







论文标题:Automated data processing and feature engineering for deep learning and big data applications: a survey
作者:Alhassan Mumuni and Fuseini Mumuni
摘要:
本篇综述论文探讨了自动化数据处理和特征工程在深度学习和大数据应用中的重要性和进展。随着大数据时代的到来,传统的深度学习方法在处理大规模、复杂异构数据时显得力不从心。为了克服这些挑战,研究者们提出了自动化机器学习(AutoML)技术,以简化数据处理任务并提高模型的性能。本文全面回顾了自动化数据处理任务的方法,包括数据预处理、数据增强和特征工程,并讨论了AutoML工具在优化机器学习管道各个阶段的应用。
1. 引言:
深度学习方法因其在数据密集型任务中的优越性能而受到青睐。然而,深度学习模型通常需要大量的数据预处理工作,如数据清洗、标签化、缺失数据处理等。此外,数据增强和特征工程也是提高模型性能的关键步骤。自动化这些任务不仅可以减少人工干预,还可以提高数据处理的效率和一致性。
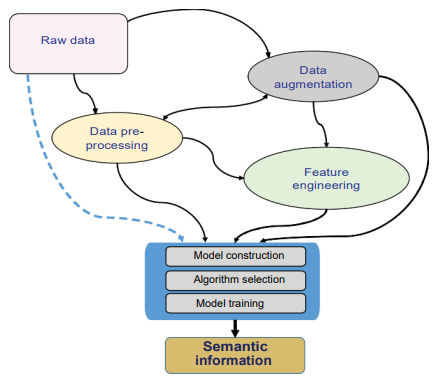
机器学习流程中的数据处理和特征工程流程
2. 自动化数据处理的背景和相关工作:
自动化数据处理的目的是简化机器学习系统的设计与实现。近
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









