










文章目录
鉴权,分别由鉴和权组成
- 鉴: 表示身份认证,认证相关用户是否存在以及相关的用户名和密码是否一致
- 权: 完成身份的鉴后,还需要判断用户是否有相关操作的权限。
因此对于某一个用户来说,通常情况下,需要完成鉴和权才能够满足一个完整的业务场景,因此通常将鉴权放在一起考量。本文探讨hdfs的鉴权常用的鉴权方式以及kerberos鉴权方式的相关方法。
1. Hdfs鉴权方式整理
hdfs本身在最开始进行设计时,并没有考虑鉴权相关设计,而是以满足大数据的业务场景作为优先要务,因此最开始时只有简单认证模式。等后续经过一定程度的发展,发现鉴权越来越成为业务的需要,因此才将鉴权作为一个功能进行设计。在设计上也是充分利用现有的框架或者外部的认证系统,hdfs对接相关的认证系统接口,从而完成高效(偷懒)的实现鉴权功能。
目前HDFS有支持两种用户身份认证:简单认证和kerberos认证。
简单认证: 基于客户端进程所在的Linux/Unix系统的当前用户名来进行认证。只要用户能正常登录操作系统就认证成功。这样客户端与NameNode交互时,会将用户的登录账号(与whoami命令输出一致)作为合法用户名传给Namenode。 这样的认证机制存在恶意用户可以伪造其他人的用户名的风险,对数据安全造成极大的隐患,线上生产环境一般不会使用。简单认证模式下,采集的鉴权模式跟linux系统一致,使用UGO(user、group、other)模式,相关的acl跟linux系统类似,本文不在追述。
drwxrwxrwt - yarn hadoop 0 2020-01-20 15:42 /app-logs
drwxr-xr-x - yarn hadoop 0 2020-01-20 15:40 /ats
drwxr-xr-x - hdfs hdfs 0 2020-01-20 15:40 /hdp
drwxr-xr-x - mapred hdfs 0 2020-01-20 15:40 /mapred
drwxrwxrwx - mapred hadoop 0 2020-01-20 15:40 /mr-history
drwxrwxrwx - hdfs hdfs 0 2020-01-20 15:41 /tmp
drwxr-xr-x - hdfs hdfs 0 2020-01-20 15:40 /user
drwxr-xr-x - hdfs hdfs 0 2020-01-20 15:40 /warehouse
相关配置
vim /usr/local/hadoop/bin/hdfs

kerberos认证: kerberos是一个网络认证协议,其使用密钥加密技术为客户端和服务端应用提供强认证功能。它有一个管理端(AdminServer)用于管理所有需要认证的账号信息,另外还有若干的密钥分发服务器(KDC)用于提供认证和分发密钥服务。 用户从 Kerberos 管理员处获取对应的 Kerberos 账号名或者密钥文件,然后通过 kinit 等方式认证Kerberos,拿到TGT(ticket-granting-ticket)票据。客户端会将TGT信息传输到NN端,NN在获取到认证信息后,将principle首部截取出来作为客户端的用户名。例如使用 todd/foobar@CORP.COMPANY.COM认证成功后, da作为principle的首部会作为该客户端的用户名使用。 使用Kerberos可以极大增强HDFS的安全性,特别是在多租户的生产环境下。
可以通过core-site.xml配置文件进行配置和调整,如果不配置,默认使用简单认证方式
<property>
<name>hadoop.http.authentication.type</name>
<value>kerberos</value>
</property>
2. Kerboers鉴权架构整理
hdfs在使用kerberors认证的整体架构如下。
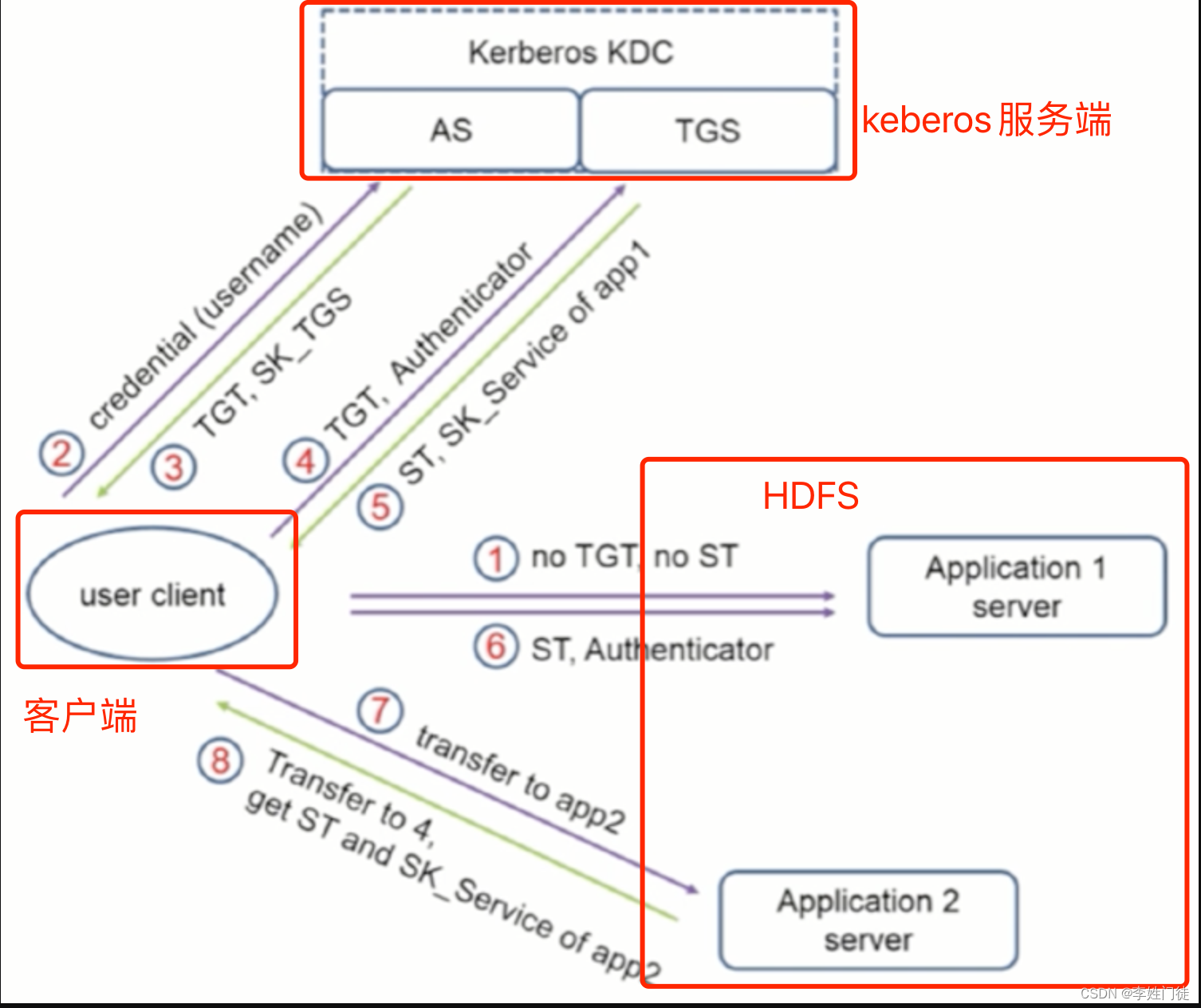
有3个重要角色
| 角色 | 作用 |
|---|---|
| Client | 需要访问hdfs的客户端 |
| Hdfs | Hdfs集群,存储相关的数据 |
| KDC | 提供鉴权认证服务,并分发相关的票据 |
认证过程如下
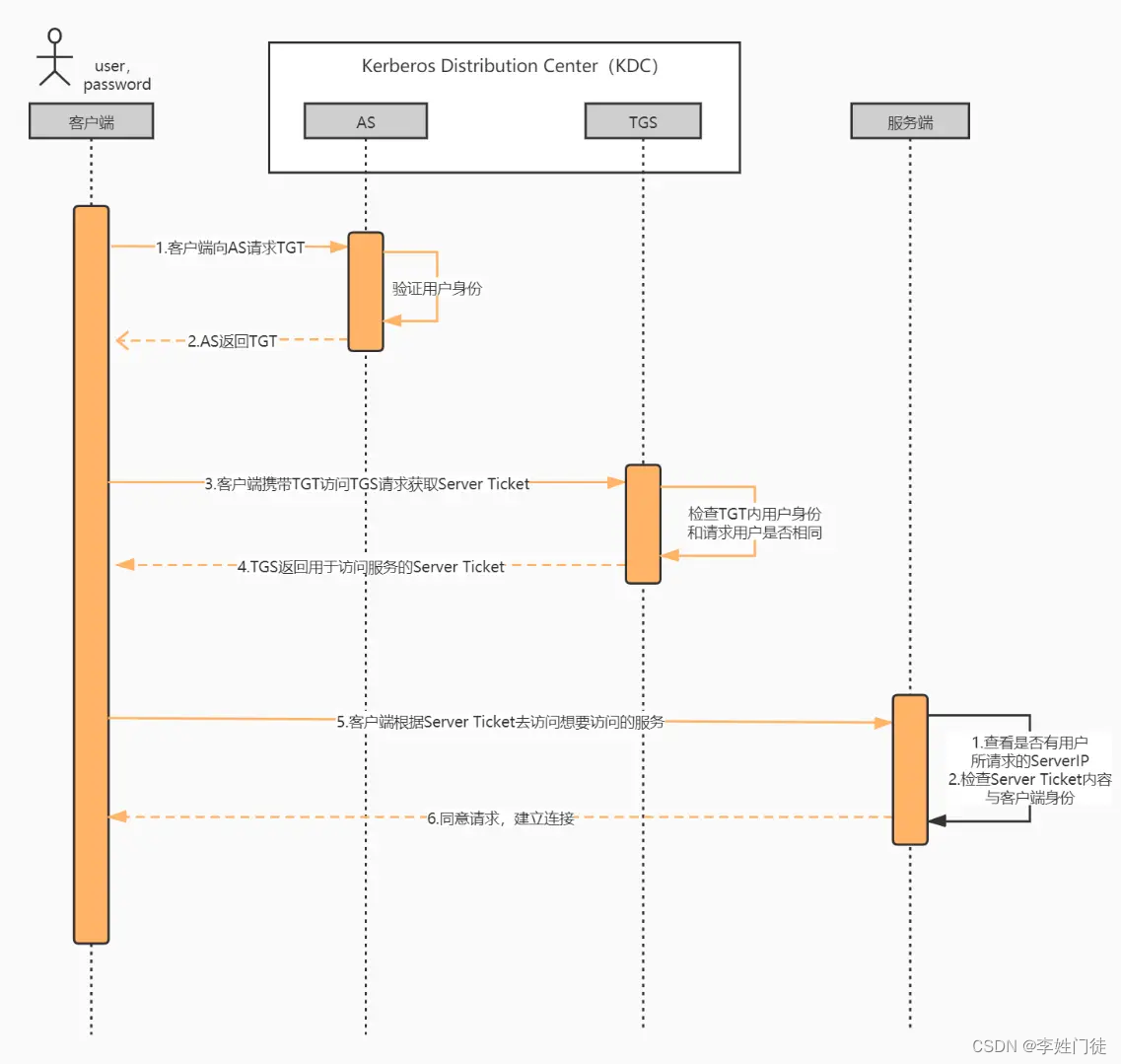
认证过程大体上分为3个步骤
- 客户端向KDC请求获取TGT ,KDC确认客户端是一个可靠且拥有权限的客户端
- 客户端向KDC请求获取 Server Ticket,即获取目标服务的服务授予票据 Server Ticket(类似获取公钥,相关的私钥信息保存在目标服务端)
- 客户端使用 Server Ticket 在目标服务进行认证(类似完成公、私钥配对,验证是否合法)
3. Kerberos安装部署以及HDFS认证配置方法
3.1 kerberos和openldap统一说明
首先说明kerberos和openladp是2套独立的服务,2者之间并没有联系。 在常规的hadoop集群可以通过kerberos认证即可,并不依赖openldap。但是在大企业、中心权限的背景下,统一配置权限的需求越来越多,因此才会出现kerberos和openldap相互集成,从而形成统一的认证权限。 kerberos提供认证服务,openldap作为相关的数据库,实现数据统一。
相关的架构如下
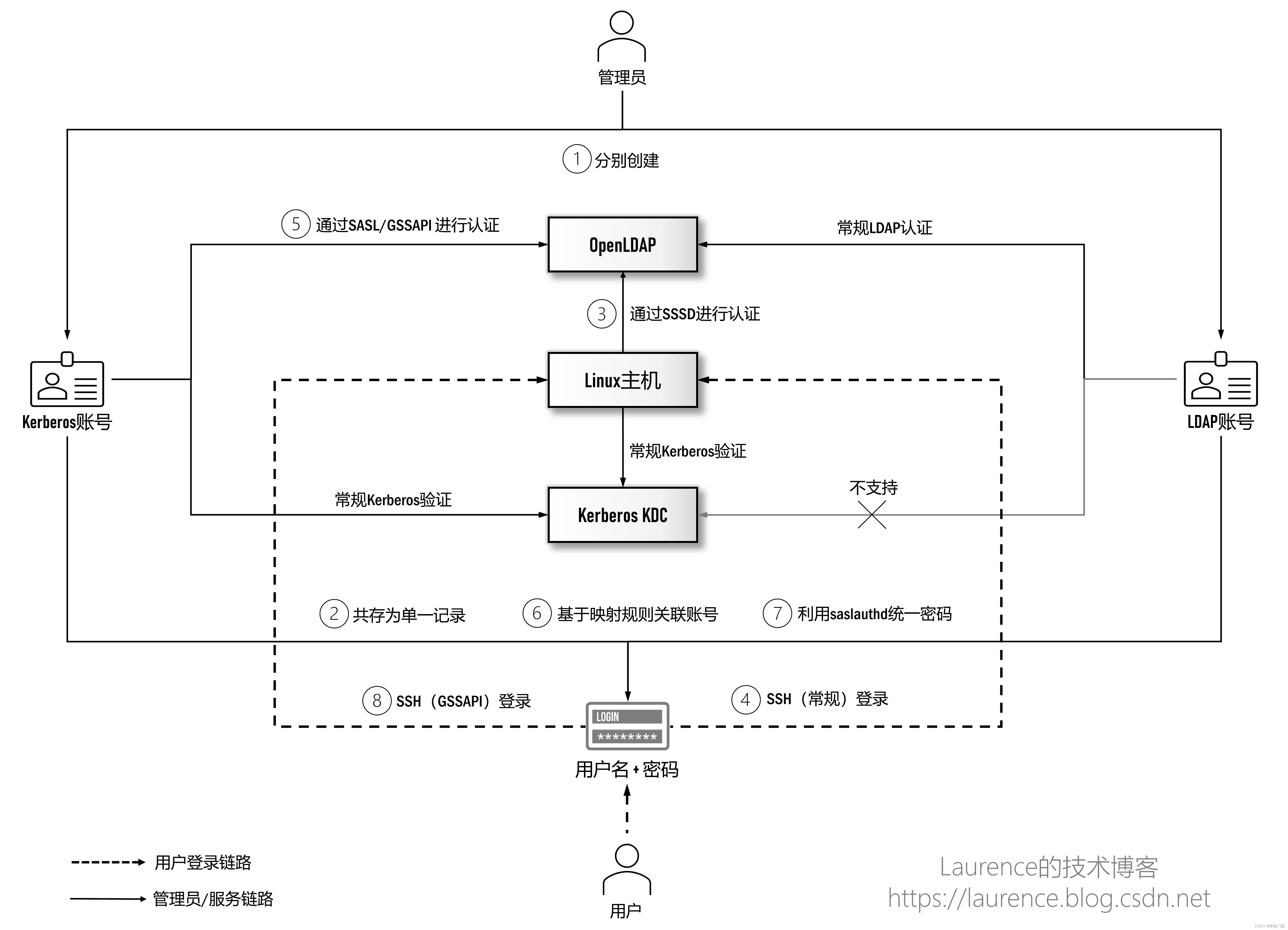
本文不作为探讨的重点,感兴趣的可以读取本文的引用文档中,有相关的记录。
3.2 kerberos安装步骤和常用命令
具体的安装步骤可以参考文章 Kerberos安装和解析
kdc完成安装后,需要给对应的客户端分发访问的princial,用于相关的鉴权认证。通常的鉴权认证方式有2种
- 密码认证
- keytab认证
常用命令如下
1, 创建数据库
kdb5_util create -r JENKIN.COM -s
2, 服务启停(不同的部署环境有差别)
# 启动kdc服务
service krb5kdc start
# 启动kadmin服务
service kadmin start
3, kadmin 模式
# 控制台执行
kadmin.local
# 交互使用命令
kadmin.local -q "listprincs"
4, 查看所有的listprincs
kadmin.local -q "listprincs"
5,查看所有的listprincs
kadmin.local -q "addprinc/delprinc admin/admin"
6,设置密码策略(policy)
kadmin.local -q "addpol -maxlife "90 days" -minlife "75 days" -minlength 8 -minclasses 3 -maxfailure 10 -history 10 user"
7,添加带有密码策略的用户
kadmin.local -q "addprinc -policy user hello/admin@XXX.COM"
8,修改用户的密码策略
kadmin.local -q "modprinc -policy user1 hello/admin@XXX.COM"
9,删除密码策略
kadmin.local -q "delpol [-force] user"
10,修改密码策略
kadmin.local -q "modpol -maxlife "90 days" -minlife "75 days" -minlength 8 -minclasses 3 -maxfailure 10 user"
11,生成keytab
kadmin.local -q "ktadd -k /etc/krb5.keytab host/master1@JENKIN.COM "
12, 查看keytab
kadmin.local -q "klist -e -k -t keytabs/hdfs_hadoop-client.keytab"
13, kinit续期证书
# 使用默认配置
kinit hdfs/hadoop-client@XXX.COM -k -t /usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs_hadoop-client.keytab
# 指定配置文件krb5.conf
export KRB5_CONFIG=/usr/local/services/hadoop-3.2.1/etc/hadoop/krb5.conf && kinit hdfs/hadoop-client@XXX.COM -k -t /usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs_hadoop-client.keytab
说明
- 用户在客户端通过 kinit 默认是读取/etc/krb5.conf配置连接到kdc服务器,成功登录 kerberos 后,会将获得的 ticket-granting ticket 缓存到客户端的 ccache (credentail cache) 文件中
cat /etc/krb5.conf
[logging]
default = LOG4C:/data//etc/krb5.d/krb5.log4c.rc
kdc = LOG4C:/data//etc/krb5.d/krb5.log4c.rc
admin_server = LOG4C:/data//etc/krb5.d/krb5.log4c.rc
[libdefaults]
default_realm = XXX.COM
dns_lookup_realm = false
dns_lookup_kdc = false
rdns = false
ticket_lifetime = 24h
forwardable = yes
allow_weak_crypto = true
[realms]
XXX.COM = {
# kdc服务端
kdc = xx.xx.xx.xx:8089
kdc = xx.xx.xx.xx:8089
admin_server = xx.xx.xx.xx:8750
admin_server = xx.xx.xx.xx:8750
default_domain = xx.com
database_module = openldap_ldapconf
}
[domain_realm]
.xx.com = XXX.COM
xx.com = XXX.COM
- ccache 文件地址是通过配置文件 /etc/krb5.conf 中的参数 default_ccache_name来配置的,在 linux 操作系统中一般是配置为 FILE:/tmp/krb5cc_%{uid},实际对应文件 /tmp/krb5cc_0 等
- 由于每次kinit只能获取8h的有效期(具体时长可以配置),因此需要定期续期。通常的做法是可以通过配置计划任务定时kinit续期,否则缓存文件中记录的ticket过期后,对应的客户端就不能直接通过hdfs命令访问客户端
crontab -l|grep kinit
0 */12 * * * kinit hdfs/hadoop-client@XXX.COM -k -t /usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs_hadoop-client.keytab
0 */12 * * * export KRB5_CONFIG=/usr/local/services/hadoop-3.2.1/etc/hadoop/krb5.conf && kinit hdfs/hadoop-client@XXX.COM -k -t /usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs_hadoop-client.keytab
3.3 hdfs配置kdc认证
通常生产服务使用的都是keytab的认证方式,一个keytab可以集成多种类型的princial,通常需要分发如下类型的princial
| 证书类型 | 备注 |
|---|---|
| krbtgt/XXX.COM@XXX.COM | tgt相关的princial |
| kadmin/admin@XXX.COM | admin相关的princial |
| hdfs/cluster@XXX.COM | hdfs集群内部通用的princial |
| HTTP/hdfs-xx-xx-xx-x@XXX.COM | dn、nn提供的http接口相关的princial,与配置文件中的值HTTP/_HOST@XXX.COM一致 |
| hdfs/hdfs-xx-xx-xx-xx@XXX.COM | dn、nn内部通信接口相关的princial ,与配置文件中的值hdfs/_HOST@XXX.COM一致 |
| yarn/hdfs-xx-xx-xx-xx@XXX.COM | yarn任务rm、nm内部通信接口相关的princial ,与配置文件中的值yarn/_HOST@XXX.COM一致 |
| mapred/hdfs-xx-xx-xx-xx@XXX.COM | mapperduce相关的princial ,与配置文件中的值mapred/_HOST@XXX.COM一致 |
| hdfs/hadoop-client@XXX.COM | 客户端访问相关的princial ,由于无法提前预知客户端,因此需要签发通用类型的keytab |
说明:
- _HOST: 代表本机的hostname,因此需要每个节点单独签发
通常这些princial可以按照节点生成对应的keytab文件,可以通过如下脚本生成对应的keytab文件
if [ ! -d /data/keytabs ];then
mkdir /data/keytabs
fi
if [ ! -f /data/keytabs/hdfs_hadoop-client.keytab ];then
kadmin.local -q "delete_principal -force hdfs/hadoop-client@XXX.COM"
kadmin.local -q "addprinc -randkey -requires_preauth hdfs/hadoop-client@XXX.COM"
kadmin.local -q "ktadd -k /data/keytabs/hdfs_hadoop-client.keytab -norandkey hdfs/hadoop-client@XXX.COM"
kadmin.local -q "addprinc -randkey -requires_preauth hdfs/cluster@XXX.COM"
fi
for host in ${host_list[@]}
do
hostName="hdfs-${host//./-}"
for value in ${principal_use[@]}
do
if [ ! -f /data/keytabs/${value}_${host}.keytab ];then
kadmin.local -q "ktadd -k /data/keytabs/${value}_${host}.keytab -norandkey ${value}/${host}@XXX.COM HTTP/${host}@XXX.COM ${value}/${hostName}@XXX.COM HTTP/${hostName}@XXX.COM"
fi
done
done
可以通过如下脚本将keytab分发到对应的节点
#/bin/bash
passwd="xxx"
port="22"
host_list=(xx.xx.xx.xx )
principal_use=("hdfs" "yarn" "mapred")
for host in ${host_list[@]}
do
for value in ${principal_use[@]}
do
sshpass -p $passwd scp -P$port /data/keytabs/${value}_${host}.keytab ${host}:/usr/local/services/hadoop-3.2.1/etc/hadoop/${value}.keytab
done
sshpass -p $passwd scp -P$port /data/keytabs/hdfs_hadoop-client.keytab ${host}:/usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs_hadoop-client.keytab
done
hdfs通过调整配置文件来调整对应的认证方式
core-site.xml
<property>
<name>hadoop.http.authentication.type</name>
<value>kerberos</value>
通过调整相关的keytab参数完成验证。
4. 相关核心参数整理
hdfs-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed ...
-->
<configuration>
<!-- 定义hdfs的namespace,可以配置多个,使用","分隔 -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!-- 定义hdfs的nn节点 -->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>namenode1,namenode2</value>
</property>
<!-- 定义hdfs的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 定义是否开启web监控页面 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 定义hdfs的nn的editlog保存路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data2/hadoop/dfs/name</value>
</property>
<!-- 定义hdfs的nn1,nn2节点信息 -->
<property>
<name>dfs.namenode.rpc-address.cluster.namenode1</name>
<value>xx.xx.xx.xx:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.namenode2</name>
<value>xx.xx.xx.xx:9000</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.cluster.namenode1</name>
<value>namenode1:53310</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.cluster.namenode2</name>
<value>namenode2:53310</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.namenode1</name>
<value>xx.xx.xx.xx:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.namenode2</name>
<value>xx.xx.xx.xx:50070</value>
</property>
<property>
<name>dfs.namenode.https-address.cluster.namenode1</name>
<value>xx.xx.xx.xx:9871</value>
</property>
<property>
<name>dfs.namenode.https-address.cluster.namenode2</name>
<value>xx.xx.xx.xx:9871</value>
</property>
<!-- 定义hdfs的jn节点信息 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://xx.xx.xx.xx:8485;xx.xx.xx.xx:8485;xx.xx.xx.xx:8485/cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data2/hadoop/journal</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 定义hdfs的nn的fencing信息,nn通过切主时会获取原主的信息,如果调用rpc原主降为standby失败,就会通过fencing ssh到对应的服务器杀死原主的nn进程 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence(root:36000)
shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>ipc.client.connect.timeout</name>
<value>60000</value>
</property>
<!-- 定义hdfs的dn数据保存目录,可以配置多个路径,用","分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/hdfsdata1/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>xx.xx.xx.xx:9868</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>xx.xx.xx.xx:9869</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 定义hdfs的dn内部的平衡、同步fimage的带宽限制 -->
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>52428800</value>
</property>
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>52428800</value>
</property>
<property>
<name>dfs.datanode.balance.max.concurrent.moves</name>
<value>50</value>
</property>
<!-- 定义hdfs的需要下线的机器列表 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/excludes_datanodes</value>
</property>
<property>
<name>dfs.namenode.http-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.https-bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 定义hdfs的zk路径,通过在该路径下创建临时节点选主 -->
<property>
<name>ha.zookeeper.parent-znode</name>
<value>/hadoop-hdfs-ha</value>
</property>
<property>
<name>dfs.datanode.https.address</name>
<value>0.0.0.0:9865</value>
</property>
<property>
<name>dfs.block.access.token.enable</name>
<value>true</value>
</property>
<!-- 定义hdfs的kerberos鉴权,如果设置鉴权可以不配置 -->
<property>
<name>dfs.namenode.keytab.file</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs.keytab</value>
</property>
<!-- 定义hdfs的kerberos用户,_HOST代表本机的hostname,因此没台dn的用户hdfs/_HOST@XX.COM有差别,需要针对每个dn单独配置证书 -->
<property>
<name>dfs.namenode.kerberos.principal</name>
<value>hdfs/_HOST@XX.COM</value>
</property>
<property>
<name>dfs.namenode.kerberos.https.principal</name>
<value>HTTP/_HOST@XX.COM</value>
</property>
<property>
<name>dfs.namenode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@XX.COM</value>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>755</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:9866</value>
</property>
<property>
<name>dfs.datanode.keytab.file</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs.keytab</value>
</property>
<property>
<name>dfs.datanode.kerberos.principal</name>
<value>hdfs/_HOST@XX.COM</value>
</property>
<property>
<name>dfs.datanode.kerberos.https.principal</name>
<value>HTTP/_HOST@XX.COM</value>
</property>
<property>
<name>dfs.journalnode.keytab.file</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs.keytab</value>
</property>
<property>
<name>dfs.journalnode.kerberos.principal</name>
<value>hdfs/_HOST@XX.COM</value>
</property>
<property>
<name>dfs.journalnode.kerberos.internal.spnego.principal</name>
<value>HTTP/_HOST@XX.COM</value>
</property>
<property>
<name>dfs.web.authentication.kerberos.principal</name>
<value>HTTP/_HOST@XX.COM</value>
</property>
<property>
<name>dfs.web.authentication.kerberos.keytab</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs.keytab</value>
</property>
<property>
<name>dfs.data.transfer.protection</name>
<value>integrity</value>
</property>
<!-- 定义hdfs的dn的最大文件数量 -->
<property>
<name>dfs.namenode.fs-limits.max-directory-items</name>
<value>3200000</value>
</property>
</configuration>
core-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed ...
-->
<configuration>
<!-- 定义hdfs的zk配置 -->
<property>
<name>ha.zookeeper.auth</name>
<value>digest:zk_user:zk_passwd</value>
</property>
<property>
<name>ha.zookeeper.acl</name>
<value>digest:zk_user:Yg6OG5Tas/LEH5bd73noFMYG3xo=:rwcda</value>
</property>
<property>
<name>hadoop.http.filter.initializers</name>
<value>org.apache.hadoop.security.AuthenticationFilterInitializer</value>
</property>
<property>
<name>hadoop.http.authentication.type</name>
<value>kerberos</value>
</property>
<property>
<name>hadoop.http.authentication.signature.secret.file</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/secret</value>
</property>
<property>
<name>hadoop.http.authentication.simple.anonymous.allowed</name>
<value>false</value>
</property>
<!-- 定义hdfs的kerberos认证信息 -->
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hadoop.http.authentication.kerberos.principal</name>
<value>HTTP/_HOST@XX.COM</value>
</property>
<property>
<name>hadoop.http.authentication.kerberos.keytab</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs.keytab</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data2/hadoop/tmp</value>
</property>
<!-- 定义hdfs的namespace集群信息,和hdfs-site.xml定义一致 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mapred.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mapred.groups</name>
<value>*</value>
</property>
<!-- 定义hdfs的zk访问地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>xx.xx.xx.xx:2181,xx.xx.xx.xx:2181,xx.xx.xx.xx:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
</property>
<!-- 定义hdfs的机架topo配置 -->
<property>
<name>topology.script.file.name</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs_rack_info.py</value>
</property>
<!-- 定义hdfs的dn 汇报心跳配置 -->
<property>
<name>ipc.client.connect.max.retries</name>
<value>10</value>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>5000</value>
</property>
<property>
<name>ipc.client.connect.max.retries.on.timeouts</name>
<value>3</value>
</property>
</configuration>
yarn-core.yaml
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明yarn集群陪配置的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>support-yarn</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>resourcemanager1,resourcemanager2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.resourcemanager1</name>
<value>xx.xx.xx.xx</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.resourcemanager2</name>
<value>xx.xx.xx.xx</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.resourcemanager1</name>
<value>xx.xx.xx.xx:8030</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.resourcemanager2</name>
<value>xx.xx.xx.xx:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address.resourcemanager1</name>
<value>xx.xx.xx.xx:8032</value>
</property>
<property>
<name>yarn.resourcemanager.address.resourcemanager2</name>
<value>xx.xx.xx.xx:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.resourcemanager1</name>
<value>hdfs-xx-xx-xx-xx:8090</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.resourcemanager2</name>
<value>hdfs-xx-xx-xx-xx:8090</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.resourcemanager1</name>
<value>xx.xx.xx.xx:5003</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.resourcemanager2</name>
<value>xx.xx.xx.xx:5003</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>xx.xx.xx.xx:2181,xx.xx.xx.xx:2181,xx.xx.xx.xx:2181</value>
</property>
<property>
<name>yarn.resourcemanager.zk-auth</name>
<value>digest:zk_user:zk_passwd</value>
</property>
<property>
<name>yarn.resourcemanager.zk-acl</name>
<value>digest:zk_user:Yg6OG5Tas/LEH5bd73noFMYG3xo=:rwcda</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- <property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/usr/local/services/hadoop-2.9.2/etc/hadoop/capacity-scheduler.xml</value>
</property> -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///data2/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///data2/hadoop/yarn/logs</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/var/log/hadoop-yarn/apps</value>
</property>
<property>
<name>yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds</name>
<value>3600</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>102400</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>90</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>https://xx.xx.xx.xx:19890/jobhistory/logs</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/logs/hadoop-yarn/staging</value>
</property>
<property>
<name>yarn.nm.liveness-monitor.expiry-interval-ms</name>
<value>100000</value>
</property>
<property>
<name>yarn.resourcemanager.nodes.exclude-path</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/excludes_nodemanagers</value>
</property>
<!--指定keytab-->
<property>
<name>yarn.resourcemanager.keytab</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/yarn.keytab</value>
</property>
<property>
<name>yarn.resourcemanager.principal</name>
<value>yarn/_HOST@XXX.COM</value>
</property>
<property>
<name>yarn.nodemanager.keytab</name>
<value>/usr/local/services/hadoop-3.2.1/etc/hadoop/yarn.keytab</value>
</property>
<property>
<name>yarn.nodemanager.principal</name>
<value>yarn/_HOST@XXX.COM</value>
</property>
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor</value>
</property>
<property>
<name>yarn.nodemanager.linux-container-executor.group</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/usr/local/services/hadoop-3.2.1/share/hadoop/mapreduce/*,/usr/local/services/hadoop-3.2.1/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election-one</value>
</property>
<property>
<name>yarn.http.policy</name>
<value>HTTPS_ONLY</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/usr/local/services/hadoop-3.2.1/etc/hadoop,
/usr/local/services/hadoop-3.2.1/share/hadoop/common/lib/*,
/usr/local/services/hadoop-3.2.1/share/hadoop/common/*,
/usr/local/services/hadoop-3.2.1/share/hadoop/hdfs,
/usr/local/services/hadoop-3.2.1/share/hadoop/hdfs/lib/*,
/usr/local/services/hadoop-3.2.1/share/hadoop/hdfs/*,
/usr/local/services/hadoop-3.2.1/share/hadoop/mapreduce/lib/*,
/usr/local/services/hadoop-3.2.1/share/hadoop/mapreduce/*,
/usr/local/services/hadoop-3.2.1/share/hadoop/yarn,
/usr/local/services/hadoop-3.2.1/share/hadoop/yarn/lib/*,
/usr/local/services/hadoop-3.2.1/share/hadoop/yarn/*,
/usr/local/services/hadoop-3.2.1/contrib/capacity-scheduler/*.jar
</value>
</property>
</configuration>
5. 疑问和思考
5.1 注意保持时钟一致性
根据经验,任何ticket、token类的认证方式,基本上很依赖于依赖服务器的的时间(通常的实现方式是,服务端获取本地的时间和ticket、token的时间对比,验证是否ticket、token已经过期),因此所有服务端的时钟保持一致,否则可能会出现各种服务都正常,但是认证失败的情况。
5.2 能否在1台机器配置2个hdfs的访问客户端
能。
1, 配置hdfs的访问客户端,阻力主要来自kdc的认证上。 由于默认情况下,hdfs客户端访问hdfs集群时,连接kdc的配置是/etc/krb5.conf配置,如果不做调整,会有该配置导致连接到错误的客户端,从而导致kdc认证错误。通过如下方法进行kinit就可以指定客户端进行配置
export KRB5_CONFIG=/usr/local/services/hadoop-3.2.1/etc/hadoop/krb5.conf && kinit hdfs/hadoop-client@XXX.COM -k -t /usr/local/services/hadoop-3.2.1/etc/hadoop/hdfs_hadoop-client.keytab
完成对应的kinit后,hdfs的客户端可以正常访问。
2,访问不同的hdfs集群是,应当做一下kinit切换,以让对应的kdc证书生效。















 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









