







Java基础
https://mp.weixin.qq.com/s/-xFSHf7Gz3FUcafTJUIGWQ
1. 线程和进程的区别
进程:
- 是系统进行资源分配和调度的基本单位
- 作用是使程序能够并发执行提高资源利用率和吞吐率;
- 创建、销毁、切换会产生大量的时间和空间的开销,数量不能太多;
线程:
- 是进程的一个实体,使操作系统有更高的并发性
- 一个进程中至少有一个线程
2. synchronized 的原理
可以去对应目录执行 javap -c xxx.class 命令查看反编译的文件
- Java提供的原子性内置锁(监视器锁),排他锁
- 使用synchronized之后,会在编译之后在同步的代码块前后加上monitorenter 和 monitorexit 字节码指令,依赖操作系统底层互斥锁实现,作用主要是实现原子性操作和解决共享变量的内存可见性问题
- 有两个队列waitSet 和 entryList
3. 锁的优化机制
- JDK1.6版本之后,synchronized 有些情况下他并不会是一个很重量级的锁了
- 锁的状态从低到高依次为:无锁->偏向锁->轻量级锁->重量级锁
- 偏向锁:当线程访问同步块获取锁时,会在对象头和栈帧中的锁记录里存储偏向锁的线程ID,之后这个线程再次进入同步块时都不需要CAS来加锁和解锁了,偏向锁会永远偏向第一个获得锁的线程
- 轻量级锁:JVM的对象的对象头中包含有一些锁的标志位,代码进入同步块的时候,JVM将会使用CAS方式来尝试获取锁,如果更新成功则会把对象头中的状态位标记为轻量级锁,如果更新失败,当前线程就尝试自旋来获得锁
4. 对象具体有什么内容
常用hostpot虚拟机中,对象在内存布局实际包含3个内容
- 对象头:
- Mark Word:hashcode、分代年龄、轻量级锁指针、重量级锁指针、GC标记、偏向锁线程ID、偏向锁时间戳
- 存储类型指针:指向类的元数据的指针,通过这个指针才能确定对象是属于哪个类的实例。
- 实例数据:存放类的信息,父类的信息
- 对齐填充:虚拟机要求对象起始地址必须是8字节的整数倍,填充数据不是必须存在的,仅仅是为了字节对齐。(一个空对象占8个字节,因为对齐填充的原因,自动补齐)
5. ReentrantLock原理,与synchronized的区别
原理
- 抽象静态内部类Sync,继承了AQS
- AQS内部维护一个state状态位,加锁的时候通过CAS修改值,如果成功设置为1,并且把当前线程ID赋值,则代表加锁成功,一旦获取到锁,其他的线程将会被阻塞进入阻塞队列自旋,获得锁的线程释放锁的时候将会唤醒阻塞队列中的线程,释放锁的时候则会把state重新置为0,同时当前线程ID置为空。
- 借助Condition和newCondition()方法可以有选择性的通知
区别:
- ReentrantLock需要显式的获取锁和释放锁
- synchronized和ReentrantLock默认都是非公平锁,ReentrantLock可以通过构造函数传参改变,使用公平锁的话会导致性能急剧下降
6. CAS原理
通过处理器的指令来保证操作的原子性
- 底层Unsafe类,(变量内存值,旧的预期值,设置的新值)
- 乐观锁的一种实现方式,轻量级锁,
缺点
- ABA问题:在CAS更新的过程中,当读取到的值是A,然后准备赋值的时候仍然是A,但是实际上有可能A的值被改成了B,然后又被改回了A,这个CAS更新的漏洞就叫做ABA,AtomicStampedReference可解决这个问题,他加入了预期标志和更新后标志两个字段,更新时不光检查值,还要检查当前的标志是否等于预期标志,全部相等的话才会更新
- 循环时间长开销大
- 只能保证一个共享变量的原子操作:多个可以通过AtomicReference来处理或者使用锁synchronized实现
7. ConcurrentHashmap原理
- CAS + synchronized + Node (jdk1.8),CAS + synchronized代替1.7的segment分段锁
put 流程
- 首先计算hash,遍历node数组,如果node是空的话,就通过CAS+自旋的方式初始化
- 如果当前数组位置是空则直接通过CAS自旋写入数据
- 如果hash==MOVED(-1),说明需要扩容,执行扩容
- 如果都不满足,就使用synchronized写入数据,写入数据同样判断链表、红黑树,链表写入和HashMap的方式一样,key hash一样就覆盖,反之就尾插法,链表长度超过8就转换成红黑树
8. volatile 原理
- 使用内存屏障来保证不会发生指令重排,解决了内存可见性的问题
- 不能保证原子性,通过atomic相关类保证(CAS)
9. JMM内存模型
JMM内存模型是对多线程下操作的一种规范,不可能让陈旧代码适配所有的CPU,可通过JMM屏蔽了不同的硬件和操作系统内存访问之间的差异,保证了Java程序在不同平台下达到一致的访问效果,同时也保证了在高并发的时候程序能正确运行
10. ThreadLocal原理
- 线程本地变量,在每个线程都创建一个副本,那么在线程之间访问内部变量副本即可,做到线程之间的相互隔离,空间换时间(synchronized 时间换空间)
- 底层是静态内部类ThreadLocalMap,key是指向ThreadLocal的弱引用,value为泛型中的值
- 弱引用是防止内存泄漏,如果是强引用,ThreadLocal对象除非线程结束,否则始终无法被回收,弱引用将在下一次GC的时候回收
- 依然造成内存泄漏,key和对象被回收了,value无法被回收,可用remove方法删除entry对象
- 可解决Spring、SimpleDataFormat中线程安全的问题
ThreadLocalMap
- 底层数据结构:Entry继承WeakReference,类似数组
- ThreadLocal的实例以及其值存放在堆上,只是通过一些技巧将可见性修改成了线程可见
11. 零拷贝
详细介绍零拷贝
传统文件传输:需要发生了 4 次用户态与内核态的上下文切换
- 磁盘数据——》操作系统内核的缓冲区——》用户的缓冲区——》内核的socket缓冲区——》网卡的缓冲区
- 提高文件传输的性能,减少用户态和内核态的上下文切换
技术实现
- mmap + write
- sendefile
Kafka、Nginx利用零拷贝技术,大幅度提升了IO的吞吐率
12. 单例模式
双检锁中volatile的作用
- 禁止指令重排,因为instance = new Singleton()不是原子操作
- 内存可见
- synchronized 锁的粒度变小,效率更高
为什么枚举是最好的Java单例实现?
可以有效防御两种破坏单例的行为(单例产生多个实例)
- 反射攻击
- 序列化攻击
13. 双亲委派机制
当前类加载器在加载一个类时,委托给其双亲先进行加载,如此反复,直到某个类加载器没有双亲为止,然后开始再依次在各自的类路径下寻找、加载class类
- 启动类加载器(BootStrap):C++编写,出厂自带,java环境变量配置中的jre的bin目录中的所有.class文件,默认加载最早的类文件(ArrayList、Object)等,导包前缀为java
- 扩展类加载器(Extension):java编写,后续版本迭代的类加载,导包前缀为javax
- 应用程序类加载器(AppClassLoader):java也叫系统类加载器,加载当前应用的classpath的所有类,自己创建定义的类,应用时需要被加载
- 启动类加载器 > 扩展类加载器 > 应用程序加载器(可通过.getclass().getClassLoader().getParent()验证 )
14. HashMap
怎么扩容的?
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍
- Rehash:遍历原Entry数组,把所有Entry重新Hash到新数组
为什么要Rehash?为什么不直接复制?
- 因为长度扩大以后,hash的规则也随之改变
默认初始化长度为什么是16?
- 赋值最好是2的幂
- 位与运算比算数计算的效率高
- 为了实现均匀分布
为什么线程不安全?
- 多线程环境下会发生数据覆盖
与HashTable不同点
- HashTable不允许key和value为null,源码做了判断抛空指针,使用的是安全失败机制(fail-safe),如果使用null值,无法判断是不存在还是为空
- HashTable继承Dictionary,HashMap 继承的是 AbstractMap
- HashMap 的初始容量为 16, HashTable为11
- HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1
15. CPU打满排查
一般CPU100%疯狂GC,都是死循环的锅
- 使用top -H命令获取占用CPU最高的线程,并将它转化为16进制
- 使用jstack命令获取应用的栈信息,搜索这个16进制
- 再用cat grep查看一下线程在文件里做的事,这样能够方便的找到引起CPU占用过高的具体原因
16. 类加载过程
加载——》连接【验证——》准备——》解析】——》初始化
1. 加载
- 获取类加载的二进制流
- 将二进制流的静态存储结构转换成方法区运行时的数据结构
- 在内存中生成一个代表该类的Class对象,作为方法区这些数据的访问入口
2. 验证
- 文件格式验证:是否以0xCAFEBABE开头
- 元数据验证:对字节码描述的信息进行语义分析
- 字节码验证
- 符号引用验证:确保解析动作能正确执行
3. 准备
正式为类变量分配内存并设置类变量初始值
4. 解析
虚拟机将常量池内的符号引用替换为直接引用的过程
5. 初始化
真正执行类中定义的Java字节码,初始化阶段是执行类构造器 clinit() 方法的过程
17. AbstractQueuedSynchronizer(AQS)
AQS是一个用来构建锁和同步器的框架,它维护了一个共享资源 state 和一个 FIFO 的等待队列,底层利用了 CAS 机制来保证操作的原子性
- 同步等待队列:保存等待在这个锁上的线程(由于lock()引起的等待)
- 条件变量等待队列:维护等待在条件变量上的等待线程,由Condition.await()引起阻塞的线程
- 底层CLH队列是虚拟的双向队列
18. Spring事务失效场景
- 数据库的存储引擎是否支持事务
- 注解所在的类是否被加载成bean
- 注解所在的方法是否为public
- 是否发生了自调的行为
- 所用的数据源是否加载了事务管理器
- mysql默认采用可重复度隔离级别,oracle默认采用读已提交隔离级别
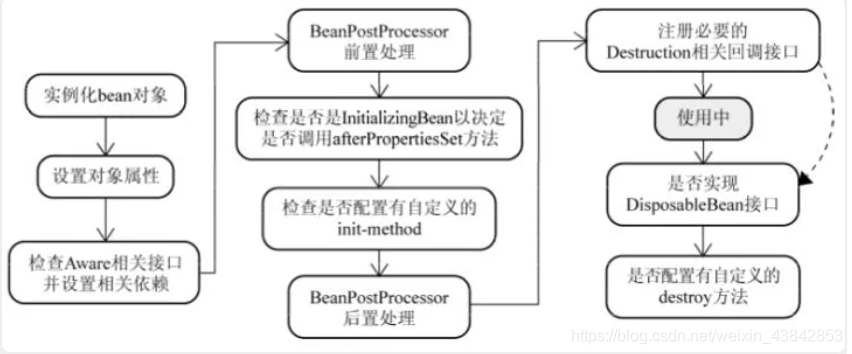
19. Spring中Bean的声明周期
- Bean容器利用反射创建一个Bean的实例
- 设置一些对应的属性值
- 传入bean的名字
- 传入类加载对象的实例
- if 实现对应的接口或者加载spring 容器相关的对象,就执行对应的方法
- if 实现了DisposableBean接口,执行destroy方法
20. Spring 循环依赖
三级缓存解决了Bean之间的循环依赖
- singletonObjects:第一级缓存,里面放置的是已经实例化好的单例对象;
- earlySingletonObjects:第二级缓存,里面存放的是提前曝光的单例对象;
- singletonFactories:第三级缓存,里面存放的是将要被实例化的对象的对象工厂















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











