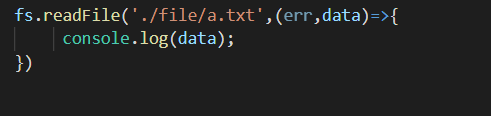
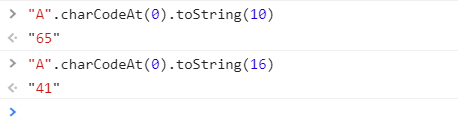
前言 前几天用nodejs去读取文件的时候发现了个问题, 文件是txt,内容是: node代码: 打印出来的data readFile不指定编码的话,返回的数据是Buffer类型。 41,42,43对应的应该是A,B,C. e8 b5 b5对应的应该是中文赵。 可是,当我打断点再看data的时候,发现变了。 什么鬼?到底data里面存的字面A是41,还是65, A的Unicode10进制是65,16进制是41.继续打印data[0] 发现是65.所以为什么之前打印Buffer会是41呢??现在也没搞明白。有大神能告知吗?但是肯定的是Buffer中存的数字是10进制。




























 8973
8973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








