







前言
写好的python程序要打包成windows的可执行文件,一般都是用pyinstaller。比如你要对test.py这个文件打包,一般的pyinstaller -F test.py就可以了。还有另一种用法,就是用spec文件,spec文件其实就相当于一个打包的架构文件,里面写了要怎么打包,类似于docker中的DockerFile。其实在用pyinstaller -F test.py这种方式打包的时候,程序也是先生成spec文件的,再次打包的时候我们就可以直接pyinstaller test.spec就可以了。
scrapy爬虫文件打包
我的目录结构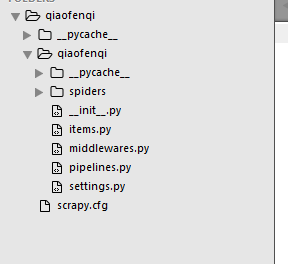
外层文件夹是qiaofenqi,里面一层是qiaofenqi和scrapy.cfg文件,爬虫文件都写在qiaofenqi文件夹里。
平时我们运行scrapy爬虫的时候,都是在命令行里用scrapy crawl +爬虫名这种方式,打包的话肯定不能用这种方式调用了,其实scrapy爬虫是可以用python程序直接调用的,我们打包的思路就是写一个py文件来调用爬虫,并把这个py文件和爬虫打包到一起。
打包步骤:
1.在scrapy.cfg文件同一层,新建一个py文件,这里我们起名为 crawl.py
# -*- coding: utf-8 -*-
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
# 这里是必须引入的
#import robotparser
import scrapy.spiderloader
import scrapy.statscollectors
import scrapy.logformatter
import scrapy.dupefilters
import scrapy.squeues
import scrapy.extensions.spiderstate
import scrapy.extensions.corestats
import scrapy.extensions.telnet
import scrapy.extensions.logstats
import scrapy.extensions.memusage
import scrapy.extensions.memdebug
import scrapy.extensions.feedexport
import scrapy.extensions.closespider
import scrapy.extensions.debug
import scrapy.extensions.httpcache
import scrapy.extensions.statsmailer
import scrapy.extensions.throttle
import scrapy.core.scheduler
import scrapy.core.engine
import scrapy.core.scraper
import scrapy.core.spidermw
import scrapy.core.downloader
import scrapy.downloadermiddlewares.stats
import scrapy.downloadermiddlewares.httpcache
import scrapy.downloadermiddlewares.cookies
import scrapy.downloadermiddlewares.useragent
import scrapy.downloadermiddlewares.httpproxy
import scrapy.downloadermiddlewares.ajaxcrawl
import scrapy.downloadermiddlewares.chunked
import scrapy.downloadermiddlewares.decompression
import scrapy.downloadermiddlewares.defaultheaders
import scrapy.downloadermiddlewares.downloadtimeout
import scrapy.downloadermiddlewares.httpauth
import scrapy.downloadermiddlewares.httpcompression
import scrapy.downloadermiddlewares.redirect
import scrapy.downloadermiddlewares.retry
import scrapy.downloadermiddlewares.robotstxt
import scrapy.spidermiddlewares.depth
import scrapy.spidermiddlewares.httperror
import scrapy.spidermiddlewares.offsite
import scrapy.spidermiddlewares.referer
import scrapy.spidermiddlewares.urllength
import scrapy.pipelines
import scrapy.core.downloader.handlers.http
import scrapy.core.downloader.contextfactory
# 自己项目用到的
import openpyxl # 用到openpyxl库
import json
import time
import os
process = CrawlerProcess(get_project_settings())
# 'credit'替换成你自己的爬虫名
process.crawl('credit')
process.start() # the script will block here until the crawling is finished
在crawl.py文件里,最下面3行代码就是scrapy官方给的运行爬虫的方法,上面的全都是依赖的引入,因为打包的时候肯定是要把python的依赖包全都打进去的,我们这里只是对这一个py文件打包,所以只能是在这里把整个爬虫文件需要的依赖全部导入,包括scrapy的全部包和你自己文件中需要用到的依赖包。这时候你直接运行crawl.py这个文件,也就调起了你的爬虫。
2.对crawl.py进行打包
为了过程好理解,我们先不管三七二十一直接对crawl.py进行打包,有问题再处理。
pyinstaller -F crawl.py
-F参数是指打成单个exe文件,其他参数自己查资料,这里不多做介绍。可以看到是可以打包成功的,dist文件中出现了crawl.exe文件,这时候你运行这个exe文件,发现是运行不成功的,直接把exe拖进cmd窗口运行,报的错误是
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\ADMINI~1\\Ap
pData\\Local\\Temp\\_MEI77122\\scrapy\\VERSION'
少VERSION文件,这个VERSION文件其实是你安装的scrapy模块下的一个文件,在安装目录是可以找到的,比如我的scrapy文件都安装在这个目录下D:\Program Files\python374\Lib\site-packages\scrapy。
既然是少了这个文件,我们只要把这个文件加入我们的打包文件中就可以了,可以用–add-data参数加,也可以在spec文件中直接配置,因为你执行了pyinstaller命令,在你的目录下已经生成了crawl.spec文件,为了方便,我们直接修改crawl.spec这个文件。然后这里其实还缺另一个mime.types文件,也是相同目录下的,这里就不演示错误了,直接加了spec文件中。其实可以看出来就是你在crawl.py中把所有的scrapy模块都引入了,就这两个文件没引入,所以会报找不到这两个文件的错误。
另外,因为我们是用crawl.py来调爬虫文件,所以爬虫文件也是要打包进我们的exe文件中的,所以在spec文件中也要加入爬虫文件。
修改后的spec文件
# -*- mode: python ; coding: utf-8 -*-
block_cipher = None
a = Analysis(['crawl.py'],
pathex=['C:\\Users\\Administrator\\Desktop\\qiaofenqi'],
binaries=[],
datas=[('D:\\Program Files\\python374\\Lib\\site-packages\\scrapy\\mime.types','scrapy'),
('D:\\Program Files\\python374\\Lib\\site-packages\\scrapy\\VERSION','scrapy'),
('.','.' )],
hiddenimports=[],
hookspath=[],
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='crawl',
debug=False,
bootloader_ignore_signals=False,
strip=False,
upx=True,
upx_exclude=[],
runtime_tmpdir=None,
console=True )
主要改的地方就是datas参数,就是你要加入打包的资源文件,一看其实就明白,mime.types放到scrapy文件夹下,VERSION放到scrapy文件夹下,(’.’,’.’ )就是把当前目录放到打包后的根路径下,其实就是把整个爬虫文件打包进去。
这样就可以重新打包了,打包之前记得把上次产生的build和dist文件夹删掉,因为这里直接用的(’.’,’.’ )把整个文件都加了打包文件里了(乐意的话可以只把py文件加入datas,但目录结构不能变),会把build和dist也打进去,造成exe文件很大。
重新打包就可以用你改好的spec文件了
pyinstaller crawl.spec
打包成功,进入dist,运行crawl.exe也没有问题。
但这还没完,如果你把exe文件拷贝到其他的地方,再运行,发现还是报错,爬虫找不到
KeyError: 'Spider not found: credit'
其实打包的过程是没错的,但爬虫运行是要依赖scrapy.cfg这个配置文件的,只要把原来爬虫文件夹里的scrapy.cfg复制一下,和exe文件放到同目录下就可以了。也就是说你发放你的exe文件的时候要和scrapy.cfg一起的。
大功告成!
总结一下
1.编写一个py文件用来调用爬虫,并导入所有的依赖
2.编写spec文件,引入其它的资源文件。不喜欢用spec文件的可以用add-data参数。
3.用spec打包。
4.把exe和scrapy.cfg一起发布。















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









