










 本文探讨了3节点Zookeeper集群中,当leaderzk2宕机时,集群无法自动选举新Leader的原因,涉及配置、投票机制、网络延迟等,并提出了优化建议和未来版本规避方法。
本文探讨了3节点Zookeeper集群中,当leaderzk2宕机时,集群无法自动选举新Leader的原因,涉及配置、投票机制、网络延迟等,并提出了优化建议和未来版本规避方法。
文章目录
探讨3节点zk集群中,zk2(leader)节点宕机后,集群无法选主的问题分析,以及避免相关问题的实践。
1. 问题说明
1.1 配置说明
环境使用的版本是3.4.14,对应的配置如下
zoo.cfg配置
cat /data/zookeeper-3.4.14/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=16
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=8
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper-3.4.14/data
dataLogDir=/data/zookeeper-3.4.14/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
maxClientCnxns=10000
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=50
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
# 配置允许删除临时数据
extendedTypesEnabled=true
# 注意该配置,如果不配置默认是5000,代表5s
# cnxTimeout=5000
# Add default super user to zookeeper for administration.
# if you want the passwd. please contact to administration.
DigestAuthenticationProvider.superDigest=super:2bS8Usm0IRIIwal5O1c6meW8uxI=
server.1=xx.xx.xx.xx:2888:3888
server.2=xx.xx.xx.xx:2888:3888
server.3=xx.xx.xx.xx:2888:3888
为了便于和节省日常运维成本,在每台zk的机器上配置了定时任务,每1min检查zk的状态,如果zk状态异常,会执行重启动作,便于自动快速恢复。没有配置cnxTimeout,采用默认值默认值5000ms
# 注意该配置,如果不配置默认是5000,代表5s
cnxTimeout=5000
1.2 触发条件
在故障前,zk2是集群的leader,zk1和zk3是follow。 由于机器底层硬件故障,导致zk2机器宕机,由于zk2正好是leader节点,因此理论上应该由zk1,zk3完成投票,重新选择一个Leader,并提供集群服务。但是实际上zk2宕机后,zk1和zk3并不能选举Leader,需要后续人工干预后才能恢复。
2. 原因分析
2.1 原因1:zk3应该成为Leader
原因分析分为多个环节进行,根据zk的选举Leader流程。
按照zk的设计,成为Leader的节点应该满足如下条件,在同一个选主周期过程中
- zxid(事务id)越大,越容易成为Leader(通常写入的数据越多)
- 如果zxid相同,sid(配置的myid)越大,越容易成为Leader(没有特别原因,长者为尊,避免多次选举)
- 获取超过集群半数节点的选票的节点,成为Leader
事后分析,zk1和zk3的zxid相同,因此按照目标,zk3应当成为Leader。
2.3 原因2:zk在投票后进行广播是按照sid排序,从小到大串行执行。
按照zk的选举逻辑,在阶段1完成投票后,需要通过广播的方式给其他节点告知选票。
根据代码分析,在进行广播时,节点编列的代码如下
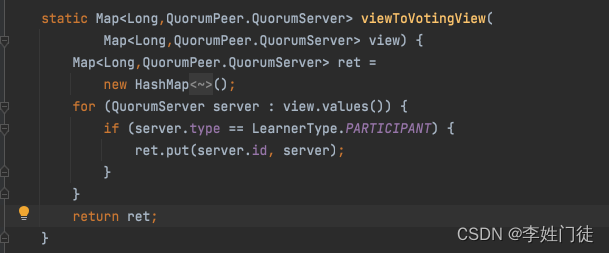
虽然使用了Map,但是由于key是sid(数字类型),进行遍历时,会呈现有序性,结果上看就是,从小到大进行排序,并且是完成一个节点的选票同步后,在进行下一个节点同步,整体上是串行进行的。
2.3 原因3:zk2宕机导致zk3收到广播选票的时间延迟
我们分开看zk1和zk3的节点行为以及相关的时间线,有2个时间我们做一下说明
timeout: 如果服务不响应的超时时间,根据zk配置,5s
exchangeTime: 交换选票的时间,大约3ms
1,zk1的视角
t0: zk1给自己投票(1,zxid),然后通过广播的方式通知其他节点自己的选票信息
t0 到 t0 + 5s: zk1通知zk2,并等待5s超时,继续通知zk3
t0 + 5s 到 t0 + 5s + exchangeTime: zk1通知zk3并快速返回
2,zk3的视角
t0: zk3给自己投票(3,zxid),然后通过广播的方式通知其他节点自己的选票信息
t0 到 t0+ exchangeTime: zk3通知zk1,并快速返回,此时zk1已经获取到zk3的选票,并将自己的选票更改为(3,zxid)
t0+ exchangeTime 到 t0+ exchangeTime + 5s: zk1通知zk2,并等待5s超时
3, 完成一轮投票后,各自统计手上的选票
zk1的选票(3,zxid),zk1成为Follower
zk3的选票分为2个阶段
t0 (3,zxid) * 1
t0 + 5s + exchangeTime: (3,zxid) * 2
也就是说,zk3需要再t0 + 5s + exchangeTime 才能成为Leader,并且集群也只能是zk3成为Leader
2.4 原因4:Follower链接Leader通讯时间短于超时时间,导致集群无法选出Leader
在zk1成为Follower后,需要跟zk3进行数据通信确认后,确认集群已经有了Leader,选主才算结束。
但是,根据代码逻辑,Follower跟Leader通信的时间只有4s,但是此时zk3由于还没有接收到zk1的选票,因此zk3不能成为Leader,4s后zk1认为集群还没有Leader,因此就会进行下一轮投票。因此选入陷入了死循环,无法选出Leader。
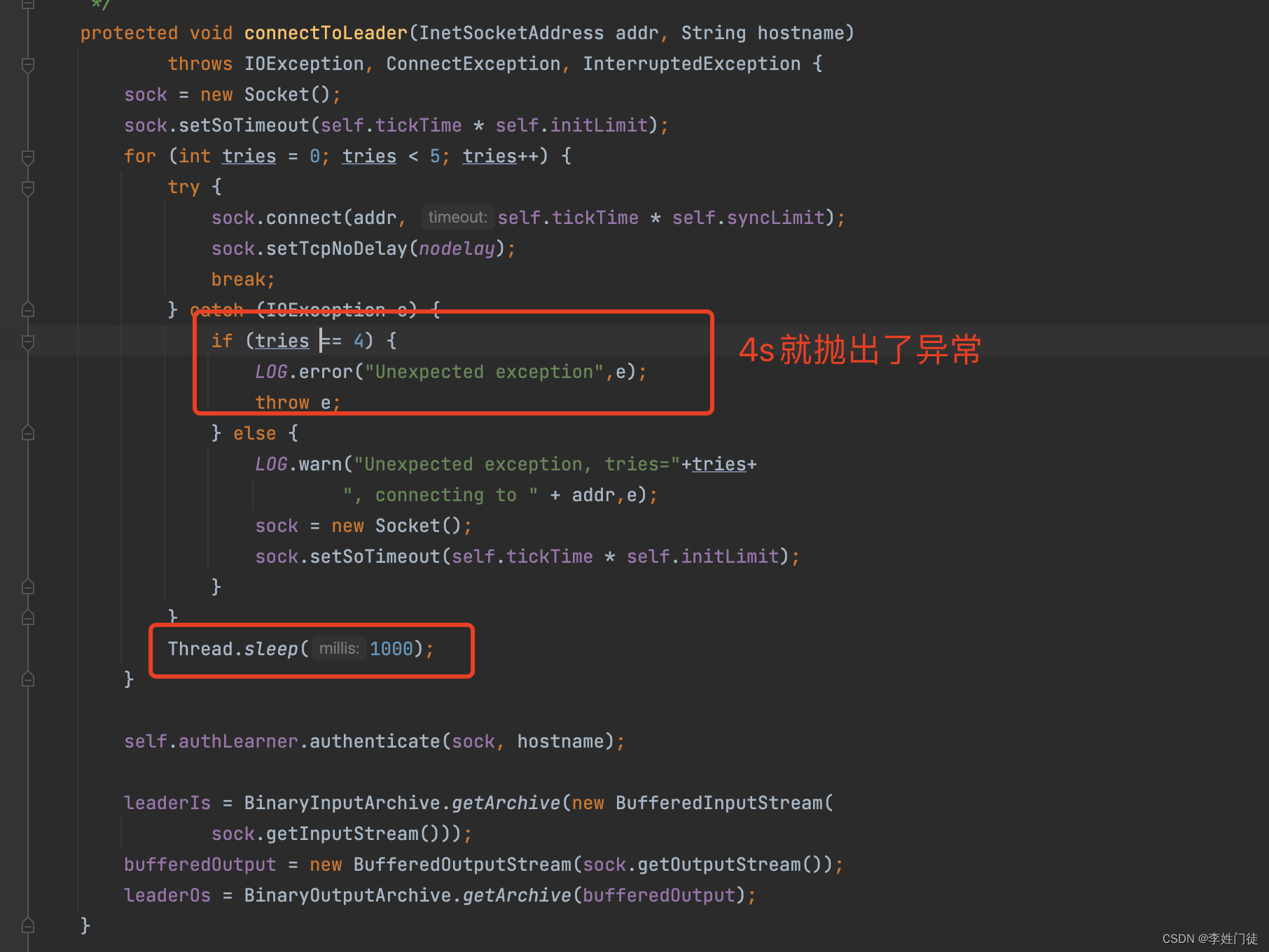
该问题在 issues ZOOKEEPER-2164中有说明
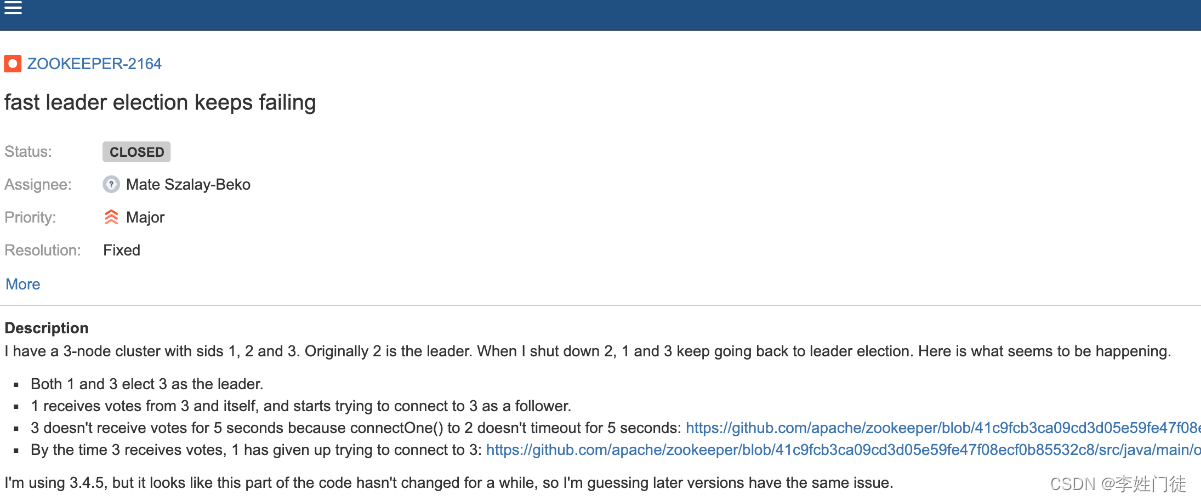
3. 复现验证
3.1 复现条件
-
3.4.6/3.4.14 版本 zk 集群 部署3个集群,并且设置zk2为Leader
-
调大参数 cnxTimeout ,由默认的 5s 调整为 8s, 更容易复现
cnxTimeout=8000
- 使用 iptables drop 端口的方式来模拟 zk2 机器故障,即可复现
iptables -t filter -I INPUT -p tcp -m multiport --dports 2181,2888,3888 -j DROP;iptables -t filter -I OUTPUT -p tcp -m multiport --dports 2181,2888,3888 -j DROP
./zkServer.sh stop
3.2 日志分析
进行日志分析,获取选举过程如下
zk1:
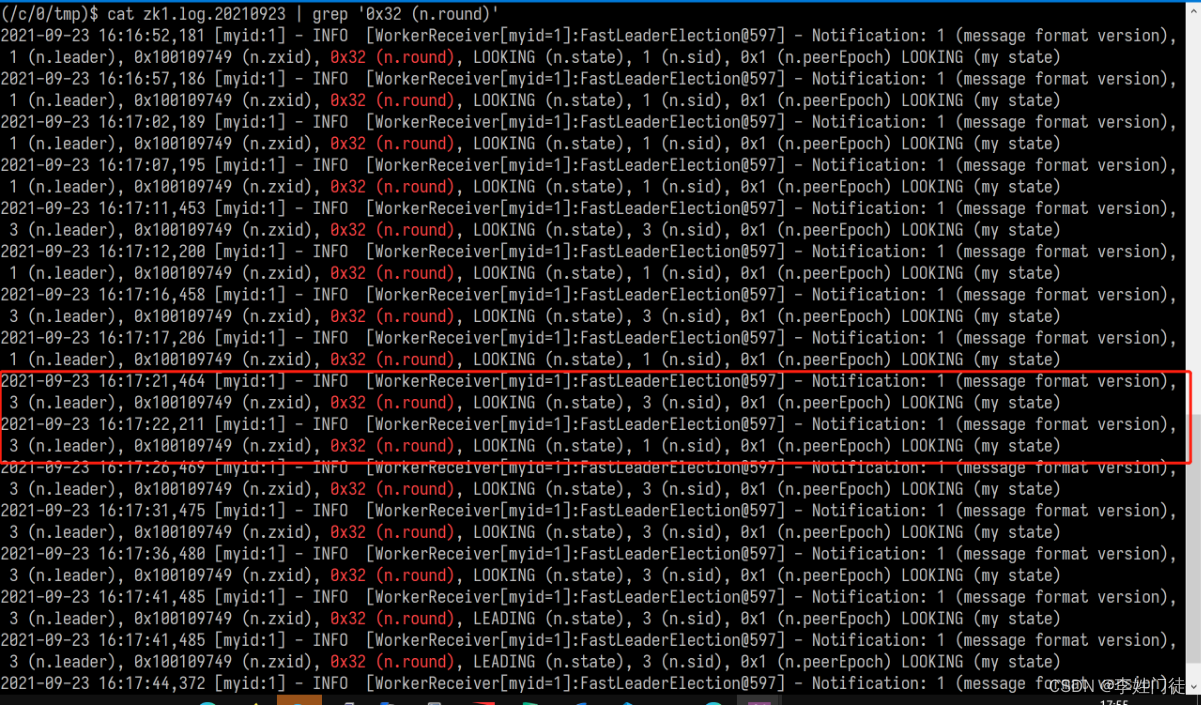
zk3:
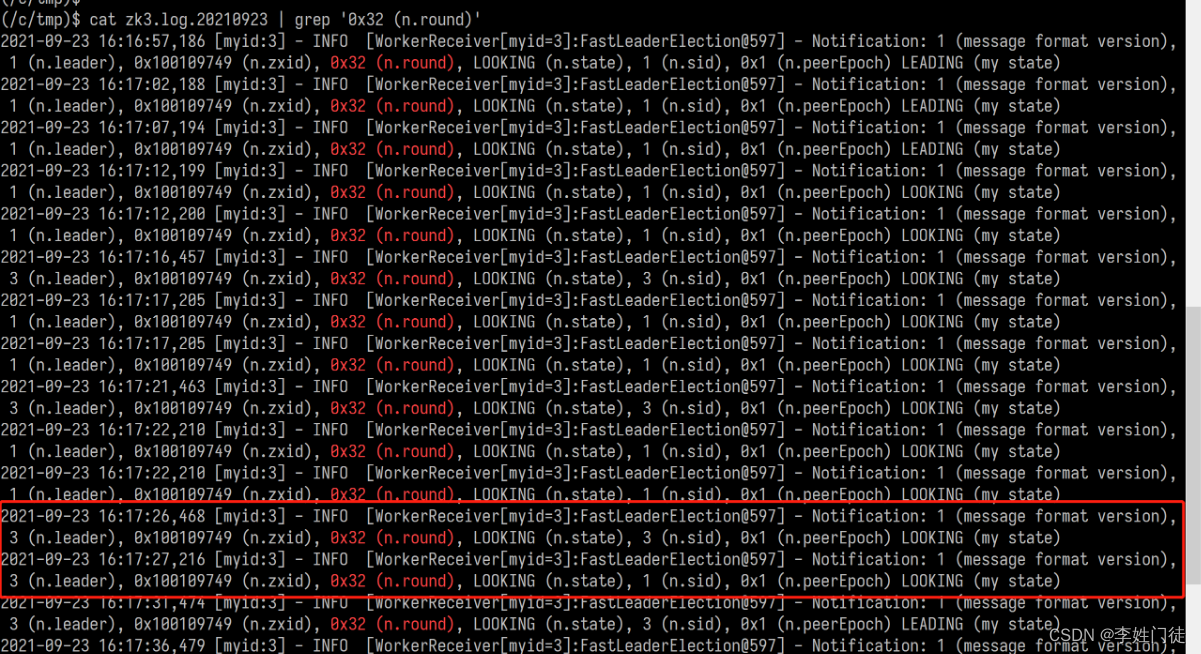
n.sid为投票发起者,n.leader为次选票选举的leader。
从截图可以看到,前几次投票都是自己选自己。直到红框这里,zk1改选zk3为leader。这张关键选票送达后,zk3即可当选为leader。
注意时间戳,在zk1日志中,zk1改选zk3这张选票时间是16:17:22;而zk3日志中收到这张选票的时间是16:17:27。这张票在传输过程中阻塞了5秒。(阻塞原因在根因分析部分第2点)
统计其他轮次zk1投给zk3的选票时间:
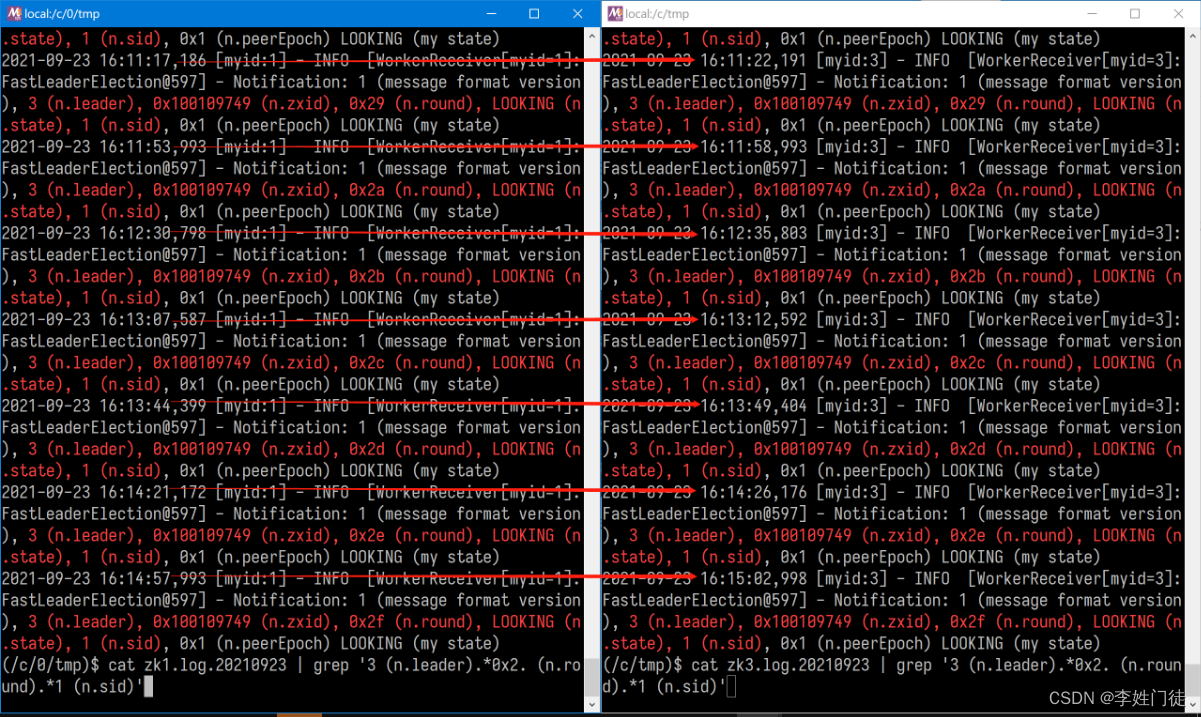
这张图能明显看出,每轮投票zk1投给zk3的选票,zk3总是晚5秒收到。
详细分析看zk1 的日志
16:17:22 zk1 认为 zk3 是leader,并开始请求 zk3 的数据同步端口
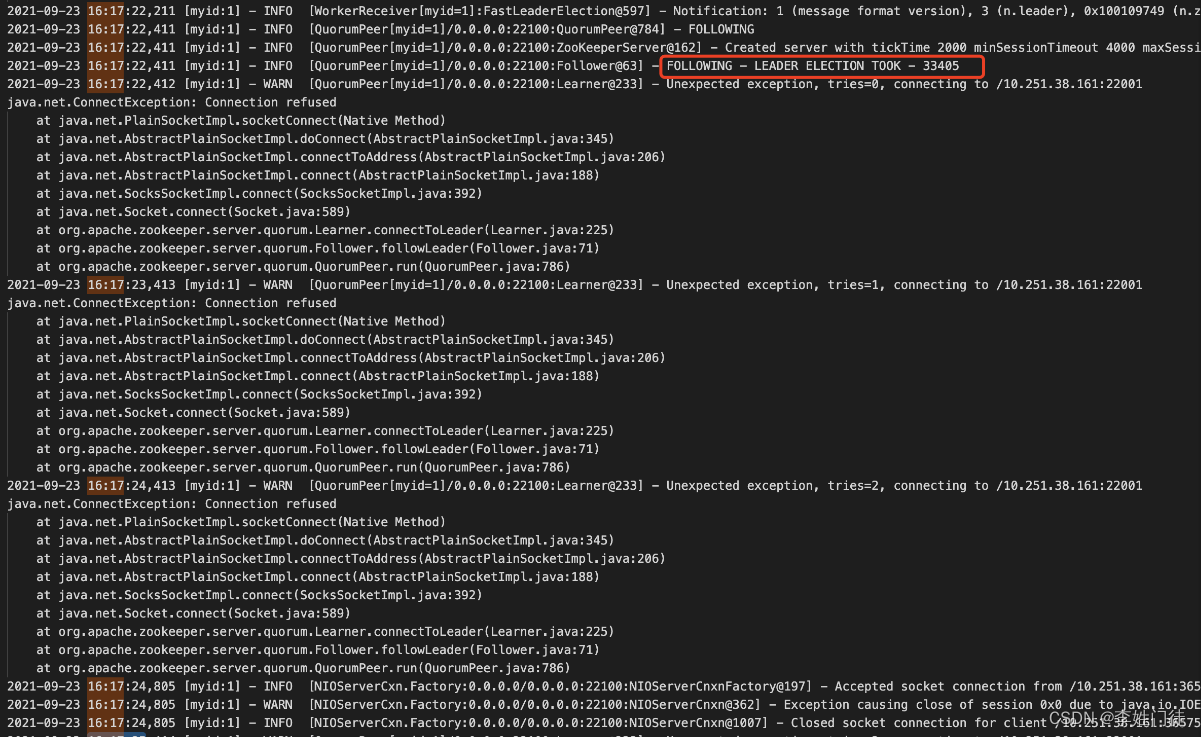
16:17:25 zk1 同步四次数据失败( tries=0 开始)
16:17:26 zk1 停止同步 (shutdown Follower), 这个过程耗时约4秒。Shutdown Follower之后开始发起新的选举(FastLeaderElection)
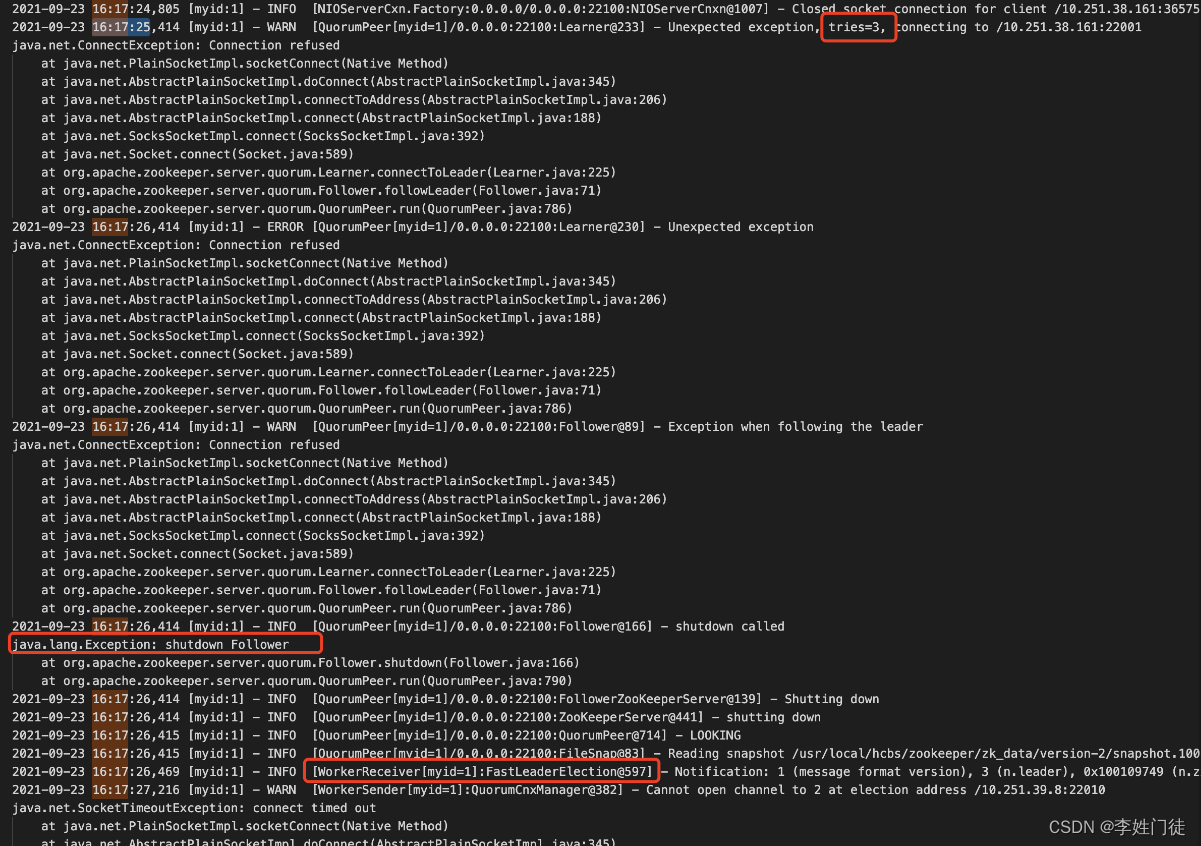
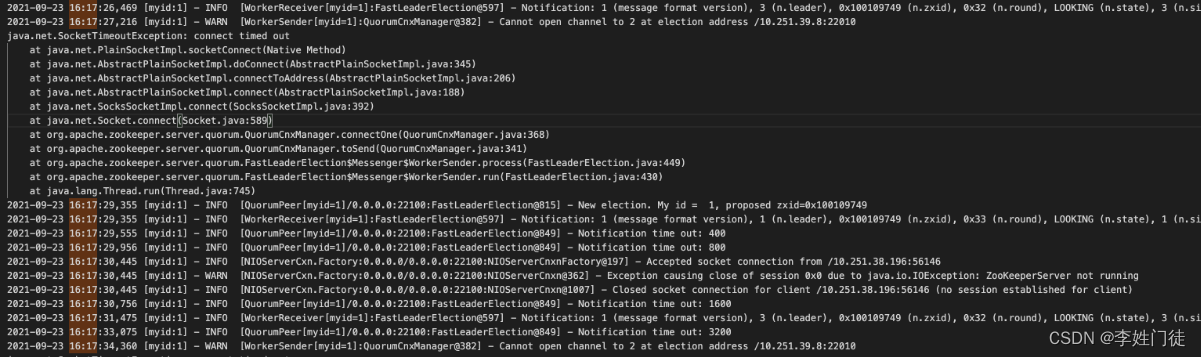
16:17:27 zk1 同步投票信息给 zk2 超时 (与 zk1 选举为follower 相差 5s), 然后zk1 按顺序 再同步投票信息给 zk3 (16:17:27 zk3 接收到 zk1 的选票)
16:17:22 ~ 16:17:26 期间,zk1尝试从zk3同步数据为什么失败呢?
打开zk3日志,查看这段时间zk3的状态。
16:17:22 zk3 还处于第一轮接受选票阶段,还不是 Leader,所以没有监听数据同步端口。
16:17:27 zk3 接收到 zk1 和 zk3 投递给自己的选票 (第二轮), 正式成为Leader
16:17:29 zk3 重新开始选举 (16:17:26 zk1 停止同步数据,重新发起选举)
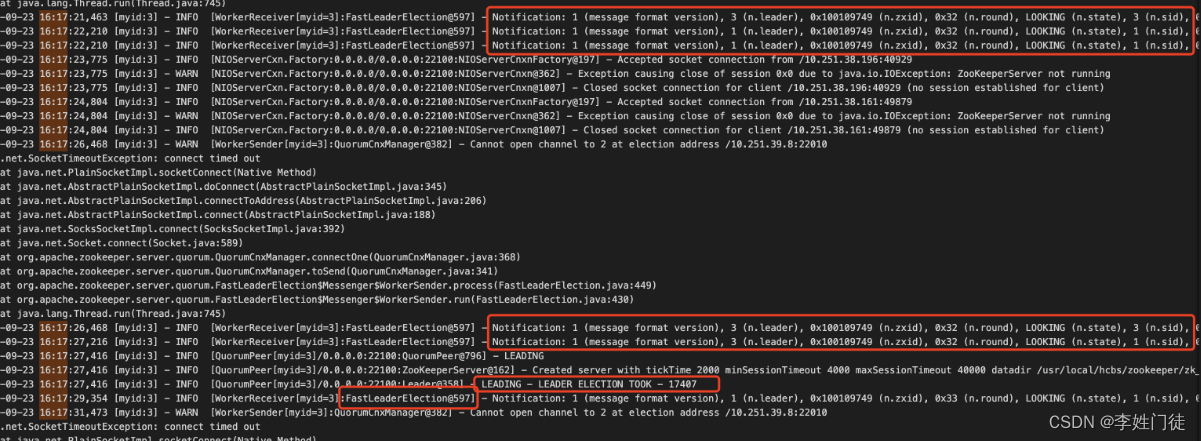
综上所述,选举失败的直接原因是zk3总是晚5秒收到zk1投给zk3的选票。
4. 优化建议
1, 设置cnxTimeout=3000进行规避,绕开4s的限制。
2, 该问题的修复版本在3.5.8以后,也可以升级到3.5.8以后的版本规避
5. 疑问和思考
5.1 Follower和Leader等待时间的差异
follower会主动连接leader的数据同步端口, 如果失败会重试4次, 总共耗时大约4s.
leader等待follower来连接的时间是initLimit(默认10)乘以tickTime(默认2s),大约是20s。
5.2 为什么多轮选举,总是不能选择出Leader?
原因是zk进行投票后的广播顺序,呈现顺序性,先从sid小的开始,串行进行。如果广播的顺序是随机进行的,则多轮选举后,选举出Leader的概率比较高。
5.3 如果zk1和zk3(非中间节点)宕机是否能够触发该风险
1, 中间节点宕机都有有概率触发该问题,导致集群无法选主
2, 边缘节点zk1、zk3不会有该风险


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









