







ImageNet Classification with Deep Convolutional Neural Networks
摘要
这个神经网络有6000万参数和650000个神经元,包含5个卷积层(某些卷积层后面带有池化层)和3个全连接层,最后是一个1000维的softmax。网络运用在ImageNet LSVRC-2010竞赛的120万高分辨率的图像分到1000不同的类别中的图像分类任务中测试,得到了top-1 37.5%, top-5 17.0%的错误率。
特性:RELU GPU实现
在同一数据集上的表现对比:
| model | top1 | top5 |
|---|---|---|
| Sparse coding | 47.1% | 28.2% |
| SIFT+FVs | 45.7% | 25.7% |
| CNN | 37.5% | 17.0% |
Sparse coding是对6个在不同特征上训练的稀疏编码模型生成的预测进行平均
SIFT+FVs是平均在Fisher向量(FV)上训练的两个分类器的预测结果,Fisher向量是通过两种密集采样特征计算得到的
引言
真实环境中的对象表现出了相当大的可变性,因此为了学习识别它们,有必要使用更大的训练数据集。
卷积神经网络(CNNs)构成了一个这样的模型(对象识别具有巨大的复杂性:从数百万图像中识别几千个图像)。它们的能力可以通过改变它们的广度和深度来控制,它们也可以对图像的本质进行强大且通常正确的假设(也就是说,统计的稳定性和像素依赖的局部性)。
深度网络的发展表现出层数越多即越深,效果越好的趋势,但同时也存在很多问题,例如:深度达到一定程度,存在梯度难以传播的问题,15年何凯明提出的深度残差网络(ResNet)解决了这个问题,17年提出基于移动框架的轻量级深度学习模型。这些模型的构建需要专业的团队设计,使用AutoML可以自动学习网络结构和参数,可以方便的自己设计网络结构。
数据集
ImageNet LSVRC-2010,1000个类别每个类别大约1000张图像,总计,大约120万训练图像,50000张验证图像和15万测试图像。
我们将图像进行下采样到固定的256×256分辨率。给定一个矩形图像,我们首先缩放图像短边长度为256,然后从结果图像中裁剪中心的256×256大小的图像块。除了在训练集上对像素减去平均活跃度外,我们不对图像做任何其它的预处理。因此我们在原始的RGB像素值(中心的)上训练我们的网络。
架构
它包含八个学习层–5个卷积层和3个全连接层,下面是网络的一些新特性
Relu非线性
修正线性单元Relu(非饱和非线性) f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
比饱和非线性 s i g m o i d ( x ) = 1 1 + e − x sigmoid(x)= \frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1和 t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=ex+e−xex−e−x收敛更快

重叠池化
池化层可看作由池化单元网格组成,网格间距为s个像素,每个网格归纳池化单元中心位置z大小的邻居。如果设置s=z,我们会得到通常在CNN中采用的传统局部池化。如果设置s<z,就得到重叠池化。
网络中设置s=2,z=3的重叠池化方案与非重叠池化s=2,z=2相比,这个方案分别降低了top-1 0.4%,top-5 0.3%的错误率。
整体架构

第2,4,5卷积层的核只与位于同一GPU上的前一层的核映射相连接。第3卷积层的核与第2层的所有核映射相连。全连接层的神经元与前一层的所有神经元相连。第1,2卷积层之后是响应归一化层。ReLU非线性应用在每个卷积层和全连接层的输出上。
第1卷积层使用96个核对 224 × 224 × 3 224 \times 224 \times 3 224×224×3的输入图像进行滤波,核大小为 11 × 11 × 3 11 \times 11 \times 3 11×11×3,步长是4个像素(核映射中相邻神经元感受野中心之间的距离)。第2卷积层使用用第1卷积层的输出(响应归一化和池化)作为输入,并使用256个核进行滤波,核大小为 5 × 5 × 48 5 \times 5 \times 48 5×5×48。第3,4,5卷积层互相连接,中间没有接入池化层或归一化层。第3卷积层有384个核,核大小为 3 × 3 × 256 3 \times 3 \times 256 3×3×256,与第2卷积层的输出(归一化的,池化的)相连。第4卷积层有384个核,核大小为 3 × 3 × 192 3 \times 3 \times 192 3×3×192,第5卷积层有256个核,核大小为 3 × 3 × 192 3 \times 3 \times 192 3×3×192。每个全连接层有4096个神经元。
(图片引自深度之眼课程)

据吴恩达课程介绍,此处的输入经计算应为
227
×
227
×
3
227\times 227\times 3
227×227×3
插入知识点1:卷积通道和特征map数量计算
(图片引自深度之眼课程)

1、输入feature map的通道channel数目是多少,卷积核filter的通道就是多少,不一样TensorFlow会报错;
2、有几个Filter就有几个feature map,例如上图中两个filter就会有两个feature map(相当于两个channel),接下来再进行convolution操作的话filter就需要有两个channel,如果有5个filter就会输出5个feature map。
插入知识点2:网络参数及连接计算
卷积特征图尺寸计算公式: F o = ⌊ F i n + 2 × p − k s ⌋ + 1 F_o=\lfloor \frac{F_{in}+2\times p - k}{s} \rfloor +1 Fo=⌊sFin+2×p−k⌋+1 . 式中2p表示对图像的上下左右各填充p个像素,式中 ⌊ ⌋ \lfloor\rfloor ⌊⌋是向下取整的符号,意思是除不尽的时候向下取整,k代表卷积核的尺寸
validmode: F o = ⌈ F i n − k + 1 s ⌉ F_o=\lceil \frac{F_{in} - k + 1}{s} \rceil Fo=⌈sFin−k+1⌉
samemode: F o = ⌈ F i n s ⌉ F_o=\lceil \frac{F_{in}}{s} \rceil Fo=⌈sFin⌉
参数数量计算公式:
(
k
2
×
k
c
+
1
)
×
F
o
c
(k^2\times k_c + 1)\times F_{oc}
(k2×kc+1)×Foc
(卷积核大小x 卷积核通道 + 1)x 卷积核数量
连接数量计算公式:
(
k
2
×
k
c
+
1
)
×
F
o
c
×
F
o
2
(k^2\times k_c + 1)\times F_{oc}\times {F_o}^2
(k2×kc+1)×Foc×Fo2
输出特征图尺寸x 参数数量
这里如果忽略bias,则去掉1,因为与网络中其他参数相比bias的参数量比较小。
池化层也是一种convolution操作,卷积方式默认为VALID,池化层没有可学习的参数,只会改变特征图的大小,不会改变通道数量。
| 网络层 | kernel_size | depth | strids | padding | input_size | output_size | parameters |
|---|---|---|---|---|---|---|---|
| conv_1 | [11x11x3] | 96 | 4 | VALID | [227x227x3] | [55x55x96] ⌈ 227 − 11 + 1 4 ⌉ \lceil\frac{227-11+1}{4}\rceil ⌈4227−11+1⌉ | [34944] ( 1 1 2 × 3 + 1 ) × 96 (11^2\times 3+1)\times 96 (112×3+1)×96 |
| maxpool_1 | [3x3] | 2 | VALID | [55x55x96] | [27x27x96] 55 − 3 + 1 2 \frac{55-3+1}{2} 255−3+1 | – | |
| conv_2_1 | [5x5x48] | 128 | 1 | SAME | [27x27x48] | [27x27x128] ⌈ 27 1 ⌉ \lceil\frac{27}{1}\rceil ⌈127⌉ | [153728] ( 5 2 × 48 + 1 ) × 128 (5^2\times 48+1)\times 128 (52×48+1)×128 |
| conv_2_2 | [5x5x48] | 128 | 1 | SAME | [27x27x48] | [27x27x128] ⌈ 27 1 ⌉ \lceil\frac{27}{1}\rceil ⌈127⌉ | [153728] ( 5 2 × 48 + 1 ) × 128 (5^2\times 48+1)\times 128 (52×48+1)×128 |
| Concate(conv2_1,conv2_2) | |||||||
| maxpool_2 | [3x3] | 2 | VALID | [27x27x256] | [13x13x256] 27 − 3 + 1 2 \frac{27-3+1}{2} 227−3+1 | – | |
| conv_3 | [3x3x256] | 384 | 1 | SAME | [13x13x256] | [13x13x384] ⌈ 13 1 ⌉ \lceil\frac{13}{1}\rceil ⌈113⌉ | [885120] ( 3 2 × 256 + 1 ) × 384 (3^2\times 256+1)\times 384 (32×256+1)×384 |
| conv_4_1 | [3x3x192] | 192 | 1 | SAME | [13x13x192] | [13x13x192] ⌈ 13 1 ⌉ \lceil\frac{13}{1}\rceil ⌈113⌉ | [331968] ( 3 2 × 192 + 1 ) × 192 (3^2\times 192+1)\times 192 (32×192+1)×192 |
| conv_4_2 | [3x3x192] | 192 | 1 | SAME | [13x13x192] | [13x13x192] ⌈ 13 1 ⌉ \lceil\frac{13}{1}\rceil ⌈113⌉ | [331968] ( 3 2 × 192 + 1 ) × 192 (3^2\times 192+1)\times 192 (32×192+1)×192 |
| Concate(conv4_1,conv4_2) | |||||||
| conv_5_1 | [3x3x192] | 128 | 1 | SAME | [13x13x192] | [13x13x128] ⌈ 13 1 ⌉ \lceil\frac{13}{1}\rceil ⌈113⌉ | [221312] ( 3 2 × 192 + 1 ) × 128 (3^2\times 192+1)\times 128 (32×192+1)×128 |
| conv_5_2 | [3x3x192] | 128 | 1 | SAME | [13x13x192] | [13x13x128] ⌈ 13 1 ⌉ \lceil\frac{13}{1}\rceil ⌈113⌉ | [221312] ( 3 2 × 192 + 1 ) × 128 (3^2\times 192+1)\times 128 (32×192+1)×128 |
| Concate(conv5_1,conv5_2) | |||||||
| maxpool_5 | [3x3] | 256 | 2 | VALID | [13x13x256] | [6x6x256] 13 − 3 + 1 2 \frac{13-3+1}{2} 213−3+1 | – |
| fc_6 | [6x6x256] 13 − 3 + 1 2 \frac{13-3+1}{2} 213−3+1 | 4096 | 6 × 6 × 256 × 4096 6\times 6\times 256\times 4096 6×6×256×4096 | ||||
| fc_7 | 4096 | 4096 | 4096 × 4096 4096\times 4096 4096×4096 | ||||
| fc_8 | 4096 | 10 | 4096 × 10 4096\times 10 4096×10 |
减少过拟合
数据增强
第一种方式是图像的变化和水平翻转
第二种方式是改变图像RGB通道的强度,做PCA主成分增强,top1 error 减小1%
失活
将许多不同模型的预测结合起来是降低测试误差的一个非常成功的方法,“dropout”,它会以0.5的概率对每个隐层神经元的输出设为0。那些“失活的”的神经元不再进行前向传播并且不参与反向传播。因此每次输入时,神经网络会采样一个不同的架构,但所有架构共享权重。这个技术减少了复杂的神经元互适应,因为一个神经元不能依赖特定的其它神经元的存在。因此,神经元被强迫学习更鲁棒的特征,它在与许多不同的其它神经元的随机子集结合时是有用的。在测试时,我们使用所有的神经元但它们的输出乘以0.5,对指数级的许多失活网络的预测分布进行几何平均,这是一种合理的近似。
我们在图2中的前两个全连接层使用失活。如果没有失活,我们的网络表现出大量的过拟合。失活大致上使要求收敛的迭代次数翻了一倍。
超参数设置
SGD优化,batchsize=128,momentum=0.9,weightdecay=0.0005
learning rate=0.01 衰减率0.1
epochs=90
权重w更新规则:
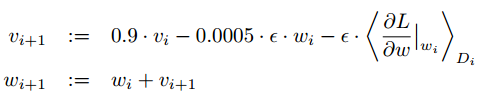
卷积核初始化方式:均值为0,标准差为0.01的高斯分布
偏置初始化方式:第2,4,5卷积层和全连接层将神经元偏置初始化为常量1,其他层偏置初始化为0














 1440
1440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









