









文章目录
Abstract
这篇论文是一篇关于NVMe设备服务质量(QoS)的综述研究,主要探讨了在多用户共享NVMe固态硬盘(SSD)时,如何同时实现高性能(高吞吐量、低延迟)、公平性、隔离性和可预测性。尽管现代NVMe设备能够提供极高的性能,但由于其复杂的内部逻辑(如垃圾回收、磨损均衡等),在多用户场景下,设备的行为难以预测,性能也容易受到干扰。论文通过分析存储堆栈的各个层面(包括设备控制器、操作系统块层、虚拟化和容器环境),总结了当前的挑战和解决方案,并提出了未来的研究方向。
一、Introduction
固态硬盘(SSD)是现代服务器、桌面和移动应用中流行的存储方式。与传统机械硬盘(HDD)相比,它们的吞吐量高出几个数量级,延迟更低。现代SSD的延迟可以低至10微秒,吞吐量可达每秒100万次I/O操作。近年来,主机接口和存储堆栈被重新设计,以更好地利用SSD的能力,例如blk-mq和NVMe。然而,提供高性能并非没有挑战。首先,SSD配备了复杂的闪存控制器,必须执行诸如垃圾回收、磨损均衡和地址转换等任务。这些任务的开销往往会干扰主机的请求,导致服务质量(QoS)问题,例如行为不可预测、吞吐量降低和高尾延迟。其次,当多个用户共享一个设备时,每个用户的性能可预测性进一步降低。正如我们将在本综述中探讨的,设计能够提供用户间公平性而不影响性能的SSD控制器和软件堆栈是一个巨大的挑战。可预测的性能和公平性在许多应用中是可取的。数据库系统希望保证每秒最低查询次数,或者虚拟化管理程序保证所有虚拟机的最低带宽。这样的保证也被称为服务质量(QoS)。本综述的目标是探讨NVMe设备上的QoS挑战和解决方案。在本综述中,我们定义QoS如下目标:
- G1 公平性:设备应该公平共享,即所有用户都应该获得按比例分配的吞吐量和延迟。
- G2 隔离性:每个用户的性能应该是隔离的。一个用户不应该能够降低其他用户的吞吐量或导致延迟激增。
- G3 可预测性:在单用户和多用户设置中,延迟和吞吐量应该是稳定的,不可预测的峰值是不可取的。
- G4 性能:应该能够充分利用设备,即用户获得的总吞吐量应接近设备的能力。
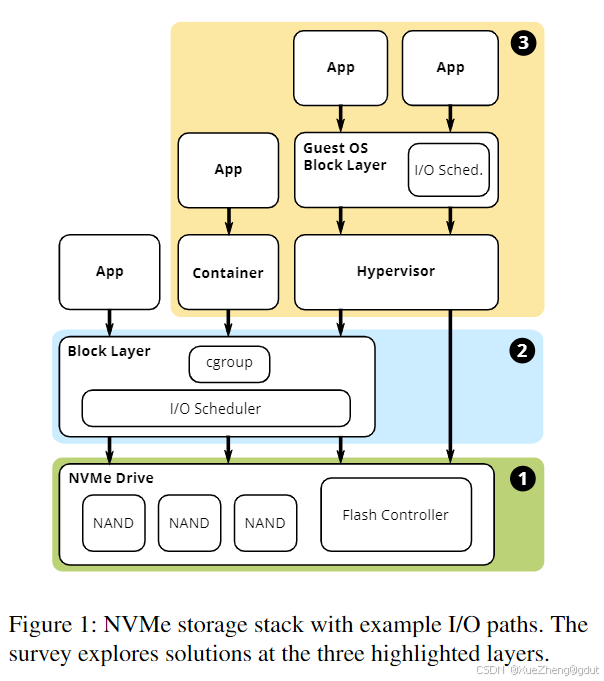
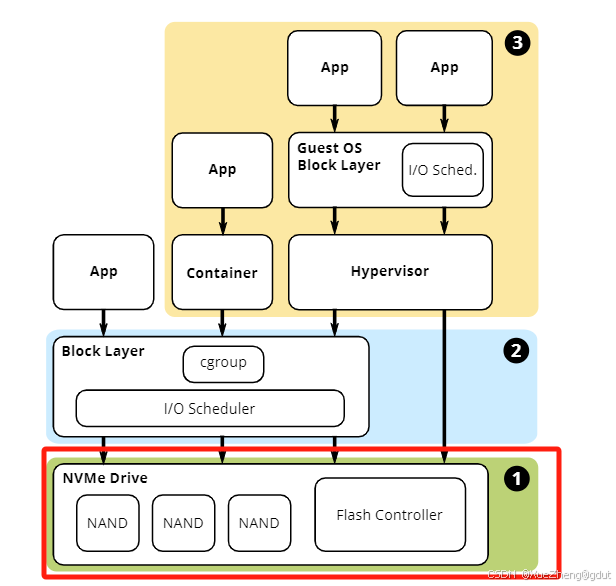
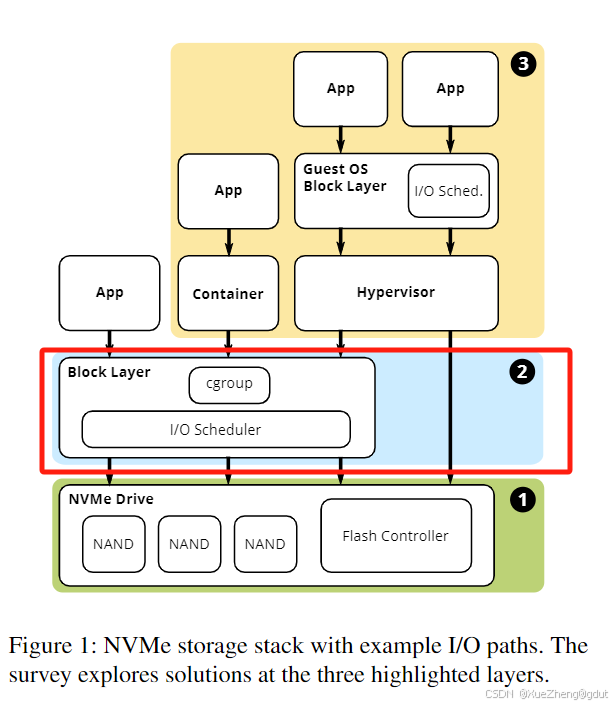
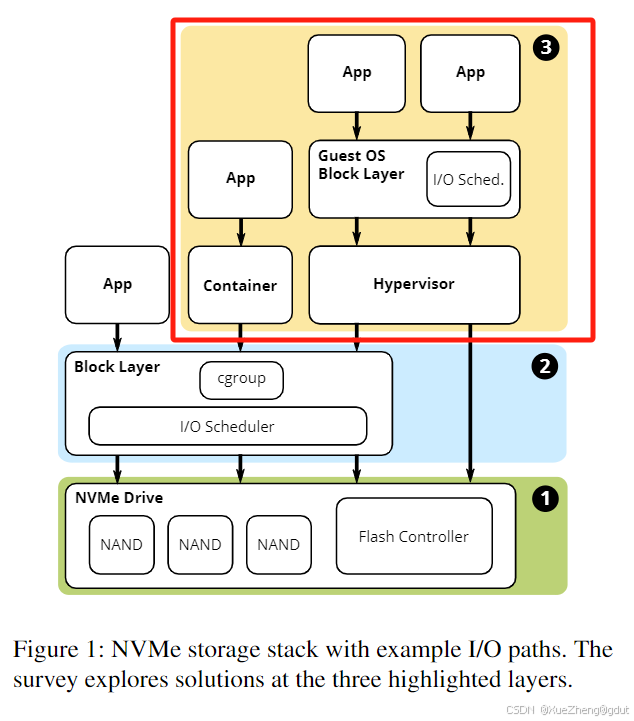
图1展示了应用I/O可能经过的路径。在最简单的情况下,应用作为操作系统进程运行,操作系统I/O调度器可以提供QoS。运行在容器中的应用可以利用cgroup策略实现QoS,最后,一些虚拟化管理程序绕过了主机块层,客户操作系统可能运行自己的调度器。在所有场景中,设备端的闪存控制器也可以做出QoS决策。
二、Survey设计
正如引言中提到的,本综述的目标是调查在NVMe设备上为多个用户共享时提供服务质量(QoS)保证的挑战。主要的调查问题是:在现代SSD上为多个应用提供公平性和可靠性能的挑战是什么? 为了帮助我们理解这一更大问题的各个方面,我们还提出了以下子问题:
- RQ1:I/O调度器如何在保持SSD峰值吞吐量的同时提供其他QoS保证?
- RQ2:导致SSD性能下降的原因是什么,如何防止这些问题?
- RQ3:在基于SSD的虚拟化和容器环境中,哪些因素限制了QoS?
- RQ4:如何探索SSD和块层的设计空间,以实现QoS的改进?
在本综述中,我们专注于特定于NVMe设备的工作。除非我们认为是重要的背景知识,否则不包括针对HDD或一般调度的研究。也有大量关于改进SSD控制器设计的研究,但除非对理解QoS方面有贡献,否则我们不包括在内。为了被纳入,论文必须满足以下所有纳入标准:
- I1:论文探讨了我们定义的一个或多个QoS目标。
- I2:论文提出了I/O调度器、SSD控制器或其他存储堆栈组件的新设计,或研究了现有解决方案的QoS属性。
- I3:论文专门针对NVMe设备。
- I4:论文是2010年或之后发表的,以限制我们工作的时效性。
我们使用几种方法来查找纳入综述的论文。我们首先从几篇种子论文开始,并使用滚雪球方法(Snowball methodology)通过查看双向引用找到相关论文。种子论文如表1所示。我们还查看了几个涵盖存储相关主题的会议论文,并寻找满足纳入标准的论文。考虑的会议包括FAST、HotStorage、USENIX ATC、SYSTOR、ODSI和EuroSys。我们查看了2018年至2023年间的全部会议论文,并寻找相关论文。最后,我们使用几个相关关键词进行手动搜索。
三、Background
3.1 HDD
硬盘驱动器(HDD)数十年来一直是主要的存储类型。因此,操作系统、文件系统和应用程序的设计在很大程度上基于它们的特性。硬盘由一个或多个旋转盘片组成,每个盘片有多个磁道,每个磁道有多个扇区(通常为512字节)。在读取/写入操作中,机械磁头移动到包含扇区的磁道上,这一过程称为寻道时间。然后,磁头等待扇区旋转到磁头下方,这一过程称为旋转延迟。HDD的性能受到盘片旋转速度的限制,通常在每分钟7200到15000转之间。I/O操作的延迟大约在1到20毫秒之间,顺序吞吐量大约为50,000 IOPS,随机吞吐量大约为250 IOPS。寻道的高成本使得随机操作非常不利。HDD仍在不断进步,但主要是在容量方面,吞吐量增长缓慢,而延迟在过去几十年中几乎停滞不前。这些特性促使系统和应用程序开发人员努力最小化I/O操作,并尽可能使操作顺序化。例如,操作系统I/O调度器会通过电梯算法合并和重新排序操作,这将在3.5节中解释。

3.2 NVM驱动器的出现
非易失性存储器(NVM)是一种半导体存储器,即使在断电后也能保留数据。一种流行的NVM类型是NAND闪存,自20世纪80年代以来一直存在,但由于其价格和容量无法与HDD竞争,直到最近才变得流行起来。固态硬盘(SSD)通常由NAND闪存芯片和控制器组成。
SSD的内部结构(SSD Internals)
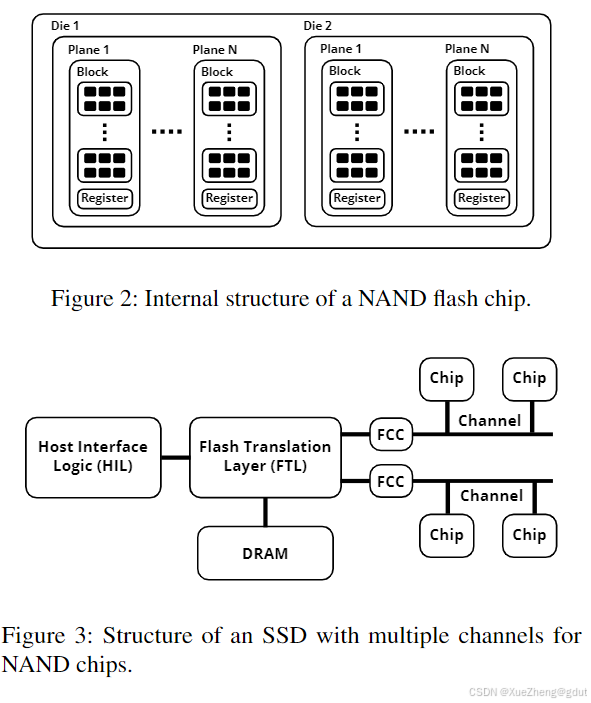
NAND闪存芯片包含一个或多个芯片,每个芯片包含多个平面(见图2)。每个平面包含多个块,每个块包含多个页面,页面大小通常为4 KB。读操作以页面为单位进行,可以访问芯片中的任何页面。写操作也以页面为单位进行,但只能写入已擦除的页面。擦除操作以块为单位进行,会将块中的所有页面清零。芯片的典型性能指标包括:读取时间为25微秒,写入时间为200微秒,擦除时间为1.5毫秒,擦除周期为10万次。闪存芯片通过数据线传输数据,并通过控制线发送命令。数据传输时间可能低于操作时间,因此可以在不同平面上交错执行多个操作。然而,交错操作必须在不同的平面上进行。SSD由多个闪存芯片和一个控制器组成,控制器用于管理数据映射和主机接口逻辑。多个闪存芯片可以共享数据线,这种单位称为通道(见图3)。NAND闪存的一个主要限制是块必须被擦除才能写入页面。主机暴露的块接口允许在任何地址进行写入操作,但为了提高写入效率,闪存转换层(FTL)会在逻辑块地址(LBA)和设备内部的物理块地址之间进行映射。当写入操作到达时,设备会选择一个空闲页面并更新映射表。然而,这意味着写入操作不会在原位置进行,旧页面会变成“僵尸”页面,需要进行垃圾回收。选择空闲页面时,还应尽量提高设备的并行性和磨损均衡,即确保设备各部分均匀老化。

垃圾回收(Garbage Collection)
当同一个逻辑块地址(LBA)被多次写入时,写入操作不会在原位置进行,旧数据所在的页面被称为“僵尸”页面,因为它们不再被任何映射指向。为了回收这些空间,需要进行垃圾回收。垃圾回收器会将一个块中的所有活动页面复制到一个新的块中,然后擦除旧块。设计高效的SSD垃圾回收器一直是研究的重点。例如,简单的垃圾回收器可能在活动页面与僵尸页面的比例(称为清理效率)达到阈值时触发。垃圾回收是昂贵的,因为它包括擦除操作和多次读写操作。根据控制器设计,垃圾回收可能会阻塞平面、芯片或整个设备的其他操作。因为垃圾回收会阻塞主机的请求,这可能导致应用程序出现高尾延迟和不可预测的性能。某些闪存芯片支持在同一平面内复制数据。如果垃圾回收选择在同一平面内的新块,数据不会跨通道传输,这可以提高性能。主机发出的写入操作与垃圾回收操作的写入放大因子(WAF)之比称为写入放大因子,较低的值表示更高效的使用。

数据放置(Data Placement)
单个闪存芯片的带宽有限,因此必须充分利用所有通道的并行性才能获得良好的性能。映射策略决定了操作如何在通道之间分配。实践中最常用的两种策略是:(i)基于LBA的映射,将LBA在通道之间进行条带化,即给定的LBA总是映射到通道LBA mod N,其中N是通道的数量;(ii)基于写入顺序的映射,将传入的写入操作在通道之间进行条带化,即第i次写入操作Wi映射到通道i mod N,其中Wi是第i次写入操作。根据映射策略,某些访问模式可能会导致操作在通道之间分配不均,从而降低性能。

3.3新硬件接口(New Hardware Interfaces)
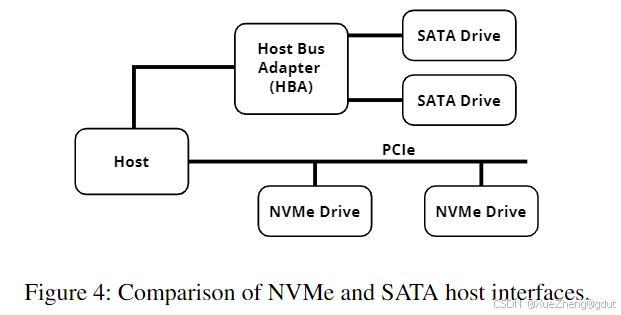
大多数早期的SSD使用了SATA或SCSI接口,这些接口是为HDD设计的。随着SSD的延迟和吞吐量不断提高,这些接口逐渐显得不足。例如,SATA 2.0的最大带宽为600 MB/s,设备通过主机总线适配器(HBA)连接,这会引入额外的延迟(见图4)[70]。此外,SATA设备一次只能有一个未完成的请求,但支持NCQ(原生命令队列)的SATA设备可以有32个队列深度。
NVMe协议是为高吞吐量SSD设计的,允许SSD直接连接到PCIe总线。NVMe允许设置多个I/O提交队列和完成队列,以充分利用SSD内部的并行性。队列的最大深度为64K,标准允许最多64K个队列,但实际设备通常支持8到128个队列。主机可以为每个应用设置一个队列对,或者像Linux块层那样为每个CPU核心设置一个队列。主流存储接口提供块设备接口,块大小通常为512字节到4 KB,不能部分读写,但可以按任意顺序访问。已经有许多关于替代SSD接口的提议。Bjorling等人[8]认为块设备接口对SSD性能有额外的开销,因为需要内部逻辑来抽象闪存擦除块。他们提出了ZNS(Zoned Namespace),该接口暴露了必须按顺序写入的区域。ZNS设备不需要内部垃圾回收或大型映射表,因此性能更加可预测。然而,最终性能取决于应用对顺序写入顺序的适应程度。SALSA[28]在主机上实现了FTL(闪存转换层),通过仅写入大块顺序数据来消除设备FTL开销。其他接口包括Open-Channel SSD[10],它比ZNS更少抽象,直接暴露通道/芯片/平面的组织结构给主机。KAML[30]暴露了一个键值接口,并在SSD控制器上实现了键值存储。最后,多流SSD[33]允许应用指定块的预期生命周期。

3.4 Linux 存储堆栈的进展(Advances in the (Linux) Storage Stack)
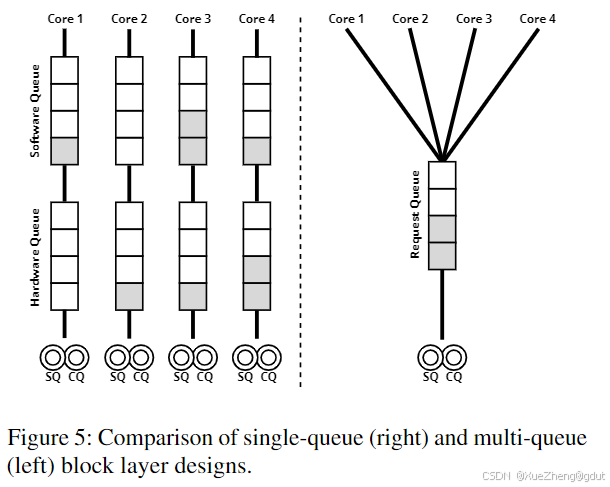
为了使 Linux 存储堆栈适应闪存时代,引入了一种新的多队列设计,称为 blk-mq,它在 Linux 3.13(2014 年)中首次引入。在传统的单队列设计中,每个存储设备只有一个全局请求队列,所有 I/O 请求都提交到这个队列中。这种设计在多核系统上存在性能瓶颈,因为多个 CPU 核心提交 I/O 请求时会产生锁竞争,导致性能下降。此外,所有硬件中断都由同一个 CPU 核心处理,这也会限制性能。
在新的多队列设计中,I/O 请求队列的数量是可配置的,通常每个 CPU 核心都有一个软件队列(见图 5)。此外,还有一组硬件调度队列,用于与支持多队列的设备匹配。软件队列作为 I/O 请求的暂存区,I/O 调度器可以在运行时插入其中,并且可以在每个软件队列内重新排序请求。硬件队列负责管理设备的反压(back-pressure),即确保设备不会收到超过其队列容量的请求。硬件队列不允许修改,请求从软件队列添加到队列尾部,设备驱动程序从队列头部消费请求。这种软件队列和硬件队列的功能分离,以及每个核心上的软件队列,使得性能能够更好地扩展。Linux 的 blk-mq 性能随着 CPU 核心数量的增加而大致线性增长。

轮询代替中断(Polling Instead of Interrupts)
传统上,硬件中断是完成 I/O 请求的唯一机制。在基于中断的 I/O 中,操作系统调度器将发起 I/O 请求的进程置于等待状态,然后在 I/O 提交完成后调度另一个任务。当设备完成请求时,会触发硬件中断,中断处理程序会将发起 I/O 请求的进程设置为可调度状态。这种机制对于 HDD 来说效果很好,因为毫秒级的 CPU 时间不会被浪费,且中断数量相对较少且快速。然而,对于可以达到每秒数百万次 I/O 操作且延迟在微秒级的 NVM 驱动器,中断数量可能会变得非常高,从而耗尽 CPU 核心的资源。此外,应用程序看到的端到端延迟可能会更糟,因为需要更多的上下文切换,且进程在被重新调度之前会有延迟。中断的替代方案是轮询,即在提交 I/O 请求后,内核进入忙循环并不断轮询设备。内核在 I/O 完成后切换回同一个进程,从而减少了上下文切换的数量,并且没有延迟。轮询可能为现代设备提供更低的延迟和更高的吞吐量,但代价是浪费 CPU 周期在忙循环中。

重新思考内核接口(Rethinking the Kernel Interface)
Linux 5.1(2019 年)引入了 io_uring,这是一个异步 I/O 接口,旨在提供未来证明、易于扩展且性能更好的接口。例如,通过最小化数据拷贝、减少上下文切换次数,并支持轮询,io_uring 提供了更好的性能。io_uring 提供了三种模式,用于在内核和应用程序之间传递提交和完成事件:
- 中断驱动:应用程序将一个或多个提交事件放入提交队列(SQ),并调用 io_uring_enter 系统调用来通知内核。该调用是异步的,会立即返回。当存储设备触发中断时,事件将被添加到相应的完成队列(CQ),并变得对应用程序可见。
- I/O 轮询:uring 被初始化为设备不会触发中断。相反,应用程序必须调用 io_uring_enter,内核将在忙循环中轮询设备,直到指定数量的事件完成。
- SQ 轮询:创建一个内核线程来轮询提交队列中的新事件。应用程序不需要调用 io_uring_enter 来提交事件,这使得操作几乎不受上下文切换的影响。使用轮询模式可以提供最佳性能,但代价是更高的 CPU 使用率。SQ 轮询内核线程需要一个专用的 CPU 核心,以获得最佳性能,因为将其抢占会导致所有提交事件被阻塞。
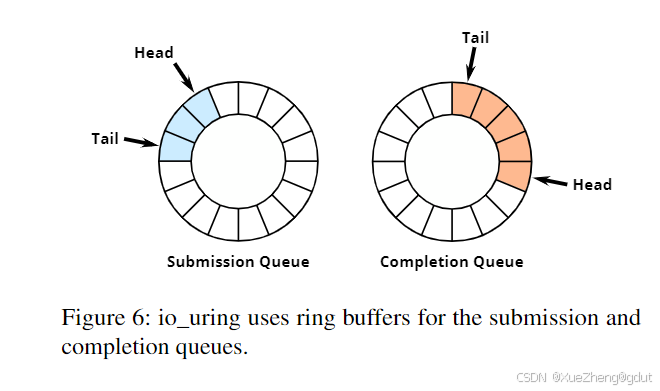
io_uring 使用一对共享环形缓冲区(见图 6),分别用于 I/O 提交和完成。为了提交 I/O,应用程序查看提交队列的头部指针,并在环形缓冲区的该位置放置一个请求。当内核从队列中消费请求时,它会更新尾指针,指向它应该下一次消费的位置。如果头部和尾部指针相同,则没有内容可供消费。完成队列的工作方式类似,但角色相反。环形缓冲区是无锁数据结构,但需要内存屏障来确保内存操作的顺序,因为现代 CPU 可能会以不同的顺序执行它们,从而导致不正确的执行。

绕过块层(Bypassing the Block Layer)
对于高性能存储应用,可能值得绕过操作系统提供的 I/O 设施。SPDK 是这样一个解决方案,它提供了一个运行在用户空间的 NVMe 驱动程序。NVMe 设备因此不由操作系统管理,只能被一个应用程序使用。I/O 路径变得更短,因为没有调度和较少的抽象,SPDK 的性能已被证明优于内核块层。SPDK 总是运行在轮询模式下,因为将中断转发到用户进程既困难又昂贵。

3.5 I/O 调度器的演变(Evolution of I/O schedulers)
I/O 调度器的目的是在将 I/O 请求提交给存储设备之前对它们进行排序和修改,例如为了提高性能或改善应用程序的体验。I/O 调度器的目标可以包括:
- 公平性:确保多个进程获得公平的 I/O 分配,这些进程不会降低其他进程的性能,且没有进程会被饿死。
- 性能:重新排序和合并请求,以产生更好的访问模式,例如通过按顺序排列请求来优化 HDD 的性能。
- 优先级:调度器可能支持为 I/O 请求分配不同的优先级。
- 截止时间:调度器可以提供截止时间保证,即保证请求在提交后的一定时间内完成。
这些目标与我们在前面定义的 QoS 目标相交。在本小节中,我们将描述 Linux 中现有的 I/O 调度器是如何演变以提供这些目标的,重点关注 Linux 中的 I/O 调度器。
电梯调度(Elevator Scheduling)
电梯调度器试图通过按扇区(LBA)顺序排列请求来最小化寻道时间。例如,SCAN 算法从调度其第一个请求开始,然后只调度具有更高(或更低,取决于方向)LBA 的请求。其他请求将被安排在下一次扫描中,按顺序递增(或递减)的方式进行。SCAN 算法的一个变体是 C-SCAN,它始终按一个方向进行扫描,因为来回扫描在统计上会优先处理中间的扇区。

Linus 电梯(The Linus Elevator)
Linux 上的第一个 I/O 调度器是一个以创建者命名的电梯调度器。它使用 SCAN 顺序队列,并且还会合并队列中与相邻请求的传入请求。它还包含一个防止饿死的机制。当插入一个新请求时,它不会被插入到比给定阈值(以成功请求的数量衡量)更旧的请求前面,从而防止饿死。然而,这种最大年龄保证并不足以防止饿死。

截止时间调度器(Deadline)
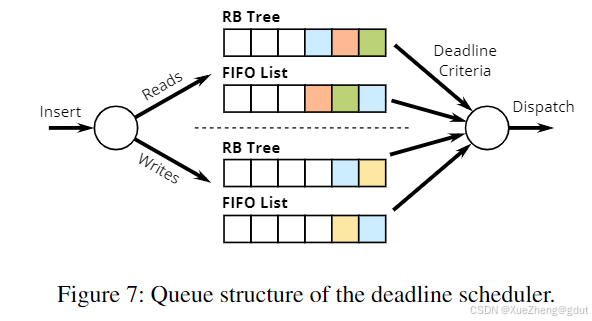
为了改进 I/O 调度,Linux 2.6(2004 年)引入了对可热插拔 I/O 调度器的支持,默认调度器是新的截止时间调度器。为了限制饿死,每个请求都被赋予了一个过期时间,默认情况下,读取请求为 500 毫秒,写入请求为 5 秒。指向请求的指针存储在两个队列中,一个按 LBA(红黑树)排序,一个按过期时间(FIFO 队列)排序,分别有读队列和写队列(见图 7)。最后,请求被移动到批量的调度队列中。请求是从读队列中移动的,除非只有写入请求,或者如果写入请求被忽略的次数过多。然后,它从按 LBA 排序的队列中取出请求,除非过期队列的头部请求已过期,在这种情况下,它将该请求及其相邻请求从排序列表中移出,保持批次的顺序性。

预期调度器(Anticipatory)
预期调度器基于截止时间调度器,但增加了一些额外的启发式规则。最显著的是,它收集每个进程的 I/O 模式统计信息,并在调度最后一个请求时,尝试预测是否很快会有新请求到来。这会阻塞来自其他进程的潜在请求,通常持续几毫秒,但防止寻道可能带来的好处更大。图 8 展示了这样一个场景。不立即处理任何工作的 I/O 调度器被称为非工作保持调度器,预期调度器就是这样一个例子。


CFQ 调度器(CFQ)
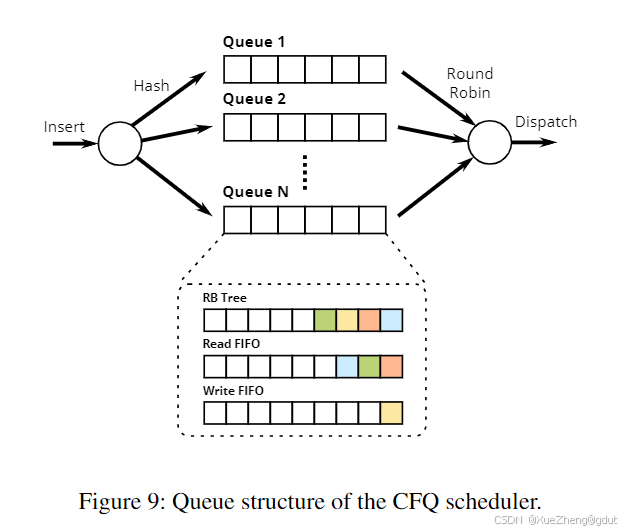
Linux 上第一个旨在提供进程间公平性的 I/O 调度器是 CFQ(Completely Fair Queuing)。它有大量队列(默认 64 个),请求被放置在通过散列进程 PID 确定的队列中(见图 9)。然后,请求被批量移动到调度队列中,以轮询方式处理。后来,它通过为每个队列分配时间片而不是移动固定批次进行了改进,允许队列在等待更多请求时处于空闲状态,类似于预期调度器。它还引入了每个进程的 I/O 优先级,默认情况下,这些优先级与进程的 CPU 优先级级别一致。与截止时间调度器相比,CFQ 可以提供更好的吞吐量和公平性,但延迟可能更高。

3.6 排队理论(Queueing Theory)

加权公平队列(Weighted Fair Queueing, WFQ)

最坏情况公平加权公平队列(Worst-case Fair Weighted Fair Queueing, WF2Q)
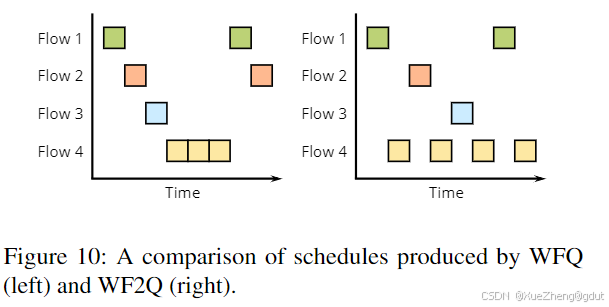
最坏情况公平加权公平队列(WF2Q)是 WFQ 的一种扩展,它提供了相同的保证,但旨在防止队列权重不同时的突发行为。通过增加一个要求,即任务的虚拟开始时间必须低于当前全局虚拟时间,所有队列将更平等地向前移动,从而产生更平滑的工作负载。图 10 展示了 4 个队列的调度情况,其中最后一个队列的权重为 3,其他队列为 1。在 WFQ 中,队列 4 会周期性地出现突发(黄色),而在 WF2Q 中,所有队列都能获得更平滑的服务。

开始时间公平队列(Start-Time Fair Queueing, SFQ)
开始时间公平队列(SFQ)也基于 WFQ,但它按开始时间而不是完成时间调度请求。SFQ 已被证明对于性能非固定的设备(如 SSD)能够提供更好的公平性。当设备完成请求的速度比配置的成本快或慢时,可能会出现不公平性,虚拟时间可能会向前或向后漂移。该时间用于标记新请求,但积压队列可能会出现时间偏差。SFQ(D) 是 SFQ 的一种扩展,它允许并行调度 D 个请求,这对于具有高并行性的 SSD 设备很有用。SFQ(D) 被用于 MQFQ、FlashFQ 和 vFair 中。

赤字轮询(Deficit Round Robin, DRR)
赤字轮询(DRR)是一种计算效率高的公平队列算法,可以在 O(1) 时间内选择要调度的任务,而不是像其他算法那样需要 O(logN) 时间。它类似于加权轮询(WRR),但考虑了不同任务的大小。在每一轮中,每个队列可以提交任务,直到给定的量子(时间片)用完,如果队列在一个较大的任务上停止,未使用的量子(赤字)将被加到下一轮的量子中。如果所有任务大小相等,DRR 与 WRR 等效。DRR 的一个缺点是服务可能是突发的,延迟可能会变长。DRR 被用于 WA-BC 中。

二维公平队列(2 Dimensional Fair Queueing, 2DFQ)
二维公平队列(2DFQ)是一种高级的公平队列算法,支持并行调度和可变请求成本。与WF2Q类似,2DFQ旨在最小化服务的突发性。当任务的成本差异较大时,2DFQ相比于其他调度器能够提供更低的尾延迟,这在I/O请求中尤其有用,例如4KB请求与256KB请求竞争时。2DFQ可能对I/O调度特别有用,因为它可以更好地处理不同大小的请求。


4 动机(Motivation)
在本节中,我们探讨了在固态硬盘(SSD)上提供服务质量(QoS)保证的挑战,这些挑战激发了本综述的研究动机。我们描述了SSD的独特特性,因为QoS机制必须围绕这些特性设计。然后,我们描述了这些特性可能引起的干扰。最后,我们探讨了软件设计中的挑战,以及I/O路径中的额外工作如何降低性能。
4.1 SSD特性(SSD Characteristics)
在SSD上提供性能保证是具有挑战性的,因为它们的吞吐量、延迟和IOPS高度依赖于访问模式和设备状态。这种特性是由SSD内部复杂的逻辑所导致的,例如FTL(闪存转换层)逻辑,它用于将块设备暴露给主机,但也会引入不可预测的行为、吞吐量降低和高尾延迟等问题。SSD的第一个特性是闪存读取和写入(编程)操作所需的时间不同,事务调度单元(TSU)可能会重新排序操作以优先处理读取操作。另一个特性是内部任务(如垃圾回收和磨损均衡)也需要访问闪存芯片,因此会与主机操作竞争。这些操作的强度取决于设备状态。当所有页面至少被写入一次且内部任务稳定时,设备达到稳态。SSD的内部并行性也会导致某些性能特性。为了实现峰值吞吐量,I/O流必须充分利用所有通道。不良的访问模式可能会导致某些通道的负载过高,从而引入瓶颈。如果SSD使用缓存来存储翻译表条目,某些访问模式可能会导致更多的缓存驱逐,从而使翻译操作耗时更长。许多SSD还包含一个写回缓存,其刷新策略不同,可能会导致延迟峰值。任何试图共享SSD并提供QoS的尝试都需要考虑这些因素。

4.2 干扰(Interference)
由于我们刚刚解释的SSD特性,混合来自多个工作负载的操作可能会产生意外的性能结果。两个不同的工作负载在单独运行时可能表现出良好的性能,但当它们交错运行时,性能可能会显著下降。干扰可能是由SSD的不同功能引起的,例如写回缓存、翻译表和每个通道的事务调度器。FLIN的作者[64]识别出SSD上的四种干扰类别:
- I/O强度:高I/O强度的工作负载会降低低I/O强度工作负载的速度。这是因为当低I/O强度工作负载单独运行时,芯片调度队列较短,等待时间较低。而高I/O强度工作负载会使队列变长,导致低I/O强度工作负载的事务在队列中位置更深(见图11)。
- 访问模式:具有不良访问模式的工作负载(相对于并行性而言)会降低具有良好访问模式的工作负载的速度。通过不利用并行性,工作负载会导致某些闪存通道或芯片出现拥塞。来自良好工作负载的事务会在这些通道或芯片上经历延迟,而I/O命令中最慢的事务决定了延迟。
- 读/写比例:读密集型工作负载会降低写密集型工作负载的速度。因为写操作在闪存上比读操作慢10-40倍,现有的调度器优先处理读操作。这导致写密集型工作负载的性能下降,因为有更多读请求被优先处理。
- 垃圾回收:需要频繁垃圾回收的工作负载会降低对垃圾回收更友好的工作负载的速度。垃圾回收事务不是根据哪个工作负载触发了它们来调度的。
垃圾回收是SSD性能问题的常见来源,可能会影响干扰。例如,考虑两个工作负载。当它们单独运行时,A具有较低的WAF(写入放大因子),而B具有较高的WAF。组合流的WAF结果不是两个WAF的平均值,它甚至可能高于B的值,这意味着每个人都输了[36]。即使应用程序不是同时运行,干扰也可能发生,例如如果一个应用程序在当前应用程序之前留下了设备处于不利于当前应用程序的状态[20]。

4.3 软件开销(Software Overheads)
鉴于SSD的高性能,软件组件(如块层)必须能够承受吞吐量并减少额外的延迟。例如,BFQ(最复杂的Linux调度器)已被证明在快速SSD上表现不佳。最近的研究表明,I/O调度器不再需要,因为即使是轻量级的调度器(如Kyber和mq-deadline)也会引入不可忽视的延迟(5-10%),并且不能提供峰值吞吐量。然而,这种观点忽略了对QoS和公平性的需求[67]。另一项研究表明,没有I/O调度器的Linux块层仍然无法利用单个CPU核心来饱和SSD,因为CPU的负载过大。轻量级解决方案(如SPDK)需要较少的CPU功率来饱和设备。此外,为了实现峰值性能,现代技术(如io_uring和轮询)必须被使用[58]。然而,这为虚拟化管理程序带来了挑战,因为这些解决方案不能轻易地传递到虚拟机中。

5 闪存设备控制器(Flash Device Controllers)
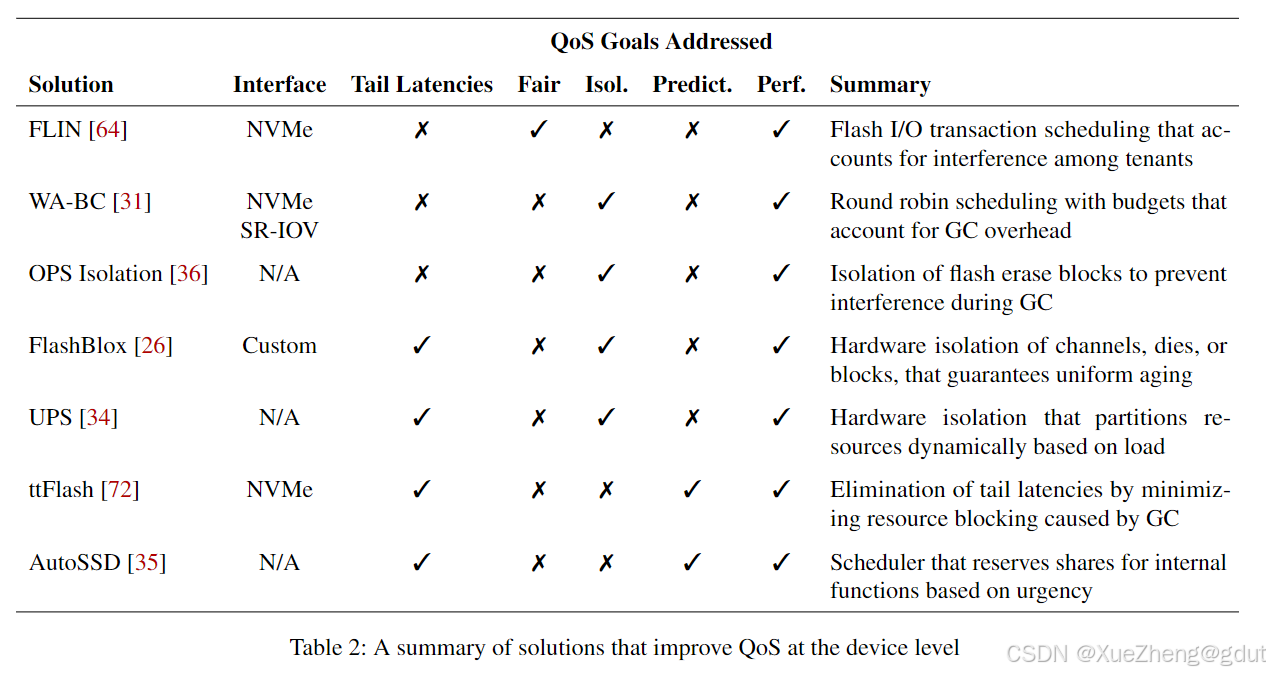
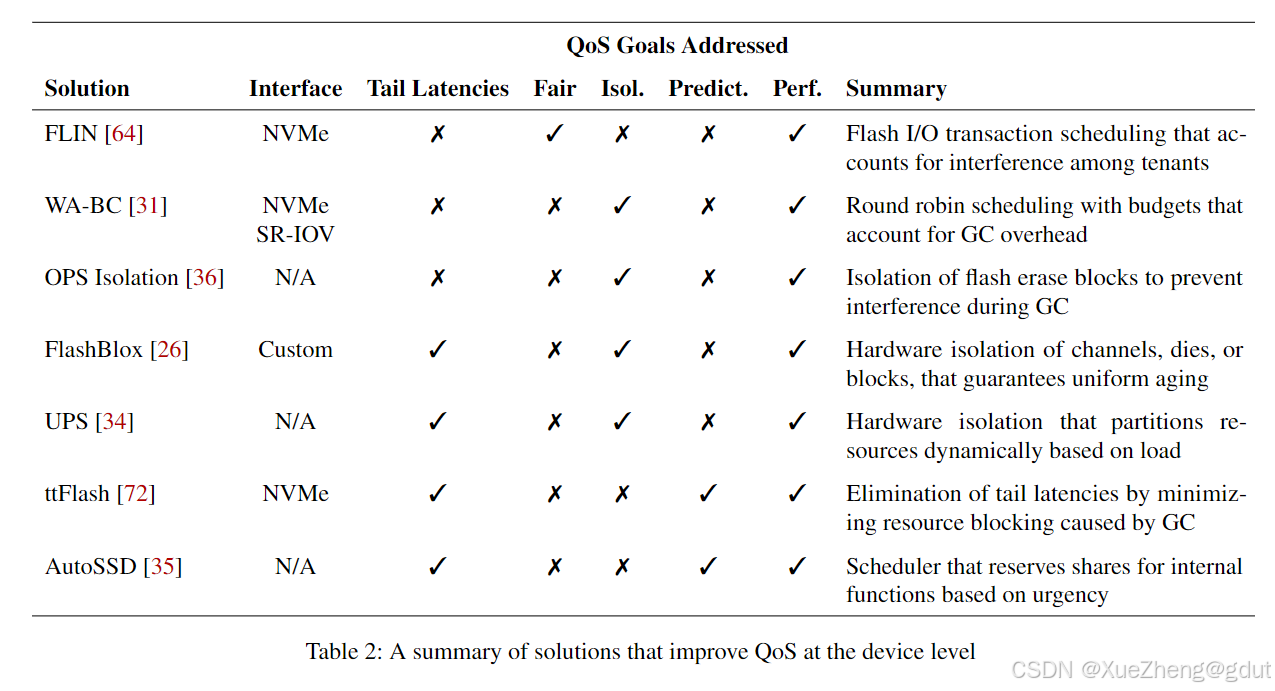
在这一节中,我们探讨了通过改变SSD固件和架构来提高服务质量(QoS)的解决方案,这些解决方案对应于图1中的第1层。这些解决方案的总结见表2,将在本节末尾讨论。
5.1 QoS感知控制器(QoS-Aware Controllers)
我们首先探讨了几种在SSD控制器上实现QoS的解决方案,例如通过实现公平队列算法或隔离方案。
FLIN(Flash-Level Interference-Aware Scheduler)
FLIN(Flash级干扰感知调度器)[64] 是一种针对SSD的事务调度器,旨在提供公平性和性能。它通过在每个芯片的事务调度单元(TSU)内重新排序和优先级调度事务,来解决四种类型的干扰(见图12)。FLIN调度器包括三个步骤,分别解决不同类型的干扰:
- 队列重排序:当事务到达芯片级调度器时,它们被插入到对应优先级和方向(读或写)的队列中,每个队列按顺序排列以优化公平性。
- 优先级感知仲裁(WRR):第二步不解决任何干扰问题,而是通过加权轮询(WRR)实现优先级感知,对每个优先级队列进行调度。
- 事务选择:第三步解决访问模式和垃圾回收(GC)干扰,从第二步的四个选项中选择一个事务(读、写、GC读或GC写)。
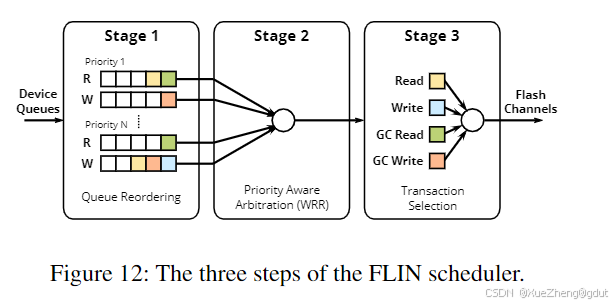
不同的I/O强度是干扰的主要来源,因此第一步提供了大部分的公平性改进。关键在于一个算法,它通过高效的两遍方法计算每个位置的公平性,并将事务插入到最优位置。
为了应对其他类型的干扰,第三步平衡读写请求的等待时间,并确保GC事务在多个流之间分配。算法计算两个可用读写事务的比例等待时间(PWT),以确保写请求不会被阻塞太久。
FLIN的一个优点是它可以在SSD控制器内实现,无需更改主机接口。它利用NVMe的多队列特性来分离流,并使用队列权重特性来设置流的优先级。FLIN使用MQSim闪存模拟器实现,显示出比现有解决方案更好的最大降速性能。值得注意的是,FLIN没有牺牲吞吐量,仅在TSU内重新排序事务。
WA-BC(Workload-Aware Budget Compensation)
WA-BC(工作负载感知预算补偿)[31] 是一种针对多个虚拟机共享的SSD的闪存调度器,使用SR-IOV(单根I/O虚拟化)机制将PCIe设备直接传递给多个虚拟机。它为每个虚拟机的队列分配预算,并使用轮询调度,但会跳过已耗尽预算的非空队列。当所有非空队列耗尽预算后,它们会被重新补充。从预算中扣除的成本取决于工作负载。首先,WA-BC使用线性回归确定不同的读写成本(CR和CW)。在给定的时间间隔内,收集读写操作的数量和总时间。当K个时间间隔过去后,得到K个包含两个变量(CR和CW)的方程(公式5),通过线性回归计算出CW和CR的最佳拟合值。然后,根据每个虚拟机的写入放大因子(WAF)调整写入成本,因为某些虚拟机的写入成本可能更高。
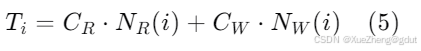
当一个擦除块包含来自多个虚拟机的页面时,很难确定每个虚拟机的WAF。因此,WA-BC实现了类似于OPS隔离和多流SSD的擦除块隔离。WA-BC在不同WAF的虚拟机并排运行时,能够实现良好的性能隔离(QoS目标G2,隔离),否则会引发高干扰。
OPS隔离(OPS Isolation)
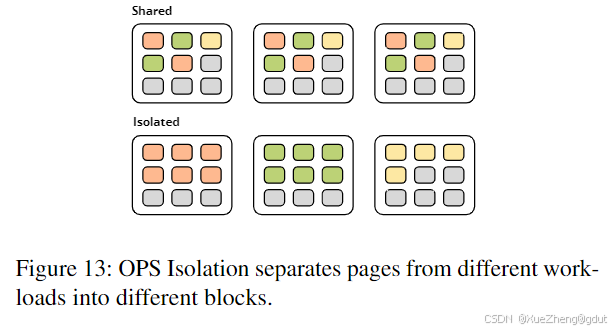
OPS隔离[36]是一种假设的SSD,它划分了SSD的过量配置资源。SSD通常包含比可访问的更多内部存储,称为过量配置空间,用于垃圾回收(GC)。当来自多个工作负载的I/O流在单个SSD上交错时,闪存块中会混合所有工作负载的页面。因此,当一个工作负载触发一个块的GC时,它会影响所有工作负载的性能。GC选择的块中有效页面的比例称为利用率(u),较低的值对应于较低的写入放大,从而获得更好的性能。研究表明,交错的工作负载可能导致利用率值低于单独执行每个工作负载时的值,从而导致整体吞吐量降低。使用OPS隔离,每个工作负载被分配一个权重,数据块和过量配置块按比例划分。I/O请求按工作负载标记,因此每个块只包含空闲页面或来自单个工作负载的数据(见图13)。每个工作负载还保证了一定的IOPS,作为设备峰值IOPS的比例。然后可以计算出维持该IOPS所需的u值。算法动态分配OPS块,以达到每个工作负载的u目标。
FlashBlox
类似于OPS隔离,FlashBlox[26]通过划分通道来提供硬件隔离,称为虚拟SSD(vSSD)。每个SSD通道独立运行,因此vSSD之间不会相互干扰。然而,通道隔离带来了磨损均衡的挑战,因为不同vSSD上的工作负载可能导致不均匀老化。为了防止不均匀老化,FlashBlox引入了一种迁移机制,定期交换最年轻和最老的通道。FlashBlox还提供了其他两种隔离模式,具有不同的权衡:
(i) 晶粒隔离的vSSD:提供较弱的隔离,因为多个晶粒必须共享同一个通道总线。在这种情况下,也需要进行磨损均衡,以确保晶粒的均匀老化。
(ii) 软件隔离的vSSD:类似于OPS隔离。主机上的令牌桶速率限制器确保每个晶粒内的块的平等访问。
FlashBlox暴露了一个类似ZNS的接口,强制顺序写入,并且每个块只分配给一个应用程序,以减少GC干扰。FlashBlox在开放通道SSD上实现,并使用LevelDB进行基准测试,这与FlashBlox的基于日志的块接口很好地集成。FlashBlox的一个限制是,运行在通道隔离的vSSD上的工作负载有一个严格的吞吐量上限,这与其通道数量成比例。例如,如果使用8个通道中的4个,只能达到SSD吞吐量的一半。软件隔离的工作负载可以从其他工作负载那里借用未使用的IOPS,但也可能引起干扰并窃取IOPS。另一个限制是定期的通道迁移用于磨损均衡。平均工作负载可能需要每3周进行一次15分钟的迁移,在此期间,吞吐量和延迟会降低三分之一。
UPS(Utilitarian Performance Isolation)
UPS[34]是一种多个租户共享SSD的方案。与FlashBlox的固定分区不同,UPS根据每个租户的效用动态划分SSD的NAND芯片。页面始终写入租户分区内的芯片,但随着分区的变化,租户的数据可能会位于另一个租户的分区中。给定一个NAND芯片分区,效用是一个值,表示一个租户对芯片的利用程度。选择分区,使得所有租户的效用相同,并根据之前的使用情况定期计算。一个租户的读取操作进入另一个租户的分区可能会影响性能隔离。为了提高隔离性,UPS利用垃圾回收的机会,将页面重新定位到它们的租户分区中。与共享设备相比,UPS减少了干扰,但也比静态分区更灵活,例如当一个工作负载出现流量突发时。
5.2 消除尾延迟(Eliminating Tail Latencies)
由内部FTL(闪存转换层)功能(如垃圾回收)引起的尾延迟是SSD上的一个大QoS问题。尝试隐藏这些内部开销的解决方案可以分为以下几类:
- 利用空闲时间(Exploiting Idle-Times):执行FTL功能的最佳时机是主机吞吐量较低时。
- 数据冗余(Data Redundancy):类似于RAID,数据可以在通道之间条带化,如果一个通道忙于内部任务,可以从其他通道重建数据。
- 基于反馈的调度(Feedback-Based Scheduling):内部任务尽可能少地占用设备,只保持足够的份额以跟上其工作。
接下来,我们将详细探讨其中两种解决方案。
ttFlash(Tiny-Tail Flash)
ttFlash [72] 是一种显著减少尾延迟的SSD控制器架构。它利用了以下三项硬件进展:
- 平面阻塞垃圾回收:当触发垃圾回收(GC)时,简单的SSD会阻塞同一通道上的请求,有些甚至会阻塞整个设备(例如USB闪存驱动器)。随着控制器计算能力的提高,可以实现平面内复制命令的平面阻塞垃圾回收(见第3.2节)。因此,GC的平面内复制命令可以与其他平面的命令交错,只阻塞一个平面。
- RAIN(NAND冗余阵列):现代SSD实现了RAIN,使用奇偶校验页来防止数据丢失,因为NAND芯片越来越密集,数据损坏变得越来越频繁。这种冗余也可以用来快速读取被GC阻塞在一个平面中的页面,通过从其他平面读取数据来实现。这需要在平面内对页面进行智能布局,并且GC必须被安排得当,以确保每个步长(即冗余组)中只有一个平面被阻塞。
- DRAM缓冲区:现在经常使用DRAM缓冲区作为写回缓存,以防电源丢失,由电容器支持。这消除了写入延迟的峰值,但写回操作必须跟上新写入的速度。ttFlash协调写回操作与GC调度,以便在GC不阻塞的平面中写回数据。
通过这三种技术,ttFlash几乎可以消除尾延迟,无论工作负载如何。使用奇偶校验页的一个缺点是会浪费一部分SSD容量。此外,使用奇偶校验数据重建页面需要更多的读取操作,这使得操作成本略有增加。同样的情况也适用于写入操作,因为奇偶校验页也需要更新。
AutoSSD
AutoSSD [35] 是一种SSD控制器架构,它将所有FTL功能(如主机I/O请求、垃圾回收、磨损均衡和读取清理)的闪存操作统一调度。读取清理是一种预防性操作,通过将频繁读取的页面迁移到其他位置来防止页面损坏。调度器使用请求窗口技术,根据每个功能的份额限制每个功能的在飞(in-flight)请求数量。这些份额通过反馈系统动态控制,旨在纠正每个FTL功能的误差值。一开始,所有份额都属于主机I/O请求,但随着垃圾回收、读取清理和磨损均衡变得更加关键,它们的份额会按比例增加。需要注意的是,AutoSSD不是工作保持的(work-conserving),一个非空队列可能会被一个更高优先级的空队列阻塞。

5.3 讨论(Discussion)
我们探讨的这些解决方案通过不同的方法来提高服务质量(QoS)。最明显的方法包括改进SSD内部调度、为SSD资源提供隔离方案,以及消除尾延迟。表2总结了每种解决方案考虑的QoS目标。我们可以看到,设备端的解决方案通常不会牺牲性能,但每种解决方案通常只考虑了前三个目标(公平性、隔离性、可预测性)中的一个。只有FlashBlox引入了一种新的主机接口,其他解决方案基于NVMe或未指定主机接口,通常是因为它们是在模拟器中实现的。
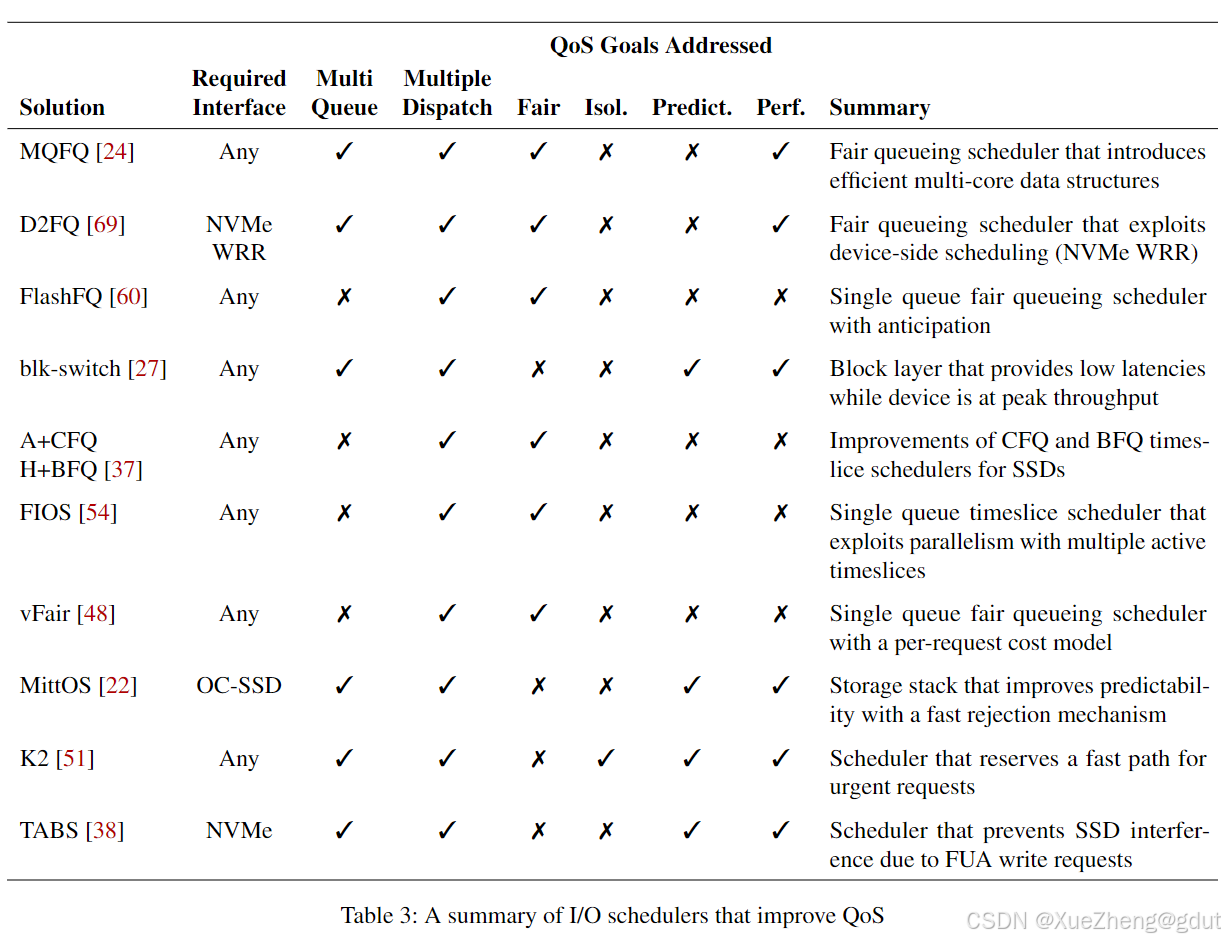
6 I/O 调度器(I/O Schedulers)
在这一节中,我们研究了旨在通过提高公平性和性能可靠性来改善服务质量(QoS)的SSD I/O调度器,或者调查性能问题。这一节对应于图1中的第2层。相关解决方案总结在表3中,将在本节末尾讨论。
6.1 Linux 调度器(Linux Schedulers)
我们首先探讨了目前Linux提供的I/O调度器。
BFQ(Budget Fair Queueing)
BFQ(预算公平队列)调度器旨在改善CFQ的公平性和延迟保证。与CFQ类似,每个应用程序都有自己的队列,但现在每个队列都有一个以块计数衡量的预算。不再以轮询方式选择队列,而是使用B-WF2Q+算法选择下一个活动队列。当预算耗尽或队列为空时,选择新队列,并以一种方式计算新预算,即高吞吐量队列获得高预算,而对延迟敏感的队列获得低预算。B-WF2Q+算法优先选择低预算队列,从而降低延迟。BFQ还包含多种启发式规则。其中一个启发式规则是早期队列合并(EQM),它合并相邻块的队列,这在具有多个I/O工作线程的应用程序中很常见。它还针对具有内部队列的闪存和NCQ设备提供了特殊启发式规则,设备可能会以牺牲公平性或增加延迟为代价来优化排序。总体而言,BFQ已被证明与CFQ具有相同的吞吐量,并且在公平性和延迟保证方面表现更好。
Kyber
对于具有高IOPS吞吐量的NVMe设备,BFQ被证明过于复杂且CPU密集,无法提供良好的性能。Kyber是一个为多队列块层设计的更简单的调度器。应用程序通常更关注读取延迟,因为应用程序可能正在等待数据变得可用,而写入操作不太可能阻塞执行。Kyber将读取和写入操作分别放入不同的队列,然后将请求移动到一个保持足够短的调度队列中,以对读取请求做出一定的延迟保证。它使用直方图计算调度队列中90百分位的延迟,并相应地调整其长度。它基于位图队列以提供良好的性能。
无调度器(None)
Linux I/O调度的另一个选项是不使用调度器(none)。在多队列块层之后,none在大约3年的时间里是唯一的选择,它也是许多发行版今天对NVMe设备的默认选项。由于NVMe设备的高性能,所有调度器对吞吐量都有不可忽视的影响,对于某些用户来说,延迟和公平性可能不太重要,因为驱动器提供了丰富的性能。
6.2 多队列调度器(Multi-Queue Schedulers)
MQFQ(Multi-Queue Fair Queueing)
MQFQ是一个为Linux多队列块层设计的I/O调度器。它引入了一个适用于多队列系统的公平队列算法,并使用巧妙的数据结构来最小化CPU核心之间协调的开销。它旨在用于具有内部并行性的多队列SSD。假设通过将飞行中的请求数量限制为D,设备可以被饱和,但SSD不需要在请求之间进行仲裁,否则可能会破坏主机端的公平性决策。参数D可以通过探测方法发现。MQFQ基于SFQ(D),但添加了一个放松的排序标准,以减少队列之间所需的协调,因为否则每次调度都需要查看所有其他队列的虚拟时间,这将限制MQFQ的可扩展性。然而,当一个队列超出窗口T时,它必须被短暂限制。此外,所有队列都必须获得一个调度槽,以便可以控制全局飞行中的请求数量。MQFQ使用三种巧妙的数据结构来管理虚拟时间、限制和调度槽:
- Mindicator:所有队列必须能够确定全局虚拟时间,即所有队列中的最低时间。简单的方法是扫描每个队列的时间数组,但这会导致过多的缓存失效。Mindicator数据结构使用一棵树,每个队列的值都在叶节点中。当一个队列的值更新时,最低值向上遍历,并且相对较少的操作更新根值,即全局最小值。这棵树与线程、核心和NUMA结构对齐,以更好地利用缓存。
- Token Tree:为了跟踪飞行中的请求数量并防止设备端仲裁,全局原子计数器无法扩展。Token Tree数据结构跟踪每个队列在调度前必须获取的令牌,并在完成后释放。通常,所有队列对令牌有平等的份额,本地使用令牌时不需要协调。如果一个队列没有使用所有令牌,附近的内核可以请求未使用的令牌。基于树的方法类似于Mindicator树,并且优先考虑来自同一核心和NUMA域的令牌。
- Timing Wheel:当一个队列被限制时,必须存储它可以解除限制的时间。Timing Wheel是一个位图数组,每个位表示一个队列可以解除限制的事件,偏移量为i的位图表示i周期后的事件。当一个事件过去后,该位图变为n周期后的事件,使其类似于一个轮子。
MQFQ调度器可以提供与CFQ相同的公平性水平,用于HDD。然而,与使用“none”选项相比,IOPS吞吐量降低了25%。

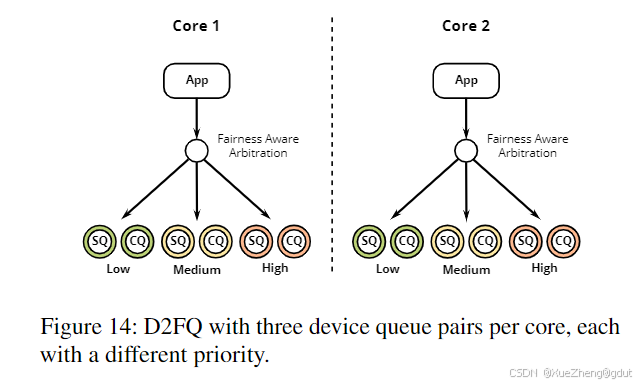
D2FQ(Device-Direct Fair Queueing)
D2FQ是一个也为Linux实现的I/O调度器。D2FQ利用NVMe的加权轮询(WRR)特性,将部分调度卸载到设备上。WRR是一个可选的NVMe特性,允许设备队列被赋予三个优先级级别(低、中、高)和每个级别1到256之间的权重。设备将根据每个队列的权重按比例处理I/O请求。D2FQ在每个核心上添加了三个队列,分别具有低、中和高优先级,并且权重会动态调整(见图14)。I/O请求默认获得高优先级,但如果需要限制,则获得中或低优先级。在Linux块层中,D2FQ使用基于虚拟时间的公平队列机制进行调度。D2FQ为每个流维护一个虚拟时间,该时间与已分发的字节数成比例增长,并根据流的权重进行归一化。当一个I/O请求到达时,调度器将该流的虚拟时间与全局虚拟时间进行比较。在严格的SFQ中,只有虚拟时间最低的流才被允许分发请求。然而,在D2FQ中,所有请求都会立即分发,但如果流的虚拟时间过早,它将被分发到低优先级队列。这导致该流的虚拟时间增长更慢,从而平衡所有流的虚拟时间。

blk-switch
blk-switch基于网络交换机的思想,修改了Linux多队列块层。它通过保留两个ionice I/O权重值来分离对延迟敏感的应用程序(L-apps)和吞吐量密集型应用程序(T-apps)。用户必须为每个进程显式选择一个配置文件。blk-switch解决了由于CPU争用导致的Linux块层中尾延迟问题。T-apps的高IOPS可能会导致块层的CPU使用率很高,从而减慢来自L-apps的请求处理速度。对于每个CPU核心,blk-switch创建了两个出队列,分别用于L-apps和T-apps。来自L-apps的请求始终优先于T-apps。为了防止T-apps完全饿死,如果CPU的负载超过某个阈值,T-app请求将被路由到负载较轻的核心的出队列。这与基础Linux块层不同,基础Linux块层中I/O请求永远不会在核心之间移动。L-apps和T-apps的处理由单独的内核线程完成,L-app线程被赋予更高的优先级。因此,即使核心由于块层开销而负载很高,它仍然会以低延迟处理L-app请求。blk-switch已被证明能够在高吞吐量场景中成功保持低延迟(QoS目标G4,性能)。然而,与基础Linux块层相比,它实现的总吞吐量略有减少。

MittOS
MittOS [22] 是一种机制,用于快速拒绝I/O请求,如果这些请求无法满足其服务等级协议(SLA)。应用程序可以指定其可以容忍的尾延迟阈值,并使用修改后的读取系统调用,如果由于太多争用而无法及时完成请求,则返回EBUSY错误。对于具有多个副本的数据库应用程序,如果第一个副本返回EBUSY,请求可以被移动到另一个副本。如果没有关于争用的知识,应用程序也可以使用等待和推测的方法,即如果请求在阈值之前没有完成,它会假设存在争用并尝试另一个副本。图15展示了与在阈值之后等待和推测的应用程序相比,立即看到争用的应用程序(灰色)的场景,这导致了更多浪费的时间。
为了实现MittOS,必须准确预测传入请求的延迟。对于没有设备端排队的机械驱动器,可以在操作系统调度器中进行估算。使用先进先出(FIFO)调度器时,请求的延迟仅仅是队列中前面所有请求的总和。然而,对于重新排序请求的调度器,请求最初可能看起来延迟较低,但后续的高优先级请求可能会将其推后。在这种情况下,MittOS可能会取消较旧的请求,同时仍然尊重SLA。在NVMe驱动器上,延迟估计变得更加复杂,因为需要了解内部状态。MittOS使用开放通道SSD来观察每个通道的争用。大型请求可能涉及多个通道,在这种情况下,最慢的通道决定了整体延迟。在多租户环境中共享存储时,嘈杂的邻居可能导致数据库查询的高尾延迟。然而,多个数据库副本不太可能同时经历争用。通过MittOS的快速拒绝机制,尾延迟几乎可以降低到单租户环境的水平。

K2
K2 [51] 是一个多队列调度器,为请求提供实时保证,但不保证公平性。它使用8个暂存队列,对应于Linux上的8个ionice优先级级别。它始终从非空的最高优先级队列中消费请求,以向高优先级请求提供更低的延迟。K2还限制了飞行中的请求数量,类似于MQFQ,以防止设备级调度进行破坏主机端决策的仲裁。当一个对延迟敏感的进程与高吞吐量进程一起运行时,K2能够比其他Linux I/O调度器提供更低的延迟,然而,它牺牲了相当一部分吞吐量。

6.3 单队列调度器(Single-Queue Schedulers)
FlashFQ
FlashFQ [60] 是Linux单队列块层的I/O调度器。FlashFQ首先指出,CFQ、BFQ、Argos和FIOS等调度器所采用的时间片调度方式并不适合闪存,因为它会影响响应性。相反,应该使用基于每个请求的细粒度队列调度算法。这是因为当一个流的时间片耗尽时,它必须在轮询中等待下一个时间片,这会导致高延迟。FlashFQ使用SFQ(D),即SFQ的扩展版本,可以并行调度D个请求。并行调度请求对于充分利用SSD的性能至关重要,但也会引入请求之间的干扰。FlashFQ认识到,闪存设备上的干扰可能导致两个并行请求之间的性能不平衡。为了平衡流量,FlashFQ引入了一种节流调度机制,当流量的虚拟时间过早时,会限制流量。正如第3节所述,预期可以提高机械硬盘的吞吐量,通过短暂闲置以接收更多顺序请求,而不是立即处理需要更多寻道时间的请求。尽管SSD不会从最大化局部性中受益,但FlashFQ发现预期可以用来提高公平性。公平队列算法的一个特点是,当一个流变得不活跃时,它不能累积份额,而是当它再次变得活跃时重新开始虚拟时间。通过在不活跃后保持流量的虚拟时间短暂窗口,流量可以在欺骗性空闲的情况下使用累积的资源。
A+CFQ和H+BFQ
Kim等人 [37] 研究了CFQ和BFQ调度器的I/O比例性。为了满足SLA要求,可以使用Linux cgroup为进程和虚拟机分配不同的I/O权重。然而,CFQ和BFQ在闪存设备上未能达到预期的比例性。这是由于快速SSD上的设备队列空闲,CFQ会不断在请求队列之间切换,使得难以达到比例性目标。为了提高比例性,A+CFQ在CFQ中实现了预期,防止队列之间过度切换。对于BFQ,比例性受到过度预算分配的影响。H+BFQ(带有历史记录的BFQ)为积极的进程分配较少的预算。尽管满足比例性是现代I/O调度器的一个重要目标,但BFQ和CFQ已被证明在SSD上表现不佳。
FIOS
FIOS [54] 是一种用于闪存的I/O调度器,它使用时间片方法来实现公平性。它解决了CFQ调度器的局限性,CFQ未能充分利用SSD的并行性,并且没有认识到闪存存储上读写操作的不同成本。FIOS对时间片机制进行了两项改进。首先,可以同时激活多个时间片;其次,时间片可以在轮询周期(也称为纪元)内被分割。对于每个调度的请求,从时间片中减去成本。在CFQ中,成本是请求的字节大小。然而,FIOS构建了两个线性模型,分别用于读取和写入,以根据它们的大小估计它们的成本,从而提高公平性。
vFair
vFair [48] 是一种单队列I/O调度器,通过计算每个请求的I/O成本来实现公平性。对于每个流量,vFair确定访问模式的饱和点,即如果单独运行可以达到的峰值吞吐量。最初,必须校准四个模型,这些模型给出了给定请求大小和访问类型(顺序、随机、读取或写入)可以达到的峰值IOPS。vFair收集每个流量的四种不同访问类型的比率,并定期通过结合四个模型计算峰值IOPS。然后,vFair通过根据每个流量的饱和点公平地减缓所有流量来实现公平性。vFair还表明,同步流量可能会被异步流量减慢,因为同步流量只能在消化前一个请求的响应后提交更多请求。这使得量化不公平性变得更加困难,因为同步流量没有可见的积压,从而表现出欺骗性公平性。
TABS
TABS [38] 是一种I/O调度器,通过限制写入操作来确保读取操作的公平性。特别是,某些数据库应用程序大量使用NVMe FUA(强制单元访问)标志,该标志使写入操作直接进入闪存,而不是进入设备的回写缓存。在这种情况下,读取和FUA写入之间会发生强烈的干扰。TABS限制未完成的FUA写入数量,以加快读取请求的速度。它使用动态反馈机制来调整实现公平性所需的队列深度限制。TABS仅考虑操作类型之间的公平性,而不是进程之间的公平性。

6.4 其他工作(Other Work)
Yang等人 [74] 指出,仅靠I/O调度器无法实现公平性。首先,当读取和写入请求被缓存在页面缓存中时,进程可能会不公平地驱逐其他进程的页面。其次,I/O调度器不允许重新排序某些写入请求,因为这涉及到一致性要求。Argon I/O调度器 [66] 探讨了设备端读取预取和写入回写缓冲区中的类似缓存不公平性问题。为了防止不公平性,Argon实现了一个缓存分区方案。大多数公平性调度器需要确定每个请求的成本,无论是推进虚拟时间还是从预算中扣除。最简单的调度器使用请求的延迟或字节大小作为成本。一些调度器(例如FIOS、vFair)构建了需要预先校准的模型。Liu等人 [47] 提出了D-IOCost,这是一个动态调整流权重的成本模型。

6.5 讨论(Discussion)
我们已经看到了多种通过I/O调度器改进服务质量(QoS)的方法,例如公平队列算法、利用特殊硬件特性、对延迟敏感请求的特殊处理以及节流启发式方法。表3总结了这些解决方案。一些解决方案提供了良好的性能(QoS目标G4),然而,只有D2FQ能够完全饱和设备。对于前三个目标(公平性、隔离性、可预测性),所有解决方案只考虑了其中的一个,除了K2。大多数解决方案可以在标准主机接口上运行,然而,D2FQ和MittOS需要特殊的硬件特性。

7 虚拟化(Virtualization)
对于云服务提供商来说,提供虚拟机和基于容器的服务是一种常见的实践,这不仅可以更好地利用资源,还能提供更高的灵活性。例如,资源可以被超额预订(oversubscribed),租户可以根据需要轻松地扩展资源。在这些多租户环境中,服务提供商通常受服务等级协议(SLA)的约束,必须保证一定的吞吐量或延迟。本章探讨了虚拟化管理程序和容器的存储堆栈设计(对应于图1中的第3层),以及如何将QoS集成到这些设计中。相关解决方案总结在表4中,将在本节末尾讨论。
7.1 存储虚拟化(Storage Virtualization)
为虚拟机提供存储有多种选择。最简单的方法是硬件直通(hardware passthrough),通过IOMMU映射将整个设备传递给虚拟机。NVMe标准还支持SR-IOV(Single Root I/O Virtualization),设备被分区并在PCI总线上呈现为多个独立设备。硬件直通通常可以提供接近原生的性能,但限制了灵活性和虚拟机的数量。
在另一端,全软件仿真(full software emulation)是通过“捕获和仿真”(trap and emulate)的方法,将真实的NVMe或SCSI设备暴露给虚拟机操作系统,但每个操作都会被虚拟机监控程序捕获并进行仿真。然而,仿真真实设备可能会占用大量CPU资源。半虚拟化(Para-virtualization)是一种技术,向虚拟机操作系统提供简化的I/O接口,与真实硬件接口相比,这种方式对虚拟机监控程序更加友好。KVM通过virtio-blk和virtio-scsi提供了半虚拟化存储,通常比全软件仿真表现更好。图16展示了这些解决方案的不同I/O路径。最近的存储虚拟化研究主要集中在通过不同方法缩小裸金属和虚拟机之间的性能差距。两种流行的方法是:SPDK存储驱动程序,它们完全在用户空间运行;以及通过最小化仿真将大部分设备功能直接传递给虚拟机的中介直通(mediated passthrough)。Dowty和Sugerman [18] 引入了以下用于GPU虚拟化的分类,也可以解释存储虚拟化中的不同权衡:
- 性能:虚拟化存储与底层设备相比的性能如何,以及引入了多少额外的CPU使用率。
- 保真度:虚拟化存储的功能丰富程度如何。
- 多租户共享:底层设备是否可以被多个租户共享?如果是,可扩展性有何限制。
- 功能插入:是否可以在虚拟机和存储设备之间引入额外功能?例如,检查点、压缩、备份和实时迁移等功能。
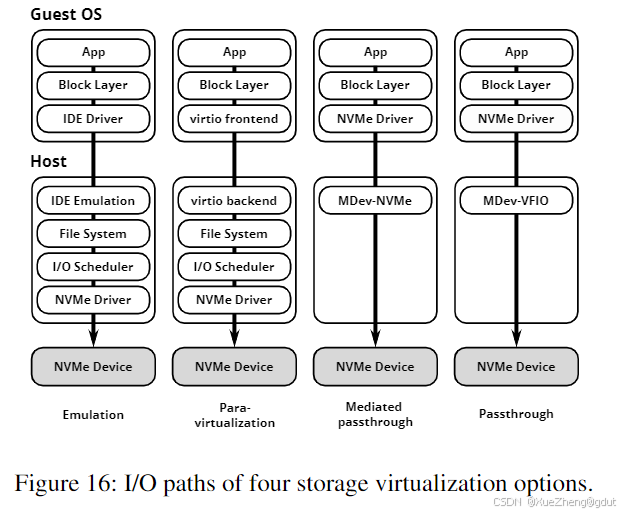
接下来,我们将详细探讨两种最先进的存储虚拟化技术,它们提供了接近原生的性能。在后续部分中,我们将看到这些工作的扩展,这些扩展提供了QoS。
MDev-NVMe
MDev-NVMe [56] 是一种针对NVMe的中介直通机制。它使用Linux内核的VFIO mdev(中介设备)模块。MDev-NVMe向虚拟机操作系统暴露了一个虚拟NVMe设备,包含多个管理队列和I/O队列。然而,每个虚拟I/O队列都是设备物理队列的影子队列。当提交I/O时,MDev-NVMe会翻译数据的DMA地址和设备块的LBA。所有管理命令都会被完全仿真,以便向虚拟机呈现一个虚拟设备,该设备可能与物理设备具有不同的属性。当通过NVMe提交I/O时,主机通常会通过MMIO向设备门铃寄存器写入。在虚拟机中,这可能是昂贵的,因为每个MMIO写入都会被捕获并需要仿真。NVMe提供了一个管理命令来设置影子门铃寄存器,MDev-NVMe可以轮询该寄存器,以防止频繁的虚拟机退出。因此,MDev-NVMe能够实现零拷贝的NVMe虚拟化,具有最小的仿真开销,并提供接近原生的性能。
SPDK vhost-NVMe
为了提高VirtIO的性能,可以使用vhost协议将仿真从QEMU移动到内核模块或用户进程。SPDK vhost-NVMe [75] 是一个在用户空间运行的存储目标,它通过共享内存与虚拟机操作系统驱动程序通信,并可以轮询虚拟机的NVMe队列,以最小化虚拟机退出的次数。与MDev-NVMe类似,这也允许零拷贝操作,并且由于虚拟机退出次数少,因此提供接近原生的性能。SPDK是一个完整的用户空间NVMe驱动程序,它绕过了块层的开销。其他vhost目标也存在,例如基于内核的virtio-scsi后端和用户空间的virtio-scsi和virtio-blk SPDK驱动程序,这些协议与NVMe数据结构的匹配度较差,需要更多的转换,从而影响性能。在用户空间运行目标还可以提高性能,因为减少了内核上下文切换的次数。

7.2 硬件卸载(Hardware Offloading)
MDev-NVMe和SPDK vhost-NVMe的一个限制是,它们依赖于轮询来提供良好的性能,这至少需要一个专用的CPU核心。Kwon等人 [42] 指出,如果NVMe设备的性能增长速度超过CPU,那么这些解决方案的CPU开销将会增加。他们发现,与原生存储相比,SPDK vhost-NVMe需要额外增加61%的CPU时间。作为回应,他们提出了FVM,这是一种基于FPGA的存储虚拟化技术。FPGA卡向虚拟机(VM)呈现SR-IOV虚拟设备,并通过PCIe对等通信直接与SSD交互。
Li等人 [43] 也发现,基于主机的存储虚拟化会带来较高的CPU开销,因为它会占用虚拟化管理程序(hypervisor)10-20%的CPU时间。他们提出了LeapIO,这是一种基于ARM协处理器的SmartNIC,用于卸载存储虚拟化任务。这两种解决方案提供的服务质量(QoS)有限。FVM通过在虚拟I/O队列之间实现轮询调度,但为每个虚拟机提供了带宽限制功能。LeapIO则按照先进先出(FIFO)的顺序从虚拟队列中调度请求。

7.3 公平中介直通(Fair Mediated Passthrough)
正如我们所见,最新的存储虚拟化技术主要关注高吞吐量,但对服务质量(QoS)的支持有限。大多数技术绕过了操作系统块层,因此块层中的I/O调度器无法提供QoS控制。LPNS [55] 是一种受MDev-NVMe启发的中介直通虚拟化系统,它还提供了可预测的延迟。LPNS可以用于混合部署,其中一些虚拟队列由主机NVMe驱动程序使用,而其他队列则直接传递给虚拟机(VMs)。

在LPNS中,虚拟存储设备可以被标记为延迟敏感型。NVMe硬件队列被分为两组:一组是1:1映射到虚拟设备的队列,另一组是1:N映射到多个设备的队列(见图17)。延迟敏感型虚拟机被分配1:1队列,以防止队列头部阻塞。LPNS使用一种称为确定性网络微积分(deterministic network calculus)的方法(该方法借鉴了网络理论)来计算给定吞吐量下的延迟上限,并在吞吐量可能导致延迟目标超出时限制虚拟队列。
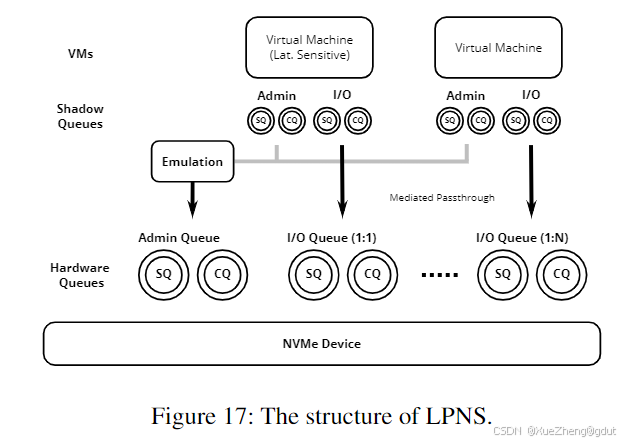
LPNS可以为虚拟机提供延迟上限,但与MDev-NVMe相比,吞吐量损失约为20%。LPNS使用轮询线程来中介直通。单个线程足以利用单个SSD,但为了实现可预测的延迟目标,可能需要更多线程。因此,这种方法会受到CPU税(CPU overhead)的影响。
mClock [21] 是在VMware ESX上实现的一种I/O调度器。它允许为每个虚拟机设置I/O权重,同时还提供基于吞吐量的最小保留和最大限制。它结合了公平队列调度方法和基于约束的方法,满足了公平性标准以及最小和最大限制。

7.4 容器存储(Container Storage)
容器通过在同一个操作系统上隔离进程,提供了轻量级的虚拟化。与虚拟机相比,容器可以实现更高层次的整合,因为资源不是静态保留的。在Linux中,可以使用cgroup功能来隔离和限制进程的资源。对于I/O资源控制,最简单的机制是blk-throttle,它允许限制读/写IOPS或每秒字节数。由于存储设备的总吞吐量会随着访问模式的不同而变化,因此设置固定的限制对于QoS控制并不有效。[4,25] IOCost(blk-iocost)[25]通过I/O成本模型改进了QoS。该模型以虚拟时间的形式返回请求的成本。当提交请求时,cgroup的本地虚拟时间会根据请求的成本进行增加,该成本会根据cgroup的I/O权重进行调整。如果cgroup的本地虚拟时间超过了全局虚拟时间,请求将被限制。默认情况下,IOCost使用四个线性模型来为读/写和随机/顺序请求分配不同的成本。可以以eBPF程序的形式指定任意模型。blk-throttle和IOCost都已集成到Linux中,并且在高性能SSD上显示出接近零的开销。

7.5 其他工作(Other Work)
Ahn等人 [4] 指出,blk-throttle无法实现比例性,即无法根据权重平衡不同cgroup之间的吞吐量。他们提出了WDT,通过动态限制实现比例共享。Spool [71] 是一个基于SPDK的用户空间驱动程序,用于QEMU,它提高了虚拟化环境中NVMe存储的可靠性。他们发现,设备错误在大规模云环境中是常见的,其中大多数可以通过重启存储系统来解决。Spool通过最小化重启时间,使得租户经历的延迟峰值更小。
vMigrater [29] 展示了,当虚拟CPU(vCPU)采用时间共享(即非专用核心)时,I/O可能在vCPU变为空闲时利用不足。他们建议在虚拟机(VM)有另一个活动vCPU时,将I/O操作迁移到该vCPU。

7.6 讨论(Discussion)
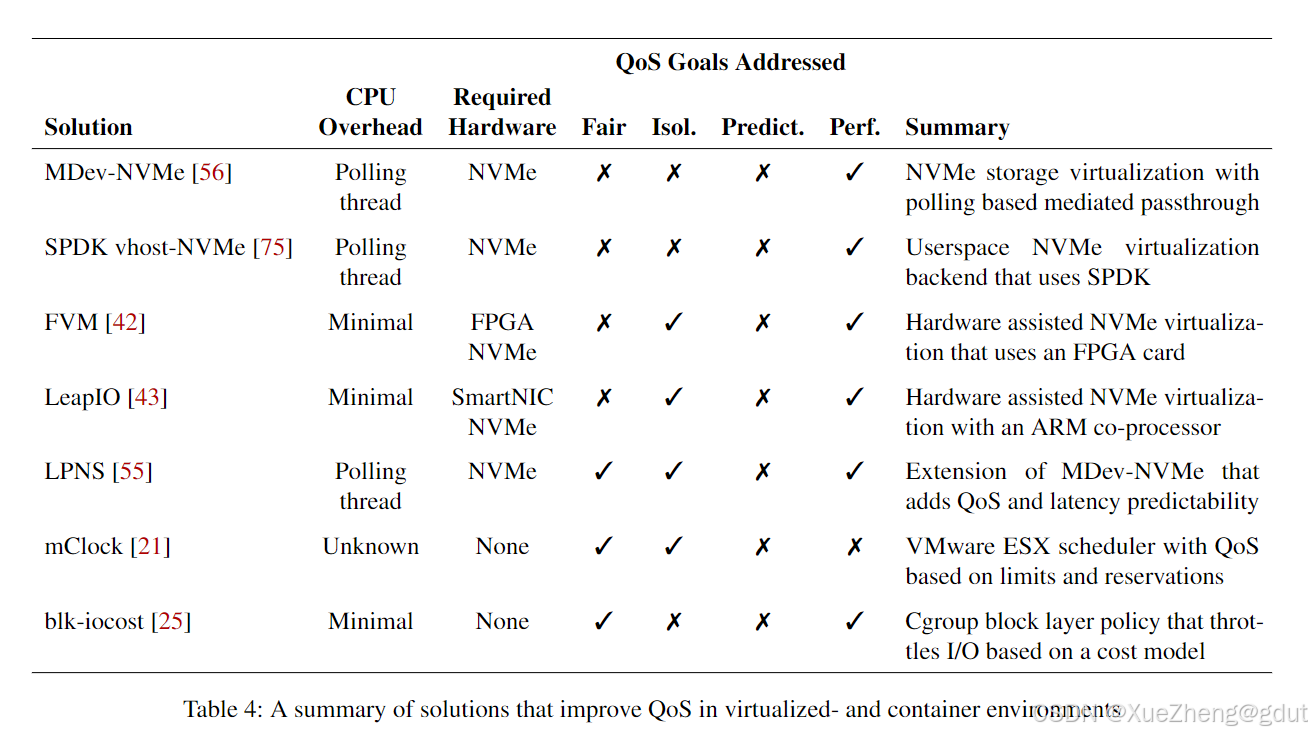
我们已经看到了几种在虚拟化环境中提高服务质量(QoS)的方法,包括中介直通、SPDK用户空间驱动程序和硬件辅助存储虚拟化。表4总结了这些解决方案及其所解决的QoS目标。大多数解决方案都集中在提高性能上,因为传统的解决方案通常比裸金属(bare-metal)表现差。一些解决方案还提供了隔离或公平性,然而,没有解决方案涉及可预测性。一个值得注意的权衡是,软件解决方案都使用轮询,因此牺牲了一个或多个CPU核心,而专用硬件可能会引入额外的成本。

8 SSD仿真(SSD Emulation)
在前面的内容中,我们已经看到了闪存设备存储堆栈具有很大的设计空间。闪存芯片的组织结构、闪存转换层(FTL)的设计、不同的主机接口以及应用层面提供了许多设计选项。为了对新设计进行原型设计,仿真和模拟平台可以对设备内部进行建模。我们在前面章节中探讨的许多解决方案都依赖于仿真平台来验证其可行性。SSD原型设计平台可以分为以下三类,它们各自具有不同的特点和挑战:
- 仿真器(Emulators)
仿真器以实时方式运行,通常表现为虚拟化设备,运行在虚拟机(VM)内部或裸金属主机上。因此,仿真器允许在其上运行未经修改的应用程序。实时性要求对仿真器设计提出了很大的挑战。 - 模拟器(Simulators)
模拟器不受实时性约束,通常处理来自真实应用程序的跟踪文件。这使得模拟器简单且成本较低,但跟踪文件比运行真实应用程序更为有限。此外,跟踪文件无法针对不同设备大小的实验进行扩展。不以实时方式运行也排除了与主机和应用程序设计相关的实验。然而,模拟器的简单性促成了许多流行的解决方案。MQSim [63] 是一种最先进的模拟器,能够模拟NVMe和SATA SSD。它通过支持多队列内部结构并考虑更多延迟来源(如PCIe传输、翻译表查找和DRAM缓存时间)来改进旧的模拟器。MQSim还引入了一种快速方法来对模拟设备进行预处理,因为实验应在SSD达到稳态后进行,即所有页面至少被写入一次之后。MQSim已被证明对QoS研究很有用,例如用于分析当前SSD设计中由于流之间的干扰而导致的不公平性。一个MQSim实验表明:(1) 适度的写入流可能会因为写入缓存中的驱逐而被高密度流减慢;(2) 当翻译表被缓存时,频繁导致驱逐的流可能会减慢对翻译缓存友好的流;(3) 来自高密度流的通道队列中的竞争可能会减慢适度的流。其他模拟器包括WiscSim [23](模拟NCQ SATA驱动器)和FlashSim [40](最早的闪存模拟器之一)。它们的局限性在于不支持多队列设计。 - 真实硬件(Real hardware)
硬件原型设计平台是真实的设备,允许对不同的固件或可能的设备组织结构进行原型设计。它们提供实时运行真实应用程序的能力,但它们可能是昂贵的,并且某些设计方面(如芯片组织结构)可能是固定的。
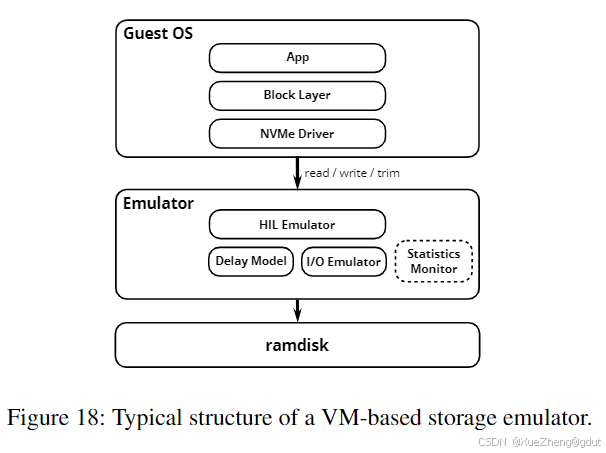
8.1 模拟器(Emulators)
实时模拟闪存设备是一种成本效益高的方法,允许在存储堆栈的所有层面进行修改实验。图 18 展示了模拟器的典型结构。FEMU [44] 是一个最先进的 SSD 模拟器,它扩展了 QEMU,以在虚拟机中暴露一个 NVMe 设备。FEMU 通过共享内存区域与虚拟机通信,类似于 SPDK 用户空间存储驱动程序,从而实现快速且无中断的执行。由于 FEMU 由 DRAM 支持且基于轮询,因此客户操作系统看到的延迟与现代 SSD 相当,无论是平均延迟还是尾延迟,这是模拟快速 SSD 的要求。在低基础延迟的情况下,FEMU 可以引入延迟模型,以准确反映真实设备上的延迟。延迟模型可以为请求添加在真实设备上会经历的相同延迟。延迟模型可以考虑由于内部竞争导致的排队延迟、到闪存芯片寄存器的传输时间,以及芯片的读、写和擦除时间。它还可以考虑不同的闪存转换和垃圾回收方案。FEMU 可以用于探索新设计的 QoS 改进,例如新的垃圾回收方案、性能隔离设计,以及为分层设计扩展 NVMe 命令。ttFlash 和 MittOS 都是使用 FEMU 进行评估的。
ConfZNS [62] 是 FEMU 的扩展,用于模拟不同设计的 ZNS 设备。特别是,区域大小以及区域如何映射到内部通道、芯片和平面,会影响每个区域的性能和性能隔离。使用 ConfZNS 的评估发现,当内部并行单元映射到单个区域时,ZNS 提供了更强的性能隔离。VSSIM [76] 是一个较老的 SSD 模拟器,基于虚拟 IDE 接口运行在 QEMU 上,限制了其可扩展性和多队列实验。VSSIM 可以由 DRAM 或真实 SSD 支持,以模拟大型设备,只要真实设备比被模拟的设备更快。Gugnani 等人 [20] 扩展了内置的 QEMU NVMe 模拟器,通过实现加权轮询(WRR)和赤字轮询(DRR)仲裁方案来支持 QoS 研究。使用他们的模拟器进行的实验表明,DRR 可以在硬件层面提供带宽保证。大多数模拟器都是为虚拟机构建的。Kim 等人 [39] 指出,这可能会限制高级功能,例如用户空间 NVMe 驱动程序和 PCIe 点对点功能。他们的解决方案 NVMeVirt 通过设置一个作为 PCI 总线出现的内存区域,然后在上面实现 NVMe 模拟,从而模拟真实的 PCIe 设备。因此,NVMeVirt 对主机和其他 PCIe 设备来说都像是一个真实设备。它支持对裸金属应用程序的实验,并且产生的延迟比 FEMU 更低,作者表明 FEMU 的延迟仅略低于现代 Optane 设备。
8.2 模拟器(Simulators)
模拟器通过处理 I/O 追踪文件工作,能够在不受实时性约束的情况下轻松模拟 SSD 的所有细节。然而,模拟器面临的一个挑战是如何处理追踪文件中请求之间的关系,例如请求之间是否存在因果依赖关系以及主机处理请求之间的时间。此外,由于不实时运行,模拟器无法进行涉及主机和应用设计的实验。此外,追踪文件无法根据实验需求进行扩展,以适应不同设备规模的测试。
尽管存在这些限制,模拟器的简单性促使其得到了广泛应用。MQSim [63] 是一个最先进的模拟器,能够模拟 NVMe 和 SATA SSD。与旧版模拟器相比,它支持多队列内部结构,并考虑了更多延迟来源。大多数旧版模拟器认为闪存芯片操作、芯片传输以及通道队列延迟是主要的延迟来源。MQSim 则指出,随着闪存芯片速度的提升,其他因素(如 PCIe 传输延迟、转换表查找延迟以及 DRAM 缓存延迟)也变得不可忽视。此外,MQSim 引入了一种快速预处理方法,用于将模拟设备置于稳态条件。这是因为实验应在 SSD 达到稳态后(即所有页面至少被写入一次后)进行。MQSim 被证明对 QoS 研究非常有用,例如用于分析当前 SSD 设计中由于流之间的干扰而导致的不公平性。实验表明:(1)适度的写入流可能会因为 intense 流导致写入缓存中的数据被驱逐而变慢;(2)当转换表被缓存时,一个频繁导致缓存驱逐的流可能会减慢对转换缓存友好的流;(3)来自 intense 流的通道队列竞争可能会减慢适度的流。
其他模拟器还包括 WiscSim [23],它模拟了支持 NCQ 的 SATA 驱动器,以及 FlashSim [40],这是最早的闪存模拟器之一。这两者都受限于不支持多队列设计。

8.3 硬件原型平台
硬件原型平台可以在没有任何主机软件的情况下呈现一个存储设备。OpenExpress [32] 在 Xilinx FPGA 板上实现了一个完整的 NVMe 控制器,并通过 DRAM 提供支持。它可以产生与英特尔傲腾 SSD 相当的带宽和延迟。然而,它没有像许多模拟器和模拟器那样提供现成的延迟模型。FPGA 的低时钟频率也限制了性能,这可能不足以用于下一代设备的原型设计。Cosmos+ OpenSSD [41] 是一个类似的 FPGA 平台,但它使用 NAND 芯片作为后端,因此其闪存特性是固定的。

9未来工作(Future Work)
在本综述中,我们探讨了多种旨在以不同方式改进 NVMe 驱动器服务质量(QoS)的解决方案。然而,尽管提出了许多解决方案,但很少有方案被实际应用到现实系统中。例如,两种最先进的公平 I/O 调度器——MQFQ [24] 和 D2FQ [69]——存在一些可能阻碍其采用的局限性。具体来说,使用 MQFQ 会导致吞吐量显著下降,而 D2FQ 需要设备支持加权轮询(WRR)功能,但目前很少有设备具备这一特性。未来的研究可能会进一步探索公平 I/O 调度的瓶颈。目前在真实环境中得到最广泛应用的解决方案可能是 IOCost [25],它被用于为 Facebook 的整个容器集群提供 I/O 公平性。然而,目前对于控制组(cgroup)策略和 I/O 调度器之间比较的研究还非常有限。
在本研究中,我们看到了多种 QoS 策略,例如公平队列算法、严格的资源隔离以及对延迟敏感请求的特殊处理。未来可能需要更好地理解这些策略如何影响最终应用程序。此外,我们还看到了通过带有中介传递(mediated passthrough)的虚拟化技术来提供 I/O 公平性的方法 [55]。这些方法可能需要进一步改进,以支持更高级的中间功能(如实时迁移),从而获得更广泛的采用。
最后,我们在本文中看到的一个明显趋势是,跟上 SSD 性能不断提升的步伐是一个挑战。几年前表现良好的解决方案可能已不再满足当今的需求。此外,云计算领域日益关注的一个问题是能效问题,但大多数解决方案并未探索其对能源使用的影响。例如,一些依赖轮询以实现高性能的解决方案,以牺牲一个或多个 CPU 核心用于轮询为代价,从而增加了能源成本。

10结论(Conclusion)
本综述深入探讨了 NVMe 驱动器上服务质量(QoS)的诸多挑战。我们通过回答在第 2 节中提出的问题,总结了本研究的核心发现,以回答我们的主要研究问题:在现代固态硬盘(SSD)上,为多个应用程序提供公平性和可靠性能的挑战是什么?
-
RQ1:I/O 调度器如何在 SSD 上实现峰值吞吐量的同时提供其他 QoS 保证?
我们发现,实现公平性需要对所有队列进行全局视图管理。多队列 I/O 调度器本质上是一个分布式系统,其主要挑战在于高效协调多个 CPU 核心之间的协作 [24]。这种协调可以通过优化的数据结构或借助设备端特性来实现。我们在第 6 节中探讨的所有解决方案在保持吞吐量方面都存在一定的性能损失,唯一的例外是 D2FQ [69],它利用设备端的仲裁功能简化了调度。因此,在没有专用设备特性的情况下,同时保持峰值吞吐量仍然是一个亟待解决的问题。 -
RQ2:导致 SSD 性能下降的原因是什么,如何预防?
正如我们在第 4 节和第 5 节中探讨的那样,SSD 的性能下降受到其内部功能和并行性的影响。特别是,由于不良的访问模式、SSD 的内部任务(如垃圾回收)或来自其他流的干扰,可能会导致延迟峰值和吞吐量降低。为了充分利用设备性能,请求必须在各个通道和芯片之间进行平衡,并且调度必须考虑公平性和由于闪存特性导致的冲突。例如,ttFlash [72] 和 FLIN [64] 等解决方案在缓解这些问题方面表现出色。 -
RQ3:在基于 SSD 的虚拟化和容器环境中,哪些因素限制了 QoS?
我们在第 7 节中讨论了许多可用的存储虚拟化解决方案。对于 NVMe 驱动器,标准解决方案会导致虚拟机内的 I/O 性能较差,因此许多解决方案被提出以提高吞吐量 [56, 75]。然而,这些解决方案绕过了主机块层,使得 QoS 的实现更加困难。目前,只有一种解决方案通过中介传递(mediated passthrough)提供了高吞吐量和 QoS [55]。容器通过操作系统的块层像其他进程一样运行,可以通过 cgroup 策略进行调整,正如我们在 IOCost [25] 中看到的那样。 -
RQ4:如何探索 SSD 和块层的设计空间以改进 QoS?
我们在第 8 节中讨论的模拟器和模拟平台可以促进对 SSD 设计空间的详细探索。许多我们在本综述中探讨的解决方案都使用模拟器来验证其可行性。进一步的 QoS 研究面临的最明显限制是难以跟上最新 SSD 的性能步伐。我们探讨的解决方案所能提供的最佳延迟水平并不比现代设备领先太多。
总结
通过本综述,我们可以看到,尽管在 NVMe 设备的 QoS 领域已经取得了许多进展,但在公平性、隔离性、可预测性和性能之间实现最佳平衡仍然是一个复杂且充满挑战的任务。未来的研究需要在这些目标之间找到更好的折中方案,并探索跨层解决方案,以应对不断发展的 SSD 技术和日益增长的能效需求。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









