







前几天接到了这样一个需求,用logstash从rabbitMq中读取json数据,并根据数据id来统计收到的数据数量,最终将统计结果输出到控制台。在网上找了一些资料,同时结合logstash官方文档最终实现了这个小需求。
logstash.conf 文件
input {
rabbitmq {
host => "0.0.0.0" #RabbitMQ-IP地址
vhost => "/command" #虚拟主机
port => 5672 #端口号
user => "admin" #用户名
password => "admin" #密码
exchange => "logstash.test"
exchange_type => "fanout"
exclusive => "true"
codec => "json"
tags => "logstash.test"
}
filter {
#统计数据个数
if "logstash.test" in [tags] {
aggregate {
task_id => "%{game_id}"
code => "map['data_count'] ||=0; map['data_count'] += 1"
push_map_as_event_on_timeout => true
timeout_task_id_field => "task_id"
timeout => 300 # 单位秒,5分钟后,不论是否还有数据,均触发超时
inactivity_timeout => 3 # 单位秒,如果3秒钟未接收到数据,则触发超时
timeout_tags => ['red_obs_aggregatetimeout']
timeout_code => "event.set('hasData', event.get('data_count') > 1)"
}
}
}
output {
if "red_obs_aggregatetimeout" in [tags]{
stdout {
codec => rubydebug{
}
}
}
}
最终控制台的统计结果:
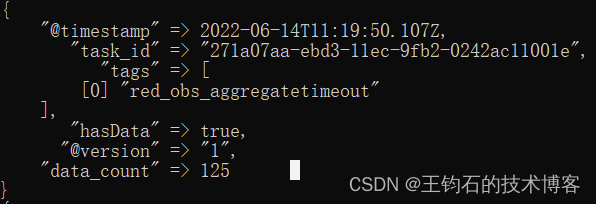
datacout就是最终的统计结果,数据有125条
最后注意上面的几点:
1.logstash 的 aggregate{}(聚合统计)插件,触发超时之后,就结束统计返回统计结果。因此一定要设置好超时时间。
2.控制台的rubydebug{}模式,不仅仅会打印统计结果,还会打印每次传输过来的数据,如果只想查看统计结果,可参照案例中的
timeout_tags => [‘red_obs_aggregatetimeout’]
来限制打印的结果。
3.设置task_id时,用了game_id,这是因为输入的每条json数据中都有game_id字段作为类别标识。相同game_id的数据会累加计数,aggregate{}函数会根据这个标识来统计数量。
关于更多的logstash的用法请参照官网:
https://www.elastic.co/cn/logstash/
本文案例中aggregate{}函数用法:
https://www.elastic.co/guide/en/logstash/current/plugins-filters-aggregate.html
















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











