









From:https://blog.wolfogre.com/posts/usage-of-mitmproxy
http://www.cnblogs.com/grandlulu/p/9525417.html
mitmProxy 介绍:https://blog.csdn.net/h416756139/article/details/51940757
github地址:https://github.com/mitmproxy/mitmprox
mitmproxy 官网:https://mitmproxy.org
mitmproxy 中文网址:http://www.hpaizhao.cn
mitmproxy 官网文档:https://docs.mitmproxy.org/stable
mitmproxy 官方示例 及 API:(推荐从 simple 开始):https://github.com/mitmproxy/mitmproxy/tree/master/examples
如何突破网站对selenium的屏蔽 : https://blog.csdn.net/qq_26877377/article/details/83307208
和 Charles 同样强大的 iOS 免费抓包工具 mitmproxy:http://ios.jobbole.com/91030
朋友圈红包照片 mitmproxy 抓包破解:https://www.jianshu.com/p/4bef2926d8b9
mitmproxy 系列博文:https://blog.csdn.net/hqzxsc2006/article/category/6971655
IT 学院 之 Python 网络 --- mitmproxy的使用:https://book.itxueyuan.com/L8P9/DWGg
App爬虫神器mitmproxy和mitmdump的使用:https://yq.aliyun.com/articles/603782?utm_content=m_1000003903
mitmproxy套件使用攻略及定制化开发:https://www.freebuf.com/sectool/76361.html
http proxy 在web渗透上占据着非常重要的地位,这方面的工具也非常多,像burp suite, Fiddler,Charles简直每个搞web的必备神器。本文主要介绍 mitmproxy,是一个较为完整的 mitmproxy 教程,侧重于介绍如何开发拦截脚本,帮助读者能够快速得到一个自定义的代理工具。
本文假设读者有基本的 python 知识,且已经安装好了一个 python 3 开发环境。如果你对 nodejs 的熟悉程度大于对 python,可移步到 anyproxy,anyproxy 的功能与 mitmproxy 基本一致,但使用 js 编写定制脚本。除此之外我就不知道有什么其他类似的工具了,如果你知道,欢迎评论告诉我。
本文基于 mitmproxy v4,当前版本号为 v4.0.1。
mitmproxy 是什么
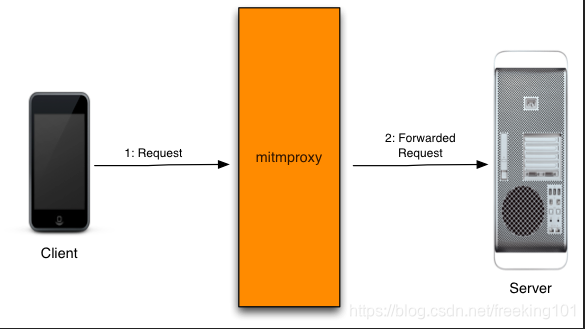
顾名思义,mitmproxy 就是用于 MITM 的 proxy,MITM 即 中间人攻击(Man-in-the-middle attack),mitmproxy 译为中间人代理工具,可以用来拦截、修改、保存 HTTP/HTTPS 请求。以命令行终端形式呈现,操作上类似于Vim,同时提供了 mitmweb 插件,是类似于 Chrome 浏览器开发者模式的可视化工具。中间人代理一般在客户端和服务器之间的网络中拦截、监听和篡改数据。用于中间人攻击的代理首先会向正常的代理一样转发请求,保障服务端与客户端的通信,其次,会适时的查、记录其截获的数据,或篡改数据,引发服务端或客户端特定的行为。
不同于 fiddler 或 wireshark 等抓包工具,mitmproxy 不仅可以截获请求帮助开发者查看、分析,更可以通过自定义脚本进行二次开发。举例来说,利用 fiddler 可以过滤出浏览器对某个特定 url 的请求,并查看、分析其数据,但实现不了高度定制化的需求,类似于:“截获对浏览器对该 url 的请求,将返回内容置空,并将真实的返回内容存到某个数据库,出现异常时发出邮件通知”。mitmproxy 它是基于Python开发的开源工具,最重要的是它提供了Python API,这样就可以通过载入自定义 python 脚本轻松实现使用Python代码来控制请求和响应。这是其它工具所不能做到的。
但 mitmproxy 并不会真的对无辜的人发起中间人攻击,由于 mitmproxy 工作在 HTTP 层,而当前 HTTPS 的普及让客户端拥有了检测并规避中间人攻击的能力,所以要让 mitmproxy 能够正常工作,必须要让客户端(APP 或浏览器)主动信任 mitmproxy 的 SSL 证书,或忽略证书异常,这也就意味着 APP 或浏览器是属于开发者本人的——显而易见,这不是在做黑产,而是在做开发或测试。
那这样的工具有什么实际意义呢?据我所知目前比较广泛的应用是做仿真爬虫,即利用手机模拟器、无头浏览器来爬取 APP 或网站的数据,mitmpproxy 作为代理可以拦截、存储爬虫获取到的数据,或修改数据调整爬虫的行为。
事实上,以上说的仅是 mitmproxy 以正向代理模式工作的情况,通过调整配置,mitmproxy 还可以作为透明代理、反向代理、上游代理、SOCKS 代理等,
总共有五种代理模式:
- 1、正向代理(regular proxy)启动时默认选择的模式。是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向mitmproxy代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
- 2、反向代理(reverse proxy)启动参数 -R host。跟正向代理正好相反,对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向mitmproxy代理服务器发送普通请求,mitmproxy转发请求到指定的服务器,并将获得的内容返回给客户端,就像这些内容 原本就是它自己的一样。
- 3、上行代理(upstream proxy)启动参数 -U host。mitmproxy接受代理请求,并将所有请求无条件转发到指定的上游代理服务器。这与反向代理相反,其中mitmproxy将普通HTTP请求转发给上游服务器。
- 4、透明代理(transparent proxy)启动参数 -T。当使用透明代理时,流量将被重定向到网络层的代理,而不需要任何客户端配置。这使得透明代理非常适合那些无法更改客户端行为的情况 - 代理无聊的Android应用程序是一个常见的例子。要设置透明代理,我们需要两个新的组件。第一个是重定向机制,可以将目的地为Internet上的服务器的TCP连接透明地重新路由到侦听代理服务器。这通常采用与代理服务器相同的主机上的防火墙形式。比如Linux下的iptables, 或者OSX中的pf,一旦客户端初始化了连接,它将作出一个普通的HTTP请求(注意,这种请求就是客户端不知道代理存在)请求头中没有scheme(比如http://或者https://), 也没有主机名(比如example.com)我们如何知道上游的主机是哪个呢?路由机制执行了重定向,但保持了原始的目的地址。
iptable设置:
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j REDIRECT --to-port 8080
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 443 -j REDIRECT --to-port 8080
启用透明代理:mitmproxy -T - 5、socks5 proxy 启动参数 --socks。采用socks协议的代理服务器
但这些工作模式针对 mitmproxy 来说似乎不大常用,故本文仅讨论正向代理模式。
mitmproxy是一款Python语言开发的开源中间人代理神器,支持SSL,支持透明代理、反向代理,支持流量录制回放,支持自定义脚本等。功能上同Windows中的Fiddler有些类似,但mitmproxy是一款console程序,没有GUI界面,不过用起来还算方便。使用mitmproxy可以很方便的过滤、拦截、修改任意经过代理的HTTP请求/响应数据包,甚至可以利用它的scripting API,编写脚本达到自动拦截修改HTTP数据的目的。
-
# test.py
-
def response(flow):
-
flow.response.headers[
"BOOM"] =
"boom!boom!boom!"
上面的脚本会在所有经过代理的Http响应包头里面加上一个名为BOOM的header。用mitmproxy -s 'test.py'命令启动mitmproxy,curl验证结果发现的确多了一个BOOM头。
-
$ http_proxy=localhost:
8080 curl -I
'httpbin.org/get'
-
HTTP/
1.1
200 OK
-
Server: nginx
-
Date: Thu,
03 Nov
2016
09:
02:
04 GMT
-
Content-Type: application/json
-
Content-Length:
186
-
Connection: keep-alive
-
Access-Control-Allow-Origin: *
-
Access-Control-Allow-Credentials:
true
-
BOOM: boom!boom!boom!
-
...
mitmweb 抓包截图:
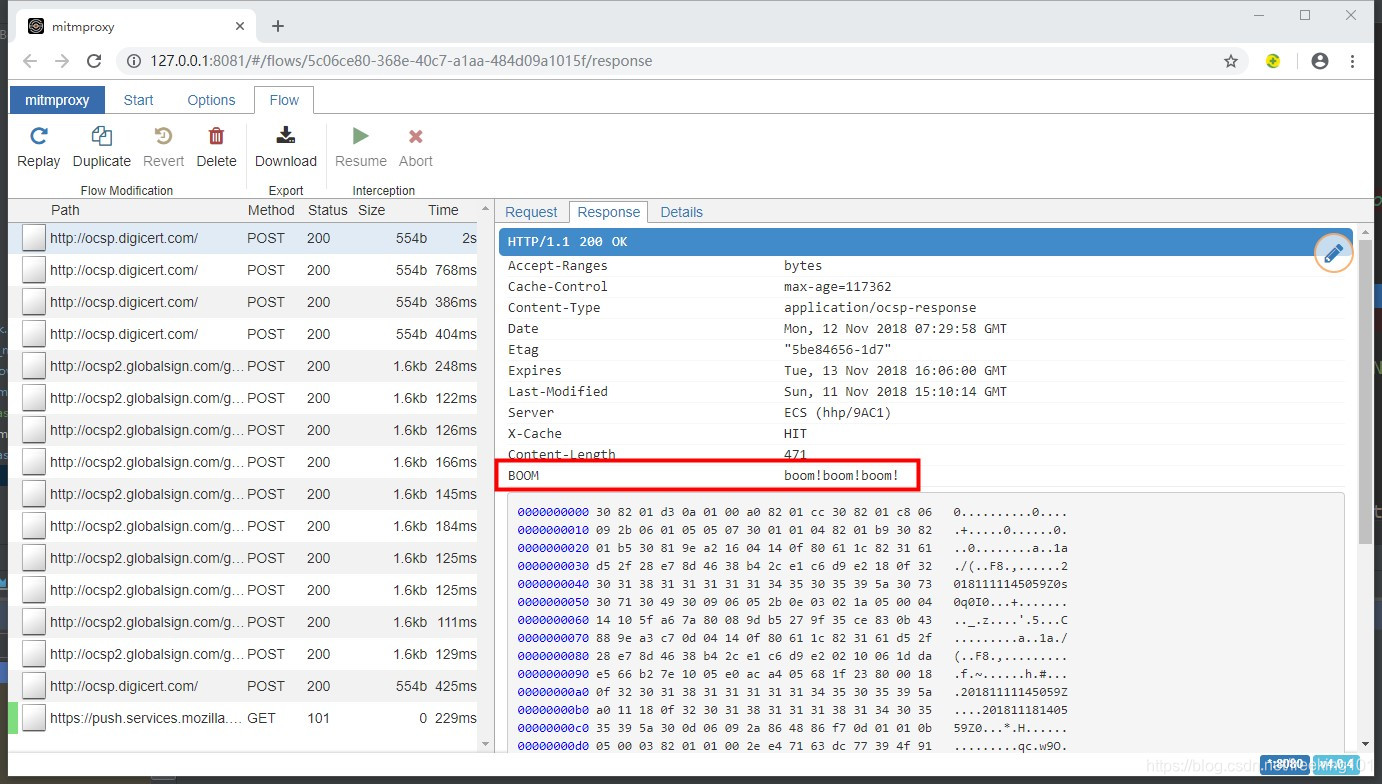
显然 mitmproxy 脚本能做的事情远不止这些,结合Python强大的功能,可以衍生出很多应用途径。除此之外,mitmproxy还提供了强大的API,在这些API的基础上,完全可以自己定制一个实现了特殊功能的专属代理服务器。
经过性能测试,发现 mitmproxy 的效率并不是特别高。如果只是用于调试目的那还好,但如果要用到生产环境,有大量并发请求通过代理的时候,性能还是稍微差点。
工作原理
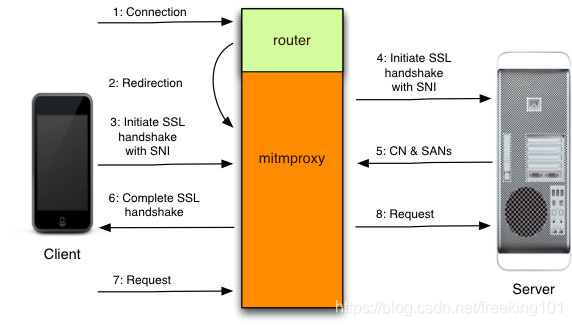
mitmproxy 实现原理:
- 客户端发起一个到 mitmproxy 的连接,并且发出 HTTP CONNECT 请求,
- mitmproxy 作出响应 (200),模拟已经建立了 CONNECT 通信管道,
- 客户端确信它正在和远端服务器会话,然后启动 SSL 连接。在 SSL 连接中指明了它正在连接的主机名 (SNI),
- mitmproxy 连接服务器,然后使用客户端发出的 SNI 指示的主机名建立 SSL 连接,
- 服务器以匹配的 SSL 证书作出响应,这个 SSL 证书里包含生成的拦截证书所必须的通用名 (CN) 和服务器备用名 (SAN),
- mitmproxy 生成拦截证书,然后继续进行与第 3 步暂停的客户端 SSL 握手,
- 客户端通过已经建立的 SSL 连接发送请求,
- mitmproxy 通过第 4 步建立的 SSL 连接传递这个请求给服务器。
mitmproxy 工作步骤:
- 设置系统、浏览器、终端等的代理地址和端口为同一局域网中 mitmproxy 所在电脑的 IP 地址,比如我的 PC 开启 mitmproxy 之后,设置 8080 端口,本地 IP 为 192.168.1.130,那么设置 Android HTTP 代理为 192.168.1.130:8080
- 浏览器或移动端访问 mitm.it 来安装 mitmproxy 提供的证书
- 在 mitmproxy 提供的命令行下,或者 mitmweb 提供的浏览器界面中就能看到 Android 端发出的请求。
安装
“安装 mitmproxy”这句话是有歧义的,既可以指“安装 mitmproxy 工具”,也可以指“安装 python 的 mitmproxy 包”,注意后者是包含前者的。
如果只是拿 mitmproxy 做一个替代 fiddler 的工具,没有什么定制化的需求,那完全只需要“安装 mitmproxy 工具”即可,去 mitmproxy 官网 上下载一个 installer 便可开箱即用,不需要提前准备好 python 开发环境。但显然,这不是这里要讨论的,我们需要的是“安装 python 的 mitmproxy 包”。
安装 python 的 mitmproxy 包除了会得到 mitmproxy 工具外,还会得到开发定制脚本所需要的包依赖,其安装过程并不复杂。
首先需要安装好 python,版本需要不低于 3.6,且安装了附带的包管理工具 pip。不同操作系统安装 python 3 的方式不一,参考 python 的下载页,这里不做展开,假设你已经准备好这样的环境了。
在 linux 中:sudo pip3 install mitmproxy
一旦用户安装上了mitmproxy,那么,在python的dist-packages目录下就会有一个libmproxy的目录。点击进去,如下图所示。
有很多文件,里面最关键的一个文件就是flow.py。里面有从客户端请求的类Request,也有从服务器返回的可以操作的类Response。并且都实现了一些方法可以调用请求或回复的数据,包括请求url,header,body,content等。具体如下:
Request的一些方法:
Response的一些方法如下:
在 windows 中,以管理员身份运行 cmd 或 power shell:pip3 install mitmproxy
在 Mac 上安装与使用 mitmproxy:https://www.cnblogs.com/LanTianYou/p/6542190.html
完成后,系统将拥有 mitmproxy、mitmdump、mitmweb 三个命令,由于 mitmproxy 命令不支持在 windows 系统中运行(这没关系,不用担心),
我们可以拿 mitmdump 测试一下安装是否成功,执行:mitmdump --version
应当可以看到类似于这样的输出:
-
Mitmproxy: 4
.0
.1
-
Python: 3
.6
.5
-
OpenSSL:
OpenSSL 1
.1
.0h 27
Mar 2018
-
Platform:
Windows-10-10
.0
.16299-SP0
安装 CA 证书
官方提供的安装方式:https://docs.mitmproxy.org/stable/concepts-certificates
方法1:
对于mitmproxy 来说,如果想要截获HTTPS请求,就得解决证书认证的问题,就需要设置CA证书,因此需要在通信发生的客户端安装证书,并且设置为受信任的根证书颁布机构。而mitmproxy安装后就会提供一套CA证书,只要客户信任了此证书即可。
当我们初次运行 mitmproxy 或 mitmdump 时,会在当前目录下生成 ~/.mitmproxy文件夹,其中该文件下包含4个文件,这就是我们要的证书了。
localhost:app zhangtao$ mitmdump
Proxy server listening at http://*:8080
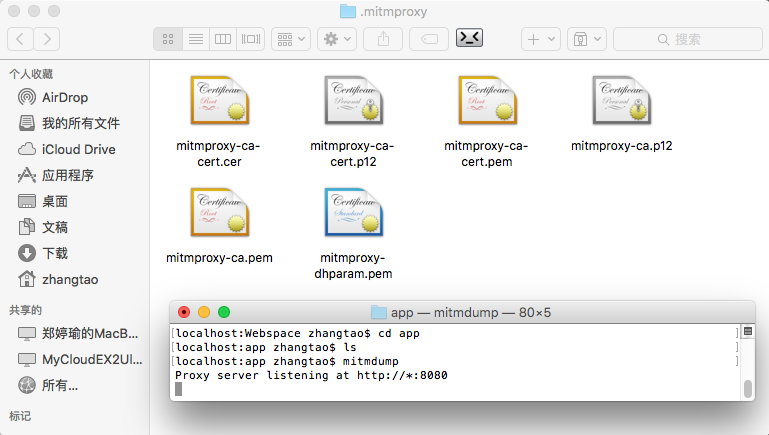
文件说明:
mitmproxy-ca.pemPEM格式的证书私钥mitmproxy-ca-cert.pemPEM格式证书,适用于大多数非Windows平台mitmproxy-ca-cert.p12PKCS12格式的证书,适用于大多数Windows平台mitmproxy-ca-cert.cer与 mitmproxy-ca-cert.pem 相同(只是后缀名不同),适用于大部分Android平台mitmproxy-dhparam.pemPEM格式的秘钥文件,用于增强SSL安全性。
方法2:
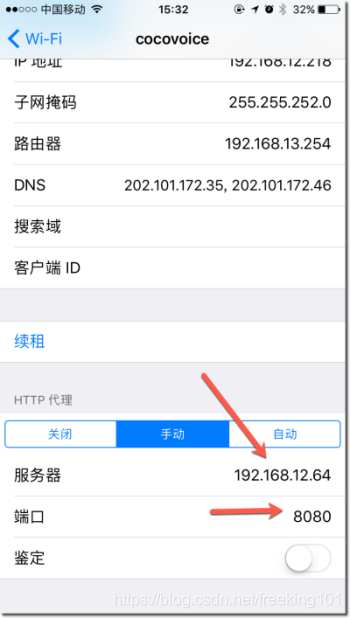
配置 浏览器 和 手机
- 1.电脑和手机连接到同一个 wifi 环境下
- 2.修改浏览器代理服务器地址为运行mitmproxy的那台机器(本机)ip地址,端口设定为你启动mitmproxy时设定的端口,如果没有指定就使用8080
- 3.手机做同样操作,修改wifi链接代理为 【手动】,然后指定ip地址和端口
以手机配置为例:
1. 设置服务器、端口
2 . 安装 CA 证书 (只需要安装一次证书即可)
第一次使用 mitmproxy 的时候需要安装 CA 证书。在手机 或 pc 机上打开浏览器访问 http://mitm.it 这个地址,选择你当前平台的图标,点击安装证书。选择你当前平台的图标,点击安装证书。
在下图中点击Apple安装证书。
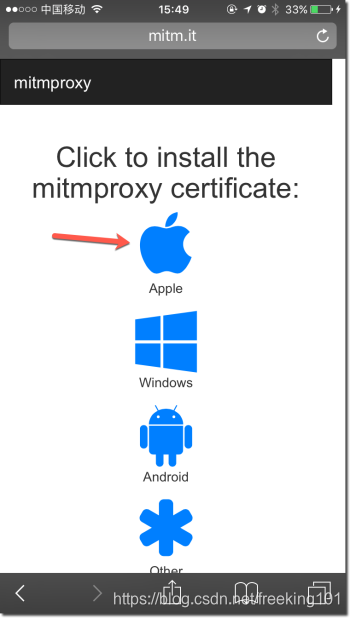
在各端配置好代理后,访问:http://mitm.it
下载 CA 证书,并按照以下方式进行验证。
iOS
- 打开设置-无线局域网-所连接的Wifi-配置代理-手动
- 填上代理服务器IP和端口
- 打开设置-通用-关于本机-证书信任设置
- 开启mitmproxy选项。
Android
- 打开设置-WLAN-长按所连接的网络-修改网络-高级选项-手动
- 填入代理服务器IP和端口
- 打开设置-安全-信任的凭据
- 查看安装的证书是否存在
macOS
- 打开系统配置(System Preferences.app)- 网络(Network)- 高级(Advanced)- 代理(Proxies)- Web Proxy(HTTP)和Secure Web Proxy(HTTPS)
- 填上代理服务器IP和端口
- 打开Keychain Access.app
- 选择login(Keychains)和Certificates(Category)中找到mitmproxy
- 点击mitmproxy,在Trust中选择Always Trust
运行启动(启动 mitmproxy 三种方式)
在完成 mitmproxy 的安装之后,mitm 提供的三个命令。要启动 mitmproxy, 用 mitmproxy、mitmdump、mitmweb 这三个命令中的任意一个即可,这三个命令功能一致,且都可以加载自定义脚本,唯一的区别是交互界面的不同。
- mitmproxy 会提供一个在终端下的图形界面,具有修改请求和响应,流量重放等功能,具体操作方式有点 vim 的风格
- mitmdump 可设定规则保存或重放请求和响应,mitmdump 的特点是支持 inline 脚本,由于拥有可以修改 request 和 response 中每一个细节的能力,批量测试,劫持等都可以轻松实现
- mitmweb 提供的一个简单 web 界面,简单实用,初学者或者对终端命令行不熟悉的可以用 mitmweb 界面
1. mitmproxy 直接启动
mitmproxy 命令启动后,会提供一个命令行界面,用户可以实时看到发生的请求,并通过命令过滤请求,查看请求数据。形如:
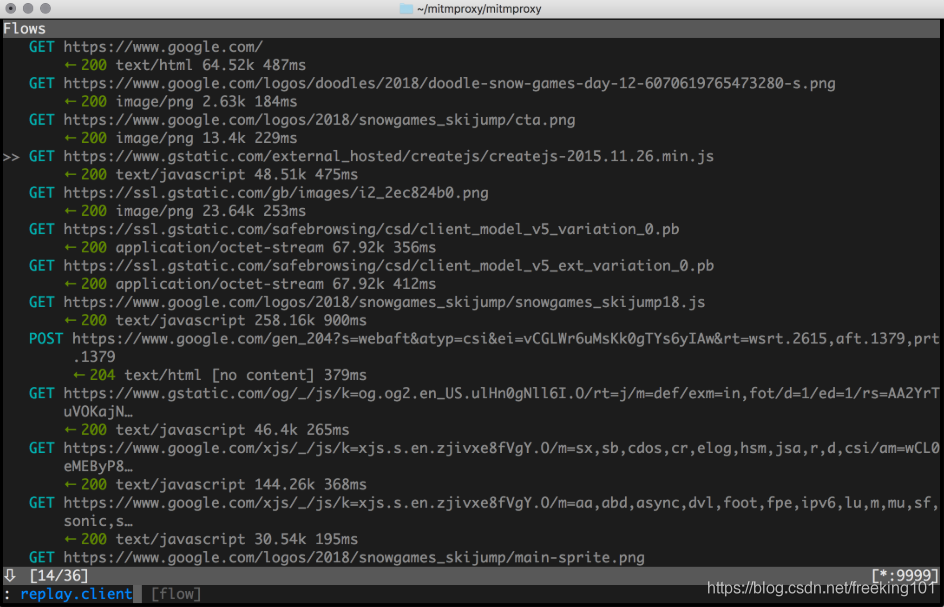
mitmproxy 基本使用
可以使用 mitmproxy -h 来查看 mitmproxy 的参数及使用方法。常用的几个命令参数:
-p PORT, --port PORT设置 mitmproxy 的代理端口-T, --transparent设置透明代理--socks设置 SOCKS5 代理-s "script.py --bar", --script "script.py --bar"来执行脚本,通过双引号来添加参数-t FILTER过滤参数
在 mitmproxy 命令模式下,在终端显示请求流,可以通过 Shift + ? 来开启帮助查看当前页面可用的命令。
-
基本快捷键
-
-
b 保存请求 / 返回头
-
C 将请求内容导出到粘贴板,按 C 之后会有选择导出哪一部分
-
d 删除 flow 请求
-
E 将 flow 导出到文件
-
w 保存所有 flow 或者该 flow
-
W 保存该 flow
-
L 加载保存的 Flow
-
m 添加 / 取消 Mark 标记,会在请求列表该请求前添加红色圆圈
-
z 清空 flow list 和 eventlog
-
/ 在详情界面,可以使用 / 来搜索,大小写敏感
-
i 开启 interception pattern 拦截请求
-
-
移动
-
-
j, k 上下
-
h, l 左右
-
g, G go
to beginning,
end
-
space 下一页
-
pg up/down 上一页 / 下一页
-
ctrl+b/ctrl+f 上一页 / 下一页
-
arrows 箭头 上下左右
-
-
-
全局快捷键
-
q 退出,或者后退
-
Q 不提示直接退出
- mitmproxy的按键操作说明
| 按键 | 说明 |
|---|---|
| q | 退出(相当于返回键,可一级一级返回) |
| d | 删除当前(黄色箭头)指向的链接 |
| D | 恢复刚才删除的请求 |
| G | 跳到最新一个请求 |
| g | 跳到第一个请求 |
| C | 清空控制台(C是大写) |
| i | 可输入需要拦截的文件或者域名(逗号需要用\来做转译,栗子:feezu.cn) |
| a | 放行请求 |
| A | 放行所有请求 |
| ? | 查看界面帮助信息 |
| ^ v | 上下箭头移动光标 |
| enter | 查看光标所在列的内容 |
| tab | 分别查看 Request 和 Response 的详细信息 |
| / | 搜索body里的内容 |
| esc | 退出编辑 |
| e | 进入编辑模式 |
同样在 mitmproxy 中不同界面中使用 ? 可以获取不同的帮助,在请求详细信息中 m 快捷键的作用就完全不同 m 在响应结果中,输入 m 可以选择 body 的呈现方式,比如 json,xml 等 e 编辑请求、响应 a 发送编辑后的请求、响应。 因此在熟悉使用 ? 之后,多次使用并熟悉快捷键即可。就如同在 Linux 下要熟悉使用 man 命令一样,在不懂地方请教 Google 一样,应该是习惯性动作。多次反复之后就会变得非常数量。
2. mitmweb 命令启动
mitmweb 命令启动后,会提供一个 web 界面,用户可以实时看到发生的请求,并通过 GUI 交互来过滤请求,查看请求数据。形如:
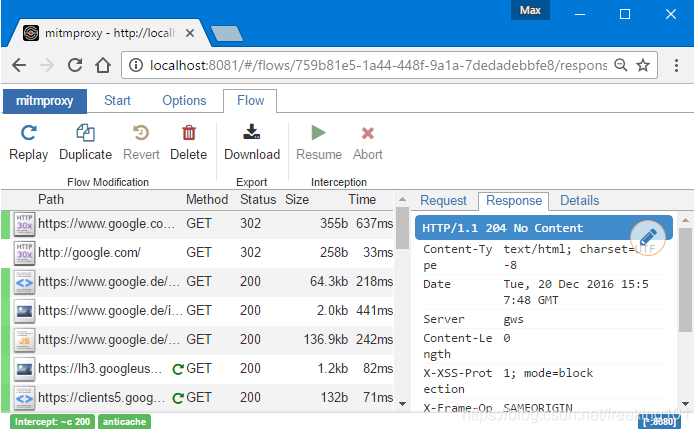
3. mitmdump 命令启动
mitmdump 命令启动后——你应该猜到了,没有界面,程序默默运行,所以 mitmdump 无法提供过滤请求、查看数据的功能,只能结合自定义脚本,默默工作。
4. 启动示例
由于 mitmproxy 命令的交互操作稍显繁杂且不支持 windows 系统,而我们主要的使用方式又是载入自定义脚本,并不需要交互,所以原则上说只需要 mitmdump 即可,但考虑到有交互界面可以更方便排查错误,所以这里以 mitmweb 命令为例。实际使用中可以根据情况选择任何一个命令。
启动 mitmproxy:mitmweb
应当看到如下输出:
-
Web server listening at http:
//127.0.0.1:8081/
-
Proxy server listening at http:
//*:8080
mitmproxy 绑定了 *:8080 作为代理端口,并提供了一个 web 交互界面在 127.0.0.1:8081。
现在可以测试一下代理,让 Chrome 以 mitmproxy 为代理并忽略证书错误。为了不影响平时正常使用,我们不去改 Chrome 的配置,而是通过命令行带参数起一个 Chrome。如果你不使用 Chrome 而是其他浏览器,也可以搜一下对应的启动参数是什么,应该不会有什么坑。此外示例仅以 windows 系统为例,因为使用 linux 或 mac 开发的同学应该更熟悉命令行的使用才对,应当能自行推导出在各自环境中对应的操作。
由于 Chrome 要开始赴汤蹈火走代理了,为了方便继续在 web 界面上与 mitmproxy 交互,我们委屈求全使用 Edge 或其他浏览器打开 127.0.0.1:8081。插一句,我用 Edge 实在是因为机器上没其他浏览器了(IE 不算),Edge 有一个默认禁止访问回环地址的狗屁设定,详见解决方案。
接下来关闭所有 Chrome 窗口,否则命令行启动时的附加参数将失效。打开 cmd,执行:
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
前面那一长串是 Chrome 的的安装路径,应当根据系统实际情况修改,后面两参数设置了代理地址并强制忽略掉证书错误。用 Chrome 打开一个网站,可以看到:
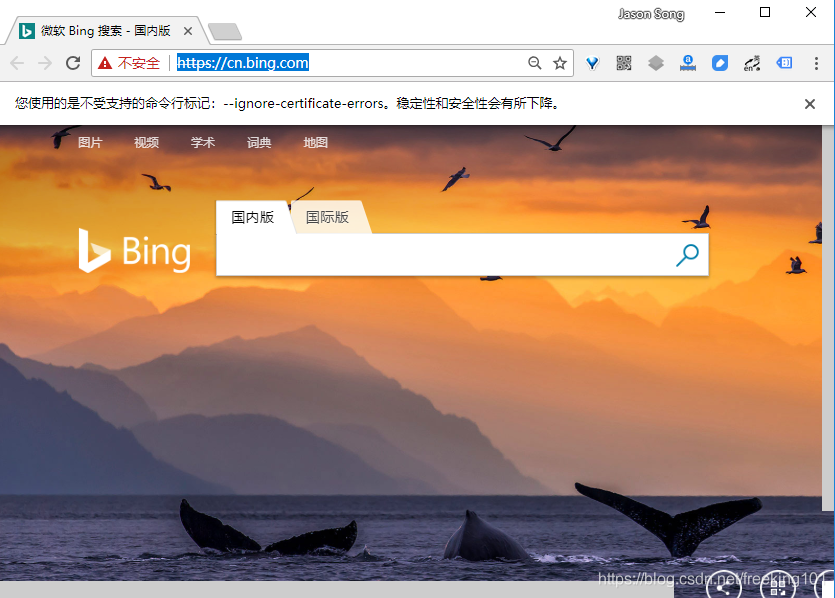
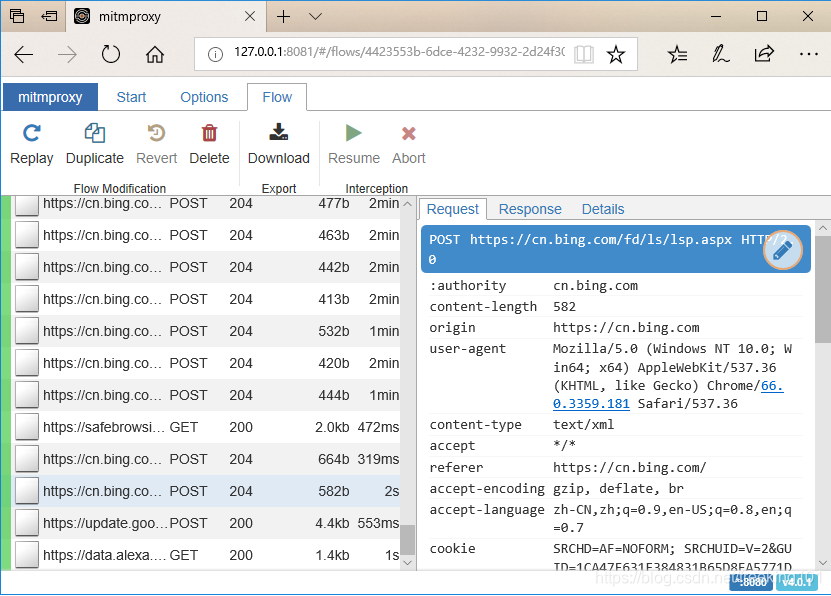
同时在 Edge 上可以看到:
脚本
重点:一个完整的 HTTP flow 会依次触发 requestheaders, request, responseheaders 和 response。
完成了上述工作,我们已经具备了操作 mitmproxy 的基本能力 了。接下来开始开发自定义脚本,这才是 mitmproxy 真正强大的地方。使用 -s 参数 制定 inline 脚本:
mitmproxy -s script.py
比如将指定 url 的请求指向新的地址
用于调试 Android 或者 iOS 客户端,打包比较复杂的时候,强行将客户端请求从线上地址指向本地调试地址。可以使用 mitmproxy scripting API mitmproxy 提供的事件驱动接口。
加上将线上地址,指向本地 8085 端口,文件为 redirect_request.py
-
#!/usr/bin/env python
-
# -*- coding: UTF-8 -*-
-
def request(flow):
-
if flow.request.pretty_host ==
'api.github.com':
-
flow.request.host =
'127.0.0.1'
-
flow.request.port =
8085
则使用 mitmweb -s redirect_request.py 来调用此脚本,则通过 mitm 的请求都会指向本地 http://127.0.0.1:8085。
更多的脚本可以参考
启用 SOCKS5 代理
添加参数 --socks 可以使用 mitmproxy 的 SOCK5 代理
透明代理
透明代理是指将网络流量直接重定向到网络端口,不需要客户端做任何设置。这个特性使得透明代理非常适合不能对客户端进行配置的时候,比如说 Android 应用等等。
脚本编写遵循的规定
脚本的编写需要遵循 mitmproxy 规定的套路,这样的套路有两个。
第一个是:编写一个 py 文件供 mitmproxy 加载,文件中定义了若干函数,这些函数实现了某些 mitmproxy 提供的事件,mitmproxy 会在某个事件发生时调用对应的函数,形如:
-
import mitmproxy.http
-
from mitmproxy
import ctx
-
-
num =
0
-
-
-
def request(flow: mitmproxy.http.HTTPFlow):
-
global num
-
num = num +
1
-
ctx.log.info(
"We've seen %d flows" % num)
第二个是:编写一个 py 文件供 mitmproxy 加载,文件定义了变量 addons,addons 是个数组,每个元素是一个类实例,这些类有若干方法,这些方法实现了某些 mitmproxy 提供的事件,mitmproxy 会在某个事件发生时调用对应的方法。这些类,称为一个个 addon,比如一个叫 Counter 的 addon:
-
import mitmproxy.http
-
from mitmproxy
import ctx
-
-
-
class Counter:
-
def __init__(self):
-
self.num =
0
-
-
def request(self, flow: mitmproxy.http.HTTPFlow):
-
self.num = self.num +
1
-
ctx.log.info(
"We've seen %d flows" % self.num)
-
-
-
addons = [
-
Counter()
-
]
这里强烈建议使用第二种套路,直觉上就会感觉第二种套路更为先进,使用会更方便也更容易管理和拓展。况且这也是官方内置的一些 addon 的实现方式。
我们将上面第二种套路的示例代码存为 addons.py,再重新启动 mitmproxy:mitmweb -s addons.py
当浏览器使用代理进行访问时,就应该能看到控制台里有类似这样的日志:
-
Web server listening at http:
//127.0.0.1:8081/
-
Loading script addons.py
-
Proxy server listening at http:
//*:8080
-
We
've seen 1 flows
-
……
-
……
-
We've seen
2 flows
-
……
-
We
've seen 3 flows
-
……
-
We've seen
4 flows
-
……
-
……
-
We
've seen 5 flows
-
……
这就说明自定义脚本生效了。
---------------------------------------------------------------------------------------------------------------------------------
mitmproxy启动时可以使用 -s 参数导入外部的脚本进行拦截处理
比如我要修改一个每个链接的响应头的
python脚本:
1、简单方法
-
from mitmproxy
import http
-
-
def response(flow: http.HTTPFlow) -> None:
-
flow.response.headers[
"server"] =
"nginx"
2、使用类
-
class ModifyHeader:
-
def response(self, flow):
-
flow.response.headers[
"serverr"] =
"nginx"
-
-
-
def start():
-
return ModifyHeader()
保存为 modifyheader.py。然后启动 mitmdump -s modifyheader.py,就会把代理抓到包的每个响应头的Server都改成“nginx”
官方参考例子:https://github.com/mitmproxy/mitmproxy/tree/master/examples
事件
上述的脚本估计不用我解释相信大家也看明白了,就是当 request 发生时,计数器加一,并打印日志。这里对应的是 request 事件,那拢共有哪些事件呢?不多,也不少,这里详细介绍一下。
事件针对不同生命周期分为 5 类。“生命周期”这里指在哪一个层面看待事件,举例来说,同样是一次 web 请求,我可以理解为“HTTP 请求 -> HTTP 响应”的过程,也可以理解为“TCP 连接 -> TCP 通信 -> TCP 断开”的过程。那么,如果我想拒绝来个某个 IP 的客户端请求,应当注册函数到针对 TCP 生命周期 的 tcp_start 事件,又或者,我想阻断对某个特定域名的请求时,则应当注册函数到针对 HTTP 声明周期的 http_connect 事件。其他情况同理。
下面一段估计会又臭又长,如果你没有耐心看完,那至少看掉针对 HTTP 生命周期的事件,然后跳到示例。
1. 针对 HTTP 生命周期
def http_connect(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 收到了来自客户端的 HTTP CONNECT 请求。在 flow 上设置非 2xx 响应将返回该响应并断开连接。CONNECT 不是常用的 HTTP 请求方法,目的是与服务器建立代理连接,仅是 client 与 proxy 的之间的交流,所以 CONNECT 请求不会触发 request、response 等其他常规的 HTTP 事件。
def requestheaders(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自客户端的 HTTP 请求的头部被成功读取。此时 flow 中的 request 的 body 是空的。
def request(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自客户端的 HTTP 请求被成功完整读取。
def responseheaders(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自服务端的 HTTP 响应的头部被成功读取。此时 flow 中的 response 的 body 是空的。
def response(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自服务端端的 HTTP 响应被成功完整读取。
def error(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 发生了一个 HTTP 错误。比如无效的服务端响应、连接断开等。注意与“有效的 HTTP 错误返回”不是一回事,后者是一个正确的服务端响应,只是 HTTP code 表示错误而已。
2. 针对 TCP 生命周期
def tcp_start(self, flow: mitmproxy.tcp.TCPFlow):
(Called when) 建立了一个 TCP 连接。
def tcp_message(self, flow: mitmproxy.tcp.TCPFlow):
(Called when) TCP 连接收到了一条消息,最近一条消息存于 flow.messages[-1]。消息是可修改的。
def tcp_error(self, flow: mitmproxy.tcp.TCPFlow):
(Called when) 发生了 TCP 错误。
def tcp_end(self, flow: mitmproxy.tcp.TCPFlow):
(Called when) TCP 连接关闭。
3. 针对 Websocket 生命周期
def websocket_handshake(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 客户端试图建立一个 websocket 连接。可以通过控制 HTTP 头部中针对 websocket 的条目来改变握手行为。flow 的 request 属性保证是非空的的。
def websocket_start(self, flow: mitmproxy.websocket.WebSocketFlow):
(Called when) 建立了一个 websocket 连接。
def websocket_message(self, flow: mitmproxy.websocket.WebSocketFlow):
(Called when) 收到一条来自客户端或服务端的 websocket 消息。最近一条消息存于 flow.messages[-1]。消息是可修改的。目前有两种消息类型,对应 BINARY 类型的 frame 或 TEXT 类型的 frame。
def websocket_error(self, flow: mitmproxy.websocket.WebSocketFlow):
(Called when) 发生了 websocket 错误。
def websocket_end(self, flow: mitmproxy.websocket.WebSocketFlow):
(Called when) websocket 连接关闭。
4. 针对网络连接生命周期
def clientconnect(self, layer: mitmproxy.proxy.protocol.Layer):
(Called when) 客户端连接到了 mitmproxy。注意一条连接可能对应多个 HTTP 请求。
def clientdisconnect(self, layer: mitmproxy.proxy.protocol.Layer):
(Called when) 客户端断开了和 mitmproxy 的连接。
def serverconnect(self, conn: mitmproxy.connections.ServerConnection):
(Called when) mitmproxy 连接到了服务端。注意一条连接可能对应多个 HTTP 请求。
def serverdisconnect(self, conn: mitmproxy.connections.ServerConnection):
(Called when) mitmproxy 断开了和服务端的连接。
def next_layer(self, layer: mitmproxy.proxy.protocol.Layer):
(Called when) 网络 layer 发生切换。你可以通过返回一个新的 layer 对象来改变将被使用的 layer。详见 layer 的定义。
5. 通用生命周期
def configure(self, updated: typing.Set[str]):
(Called when) 配置发生变化。updated 参数是一个类似集合的对象,包含了所有变化了的选项。在 mitmproxy 启动时,该事件也会触发,且 updated 包含所有选项。
def done(self):
(Called when) addon 关闭或被移除,又或者 mitmproxy 本身关闭。由于会先等事件循环终止后再触发该事件,所以这是一个 addon 可以看见的最后一个事件。由于此时 log 也已经关闭,所以此时调用 log 函数没有任何输出。
def load(self, entry: mitmproxy.addonmanager.Loader):
(Called when) addon 第一次加载时。entry 参数是一个 Loader 对象,包含有添加选项、命令的方法。这里是 addon 配置它自己的地方。
def log(self, entry: mitmproxy.log.LogEntry):
(Called when) 通过 mitmproxy.ctx.log 产生了一条新日志。小心不要在这个事件内打日志,否则会造成死循环。
def running(self):
(Called when) mitmproxy 完全启动并开始运行。此时,mitmproxy 已经绑定了端口,所有的 addon 都被加载了。
def update(self, flows: typing.Sequence[mitmproxy.flow.Flow]):
(Called when) 一个或多个 flow 对象被修改了,通常是来自一个不同的 addon。
From:https://www.cnblogs.com/c-x-a/p/9753526.html
主要 events 一览表
需要修改各种事件内容时,重写以下对应方法,这里主要用的是request、response方法
import typing
import mitmproxy.addonmanager
import mitmproxy.connections
import mitmproxy.http
import mitmproxy.log
import mitmproxy.tcp
import mitmproxy.websocket
import mitmproxy.proxy.protocol
-
def requestheaders(self, flow: mitmproxy.http.HTTPFlow):
-
"""
-
HTTP request headers were successfully read. At this point, the body
-
is empty.
-
"""
-
-
def request(self, flow: mitmproxy.http.HTTPFlow):
-
"""
-
The full HTTP request has been read.
-
"""
-
-
def responseheaders(self, flow: mitmproxy.http.HTTPFlow):
-
"""
-
HTTP response headers were successfully read. At this point, the body
-
is empty.
-
"""
-
-
def response(self, flow: mitmproxy.http.HTTPFlow):
-
"""
-
The full HTTP response has been read.
-
"""
-
-
def error(self, flow: mitmproxy.http.HTTPFlow):
-
"""
-
An HTTP error has occurred, e.g. invalid server responses, or
-
interrupted connections. This is distinct from a valid server HTTP
-
error response, which is simply a response with an HTTP error code.
-
"""
-
-
# TCP lifecycle
-
def tcp_start(self, flow: mitmproxy.tcp.TCPFlow):
-
"""
-
A TCP connection has started.
-
"""
-
-
def tcp_message(self, flow: mitmproxy.tcp.TCPFlow):
-
"""
-
A TCP connection has received a message. The most recent message
-
will be flow.messages[-1]. The message is user-modifiable.
-
"""
-
-
def tcp_error(self, flow: mitmproxy.tcp.TCPFlow):
-
"""
-
A TCP error has occurred.
-
"""
-
-
def tcp_end(self, flow: mitmproxy.tcp.TCPFlow):
-
"""
-
A TCP connection has ended.
-
"""
-
-
# Websocket lifecycle
-
def websocket_handshake(self, flow: mitmproxy.http.HTTPFlow):
-
"""
-
Called when a client wants to establish a WebSocket connection. The
-
WebSocket-specific headers can be manipulated to alter the
-
handshake. The flow object is guaranteed to have a non-None request
-
attribute.
-
"""
-
-
def websocket_start(self, flow: mitmproxy.websocket.WebSocketFlow):
-
"""
-
A websocket connection has commenced.
-
"""
-
-
def websocket_message(self, flow: mitmproxy.websocket.WebSocketFlow):
-
"""
-
Called when a WebSocket message is received from the client or
-
server. The most recent message will be flow.messages[-1]. The
-
message is user-modifiable. Currently there are two types of
-
messages, corresponding to the BINARY and TEXT frame types.
-
"""
-
-
def websocket_error(self, flow: mitmproxy.websocket.WebSocketFlow):
-
"""
-
A websocket connection has had an error.
-
"""
-
-
def websocket_end(self, flow: mitmproxy.websocket.WebSocketFlow):
-
"""
-
A websocket connection has ended.
-
"""
-
-
# Network lifecycle
-
def clientconnect(self, layer: mitmproxy.proxy.protocol.Layer):
-
"""
-
A client has connected to mitmproxy. Note that a connection can
-
correspond to multiple HTTP requests.
-
"""
-
-
def clientdisconnect(self, layer: mitmproxy.proxy.protocol.Layer):
-
"""
-
A client has disconnected from mitmproxy.
-
"""
-
-
def serverconnect(self, conn: mitmproxy.connections.ServerConnection):
-
"""
-
Mitmproxy has connected to a server. Note that a connection can
-
correspond to multiple requests.
-
"""
-
-
def serverdisconnect(self, conn: mitmproxy.connections.ServerConnection):
-
"""
-
Mitmproxy has disconnected from a server.
-
"""
-
-
def next_layer(self, layer: mitmproxy.proxy.protocol.Layer):
-
"""
-
Network layers are being switched. You may change which layer will
-
be used by returning a new layer object from this event.
-
"""
-
-
# General lifecycle
-
def configure(self, updated: typing.Set[str]):
-
"""
-
Called when configuration changes. The updated argument is a
-
set-like object containing the keys of all changed options. This
-
event is called during startup with all options in the updated set.
-
"""
-
-
def done(self):
-
"""
-
Called when the addon shuts down, either by being removed from
-
the mitmproxy instance, or when mitmproxy itself shuts down. On
-
shutdown, this event is called after the event loop is
-
terminated, guaranteeing that it will be the final event an addon
-
sees. Note that log handlers are shut down at this point, so
-
calls to log functions will produce no output.
-
"""
-
-
def load(self, entry: mitmproxy.addonmanager.Loader):
-
"""
-
Called when an addon is first loaded. This event receives a Loader
-
object, which contains methods for adding options and commands. This
-
method is where the addon configures itself.
-
"""
-
-
def log(self, entry: mitmproxy.log.LogEntry):
-
"""
-
Called whenever a new log entry is created through the mitmproxy
-
context. Be careful not to log from this event, which will cause an
-
infinite loop!
-
"""
-
-
def running(self):
-
"""
-
Called when the proxy is completely up and running. At this point,
-
you can expect the proxy to be bound to a port, and all addons to be
-
loaded.
-
"""
-
-
def update(self, flows: typing.Sequence[mitmproxy.flow.Flow]):
-
"""
-
Update is called when one or more flow objects have been modified,
-
usually from a different addon.
-
"""
针对 http,常用的 API
-
# http.HTTPFlow 实例 flow
-
flow.
request.headers # 获取所有头信息,包含Host、User-Agent、Content-type等字段
-
flow.
request.url # 完整的请求地址,包含域名及请求参数,但是不包含放在body里面的请求参数
-
flow.
request.pretty_url # 同flow.
request.url目前没看出什么差别
-
flow.
request.host # 域名
-
flow.
request.method # 请求方式。POST、
GET等
-
flow.
request.scheme # 什么请求 ,如 https
-
flow.
request.path # 请求的路径,url除域名之外的内容
-
flow.
request.get_text() # 请求中body内容,有一些http会把请求参数放在body里面,那么可通过此方法获取,返回字典类型
-
flow.
request.query # 返回MultiDictView类型的数据,url直接带的键值参数
-
flow.
request.get_content() # bytes,结果如flow.
request.get_text()
-
flow.
request.raw_content # bytes,结果如flow.
request.get_content()
-
flow.
request.urlencoded_form # MultiDictView,content-type:application/x-www-form-urlencoded 时的请求参数,不包含url直接带的键值参数
-
flow.
request.multipart_form # MultiDictView,content-type:multipart/form-data 时的请求参数,不包含url直接带的键值参数
以上均为获取 request 信息的一些常用方法,对于 response,同理
-
flow
.response
.status_code # 状态码
-
flow
.response
.text # 返回内容,已解码
-
flow
.response
.content # 返回内容,二进制
-
flow
.response
.setText() # 修改返回内容,不需要转码
以上为不完全列举
示例
修改response内容,这里是服务器已经有返回了结果,再更改,也可以做不经过服务器处理,直接返回,看需求
def response(flow:http.HTTPFlow)-> None:
#特定接口需要返回1001结果
interface_list=["page/**"] #由于涉及公司隐私问题,隐藏实际的接口
-
url_path=flow.request.path
-
if url_path.split(
"?")[
0]
in interface_list:
-
ctx.log.info(
"#"*
50)
-
ctx.log.info(
"待修改路径的内容:"+url_path)
-
ctx.log.info(
"修改成:1001错误返回")
-
ctx.log.info(
"修改前:\n")
-
ctx.log.info(flow.response.text)
-
flow.response.set_text(json.dumps({
"result":
"1001",
"message":
"服务异常"}))
#修改,使用set_text不用转码
-
ctx.log.info(
"修改后:\n")
-
ctx.log.info(flow.response.text)
-
ctx.log.info(
"#"*
50)
-
elif flow.request.host
in host_list:
#host_list 域名列表,作为全局变量,公司有多个域名,也隐藏
-
ctx.log.info(
"response= "+flow.response.text)
示 例
估计看了那么多的事件你已经晕了,正常,鬼才会记得那么多事件。事实上考虑到 mitmproxy 的实际使用场景,大多数情况下我们只会用到针对 HTTP 生命周期的几个事件。再精简一点,甚至只需要用到 http_connect、request、response 三个事件就能完成大多数需求了。
这里以一个稍微有点黑色幽默的例子,覆盖这三个事件,展示如果利用 mitmproxy 工作。
需求是这样的:
- 因为百度搜索是不靠谱的,所有当客户端发起百度搜索时,记录下用户的搜索词,再修改请求,将搜索词改为“360 搜索”;
- 因为 360 搜索还是不靠谱的,所有当客户端访问 360 搜索时,将页面中所有“搜索”字样改为“请使用谷歌”。
- 因为谷歌是个不存在的网站,所有就不要浪费时间去尝试连接服务端了,所有当发现客户端试图访问谷歌时,直接断开连接。
- 将上述功能组装成名为 Joker 的 addon,并保留之前展示名为 Counter 的 addon,都加载进 mitmproxy。
第一个需求需要篡改客户端请求,所以实现一个 request 事件:
-
def request(self, flow: mitmproxy.http.HTTPFlow):
-
# 忽略非百度搜索地址
-
if flow.request.host !=
"www.baidu.com"
or
not flow.request.path.startswith(
"/s"):
-
return
-
-
# 确认请求参数中有搜索词
-
if
"wd"
not
in flow.request.query.keys():
-
ctx.log.warn(
"can not get search word from %s" % flow.request.pretty_url)
-
return
-
-
# 输出原始的搜索词
-
ctx.log.info(
"catch search word: %s" % flow.request.query.get(
"wd"))
-
# 替换搜索词为“360搜索”
-
flow.request.query.set_all(
"wd", [
"360搜索"])
第二个需求需要篡改服务端响应,所以实现一个 response 事件:
-
def response(self, flow: mitmproxy.http.HTTPFlow):
-
# 忽略非 360 搜索地址
-
if flow.request.host !=
"www.so.com":
-
return
-
-
# 将响应中所有“搜索”替换为“请使用谷歌”
-
text = flow.response.get_text()
-
text = text.replace(
"搜索",
"请使用谷歌")
-
flow.response.set_text(text)
第三个需求需要拒绝客户端请求,所以实现一个 http_connect 事件:
-
def http_connect(self, flow: mitmproxy.http.HTTPFlow):
-
# 确认客户端是想访问 www.google.com
-
if flow.request.host ==
"www.google.com":
-
# 返回一个非 2xx 响应断开连接
-
flow.response = http.HTTPResponse.make(
404)
为了实现第四个需求,我们需要将代码整理一下,即易于管理也易于查看。
创建一个 joker.py 文件,内容为:
-
import mitmproxy.http
-
from mitmproxy
import ctx, http
-
-
-
class Joker:
-
def request(self, flow: mitmproxy.http.HTTPFlow):
-
if flow.request.host !=
"www.baidu.com"
or
not flow.request.path.startswith(
"/s"):
-
return
-
-
if
"wd"
not
in flow.request.query.keys():
-
ctx.log.warn(
"can not get search word from %s" % flow.request.pretty_url)
-
return
-
-
ctx.log.info(
"catch search word: %s" % flow.request.query.get(
"wd"))
-
flow.request.query.set_all(
"wd", [
"360搜索"])
-
-
def response(self, flow: mitmproxy.http.HTTPFlow):
-
if flow.request.host !=
"www.so.com":
-
return
-
-
text = flow.response.get_text()
-
text = text.replace(
"搜索",
"请使用谷歌")
-
flow.response.set_text(text)
-
-
def http_connect(self, flow: mitmproxy.http.HTTPFlow):
-
if flow.request.host ==
"www.google.com":
-
flow.response = http.HTTPResponse.make(
404)
创建一个 counter.py 文件,内容为:
-
import mitmproxy.http
-
from mitmproxy
import ctx
-
-
-
class Counter:
-
def __init__(self):
-
self.num =
0
-
-
def request(self, flow: mitmproxy.http.HTTPFlow):
-
self.num = self.num +
1
-
ctx.log.info(
"We've seen %d flows" % self.num)
创建一个 addons.py 文件,内容为:
-
import counter
-
import joker
-
-
addons = [
-
counter.Counter(),
-
joker.Joker(),
-
]
将三个文件放在相同的文件夹,在该文件夹内启动命令行,运行:mitmweb -s addons.py
老规矩,关闭所有 Chrome 窗口,从命令行中启动 Chrome 并指定代理且忽略证书错误。
测试一下运行效果:
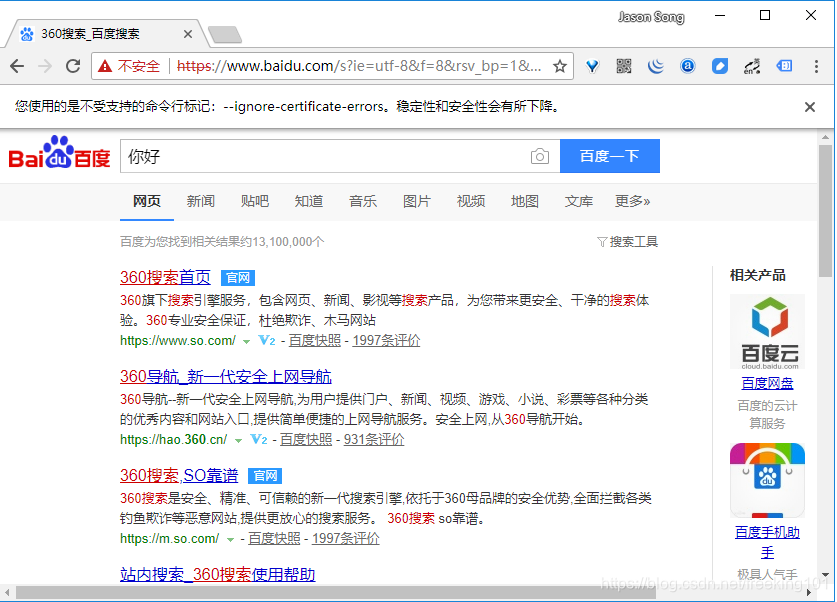
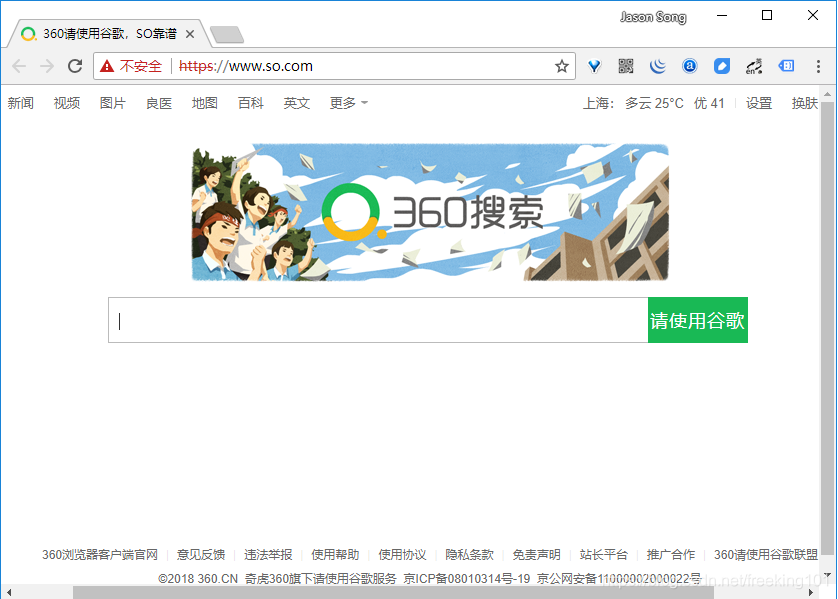

脚本编写
From:https://www.jianshu.com/p/0eb46f21fee9
GitHub:https://github.com/ctwj/mitm_exam
编写脚本的话,主要用到的有两个东西
- Event
- API
1. Event 事件
事件里面有3个事件是比较重要的
start 启动的时候被调用,会替换当前的插件, 可以用此事件注册过滤器.
request(flow) 当发送请求时,被调用.
response(flow) 当接收到回复时被调用.
2. API
三个比较重要的数据结构
mitmproxy.models.http.HTTPRequest
mitmproxy.models.http.HTTPResponse
mitmproxy.models.http.HTTPFlow
在编写脚本的时候,如果不知道该怎么写,传过来的参数里面有什么,去 (https://docs.mitmproxy.org/stable) 查看这些就对了.
先上代码:头脑王者即时显示答案脚本
-
#!/usr/bin/env python
-
#coding=utf-8
-
import sys
-
import json
-
from mitmproxy
import flowfilter
-
from pymongo
import MongoClient
-
reload(sys)
-
sys.setdefaultencoding(
'utf-8')
-
-
'''
-
头脑王者即时显示答案脚本
-
'''
-
-
class TNWZ:
-
'''
-
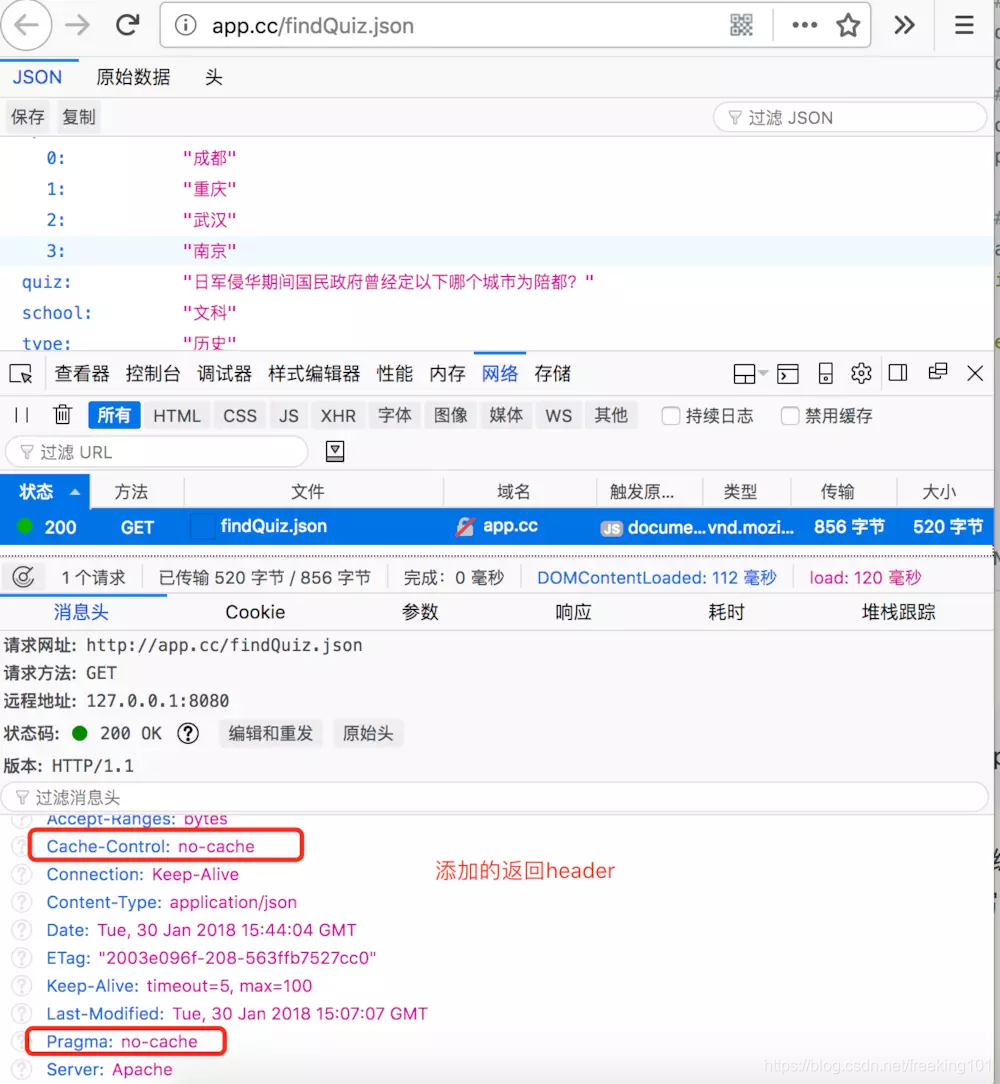
从抓包可以看到 问题包的链接最后是 findQuiz
-
'''
-
def __init__(self):
-
#添加一个过滤器,只处理问题包
-
self.filter = flowfilter.parse(
'~u findQuiz')
-
#连接答案数据库
-
self.conn = MongoClient(
'localhost',
27017)
-
self.db = self.conn.tnwz
-
self.answer_set = self.db.quizzes
-
-
def request(self, flow):
-
'''
-
演示request事件效果, 请求的时候输出提示
-
:param flow:
-
:return:
-
'''
-
if flowfilter.match(self.filter,flow):
-
-
print(
u'准备请求答案')
-
-
def responseheaders(self, flow):
-
'''
-
演示responseheaders事件效果, 添加头信息
-
:param flow:
-
:return:
-
'''
-
if flowfilter.match(self.filter, flow):
-
flow.response.headers[
'Cache-Control'] =
'no-cache'
-
flow.response.headers[
'Pragma'] =
'no-cache'
-
-
def response(self, flow):
-
'''
-
HTTPEvent 下面所有事件参数都是 flow 类型 HTTPFlow
-
可以在API下面查到 HTTPFlow, 下面有一个属性response 类型 TTPResponse
-
HTTPResponse 有个属性为 content 就是response在内容,更多属性可以查看 文档
-
:param flow:
-
:return:
-
'''
-
-
if flowfilter.match(self.filter, flow):
-
#匹配上后证明抓到的是问题了, 查答案
-
data = flow.response.content
-
quiz = json.loads(data)
-
#获取问题
-
question = quiz[
'quiz']
-
print(question)
-
-
#获取答案
-
answer = self.answer_set.find_one({
"quiz":question})
-
if answer
is
None:
-
print(
'no answer')
-
else:
-
answerIndex = int(answer[
'answer'])
-1
-
options = answer[
'options']
-
print(options[answerIndex])
-
-
#这里简单演示下start事件
-
def start():
-
return TNWZ()
使用方法:mitmdump -s quiz.py
启动后也可以编辑脚本文件,mitmdump会自动重新加载不需要重新运行命令,本来是写了一个头脑王者自动抓问题找答案,结果游戏被封了,只在本地模拟下

是不是很简单, 如果还不够,可以考虑,在发送答案的时候, 拦截请求,然后替换为标准答案再发送到服务器,是不是很给力。工具都是死的,就看怎么用了。
利用appium和mitmproxy登录获取cookies
环境搭建
参考我之前写的 :
windows中Appium-desktop配合夜神模拟器的使用 : https://www.cnblogs.com/c-x-a/p/9163221.html
appium
代码 start_appium.py
-
# -*- coding: utf-8 -*-
-
# @Time : 2018/10/8 11:00
-
# @Author : cxa
-
# @File : test.py
-
# @Software: PyCharmctx
-
from appium
import webdriver
-
from selenium.webdriver.support.ui
import WebDriverWait
-
from selenium.webdriver.support
import expected_conditions
as EC
-
from selenium.webdriver.common.by
import By
-
import time
-
import base64
-
-
-
def start_appium():
-
desired_caps = {}
-
desired_caps[
'platformName'] =
'Android'
# 设备系统
-
desired_caps[
'deviceName'] =
'127.0.0.1:62001'
# 设备名称
-
desired_caps[
'appPackage'] =
'com.xxxx.xxxx'
# 测试app包名,如何获取包名方式看上面的环境搭建。
-
desired_caps[
'appActivity'] =
'com.xxxx.xxxx.xxx.xxxx'
# 测试appActivity,如何获取包名方式看上面的环境搭建。
-
desired_caps[
'platformVersion'] =
'4.4.2'
# 设备系统的安卓版本,版本不要太高,设计安全策略得外部因素。
-
desired_caps[
'noReset'] =
True
# 启动后结束后不清空应用数据
-
desired_caps[
'unicodeKeyboard'] =
True
# 此两行是为了解决字符输入不正确的问题
-
desired_caps[
'resetKeyboard'] =
True
# 运行完成后重置软键盘的状态
-
driver = webdriver.Remote(
'http://localhost:4723/wd/hub', desired_caps)
# 启动app,启动前记得打开appium服务。
-
wait = WebDriverWait(driver,
60)
#设置等待事件
-
try:
-
btn_xpath =
'//android.widget.Button[@resource-id="com.alicom.smartdail:id/m_nonum_confirm_btn"]'
-
btn_node = wait.until(EC.presence_of_element_located((By.XPATH, btn_xpath)))
#等元素出现再继续,最长等待时间上面设置的60s。
-
# btn_node=driver.find_element_by_xpath(btn_xpath)
-
btn_node.click()
-
except:
-
driver.back()
-
btn_xpath =
'//android.widget.Button[@resource-id="com.alicom.smartdail:id/m_nonum_confirm_btn"]'
-
btn_node = wait.until(EC.presence_of_element_located((By.XPATH, btn_xpath)))
-
# btn_node = driver.find_element_by_xpath(btn_xpath)
-
btn_node.click()
-
# sleep 30s
-
# 点击
-
-
-
def login_in(driver):
-
id_xpath =
'//android.widget.EditText[@content-desc="账户名输入框"]'
-
id_node = driver.find_element_by_xpath(id_xpath)
-
id_node.clear()
-
id_node.send_keys(
"test")
-
pwd = str(base64.b64decode(
"MTIzNHF3ZXI="),
'u8')
-
pwd_xpath =
'//android.widget.EditText[@content-desc="密码输入框"]'
-
pwd_node = driver.find_element_by_xpath(pwd_xpath)
-
pwd_node.clear()
-
pwd_node.send_keys(pwd)
-
submit =
"//android.widget.Button[@text='登录']"
-
submit_node = driver.find_element_by_xpath(submit)
-
submit_node.click()
-
time.sleep(
10)
-
-
-
if __name__ ==
'__main__':
-
start_appium()
mitmproxy
代码 mitm_proxy_script.py
-
# -*- coding: utf-8 -*-
-
# @Time : 2018/10/8 11:00
-
# @Author : cxa
-
# @File : mitm_proxy_script.py
-
# @Software: PyCharm
-
import sys
-
sitename =
'ali'
-
-
-
def response(flow):
-
request = flow.request
-
if
'.png'
in request.url
or
'xxx.x.xxx.com'
not
in request.url:
-
return
#如果不在观察的url内则返回
-
if
'xxx.x.xxx.com'
in request .url:
-
print(request .url)
-
cookies = dict(request.cookies)
#转换cookies格式为dict
-
if cookies:
-
save_cookies(repr(cookies))
#如果不为空保存cookies
-
-
-
def save_cookies(cookies):
-
sys.path.append(
"../")
-
from database
import getcookies
-
getcookies.insert_data(sitename, cookies)
#保存cookies
拦截猫眼跳转到美团的验证码
参考:selenium + chromedriver 被反爬的解决方法 :https://blog.csdn.net/weixin_39847926/article/details/82262048
如何突破网站对selenium的屏蔽 : https://blog.csdn.net/qq_26877377/article/details/83307208
使用 selenium 驱动 Chrome 浏览器时,猫眼的 js 代码 中有检测,所以需要使用 mitmproxy 做代理拦截请求,然后把 js 文件中对 selenium 检测的关键字全部替换了。
如果不替换,selenium 驱动浏览器出现美团验证码的时候,手动输入验证码点击确定会报错,
拦截替换后,手动输入验证码可以通过。
拦截脚本 (mitmproxy_script.py):
-
#!/usr/bin/python3
-
# -*- coding: utf-8 -*-
-
# @Author :
-
# @File : mitmproxy_script.py
-
# @Software : PyCharm
-
# @description : XXX
-
-
-
from mitmproxy
import http
-
-
import winreg
-
import requests
-
import ctypes
-
import socks
-
-
import socket
-
-
-
# ############################# 改系统代理 ############################################
-
proxy =
"117.60.167.134"
-
port =
4532
-
-
-
INTERNET_SETTINGS = winreg.OpenKey(
-
winreg.HKEY_CURRENT_USER,
-
r'Software\Microsoft\Windows\CurrentVersion\Internet Settings',
-
0,
-
winreg.KEY_ALL_ACCESS
-
)
-
-
INTERNET_OPTION_REFRESH =
37
-
INTERNET_OPTION_SETTINGS_CHANGED =
39
-
-
internet_set_option = ctypes.windll.Wininet.InternetSetOptionW
-
-
socks.setdefaultproxy(socks.PROXY_TYPE_SOCKS5, proxy, port)
-
socks.setdefaultproxy(socks.PROXY_TYPE_SOCKS4, proxy, port)
-
socks.setdefaultproxy(socks.PROXY_TYPE_HTTP, proxy, port)
-
socket.socket = socks.socksocket
-
-
-
def set_key(name, value):
-
"""
-
# 修改键值
-
:param name:
-
:param value:
-
:return:
-
"""
-
_, reg_type = winreg.QueryValueEx(INTERNET_SETTINGS, name)
-
winreg.SetValueEx(INTERNET_SETTINGS, name,
0, reg_type, value)
-
-
##########################################################################
-
-
-
def chang_ip():
-
"""
-
启用代理
-
:return:
-
"""
-
set_key(
'ProxyEnable',
1)
# 启用
-
set_key(
'ProxyOverride',
u'*.local;<local>')
# 绕过本地
-
set_key(
'ProxyServer',
u'{}:{}'.format(proxy,port))
# 代理IP及端口
-
internet_set_option(
0, INTERNET_OPTION_REFRESH,
0,
0)
-
internet_set_option(
0, INTERNET_OPTION_SETTINGS_CHANGED,
0,
0)
-
# 停用代理
-
set_key(
'ProxyEnable',
0)
-
internet_set_option(
0, INTERNET_OPTION_REFRESH,
0,
0)
-
internet_set_option(
0, INTERNET_OPTION_SETTINGS_CHANGED,
0,
0)
-
-
-
def request(flow):
-
print(flow.request.url)
-
# if 'bs/yoda-static/file' in flow.request.url:
-
# print('*' * 100)
-
# print(flow.request.url)
-
# flow.response.text = flow.response.text.replace("webdriver", "fuck_that")
-
# flow.response.text = flow.response.text.replace("Webdriver", "fuck_that")
-
# flow.response.text = flow.response.text.replace("WEBDRIVER", "fuck_that")
-
# chang_ip()
-
pass
-
-
-
def response(flow):
-
# print(type(flow.response.text))
-
if
'webdriver'
in flow.response.text:
-
print(
'*' *
100)
-
print(
'find web_driver key')
-
flow.response.text = flow.response.text.replace(
"webdriver",
"fuck_that_1")
-
if
'Webdriver'
in flow.response.text:
-
print(
'*' *
100)
-
print(
'find web_driver key')
-
flow.response.text = flow.response.text.replace(
"Webdriver",
"fuck_that_2")
-
if
'WEBDRIVER'
in flow.response.text:
-
print(
'*' *
100)
-
print(
'find web_driver key')
-
flow.response.text = flow.response.text.replace(
"WEBDRIVER",
"fuck_that_3")
-
猫眼 对 selenium 驱动 的关键字有三个 :webdriver、Webdriver、WEBDRIVER,把这三个全替换了。
然后执行:mitmweb -s mitmproxy_script.py
使用 selenium 驱动 Chrome 访问猫眼时,如果再出现验证码,手动输入就可以通过了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









