







一、如何管理庞大而复杂的项目开发?
1、从设计原则和思想的角度来看,如何应对庞大而复杂的项目开发?
① 封装与抽象:
“一切皆文件”:封装了不同类型设备的访问细节,抽象为统一的文件访问方式,更高层的代码就能基于统一的访问方式,来访问底层不同类型的设备。这样做的好处是,隔离底层设备访问的复杂性。统一的访问方式能够简化上层代码的编写,并且代码更容易复用。
② 分层与模块化:
a、模块化:
每个小的团队聚焦于一个独立的高内聚模块来开发,最终像搭积木一样,将各个模块组装起来,构建成一个超级复杂的系统。
b、分层:
每一层都对上层封装实现细节,暴露抽象的接口来调用。而且,任意一层都可以被重新实现,不会影响到其他层的代码。
面对复杂系统的开发,我们要善于应用分层技术,把容易复用、跟具体业务关系不大的代码,尽量下沉到下层,把容易变动、跟具体业务强相关的代码,尽量上移到上层。
③ 基于接口通信:
在设计模块(module)或者层(layer)要暴露的接口的时候,我们要学会隐藏实现,接口从命名到定义都要抽象一些,尽量少涉及具体的实现细节。
④ 高内聚、松耦合:
能让我们在修改或者阅读代码的时候,聚集到在一个小范围的模块或者类中,不需要了解太多其他模块或类的代码,让我们的焦点不至于太发散,也就降低了阅读和修改代码的难度。
比如封装、抽象、分层、模块化、基于接口通信,都能有效地实现代码的高内聚、松耦合。
⑤ 为扩展而设计
⑥ KISS 首要原则:
简单清晰、可读性好,是任何大型软件开发要遵循的首要原则。
如果你对现有代码的逻辑似懂非懂,抱着尝试的心态去修改代码,引入 bug 的可能性就会很大。
在参与大型项目开发的时候,要尽量避免过度设计、过早优化,在扩展性和可读性有冲突的时候,或者在两者之间权衡,模棱两可的时候,应该选择遵循 KISS 原则,首选可读性。
⑦ 最小惊奇原则:
等同于“遵守开发规范”
2、从研发管理和开发技巧的角度来看,如何应对庞大而复杂的项目开发?
① 吹毛求疵般地执行编码规范
② 编写高质量的单元测试:
底层细粒度的代码 bug 少了,组合起来构建而成的整个系统的 bug 也就相应的减少了。
③ 不流于形式的 Code Review
④ 开发未动、文档先行
⑤ 持续重构、重构、重构
⑥ 对项目与团队进行拆分
面对大型复杂项目,我们不仅仅需要对代码进行拆分,还需要对研发团队进行拆分,比如模块化、分层等
3、聚焦在 Code Review 上来看,如何通过 Code Reviwe 保持项目的代码质量?
① 上线前对上线功能进行Code Review
二、如何发现和开放通用的功能模块?
1、如何发现通用的功能模块?
① 复用
② 业务无关
2、如何开发通用的功能模块?
① 对于这些类库、框架、功能组件的开发,我们不能闭门造车,要把它们当作“产品”来开发。这个产品是一个“技术产品”,我们的目标用户是“程序员”,解决的是他们的“开发痛点”。我们要多换位思考,站在用户的角度上,来想他们到底想要什么样的功能。
例如:具体到 Google Guava,它是一个开发类库,目标用户是 Java 开发工程师,解决用户主要痛点是,相对于 JDK,提供更多的工具类,简化代码编写,比如,它提供了用来判断 null 值的 Preconditions 类;Splitter、Joiner、CharMatcher 字符串处理类;Multisets、Multimaps、Tables 等更丰富的 Collections 类等等。
三、使用spring 框架的好处:
1、解耦业务和非业务开发、让程序员聚焦在业务开发上;
2、隐藏复杂实现细节、降低开发难度、减少代码 bug;
3、实现代码复用、节省开发时间;
4、规范化标准化项目开发、降低学习和维护成本等等。实
四、Spring 框架蕴含的设计思想
1、约定优于配置:
① 就是提供配置的默认值,优先使用默认值。
例如:基于约定,代码中定义的 Order 类就对应数据库中的“order”表。只有在偏离这一约定的时候,例如数据库中表命名为“order_info”而非“order”,我们才需要显示地去配置类与表的映射关系(Order 类 ->order_info 表)。
2、低侵入、松耦合:
① Spring 提供的 IOC 容器,在不需要 Bean 继承任何父类或者实现任何接口的情况下,仅仅通过配置,就能将它们纳入进 Spring 的管理中。如果我们换一个 IOC 容器,也只是重新配置一下就可以了,原有的 Bean 都不需要任何修改。
② Spring 提供的 AOP 功能,也体现了低侵入的特性。在项目中,对于非业务功能,比如请求日志、数据采点、安全校验、事务等等,我们没必要将它们侵入进业务代码中。因为一旦侵入,这些代码将分散在各个业务代码中,删除、修改的成本就变得很高。而基于 AOP 这种开发模式,将非业务代码集中放到切面中,删除、修改的成本就变得很低了。
3、模块化、轻量级:
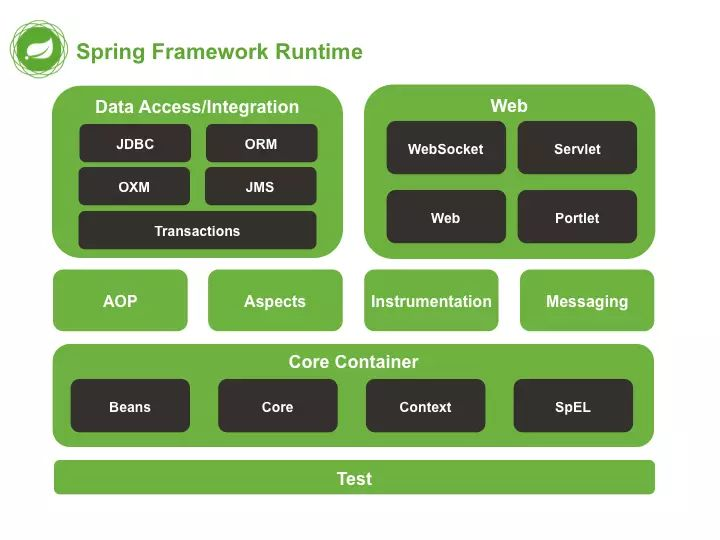
4、再封装、再抽象
Spring 不仅仅提供了各种 Java 项目开发的常用功能模块,而且还对市面上主流的中间件、系统的访问类库,做了进一步的封装和抽象,提供了更高层次、更统一的访问接口。
比如,Spring 提供了 spring-data-redis 模块,对 Redis Java 开发类库(比如 Jedis、Lettuce)做了进一步的封装,适配 Spring 的访问方式,让编程访问 Redis 更加简单。
五、Spring中支持扩展的设计模式:
1、观察者模式在 Spring 中的应用
// Event事件
public class DemoEvent extends ApplicationEvent {
private String message;
public DemoEvent(Object source, String message) {
super(source);
}
public String getMessage() {
return this.message;
}
}
// Listener监听者
@Component
public class DemoListener implements ApplicationListener<DemoEvent> {
@Override
public void onApplicationEvent(DemoEvent demoEvent) {
String message = demoEvent.getMessage();
System.out.println(message);
}
}
// Publisher发送者
@Component
public class DemoPublisher {
@Autowired
private ApplicationContext applicationContext;
public void publishEvent(DemoEvent demoEvent) {
this.applicationContext.publishEvent(demoEvent);
}
}2、模板模式在 Spring 中的应用
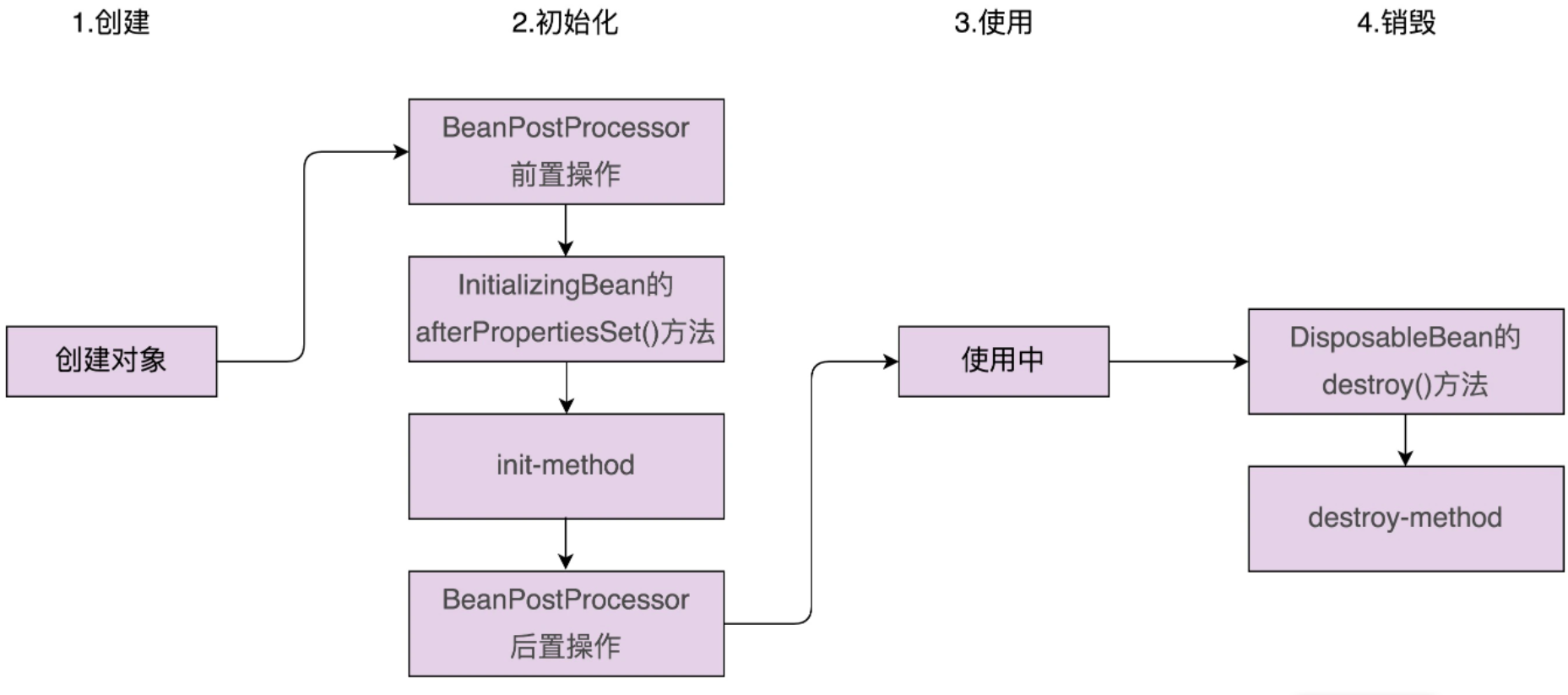
① Spring Bean 的创建过程,可以大致分为两大步:对象的创建和对象的初始化。
② 对象的创建是通过反射来动态生成对象,而不是 new 方法。不管是哪种方式,说白了,总归还是调用构造函数来生成对象,没有什么特殊的。
模板模式在Spring Bean中创建使用示例:
public class DemoClass {
//...
public void initDemo() {
//...初始化..
}
}
// 配置:需要通过init-method显式地指定初始化方法
<bean id="demoBean" class="com.xzg.cd.DemoClass" init-method="initDemo"></bean>这种初始化方式有一个缺点,初始化函数并不固定,由用户随意定义,这就需要 Spring 通过反射,在运行时动态地调用这个初始化函数。而反射又会影响代码执行的性能
③ Spring 针对对象的初始化过程,还做了进一步的细化,将它拆分成了三个小步骤:初始化前置操作、初始化、初始化后置操作。其中,中间的初始化操作就是我们刚刚讲的那部分,初始化的前置和后置操作,定义在接口 BeanPostProcessor 中。BeanPostProcessor 的接口定义如下所示:
public interface BeanPostProcessor {
Object postProcessBeforeInitialization(Object var1, String var2) throws BeansException;
Object postProcessAfterInitialization(Object var1, String var2) throws BeansException;
}
六、MyBatis如何权衡易用性、性能和灵活性?
1、Mybatis 和 ORM 框架介绍
① MyBatis 是一个 ORM(Object Relational Mapping,对象 - 关系映射)框架
② MyBatis 依赖 JDBC 驱动,所以,在项目中使用 MyBatis,除了需要引入 MyBatis 框架本身(mybatis.jar)之外,还需要引入 JDBC 驱动(比如,访问 MySQL 的 JDBC 驱动实现类库 mysql-connector-java.jar)。将两个 jar 包引入项目之后,我们就可以开始编程了。使用 MyBatis 来访问数据库中用户信息的代码如下所示:
// 1. 定义UserDO
public class UserDo {
private long id;
private String name;
private String telephone;
// 省略setter/getter方法
}
// 2. 定义访问接口
public interface UserMapper {
public UserDo selectById(long id);
}
// 3. 定义映射关系:UserMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org/DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="cn.xzg.cd.a87.repo.mapper.UserMapper">
<select id="selectById" resultType="cn.xzg.cd.a87.repo.UserDo">
select * from user where id=#{id}
</select>
</mapper>
// 4. 全局配置文件: mybatis.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="dev">
<environment id="dev">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8" />
<property name="username" value="root" />
<property name="password" value="..." />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
</configuration>在使用 MyBatis 的实现方式中,类字段与数据库字段之间的映射关系、接口与 SQL 之间的映射关系,是写在 XML 配置文件中的,是跟代码相分离的,这样会更加灵活、清晰,维护起来更加方便。
2、如何利用职责链与代理模式实现MyBatis Plugin?
例如:假设我们需要统计应用中每个 SQL 的执行耗时,如果使用 MyBatis Plugin 来实现的话,我们只需要定义一个 SqlCostTimeInterceptor 类,让它实现 MyBatis 的 Interceptor 接口,并且,在 MyBatis 的全局配置文件中,简单声明一下这个插件就可以了。具体的代码和配置如下所示
@Intercepts({
@Signature(type = StatementHandler.class, method = "query", args = {Statement.class, ResultHandler.class}),
@Signature(type = StatementHandler.class, method = "update", args = {Statement.class}),
@Signature(type = StatementHandler.class, method = "batch", args = {Statement.class})})
public class SqlCostTimeInterceptor implements Interceptor {
private static Logger logger = LoggerFactory.getLogger(SqlCostTimeInterceptor.class);
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object target = invocation.getTarget();
long startTime = System.currentTimeMillis();
StatementHandler statementHandler = (StatementHandler) target;
try {
return invocation.proceed();
} finally {
long costTime = System.currentTimeMillis() - startTime;
BoundSql boundSql = statementHandler.getBoundSql();
String sql = boundSql.getSql();
logger.info("执行 SQL:[ {} ]执行耗时[ {} ms]", sql, costTime);
}
}
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
System.out.println("插件配置的信息:"+properties);
}
}
<!-- MyBatis全局配置文件:mybatis-config.xml -->
<plugins>
<plugin interceptor="com.xzg.cd.a88.SqlCostTimeInterceptor">
<property name="someProperty" value="100"/>
</plugin>
</plugins>我们只重点看下 @Intercepts 注解这一部分。
我们知道,不管是拦截器、过滤器还是插件,都需要明确地标明拦截的目标方法。
@Intercepts 注解实际上就是起了这个作用。其中,@Intercepts 注解又可以嵌套 @Signature 注解。一个 @Signature 注解标明一个要拦截的目标方法。如果要拦截多个方法,我们可以像例子中那样,编写多条 @Signature 注解。
@Signature 注解包含三个元素:type、method、args。其中,type 指明要拦截的类、method 指明方法名、args 指明方法的参数列表。通过指定这三个元素,我们就能完全确定一个要拦截的方法。
默认情况下,MyBatis Plugin 允许拦截的方法有下面这样几个:

为什么默认允许拦截的是这样几个类的方法呢?
MyBatis 底层是通过 Executor 类来执行 SQL 的。Executor 类会创建 StatementHandler、ParameterHandler、ResultSetHandler 三个对象,并且,首先使用 ParameterHandler 设置 SQL 中的占位符参数,然后使用 StatementHandler 执行 SQL 语句,最后使用 ResultSetHandler 封装执行结果。所以,我们只需要拦截 Executor、ParameterHandler、ResultSetHandler、StatementHandler 这几个类的方法,基本上就能满足我们对整个 SQL 执行流程的拦截了。
七、面向对象设计与实现:
① 划分职责识别类
② 定义属性(名词)和方法(动词)
③ 定义类之间的交互关系
④ 组装类并提供执行入口。
八、接口请求超时幂等处理:
1、“幂等”原理:
幂等的意思是,针对同一个接口,多次发起同一个业务请求,必须保证业务只执行一次。
2、幂等处理流程
① 由幂等框架来统一提供幂等号生成算法的代码实现,并封装成开发类库,提供给各个调用方复用。
② 幂等号随着请求传递到接口实现方之后,接口实现方将幂等号解析出来,传递给幂等框架。
③ 幂等框架先去数据库(比如 Redis)中查找这个幂等号是否已经存在。
④ 如果存在,说明业务逻辑已经或者正在执行,就不要重复执行了。如果幂等号不存在,就将幂等号存储在数据库中,然后再执行相应的业务逻辑。
3、异常处理
① 对于业务代码异常,为了让幂等框架尽可能的灵活,低侵入业务逻辑,发生异常(不管是业务异常还是系统异常),是否允许再重试执行业务逻辑,交给开发这块业务的工程师来决定。
② 对于业务系统宕机,对于这种极少发生的异常,在工程中,我们能够做到,在出错时能及时发现问题、能够根据记录的信息人工修复,就可以了。所以,我们建议业务系统记录 SQL 的执行日志,在日志中附加上幂等号。这样我们就能在机器宕机时,根据日志来判断业务执行情况和幂等号的记录是否一致。
③ 在幂等逻辑执行异常时,我们选择让接口请求也失败,相应的业务逻辑就不会被重复执行了。毕竟接口请求失败(比如转钱没转成功),比业务执行出错(比如多转了钱),修复的成本要低很多。或者交由业务系统或者人工介入处理。
九、如何将设计思想、原则、模式等理论知识应用到项目中?
1、吃透理论、先把书读厚再把书读薄
2、在实战中反复学习、模仿和借鉴
3、刻意思考、刻意训练、追求极致
十、算法学习:
① 你就可以先从“照抄”开始,把所有的代码都抄一遍或者抄几遍,
② 然后再慢慢地过渡到自己去默写。
十一、设计模式学习:
① 设计思想、原则、模式,打印出来贴在电脑旁,
② 每次写代码的时候,对照着每个知识点,一个一个去审视代码。















 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









