







在使用ELK做数据分析时,比不可少的要使用logstash的数据筛选过滤功能对用于数据挖掘的数据集合做一些统一的预处理。
logstash是用Java语言来实现的,因此要借助jvm来运行,此时处理的数据量过大,就会造成java.lang.OutOfMemoryError: Java heap space这样的错误,上面的报错是每个Java程序员再熟悉不过的了。
笔者近期做的一个需求是,从rabbitMQ中获取json数据,提取json数据中的某个jsonArray数组,将其拆分成多个jsonObject存入eleastic search库中。在用filter 过滤的时候,由于jsonArray数组过长,信息量过大导致堆内存溢出,报错截图如下:
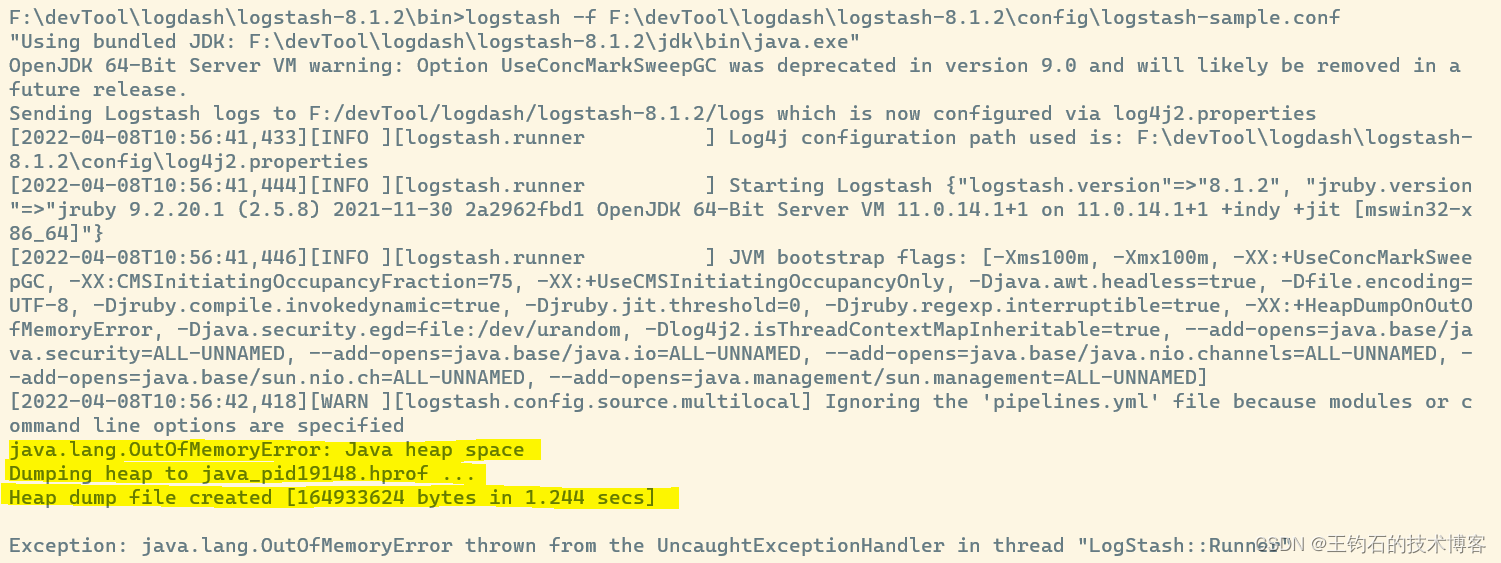
此时,在排除了程序错误的情况下,我们的解决方案是扩大logstash运行的jvm内存空间。
进入logstash的安装目录:
(我的Logstash版本是8.1.2,其他版本文件夹的目录结构可能略有不同,大家可根据目录的含义自行寻找)
找到config目录,这个目录是放置配置文件的
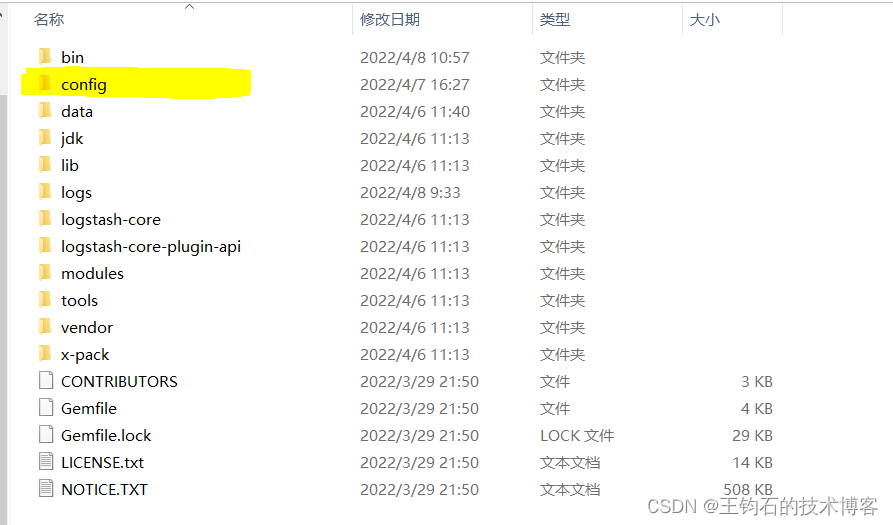
进入后:打开jvm.options这个文件,这个文件主要配置了logstash运行时jvm的一些基本参数
可以使用vscode打开这个文件,找到虚拟机配置
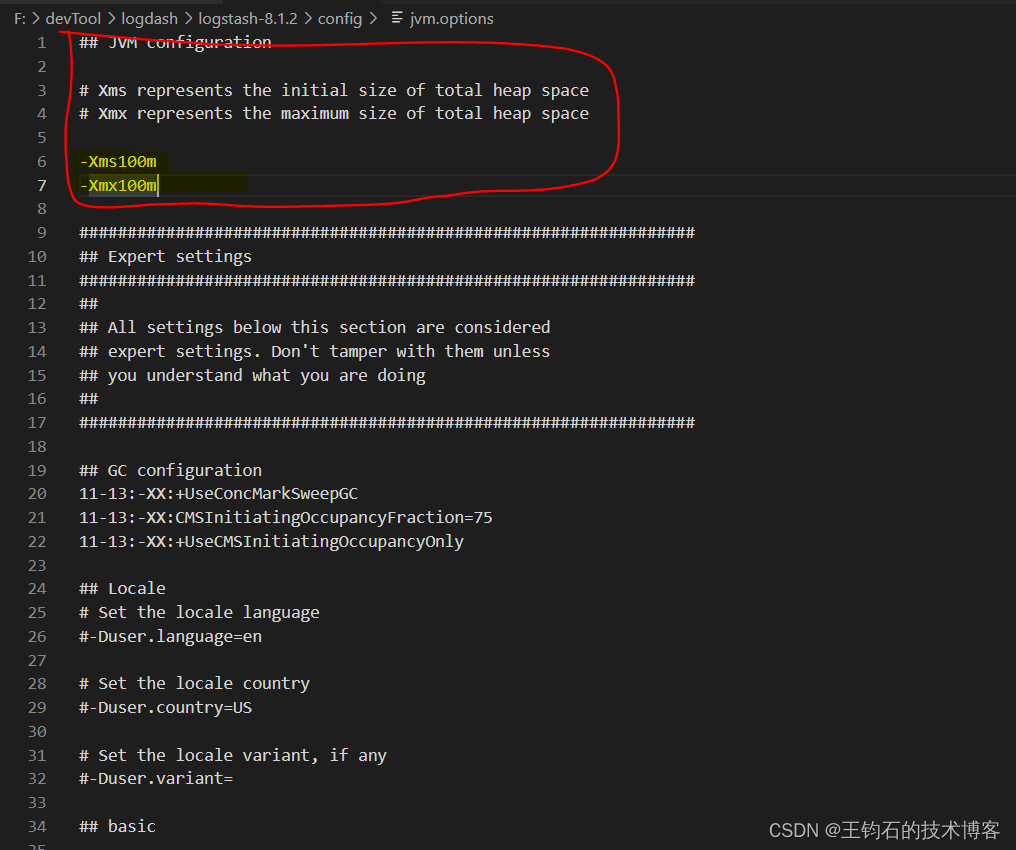
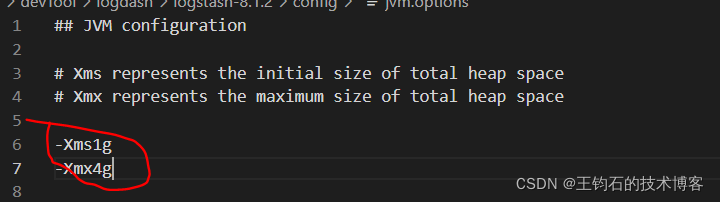
可以看到现在给jvm分配的内存大小只有100m,我们将初始运行内存-Xms改成1g,将最大运行内存-Xmx改成4g
此时重启logstash看下效果:

此时logstash已经正常运行


















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包










