的对象
# tj.addTest(Jk("testa")) #通过addtest 添加单个用例
tj.addTests([Jk("testa"),Jk("test1")])
unittest.TextTestRunner().run(tj) # #TextTestRunner运行套件tj(三)第三种方法:执行一个路径下的用例
语句:nittest.TestLoader().discover(start_dir=lj,pattern="kj1*.py")
import unittest #导入unittest 框架,python自带的框架
class Jk(unittest.TestCase): #创建一个类,继承unittest.case的类
@classmethod
def setUpClass(cls) -> None:
print("类的开始")
@classmethod
def tearDownClass(cls) -> None:
print("类的结束")
def setUp(self) -> None:
print("方法开始")
def tearDown(self) -> None:
print("方法结束")
def test1(self):
print(1)
def test3(self):
print(3)
def test2(self):
print(2)
def testa(self):
print("a")
def testA(self):
print("A")
def testb(self):
print("b")
def du(self):
print("独有")
if __name__ == '__main__':
# unittest.main() #调用所有的用例
# tj=unittest.TestSuite() #创建一个套件的对象
# tj.addTest(Jk("testa")) #通过addtest 添加单个用例
# tj.addTests([Jk("testa"),Jk("test1")])
# # unittest.TextTestRunner().run(tj) # #TextTestRunner运行套件tj
lj=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\uizdx" #相对路径
d=unittest.TestLoader().discover(start_dir=lj,pattern="kj1*.py")
unittest.TextTestRunner().run(d)(四)第四种方法:通过报告模板生成用例报告
报告模板:
HTMLTestRunnerNew.py
# coding=utf-8
"""
A连接信息 TestRunner for use with the Python unit testing framework. It
generates a HTML report to show the result at a glance.
The simplest way to use this is to invoke its main method. E列表.g.
import unittest
import HTMLTestRunner
... define your tests ...
if __name__ == '__main__':
HTMLTestRunner.main()
For more customization options, instantiates a HTMLTestRunner object.
HTMLTestRunner is a counterpart to unittest's TextTestRunner. E列表.g.
# output to a file
fp = file('my_report.html', 'wb')
runner = HTMLTestRunner.HTMLTestRunner(
stream=fp,
title='My unit test',
description='This demonstrates the report output by HTMLTestRunner.'
)
# Use an external stylesheet.
# See the Template_mixin class for more customizable options
runner.STYLESHEET_TMPL = '<link rel="stylesheet" href="my_stylesheet.css" type="text/css">'
# run the test
runner.run(my_test_suite)
------------------------------------------------------------------------
Copyright (c) 2004-2007, Wai Yip Tung
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are
met:
* Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or 课堂代码 materials provided with the distribution.
* Neither the name Wai Yip Tung nor the names of its contributors may be
used to endorse or promote products derived from this software without
specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS
IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED
TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A连接信息
PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER
OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""
# URL: http://tungwaiyip.info/software/HTMLTestRunner.html
__author__ = "Wai Yip Tung, Findyou"
__version__ = "0.8.2.2"
"""
Change History
Version 0.8.2.1 -Findyou
* 改为支持python3
Version 0.8.2.1 -Findyou
* 支持中文,汉化
* 调整样式,美化(需要连入网络,使用的百度的Bootstrap.js)
* 增加 通过分类显示、测试人员、通过率的展示
* 优化“详细”与“收起”状态的变换
* 增加返回顶部的锚点
Version 0.8.2
* Show output inline instead of popup window (Viorel Lupu).
Version in 0.8.1
* Validated XHTML (Wolfgang Borgert).
* Added description of test classes and test cases.
Version in 0.8.0
* Define Template_mixin class for customization.
* Workaround a IE 6 bug that it does not treat <script> block as CDATA.
Version in 0.7.1
* Back port to Python 2.3 (Frank Horowitz).
* Fix missing scroll bars in detail log (Podi).
"""
# TODO: color stderr
# TODO: simplify javascript using ,ore than 1 class in the class attribute?
import datetime
import io
import sys
import time
import unittest
from xml.sax import saxutils
# ------------------------------------------------------------------------
# The redirectors below are used to capture output during testing. Output
# sent to sys.stdout and sys.stderr are automatically captured. However
# in some cases sys.stdout is already cached before HTMLTestRunner is
# invoked (e.g. calling logging.basicConfig). In order to capture those
# output, use the redirectors for the cached stream.
#
# e.g.
# >>> logging.basicConfig(stream=HTMLTestRunner.stdout_redirector)
# >>>
class OutputRedirector(object):
""" Wrapper to redirect stdout or stderr """
def __init__(self, fp):
self.fp = fp
def write(self, s):
self.fp.write(s)
def writelines(self, lines):
self.fp.writelines(lines)
def flush(self):
self.fp.flush()
stdout_redirector = OutputRedirector(sys.stdout)
stderr_redirector = OutputRedirector(sys.stderr)
# ----------------------------------------------------------------------
# Template
class Template_mixin(object):
"""
Define a HTML template for report customerization and generation.
Overall structure of an HTML report
HTML
+------------------------+
|<html> |
| <head> |
| |
| STYLESHEET |
| +----------------+ |
| | | |
| +----------------+ |
| |
| </head> |
| |
| <body> |
| |
| HEADING |
| +----------------+ |
| | | |
| +----------------+ |
| |
| REPORT |
| +----------------+ |
| | | |
| +----------------+ |
| |
| ENDING |
| +----------------+ |
| | | |
| +----------------+ |
| |
| </body> |
|</html> |
+------------------------+
"""
STATUS = {
0: '通过',
1: '失败',
2: '错误',
}
DEFAULT_TITLE = '多测师自动化测试报告'
DEFAULT_DESCRIPTION = ''
DEFAULT_TESTER = '多测师_王sir'
# ------------------------------------------------------------------------
# HTML Template
HTML_TMPL = r"""<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>%(title)s</title>
<meta name="generator" content="%(generator)s"/>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
<link href="http://libs.baidu.com/bootstrap/3.0.3/css/bootstrap.min.css" rel="stylesheet">
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
<script src="http://libs.baidu.com/bootstrap/3.0.3/js/bootstrap.min.js"></script>
%(stylesheet)s
</head>
<body >
<script language="javascript" type="text/javascript">
output_list = Array();
/*level 调整增加只显示通过用例的分类 --Findyou
0:Summary //all hiddenRow
1:Failed //pt hiddenRow, ft none
2:Pass //pt none, ft hiddenRow
3:All //pt none, ft none
*/
function showCase(level) {
trs = document.getElementsByTagName("tr");
for (var i = 0; i < trs.length; i++) {
tr = trs[i];
id = tr.id;
if (id.substr(0,2) == 'ft') {
if (level == 2 || level == 0 ) {
tr.className = 'hiddenRow';
}
else {
tr.className = '';
}
}
if (id.substr(0,2) == 'pt') {
if (level < 2) {
tr.className = 'hiddenRow';
}
else {
tr.className = '';
}
}
}
//加入【详细】切换文字变化 --Findyou
detail_class=document.getElementsByClassName('detail');
//console.log(detail_class.length)
if (level == 3) {
for (var i = 0; i < detail_class.length; i++){
detail_class[i].innerHTML="收起"
}
}
else{
for (var i = 0; i < detail_class.length; i++){
detail_class[i].innerHTML="详细"
}
}
}
function showClassDetail(cid, count) {
var id_list = Array(count);
var toHide = 1;
for (var i = 0; i < count; i++) {
//ID修改 点 为 下划线 -Findyou
tid0 = 't' + cid.substr(1) + '_' + (i+1);
tid = 'f' + tid0;
tr = document.getElementById(tid);
if (!tr) {
tid = 'p' + tid0;
tr = document.getElementById(tid);
}
id_list[i] = tid;
if (tr.className) {
toHide = 0;
}
}
for (var i = 0; i < count; i++) {
tid = id_list[i];
//修改点击无法收起的BUG,加入【详细】切换文字变化 --Findyou
if (toHide) {
document.getElementById(tid).className = 'hiddenRow';
document.getElementById(cid).innerText = "详细"
}
else {
document.getElementById(tid).className = '';
document.getElementById(cid).innerText = "收起"
}
}
}
function html_escape(s) {
s = s.replace(/&/g,'&');
s = s.replace(/</g,'<');
s = s.replace(/>/g,'>');
return s;
}
</script>
%(heading)s
%(report)s
%(ending)s
</body>
</html>
"""
# variables: (title, generator, stylesheet, heading, report, ending)
# ------------------------------------------------------------------------
# Stylesheet
#
# alternatively use a <link> for external style sheet, e.g.
# <link rel="stylesheet" href="$url" type="text/css">
STYLESHEET_TMPL = """
<style type="text/css" media="screen">
body { font-family: Microsoft YaHei,Tahoma,arial,helvetica,sans-serif;padding: 20px; font-size: 120%; }
table { font-size: 100%; }
/* -- heading ---------------------------------------------------------------------- */
.heading {
margin-top: 0ex;
margin-bottom: 1ex;
}
.heading .description {
margin-top: 4ex;
margin-bottom: 6ex;
}
/* -- report ------------------------------------------------------------------------ */
#total_row { font-weight: bold; }
.passCase { color: #5cb85c; }
.failCase { color: #d9534f; font-weight: bold; }
.errorCase { color: #f0ad4e; font-weight: bold; }
.hiddenRow { display: none; }
.testcase { margin-left: 2em; }
</style>
"""
# ------------------------------------------------------------------------
# Heading
#
HEADING_TMPL = """<div class='heading'>
<h1 style="font-family: Microsoft YaHei">%(title)s</h1>
%(parameters)s
<p class='description'>%(description)s</p>
</div>
""" # variables: (title, parameters, description)
HEADING_ATTRIBUTE_TMPL = """<p class='attribute'><strong>%(name)s : </strong> %(value)s</p>
""" # variables: (name, value)
# ------------------------------------------------------------------------
# Report
#
# 汉化,加美化效果 --Findyou
REPORT_TMPL = """
<p id='show_detail_line'>
<a class="btn btn-primary" href='javascript:showCase(0)'>概要{ %(passrate)s }</a>
<a class="btn btn-danger" href='javascript:showCase(1)'>失败{ %(fail)s }</a>
<a class="btn btn-success" href='javascript:showCase(2)'>通过{ %(Pass)s }</a>
<a class="btn btn-info" href='javascript:showCase(3)'>所有{ %(count)s }</a>
</p>
<table id='result_table' class="table table-condensed table-bordered table-hover">
<colgroup>
<col align='left' />
<col align='right' />
<col align='right' />
<col align='right' />
<col align='right' />
<col align='right' />
</colgroup>
<tr id='header_row' class="text-center success" style="font-weight: bold;font-size: 16px;">
<td>用例集/测试用例</td>
<td>总计</td>
<td>通过</td>
<td>失败</td>
<td>错误</td>
<td>详细</td>
</tr>
%(test_list)s
<tr id='total_row' class="text-center active">
<td>总计</td>
<td>%(count)s</td>
<td>%(Pass)s</td>
<td>%(fail)s</td>
<td>%(error)s</td>
<td>通过率:%(passrate)s</td>
</tr>
</table>
""" # variables: (test_list, count, Pass, fail, error ,passrate)
REPORT_CLASS_TMPL = r"""
<tr class='%(style)s warning'>
<td>%(desc)s</td>
<td class="text-center">%(count)s</td>
<td class="text-center">%(Pass)s</td>
<td class="text-center">%(fail)s</td>
<td class="text-center">%(error)s</td>
<td class="text-center"><a href="javascript:showClassDetail('%(cid)s',%(count)s)" class="detail" id='%(cid)s'>详细</a></td>
</tr>
""" # variables: (style, desc, count, Pass, fail, error, cid)
# 失败 的样式,去掉原来JS效果,美化展示效果 -Findyou
REPORT_TEST_WITH_OUTPUT_TMPL = r"""
<tr id='%(tid)s' class='%(Class)s'>
<td class='%(style)s'><div class='testcase'>%(desc)s</div></td>
<td colspan='5' align='center'>
<!--默认收起错误信息 -Findyou
<button id='btn_%(tid)s' type="button" class="btn btn-danger btn-xs collapsed" data-toggle="collapse" data-target='#div_%(tid)s'>%(status)s</button>
<div id='div_%(tid)s' class="collapse"> -->
<!-- 默认展开错误信息 -Findyou -->
<button id='btn_%(tid)s' type="button" class="btn btn-danger btn-xs" data-toggle="collapse" data-target='#div_%(tid)s'>%(status)s</button>
<div id='div_%(tid)s' class="collapse in" align="left">
<pre>
%(script)s
</pre>
</div>
</td>
</tr>
""" # variables: (tid, Class, style, desc, status)
# 通过 的样式,加标签效果 -Findyou
REPORT_TEST_NO_OUTPUT_TMPL = r"""
<tr id='%(tid)s' class='%(Class)s'>
<td class='%(style)s'><div class='testcase'>%(desc)s</div></td>
<td colspan='5' align='center'><span class="label label-success success">%(status)s</span></td>
</tr>
""" # variables: (tid, Class, style, desc, status)
REPORT_TEST_OUTPUT_TMPL = r"""
%(id)s: %(output)s
""" # variables: (id, output)
# ------------------------------------------------------------------------
# ENDING
#
# 增加返回顶部按钮 --Findyou
ENDING_TMPL = """<div id='ending'> </div>
<div style=" position:fixed;right:50px; bottom:30px; width:20px; height:20px;cursor:pointer">
<a href="#"><span class="glyphicon glyphicon-eject" style = "font-size:30px;" aria-hidden="true">
</span></a></div>
"""
# -------------------- The end of the Template class -------------------
TestResult = unittest.TestResult
class _TestResult(TestResult):
# note: _TestResult is a pure representation of results.
# It lacks the output and reporting ability compares to unittest._TextTestResult.
def __init__(self, verbosity=1):
TestResult.__init__(self)
self.stdout0 = None
self.stderr0 = None
self.success_count = 0
self.failure_count = 0
self.error_count = 0
self.verbosity = verbosity
# result is a list of result in 4 tuple
# (
# result code (0: success; 1: fail; 2: error),
# TestCase object,
# Test output (byte string),
# stack trace,
# )
self.result = []
# 增加一个测试通过率 --Findyou
self.passrate = float(0)
def startTest(self, test):
print("{0} - Start Test:{1}".format(time.asctime(), str(test)))
TestResult.startTest(self, test)
# just one buffer for both stdout and stderr
self.outputBuffer = io.StringIO()
stdout_redirector.fp = self.outputBuffer
stderr_redirector.fp = self.outputBuffer
self.stdout0 = sys.stdout
self.stderr0 = sys.stderr
sys.stdout = stdout_redirector
sys.stderr = stderr_redirector
def complete_output(self):
"""
Disconnect output redirection and return buffer.
Safe to call multiple times.
"""
if self.stdout0:
sys.stdout = self.stdout0
sys.stderr = self.stderr0
self.stdout0 = None
self.stderr0 = None
return self.outputBuffer.getvalue()
def stopTest(self, test):
# Usually one of addSuccess, addError or addFailure would have been called.
# But there are some path in unittest that would bypass this.
# We must disconnect stdout in stopTest(), which is guaranteed to be called.
self.complete_output()
def addSuccess(self, test):
self.success_count += 1
TestResult.addSuccess(self, test)
output = self.complete_output()
self.result.append((0, test, output, ''))
if self.verbosity > 1:
sys.stderr.write('ok ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('.')
def addError(self, test, err):
self.error_count += 1
TestResult.addError(self, test, err)
_, _exc_str = self.errors[-1]
output = self.complete_output()
self.result.append((2, test, output, _exc_str))
if self.verbosity > 1:
sys.stderr.write('E列表 ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('E列表')
def addFailure(self, test, err):
self.failure_count += 1
TestResult.addFailure(self, test, err)
_, _exc_str = self.failures[-1]
output = self.complete_output()
self.result.append((1, test, output, _exc_str))
if self.verbosity > 1:
sys.stderr.write('F ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('F')
class HTMLTestRunner(Template_mixin):
"""
"""
def __init__(self, stream=sys.stdout, verbosity=2, title=None, description=None, tester=None):
self.stream = stream
self.verbosity = verbosity
if title is None:
self.title = self.DEFAULT_TITLE
else:
self.title = title
if description is None:
self.description = self.DEFAULT_DESCRIPTION
else:
self.description = description
if tester is None:
self.tester = self.DEFAULT_TESTER
else:
self.tester = tester
self.startTime = datetime.datetime.now()
def run(self, test):
"Run the given test case or test suite."
result = _TestResult(self.verbosity)
test(result)
self.stopTime = datetime.datetime.now()
self.generateReport(test, result)
print('\nTime Elapsed: %s' % (self.stopTime - self.startTime), file=sys.stderr)
return result
def sortResult(self, result_list):
# unittest does not seems to run in any particular order.
# Here at least we want to group them together by class.
rmap = {}
classes = []
for n, t, o, e in result_list:
cls = t.__class__
if cls not in rmap:
rmap[cls] = []
classes.append(cls)
rmap[cls].append((n, t, o, e))
r = [(cls, rmap[cls]) for cls in classes]
return r
# 替换测试结果status为通过率 --Findyou
def getReportAttributes(self, result):
"""
Return report attributes as a list of (name, value).
Override this to add custom attributes.
"""
startTime = str(self.startTime)[:19]
duration = str(self.stopTime - self.startTime)
status = []
status.append('共 %s' % (result.success_count + result.failure_count + result.error_count))
if result.success_count: status.append('通过 %s' % result.success_count)
if result.failure_count: status.append('失败 %s' % result.failure_count)
if result.error_count: status.append('错误 %s' % result.error_count)
if status:
status = ','.join(status)
self.passrate = str("%.2f%%" % (float(result.success_count) / float(
result.success_count + result.failure_count + result.error_count) * 100))
else:
status = 'none'
return [
('测试人员', self.tester),
('开始时间', startTime),
('合计耗时', duration),
('测试结果', status + ",通过率= " + self.passrate),
]
def generateReport(self, test, result):
report_attrs = self.getReportAttributes(result)
generator = 'HTMLTestRunner %s' % __version__
stylesheet = self._generate_stylesheet()
heading = self._generate_heading(report_attrs)
report = self._generate_report(result)
ending = self._generate_ending()
output = self.HTML_TMPL % dict(
title=saxutils.escape(self.title),
generator=generator,
stylesheet=stylesheet,
heading=heading,
report=report,
ending=ending,
)
self.stream.write(output.encode('utf8'))
def _generate_stylesheet(self):
return self.STYLESHEET_TMPL
# 增加Tester显示 -Findyou
def _generate_heading(self, report_attrs):
a_lines = []
for name, value in report_attrs:
line = self.HEADING_ATTRIBUTE_TMPL % dict(
name=saxutils.escape(name),
value=saxutils.escape(value),
)
a_lines.append(line)
heading = self.HEADING_TMPL % dict(
title=saxutils.escape(self.title),
parameters=''.join(a_lines),
description=saxutils.escape(self.description),
tester=saxutils.escape(self.tester),
)
return heading
# 生成报告 --Findyou添加注释
def _generate_report(self, result):
rows = []
sortedResult = self.sortResult(result.result)
for cid, (cls, cls_results) in enumerate(sortedResult):
# subtotal for a class
np = nf = ne = 0
for n, t, o, e in cls_results:
if n == 0:
np += 1
elif n == 1:
nf += 1
else:
ne += 1
# format class description
if cls.__module__ == "__main__":
name = cls.__name__
else:
name = "%s.%s" % (cls.__module__, cls.__name__)
doc = cls.__doc__ and cls.__doc__.split("\n")[0] or ""
desc = doc and '%s: %s' % (name, doc) or name
row = self.REPORT_CLASS_TMPL % dict(
style=ne > 0 and 'errorClass' or nf > 0 and 'failClass' or 'passClass',
desc=desc,
count=np + nf + ne,
Pass=np,
fail=nf,
error=ne,
cid='c%s' % (cid + 1),
)
rows.append(row)
for tid, (n, t, o, e) in enumerate(cls_results):
self._generate_report_test(rows, cid, tid, n, t, o, e)
report = self.REPORT_TMPL % dict(
test_list=''.join(rows),
count=str(result.success_count + result.failure_count + result.error_count),
Pass=str(result.success_count),
fail=str(result.failure_count),
error=str(result.error_count),
passrate=self.passrate,
)
return report
def _generate_report_test(self, rows, cid, tid, n, t, o, e):
# e.g. 'pt1.1', 'ft1.1', etc
has_output = bool(o or e)
# ID修改点为下划线,支持Bootstrap折叠展开特效 - Findyou
tid = (n == 0 and 'p' or 'f') + 't%s_%s' % (cid + 1, tid + 1)
name = t.id().split('.')[-1]
doc = t.shortDescription() or ""
desc = doc and ('%s: %s' % (name, doc)) or name
tmpl = has_output and self.REPORT_TEST_WITH_OUTPUT_TMPL or self.REPORT_TEST_NO_OUTPUT_TMPL
# utf-8 支持中文 - Findyou
# o and e should be byte string because they are collected from stdout and stderr?
if isinstance(o, str):
# TODO: some problem with 'string_escape': it escape \n and mess up formating
# uo = unicode(o.encode('string_escape'))
# uo = o.decode('latin-1')
uo = o
else:
uo = o
if isinstance(e, str):
# TODO: some problem with 'string_escape': it escape \n and mess up formating
# ue = unicode(e.encode('string_escape'))
# ue = e.decode('latin-1')
ue = e
else:
ue = e
script = self.REPORT_TEST_OUTPUT_TMPL % dict(
id=tid,
output=saxutils.escape(uo + ue),
)
row = tmpl % dict(
tid=tid,
Class=(n == 0 and 'hiddenRow' or 'none'),
style=n == 2 and 'errorCase' or (n == 1 and 'failCase' or 'passCase'),
desc=desc,
script=script,
status=self.STATUS[n],
)
rows.append(row)
if not has_output:
return
def _generate_ending(self):
return self.ENDING_TMPL
##############################################################################
# Facilities for running tests from the command line
##############################################################################
# Note: Reuse unittest.TestProgram to launch test. In the future we may
# build our own launcher to support more specific command line
# parameters like test title, CSS, etc.
class TestProgram(unittest.TestProgram):
"""
A连接信息 variation of the unittest.TestProgram. Please refer to the base
class for command line parameters.
"""
def runTests(self):
# Pick HTMLTestRunner as the default test runner.
# base class's testRunner parameter is not useful because it means
# we have to instantiate HTMLTestRunner before we know self.verbosity.
if self.testRunner is None:
self.testRunner = HTMLTestRunner(verbosity=self.verbosity)
unittest.TestProgram.runTests(self)
main = TestProgram
##############################################################################
# Executing this module from the command line
##############################################################################
if __name__ == "__main__":
main(module=None)
HTMLTestRunner3_New.py
# coding=utf-8
"""
A连接信息 TestRunner for use with the Python unit testing framework. It
generates a HTML report to show the result at a glance.
The simplest way to use this is to invoke its main method. E列表.g.
import unittest
import HTMLTestRunner
... define your tests ...
if __name__ == '__main__':
HTMLTestRunner.main()
For more customization options, instantiates a HTMLTestRunner object.
HTMLTestRunner is a counterpart to unittest's TextTestRunner. E列表.g.
# output to a file
fp = file('my_report.html', 'wb')
runner = HTMLTestRunner.HTMLTestRunner(
stream=fp,
title='My unit test',
description='This demonstrates the report output by HTMLTestRunner.'
)
# Use an external stylesheet.
# See the Template_mixin class for more customizable options
runner.STYLESHEET_TMPL = '<link rel="stylesheet" href="my_stylesheet.css" type="text/css">'
# run the test
runner.run(my_test_suite)
------------------------------------------------------------------------
Copyright (c) 2004-2007, Wai Yip Tung
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are
met:
* Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or 课堂代码 materials provided with the distribution.
* Neither the name Wai Yip Tung nor the names of its contributors may be
used to endorse or promote products derived from this software without
specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS
IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED
TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A连接信息
PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER
OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""
# URL: http://tungwaiyip.info/software/HTMLTestRunner.html
__author__ = "Wai Yip Tung, Findyou"
__version__ = "0.8.2.2"
"""
Change History
Version 0.8.2.1 -Findyou
* 改为支持python3
Version 0.8.2.1 -Findyou
* 支持中文,汉化
* 调整样式,美化(需要连入网络,使用的百度的Bootstrap.js)
* 增加 通过分类显示、测试人员、通过率的展示
* 优化“详细”与“收起”状态的变换
* 增加返回顶部的锚点
Version 0.8.2
* Show output inline instead of popup window (Viorel Lupu).
Version in 0.8.1
* Validated XHTML (Wolfgang Borgert).
* Added description of test classes and test cases.
Version in 0.8.0
* Define Template_mixin class for customization.
* Workaround a IE 6 bug that it does not treat <script> block as CDATA.
Version in 0.7.1
* Back port to Python 2.3 (Frank Horowitz).
* Fix missing scroll bars in detail log (Podi).
"""
# TODO: color stderr
# TODO: simplify javascript using ,ore than 1 class in the class attribute?
import datetime
import io
import sys
import time
import unittest
from xml.sax import saxutils
# ------------------------------------------------------------------------
# The redirectors below are used to capture output during testing. Output
# sent to sys.stdout and sys.stderr are automatically captured. However
# in some cases sys.stdout is already cached before HTMLTestRunner is
# invoked (e.g. calling logging.basicConfig). In order to capture those
# output, use the redirectors for the cached stream.
#
# e.g.
# >>> logging.basicConfig(stream=HTMLTestRunner.stdout_redirector)
# >>>
class OutputRedirector(object):
""" Wrapper to redirect stdout or stderr """
def __init__(self, fp):
self.fp = fp
def write(self, s):
self.fp.write(s)
def writelines(self, lines):
self.fp.writelines(lines)
def flush(self):
self.fp.flush()
stdout_redirector = OutputRedirector(sys.stdout)
stderr_redirector = OutputRedirector(sys.stderr)
# ----------------------------------------------------------------------
# Template
class Template_mixin(object):
"""
Define a HTML template for report customerization and generation.
Overall structure of an HTML report
HTML
+------------------------+
|<html> |
| <head> |
| |
| STYLESHEET |
| +----------------+ |
| | | |
| +----------------+ |
| |
| </head> |
| |
| <body> |
| |
| HEADING |
| +----------------+ |
| | | |
| +----------------+ |
| |
| REPORT |
| +----------------+ |
| | | |
| +----------------+ |
| |
| ENDING |
| +----------------+ |
| | | |
| +----------------+ |
| |
| </body> |
|</html> |
+------------------------+
"""
STATUS = {
0: '通过',
1: '失败',
2: '错误',
}
DEFAULT_TITLE = '多测师自动化测试报告'
DEFAULT_DESCRIPTION = ''
DEFAULT_TESTER = '多测师_王sir'
# ------------------------------------------------------------------------
# HTML Template
HTML_TMPL = r"""<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>%(title)s</title>
<meta name="generator" content="%(generator)s"/>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
<link href="http://libs.baidu.com/bootstrap/3.0.3/css/bootstrap.min.css" rel="stylesheet">
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
<script src="http://libs.baidu.com/bootstrap/3.0.3/js/bootstrap.min.js"></script>
%(stylesheet)s
</head>
<body >
<script language="javascript" type="text/javascript">
output_list = Array();
/*level 调整增加只显示通过用例的分类 --Findyou
0:Summary //all hiddenRow
1:Failed //pt hiddenRow, ft none
2:Pass //pt none, ft hiddenRow
3:All //pt none, ft none
*/
function showCase(level) {
trs = document.getElementsByTagName("tr");
for (var i = 0; i < trs.length; i++) {
tr = trs[i];
id = tr.id;
if (id.substr(0,2) == 'ft') {
if (level == 2 || level == 0 ) {
tr.className = 'hiddenRow';
}
else {
tr.className = '';
}
}
if (id.substr(0,2) == 'pt') {
if (level < 2) {
tr.className = 'hiddenRow';
}
else {
tr.className = '';
}
}
}
//加入【详细】切换文字变化 --Findyou
detail_class=document.getElementsByClassName('detail');
//console.log(detail_class.length)
if (level == 3) {
for (var i = 0; i < detail_class.length; i++){
detail_class[i].innerHTML="收起"
}
}
else{
for (var i = 0; i < detail_class.length; i++){
detail_class[i].innerHTML="详细"
}
}
}
function showClassDetail(cid, count) {
var id_list = Array(count);
var toHide = 1;
for (var i = 0; i < count; i++) {
//ID修改 点 为 下划线 -Findyou
tid0 = 't' + cid.substr(1) + '_' + (i+1);
tid = 'f' + tid0;
tr = document.getElementById(tid);
if (!tr) {
tid = 'p' + tid0;
tr = document.getElementById(tid);
}
id_list[i] = tid;
if (tr.className) {
toHide = 0;
}
}
for (var i = 0; i < count; i++) {
tid = id_list[i];
//修改点击无法收起的BUG,加入【详细】切换文字变化 --Findyou
if (toHide) {
document.getElementById(tid).className = 'hiddenRow';
document.getElementById(cid).innerText = "详细"
}
else {
document.getElementById(tid).className = '';
document.getElementById(cid).innerText = "收起"
}
}
}
function html_escape(s) {
s = s.replace(/&/g,'&');
s = s.replace(/</g,'<');
s = s.replace(/>/g,'>');
return s;
}
</script>
%(heading)s
%(report)s
%(ending)s
</body>
</html>
"""
# variables: (title, generator, stylesheet, heading, report, ending)
# ------------------------------------------------------------------------
# Stylesheet
#
# alternatively use a <link> for external style sheet, e.g.
# <link rel="stylesheet" href="$url" type="text/css">
STYLESHEET_TMPL = """
<style type="text/css" media="screen">
body { font-family: Microsoft YaHei,Tahoma,arial,helvetica,sans-serif;padding: 20px; font-size: 120%; }
table { font-size: 100%; }
/* -- heading ---------------------------------------------------------------------- */
.heading {
margin-top: 0ex;
margin-bottom: 1ex;
}
.heading .description {
margin-top: 4ex;
margin-bottom: 6ex;
}
/* -- report ------------------------------------------------------------------------ */
#total_row { font-weight: bold; }
.passCase { color: #5cb85c; }
.failCase { color: #d9534f; font-weight: bold; }
.errorCase { color: #f0ad4e; font-weight: bold; }
.hiddenRow { display: none; }
.testcase { margin-left: 2em; }
</style>
"""
# ------------------------------------------------------------------------
# Heading
#
HEADING_TMPL = """<div class='heading'>
<h1 style="font-family: Microsoft YaHei">%(title)s</h1>
%(parameters)s
<p class='description'>%(description)s</p>
</div>
""" # variables: (title, parameters, description)
HEADING_ATTRIBUTE_TMPL = """<p class='attribute'><strong>%(name)s : </strong> %(value)s</p>
""" # variables: (name, value)
# ------------------------------------------------------------------------
# Report
#
# 汉化,加美化效果 --Findyou
REPORT_TMPL = """
<p id='show_detail_line'>
<a class="btn btn-primary" href='javascript:showCase(0)'>概要{ %(passrate)s }</a>
<a class="btn btn-danger" href='javascript:showCase(1)'>失败{ %(fail)s }</a>
<a class="btn btn-success" href='javascript:showCase(2)'>通过{ %(Pass)s }</a>
<a class="btn btn-info" href='javascript:showCase(3)'>所有{ %(count)s }</a>
</p>
<table id='result_table' class="table table-condensed table-bordered table-hover">
<colgroup>
<col align='left' />
<col align='right' />
<col align='right' />
<col align='right' />
<col align='right' />
<col align='right' />
</colgroup>
<tr id='header_row' class="text-center success" style="font-weight: bold;font-size: 16px;">
<td>用例集/测试用例</td>
<td>总计</td>
<td>通过</td>
<td>失败</td>
<td>错误</td>
<td>详细</td>
</tr>
%(test_list)s
<tr id='total_row' class="text-center active">
<td>总计</td>
<td>%(count)s</td>
<td>%(Pass)s</td>
<td>%(fail)s</td>
<td>%(error)s</td>
<td>通过率:%(passrate)s</td>
</tr>
</table>
""" # variables: (test_list, count, Pass, fail, error ,passrate)
REPORT_CLASS_TMPL = r"""
<tr class='%(style)s warning'>
<td>%(desc)s</td>
<td class="text-center">%(count)s</td>
<td class="text-center">%(Pass)s</td>
<td class="text-center">%(fail)s</td>
<td class="text-center">%(error)s</td>
<td class="text-center"><a href="javascript:showClassDetail('%(cid)s',%(count)s)" class="detail" id='%(cid)s'>详细</a></td>
</tr>
""" # variables: (style, desc, count, Pass, fail, error, cid)
# 失败 的样式,去掉原来JS效果,美化展示效果 -Findyou
REPORT_TEST_WITH_OUTPUT_TMPL = r"""
<tr id='%(tid)s' class='%(Class)s'>
<td class='%(style)s'><div class='testcase'>%(desc)s</div></td>
<td colspan='5' align='center'>
<!--默认收起错误信息 -Findyou
<button id='btn_%(tid)s' type="button" class="btn btn-danger btn-xs collapsed" data-toggle="collapse" data-target='#div_%(tid)s'>%(status)s</button>
<div id='div_%(tid)s' class="collapse"> -->
<!-- 默认展开错误信息 -Findyou -->
<button id='btn_%(tid)s' type="button" class="btn btn-danger btn-xs" data-toggle="collapse" data-target='#div_%(tid)s'>%(status)s</button>
<div id='div_%(tid)s' class="collapse in" align="left">
<pre>
%(script)s
</pre>
</div>
</td>
</tr>
""" # variables: (tid, Class, style, desc, status)
# 通过 的样式,加标签效果 -Findyou
REPORT_TEST_NO_OUTPUT_TMPL = r"""
<tr id='%(tid)s' class='%(Class)s'>
<td class='%(style)s'><div class='testcase'>%(desc)s</div></td>
<td colspan='5' align='center'><span class="label label-success success">%(status)s</span></td>
</tr>
""" # variables: (tid, Class, style, desc, status)
REPORT_TEST_OUTPUT_TMPL = r"""
%(id)s: %(output)s
""" # variables: (id, output)
# ------------------------------------------------------------------------
# ENDING
#
# 增加返回顶部按钮 --Findyou
ENDING_TMPL = """<div id='ending'> </div>
<div style=" position:fixed;right:50px; bottom:30px; width:20px; height:20px;cursor:pointer">
<a href="#"><span class="glyphicon glyphicon-eject" style = "font-size:30px;" aria-hidden="true">
</span></a></div>
"""
# -------------------- The end of the Template class -------------------
TestResult = unittest.TestResult
class _TestResult(TestResult):
# note: _TestResult is a pure representation of results.
# It lacks the output and reporting ability compares to unittest._TextTestResult.
def __init__(self, verbosity=1):
TestResult.__init__(self)
self.stdout0 = None
self.stderr0 = None
self.success_count = 0
self.failure_count = 0
self.error_count = 0
self.verbosity = verbosity
# result is a list of result in 4 tuple
# (
# result code (0: success; 1: fail; 2: error),
# TestCase object,
# Test output (byte string),
# stack trace,
# )
self.result = []
# 增加一个测试通过率 --Findyou
self.passrate = float(0)
def startTest(self, test):
print("{0} - Start Test:{1}".format(time.asctime(), str(test)))
TestResult.startTest(self, test)
# just one buffer for both stdout and stderr
self.outputBuffer = io.StringIO()
stdout_redirector.fp = self.outputBuffer
stderr_redirector.fp = self.outputBuffer
self.stdout0 = sys.stdout
self.stderr0 = sys.stderr
sys.stdout = stdout_redirector
sys.stderr = stderr_redirector
def complete_output(self):
"""
Disconnect output redirection and return buffer.
Safe to call multiple times.
"""
if self.stdout0:
sys.stdout = self.stdout0
sys.stderr = self.stderr0
self.stdout0 = None
self.stderr0 = None
return self.outputBuffer.getvalue()
def stopTest(self, test):
# Usually one of addSuccess, addError or addFailure would have been called.
# But there are some path in unittest that would bypass this.
# We must disconnect stdout in stopTest(), which is guaranteed to be called.
self.complete_output()
def addSuccess(self, test):
self.success_count += 1
TestResult.addSuccess(self, test)
output = self.complete_output()
self.result.append((0, test, output, ''))
if self.verbosity > 1:
sys.stderr.write('ok ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('.')
def addError(self, test, err):
self.error_count += 1
TestResult.addError(self, test, err)
_, _exc_str = self.errors[-1]
output = self.complete_output()
self.result.append((2, test, output, _exc_str))
if self.verbosity > 1:
sys.stderr.write('E列表 ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('E列表')
def addFailure(self, test, err):
self.failure_count += 1
TestResult.addFailure(self, test, err)
_, _exc_str = self.failures[-1]
output = self.complete_output()
self.result.append((1, test, output, _exc_str))
if self.verbosity > 1:
sys.stderr.write('F ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('F')
class HTMLTestRunner(Template_mixin):
"""
"""
def __init__(self, stream=sys.stdout, verbosity=2, title=None, description=None, tester=None):
self.stream = stream
self.verbosity = verbosity
if title is None:
self.title = self.DEFAULT_TITLE
else:
self.title = title
if description is None:
self.description = self.DEFAULT_DESCRIPTION
else:
self.description = description
if tester is None:
self.tester = self.DEFAULT_TESTER
else:
self.tester = tester
self.startTime = datetime.datetime.now()
def run(self, test):
"Run the given test case or test suite."
result = _TestResult(self.verbosity)
test(result)
self.stopTime = datetime.datetime.now()
self.generateReport(test, result)
print('\nTime Elapsed: %s' % (self.stopTime - self.startTime), file=sys.stderr)
return result
def sortResult(self, result_list):
# unittest does not seems to run in any particular order.
# Here at least we want to group them together by class.
rmap = {}
classes = []
for n, t, o, e in result_list:
cls = t.__class__
if cls not in rmap:
rmap[cls] = []
classes.append(cls)
rmap[cls].append((n, t, o, e))
r = [(cls, rmap[cls]) for cls in classes]
return r
# 替换测试结果status为通过率 --Findyou
def getReportAttributes(self, result):
"""
Return report attributes as a list of (name, value).
Override this to add custom attributes.
"""
startTime = str(self.startTime)[:19]
duration = str(self.stopTime - self.startTime)
status = []
status.append('共 %s' % (result.success_count + result.failure_count + result.error_count))
if result.success_count: status.append('通过 %s' % result.success_count)
if result.failure_count: status.append('失败 %s' % result.failure_count)
if result.error_count: status.append('错误 %s' % result.error_count)
if status:
status = ','.join(status)
self.passrate = str("%.2f%%" % (float(result.success_count) / float(
result.success_count + result.failure_count + result.error_count) * 100))
else:
status = 'none'
return [
('测试人员', self.tester),
('开始时间', startTime),
('合计耗时', duration),
('测试结果', status + ",通过率= " + self.passrate),
]
def generateReport(self, test, result):
report_attrs = self.getReportAttributes(result)
generator = 'HTMLTestRunner %s' % __version__
stylesheet = self._generate_stylesheet()
heading = self._generate_heading(report_attrs)
report = self._generate_report(result)
ending = self._generate_ending()
output = self.HTML_TMPL % dict(
title=saxutils.escape(self.title),
generator=generator,
stylesheet=stylesheet,
heading=heading,
report=report,
ending=ending,
)
self.stream.write(output.encode('utf8'))
def _generate_stylesheet(self):
return self.STYLESHEET_TMPL
# 增加Tester显示 -Findyou
def _generate_heading(self, report_attrs):
a_lines = []
for name, value in report_attrs:
line = self.HEADING_ATTRIBUTE_TMPL % dict(
name=saxutils.escape(name),
value=saxutils.escape(value),
)
a_lines.append(line)
heading = self.HEADING_TMPL % dict(
title=saxutils.escape(self.title),
parameters=''.join(a_lines),
description=saxutils.escape(self.description),
tester=saxutils.escape(self.tester),
)
return heading
# 生成报告 --Findyou添加注释
def _generate_report(self, result):
rows = []
sortedResult = self.sortResult(result.result)
for cid, (cls, cls_results) in enumerate(sortedResult):
# subtotal for a class
np = nf = ne = 0
for n, t, o, e in cls_results:
if n == 0:
np += 1
elif n == 1:
nf += 1
else:
ne += 1
# format class description
if cls.__module__ == "__main__":
name = cls.__name__
else:
name = "%s.%s" % (cls.__module__, cls.__name__)
doc = cls.__doc__ and cls.__doc__.split("\n")[0] or ""
desc = doc and '%s: %s' % (name, doc) or name
row = self.REPORT_CLASS_TMPL % dict(
style=ne > 0 and 'errorClass' or nf > 0 and 'failClass' or 'passClass',
desc=desc,
count=np + nf + ne,
Pass=np,
fail=nf,
error=ne,
cid='c%s' % (cid + 1),
)
rows.append(row)
for tid, (n, t, o, e) in enumerate(cls_results):
self._generate_report_test(rows, cid, tid, n, t, o, e)
report = self.REPORT_TMPL % dict(
test_list=''.join(rows),
count=str(result.success_count + result.failure_count + result.error_count),
Pass=str(result.success_count),
fail=str(result.failure_count),
error=str(result.error_count),
passrate=self.passrate,
)
return report
def _generate_report_test(self, rows, cid, tid, n, t, o, e):
# e.g. 'pt1.1', 'ft1.1', etc
has_output = bool(o or e)
# ID修改点为下划线,支持Bootstrap折叠展开特效 - Findyou
tid = (n == 0 and 'p' or 'f') + 't%s_%s' % (cid + 1, tid + 1)
name = t.id().split('.')[-1]
doc = t.shortDescription() or ""
desc = doc and ('%s: %s' % (name, doc)) or name
tmpl = has_output and self.REPORT_TEST_WITH_OUTPUT_TMPL or self.REPORT_TEST_NO_OUTPUT_TMPL
# utf-8 支持中文 - Findyou
# o and e should be byte string because they are collected from stdout and stderr?
if isinstance(o, str):
# TODO: some problem with 'string_escape': it escape \n and mess up formating
# uo = unicode(o.encode('string_escape'))
# uo = o.decode('latin-1')
uo = o
else:
uo = o
if isinstance(e, str):
# TODO: some problem with 'string_escape': it escape \n and mess up formating
# ue = unicode(e.encode('string_escape'))
# ue = e.decode('latin-1')
ue = e
else:
ue = e
script = self.REPORT_TEST_OUTPUT_TMPL % dict(
id=tid,
output=saxutils.escape(uo + ue),
)
row = tmpl % dict(
tid=tid,
Class=(n == 0 and 'hiddenRow' or 'none'),
style=n == 2 and 'errorCase' or (n == 1 and 'failCase' or 'passCase'),
desc=desc,
script=script,
status=self.STATUS[n],
)
rows.append(row)
if not has_output:
return
def _generate_ending(self):
return self.ENDING_TMPL
##############################################################################
# Facilities for running tests from the command line
##############################################################################
# Note: Reuse unittest.TestProgram to launch test. In the future we may
# build our own launcher to support more specific command line
# parameters like test title, CSS, etc.
class TestProgram(unittest.TestProgram):
"""
A连接信息 variation of the unittest.TestProgram. Please refer to the base
class for command line parameters.
"""
def runTests(self):
# Pick HTMLTestRunner as the default test runner.
# base class's testRunner parameter is not useful because it means
# we have to instantiate HTMLTestRunner before we know self.verbosity.
if self.testRunner is None:
self.testRunner = HTMLTestRunner(verbosity=self.verbosity)
unittest.TestProgram.runTests(self)
main = TestProgram
##############################################################################
# Executing this module from the command line
##############################################################################
if __name__ == "__main__":
main(module=None)
把报告模板放到project目录下: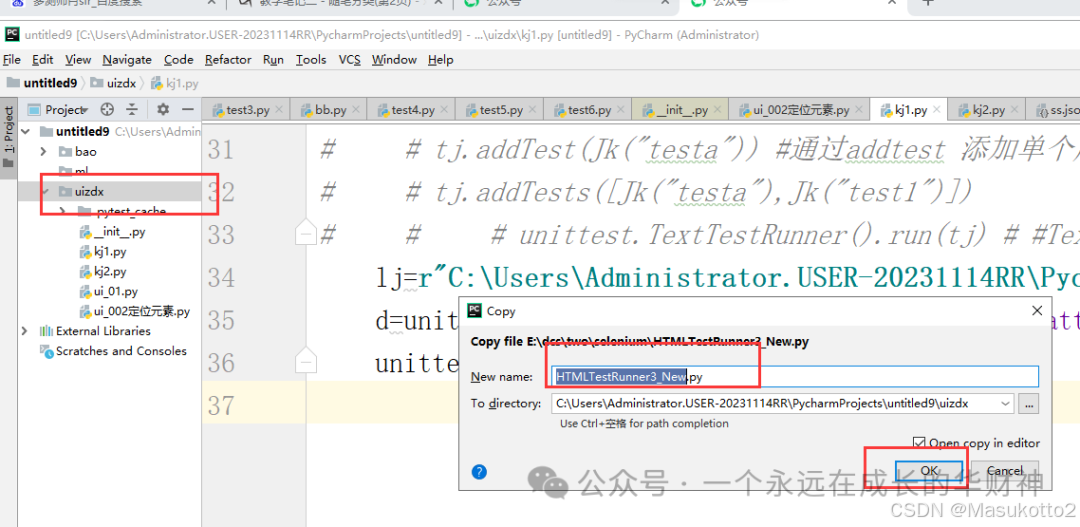
导入报告模板:
unittest框架操作:
import unittest #导入unittest 框架,python自带的框架
from time import *
from uizdx.HTMLTestRunner3_New import HTMLTestRunner
class Jk1(unittest.TestCase): #创建一个类,继承unittest.case的类
@classmethod
def setUpClass(cls) -> None:
print("类的开始")
@classmethod
def tearDownClass(cls) -> None:
print("类的结束")
def setUp(self) -> None:
print("方法开始")
def tearDown(self) -> None:
print("方法结束")
def test1(self):
print(1)
def test3(self):
print(3)
def test2(self):
print(2)
def testa(self):
print("a")
def testA(self):
print("A")
def testb(self):
print("b")
def test_du(self):
print("独有")
#
# if __name__ == '__main__':
# # unittest.main() #调用所有的用例
# # tj=unittest.TestSuite() #创建一个套件的对象
# # tj.addTest(Jk("testa")) #通过addtest 添加单个用例
# # tj.addTests([Jk("testa"),Jk("test1")])
# # # unittest.TextTestRunner().run(tj) # #TextTestRunner运行套件tj
lj=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\uizdx" #相对路径
d=unittest.TestLoader().discover(start_dir=lj,pattern="kj*.py")
bglj=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled9\uizdx" #相对路径
new=strftime("%y-%m-%d %H-%M-%S")
file=lj+"/"+str(new)+"_uizdh.html"
f=open(file,"bw")
b=HTMLTestRunner(
stream=f,description="自动化执行情况",title="ui自动化测试报告",
tester="dcs"
)
b.run(d) 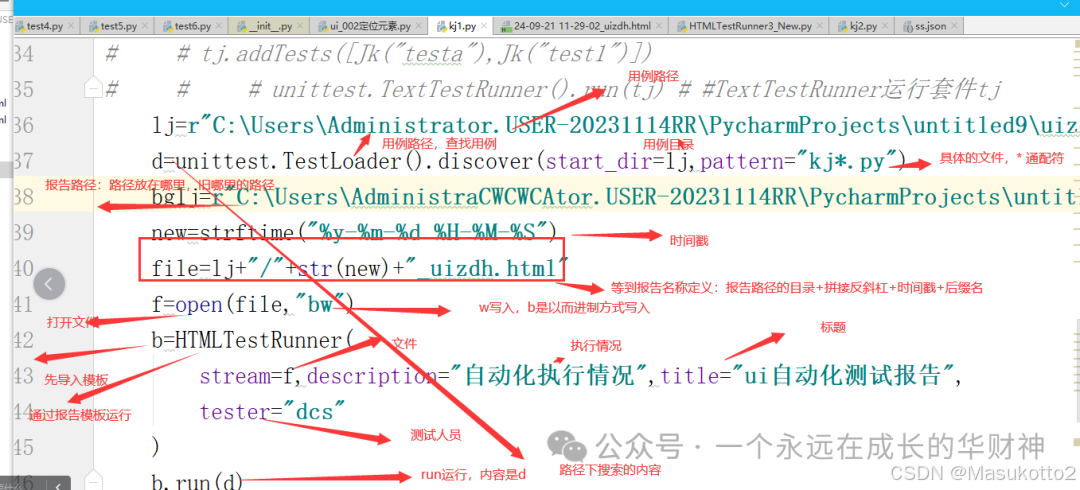
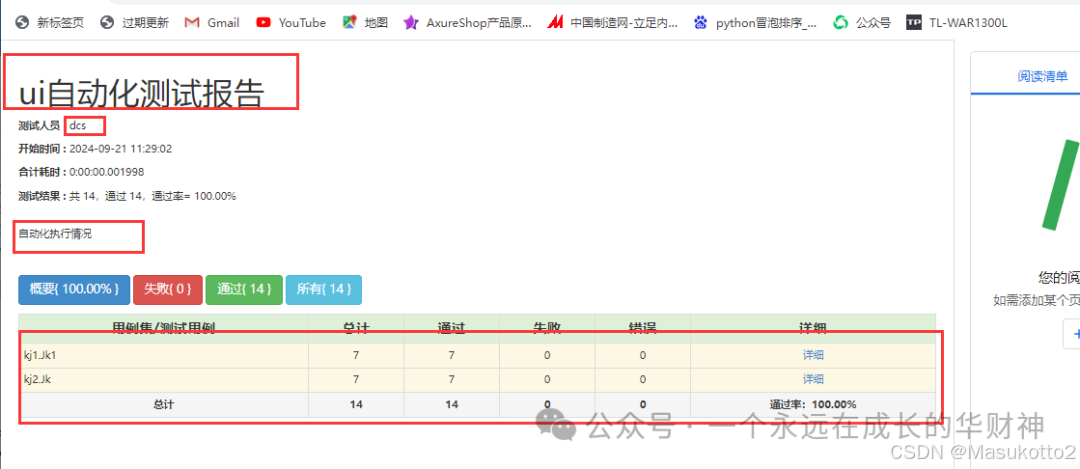
总结框架讲解--参考
讲解1:
流程:
我们要建立这个框架,首先需要导入unittest这个模块,我们做自动化的话还需要导入selenium这个模块,以及一些相关的,比方说time模块,OS模块,HTMLTestRunner模块。把我们需要的模块都导入,在unittest里我们需要去定义一个类,定义类名,继承testcase,一个testcase的实例就是一个用例,类里需要有类的开始:setupclass,以及类的结束:teardownclass,然后我们需要去定义我们的用例,test1,test2,注意一定要以test开头,因为TestLoader只搜索所有以test开头的测试用例。
写完用例以后,我们需要去调用它,我们以main作为unittest的入口,执行自动化我们主要有4种调用的方式
第一种用unittest.main()去运行所有用例
第二种是创建一个套件TestSuite(),然后用addtest去添加你要执行的用例,这种方法可以执行部分测试用例,不会全部执行
第三种就是搜索绝对路径去执行自动化,调用unittest.testloader.discover方法执行用例
第四种是生成测试报告,搜索绝对路径去执行自动化,调用unittest.testloader.discover方法执行用例,然后把执行结果写入我们导入的模板文件,执行之后就能看到我们路径下所有用例的执行结果。
以上就是unittest框架的整个基本流程
讲解2:
建立unittest框架流程:
第一步先导入unittest模块:import unittest;然后导入selenium模块:from selenium import webdriver、时间模块:from time import*等。第二步定义一个类,给这个类取一个类名,继承unittest.testcase,一个testcase就是一个用例,之后定义一个类方法,类方法要有类的开始(setUpClass)和类的结束(tearDownClass)。第三步进行方法的开始(setUp),每一条用例执行,他们都去执行,之后是方法的结束(tearDown)。第四步写用例,用例一定要用test开头=》test1、test2,没有以test开头的用例 ,不被运行。第五步调用函数,使用main方法(if __name__=='__main__':)进行主函数调用。第六步执行用例,第一种可以用unittest.main()运行所有用例;第二种可以创建一个套件TestSuite(),然后用addtest去添加你要执行的用例,这种方法可以执行部分测试用例,不会全部执行;第三种搜索绝对路径去执行自动化,调用unittest.testloader.discover方法执行用例;第四种生成测试报告,搜索绝对路径去执行自动化,调用unittest.testloader.discover方法执行用例,然后把执行结果写入我们导入的模板文件,执行之后就能看到我们路径下所有用例的执行结果。
讲解3:
下面我介绍一下自动化框架的基本流程:自动化框架是用来管理和组织测试用例的,首先我们先导入unittest框架,再导入本次测试应用到的一些模块,比如time模块(进行计时)等等。接下来我们进行类的定义,创建一个类,一个testcase就是一个用例,继承unittest.testcase,定义类需要类的开始setUpClass()和类的结束tearDownClass() ,在整个框架中只运行一次。为了减少代码的冗余,我们需要进行方法的定义,调用的时候直接使用这个方法名就可以了,方法的开始和结束每一条用例都会执行。然后我们进行用例定义,用例要以test开头,如果没有以test开头就不能运行,运行顺序按ascllma标准排序:0-9 A-Z a-z。
用例编写完成之后,我们进行用例的调用,这里我们有四种方法:
1.unittest.main() #第一种执行方法,执行所有的用例
2.创建一个套件TestSuite(),通过addtest添加用例到套件中,通过TextTestRunner去运行套件中的用例
3.根据运行文件的相对路径执行自动化测试,通过unittest.TestLoader().discover匹配测试路径和文件, unittest.TextTestRunner().run(d) 运行路径d下的用例
4.根据运行文件的相对路径执行自动化测试,通过unittest.TestLoader().discover匹配测试路径和文件,接下来把执行结果写入我们导入的模板文件,执行之后就能看到我们路径下所有用例的执行结果。
4)实践操作
1.调用所有用例【cs004.py】
from selenium import webdriver from time import * from selenium.webdriver.common.action_chains import ActionChains #动作链 import unittest class cms(unittest.TestCase): @classmethod def setUp(self) -> None: pass @classmethod def tearDownClass(cls) -> None: pass def setUp(self) -> None: #登录 self.dx = webdriver.Chrome() url = "http://192.168.137.243:8080/cms/manage/login.do" self.dx.get(url) self.dx.find_element_by_id("userAccount").send_keys("admin") # sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") # sleep(2) self.dx.find_element_by_id("loginBtn").click() def tearDown(self) -> None: sleep(3) self.dx.quit() def test_tjlm(self): # 点击系统管理 self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click() sleep(3) # 点击栏目设置 lmsz = self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[1]/a').click() sleep(3) # 进 栏目设置 的iframe框,点击 添加栏目 self.dx.switch_to.frame('/cms/manage/article-class.html') self.dx.find_element_by_css_selector('body > div > div.cl.pd-5.bg-1.bk-gray.mt-20 > span.l > a').click() sleep(2) # 进 添加栏目 的iframe框 tjlm = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # # sleep(3) self.dx.switch_to.frame(tjlm) # # sleep(2) # 在 添加栏目 框里输入 栏目名称、栏目目录,点击保存 self.dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("789") self.dx.find_element_by_xpath('//*[@id="categoryCode"]').send_keys("789") self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() self.dx.switch_to.default_content() # 退出 栏目管理 的iframe框 # self.dx.quit() def test_tjzx(self): # 点击系统管理 self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click() sleep(3) # 点击 文章管理 self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[2]/a').click() # 进 文章管理 的iframe框,点击 全部分类 self.dx.switch_to.frame('/cms/manage/article-list.html') self.dx.find_element_by_css_selector('#categoryId').click() # # 点击 全部分类,展开下拉框,点击 123 # qbfl = self.dx.find_element_by_xpath('//*[@id="categoryId"]') # sleep(3) # ActionChains(self.dx).move_to_element(qbfl).perform() # sleep(2) # # dx.find_element_by_link_text("123").click() # self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click() # 点击 添加资讯 self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click() # 进 添加资讯 的iframe框,选择 文章栏目,输入 资讯标题、资讯描述、选择是否发布,输入 内容,点击 确定 tjzx = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # '/cms/manage/article-add.html' self.dx.switch_to.frame(tjzx) wzlm = self.dx.find_element_by_xpath('//*[@id="categoryId"]') sleep(2) ActionChains(self.dx).move_to_element(wzlm).perform() sleep(1) self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click() self.dx.find_element_by_name('articleTitle').send_keys("test2") self.dx.find_element_by_name('articleDesc').send_keys("test22") # 点击单选框:发布/下架 fb_btn = self.dx.find_element_by_css_selector( '#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(1)').click() # fb_btn=dx.find_element_by_css_selector('#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(2)').click() # 进编辑 内容 的iframe框,输入内容 nr = self.dx.find_element_by_id("ueditor_0") self.dx.switch_to.frame(nr) self.dx.find_element_by_css_selector('body > p:nth-child(1)').send_keys("12346567899") self.dx.switch_to.default_content() # 退出frame框 # print(1) # 进 文章管理 的iframe框 self.dx.switch_to.frame('/cms/manage/article-list.html') # 移动 添加资讯 的iframe框,鼠标按下、拖动到指定位置、释放鼠标 zx = self.dx.find_element_by_xpath('//*[@id="xubox_layer1"]/div/div') ActionChains(self.dx).click_and_hold(zx).perform() # 按下鼠标 sleep(2) # print(1) ActionChains(self.dx).drag_and_drop_by_offset(zx, 600, 1500) # 移动位置,移到(600,1500)的位置 # print(2.1) ActionChains(self.dx).perform() # 执行鼠标的移动位置操作 # print(2.2) # ActionChains(dx).release() #释放鼠标 # ActionChains(dx).perform() ActionChains(self.dx).move_to_element(zx).perform() # 鼠标移动到目标位置 # print(3) # sleep(2) ActionChains(self.dx).click().perform() # 点击一下【可能移了跟没移一样,鼠标点击一下空白处,位置就更新了】 # print(4) # 进 添加资讯 的iframe框 self.dx.switch_to.frame(tjzx) # 向下滑动右侧滚动条---找元素定位 j = 'window.scrollTo(0,2000)' self.dx.execute_script(j) # 输入作者、来源,点击确定 self.dx.find_element_by_xpath('//*[@id="articleAuthor"]').send_keys("asd99") sleep(2) self.dx.find_element_by_css_selector('#articleSource').send_keys("asd666") sleep(2) self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() # self.dx.quit() if __name__ == '__main__': unittest.main() #调用所有的用例2.运行单个用例 / 运行多个用例【cs004_1.py】
from selenium import webdriver from time import * from selenium.webdriver.common.action_chains import ActionChains #动作链 import unittest class cms(unittest.TestCase): @classmethod def setUp(self) -> None: pass @classmethod def tearDownClass(cls) -> None: pass def setUp(self) -> None: #登录 self.dx = webdriver.Chrome() url = "http://192.168.137.243:8080/cms/manage/login.do" self.dx.get(url) self.dx.find_element_by_id("userAccount").send_keys("admin") # sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") # sleep(2) self.dx.find_element_by_id("loginBtn").click() def tearDown(self) -> None: sleep(3) self.dx.quit() def test_tjlm(self): # 点击系统管理 self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click() sleep(3) # 点击栏目设置 lmsz = self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[1]/a').click() sleep(3) # 进 栏目设置 的iframe框,点击 添加栏目 self.dx.switch_to.frame('/cms/manage/article-class.html') self.dx.find_element_by_css_selector('body > div > div.cl.pd-5.bg-1.bk-gray.mt-20 > span.l > a').click() sleep(2) # 进 添加栏目 的iframe框 tjlm = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # # sleep(3) self.dx.switch_to.frame(tjlm) # # sleep(2) # 在 添加栏目 框里输入 栏目名称、栏目目录,点击保存 self.dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("789") self.dx.find_element_by_xpath('//*[@id="categoryCode"]').send_keys("789") self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() self.dx.switch_to.default_content() # 退出 栏目管理 的iframe框 # self.dx.quit() def test_tjzx(self): # 点击系统管理 self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click() sleep(3) # 点击 文章管理 self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[2]/a').click() # 进 文章管理 的iframe框,点击 全部分类 self.dx.switch_to.frame('/cms/manage/article-list.html') self.dx.find_element_by_css_selector('#categoryId').click() # # 点击 全部分类,展开下拉框,点击 123 # qbfl = self.dx.find_element_by_xpath('//*[@id="categoryId"]') # sleep(3) # ActionChains(self.dx).move_to_element(qbfl).perform() # sleep(2) # # dx.find_element_by_link_text("123").click() # self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click() # 点击 添加资讯 self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click() # 进 添加资讯 的iframe框,选择 文章栏目,输入 资讯标题、资讯描述、选择是否发布,输入 内容,点击 确定 tjzx = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # '/cms/manage/article-add.html' self.dx.switch_to.frame(tjzx) wzlm = self.dx.find_element_by_xpath('//*[@id="categoryId"]') sleep(2) ActionChains(self.dx).move_to_element(wzlm).perform() sleep(1) self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click() self.dx.find_element_by_name('articleTitle').send_keys("test2") self.dx.find_element_by_name('articleDesc').send_keys("test22") # 点击单选框:发布/下架 fb_btn = self.dx.find_element_by_css_selector( '#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(1)').click() # fb_btn=dx.find_element_by_css_selector('#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(2)').click() # 进编辑 内容 的iframe框,输入内容 nr = self.dx.find_element_by_id("ueditor_0") self.dx.switch_to.frame(nr) self.dx.find_element_by_css_selector('body > p:nth-child(1)').send_keys("12346567899") self.dx.switch_to.default_content() # 退出frame框 # print(1) # 进 文章管理 的iframe框 self.dx.switch_to.frame('/cms/manage/article-list.html') # 移动 添加资讯 的iframe框,鼠标按下、拖动到指定位置、释放鼠标 zx = self.dx.find_element_by_xpath('//*[@id="xubox_layer1"]/div/div') ActionChains(self.dx).click_and_hold(zx).perform() # 按下鼠标 sleep(2) # print(1) ActionChains(self.dx).drag_and_drop_by_offset(zx, 600, 1500) # 移动位置,移到(600,1500)的位置 # print(2.1) ActionChains(self.dx).perform() # 执行鼠标的移动位置操作 # print(2.2) # ActionChains(dx).release() #释放鼠标 # ActionChains(dx).perform() ActionChains(self.dx).move_to_element(zx).perform() # 鼠标移动到目标位置 # print(3) # sleep(2) ActionChains(self.dx).click().perform() # 点击一下【可能移了跟没移一样,鼠标点击一下空白处,位置就更新了】 # print(4) # 进 添加资讯 的iframe框 self.dx.switch_to.frame(tjzx) # 向下滑动右侧滚动条---找元素定位 j = 'window.scrollTo(0,2000)' self.dx.execute_script(j) # 输入作者、来源,点击确定 self.dx.find_element_by_xpath('//*[@id="articleAuthor"]').send_keys("asd99") sleep(2) self.dx.find_element_by_css_selector('#articleSource').send_keys("asd666") sleep(2) self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() # self.dx.quit() if __name__ == '__main__': tj=unittest.TestSuite() # --运行单个用例-- tj.addTest(cms("test_tjzx")) # 通过addtest 添加单个用例 # tj.addTest(Jk("testb")) #通过addtest 添加单个用例 # tj.addTest(Jk("test2")) #通过addtest 添加单个用例 # --运行多个用例-- tj.addTests([cms("test_tjlm"), cms("test_tjzx")]) unittest.TextTestRunner().run(tj) # #TextTestRunner运行套件tj3.运行一个路径下的用例【无html报告】【cs004_2.py】
from selenium import webdriver from time import * from selenium.webdriver.common.action_chains import ActionChains #动作链 import unittest from uizdx.HTMLTestRunner3_New import HTMLTestRunner class cms(unittest.TestCase): @classmethod def setUp(self) -> None: pass @classmethod def tearDownClass(cls) -> None: pass def setUp(self) -> None: #登录 self.dx = webdriver.Chrome() url = "http://192.168.137.243:8080/cms/manage/login.do" self.dx.get(url) self.dx.find_element_by_id("userAccount").send_keys("admin") # sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") # sleep(2) self.dx.find_element_by_id("loginBtn").click() def tearDown(self) -> None: sleep(3) self.dx.quit() def test_tjlm(self): # 点击系统管理 self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click() sleep(3) # 点击栏目设置 lmsz = self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[1]/a').click() sleep(3) # 进 栏目设置 的iframe框,点击 添加栏目 self.dx.switch_to.frame('/cms/manage/article-class.html') self.dx.find_element_by_css_selector('body > div > div.cl.pd-5.bg-1.bk-gray.mt-20 > span.l > a').click() sleep(2) # 进 添加栏目 的iframe框 tjlm = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # # sleep(3) self.dx.switch_to.frame(tjlm) # # sleep(2) # 在 添加栏目 框里输入 栏目名称、栏目目录,点击保存 self.dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("789") self.dx.find_element_by_xpath('//*[@id="categoryCode"]').send_keys("789") self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() self.dx.switch_to.default_content() # 退出 栏目管理 的iframe框 # self.dx.quit() def test_tjzx(self): # 点击系统管理 self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click() sleep(3) # 点击 文章管理 self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[2]/a').click() # 进 文章管理 的iframe框,点击 全部分类 self.dx.switch_to.frame('/cms/manage/article-list.html') self.dx.find_element_by_css_selector('#categoryId').click() # # 点击 全部分类,展开下拉框,点击 123 # qbfl = self.dx.find_element_by_xpath('//*[@id="categoryId"]') # sleep(3) # ActionChains(self.dx).move_to_element(qbfl).perform() # sleep(2) # # dx.find_element_by_link_text("123").click() # self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click() # 点击 添加资讯 self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click() # 进 添加资讯 的iframe框,选择 文章栏目,输入 资讯标题、资讯描述、选择是否发布,输入 内容,点击 确定 tjzx = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # '/cms/manage/article-add.html' self.dx.switch_to.frame(tjzx) wzlm = self.dx.find_element_by_xpath('//*[@id="categoryId"]') sleep(2) ActionChains(self.dx).move_to_element(wzlm).perform() sleep(1) self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click() self.dx.find_element_by_name('articleTitle').send_keys("test2") self.dx.find_element_by_name('articleDesc').send_keys("test22") # 点击单选框:发布/下架 fb_btn = self.dx.find_element_by_css_selector( '#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(1)').click() # fb_btn=dx.find_element_by_css_selector('#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(2)').click() # 进编辑 内容 的iframe框,输入内容 nr = self.dx.find_element_by_id("ueditor_0") self.dx.switch_to.frame(nr) self.dx.find_element_by_css_selector('body > p:nth-child(1)').send_keys("12346567899") self.dx.switch_to.default_content() # 退出frame框 # print(1) # 进 文章管理 的iframe框 self.dx.switch_to.frame('/cms/manage/article-list.html') # 移动 添加资讯 的iframe框,鼠标按下、拖动到指定位置、释放鼠标 zx = self.dx.find_element_by_xpath('//*[@id="xubox_layer1"]/div/div') ActionChains(self.dx).click_and_hold(zx).perform() # 按下鼠标 sleep(2) # print(1) ActionChains(self.dx).drag_and_drop_by_offset(zx, 600, 1500) # 移动位置,移到(600,1500)的位置 # print(2.1) ActionChains(self.dx).perform() # 执行鼠标的移动位置操作 # print(2.2) # ActionChains(dx).release() #释放鼠标 # ActionChains(dx).perform() ActionChains(self.dx).move_to_element(zx).perform() # 鼠标移动到目标位置 # print(3) # sleep(2) ActionChains(self.dx).click().perform() # 点击一下【可能移了跟没移一样,鼠标点击一下空白处,位置就更新了】 # print(4) # 进 添加资讯 的iframe框 self.dx.switch_to.frame(tjzx) # 向下滑动右侧滚动条---找元素定位 j = 'window.scrollTo(0,2000)' self.dx.execute_script(j) # 输入作者、来源,点击确定 self.dx.find_element_by_xpath('//*[@id="articleAuthor"]').send_keys("asd99") sleep(2) self.dx.find_element_by_css_selector('#articleSource').send_keys("asd666") sleep(2) self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() # self.dx.quit() if __name__ == '__main__': lj = r"E:\PycharmProjects\duoceshi2\cs1" # 相对路径 要运行的.py文件所在位置 d = unittest.TestLoader().discover(start_dir=lj, pattern="cs004_2*.py") unittest.TextTestRunner().run(lj) # #TextTestRunner运行套件tj4.结合路径查找用例,生成报告【有html报告】【cs004_3.py】
from selenium import webdriver from time import * from selenium.webdriver.common.action_chains import ActionChains #动作链 import unittest from uizdx.HTMLTestRunner3_New import HTMLTestRunner class cms(unittest.TestCase): @classmethod def setUp(self) -> None: pass @classmethod def tearDownClass(cls) -> None: pass def setUp(self) -> None: #登录 self.dx = webdriver.Chrome() url = "http://192.168.137.243:8080/cms/manage/login.do" self.dx.get(url) self.dx.find_element_by_id("userAccount").send_keys("admin") # sleep(2) self.dx.find_element_by_id("loginPwd").send_keys("123456") # sleep(2) self.dx.find_element_by_id("loginBtn").click() def tearDown(self) -> None: sleep(3) self.dx.quit() def test_tjlm(self): # 点击系统管理 self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click() sleep(3) # 点击栏目设置 lmsz = self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[1]/a').click() sleep(3) # 进 栏目设置 的iframe框,点击 添加栏目 self.dx.switch_to.frame('/cms/manage/article-class.html') self.dx.find_element_by_css_selector('body > div > div.cl.pd-5.bg-1.bk-gray.mt-20 > span.l > a').click() sleep(2) # 进 添加栏目 的iframe框 tjlm = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # # sleep(3) self.dx.switch_to.frame(tjlm) # # sleep(2) # 在 添加栏目 框里输入 栏目名称、栏目目录,点击保存 self.dx.find_element_by_xpath('//*[@id="categoryName"]').send_keys("854") self.dx.find_element_by_xpath('//*[@id="categoryCode"]').send_keys("asd") self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() self.dx.switch_to.default_content() # 退出 栏目管理 的iframe框 # self.dx.quit() def test_tjzx(self): # 点击系统管理 self.dx.find_element_by_xpath('//*[@id="menu-system"] /dt').click() sleep(3) # 点击 文章管理 self.dx.find_element_by_xpath('//*[@id="menu-system"]/dd/ul/li[2]/a').click() # 进 文章管理 的iframe框,点击 全部分类 self.dx.switch_to.frame('/cms/manage/article-list.html') self.dx.find_element_by_css_selector('#categoryId').click() # # 点击 全部分类,展开下拉框,点击 123 # qbfl = self.dx.find_element_by_xpath('//*[@id="categoryId"]') # sleep(3) # ActionChains(self.dx).move_to_element(qbfl).perform() # sleep(2) # # dx.find_element_by_link_text("123").click() # self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click() # 点击 添加资讯 self.dx.find_element_by_xpath('/html/body/div/div[2]/span[1]/a[2]').click() # 进 添加资讯 的iframe框,选择 文章栏目,输入 资讯标题、资讯描述、选择是否发布,输入 内容,点击 确定 tjzx = self.dx.find_element_by_xpath('//*[@id="xubox_iframe1"]') # '/cms/manage/article-add.html' self.dx.switch_to.frame(tjzx) wzlm = self.dx.find_element_by_xpath('//*[@id="categoryId"]') sleep(2) ActionChains(self.dx).move_to_element(wzlm).perform() sleep(1) self.dx.find_element_by_xpath('//*[@id="categoryId"]/option[2]').click() self.dx.find_element_by_name('articleTitle').send_keys("test2") self.dx.find_element_by_name('articleDesc').send_keys("test22") # 点击单选框:发布/下架 fb_btn = self.dx.find_element_by_css_selector( '#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(1)').click() # fb_btn=dx.find_element_by_css_selector('#sysArticleForm > table > tbody > tr:nth-child(4) > td > label:nth-child(2)').click() # 进编辑 内容 的iframe框,输入内容 nr = self.dx.find_element_by_id("ueditor_0") self.dx.switch_to.frame(nr) self.dx.find_element_by_css_selector('body > p:nth-child(1)').send_keys("12346567899") self.dx.switch_to.default_content() # 退出frame框 # print(1) # 进 文章管理 的iframe框 self.dx.switch_to.frame('/cms/manage/article-list.html') # 移动 添加资讯 的iframe框,鼠标按下、拖动到指定位置、释放鼠标 zx = self.dx.find_element_by_xpath('//*[@id="xubox_layer1"]/div/div') ActionChains(self.dx).click_and_hold(zx).perform() # 按下鼠标 sleep(2) # print(1) ActionChains(self.dx).drag_and_drop_by_offset(zx, 600, 1500) # 移动位置,移到(600,1500)的位置 # print(2.1) ActionChains(self.dx).perform() # 执行鼠标的移动位置操作 # print(2.2) # ActionChains(dx).release() #释放鼠标 # ActionChains(dx).perform() ActionChains(self.dx).move_to_element(zx).perform() # 鼠标移动到目标位置 # print(3) # sleep(2) ActionChains(self.dx).click().perform() # 点击一下【可能移了跟没移一样,鼠标点击一下空白处,位置就更新了】 # print(4) # 进 添加资讯 的iframe框 self.dx.switch_to.frame(tjzx) # 向下滑动右侧滚动条---找元素定位 j = 'window.scrollTo(0,2000)' self.dx.execute_script(j) # 输入作者、来源,点击确定 self.dx.find_element_by_xpath('//*[@id="articleAuthor"]').send_keys("asd99") sleep(2) self.dx.find_element_by_css_selector('#articleSource').send_keys("asd666") sleep(2) self.dx.find_element_by_xpath('//*[@id="submitBtn"]').click() # self.dx.quit() if __name__ == '__main__': lj = r"E:\PycharmProjects\duoceshi2\cs1" # 相对路径 要运行的.py文件所在位置 d = unittest.TestLoader().discover(start_dir=lj, pattern="cs004_3*.py") bglj = r"E:\PycharmProjects\duoceshi2\uizdx" # 相对路径 html报告的输出位置 new = strftime("%y-%m-%d %H-%M-%S") file = lj + "/" + str(new) + "_uizdh.html" f = open(file, "bw") b = HTMLTestRunner( stream=f, description="自动化执行情况", title="ui自动化测试报告", tester="masukotto" ) b.run(d)
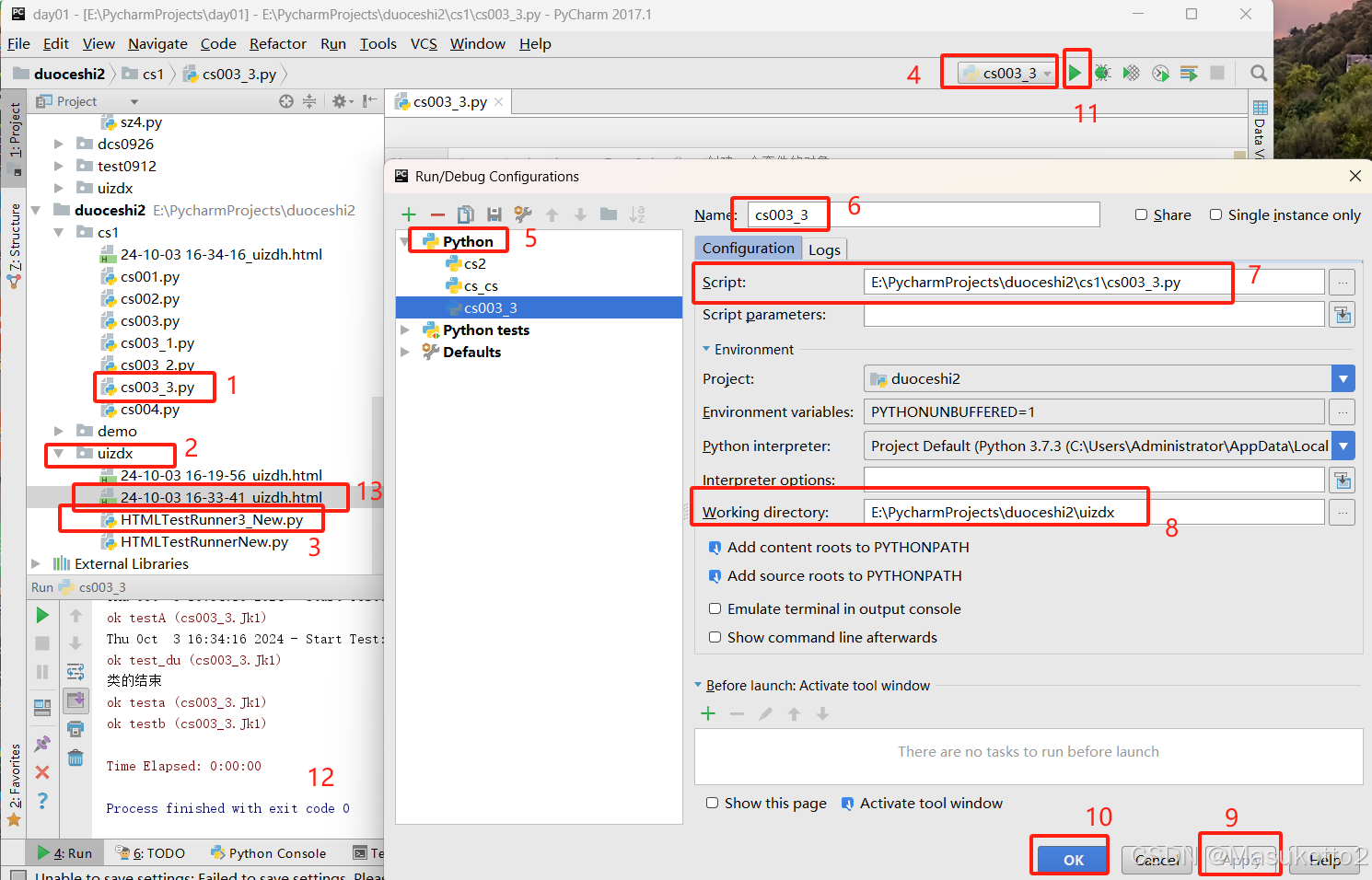
九、接口测试--基础协议和抓包工具
1.什么叫接口?
接口统称为api,程序与程序之间的对接、交接,接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点;主要是为了检验不同组件(模块入之间数据的传递是否正确,同时接口测试还要测试当前系统与第三方系统的对接,比如和:支付宝、财付通、微信、银联。
2.为什么做接口测试?
当界面功能没出来时,测试人员可以做接口测试,是节省时间,二是测试一些界面功能测不到的场景。
---------------------------------------------------------------------------------------------------------------------------------
(1)在测试过程中ui界面还没写好,测试人员提前进行接口测试(提前介入测试)
(2)节省时间
(3)测试一些功能测试测试不到的场景(比如:金额的负数)
3.如何做接口测试?
目前项目前后端主要是基于http协议的接口,所以测试接口时主要通过工具或代码模拟http请求发送与接收,来实现手工接口测试和自动化接口测试。
在公司中的实际情况:
前台开发和后台开发是独立进行的,一个项目是由前后台组成,最终我们要进行前后台联调,这个时候我们就要使用接口,那么在前后台联调前,我们需要对不同的接口进行测试。
通过代码或接口测试工具进行接口测试:
工具:postman,jmeter(都会讲)
代码:python+request (会讲)
--------------------------------------------------------------------------------------------------------------------------------
在公司中具体情况?
(1)前台开发和后台开发是独立进行的,一个项目是由前后台组成,最终我们要进行前后台联调,这个时候我们就要使用接口,前后台联调前,我们需要对不同的接口测试。
(2)第三方接口测试
什么是联调测试?(了解联调)
联调测试性质:集成测试,又称组装测试,联合测试,联调测试,等,侧重点在于模块间接口的正确性,各模块间的数据流和控制流是否按照设计实现其功能,以及集成后整体功能的正确性。
联调测试关注点:模块间的接口,至于模块怎么划分要根据具体项目来有针对性的划分。
理解为:数据的比对
在接口还没有测试,有一些无法实现的场景?
(比如a公司,b公司对接。开发的过程b还没有没有完成,a通过加测试来模拟)
桩(开发写桩)
mock 假测试
4.接口测试之网络基础
- 在IT领域,网络是信息传输、交换、接收、共享的虚拟平台,通过它把各个点、线、面的信息联系在一起,从而实现资源共享。
- 网络的四要素:有独立功能的计算机、有通讯设备和通讯线路、有网络软件支持、实现资源共享
- 网络的发展阶段:
第一代:远程终端连接(20世纪60年代初) 例如:xshelli连接Linux服务器
第二代:局域网(20世纪60年代中期)例如:校园网
第三代:广域网(internet-20世纪80年代)例如:跨城沛,跨洲
第四代:信息高速阶段(如:可视电话,网上电视点播,干兆以太网等) - 服务模式:
ISP (internet service provider)分:互联网业务提供商。(如:电信,移动,联通)
ICP (internet content provider):互联网内容提供商。(如:新浪,腾讯,抖音) - 网络的分类
1)按覆盖范围分:局域网>城域网->广域网
2)按拓扑结构分:总线型,环型,星型,网状型
3)按传输介质分:有线网,无线网,光纤网 - 网络协议 (TCP/IP) (network protocol)
1)什么是tcp/ip协议?
TCP/IP协议是一个协议集合。所以统称为TCPP。TCP/IP协议族中有一个重要的概念是分层,TCPP协议按照层次分为以下五层。应用层、传输层、网络层、数据链路层,物理层。
2)什么是OSI
OSI参考模型(OSl/RM)的全称是开放系统互连参考模型(Open System Interconnection Reference Model,OSl/RM),它是由国际标准化组织提出的一个网络系统互连模型。在这个OS七层模型中,每一层都为其上一层提供服务、并为其上一层提供一个访问接口或界面,不同主机之间的相同层次称为对等层。对等层之间互相通信需要遵守一定的规则,如通信的内容、通信的方式我们将其称为协议(Protocol)
3)OSI与TCP/IP对应关系: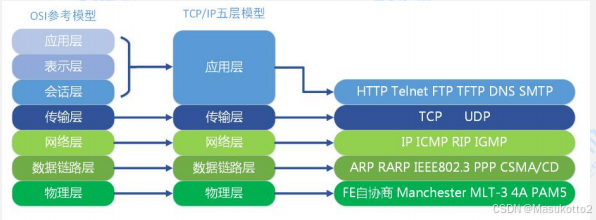
5.常见的协议及接口
1、HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议,HTTP协议的端口号为:80
2、HTTP协议的工作原理:
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Wb服务器根据接收到的请求后,向客户端发送响应信息。
3、HTTPS(全称:Hypertext Transfer Protocol Secure,超文本传输安全协议)WEB服务存在http和https两种通信方式,http对于传输采用不加密的方式,https默认采用443端口,在HTTPS数据传输的过程中,需要用SSL/TLS对数据进行加密和解密。
4、TCP传输控制协议(Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通信协议,电脑是通过增删改查这四种方式与服务器进行交互的。其中中间有一个TCP传输层,让电脑和服务器建立连接的,它是采用三次握手确认建立一个连接。四次挥手,终止TCP连接。
5.其他的协议和端口
telnet:远程登入协议 23
FTP:文件传输协议 21
SMTP:邮件传输协议 25
DNS:域名解析协议 53
POP3:邮件服务器 110
UDP:用户数据报协议
OSI:网络协议
iOS:苹果操作系统
ISO:镜像文件格式
6.常见的接口测试工具
fiddler (抓包软件,也可以用来测试接口)
postman(以前属于谷歌浏览器的插件,最常用的一款接口测试工具)
jmeter (市面上最流行的接口和性能测试工具)
Charles (Mac系统苹果电脑用这个抓包工具用的比较多)
soapui (soapUli可以测自动化和性能,也比较常用)
wireshark (抓包软件,也可以用来抓取tcp和udp,tls协议的数据)
7.接口类型
1、http接口:基于http协议的开发接口分为:http和https的接口,请求报文都是key-value形式的,返回报文一般都是json串和文本格式等等。
2、RPC接口:Remote Procedure Calls远程过程调用(RPC)是一种协议
3、RMl:RMl(Remote Method Invocation,远程方法调用)RMI是针对于java语言的,RMl允许您使用Java编写分布式对象
4、Webservice接口:Webservice是系统对外的接口
5、RESTfull风格的接口
8.接口的测试流程
接口测试需求分析
接口测试需求评审
编写接口测试计划
编写接口测试用例/接口测试用例评审
用例导入接口测试工具(执行用例)
发现BUG提交到禅道
编写小结测试报告
编写总结测试报告
9.Fiddler抓包
抓包原理:
Fiddler是位于客户端和服务器端之间的HTTP代理,它可以设置断点、修改请求的数据和服务器返回的数据,Fiddler启动后会自动将代理服务器设置成本机,默认端口为8888。
常用快捷键:
ctrl+X :清空所有记录 或 remove all
Ctrl+F:查找
F12:启动或者停止抓包 (fn+f12) 或者点击左下角的capturingdelete 删除已选中的session
shift+delete 删除未选中的session快捷键进行断点:
fn+f11 开启全局断点before request,拦截所有会话
alt+f11 开启全局断点 after request 显示:箭头显示向下
shifi+f11 取消全局断点
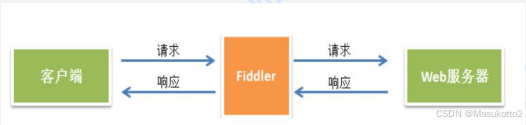
1、接口的请求方法(HTTP1.1)
GET (查) 请求指定的页面信息,并返回实体主体,请求参数一般放在ul地址栏的后面。
POST (增) 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。
HEAD 类似于gt请求,只不过返回的响应中没有具体的内容,用于获取报头
PUT (改) 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE (删) 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
2、请求方法:get
1)请求的数据一般会显示在地址栏
2)安全性差,请求的入参信息全部暴露在URL地址栏当中
3)请求的数据量比较小
3、请求方法:post
1)请求的数据一般不会显示在地址栏里面,会把数据封装在表单里面(入参放在requests body当中)再提交;
2)安全性比较高
3)请求的数据量比较大
4、HTTP请求头和请求体、响应头和响应体
1)请求头部信息:
post:表示请求的方法
HTTP/1.1:表示超文本传输协议版本为1.1版本URL统一资源定位符
Host:域名Host表示请求的服务器网址
Content-Length:用来说明传输的正文大小或者内容长度
Connection:Keep-Alive Connection表示客户端与服务连接类型
Keep-Alive:表示持久连接
Accept:text html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
浏览器支持的MlME消息内容类型分别是text html、application/xhtml+xml、application/,xml和*/*,优先顺序是它们从左到右的排列顺序
origin:标识跨域资源请求
X-Requested-With:标识Ajax请求,大部分js框架发送请求时都会设置它为XMLHttpRequest
User~Agent:用户代理的字符串值浏览器的身份标识字符串,user-agents会告诉网站服务器,访问者是通过什么工具来请求的
Content-jype:设置请求体的MlME类型
Content-Type:application/x-www-form-urlencoded
Referer:设置前一个页面的地址,并且前一个页面中的连接指向当前请求
Accept-Encoding:设置接受的编码格式Accept-Encoding:gzip,deflate
Accept-.Language:设置接受的语言
Accept-Language:en-US是英文 zh-cn为中文
Cookie:设置服务器使用Set-Cookie发送的http cookie Cookiel的作用就是用于解决记录客户端的用户信息当用户下一次访问该web页面时,可以在cookier中读取用户访问记录。
2)请求体部信息
userAcount=admin&userPwd=123456
3)响应头部信息
HTTP/1.1:表示超文本传输协议版本为1.1版本URL统一资源定位符
Server:服务器名称Server:Apache/2.4.1(Unix)
Set-Cookie:HTTP Cookie Set-Cookie:UserlD=JohnDoe;Max-Age=3600;
Version=1
Content-type:设置响应体的MlME类型Content-Type:text/html;charset=utf-8
Transfer-Encoding:设置传输实体的编码格式,目前支持的格式:chunked,compress,deflate,gzip,identity
Date:设置消息发送的日期和时间Date:Tue,15 Nov 1994 08:12:31 GMT
4)响应体部信息
{"code":"200","msg":"登录成功!","mode":}
5、HTTP状态码:
200 请求已成功,请求所希望的响应头或数据体将随此响应返回;
201 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其URI已经随Location头信息返回;
302 请求的资源现在临时从不同的UR1响应请求;
400 语义有误,当前请求无法被服务器理解;除非进行修改,否则客户端不应该
重复提交这个请求/请求参数有误;
403 服务器已经理解请求,但是拒绝执行它;
404 请求失败,请求所希望得到的资源未被在服务器上发现;
500 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理;
501 服务器不支持当前请求所需要的某个功能;
505 服务器不支持,或者拒绝支持在请求中使用的HTTP版本;
6、Fiddler实践操作
抓取到的接口内容:
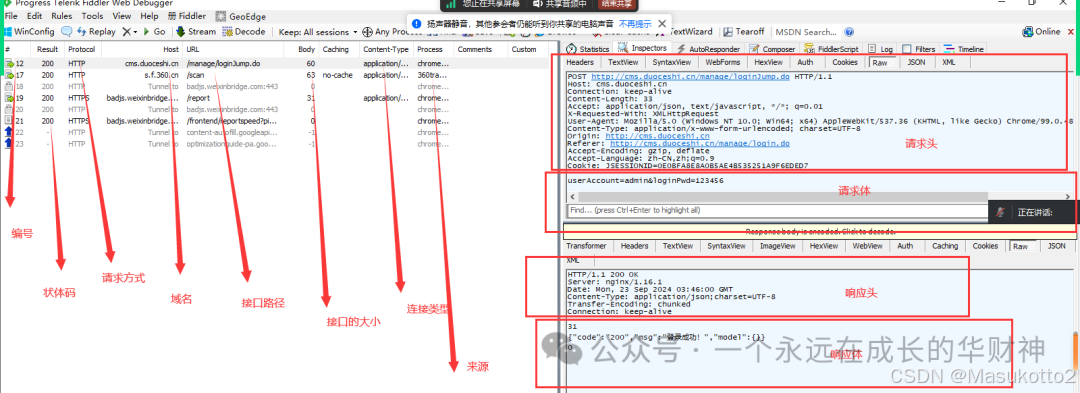
一般以.do 是java的命名
(1)[#]-HTTP Request的顺序,从1开始,按照页面加载请求的顺序排序。
(2)[Result] – HTTP 响应的状态。
(3)[Protocol]一一请求使用的协议(如HTTP/HTTPS/FTP)
(4)[Host] --请求地址的域名
(5)[URL] -一请求的服务器路径和文件名, 也包括GET参数
(6)[BODY]-- 请求的大小,以byte为单位
(7)[Caching] -一请求的缓存过期时间或缓存控制header等值
(8)[Content-Type] - -请求响应的类型(Content-Type)
(9)[Process] 一发出此请求的Windows 进程及进程ID
(10)[Comments] - -一用户通过脚本或者右键菜单给此session增加的备注)
(11)[Custom]-- 用户可以通过脚本设置的自定义值
分析一个接口的详情:
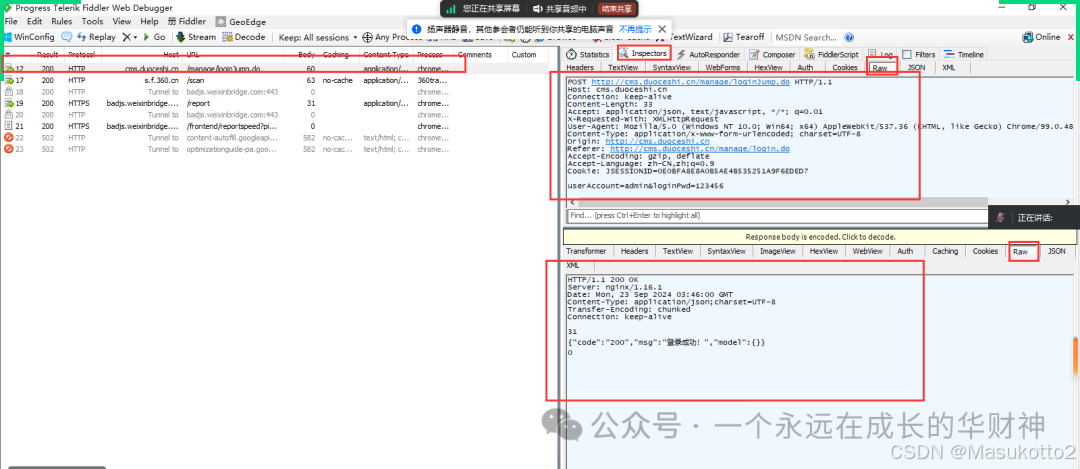
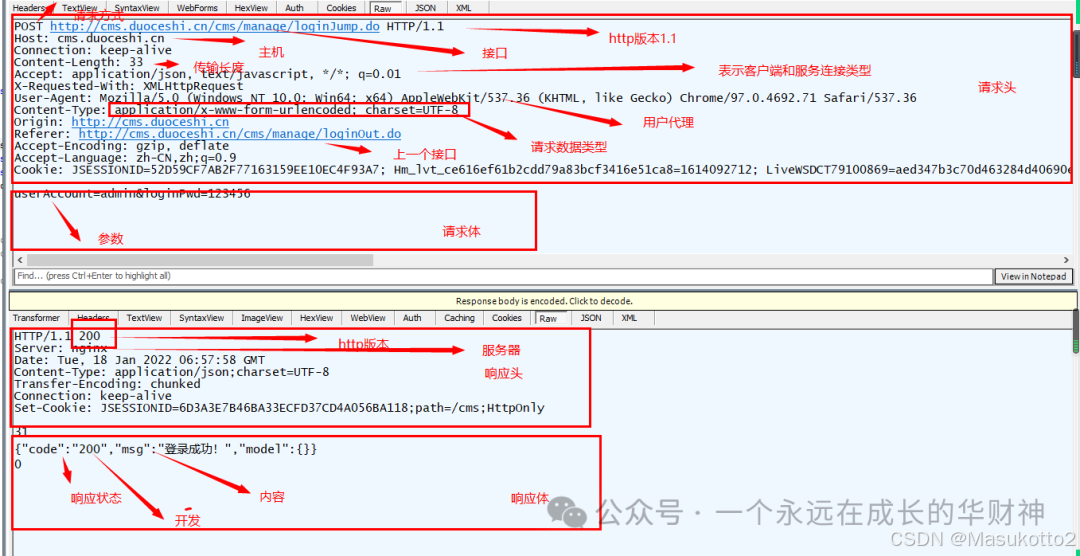
HTTP请求头和请求体、响应头和响应体
1)请求头部信息:
post :表示请求的方法
HTTP/1.1 :表示超文本传输协议 版本为1.1就是版本 URL统一资源定位符
Host:域名 Host表示请求的服务器网址 (ip地址)
Content-Length:用来说明传输的正文大小或者内容长度 #length长度
Connection:Keep-Alive Connection表示客户端与服务连接类型 #持续连接
Keep-Alive:表示持久连接
Accept:text html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8 (支持的数据类型)
浏览器支持的 MIME 消息内容类型分别是 text html、application/xhtml+xml、pplication/xml 和 /,优先顺序是它们从左到右的排列顺序
Content-Type: application/x-www-form-urlencoded; charset=UTF-8 请求的老数据类型
origin:表示跨域资源请求POST http://localhost:8080/cms/manage/loginJump.do HTTP/1.1 #接口请求的方式
Host: localhost:8080 #请求 的域名和地址
Connection: keep-alive #持续连接
Content-Length: 33 #连接长度
Accept: application/json, text/javascript, /; q=0.01 #接收的数据类型X-Requested-With: XMLHttpRequest #标识ajax请求UserAgent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36
#用户的代理人:浏览器/5.0
内容类型
Origin: http://localhost:8080 #起源
Sec-Fetch-Site: same-origin #场地
Sec-Fetch-Mode: cors #模式
Sec-Fetch-Dest: empty #教育
Referer: http://localhost:8080/cms/manage/loginOut.do
Accept-Encoding: gzip, deflate, br # 接收的编码格式
Accept-Language: zh-CN,zh;q=0.9 # 接收的语言Cookie: JSESSIONID=F6D7AE748A7C87ACC4867A362796358A #比较重要,就是客户端发服务端发送请求,就会发送一个会话,有个sessions id ,cookie保持会话持续,保持时间一个员,或者更久,只要不是手动删除,会以cookie的方法保持在服务端
Cookie:设置服务器使用Set-Cookie发送的http cookie Cookie的作用就是用于解决记录客户端的用户信息当用户下一次访问该web页面时,可以在cookie中读取用户访问记录。rigin:标识跨域资源请求
X-Requested-With:标识Ajax请求,大部分js框架发送请求时都会设置它为XMLHttpRequest
User-Agent:用户代理的字符串值浏览器的身份标识字符串,user-agent会告诉网站服务器,访问者是通过什么工具来请求的
Content-Type: 设置请求体的MIME类型 Content-Type: application/x-www-form-urlencoded
Referer :设置前一个页面的地址,并且前一个页面中的连接指向当前请求
Accept-Encoding :设置接受的编码格式 Accept-Encoding: gzip, deflate
Accept-Language :设置接受的语言
Accept-Language:en-US 是英文 zh-cn为中文
2)请求体部信息userAcount=admin&userPwd=123456 想做的入参,
3)响应头部信息
HTTP/1.1:表示超文本传输协议 版本为1.1版本 URL统一资源定位符
响应状态:200
Server:服务器名称 Server: Apache/2.4.1 (Unix)
Set-Cookie:设置HTTP Cookie Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1
Content-Type:设置响应体的MIME类型 Content-Type: text/html; charset=utf-8
Transfer-Encoding:设置传输实体的编码格式,目前支持的格式:chunked, compress, deflate, gzip, identity
Date:设置消息发送的日期和时间 Date: Tue, 15 Nov 1994 08:12:31 GMT #接口响应时间
---------------------------------------------------------------------------------------------------------------------------------
接口基础知识
1、网络的概念:网络信息传输,交换、接收、共享的虚拟平台,通过它把个点、线、面的信息联系在一起,从而实现资源共享。
2、网络的四要素:
(1)有独立的计算机
(2)通讯设备和通讯线路
(3)网络
(4)实现资源共享
3、网络的发展阶段
(1)远程终端连接 20世纪60年代初 xshell或linux
(2)局域网 20世纪60年代中 校园网
(3)广域网 20世纪80年代 跨城市
(4)信息高速阶段 视频,光纤
4、服务模式
isp (电信,移动,联通,广电)
icp (新浪、腾讯、抖音)
5、网络的分类
(1)按覆盖范围分
局域网=====城域网=====广域网
(2)按拓扑结构
总线型、环型、星型、网状型
(3)按传输介质分
有线网、无线网、光纤网
6、网络协议tcp/ip(重要)
(1)什么是tcp和ip协议
文件传输协议,规定的一种计算机语言
(2)tcp协议(重点)
5层协议(国内):物理层,数据链路层、网络层、传输层、应用层
7层协议(国际):物理层,数据链路层、网络层、传输层、(会话层、表示层、应用层)
7、tcp和udp区别:
8、https协议详解?
定义:超文本传输安全协议,web服务器存在http和https两种通讯方式,http对于传输采用不加密的方式,https是在数据传输的过程中,需要用ssl/tls对数据进行加密和解密
https=http+tls或ssl 端口号:443
9、https和http的区别
(1)端口号不一样: http端口号80, https是443
(2)https是加密传输,http是不加密传输
(3)http页面响应速度要比https快
(4)https比http更耗费服务资源
10、tcp 传输控制协议:
(1)三次握手 (tcp建立连接)
(2)四次挥手
建立连接3次、断开连接4次
总共:65535个端口 ,1-1023 端口 公认端口 ,1024-49151注册端口 ,49152-65535是动态端口或私有端口
11、常用的协议和端口
xshell:22
mysqld:3306
http:80
https:443
smtp:25
12、接口常用的工具?
(1)fiddler (抓包软件,也是一个调试工具)
(2)postman 接口工具
(3)jmeter 接口工具
(4)charles mac系统抓包工具
13、接口的类型有哪些?
(1)http接口 (我们讲)或https
(2)rpc接口
(3)rmi接口
(4)webservice 接口
(5)restful接口
14、接口测试的流程?
a:有接口文档
(1)接口文档(开发提供接口文档),参考接口文档,如果没有接口文档就是自己去抓包
(2)根据获取的接口,根据入参和响应参数,进行编写接口用例
(3)接口测试用例评审
(4)接口测试用例导入用例管理工具(禅道)
(5)搭建好测试环境
(6)使用接口工具或代码去调试接口
(7)有bug通过bug管理工具提bug给开,开发修改,测试验证
(8)测试完后,输出接口测试报告
b:没有接口文档
(1)通过抓包工具,抓取接口
(2)根据获取的接口,根据入参和响应参数,进行编写接口用例
(3)接口测试用例评审
(4)接口测试用例导入用例管理工具(禅道)
(5)搭建好测试环境
(6)使用接口工具或代码去调试接口
(7)有bug通过bug管理工具提bug给开,开发修改,测试验证
(8)测试完后,输出接口测试报告
15、抓包两种方式:(1)通过F12抓包(2)fiddler工具抓包
fn+f12 开发者工具
1、查看接口 (例如:cms登录接口)
url:http://cms.duoceshi.cn/cms/manage/index.do
2、按fn+12
3、找到接口后,在分析接口
请求体
响应体:
General部分:
Request URL:资源的请求url # (重点)
Request Method:HTTP方法 (方式)
Status Code:响应状态码
200(状态码) OK
301 - 资源(网页等)被永久转移到其它URL
404 - 请求的资源(网页等)不存在
500 - 内部服务器错误
Response Headers:(响应头信息)
Content-Encoding:gzip 压缩编码类型
Content-Type:text/html 服务端发送的类型及采用的编码方式 (入参格式)
Date:Tue, 14 Feb 2017 03:38:28 GMT 客户端请求服务端的时间
Last-Modified:Fri, 10 Feb 2017 09:46:23 GMT 服务端对该资源最后修改的时间
Server:nginx/1.2.4 服务端的Web服务端名
Transfer-Encoding:chunked 分块传递数据到客户端
Response Headers:
Accept:客户端能接收的资源类型
Accept-Encoding:gzip, deflate(客户端能接收的压缩数据的类型)
Accept-Language:en-US,en;q=0.8 客户端接收的语言类型
Cache-Control:no-cache 服务端禁止客户端缓存页面数据
Connection:keep-alive 维护客户端和服务端的连接关系
Cookie:客户端暂存服务端的信息
Host:www.jnshu.com 连接的目标主机和端口号Pragma:no-cache 服务端禁止客户端缓存页面数据url : ip+接口路径
url 有:uri 、url、urn
uri:统一资源标识符(主机名或去域名)
urn:统一资源名称
url:统一资源定位符(重点)
主要记录使用的协议,访问资源的具体路径
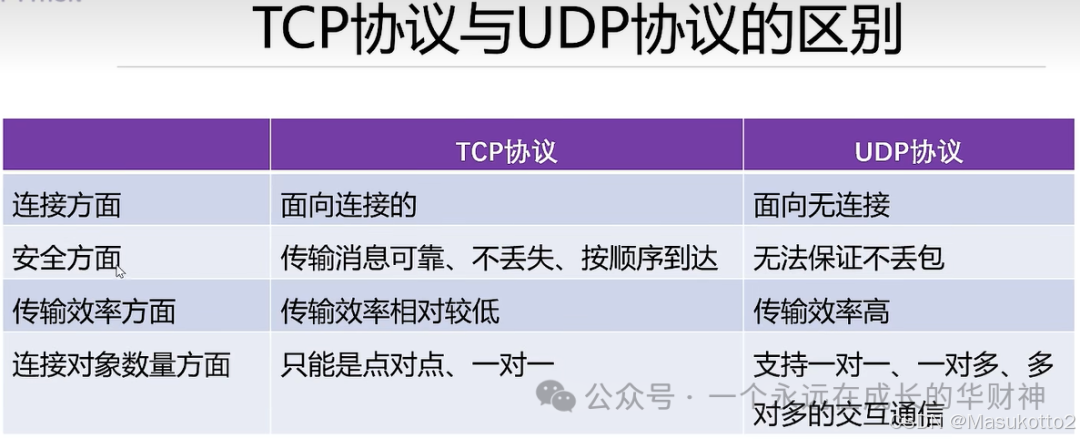
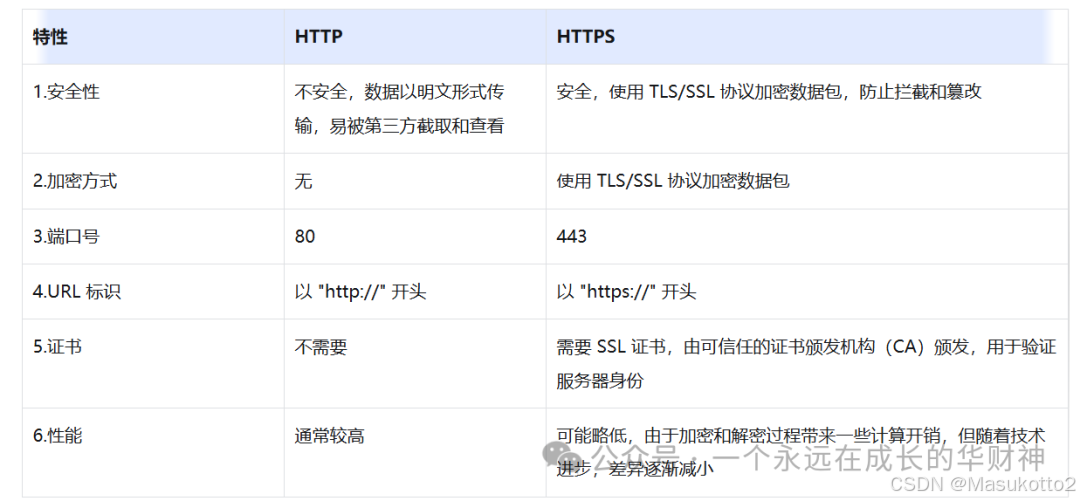
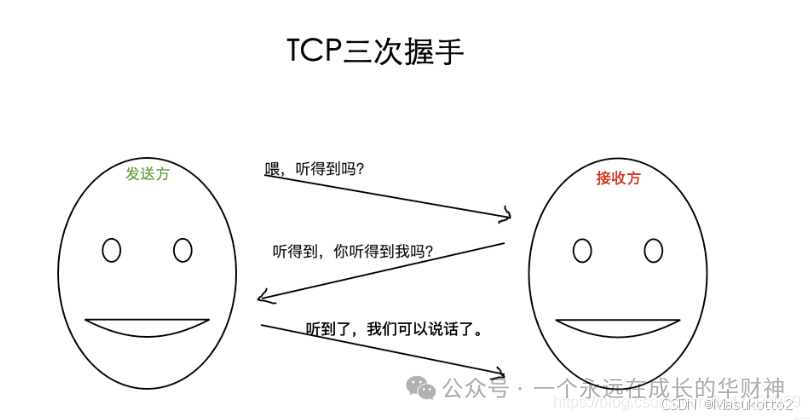
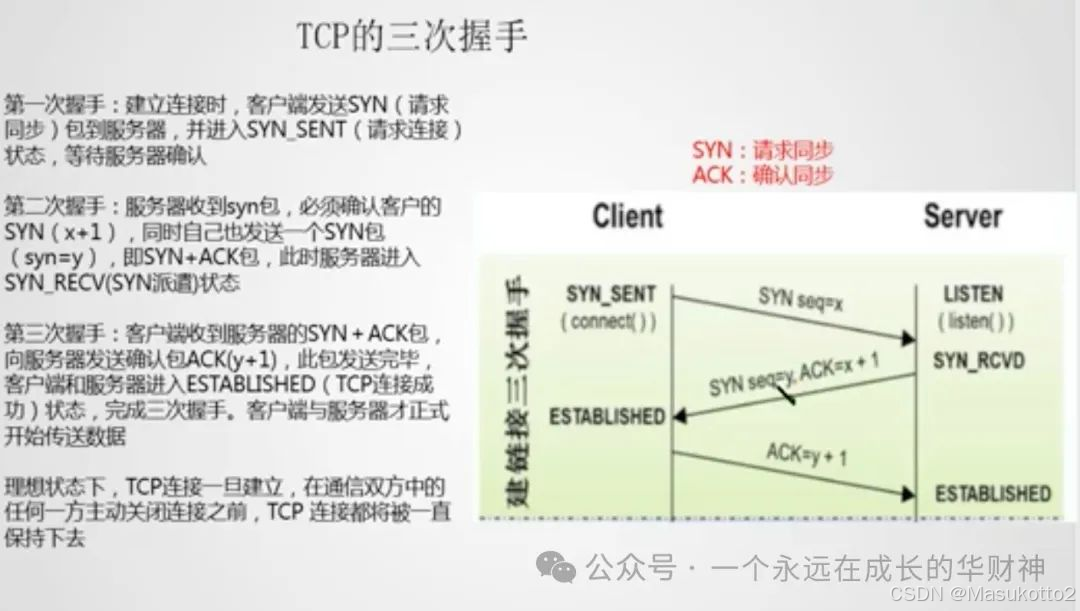
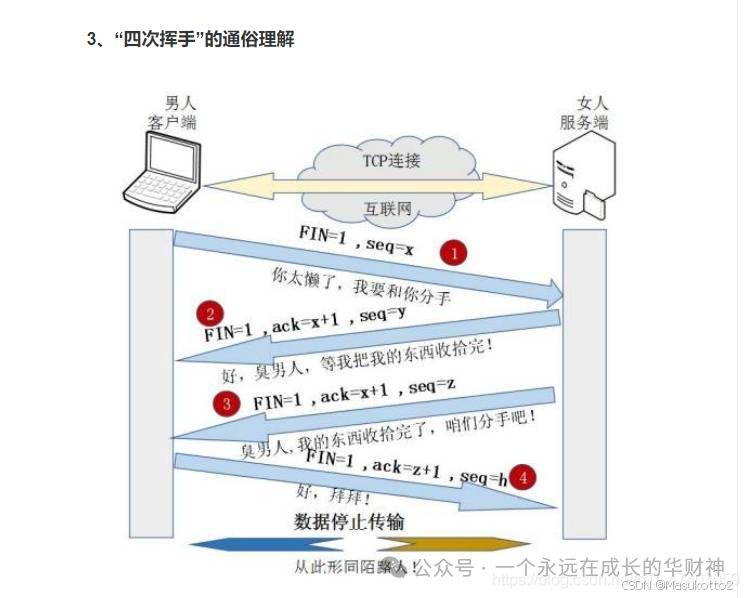
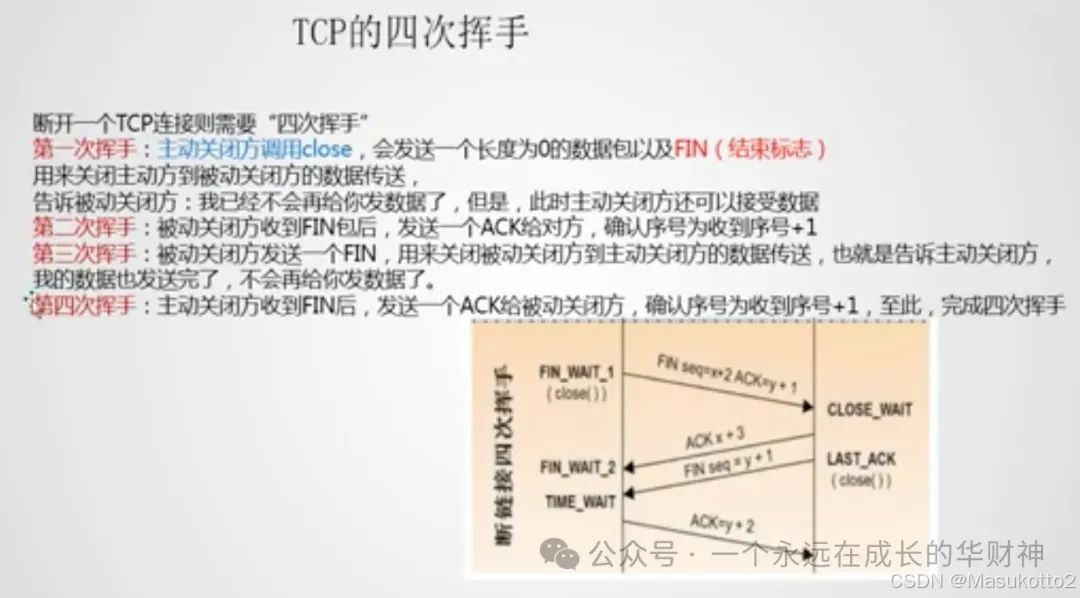

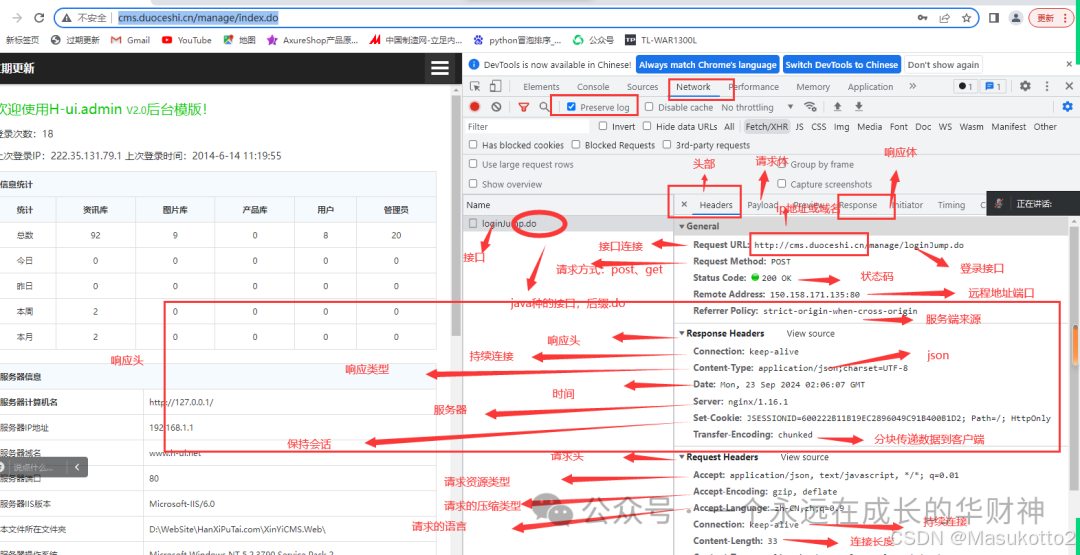
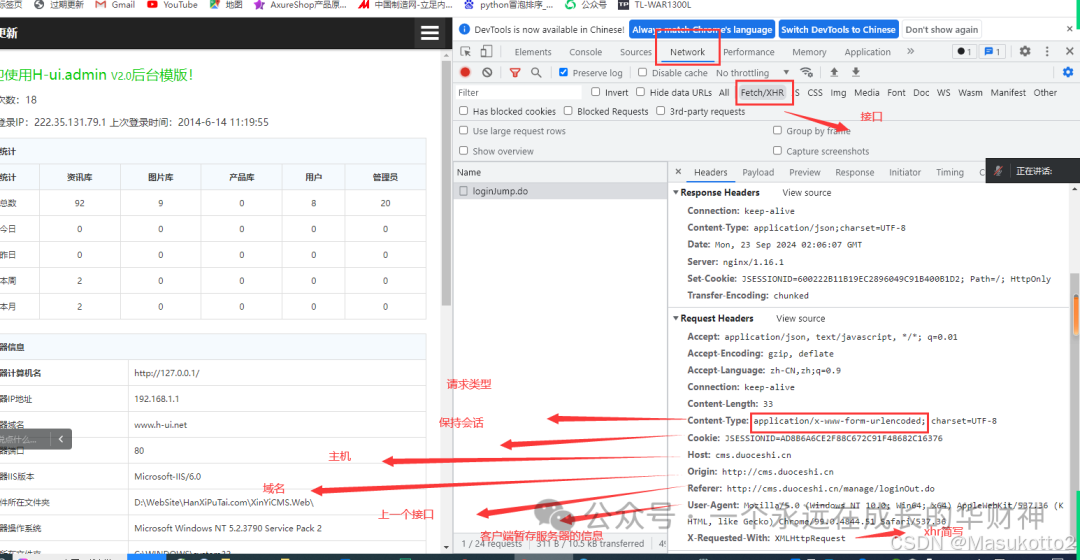
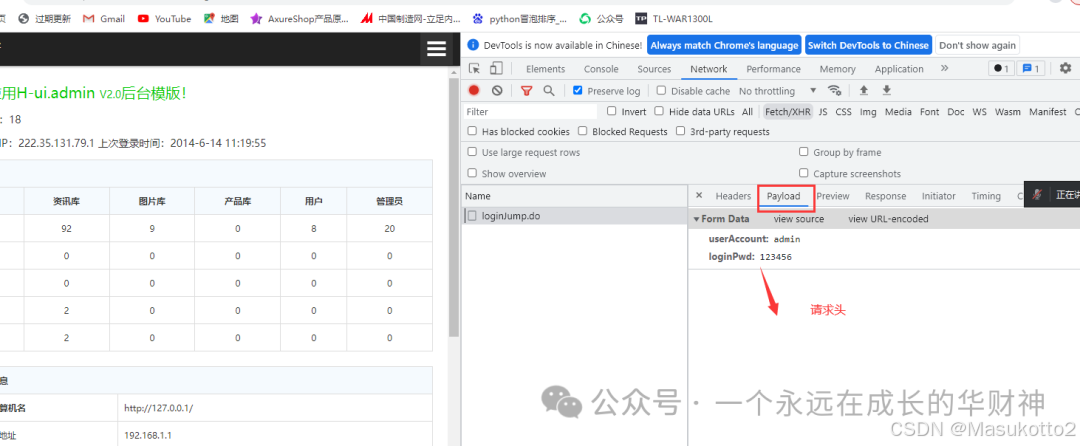
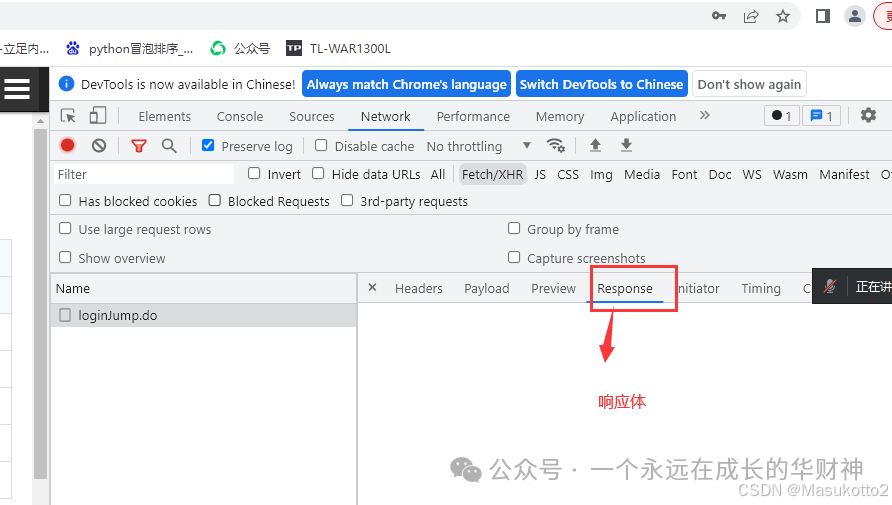
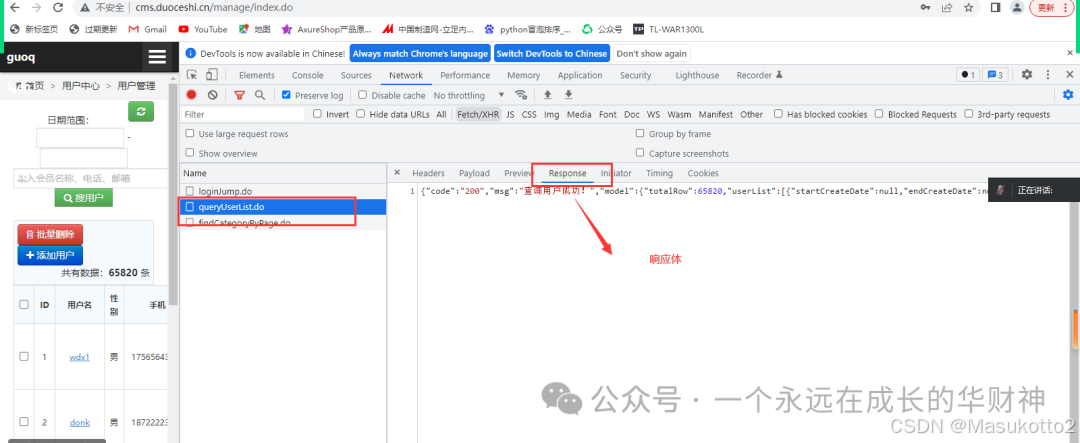
十、接口测试-- postman
- 下载安装postman
- 发送get请求
- 接口地址:http://192.168.23.148:8080/cms/manage/.loginJump.do
在get请求地址栏中后面加上?userAcount=admin&loginPwd=123456
完整接口地址:http://192.168.23.148:8080/cms/manage/.loginJump.do?userAcount=admin&loginPwd=123456- 发送post请求
1)post请求的请求参数放在body当中
2)在post请求的body中选择x-www-form-urlencoded- postman的body中的类型
1)form-data
就是http请求中的multipart/,form-data,它会将表单的数据处理为一条消息,以标签为单元,用分隔符分开。multipart/,form-data既可以上传文件,也可以上传键值对,它采用了键值对的方式,所以可以上传多个文件。
2)x-www-form-urlencoded
application/x-www-form-urlencoded,会将表单内的数据转换为键值对,如:
userAccount=admin&loginPwd=123456
3)raw
可上传任意格式的文本,可以上传text、json,xml、html、JavaScript等各种文本类型
4)binary
等同于Content-Type:application/.octet-stream,只可上传二进制数据,通常用来上传文件
由于没有键值,所以一次只能上传一个文件- Tests中增加断言
1)断言方式一:断言响应的结果中包含某个字符串
tests["Body matches string"]=responseBody.has("string_you_want_to_search")
2)断言方式二:断言响应状态码等于200
tests["Status code is 200"]=responseCode.code === 200
3)断言方式三:断言响应时间小于200ms
tests["Response time is less than 200ms"] = responseTime < 200
get和post请求的区别
(1)get的请求数据在地址栏上,post在请求数据在body中
(2)get请求的安全性要低于post请求
(3)get请求数据量比较小,post请求量相对于更大
响应状态码(重点:常用的状态码必须记下来)
常见的HTTP状态码:
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
200和304都可以认为请求成功,200还要readystatus为4,这两个符合就可以去加载了
404 - 请求的资源(网页等)不存在,请求故障
500 - 内部服务器错误,服务端故障
HTTP状态码分类
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
HTTP状态码分类
1 信息,服务器收到请求,需要请求者继续执行操作
2 成功,操作被成功接收并处理
3 重定向,需要进一步的操作以完成请求
4 客户端错误,请求包含语法错误或无法完成请求
5** 服务器错误,服务器在处理请求的过程中发生了错误
HTTP状态码列表:
100 Continue 继续。客户端应继续其请求
101 Switching Protocols 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议
200 OK 请求成功。一般用于GET与POST请求
201 Created 已创建。成功请求并创建了新的资源
202 Accepted 已接受。已经接受请求,但未处理完成
203 Non-Authoritative Information 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本
204 No Content 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档
205 Reset Content 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域
206 Partial Content 部分内容。服务器成功处理了部分GET请求
300 Multiple Choices 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择
301 Moved Permanently 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
302 Found 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI
303 See Other 查看其它地址。与301类似。使用GET和POST请求查看
304 Not Modified 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源
305 Use Proxy 使用代理。所请求的资源必须通过代理访问
306 Unused 已经被废弃的HTTP状态码
307 Temporary Redirect 临时重定向。与302类似。使用GET请求重定向
400 Bad Request 客户端请求的语法错误,服务器无法理解
401 Unauthorized 请求要求用户的身份认证
402 Payment Required 保留,将来使用
403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求
404 Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面
405 Method Not Allowed 客户端请求中的方法被禁止
406 Not Acceptable 服务器无法根据客户端请求的内容特性完成请求
407 Proxy Authentication Required 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权
408 Request Time-out 服务器等待客户端发送的请求时间过长,超时
409 Conflict 服务器完成客户端的PUT请求是可能返回此代码,服务器处理请求时发生了冲突
410 Gone 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置
411 Length Required 服务器无法处理客户端发送的不带Content-Length的请求信息
412 Precondition Failed 客户端请求信息的先决条件错误
413 Request Entity Too Large 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息
414 Request-URI Too Large 请求的URI过长(URI通常为网址),服务器无法处理
415 Unsupported Media Type 服务器无法处理请求附带的媒体格式
416 Requested range not satisfiable 客户端请求的范围无效
417 Expectation Failed 服务器无法满足Expect的请求头信息
500 Internal Server Error 服务器内部错误,无法完成请求
501 Not Implemented 服务器不支持请求的功能,无法完成请求
502 Bad Gateway 充当网关或代理的服务器,从远端服务器接收到了一个无效的请求
503 Service Unavailable 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中
504 Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求
505 HTTP Version not supported 服务器不支持请求的HTTP协议的版本,无法完成处理
同步接口和异步接口
1、同步接口:发起一个接口请求必须要等到响应结果才能发起下一个接口请求
2、异步接口:发起一个接口请求不需要等到响应结果就能发起下一个接口请求
一、cookie (cookie存储在客户端上)
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie是一个非常具体的东西,指的就是浏览器里面能永久存储的一种数据,cookie由服务器生成,发送给浏览器,浏览器把cookie以kv形式保存到某个目录下的文本文件内,下一次请求同一网站时会把该cookie发送给服务器。
3、cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
二、session (session存储在服务器上)
1、session翻译为会话
2、session服务器会保存一份,可能保存到缓存/数据库/文件里面。
3、session从字面上讲,就是会话。服务器要知道当前发请求给自己的是谁。为了做这种区分,服务器就要给每个客户端分配不同的“身份标识”,然后客户端每次向服务器发请求的时候,都带上这个“身份标识”,服务器就知道这个请求来自于谁了。至于客户端怎么保存这个“身份标识”,对于浏览器客户端,大都默认采用cookie 的方式。
服务器使用session把用户的信息临时保存在了服务器上,用户离开网站后session会被销毁。这种用户信息存储方式相对cookie来说更安全,可是session有一个缺陷:如果web服务器做了负载均衡,那么下一个操作请求到了另一台服务器的时候session会丢失。4、token:(令牌,服务器返回给到客户端的)
1、token的定义: token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个token便将此token返回给客户端,以后客户端只需带上这个token前来请求数据即可,无需再次带上用户名和密码。
2、使用token的目的: token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
3、token的原理:
- 第一步:你第一次登入成功之后,服务器就会产生一个token值,而这个值就会被服务器保存,同时将token值发送给客户端。
- 第二步:客户端拿到token值后要进行保存
- 第三步:当客户端再次发起网络请求时(该请求不是登录请求,是登录之后的请求),在该次请求中token值会发送给服务器。
- 第四步:服务器接受到客户端的请求后,会进行token值的对比。当token值一致时,说明已经登入成功,用户处于登入状态;当token值不一致时,说明原来登入的信息已经失效,让用户重新登入。
1、接口参数化
- get请求,接口入参需放入url地址栏中
http://192.168.23.148:8080/cms/manage/loginJump.do?userAccount={fusername))&loginPwd=((pwd))- 创建一个data.csv文件
- 在postman右上角点击Manage Environments添加一个测试环境
- 点击Add按钮添加一个测试环境
- 在前置请求脚本(Pre-request Script)中添加2个环境变量
- 点击用例所在集合右侧的>符号、点击run按钮、填写如下参数:
a.Iterations:迭代的次数
b.Delay:延迟多少毫秒启动
c.Data:选择刚刚创建的data.csv文件
d.Data File Type:入参文件支持的格式- 点击启动后产生结果如下:
a.PASSED:代表断言成功的数量
b.FAILED:代表断言失败的数量
c.Export Results:可以把生成的结果导出为报告
d.retry:表示重新执行一次用例
e.New:新建一个用例- 发送post请求(把参数写在body当中,其他操作和get一致)
2、关联接口
定义:上个接口返回的参数作为下一个接口的入参
接口1:查询出所有的州,自治区,直辖市,省(且发送请求不需要入参)
接口url地址:
http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSuppor
tProvince接口2:通过输入省份,查询出省对应的城市
参数:province='省份名称'
接口url地址:
http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportCity选择发送post请求、body选择x-www-form-urlencoded
在Tests中获取接口返回的省份信息设置为环境变量
a.将response Body响应体中的xml格式文件通过xml2Json方法转换为json对象
var jsonObject xml2Json(responseBody);
b.获取json对象中的数据
var js jsonObject.ArrayOfString.string[17];
c.将取到的省份名称设置为环境变量
postman.setEnvironmentVariable("province",js);根据省份获取城市接口,把byProvinceName参数对应的值设置为{province}来接受环境变量当中的实际的参数;
3、Fiddler打断点
1)为什么要打断点?
1、开发人员,调试,出错后的某个位置打断点调试代码
2、测试人员,测试,饶过前端的限制,测试后端的反应,
3、测试人员,构造数据,设置断点可篡改请求和返回的数据,根据不同的场景修改内容,达到测试的目的
2)断点分类
1、全局断点和单个接口断点
2、请求前断点和请求后断点
3、请求前断点:修改请求前的参数,请求头和请求体
4、请求后断点:修改响应的参数,响应头和响应体
5、单个接口请求前断点命令: 请求前命令:bpu+url 取消断点:bpu
6 、单个接口请求后断点命令: 请求前命令:bpafter+url 取消断点:bpafter
1)全局断点
- rules->automatic breakpoint ->before requests
- 打开cms平台首页:http:/192.168.23.130:8080/cms/manage/loginJump.do看到红色T的标识,说明断点成功
- 找到需要修改的请求后,选中该条会话,右侧打开WebFroms,可以进行参数的修改了。
- 修改之后点击Run to Completion
2)单个断点
- 请求前断点(before response):
在命令行输入:
bpu http://192.168.23.130:8080/cms/manage/loginJump.do
取消断点:在命令行输入bpu-按回车键 - 响应后断点(after requests)
在命令行输入:bpafter
http://192.168.23.130:8080/cms/manage/saveModuleCategory.do
取消断点:在命令行输入bpafter-按回车键
3)断点的实践操作
(1)请求前全局断点
a、开启请求前断点
在网页上输入cms网址,进行登录,抓取到登录的接口,如下
在对抓取的接口进行修改内容:请求体、请求头 ,在运行
(2)请求后的断点
a.设置请求后的断点
打开网址:输入网址,输入账号,密码,点击登录,在通过fiddler抓取接口
(3)请求前的单个断点
a、确定要断点的接口
bpu +接口
bpu http://cms.duoceshi.cn/manage/loginJump.do
在左下角输入bpu+接口 ,敲回车
敲回车显示
bpu 输入敲回车,取消请i去前断点
(4)请求后的单个断点:
bpafter+接口
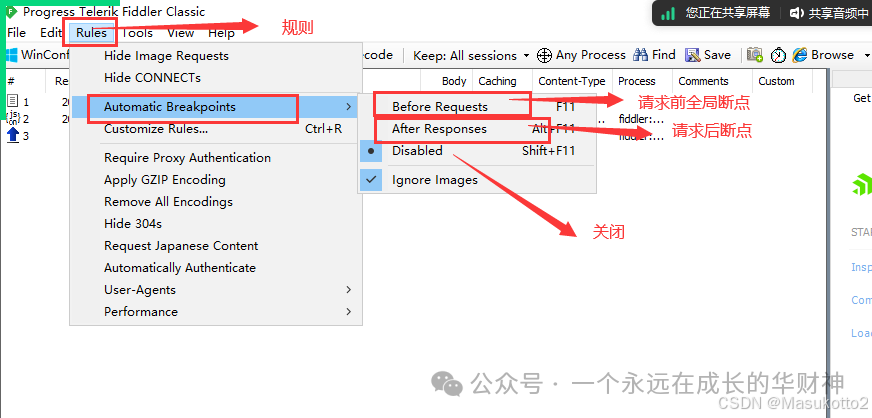
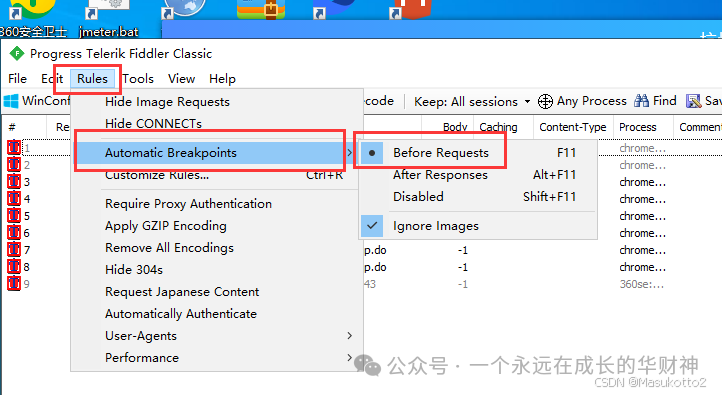
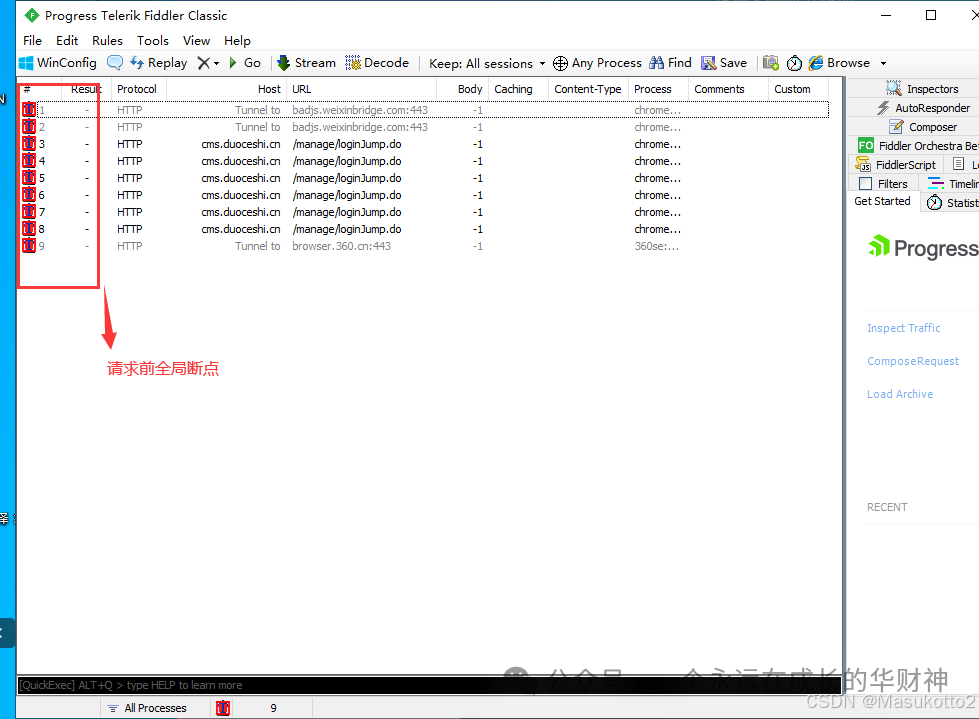
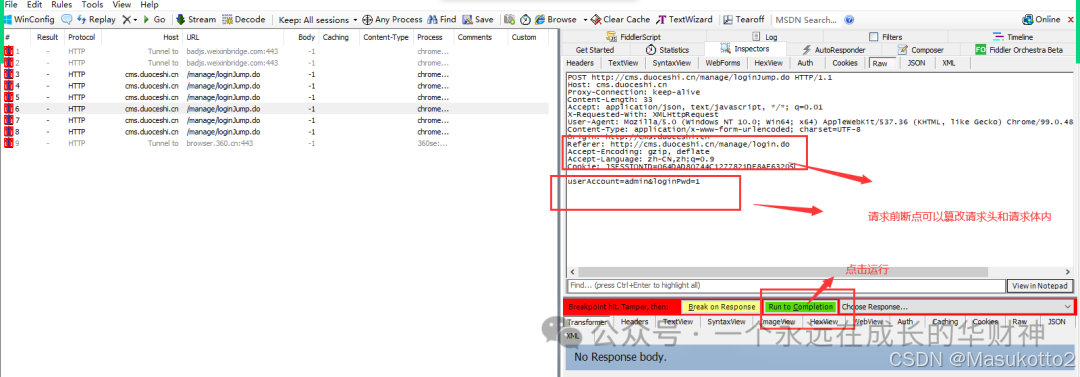
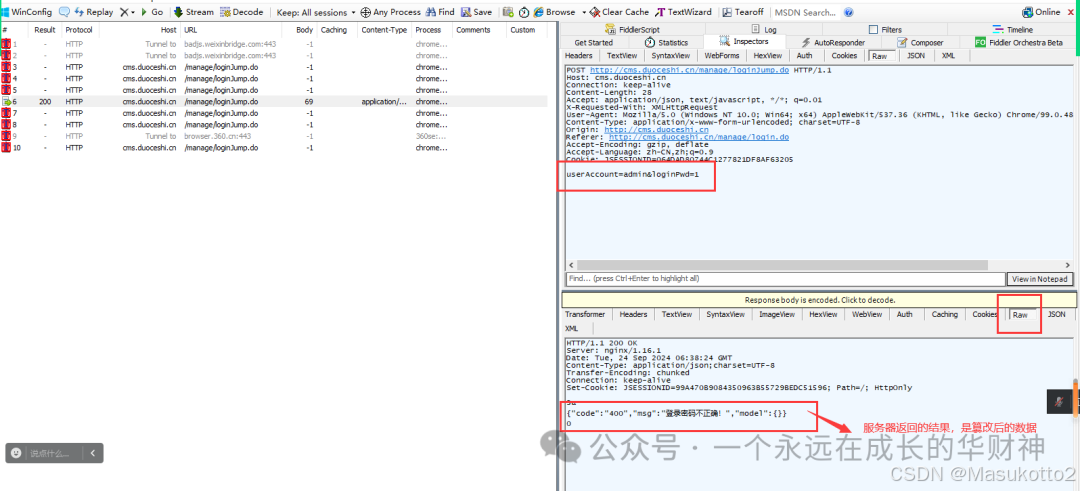

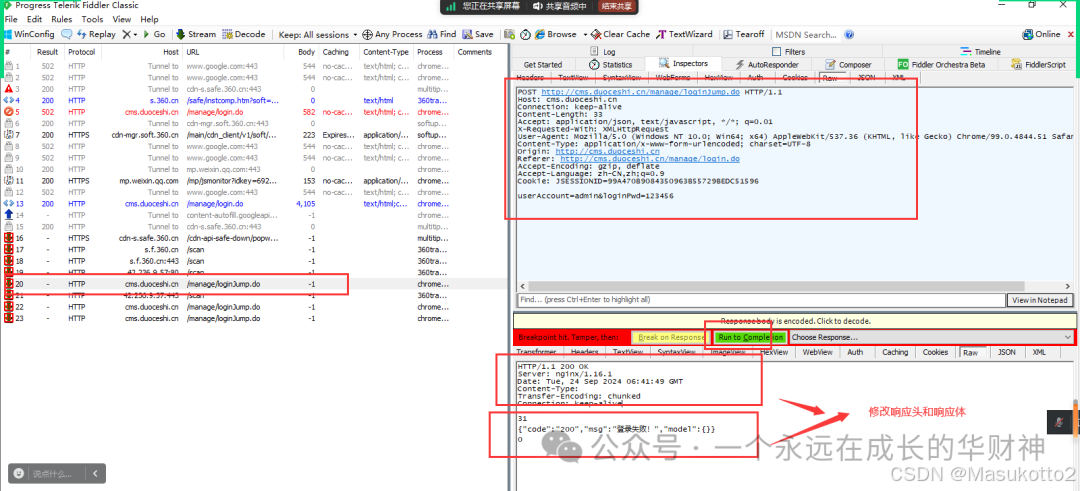
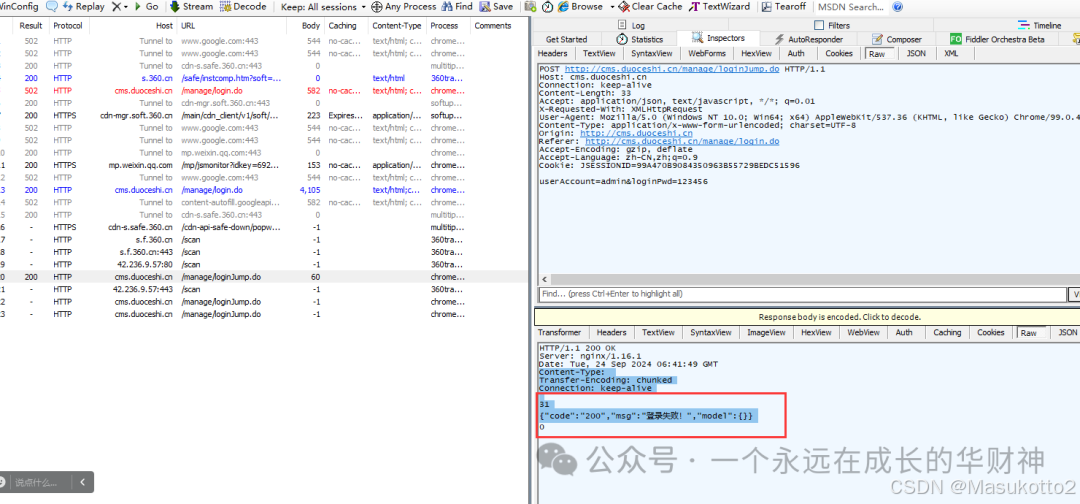

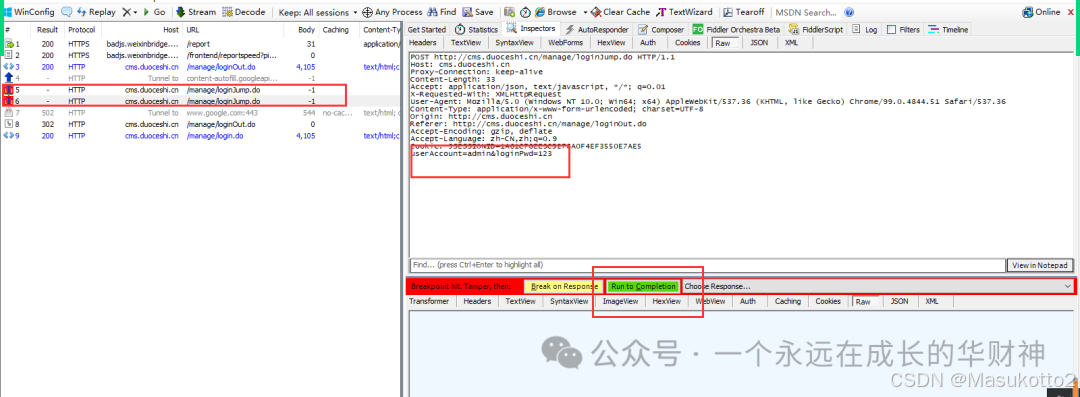
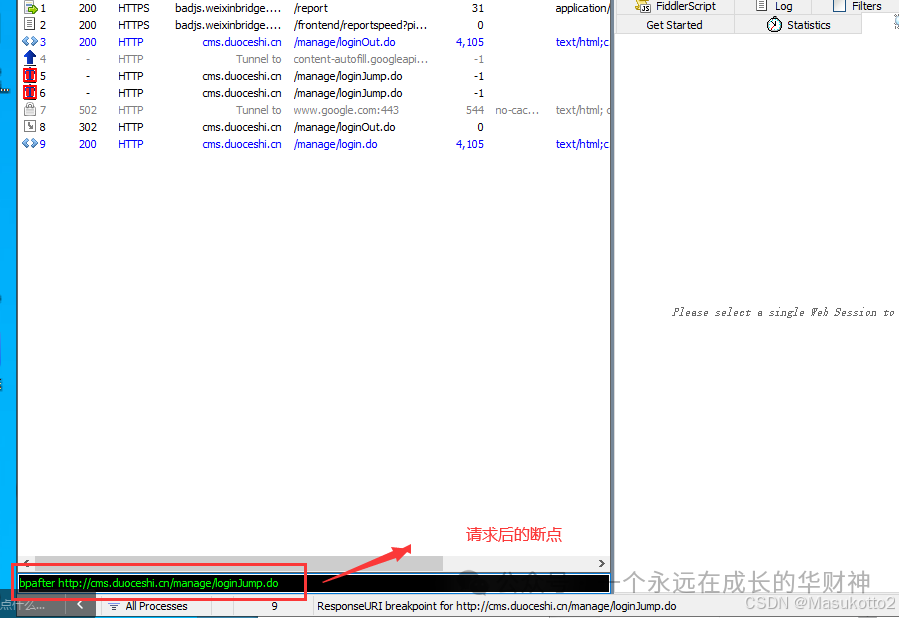
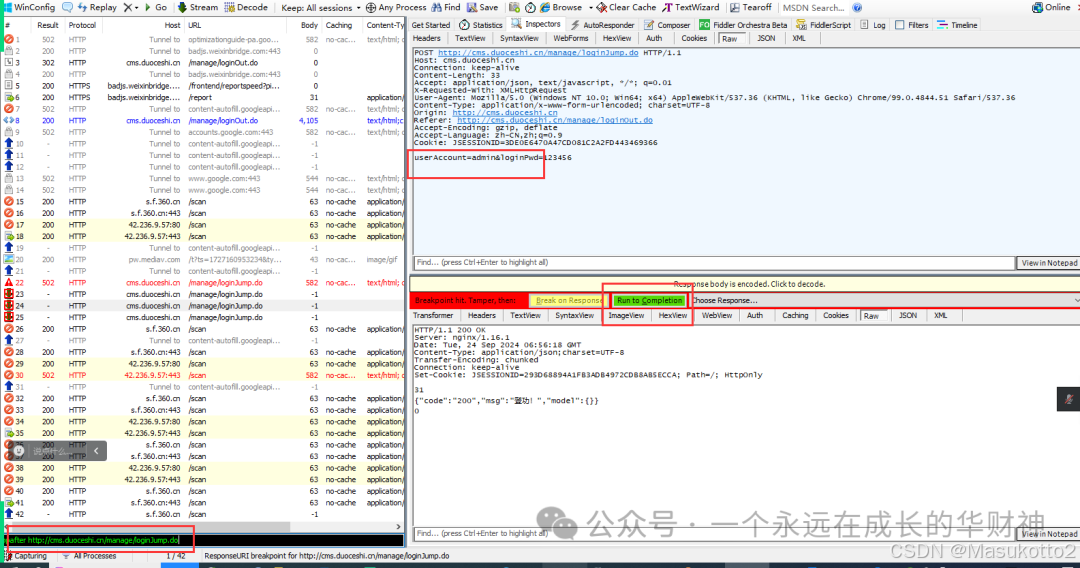
4、同步接口和异步接口
- 同步接口:发起一个接口请求必须要等到响应结果才能发起下一个接口请求
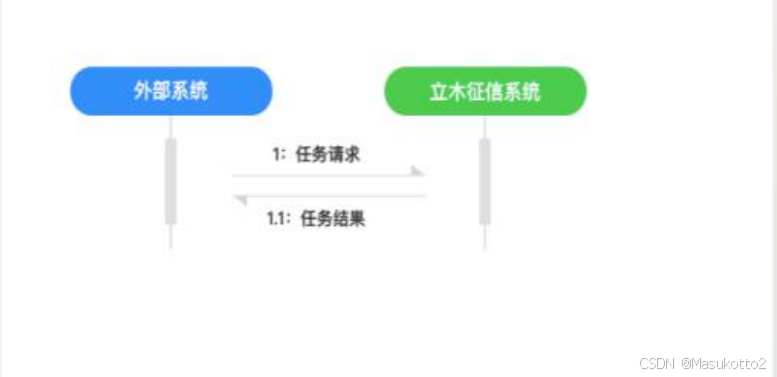
- 异步接口:发起一个接口请求不需要等到响应结果就能发起下一个接口请求
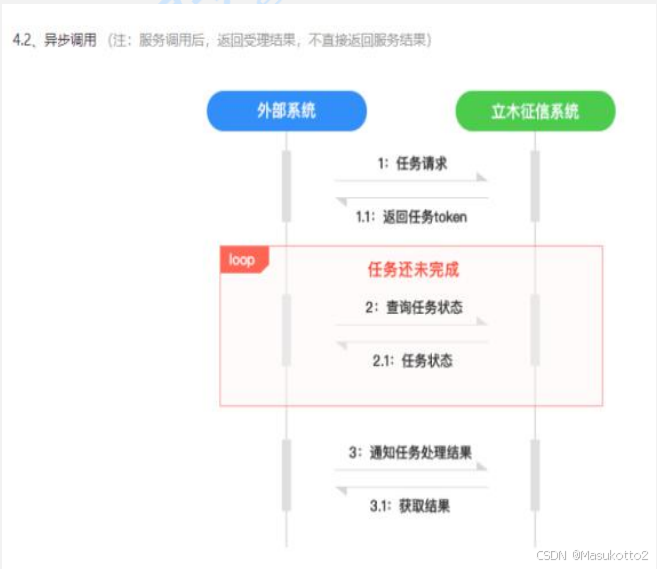
5、cookie、session和token的区别
cookie(cookie存储在客户端上)
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- cookie是一个非常具体的东西,指的就是浏览器里面能永久存储的一种数据cookie由服务器生成,发送给浏览器,浏览器把cookiel以kv形式保存到某个目录下的文本文件内,下一次请求同一网站时会把该cookie发送给服务器
- cookie不是很安全,别人可以分析存放在本地的cookie?并进行cookie欺骗,考虑到安全应当使用session。
session(session存储在服务器上)
- session翻译为会话
- session服务器会保存一份,可能保存到缓存/数据库/文件里面。
- session从字面上讲,就是会话。服务器要知道当前发请求给自己的是谁。为了做这种区分,服务器就要给每个客户端分配不同的“身份标识”,然后客户端每次向服务器发请求的时候,都带上这个“身份标识”,服务器就知道这个请求来自于谁了。至于客户端怎么保存这个“身份标识”,对于浏览器客户端,大都默认采用cookie的方式。
服务器使用session把用户的信息临时保存在了服务器上,用户离开网站后session会被销毁。这种用户信息存储方式相对cookie:来说更安全,可是session有一个缺陷:如果web服务器做了负载均衡,那么下一个操作请求到了另一台服务器的时候session会丢失。
token(令牌,服务器返回给到客户端的)
- token的定义:token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个token便将此tokeni返回给客户端,以后客户端只需带上这个token前来请求数据即可,无需再次带上用户名和密码。
- 使用token的目的:token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
- token的原理:
第一步:你第一次登入成功之后,服务器就会产生一个tokn值,而这个值就会被服务器保存,同时将token值发送给客户端。
第二步:客户端拿到Jtoken值后要进行保存
第三步:当客户端再次发起网络请求时(该请求不是登录请求,是登录之后的请求),在该次请求中token值会发送给服务器。
第四步:服务器接受到客户端的请求后,会进行token值的对比。当token值一致时,说明已经登入成功,用户处于登入状态;当token值不一致时,说明原来登入的信息已经失效,让用户重新登入。
6、postman实践操作
postman是一个接口测试工具
1.下载安装postman,并打开
2.创建一个集合
3.创建接口
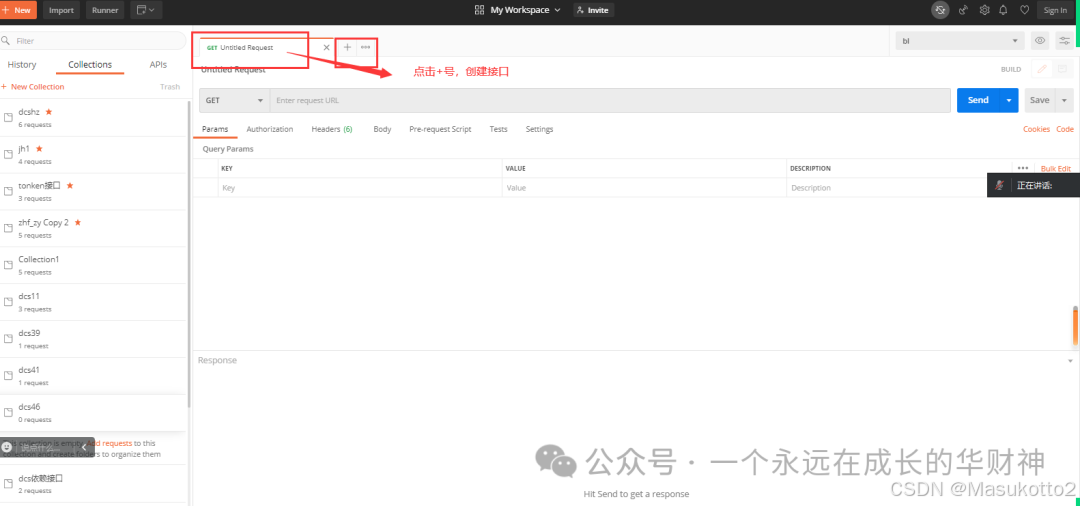
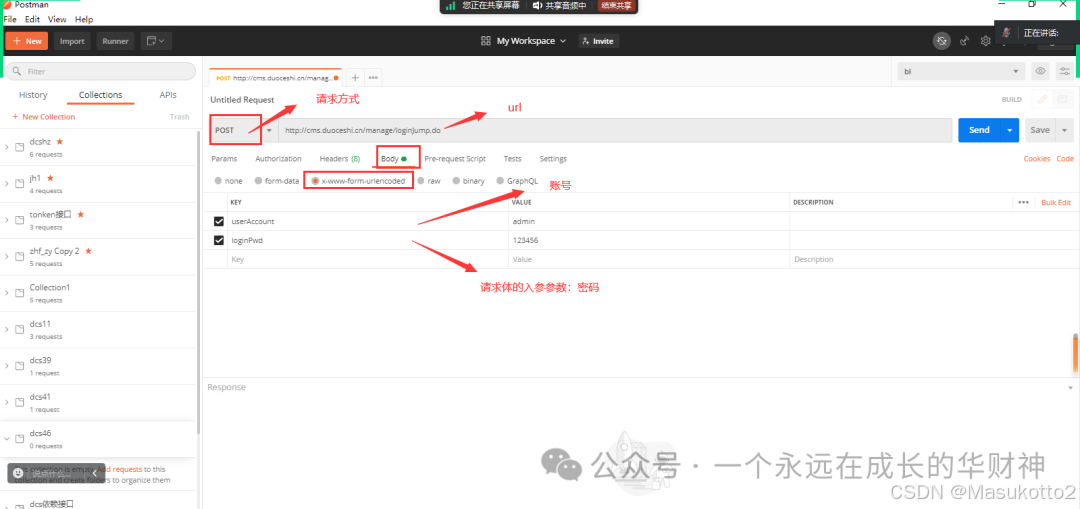
4.保存接口,存放到集合中
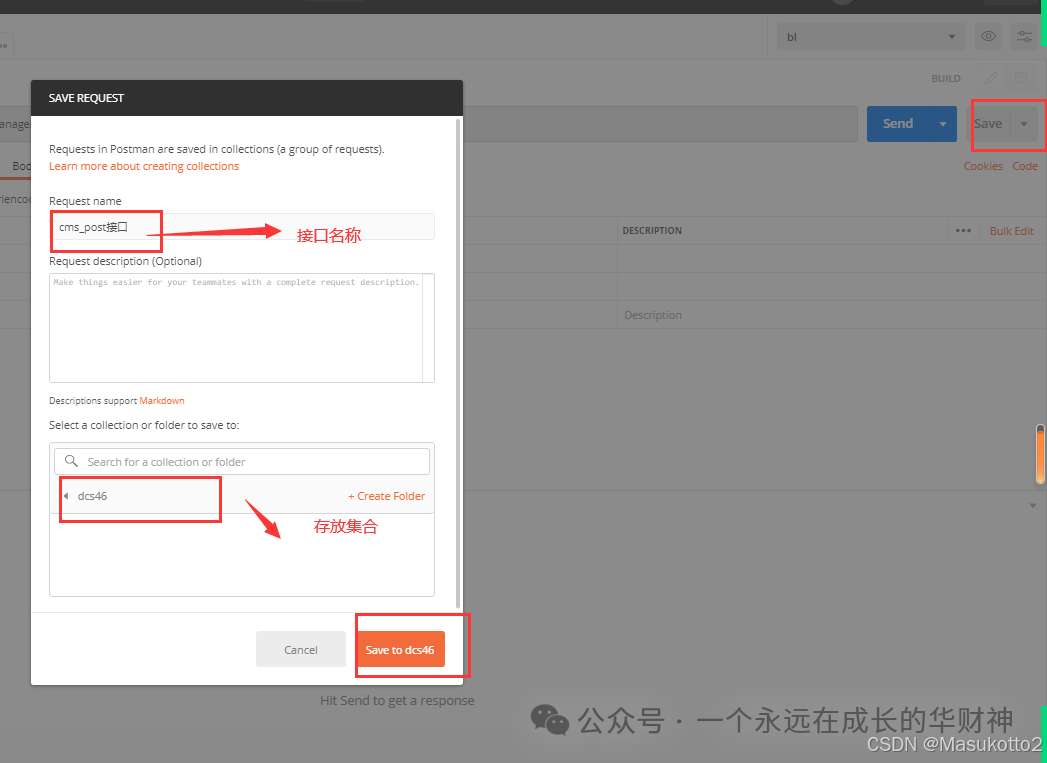
5.send 发送接口
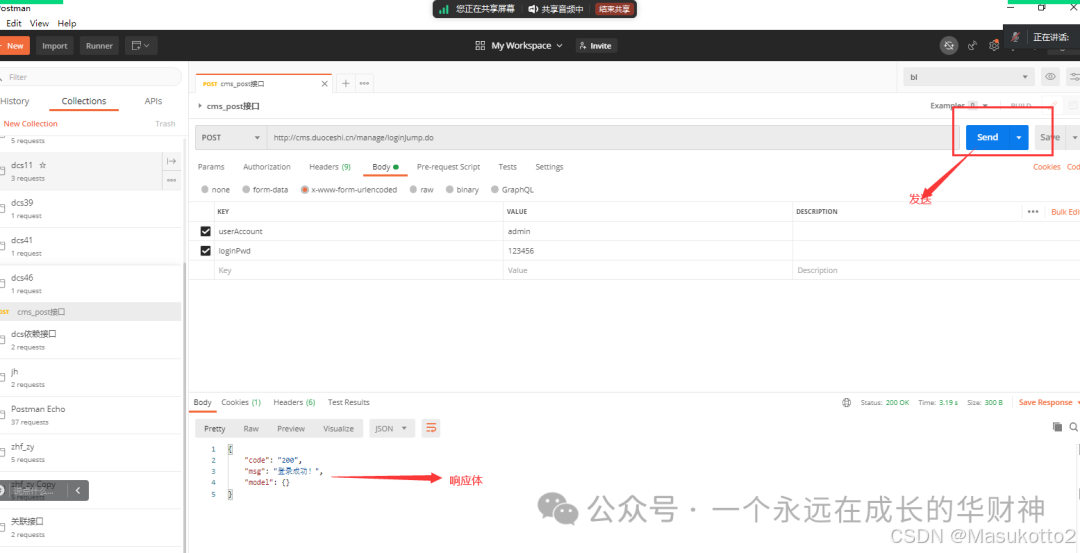
【至此接口创建完成】
6.postman界面详情介绍
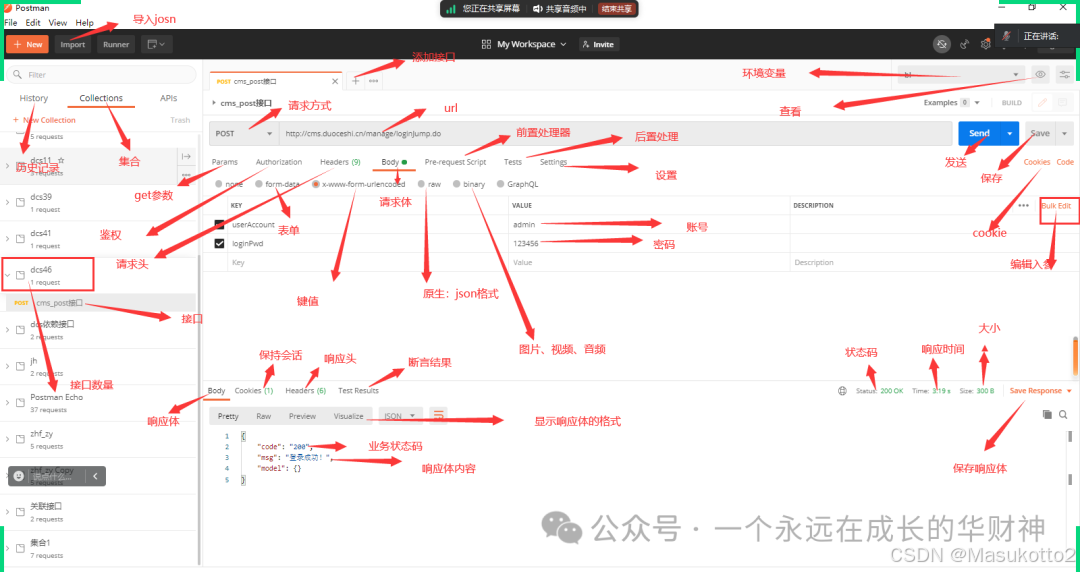
7.切换主题setting
8.添加环境变量
9.添加一个post接口和get接口
1)post接口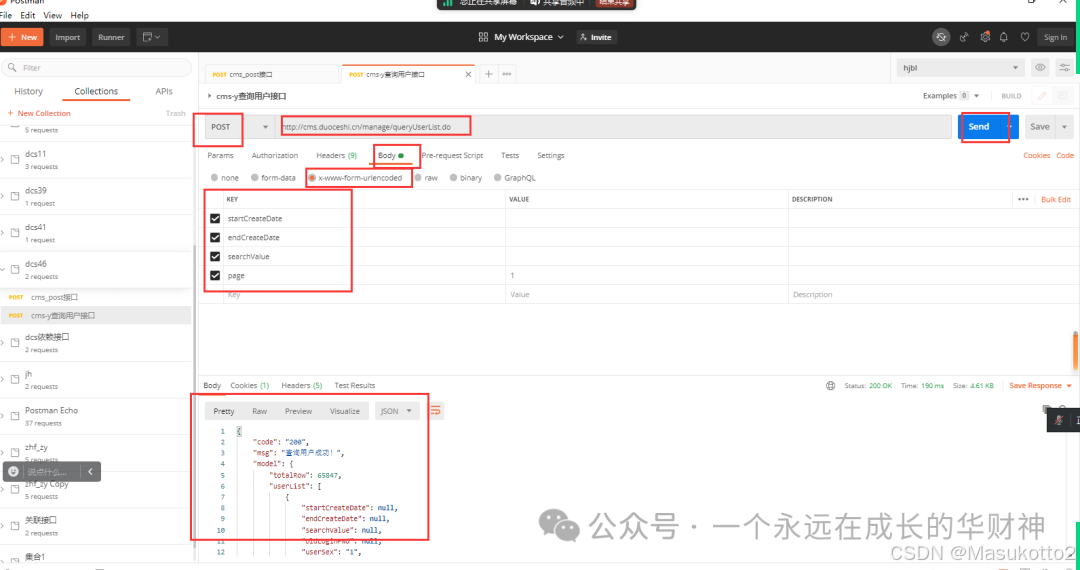
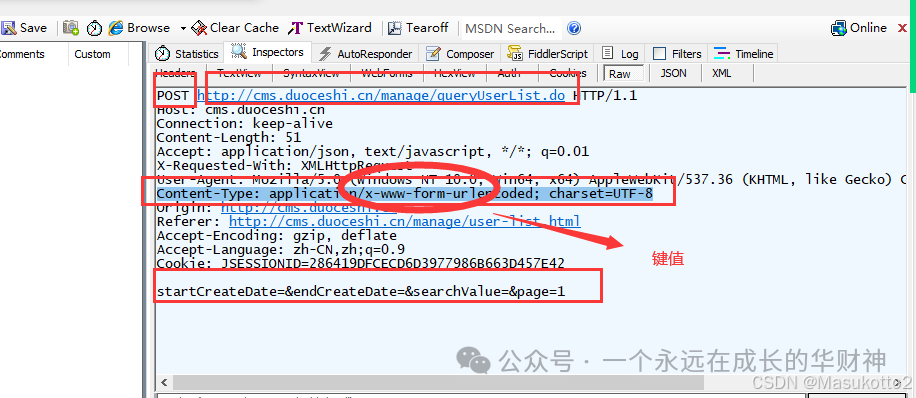
入参格式:
body
form-data是web表单默认的传输格式,编辑器允许你通过设置key-value形式的数据来模拟填充表单,你可以在最后的选项中选择添加文件。x-www-form-urlencoded:编码格式通过设置key-value的方式作为URL的参数
raw:一个raw请求可以包含任何内容,在这里你可以设置我们常用的JSON和XML数据格式
binary:上传发送视频、音频、图片、文本等
2)get接口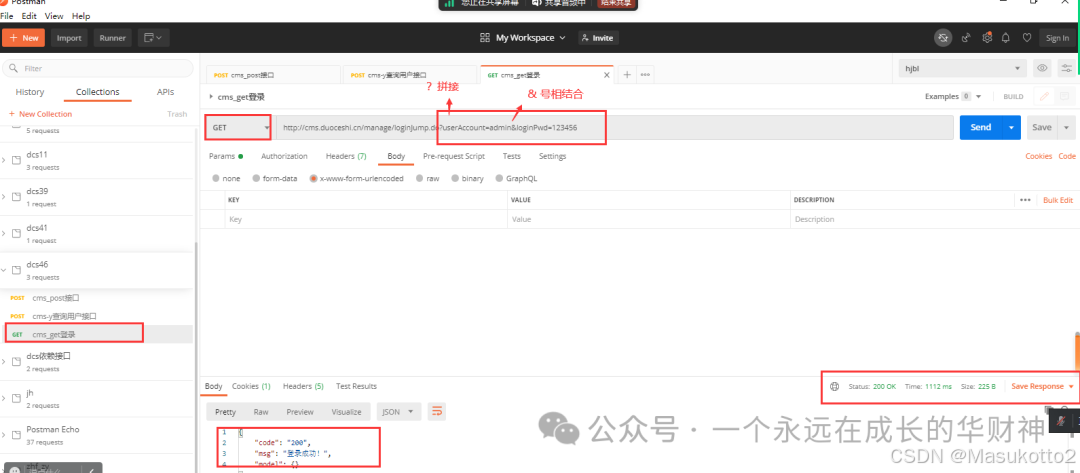
10.设置变量
{{变量名}} 变量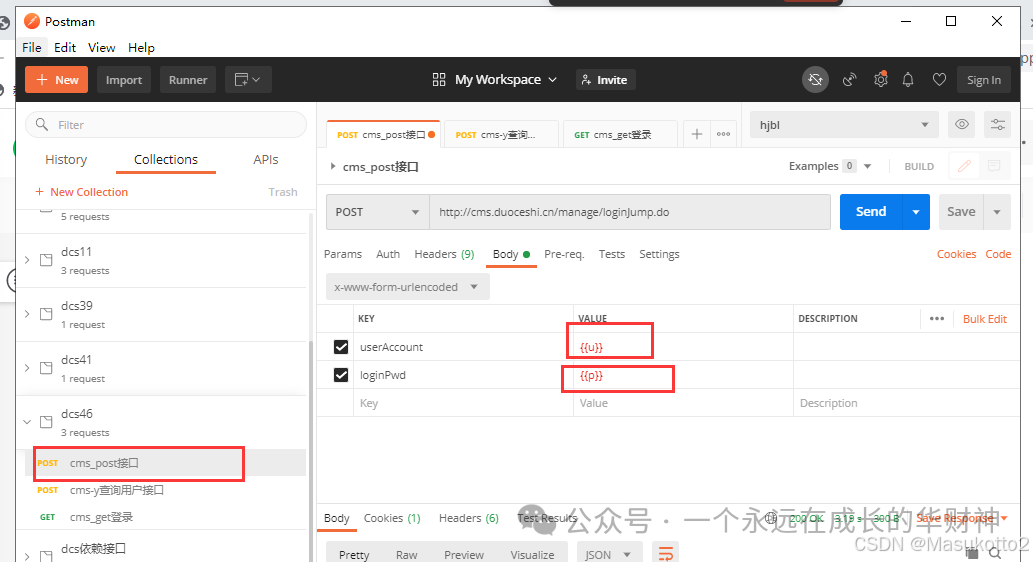
1)引用的变量来自环境变量
a、添加环境变量:u,p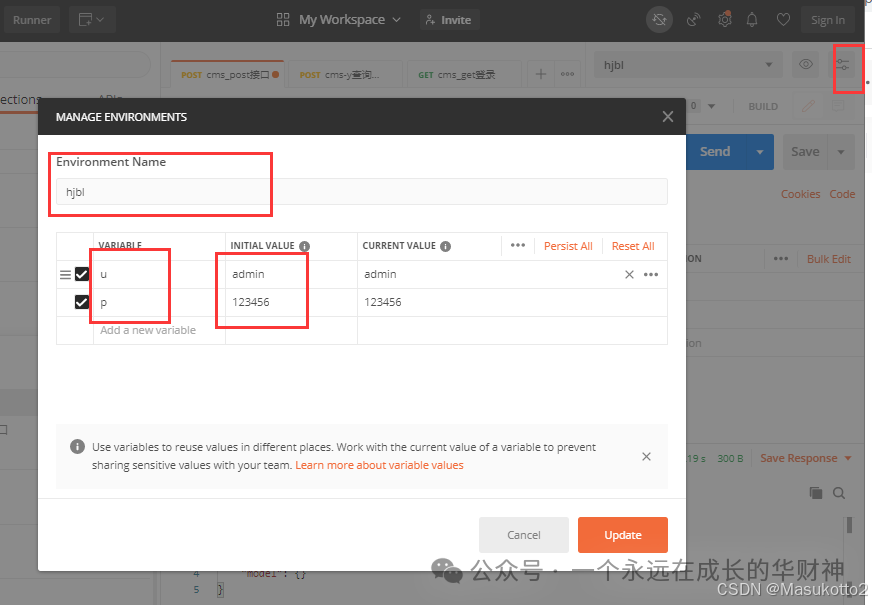
b、设置接口的变量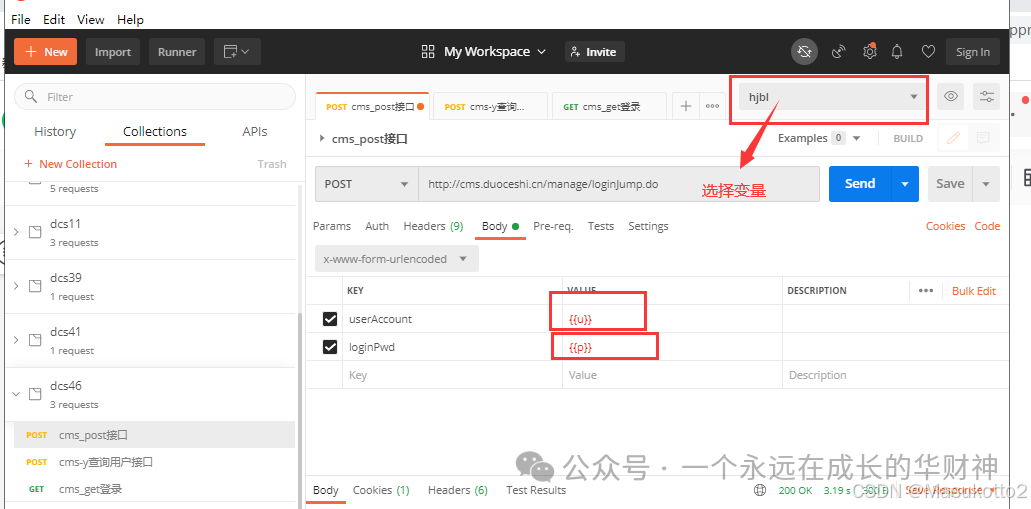
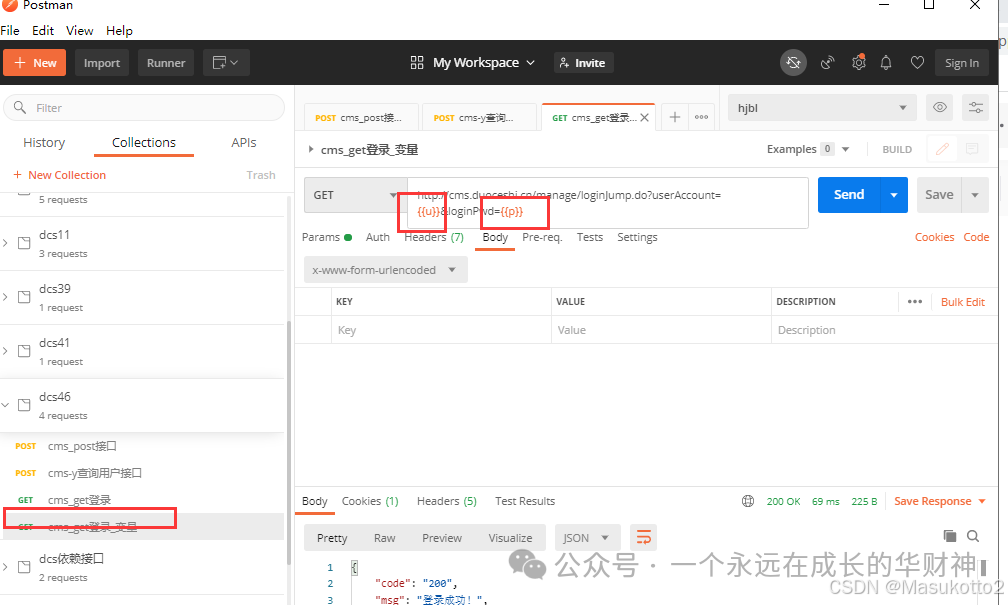
11.依赖接口
两个介接口以上:登录接口,查询用户接口(先登录才能查看用例)
1.登录接口,有了cookies
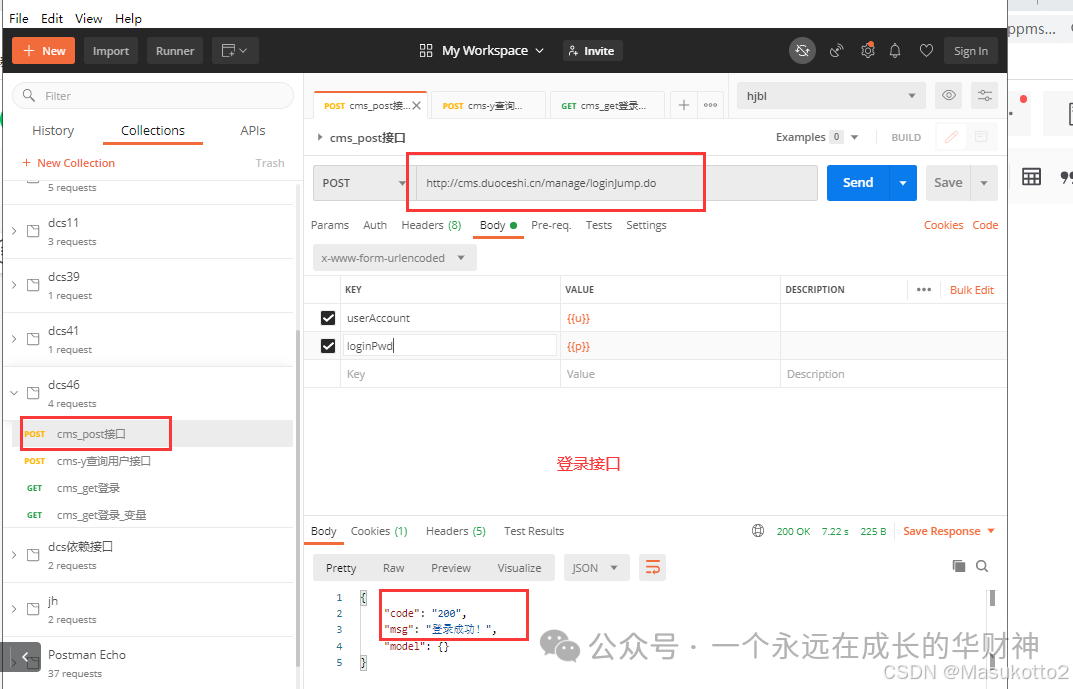
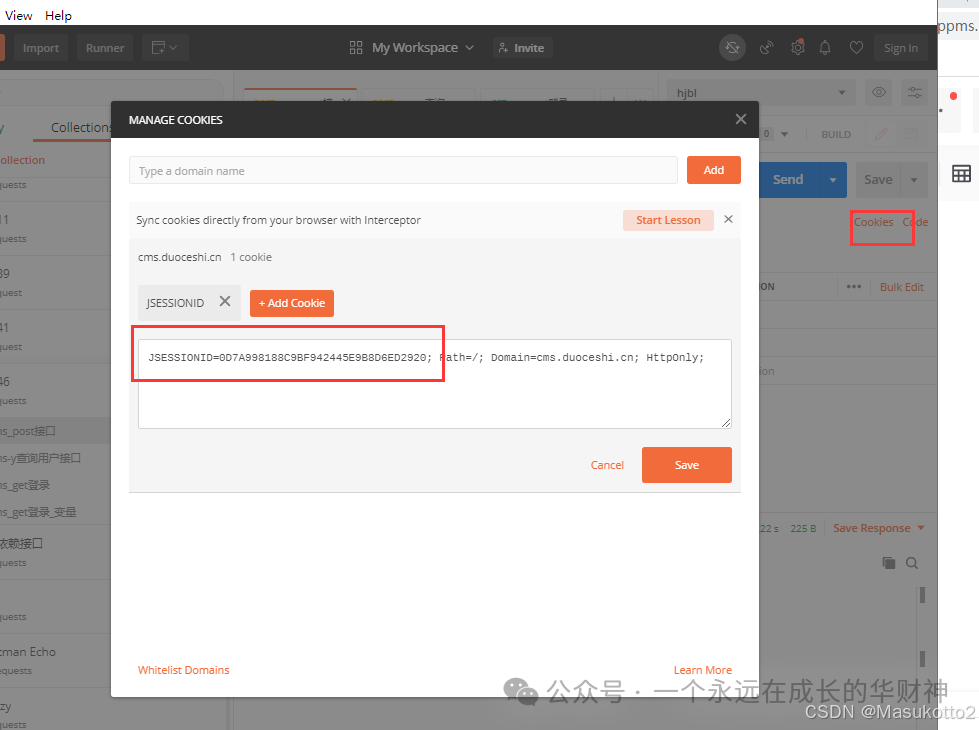
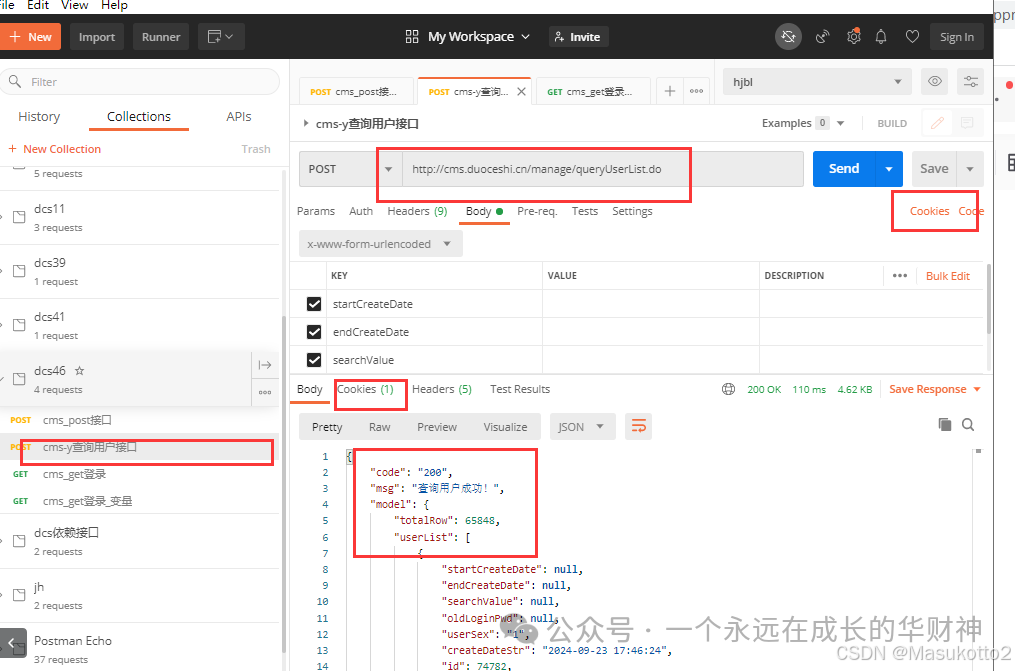
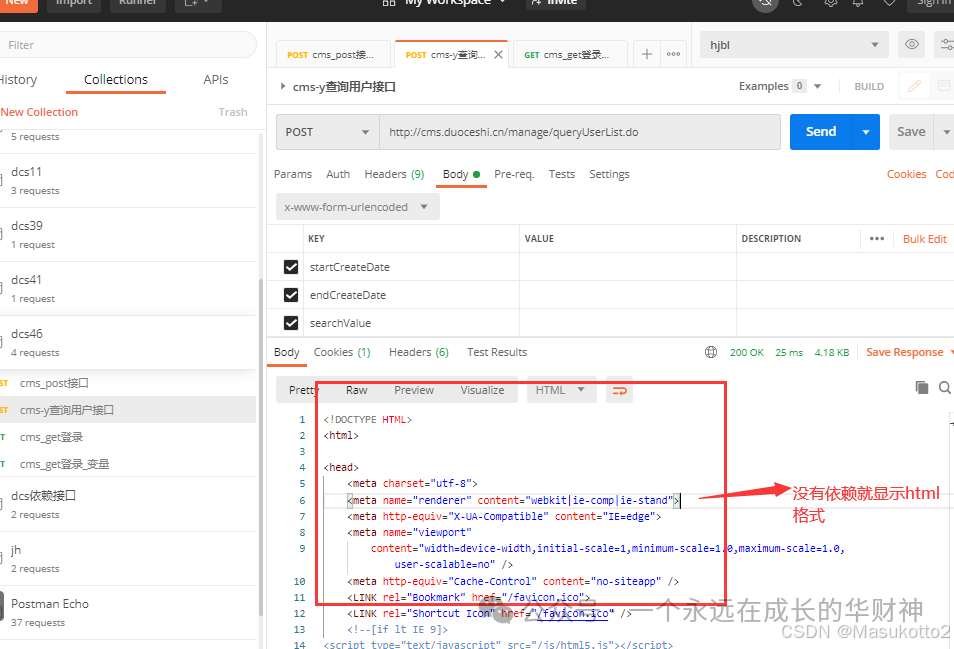
12.断言
test 是断言
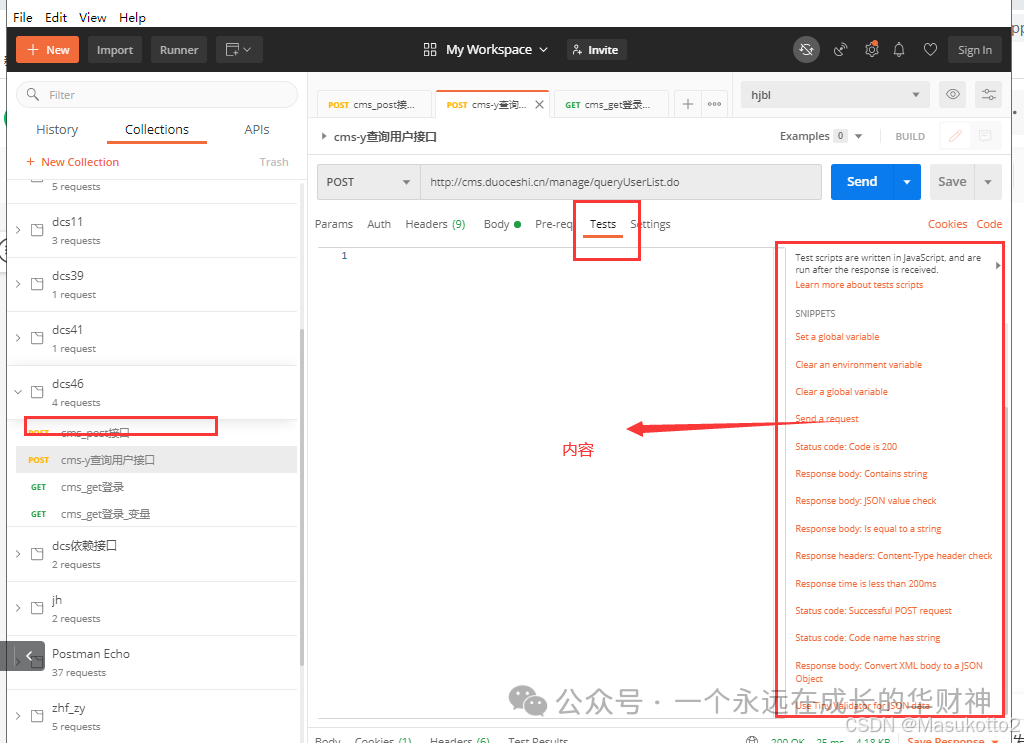
常用的断言响应时间、响应状态码、响应内容
pm.test("Status code is 200", function () {
pm.response.to.have.status(200);
});
pm.test("Body matches string", function () {
pm.expect(pm.response.text()).to.include("成功");
});
pm.test("Response time is less than 200ms", function () {
pm.expect(pm.response.responseTime).to.be.below(200);
})
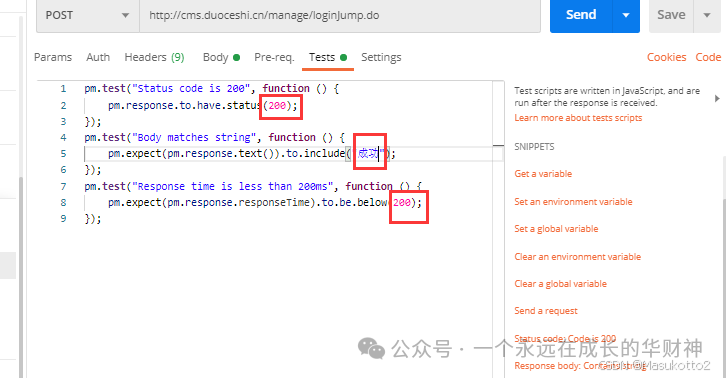
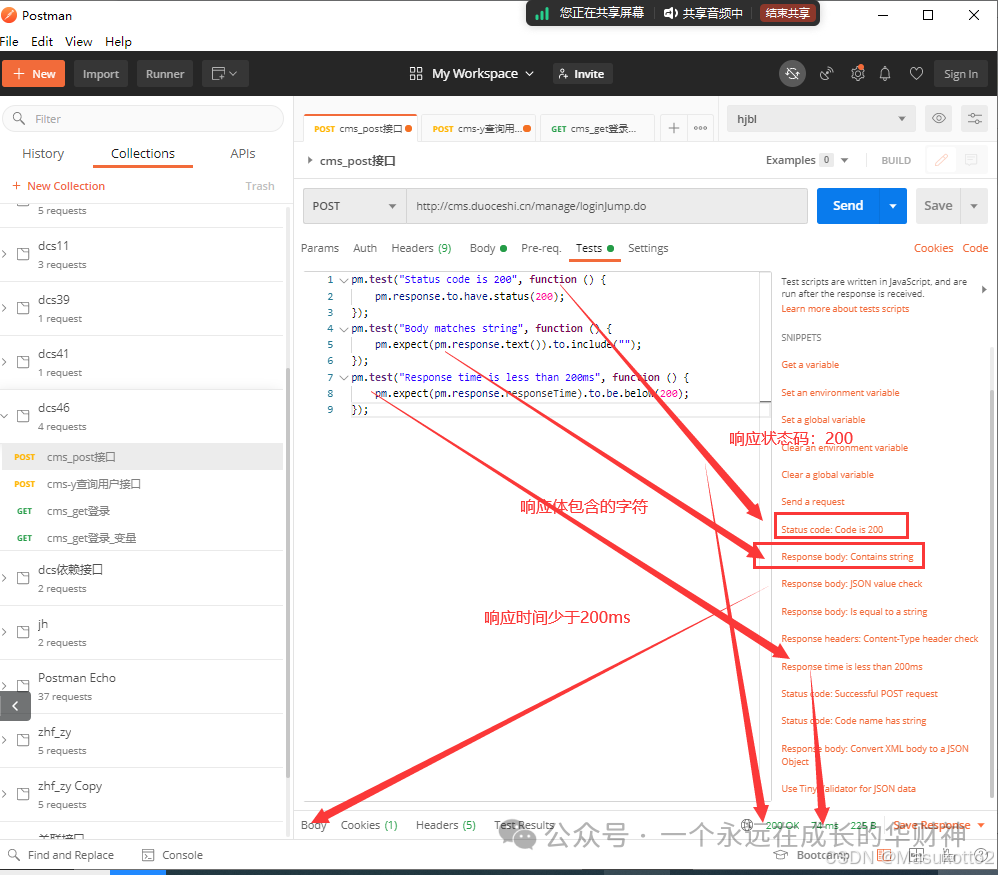
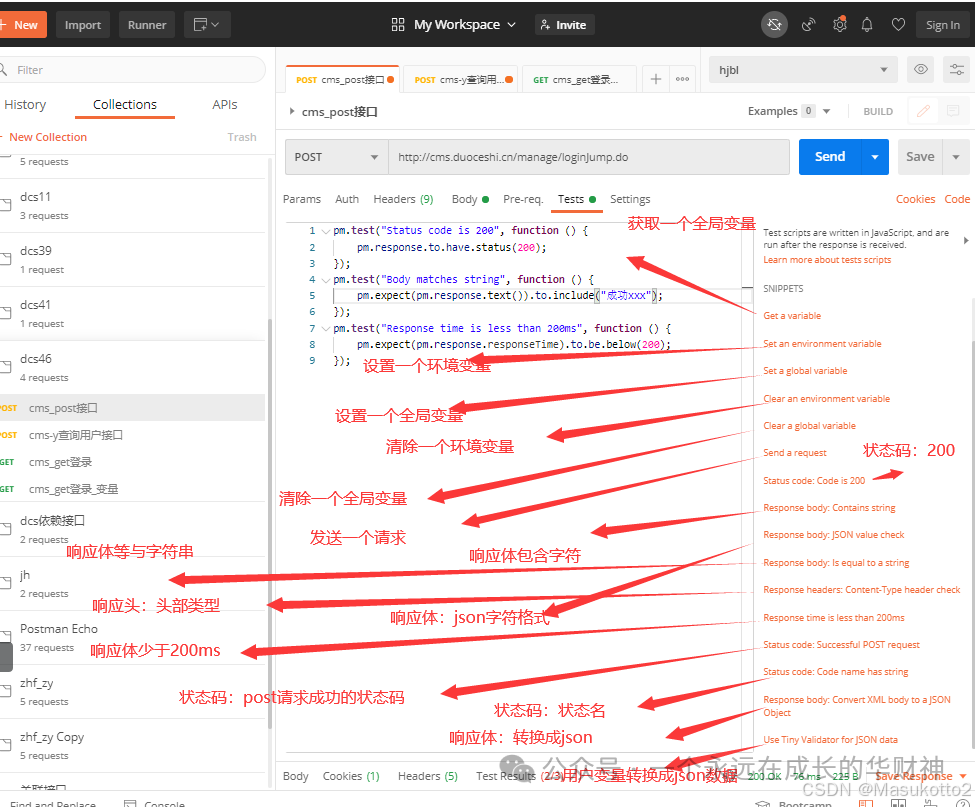
Get a wariable
Set an environment variable
set a global variable
Clear an environment variable
Clear a global variable
send a request
Status code: Code is 200
Response body: Contains string
Response body: JSON value check
Response body. Is equal to a string
Response headers: Content-Type header check
Response time is less than 200ms
Status code: Successful POST request
Status code: Code name has string
Response body: ConwertXML body to a ]SONobject
Use Tiny Validator for JSON data
13.关联接口
定义:拿上一个接口的返回参数,做下一个接口入参
省份接口:
http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportProvince
城市接口:
post http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportCity
body byProvinceName 身份
关联接口
1、先请求省份接口,在省份接口的test中将响应体转换成json
// 将响应体中内容转换成json格式
var jsonObject = xml2Json(responseBody);
// 通过jsonobject 拿到所有的值
js=jsonObject.ArrayOfString.string
// 设置一个环境变量
pm.environment.set("cs", js[4]);
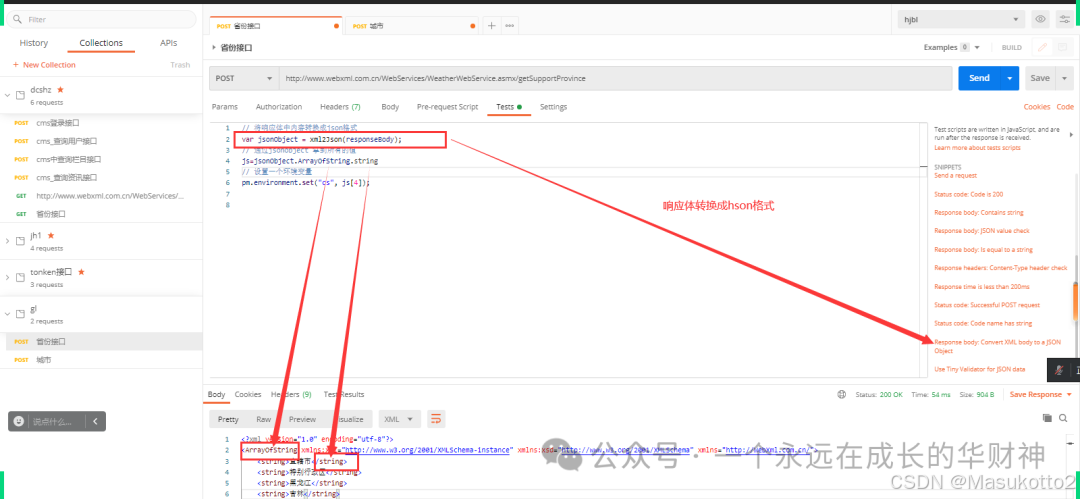
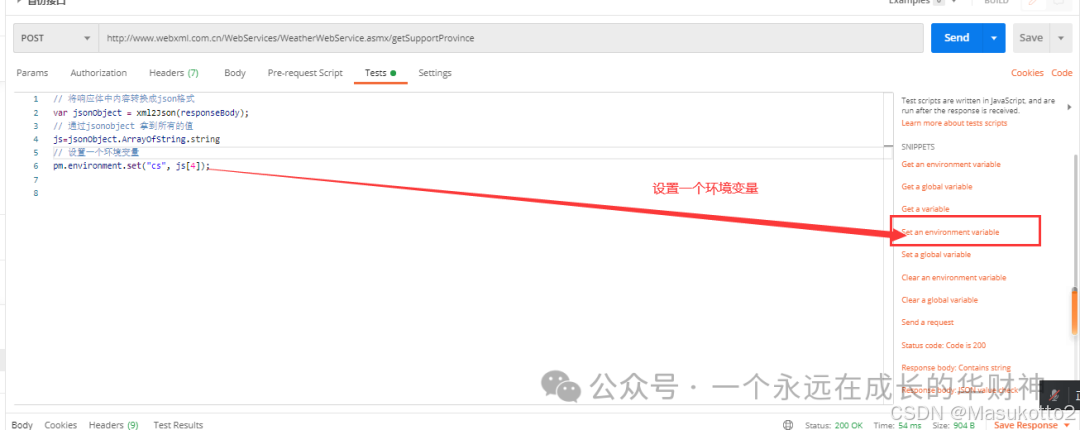
提取的响应体,都存放在环境变量中
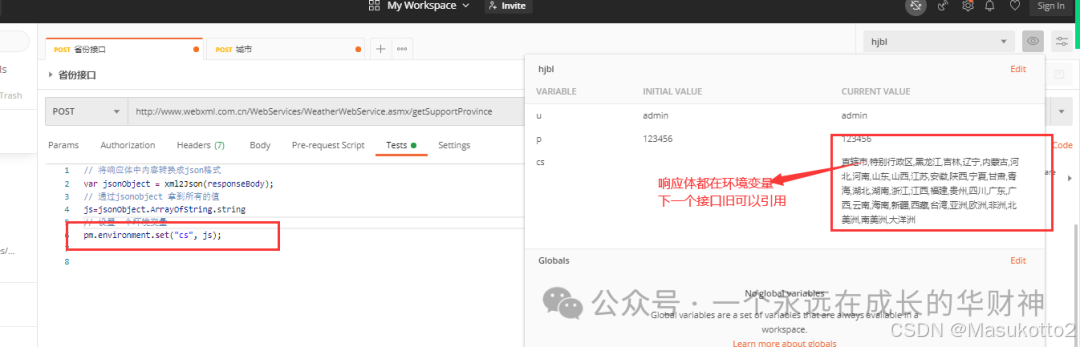
城市接口
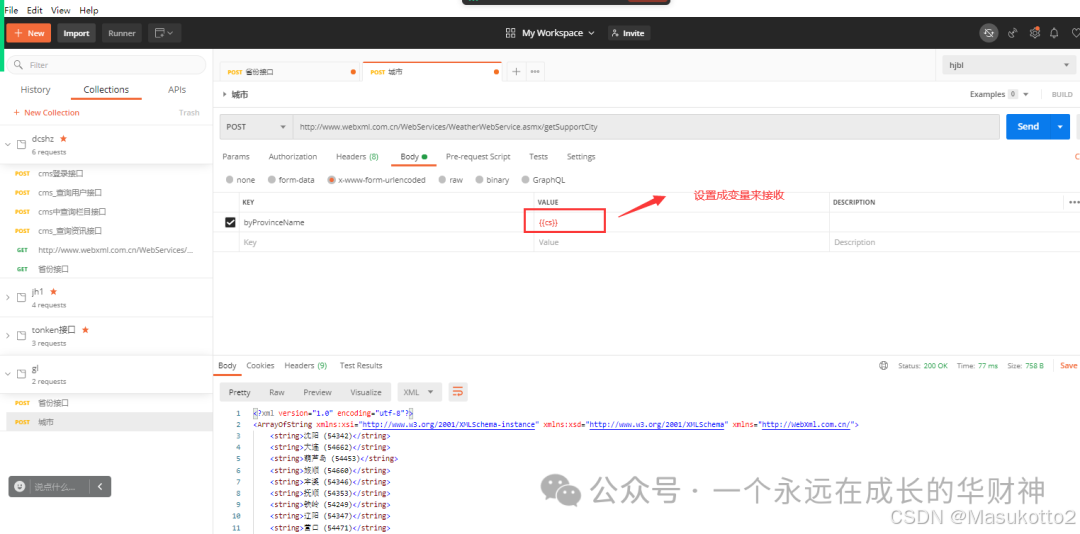
14.多接口的执行(自动执行)
(1)接口脚本导出,我在导入
将集合右键==export===导出
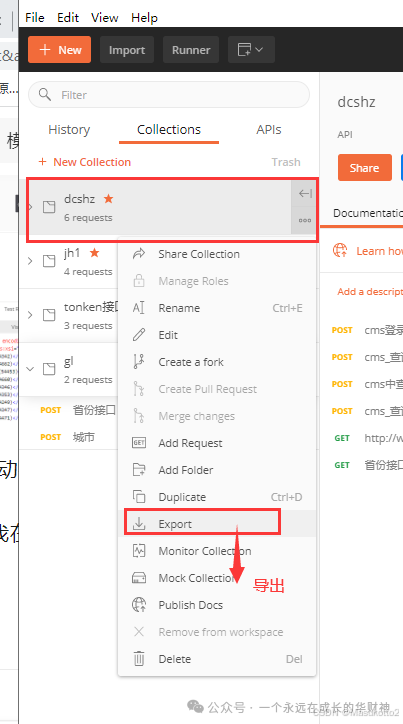
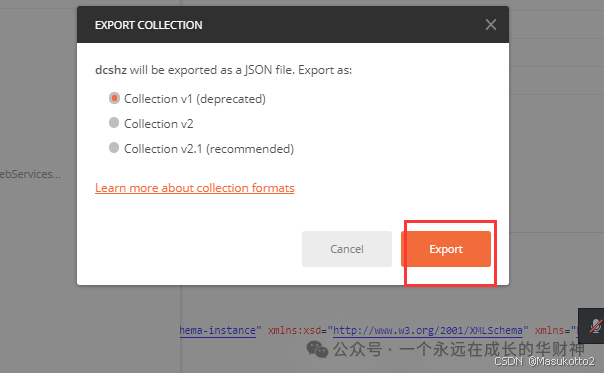
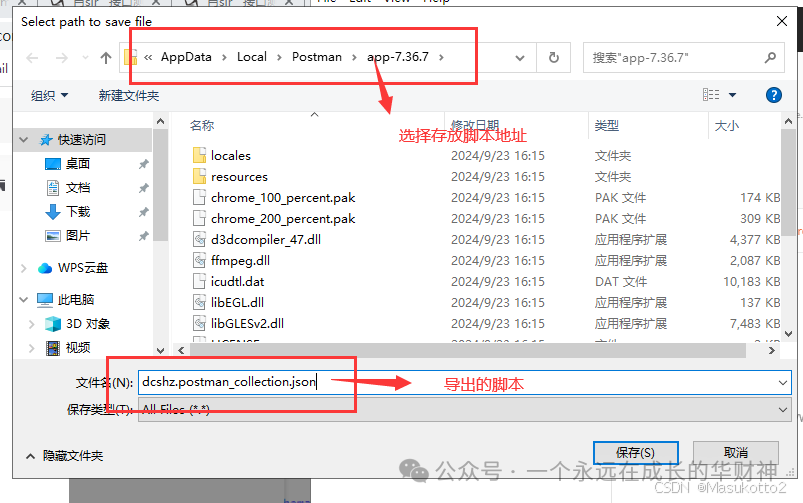
查看导出的脚本:json为后缀的文件
(2)导入接口脚本,后缀名为json格式的
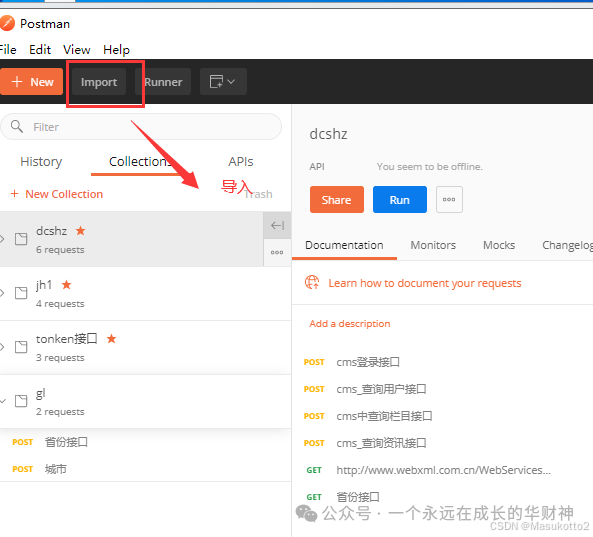
上传文件
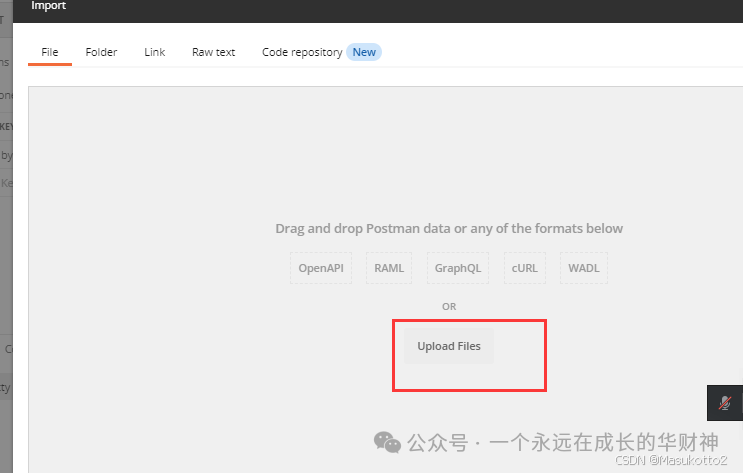
选择json脚本
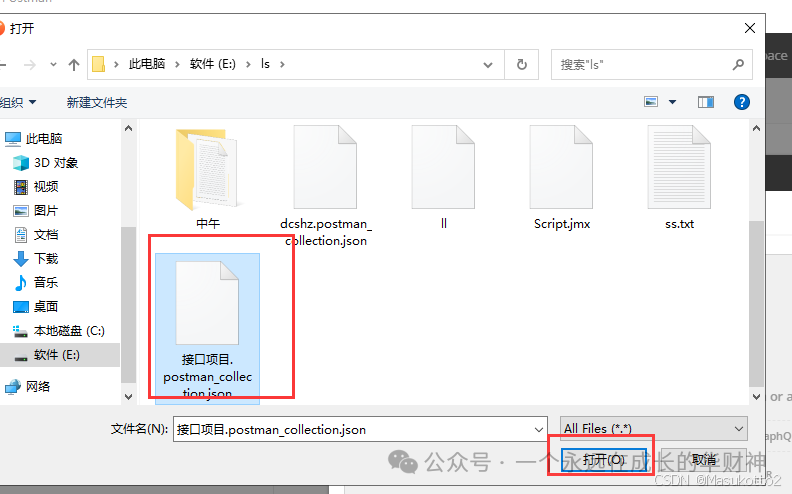
导入好的接口
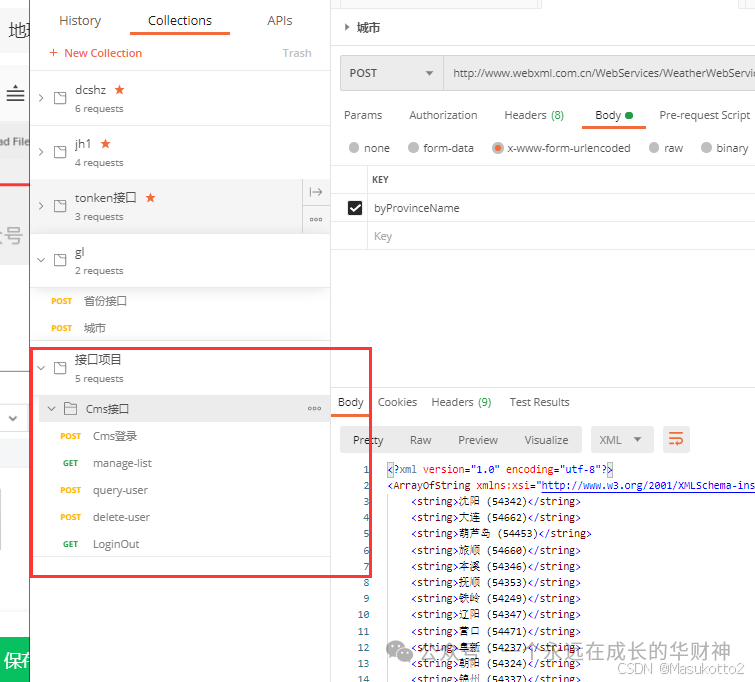
15.知识点多接口的运行
1、点击集合、点击run
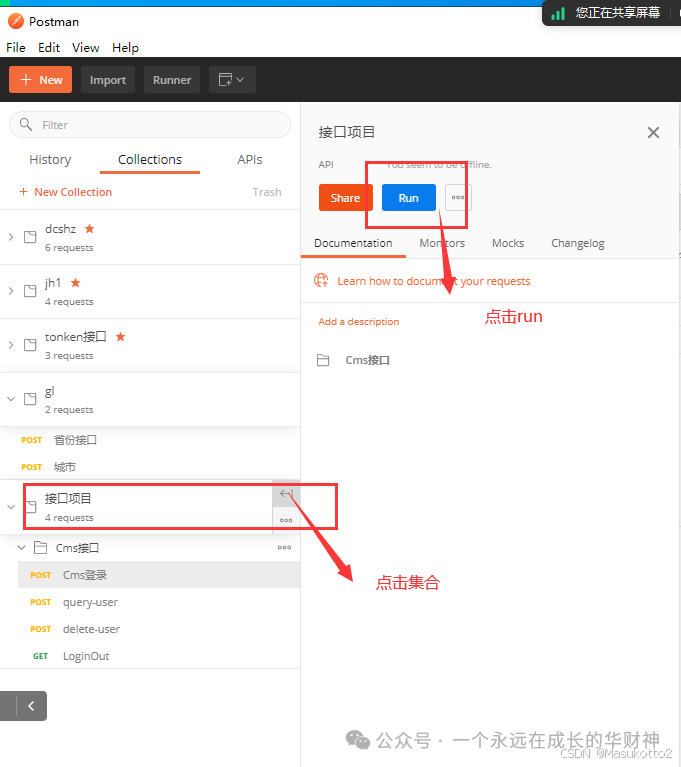
2、环境环境变量,点击run
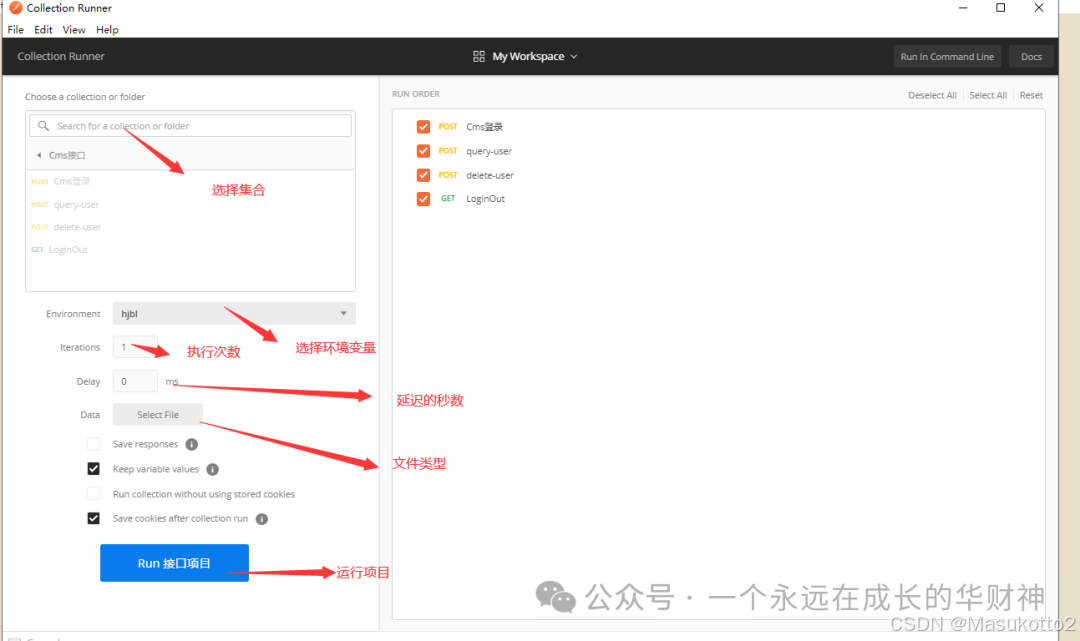
断言数

16.通过csv文件进行参数化(变量)
1、新建一个csv文件(文件最好另存)
2、编辑文件
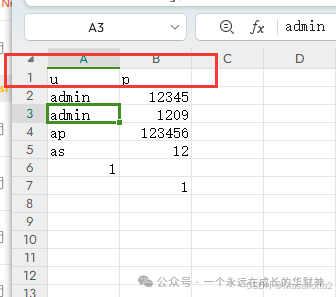
3、编辑登录接口
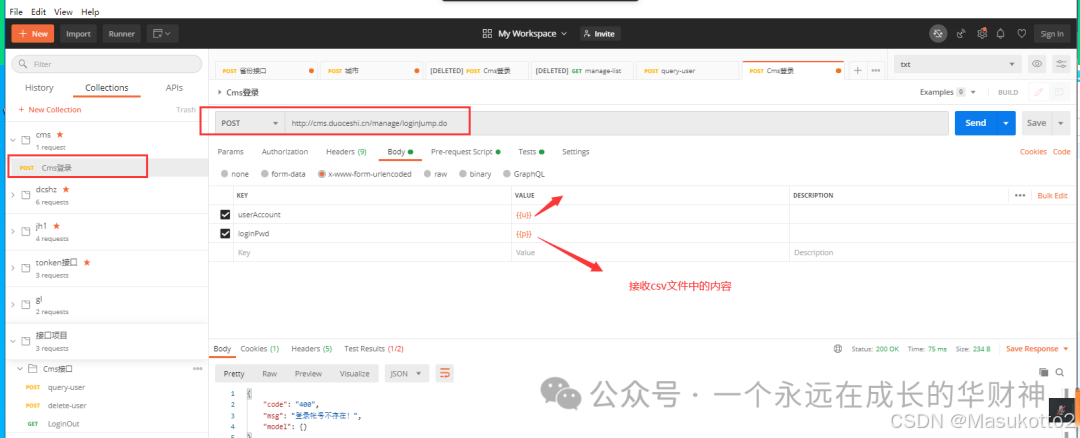
请求前要读取csv文件的内容
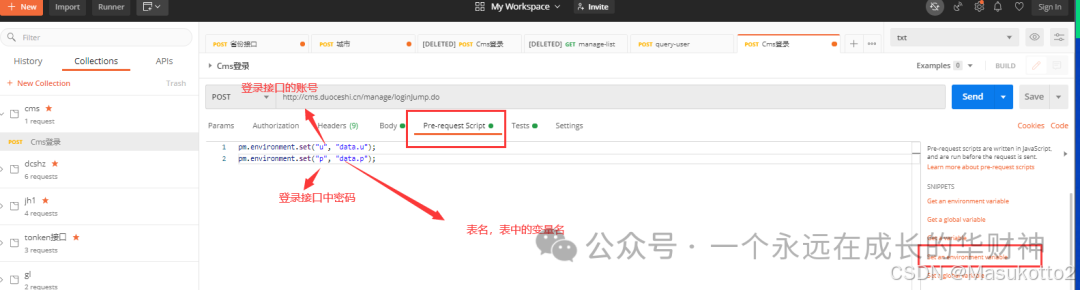
点击run
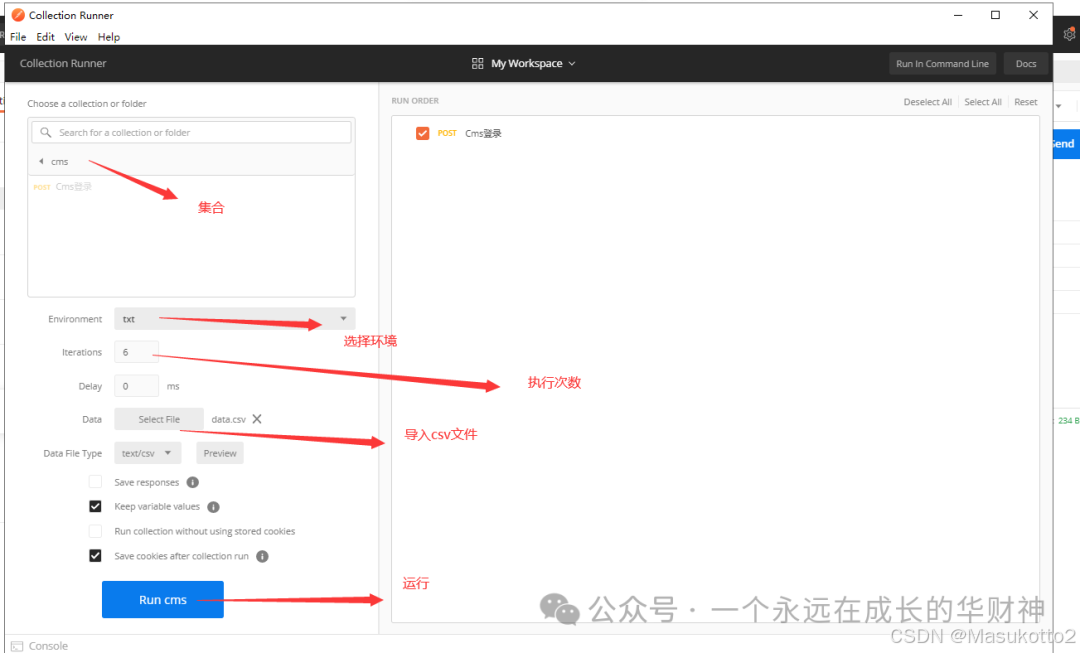
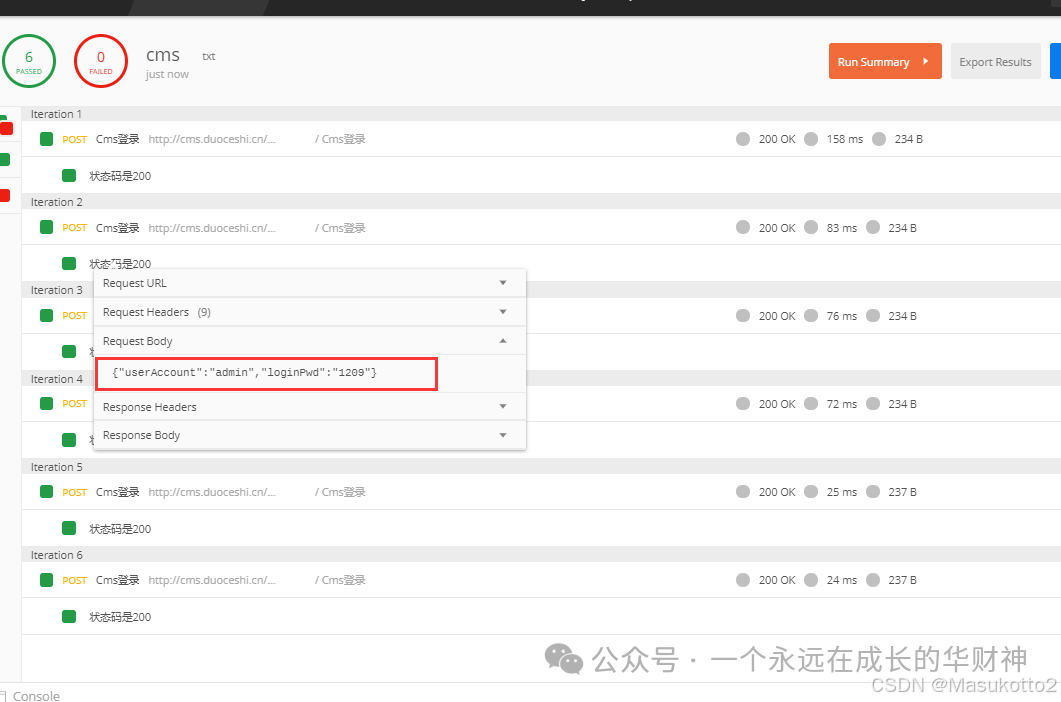
以上旧读取scv中文件
17.通过text文档进行参数
(1)新建text文档,编辑账号,密码
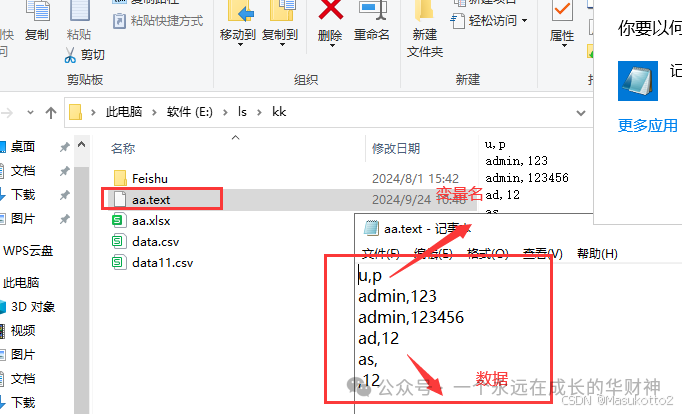
(2)编写接口,设置变量
(3)前置处理器,设置环境变量
(4)在集合中点击run
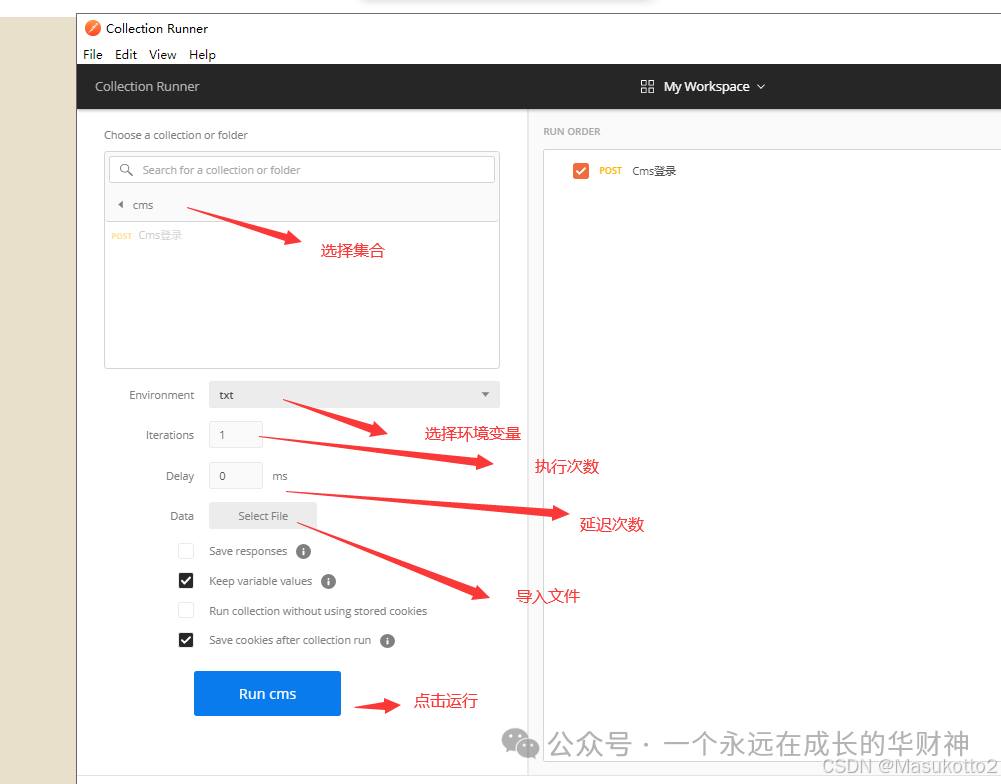
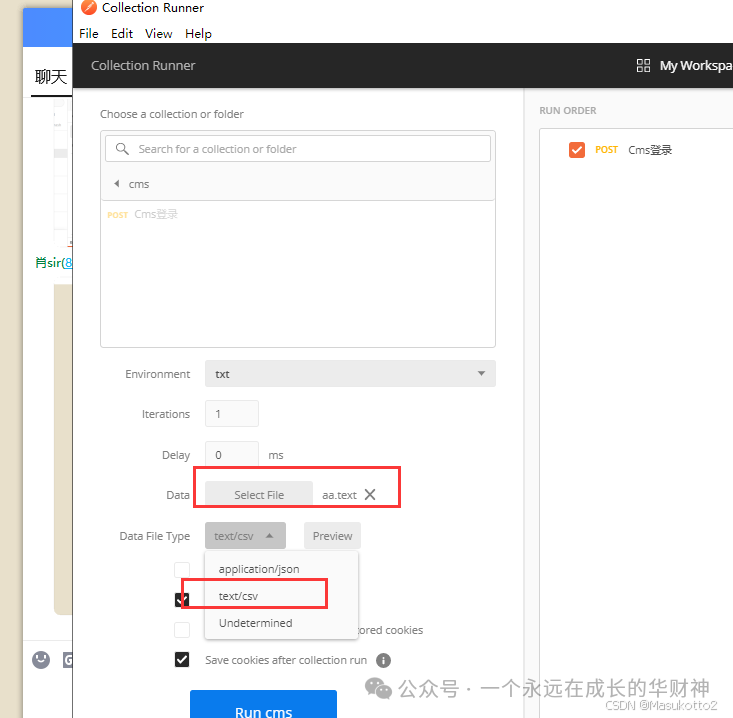
以上选择文件类型
(5)点击run
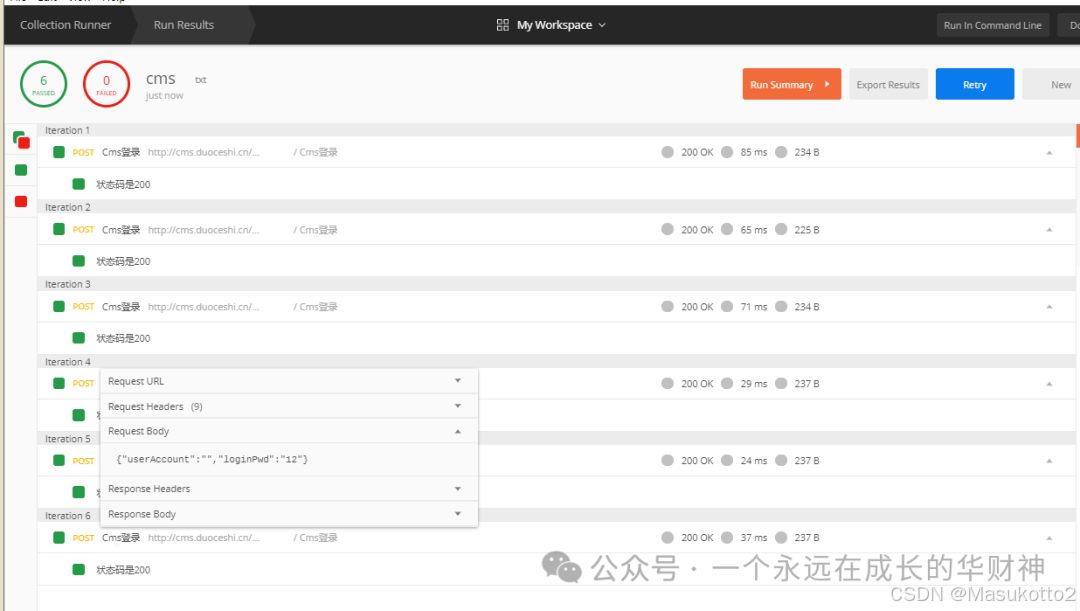
---------------------------------------------------------------------------------------------------------------------------------
作业:
通过postman创建一个集合和通过抓包工具或者Chrome浏览器F12调试抓取如下的接口做接口测试
1、用户管理中的添加用户接口
2、用户管理中的搜用户接口
3、个人修改密码接口
4、栏目设置的添加栏目接口
5、文章管理中的添加资讯接口
接口作业二:
根据用户增删改查接口文档设计测试用例20条
1、正常场景有:输入正确的参数
2、异常场景:假如需求入参为11位-考虑边界值和等价类
入参为10位
入参为12位
删除或者增加入参、不写参数
写参数不填入值(值为空)
入参内容填入关键字参数比如:post get等等
十一、接口测试-- python + requests库
python+request
1.调用的方法
1)requests是一个第三方库
a、下载地方库pip install requests
b、pycaharm中下载
2)导入requests库
3)requests中的三种调用方法
第一种:
requests.get
requests.post
查看使用方法post(ctrl点击post方法)
import requests url="http://cms.duoceshi.cn/manage/loginJump.do" data={'userAccount':'admin','loginPwd':'123456'} headers={"Content-Type":"application/x-www-form-urlencoded"} dx=requests.post(url=url,data=data,json=headers) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 print(dx.json()) #{'code': '200', 'msg': '登录成功!', 'model': {}} 打印json格式 print(dx.cookies) #打印cookie print(dx.status_code) #打印状态码 print(dx.url) #url print(dx.headers) #请求头 print(dx.request) #请求方式查看get的请求方法
a、get中的方法1:params=data 是拼接的参数
import requests url="http://cms.duoceshi.cn/manage/loginJump.do" data={'userAccount':'admin','loginPwd':'123456'} headers={"Content-Type":"application/x-www-form-urlencoded"} dx=requests.get(url=url,params=data,headers=headers) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 print(dx.json()) #{'code': '200', 'msg': '登录成功!', 'model': {}} 打印json格式 print(dx.cookies) #打印cookie print(dx.status_code) #打印状态码 print(dx.url) #url print(dx.headers) #请求头 print(dx.request) #请求方式
b、在url中直接拼接
import requests url="http://cms.duoceshi.cn/manage/loginJump.do?userAccount=admin&loginPwd=123456" headers={"Content-Type":"application/x-www-form-urlencoded"} dx=requests.get(url=url,headers=headers) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 print(dx.json()) #{'code': '200', 'msg': '登录成功!', 'model': {}} 打印json格式 print(dx.cookies) #打印cookie print(dx.status_code) #打印状态码 print(dx.url) #url print(dx.headers) #请求头 print(dx.request) #请求方式第二种方法:
requests.request("get",url=url,headers=headers)
a、get方法
(1)
import requests url="http://cms.duoceshi.cn/manage/loginJump.do?userAccount=admin&loginPwd=123456" headers={"Content-Type":"application/x-www-form-urlencoded"} dx=requests.request("get",url=url,headers=headers) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 print(dx.json()) #{'code': '200', 'msg': '登录成功!', 'model': {}} 打印json格式 print(dx.cookies) #打印cookie print(dx.status_code) #打印状态码 print(dx.url) #url print(dx.headers) #请求头 print(dx.request) #请求方式(2)get中的params方法
import requests url="http://cms.duoceshi.cn/manage/loginJump.do" data={'userAccount':'admin','loginPwd':'123456'} headers={"Content-Type":"application/x-www-form-urlencoded"} dx=requests.request("get",url=url,params=data,headers=headers,) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 print(dx.json()) #{'code': '200', 'msg': '登录成功!', 'model': {}} 打印json格式 print(dx.cookies) #打印cookie print(dx.status_code) #打印状态码 print(dx.url) #url print(dx.headers) #请求头 print(dx.request) #请求方式b.post请求
import requests url="http://cms.duoceshi.cn/manage/loginJump.do" data={'userAccount':'admin','loginPwd':'123456'} headers={"Content-Type":"application/x-www-form-urlencoded"} dx=requests.request("post",url=url,data=data,headers=headers,) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 print(dx.json()) #{'code': '200', 'msg': '登录成功!', 'model': {}} 打印json格式 print(dx.cookies) #打印cookie print(dx.status_code) #打印状态码 print(dx.url) #url print(dx.headers) #请求头 print(dx.request) #请求方式第三种方法:保持会话
import requests s=requests.Session() url="http://cms.duoceshi.cn/manage/loginJump.do" data={'userAccount':'admin','loginPwd':'123456'} headers={"Content-Type":"application/x-www-form-urlencoded"} dx=s.request("post",url=url,data=data,headers=headers,) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 print(dx.json()) #{'code': '200', 'msg': '登录成功!', 'model': {}} 打印json格式 print(dx.cookies) #打印cookie print(dx.status_code) #打印状态码 print(dx.url) #url print(dx.headers) #请求头 print(dx.request) #请求方式
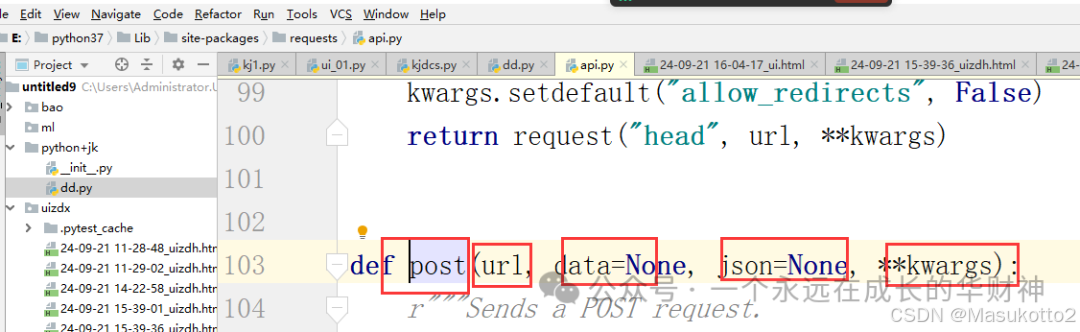
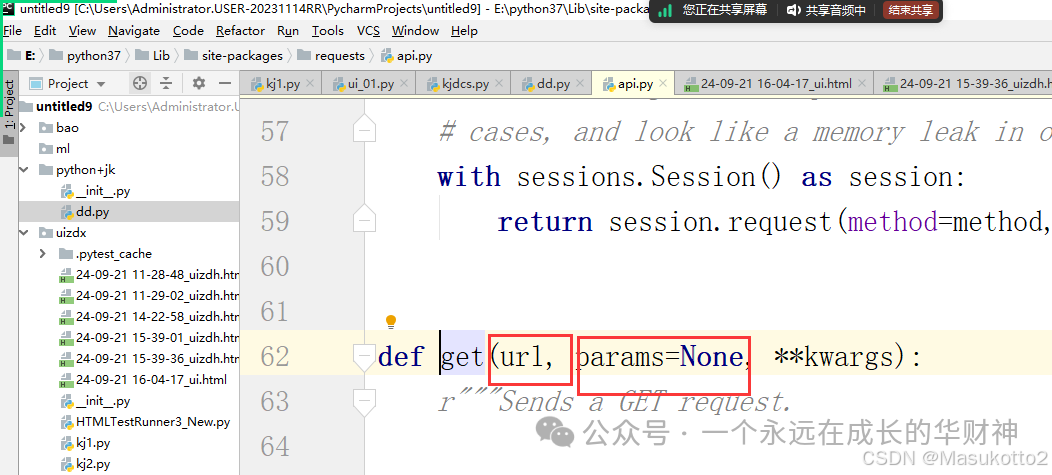
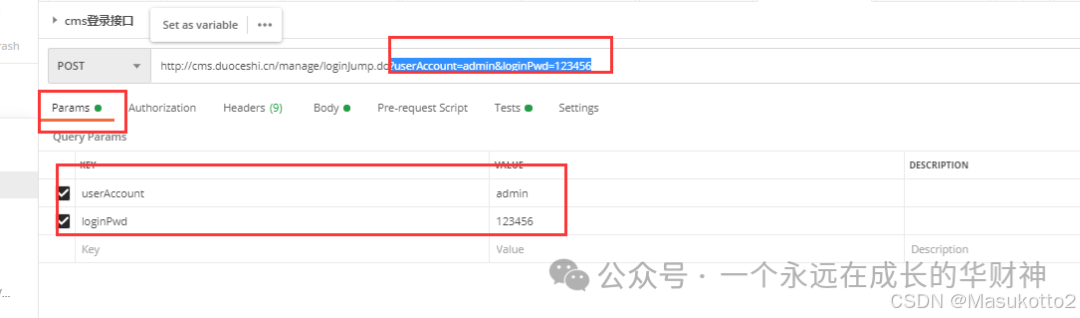
2.依赖接口
(1)第一种方法:requests.session
准备两个接口:一个登录接口,一个用户查询接口
登录接口:http://cms.duoceshi.cn/manage/loginJump.do
请求体:
userAccount:admin
loginPwd:123456
用户查询接口:http://cms.duoceshi.cn/manage/queryUserList.do
请求体:
startCreateDate:
endCreateDate:
searchValue:
page:1
import requests s=requests.Session() url="http://cms.duoceshi.cn/manage/loginJump.do" data={'userAccount':'admin','loginPwd':'123456'} headers={"Content-Type":"application/x-www-form-urlencoded"} dx=s.request("post",url=url,data=data,headers=headers,) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 url2="http://cms.duoceshi.cn/manage/queryUserList.do" data2={'startCreateDate':'','endCreateDate':'','searchValue':'','page':1} headers2={"Content-Type":"application/x-www-form-urlencoded"} dx2=s.request("post",url=url2,data=data2,headers=headers2) print(dx2.text)
(2)第二种方法:通过cookies保持会话
import requests class Cms(object): def __init__(self): pass def dl(self): url="http://cms.duoceshi.cn/manage/loginJump.do" data={'userAccount':'admin','loginPwd':'123456'} headers={"Content-Type":"application/x-www-form-urlencoded"} dx=requests.request("post",url=url,data=data,headers=headers,) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 # print(dx.cookies) c=str(dx.cookies) # 将cookie和转换成字符串 self.s=c.split(" ")[1] def yhgl(self): url2="http://cms.duoceshi.cn/manage/queryUserList.do" data2={'startCreateDate':'','endCreateDate':'','searchValue':'','page':1} headers2={"Content-Type":"application/x-www-form-urlencoded","Cookie":self.s} dx2=requests.request("post",url=url2,data=data2,headers=headers2) print(dx2.text) if __name__ == '__main__': d=Cms() d.dl() d.yhgl()
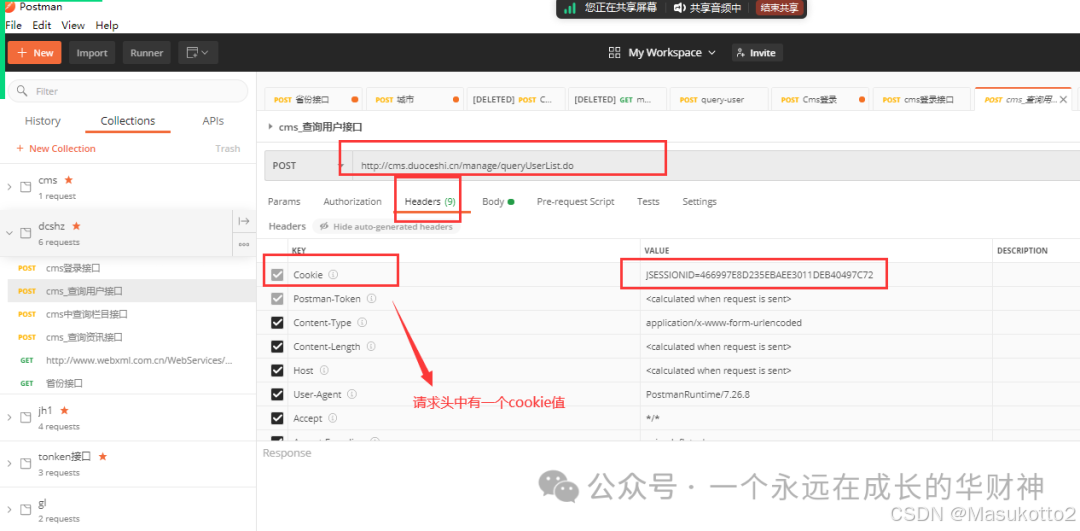
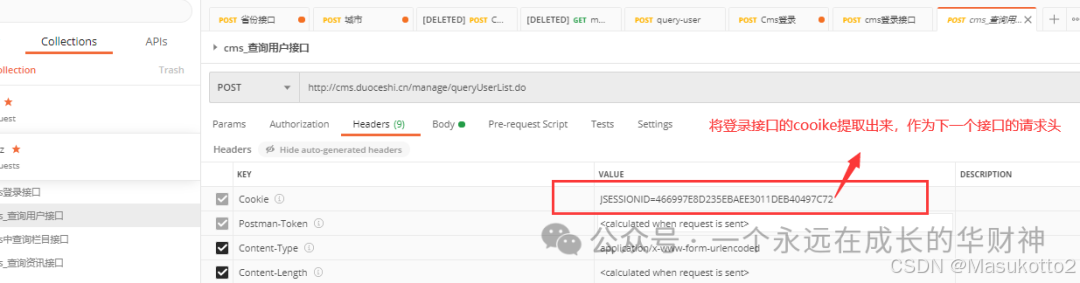

(3)通过提取登录接口的cooike ,作为一个返回
import requests class Cms(object): def __init__(self): pass def dl(self): url="http://cms.duoceshi.cn/manage/loginJump.do" data={'userAccount':'admin','loginPwd':'123456'} headers={"Content-Type":"application/x-www-form-urlencoded"} dx=requests.request("post",url=url,data=data,headers=headers,) print(dx.text) #{"code":"200","msg":"登录成功!","model":{}} 响应体 # print(dx.cookies) c=str(dx.cookies) # 将cookie和转换成字符串 s=c.split(" ")[1] return s def yhgl(self): f=self.dl() url2="http://cms.duoceshi.cn/manage/queryUserList.do" data2={'startCreateDate':'','endCreateDate':'','searchValue':'','page':1} headers2={"Content-Type":"application/x-www-form-urlencoded","Cookie":f} dx2=requests.request("post",url=url2,data=data2,headers=headers2) print(dx2.text) if __name__ == '__main__': d=Cms() d.dl() d.yhgl()
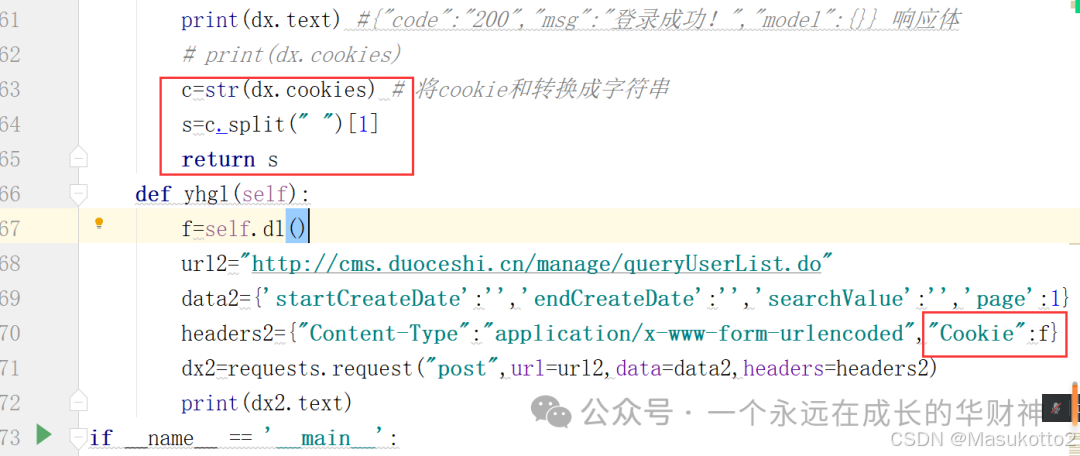
3.关联接口
关联接口:
上一个接口的响应体,作为下一个接口的请求体
案例:
准备省份接口
城市接口:
http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportProvince
城市接口:
http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportCity
入参:
byProvinceName:城市名称
案例1:管理接口单独调通
import requests s=requests.Session() class Gl(object): def __init__(self): pass def sf(self): url="http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportProvince" headers = {"Content-Type": "application/x-www-form-urlencoded"} dx=s.request("get",url=url,headers=headers) print(dx.text) def cs(self): url2="http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportCity" data2={"byProvinceName":"浙江"} headers2 = {"Content-Type": "application/x-www-form-urlencoded"} dx2=s.request("post",url=url2,data=data2,headers=headers2) print(dx2.text) if __name__ == '__main__': d=Gl() d.sf() d.cs()
管理接口:
将省份的响应体提取出来,用到re正则提取,
在存放在城市的请求体中
提取汉字:
<string>(.+?)</string> 内容匹配0次或1次或n次,
. 匹配任意字符 + 匹配1次或n次 ?是匹配0次或1次
(1)管理接口中 通过self.实例变量
class Gl(object): def __init__(self): pass def sf(self): url="http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportProvince" headers = {"Content-Type": "application/x-www-form-urlencoded"} dx=s.request("get",url=url,headers=headers) nr=dx.text self.tq=re.findall("<string>(.+?)</string>",nr)[3] print(self.tq) def cs(self): url2="http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportCity" data2={"byProvinceName":self.tq} headers2 = {"Content-Type": "application/x-www-form-urlencoded"} dx2=s.request("post",url=url2,data=data2,headers=headers2) print(dx2.text) if __name__ == '__main__': d=Gl() d.sf() d.cs()(2)通过return 来进行传递
import requests import re s=requests.Session() class Gl(object): def __init__(self): pass def sf(self): url="http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportProvince" headers = {"Content-Type": "application/x-www-form-urlencoded"} dx=s.request("get",url=url,headers=headers) nr=dx.text tq=re.findall("<string>(.+?)</string>",nr)[3] return tq def cs(self): c=self.sf() url2="http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportCity" data2={"byProvinceName":c} headers2 = {"Content-Type": "application/x-www-form-urlencoded"} dx2=s.request("post",url=url2,data=data2,headers=headers2) print(dx2.text) if __name__ == '__main__': d=Gl() d.sf() d.cs()重点是提取:所有的省份
tq=re.findall("<string>(.+?)</string>",nr)
(3)随机获取省份
import requests import re import random s=requests.Session() class Gl(object): def __init__(self): pass def sf(self): url="http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportProvince" headers = {"Content-Type": "application/x-www-form-urlencoded"} dx=s.request("get",url=url,headers=headers) nr=dx.text tq=re.findall("<string>(.+?)</string>",nr) self.b=random.choice(tq) def cs(self): c=self.sf() url2="http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportCity" data2={"byProvinceName":self.b} headers2 = {"Content-Type": "application/x-www-form-urlencoded"} dx2=s.request("post",url=url2,data=data2,headers=headers2) print(dx2.text) if __name__ == '__main__': d=Gl() d.sf() d.cs()

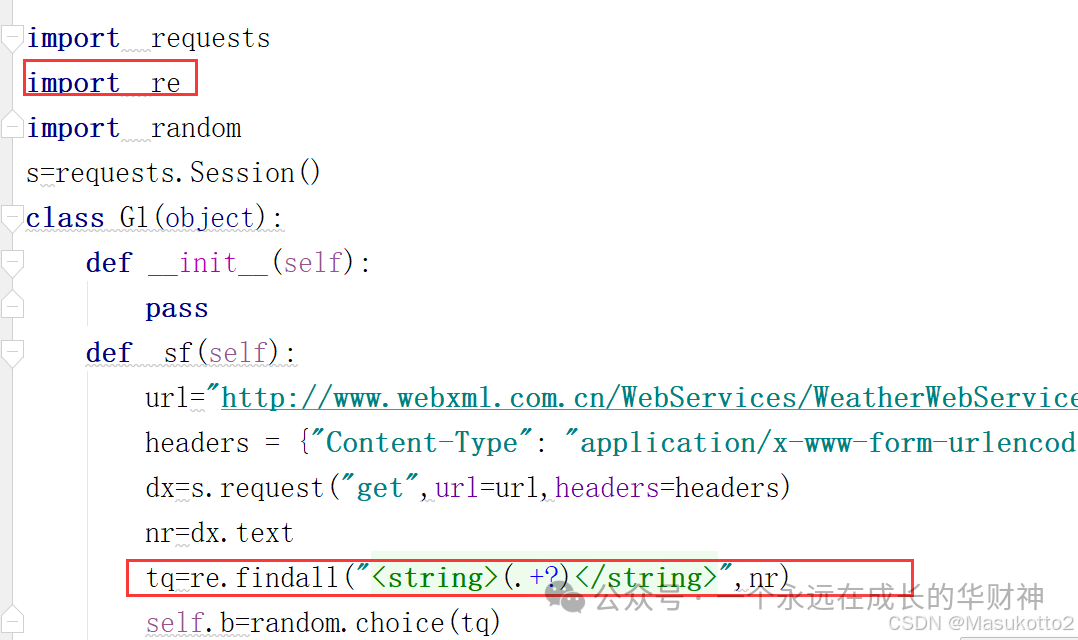
4.tonken
一、如何提取tonken值
token案例:
网站:http://shop.duoceshi.com/login?redirect=%2Fdashboard验证码(固定):8888
二、抓取接口
第一个接口:code接口:http://manage.duoceshi.com/auth/code
第二个接口:登录接口:http://manage.duoceshi.com/auth/login
登录接口参数:{"username":"admin","password":"e6WGOz+g/FuR646O7IF8JrlC6qH/anCI9/0UCsVDnUxN2aBdGKtRffNb1W7i87dRavZCNyP9yqvAcXLgdKtsRA==","code":"8888","uuid":"{{uuid}}"}入参类型:Content-Type:application/json
登录成功以后才会生成token值
第三个接口:
http://manage.duoceshi.com/api/menus/build
搜索商品接口:http://manage.duoceshi.com/api/yxStoreCategory?page=0&size=10&sort=sort%2Cdesc
Authorization:
Bearer eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsImV4cCI6MTY4MDE0OTgwNX0.fmlEdR5Xh1BF2al6crfPMjG8dd-M6TOKux3wni5ejvGFLce4Zk0tvKsCobj7WEaXvXI-N-21AIj2HH5LFlFMNw
三、实战
案例1:提取方法是通过转换成json格式, 通过键,得到值
import requests s= requests.Session() class Yshop(object): def __init__(self): pass def code(self): url1="http://manage.duoceshi.com/auth/code" headers1={"Content-Type": "application/json"} dx1=s.request("get",url=url1,headers=headers1) print(dx1.text) self.u=dx1.json()["uuid"] print(self.u) #code-keyee684cda1a424969bb7e945bc877bd7a def dl(self): url2="http://manage.duoceshi.com/auth/login" data2={'username': 'admin', 'password': 'XwJxEfCdytLwgz7BqKcxqSih6VZB8+PtfUS5kXhHgO8g5Mla1KY6qAczAR2fhCvnMJqKYu8F0nySHTmuhE08wg==', 'code': '8888', 'uuid': self.u} headers2 = {"Content-Type": "application/json"} dx2=s.request("post",url=url2,json=data2,headers=headers2) print(dx2.text) self.t=dx2.json()["token"] print(self.t) def buid(self): url3="http://manage.duoceshi.com/api/menus/build" headers3 = {"Content-Type": "application/json", "Authorization":self.t} dx3=s.request("get",url=url3,headers=headers3) print(dx3.text) if __name__ == '__main__': d=Yshop() d.code() d.dl() d.buid()案例2:
import requests import re s= requests.Session() class Yshop(object): def __init__(self): pass def code(self): url1="http://manage.duoceshi.com/auth/code" headers1={"Content-Type": "application/json"} dx1=s.request("get",url=url1,headers=headers1) wb=dx1.text print(wb) u=re.findall('"uuid":"(.+?)"',wb) self.uid="".join(u) def dl(self): url2="http://manage.duoceshi.com/auth/login" data2={'username': 'admin', 'password': 'XwJxEfCdytLwgz7BqKcxqSih6VZB8+PtfUS5kXhHgO8g5Mla1KY6qAczAR2fhCvnMJqKYu8F0nySHTmuhE08wg==', 'code': '8888', 'uuid': self.uid} headers2 = {"Content-Type": "application/json"} dx2=s.request("post",url=url2,json=data2,headers=headers2) print(dx2.text) t=re.findall('"token":"(.+?)"',dx2.text) self.t1="".join(t) def buid(self): url3="http://manage.duoceshi.com/api/menus/build" headers3 = {"Content-Type": "application/json", "Authorization":self.t1} dx3=s.request("get",url=url3,headers=headers3) print(dx3.text) if __name__ == '__main__': d=Yshop() d.code() d.dl() d.buid()
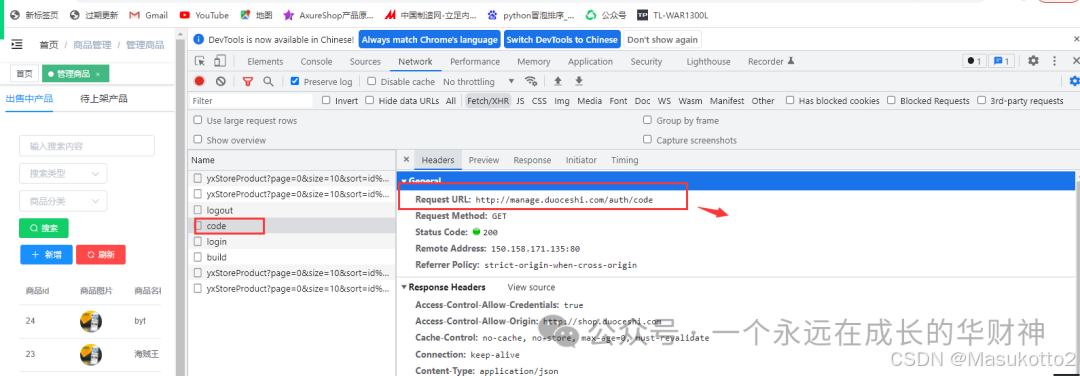
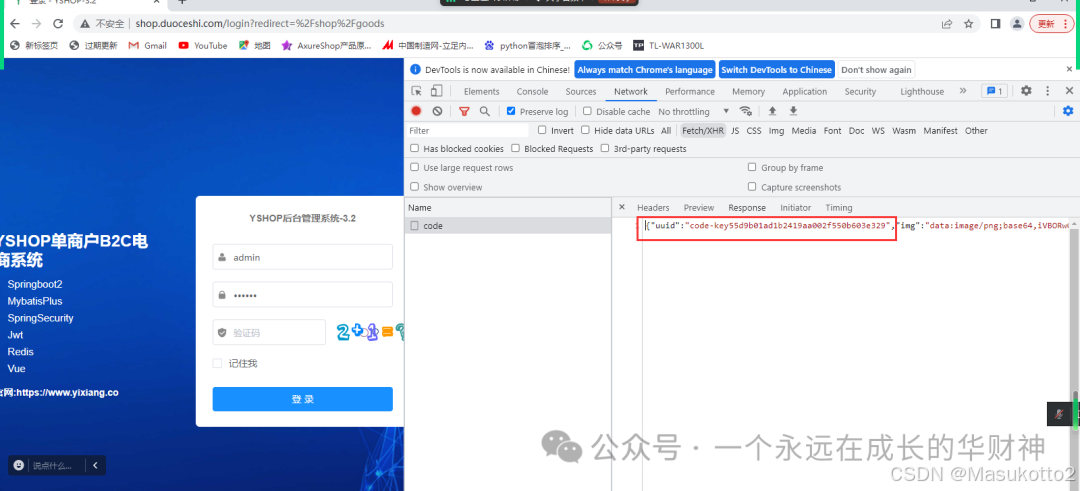
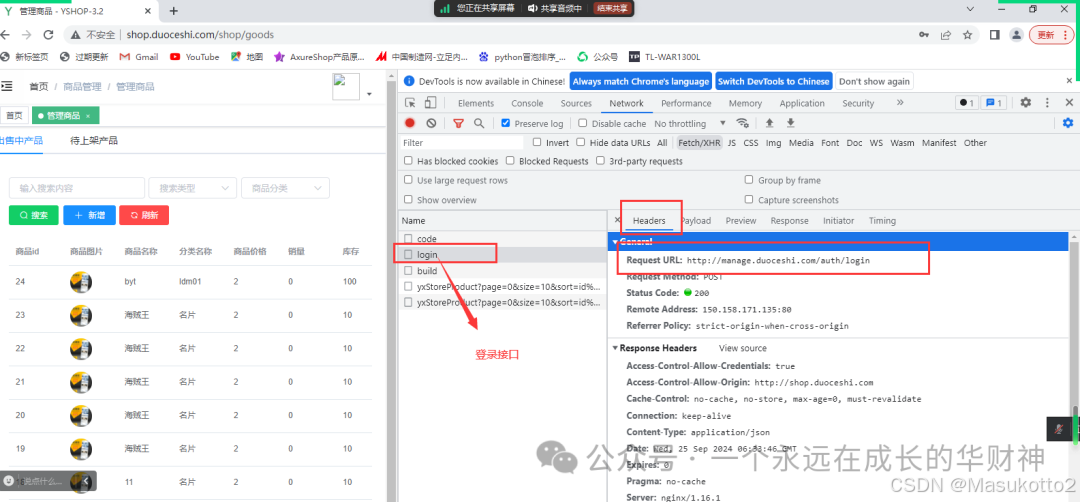
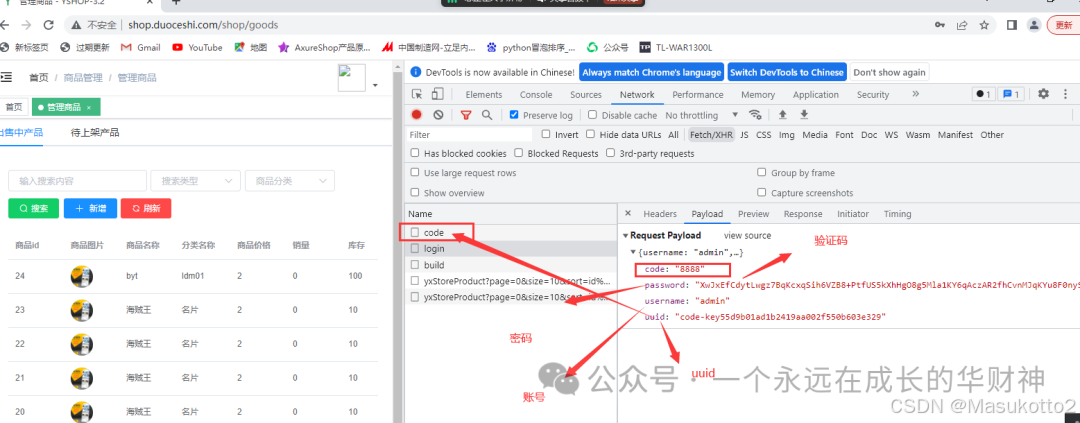
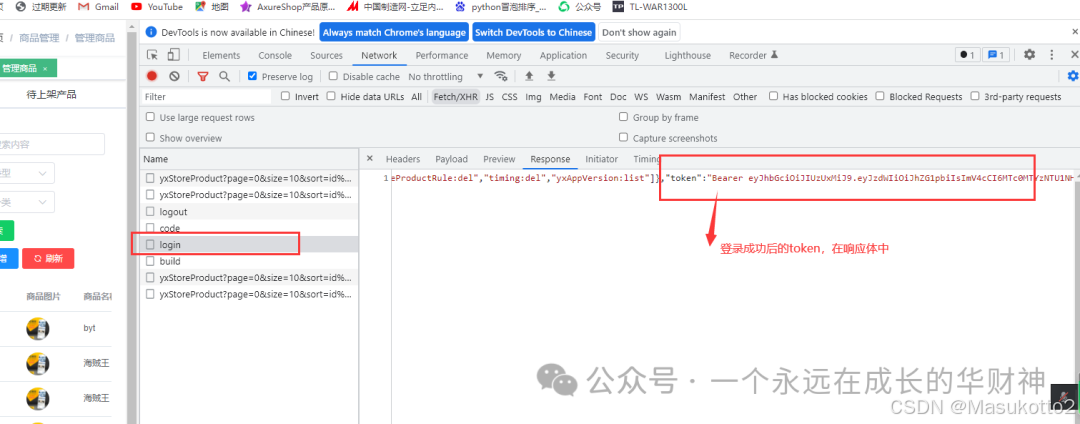

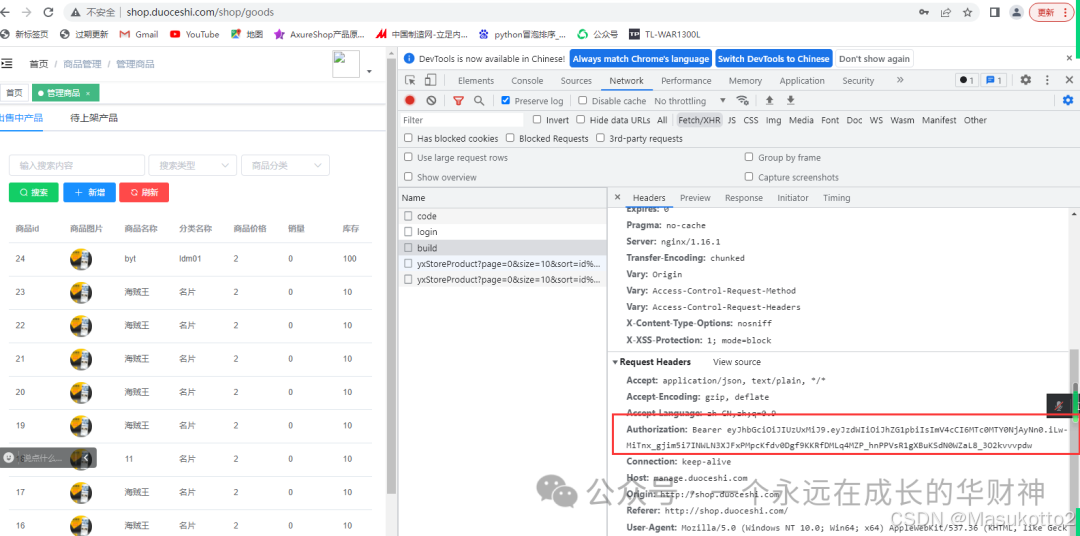
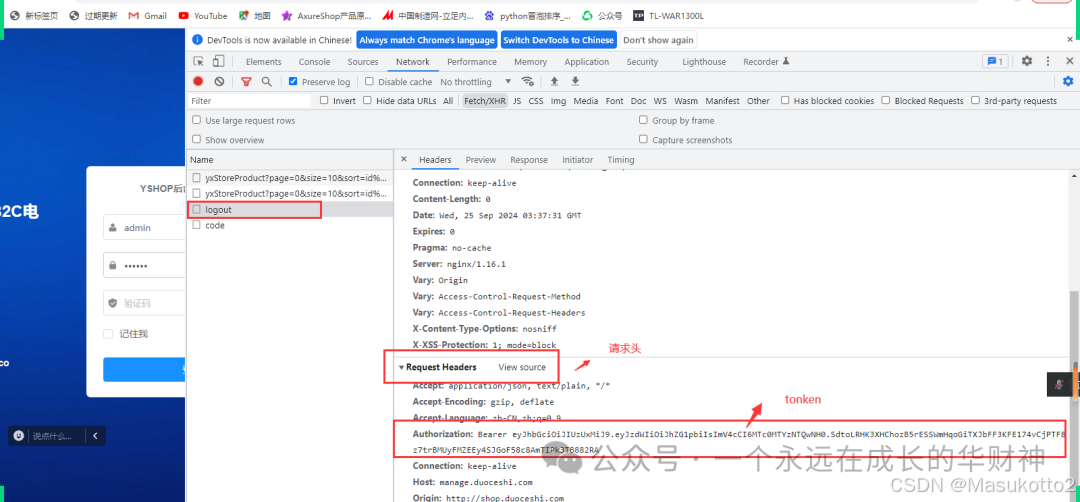
5.python+request+unittest分层测试自动化框架
十二、Jmeter
1.介绍与安装
Jmeter 是 java 语言开发的接口测试工具和一个性能测试工具。
特点:安装简单、安装包小、拓展性强、支持多线程、可以实现分布式负载。
2.实践操作
一、jmeter 界面
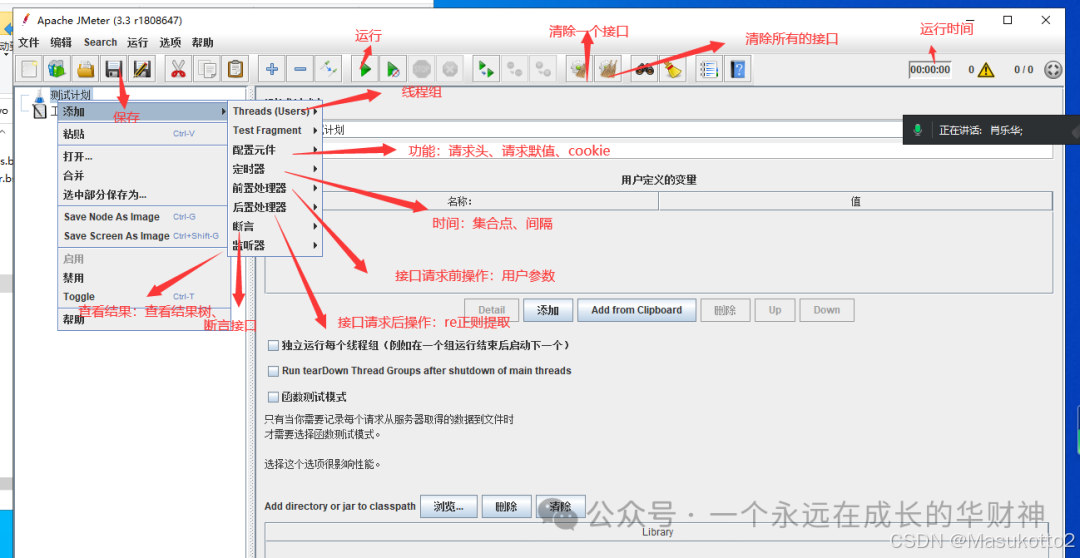
二、jmeret 操作接口
(一)、post接口
(1)添加线程组
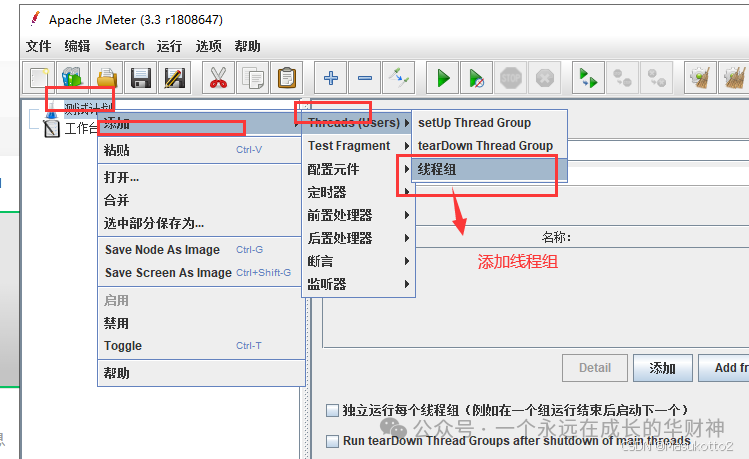
(2)添加http请求
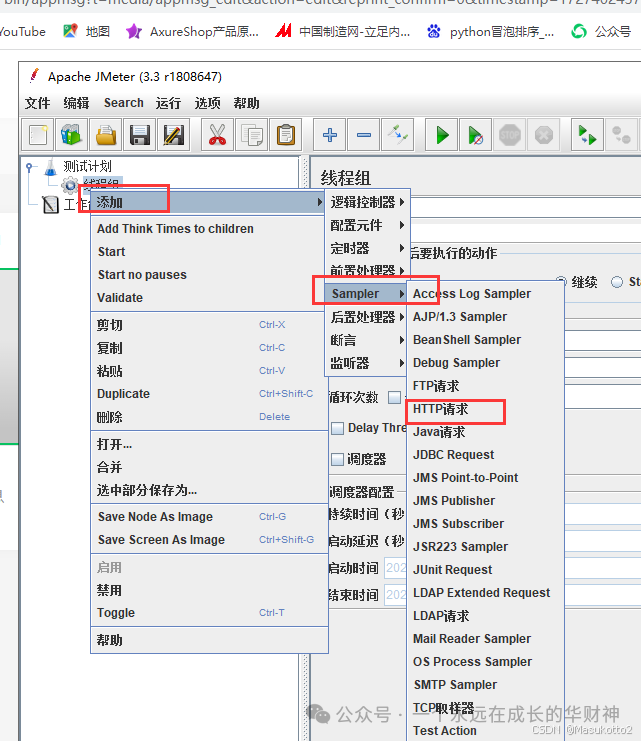
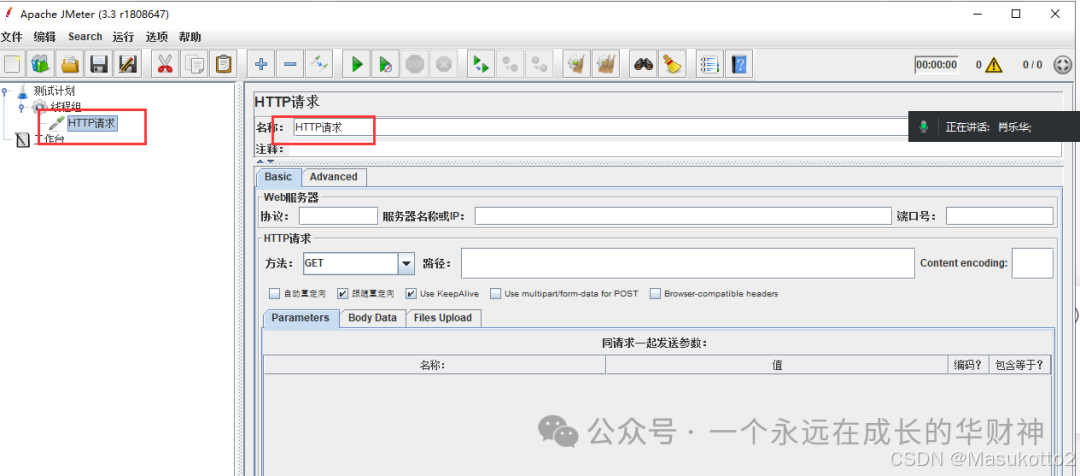
(3)编辑接口
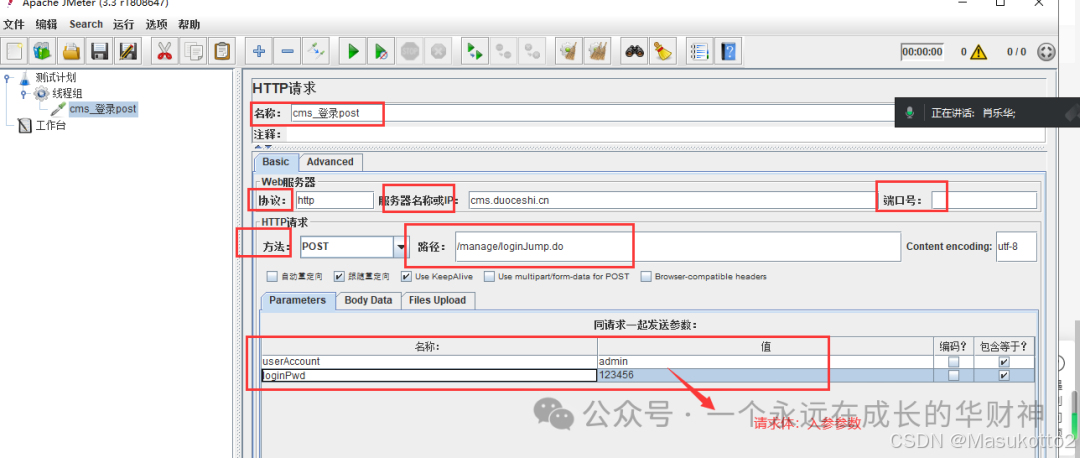
(4) 断言接口
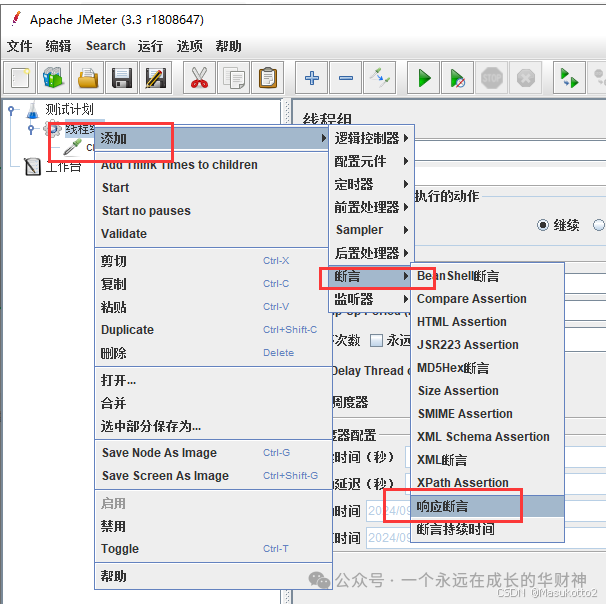
编辑断言内容
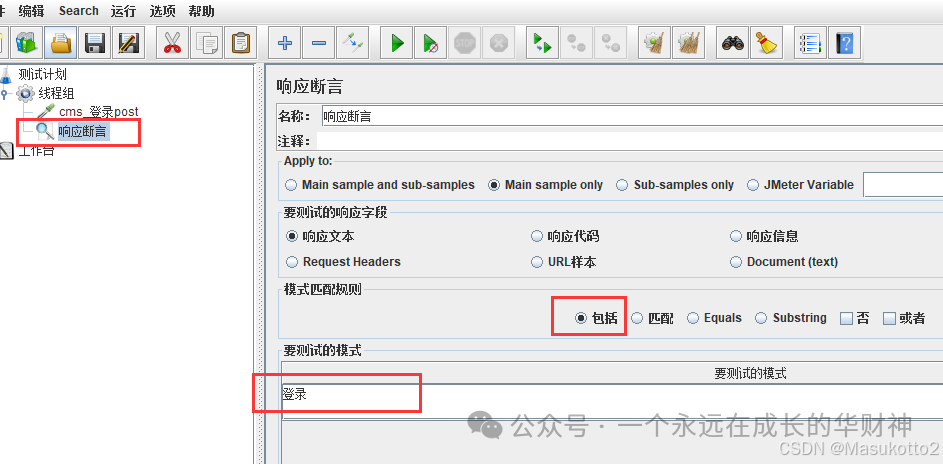
(5)查看结果树
在监听器
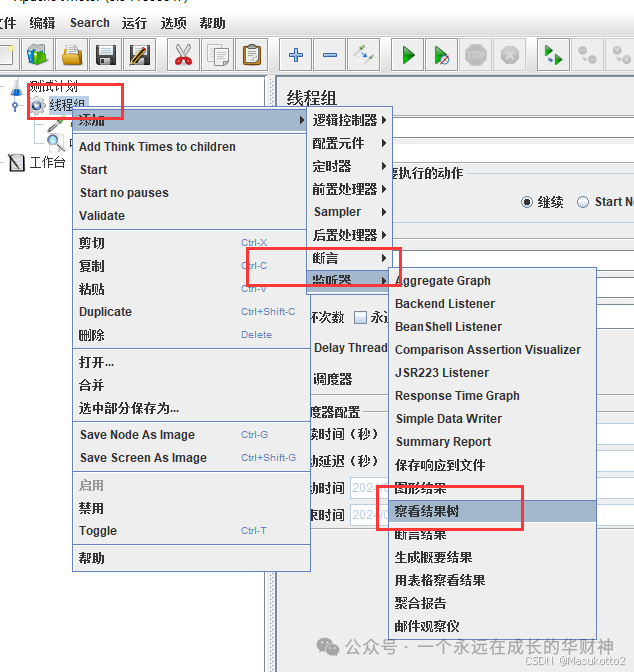
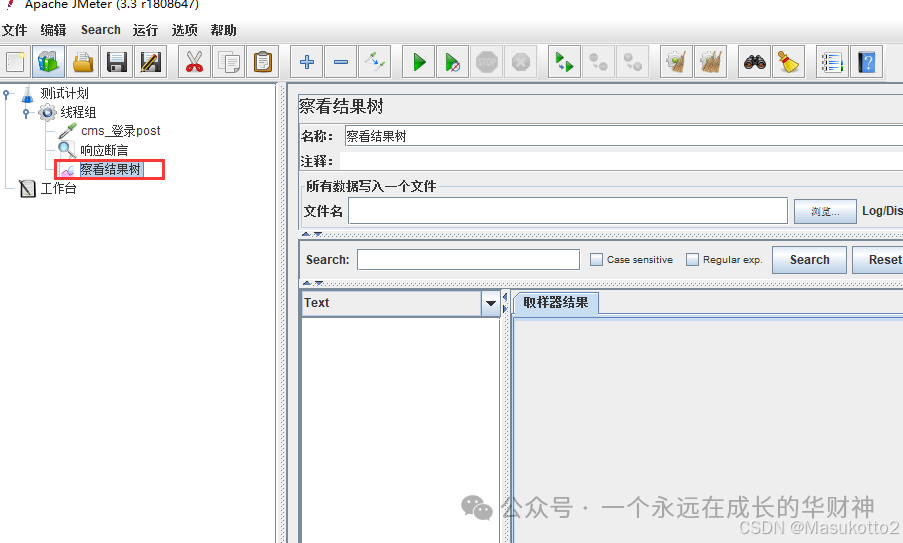
(6)保存接口
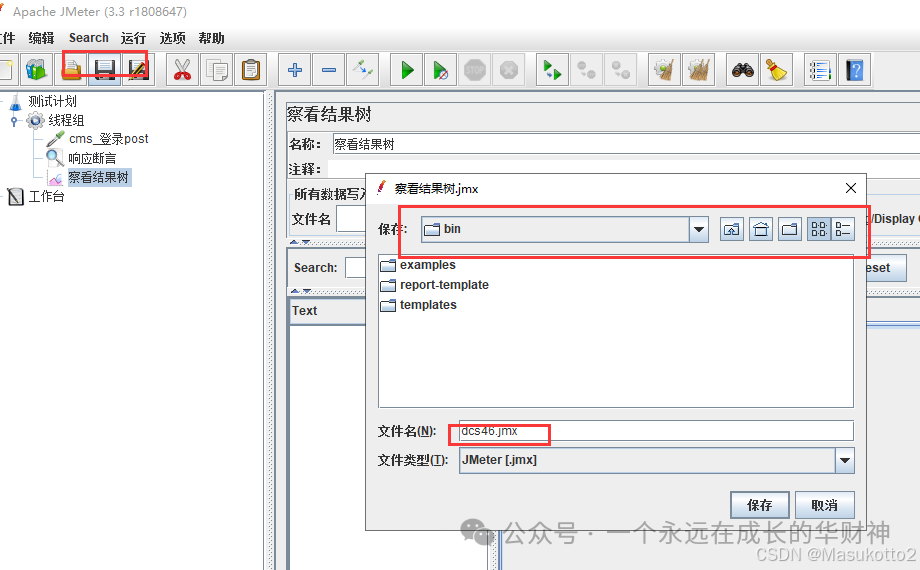
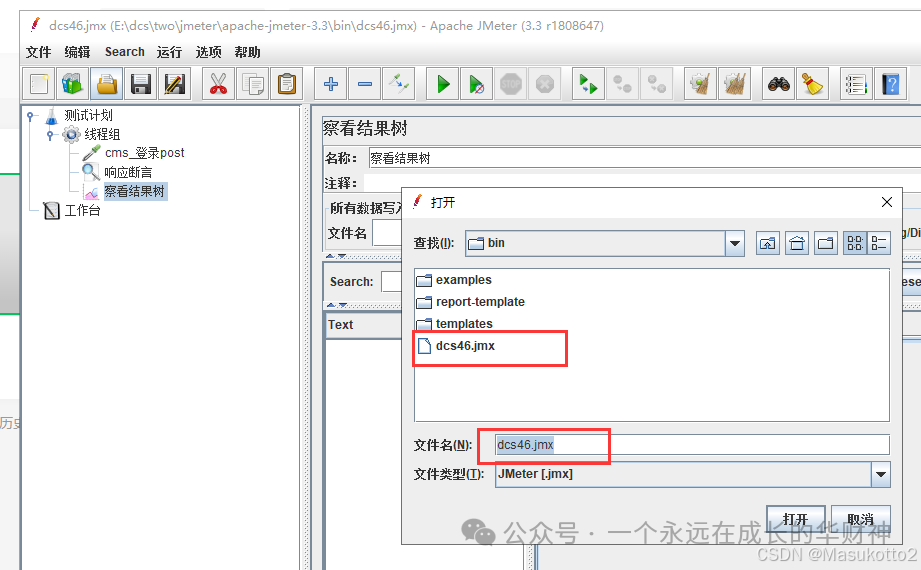
(7)运行接口
点击运行
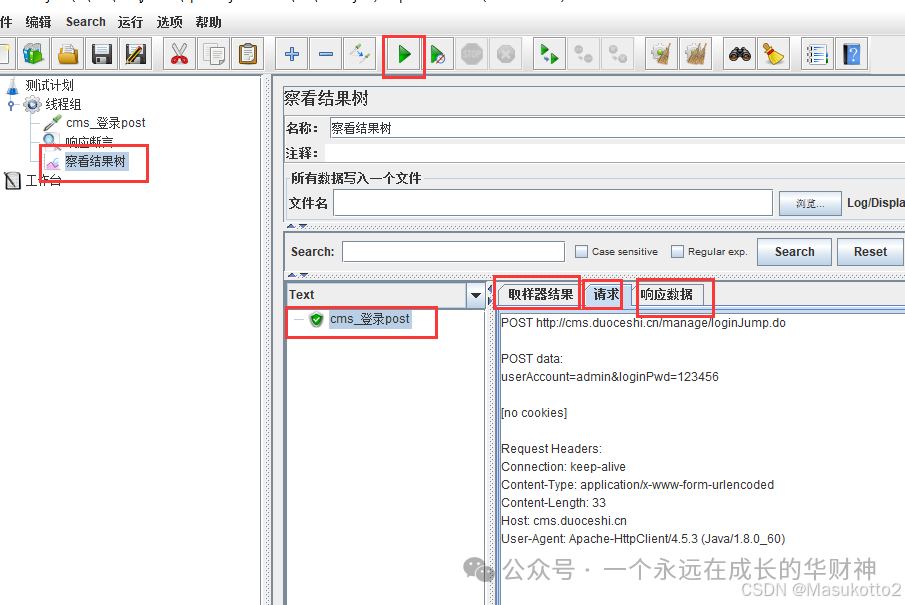
(二)get请求接口
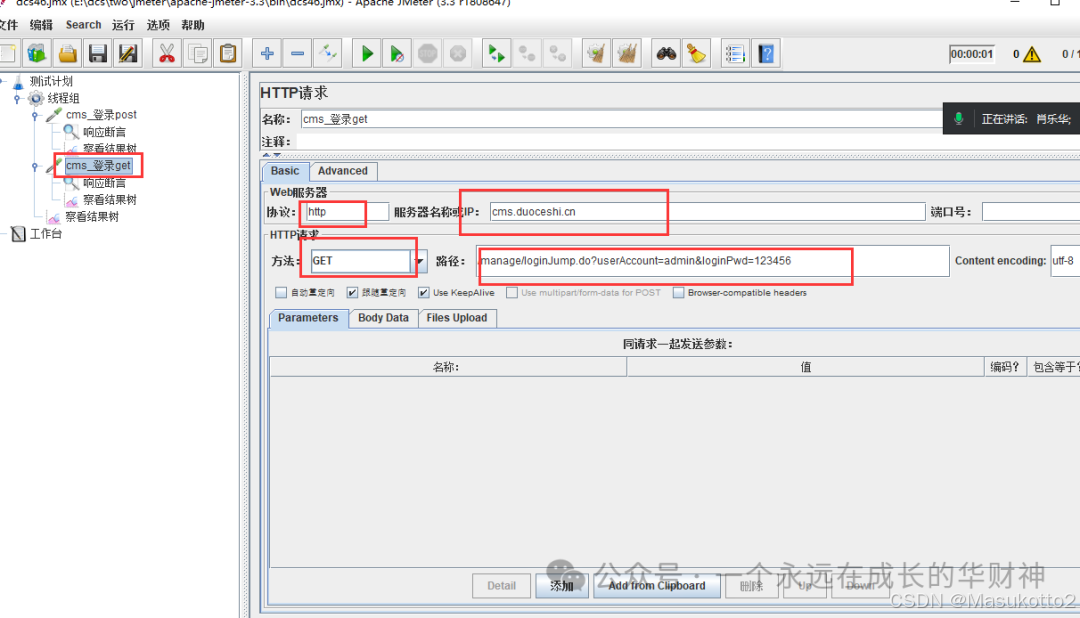
(三)请求默认值
在配置原件中,http默认值
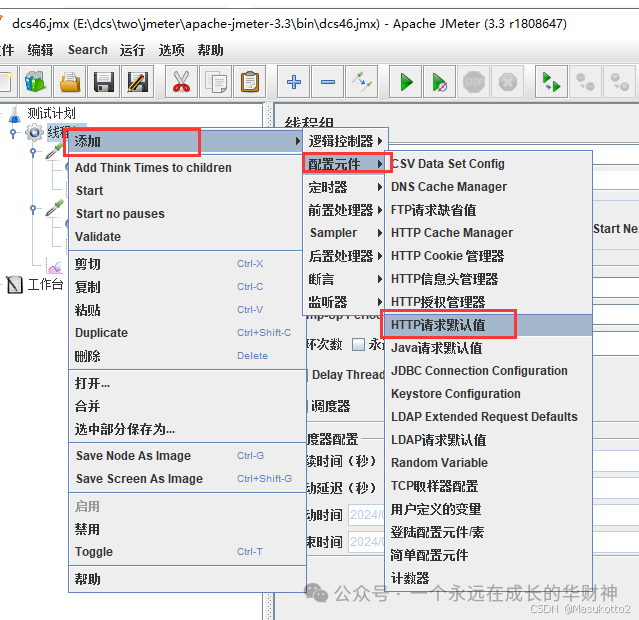
(四)依赖接口
http cookie 管理器 :用来保持会话
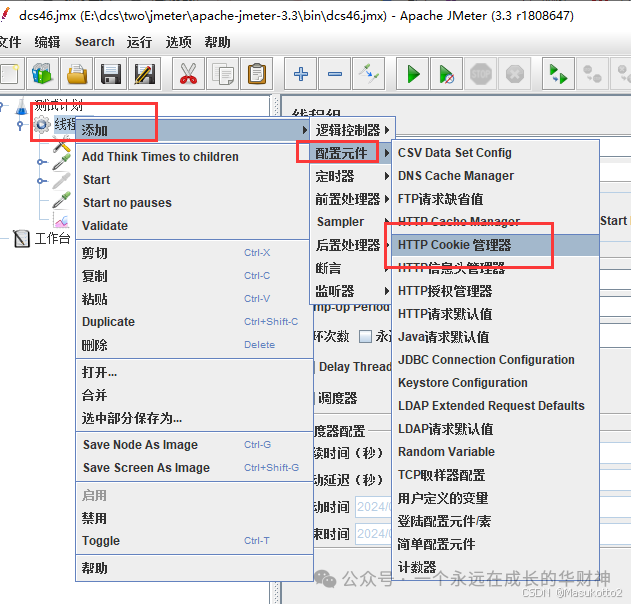
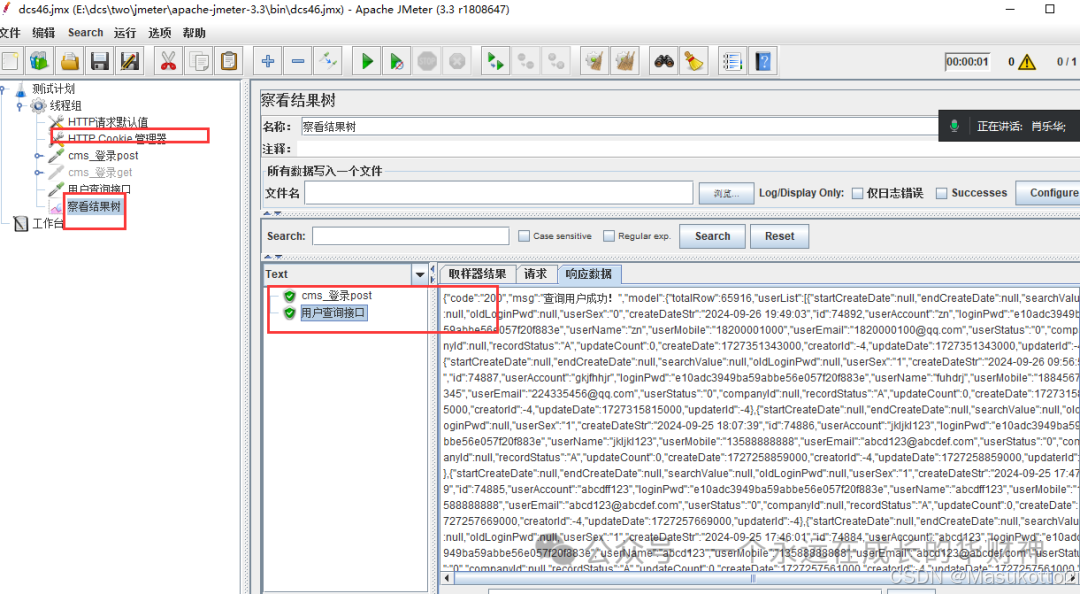
(五)jmeter中的参数化(用户参数实现)
键:值 ${变量}
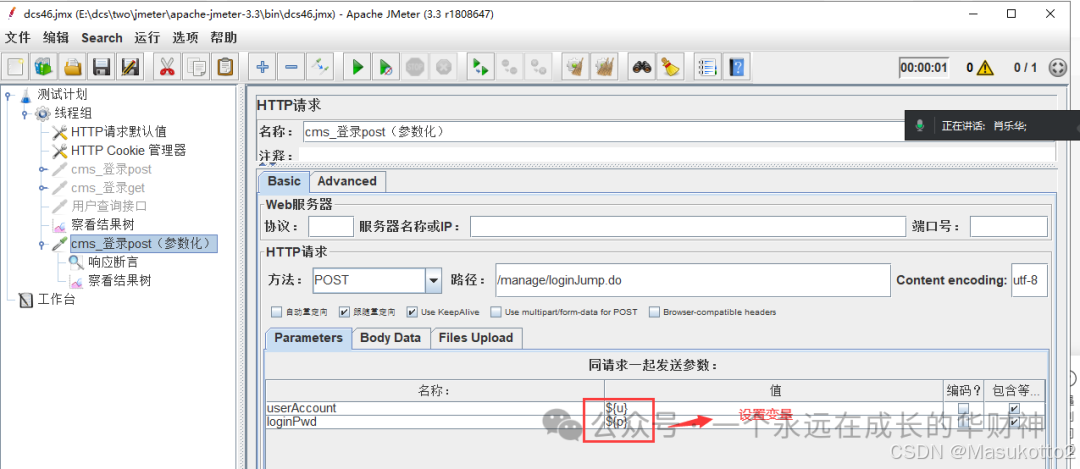
参数传递,通过前置处理器:用户参数
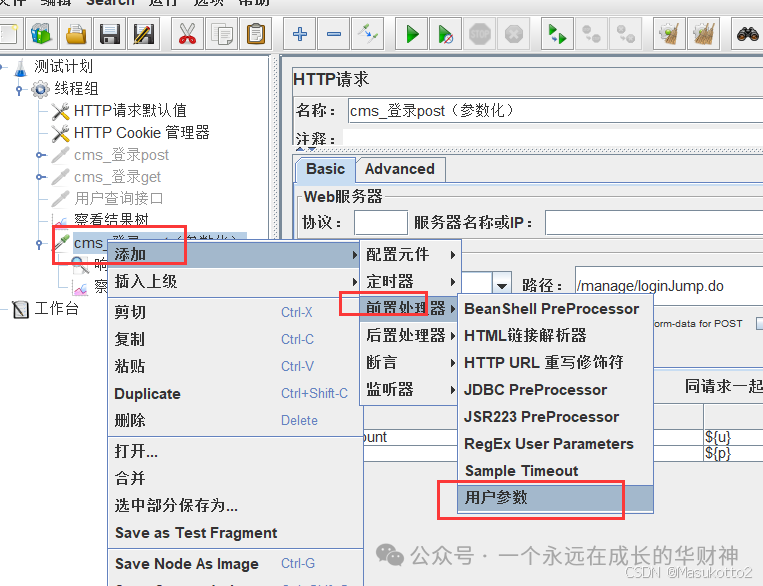
编辑用户参数
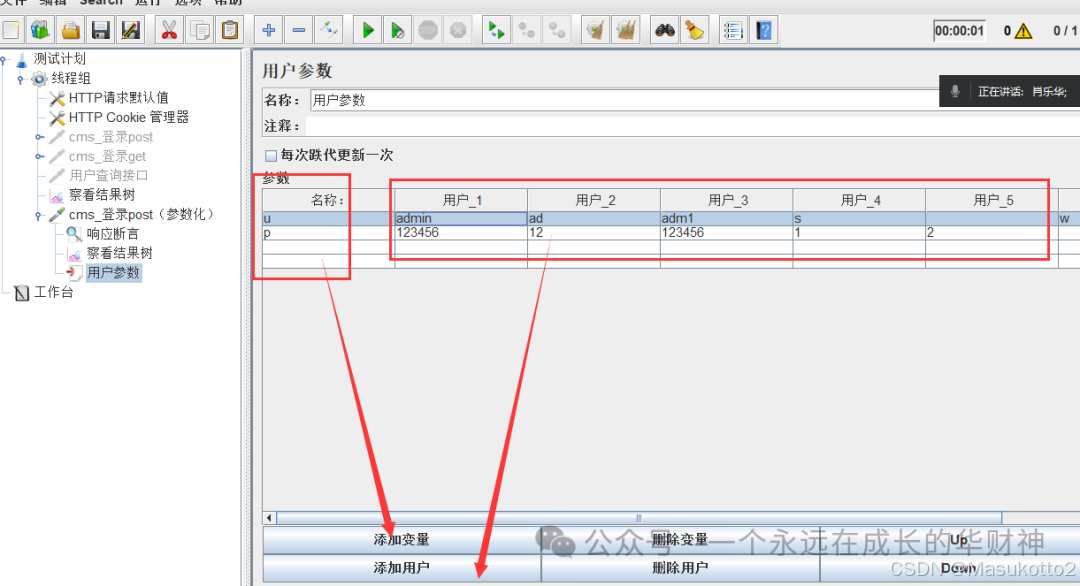
执行6个数据,执行6次
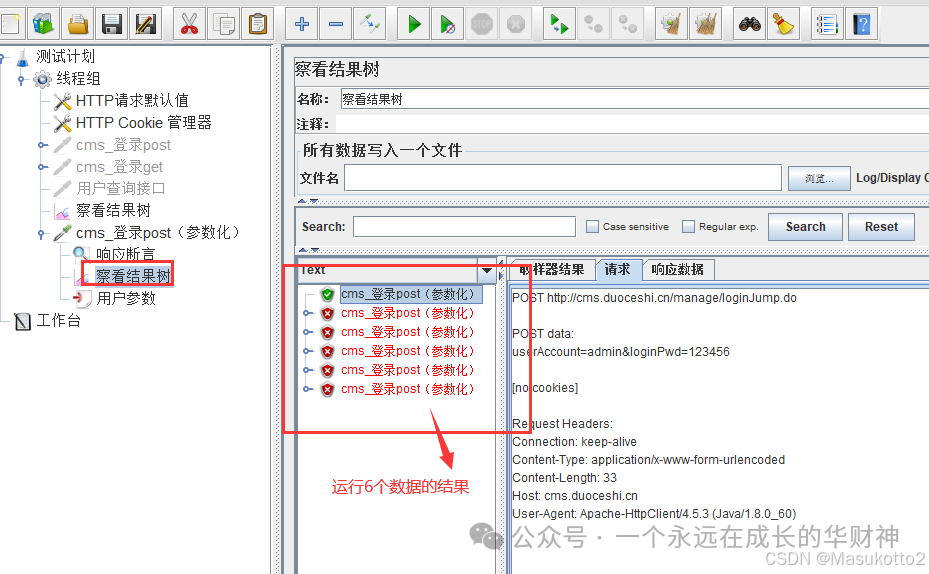
(六)通过txt文档来进行参数化
1、新建一个txt文档,编辑变量和用户
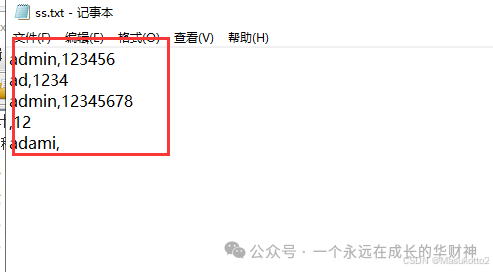
2、配置原件中添加csv data config 控件
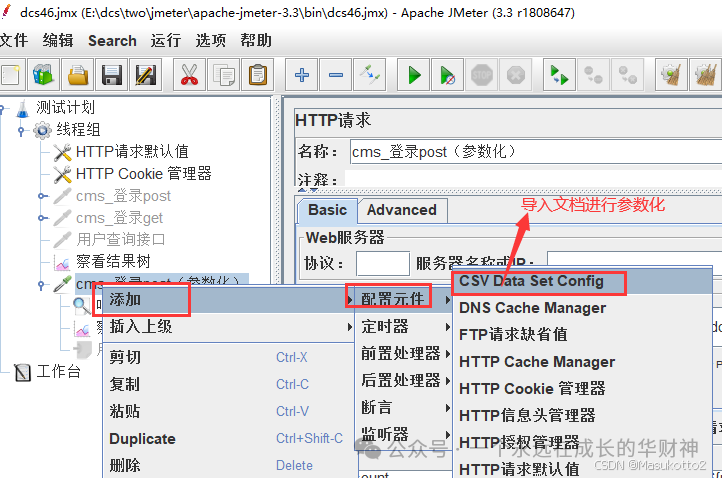
3、编辑csv data set config 内容
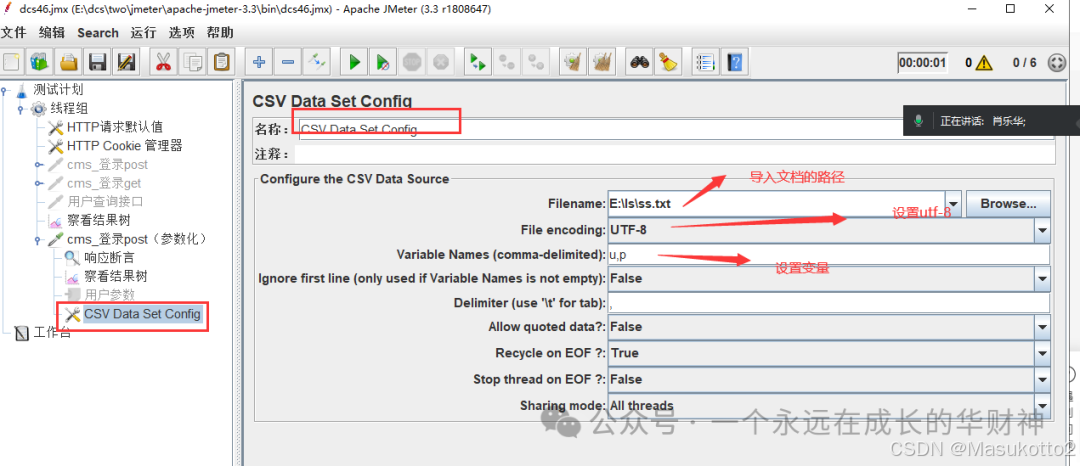
4、设置线程数,在测试计划中
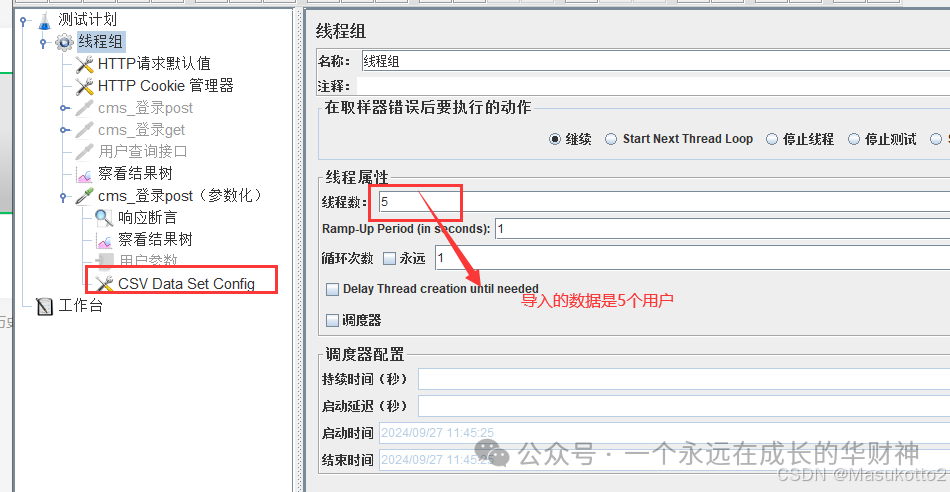
(7)关联接口
省份接口:http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportProvince
城市接口:
http://www.webxml.com.cn/WebServices/WeatherWebService.asmx/getSupportCity
byProvinceName
1、填写http默认值
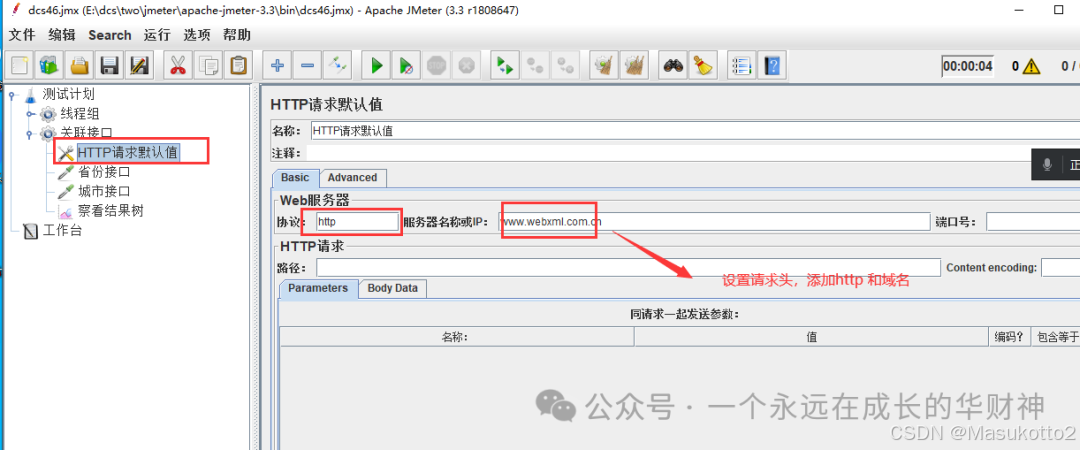
2、填写省份接口
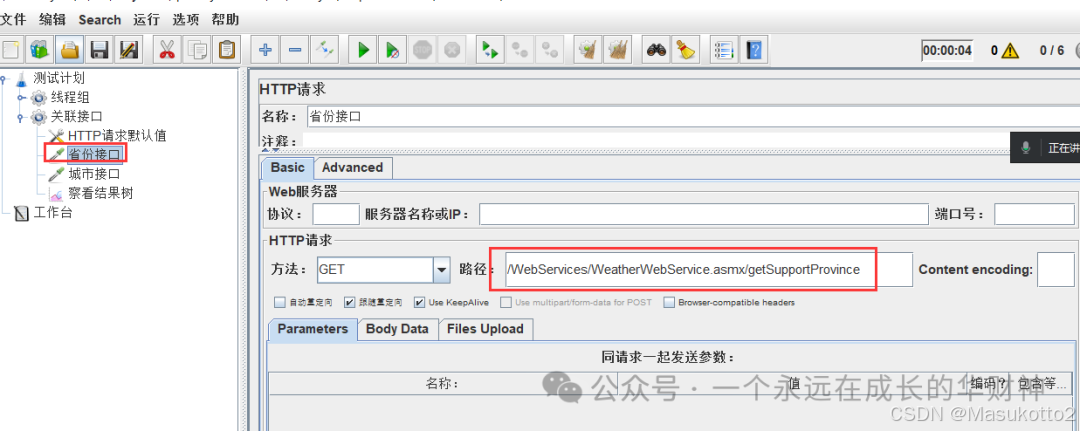
3、填写城市接口
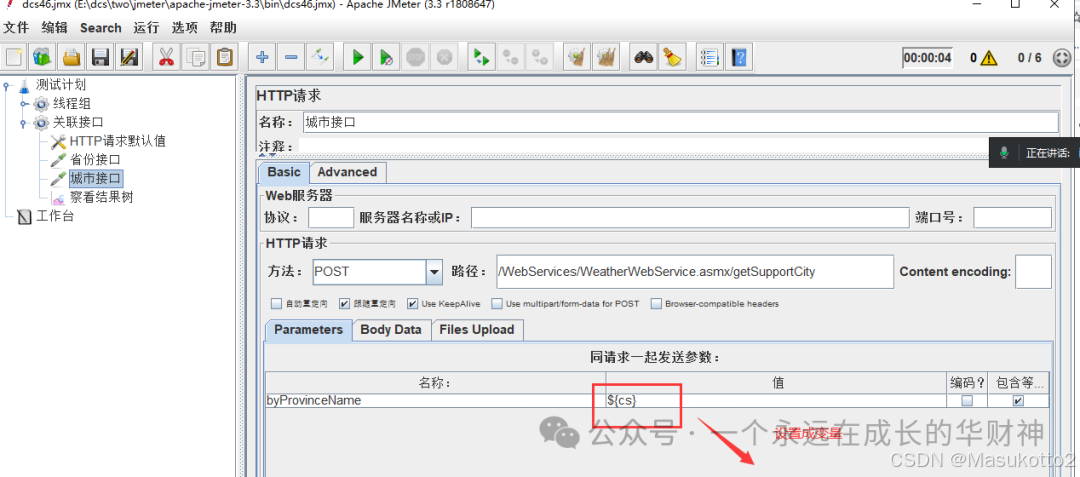
4、省份接口的提取:
正则表达式
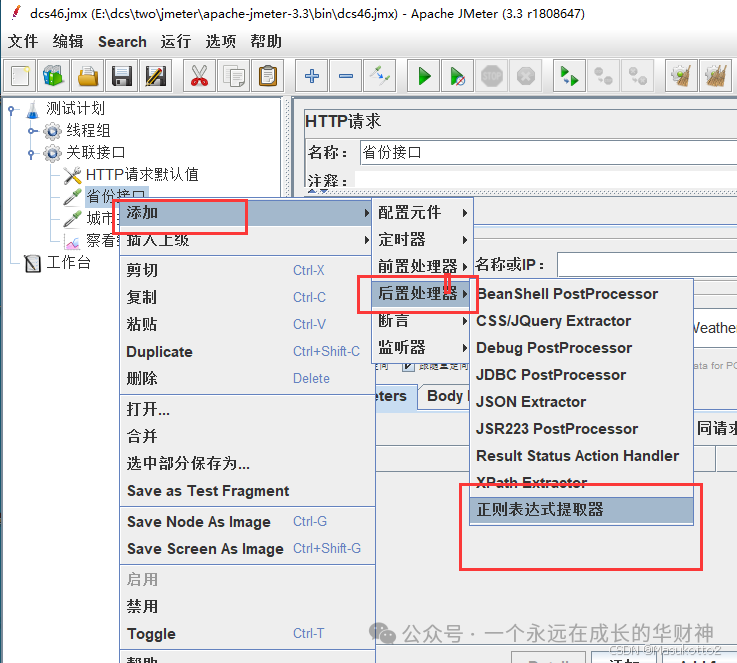
填写表达式:
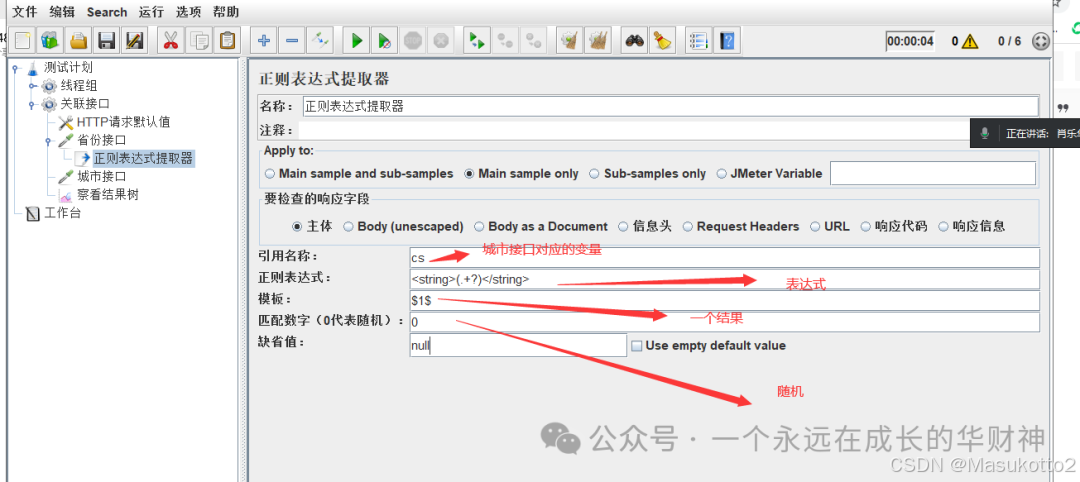
正则匹配:
1、引用名称(Name of created variable):
Jmeter变量的名称,存储提取的结果;即下个请求需要引用的值、字段、变量名,后文中引用方法是$
2、正则表达式(Regular Expression):
使用正则表达式解析响应结果,()括号表示提取字符串中的部分值,前后是提取的边界内容。
3、模板(Template):正则表达式的提取模式。
如果正则表达式有多个提取结果,则结果是数组形式,模板1 11,2 22等等,表示把解析到的第几个值赋给变量;从1开始匹配,以此类推。
若只有一个结果,则只能是1 11;
4、匹配数字(Match No):
正则表达式匹配数据的结果可以看做一个数组,表示如何取值:0代表随机取值,正数n则表示取第n个值(比如1代表取第一个值),负数则表示提取所有符合条件的值。
5、缺省值:
匹配失败时候的默认值;通常用于后续的逻辑判断,一般通常为特定含义的英文大写组合,比如:ERROR等。
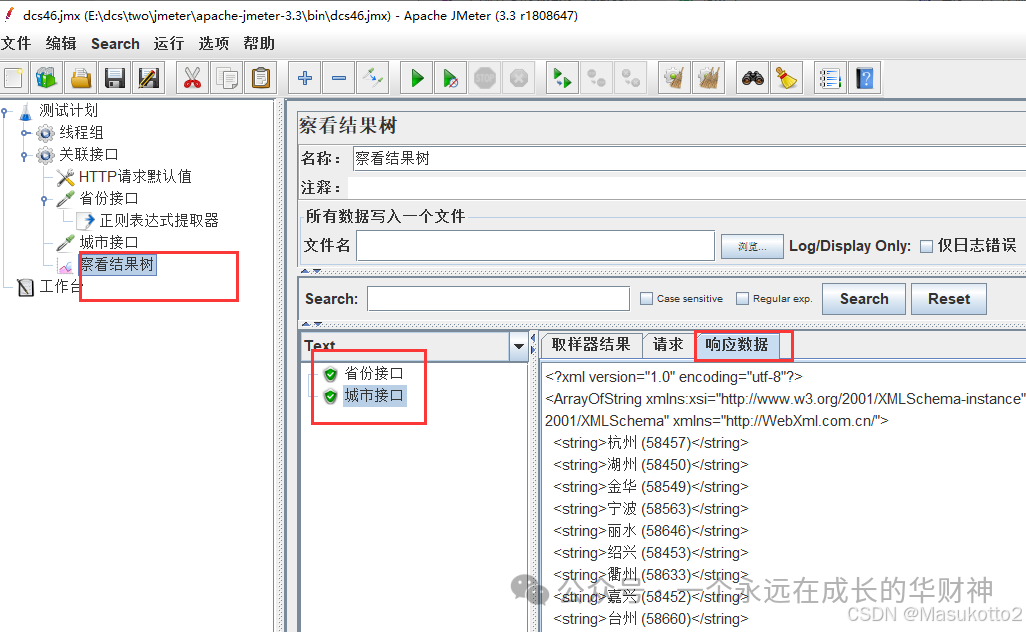


















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









